Продолжаем обзор паттернов интеграции микросервисов. В первой части мы рассказали, зачем IT-специалистам нужны шаблоны интеграции, и для каких задач они подходят. Подробно остановились на Circuit Breaker, Sidecar, Ambassador, Anti-Corruption Layer и Async Request-Reply. Сегодня по плану разобрать Backends for Frontends, Cache-Aside, Gateway, Gateway Aggregation и Gateway Routing.

Дисклеймер: эта статья — текстовая версия нашего недавнего вебинара «Обзор паттернов интеграции микросервисов» от энтерпрайз-архитектора Пётр Щербакова. Для тех, кому удобнее смотреть, а не читать, есть запись.
Backends for Frontends
Backends for Frontends — паттерн интеграции между бэком и фронтом для разных платформ. Позволяет упростить разработку бэкенд-логики, улучшить масштабирование и повысить отказоустойчивость. За счёт разделения по признаку платформы или типа пользовательского интерфейса повышает возможности для оптимизации. Подчиняется принципам ISP и SRP.

Плюсы:
Масштабируемость. Если понимаете, что количество десктопных клиентов меньше, то и количество десктопных бэкендов тоже будет меньше.
Упрощение расширения функций для платформы. Каждый десктоп связан только со своим фронтом, и вместе они связаны с базами (база может быть не одна).
Гибкая оптимизация для каждой из платформ. Каждый из бэкендов вы можете настроить под конкретную платформу.
Минусы:
Усложнение поддержки и мониторинга. Вы получаете три платформы (три бэка) и должны мониторить каждый из них.
Вероятность рассинхронизации платформ по функциям. Мобильный бэкенд может оказаться быстрее в разработке, поэтому функций, которые доступны для мобильных устройств, может не быть в вебе или десктопе.
Возможность deadlock. При использовании одной базы и параллельной работе двух клиентов нужно правильно управлять deadlock для корректной синхронизации данных.
Cache-Aside
Cache-Aside — паттерн интеграции сервиса в базу данных на основе кэша для увеличения производительности. Позволяет повысить производительность и помогает поддерживать согласованность между данными из кэша и данными из базового хранилища данных.
Как работает: мы ищем в кэше запрашиваемые данные. Если данных в кэше нет, забираем их из БД. Загружаем в кэш и отдаём клиентам, которые их запрашивают.

Cache-Aside предназначен для непредсказуемого спроса, когда вы не знаете, сколько раз запросят одни и те же данные. Простой пример: у вас новостной портал, где ежедневно публикуются 200-300 новостей. Каждую новость вы загружаете в кэш. Допустим, самая популярная новость становится первой — скорее всего, её будут открывать чаще, но не факт. Здесь и проявляется непредсказуемость спроса. Чтобы постоянно не ходить в базу данных и не забирать новость, вы кладёте её в кэш. Теперь, когда пользователи будут её запрашивать, вы легко вытянете из кэша нужную новость.
Cache-Aside – это история, когда вы в первую очередь живёте на кэше. Сначала кэш, а потом база данных.
Плюсы:
производительность;
простота реализации;
снижение нагрузки на БД;
сглаживание нагрузки на СХД.
Минусы:
необходимость управления состоянием данных в кэше;
дополнительная точка возможного отказа;
потребление ресурса памяти.
Gateway
Gateway — паттерн интеграции между клиентским приложением и большим количеством сервисов.
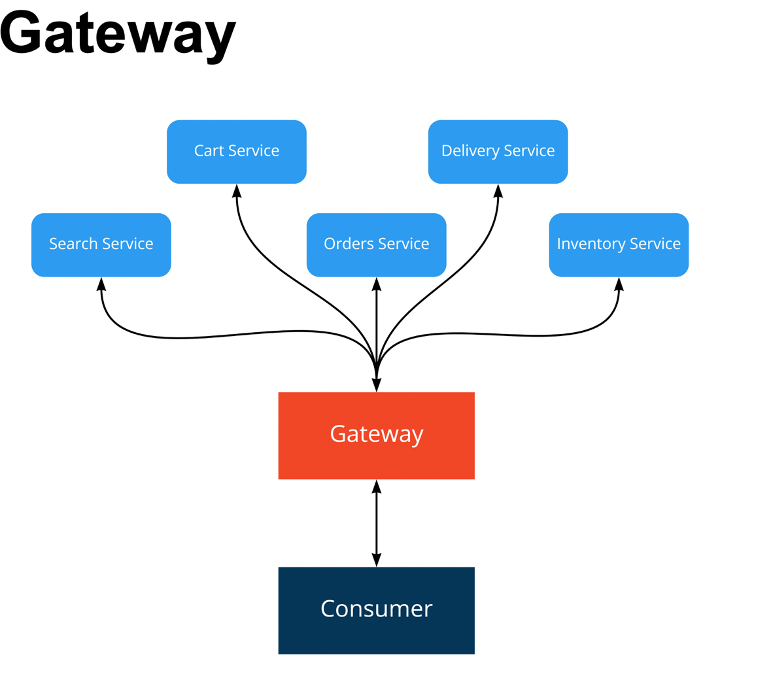
Gateway отвечает за:
мониторинг — статистику спроса по эндпоинту и логирование запросов;
безопасность — SSL на внутренние сервисы и политики безопасности;
тротлинг — Rate Limit (максимальное количество запросов от сервиса) и User quota (квоту на пользователей);
проксирование — авторизацию, балансировку нагрузки и смену протоколов (как минимум, с HTTPS на HTTP);
декодирование форматов;
фильтрацию;
кэширование;
трансформацию данных.
Предлагаем пойти дальше и посмотреть более предметно, когда Gateway точно помогает.
Gateway Aggregation
Gateway Aggregation — паттерн интеграции между клиентским приложением и большим количеством сервисов. Позволяет сделать один запрос, объединяющий в себе несколько запросов, и получить объединённый ответ. Применяется для сокращения количества походов от клиента к сервисам.
Как работает: изначально у нас был Consumer, и мы обращались к каждому сервису, чтобы собрать данные.

Благодаря Gateway мы просто делаем один вызов. Далее Gateway самостоятельно распараллеливает вызовы каждого сервиса по нужным характеристикам.

При необходимости мы можем сказать Gateway, что нужно дождаться ответа от одного сервиса и пойти в другой уже с какими-то параметрами.
Плюсы:
единая точка интеграции для клиента;
устойчивость к расширению;
сокращение количества походов клиентом;
подходит для сетей со значительной задержкой.
Минусы:
единая и дополнительная точка отказа;
большой разовый объём передачи данных;
при падении запроса теряется вся информация.
Gateway Routing
Gateway Routing — паттерн интеграции между клиентским приложением
и большим количеством сервисов. Позволяет сделать единый контракт для системы пользователя ресурсов (клиента) из различных сервисов. Предоставляет единую точку доступа ко всем сервисам. Для каждого из клиентов вы можете создать уникальный контракт.
Есть специфика: вы можете сделать множество Gateway с разным количеством сервисов для клиента. Но поскольку Gateway отвечает за авторизацию и маршрутизацию, то набор эндпоинтов может предоставляться по имени пользователя.

Плюсы:
единая точка интеграции для клиента;
устойчивость к расширению и масштабируемость;
унификация интерфейса взаимодействия с клиентом.
Минусы:
единая и дополнительная точка отказа;
небольшое увеличение latency;
отсутствие ресурсов, потребность в множестве разнородных контрактов.
Query-based Load Leveling
Query-based Load Leveling — паттерн интеграции между приложениями на основе очередей с целью балансировки нагрузки. Использует очередь для сглаживания нагрузки на сервис.
Периодические тяжелые нагрузки могут «ронять» сервис или повышать тайм-аут обработки задачи. Данный паттерн сглаживает влияние пиков на доступность и оперативность реагирования. Пример — использование очереди на входе сервиса сбора логов.
Как работает: у вас есть сервис, и есть очередь сообщений, куда падают таски. Таски могут генерироваться любой системой. Вы знаете, что в какой-то момент времени есть всплески по задачам.
Нагрузочное тестирование показало, что ваша конфигурация выдерживает 100 запросов. Но вы работаете по HTTP и понимаете, что у вас всплеск — 150 запросов. По идее, в такой момент сервис может что-то отложить и обработать позже, а может свалиться от количества запросов и перестать отвечать.
Чтобы избежать этого, мы ставим очередь на вход — если раньше был запрос напрямую к сервису, то теперь мы всё делаем на очередях. Таски падают в очередь, и сервис их обрабатывает.
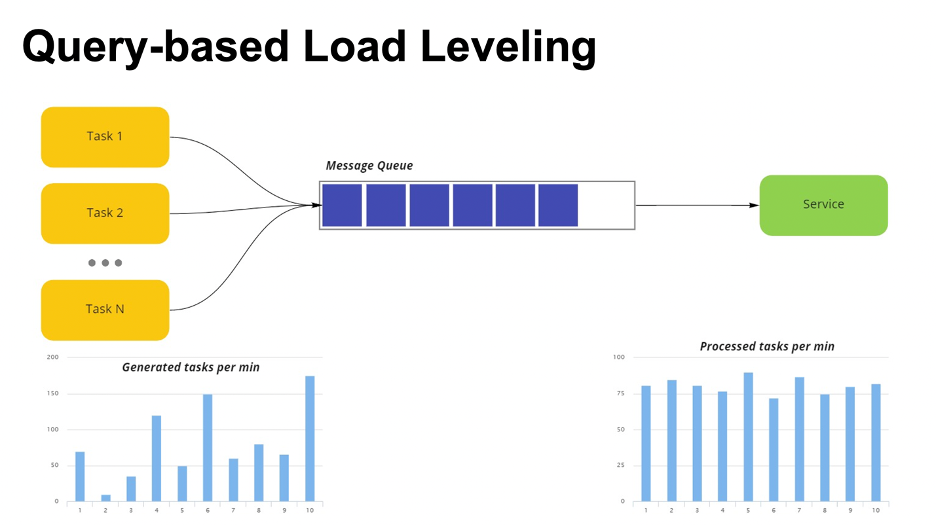
Плюс: подходит для любого приложения, которое интегрировано с сервисами подверженными перегрузкам.
Минус: бесполезен, когда ответ от сервиса должен прийти с минимальной задержкой.
При потребности отправки ответа на сообщение нужно организовать очередь ответа.
Пара слов напоследок
Всё, к чему мы пытались привести в рамках статьи, — это то, что интеграционные паттерны стоит использовать осознанно. Обычно они применяются между микросервисами, или когда вы распиливаете монолит.
Для тех, кто хочет разобраться в распиле монолита и получить скидку на обучение
29 сентября у нас стартует курс «Микросервисы: проектирование и интеграция на Go», который будет полезен для middle и senior-разработчикам, системным аналитикам, архитекторам и тимлидам.
Вы узнаете:
какие бывают потребности в разделении и как к нему приступить;
какую стратегию выбрать;
как избежать подводных камней;
как поддерживать получившуюся архитектуру.
Автор курса — Петр Щербаков, Enterprise Architect.
Подробнее ознакомиться с программой: https://slurm.club/3QlJ6JH
Промокод «READER» даёт скидку 10% при покупке курса.
