Когда мы говорим о KPI и эффективности, возникает вопрос: а что вообще должен отслеживать SOC в своей повседневной деятельности? С одной стороны, тут все понятно: во-первых, соблюдение SLA, а во-вторых, возникающие события с подозрениями на инциденты. Но ведь статистику событий можно смотреть под разными углами. А еще проблемы с источниками, а еще аномалии, а еще нагрузка на SIEM и т.д. – параметров масса. Какие из них достойны дашборда аналитика – об этом поговорим ниже.

Первое, что приходит в голову, — это степень выполнения SLA. Отслеживать этот параметр нужно на всех этапах: регистрация и анализ событий ИБ, оповещение заказчика, решение инцидента, проведение расследования и т. д. И здесь надо видеть не только среднее время (а лучше медиану), но и максимальные и минимальные значения. Разумеется, должна быть возможность видеть выполнение SLA по каждому инциденту, чтобы проводить анализ и выяснять, в каких случаях он нарушается.
Понятно, что отслеживать только время недостаточно — нужно вести статистику изменения количества инцидентов, по которым был нарушен SLA. Иными словами, при подключении заказчика мы прописываем SLA не только по сервису в целом, но и по каждому конкретному событию ИБ (в данном случае нас интересует информация о том, что это за инцидент и в какие моменты он изменял свои статусы). Так мы сможем адресно раздать люлей понять, кто «виноват» и в какой момент случился сбой в процессе, чтобы сразу выявить причины. Ну и подстелить соломки, дабы избежать такого «счастья» в будущем.
Такая статистика даст понимание, насколько компания подвержена внешним и/или внутренним атакам, на какие объекты они направлены (а это уже может стать стимулом для оптимизации внутренних ИБ-процессов у заказчика). И тут нам важно понимать:
Кроме того, будет полезно понимать, в какой стадии жизненного цикла сейчас находится событие ИБ (зарегистрировано, в работе, эскалация, решено, отклонено или расследование), насколько оно критичное, какие активы затрагивает, сколько сил уже потрачено на его «ликвидацию» и сколько еще потребуется.

Отдельно смотрим статистику по событиям, признанным инцидентами. Разрезов, в которых мы можем смотреть статистику, множество: категории и статусы событий; внешняя атака или внутренний инцидент; критичность; SLA; хосты или пользователи, которых затрагивают события; затронутые системы или подразделения; источники, с которых были получены события ИБ, и т. д.
Здесь мы отслеживаем, сколько времени занимает ответ заказчика на наше оповещение о возможном инциденте ИБ, и ведем статистику по оповещениям, которые остались без ответа с его стороны. Это нужно в первую очередь для выстраивания эффективного взаимодействия. Например, если заказчик не слишком активно смотрит наши оповещения, то в случае критичного инцидента мы будем использовать все доступные каналы связи, чтобы поставить его в известность. Кроме того, в некоторых компаниях есть внутренние KPI по реагированию на сообщения SOC, и наша статистика оказывается в этой части очень востребованной.
В зависимости от того, что отвечает заказчик (признает событие инцидентом, легитимной активностью или ложным срабатыванием), мы корректируем правила. То есть понимаем, какое событие ИБ — норма и его можно занести в исключение, а какое — критичный инцидент, о котором надо оповещать заказчика не только по электронной почте, но и более оперативным путем, например, по телефону.
Для себя мы выделили еще несколько параметров, которые считаем важным отслеживать на дашбордах. Давайте по порядку.
1. Сработки сценариев, на основании которых формируется конечное событие ИБ.
Если сценарии почему-то перестали срабатывать, нужно вовремя это увидеть. Так мы сможем заметить сбои в работе и исправить их. Еще бывают сценарии, которые раньше никогда не срабатывали / срабатывали крайне редко, и вдруг это произошло впервые / участилось. Причины таких аномалий тоже надо выяснять. Когда это в явном виде показано на дашборде, намного проще следить за подобными моментами. А в итоге мы можем выявить инцидент, который ничто не предвещало.
2. Аномалии в поступлении событий ИБ с источников.
Здесь мы не только отслеживаем полное отсутствие событий от источника, но и автоматически сравниваем этот период «молчания» со статистикой «обычного» поведения источника. И если «пауза» слишком затянулась, это стоит подсветить на дашборде. Так мы сможем быстро среагировать и вовремя восстановить работу источника. Иначе может возникнуть ложное ощущение, что событий нет, значит, все хорошо и нас никто не атакует. Но по факту причин такого молчания может быть много – от некорректного вмешательства ИТ-службы заказчика в инфраструктуру до деятельности злоумышленника, который, например, написал вредоносное ПО так, что оно обходит часть пунктов в правиле. Не расслабляемся!
Динамика получения событий – тоже важный показатель. Бывает такая любопытная штука: события вроде бы есть, но в их потоке наблюдаются таинственные «проседания» или «провалы». Такую картинку на графике лучше заметить вовремя, чтобы потом не пропустить инцидент.
3. Данные конкретного источника.
Видя дашборды по конкретным источникам, мы можем сравнить собранные ими события с тем, что SIEM посчитал инцидентами. Здесь мы анализируем, какие из событий были обработаны корректно, а какие надо добавить в корреляцию для выявления инцидентов. Сырую статистику со средств защиты забираем в дашборд и сравниваем, сколько атак было заблокировано ими, а сколько прилетело в SOC. Таким образом, дашборд должен показать общий уровень (количество и сложность) атак на заказчика и сколько атак требуют его реакции. То есть сколько их было совершено и сколько дошло до заказчика.
4. Нагрузка SIEM.
Можно написать много красивых сценариев и правил в SIEM-системе, которые будут круто работать. Но при этом они могут очень сильно ее нагружать, а в какой-то момент вообще «положат», да и линиям мониторинга будет трудно справляться с ними. Поэтому статистику по нагрузке правила надо показывать на дашборде в явном виде – в этом вопросе лучше перебдеть, чем недобдеть. Ну а дальше смотрим и анализируем, как изменялась нагрузка каждого правила. Отслеживаем влияние на нагрузку SIEM корректировок внутри правила и внешние изменения (например, если произошли изменения в инфраструктуре заказчика или правило было запущено у нескольких заказчиков). Исходя из этого, делаем выводы: нужно ли такое правило в целом (и в нынешнем виде в частности), не проще ли его отключить совсем или модифицировать.
5. Массовость атак.
Когда у вас много заказчиков по всей стране или даже миру, есть смысл сделать дашборд с картой, на которой можно отслеживать массовость атак. На карте почти в реальном времени будет отображаться информация о возникающих инцидентах, координаты начала атаки (IP источника) и ее цели (IP назначения).

Если векторов на карте становится слишком много, мы видим массовые атаки. Бывает, что все они исходят из одной точки, а направлены на разные. Бывает и наоборот. Для наглядности эти векторы лучше подсвечивать разным цветом в зависимости от критичности инцидента.
Елена Трещёва, ведущий аналитик Solar JSOC

Отслеживаем выполнение SLA
Первое, что приходит в голову, — это степень выполнения SLA. Отслеживать этот параметр нужно на всех этапах: регистрация и анализ событий ИБ, оповещение заказчика, решение инцидента, проведение расследования и т. д. И здесь надо видеть не только среднее время (а лучше медиану), но и максимальные и минимальные значения. Разумеется, должна быть возможность видеть выполнение SLA по каждому инциденту, чтобы проводить анализ и выяснять, в каких случаях он нарушается.
Понятно, что отслеживать только время недостаточно — нужно вести статистику изменения количества инцидентов, по которым был нарушен SLA. Иными словами, при подключении заказчика мы прописываем SLA не только по сервису в целом, но и по каждому конкретному событию ИБ (в данном случае нас интересует информация о том, что это за инцидент и в какие моменты он изменял свои статусы). Так мы сможем
Ведем статистику событий ИБ
Такая статистика даст понимание, насколько компания подвержена внешним и/или внутренним атакам, на какие объекты они направлены (а это уже может стать стимулом для оптимизации внутренних ИБ-процессов у заказчика). И тут нам важно понимать:
- что является нормальным поведением систем/пользователей, а на что стоит обратить внимание;
- сколько событий ИБ происходит в целом;
- о скольких мы сообщаем заказчику как о подозрении на инцидент;
- какие события наиболее часты;
- где они происходят;
- насколько важные для заказчика активы затрагиваются (иногда коммерческий SOC знает инфраструктуру заказчика лучше, чем он сам);
- какие подразделения вовлекаются в события в качестве жертв и в качестве источников;
- в какой момент происходят всплески по количеству событий, почему так случается, есть ли в этом какая-то закономерность и можем ли мы с этим что-то сделать.
Кроме того, будет полезно понимать, в какой стадии жизненного цикла сейчас находится событие ИБ (зарегистрировано, в работе, эскалация, решено, отклонено или расследование), насколько оно критичное, какие активы затрагивает, сколько сил уже потрачено на его «ликвидацию» и сколько еще потребуется.
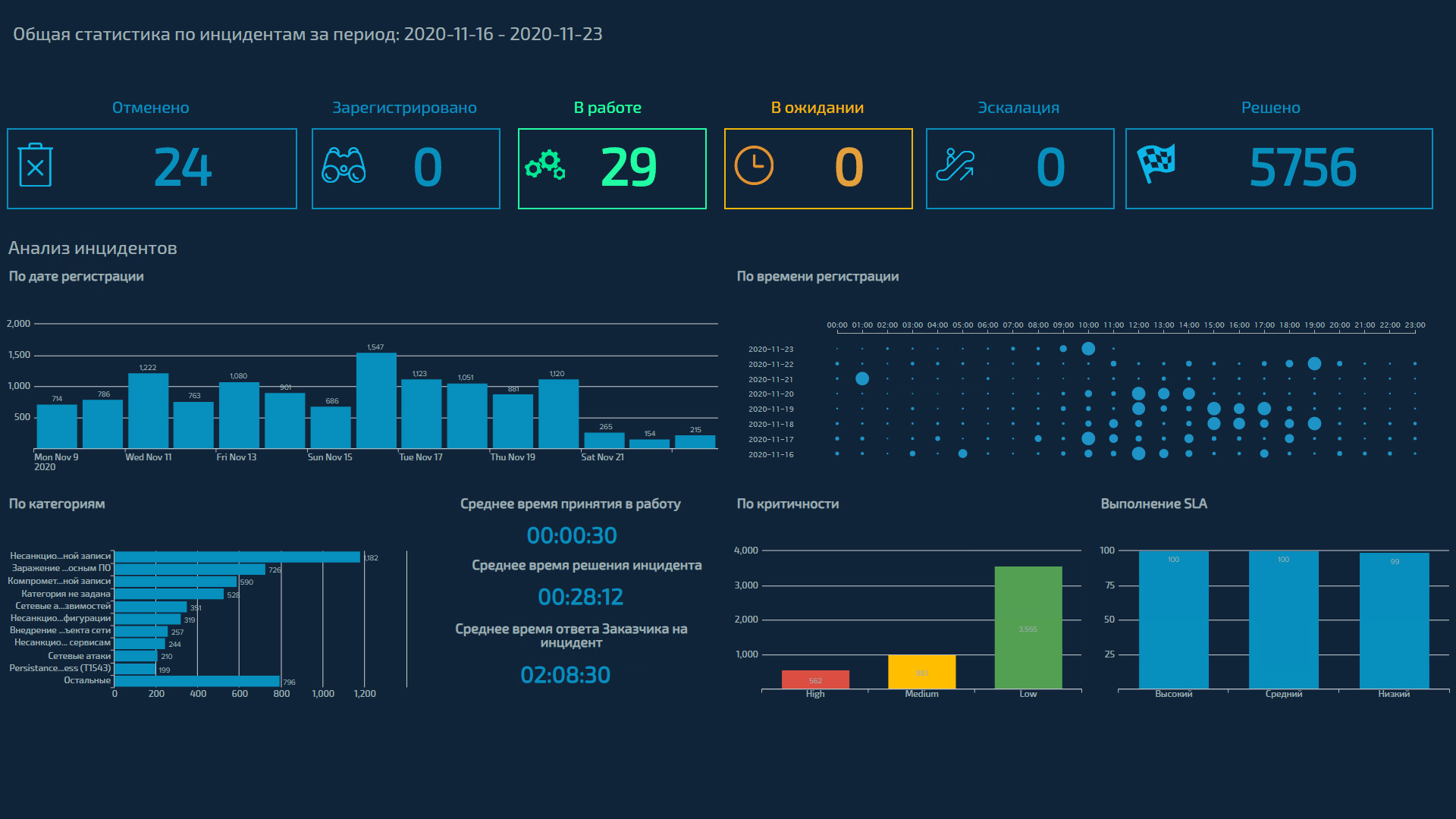
Отдельно смотрим статистику по событиям, признанным инцидентами. Разрезов, в которых мы можем смотреть статистику, множество: категории и статусы событий; внешняя атака или внутренний инцидент; критичность; SLA; хосты или пользователи, которых затрагивают события; затронутые системы или подразделения; источники, с которых были получены события ИБ, и т. д.
Смотрим на реакцию заказчика
Здесь мы отслеживаем, сколько времени занимает ответ заказчика на наше оповещение о возможном инциденте ИБ, и ведем статистику по оповещениям, которые остались без ответа с его стороны. Это нужно в первую очередь для выстраивания эффективного взаимодействия. Например, если заказчик не слишком активно смотрит наши оповещения, то в случае критичного инцидента мы будем использовать все доступные каналы связи, чтобы поставить его в известность. Кроме того, в некоторых компаниях есть внутренние KPI по реагированию на сообщения SOC, и наша статистика оказывается в этой части очень востребованной.
В зависимости от того, что отвечает заказчик (признает событие инцидентом, легитимной активностью или ложным срабатыванием), мы корректируем правила. То есть понимаем, какое событие ИБ — норма и его можно занести в исключение, а какое — критичный инцидент, о котором надо оповещать заказчика не только по электронной почте, но и более оперативным путем, например, по телефону.
Что еще?
Для себя мы выделили еще несколько параметров, которые считаем важным отслеживать на дашбордах. Давайте по порядку.
1. Сработки сценариев, на основании которых формируется конечное событие ИБ.
Если сценарии почему-то перестали срабатывать, нужно вовремя это увидеть. Так мы сможем заметить сбои в работе и исправить их. Еще бывают сценарии, которые раньше никогда не срабатывали / срабатывали крайне редко, и вдруг это произошло впервые / участилось. Причины таких аномалий тоже надо выяснять. Когда это в явном виде показано на дашборде, намного проще следить за подобными моментами. А в итоге мы можем выявить инцидент, который ничто не предвещало.
2. Аномалии в поступлении событий ИБ с источников.
Здесь мы не только отслеживаем полное отсутствие событий от источника, но и автоматически сравниваем этот период «молчания» со статистикой «обычного» поведения источника. И если «пауза» слишком затянулась, это стоит подсветить на дашборде. Так мы сможем быстро среагировать и вовремя восстановить работу источника. Иначе может возникнуть ложное ощущение, что событий нет, значит, все хорошо и нас никто не атакует. Но по факту причин такого молчания может быть много – от некорректного вмешательства ИТ-службы заказчика в инфраструктуру до деятельности злоумышленника, который, например, написал вредоносное ПО так, что оно обходит часть пунктов в правиле. Не расслабляемся!
Динамика получения событий – тоже важный показатель. Бывает такая любопытная штука: события вроде бы есть, но в их потоке наблюдаются таинственные «проседания» или «провалы». Такую картинку на графике лучше заметить вовремя, чтобы потом не пропустить инцидент.
3. Данные конкретного источника.
Видя дашборды по конкретным источникам, мы можем сравнить собранные ими события с тем, что SIEM посчитал инцидентами. Здесь мы анализируем, какие из событий были обработаны корректно, а какие надо добавить в корреляцию для выявления инцидентов. Сырую статистику со средств защиты забираем в дашборд и сравниваем, сколько атак было заблокировано ими, а сколько прилетело в SOC. Таким образом, дашборд должен показать общий уровень (количество и сложность) атак на заказчика и сколько атак требуют его реакции. То есть сколько их было совершено и сколько дошло до заказчика.
4. Нагрузка SIEM.
Можно написать много красивых сценариев и правил в SIEM-системе, которые будут круто работать. Но при этом они могут очень сильно ее нагружать, а в какой-то момент вообще «положат», да и линиям мониторинга будет трудно справляться с ними. Поэтому статистику по нагрузке правила надо показывать на дашборде в явном виде – в этом вопросе лучше перебдеть, чем недобдеть. Ну а дальше смотрим и анализируем, как изменялась нагрузка каждого правила. Отслеживаем влияние на нагрузку SIEM корректировок внутри правила и внешние изменения (например, если произошли изменения в инфраструктуре заказчика или правило было запущено у нескольких заказчиков). Исходя из этого, делаем выводы: нужно ли такое правило в целом (и в нынешнем виде в частности), не проще ли его отключить совсем или модифицировать.
5. Массовость атак.
Когда у вас много заказчиков по всей стране или даже миру, есть смысл сделать дашборд с картой, на которой можно отслеживать массовость атак. На карте почти в реальном времени будет отображаться информация о возникающих инцидентах, координаты начала атаки (IP источника) и ее цели (IP назначения).
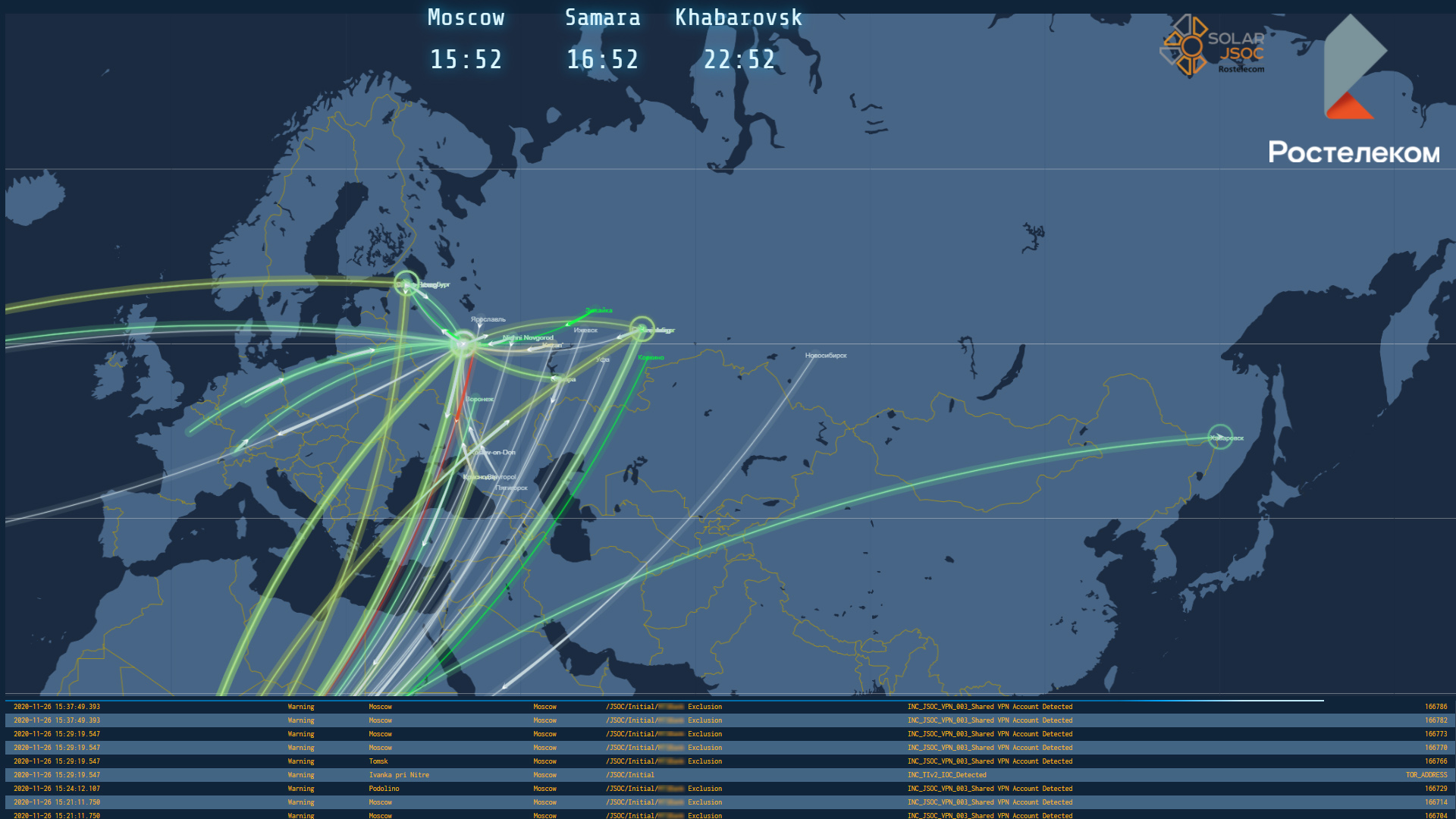
Если векторов на карте становится слишком много, мы видим массовые атаки. Бывает, что все они исходят из одной точки, а направлены на разные. Бывает и наоборот. Для наглядности эти векторы лучше подсвечивать разным цветом в зависимости от критичности инцидента.
Елена Трещёва, ведущий аналитик Solar JSOC
