
- Реализация AI: как сделать максимально просто?
- RPC клиент-сервер: json или бинарная «самопальщина»?
- Асинхронные сокеты или многопоточная архитектура?
- Кеширование объектов на уровне приложения или больше памяти для СУБД?
- Работа с БД без Reflection API: действительно ли это так сложно?
Сегодня мы продолжим рассматривать архитектуру и особенности реализации игрового backend'а на С++ для онлайн игры на примере ММО РПГ «Звездные Призраки». Это вторая часть статьи про сервер, начало можно прочитать здесь.
Модуль AI.
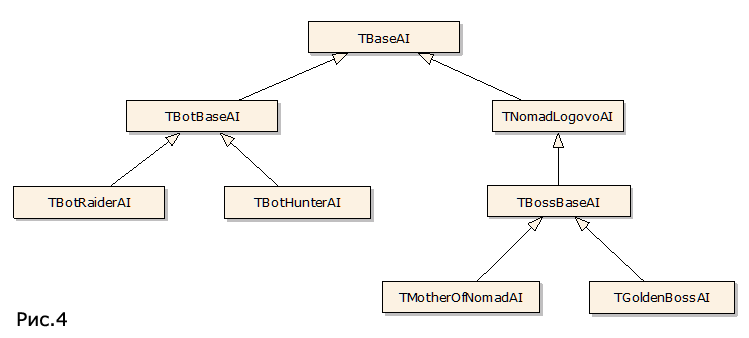
Обычно реализация AI – это достаточно сложный процесс. Но нам удалось сделать это «малой кровью» прежде всего за счет использования Actions. Фактически AI представляет конечный автомат, который может куда-то лететь, собирать ресурсы, нападать на другие космические корабли и перемещаться между системами. На момент создания AI реализация всех этих действий уже была в Actions для управления кораблем игрока. То есть все написание TBaseAI – это создание загрузки данных из БД для конечного автомата и сам этот автомат из нескольких действий, что достаточно просто в реализации.
Немного сложностей появилось только после введения таких монстров, как «Босс», «Золотой Босс» и «Королева Роя». У них есть специфичные навыки, которые доступны только им. Реализация этих навыков полностью находится в их классах AI (TBossBaseAI, TGoldenBossAI и TMotherOfNomadAI).
Так же для AI пришлось создать класс TAISpaceShip, потомок от TSpaceShip, который содержит в себе экземпляр TBaseAI и вызывает TBaseAI ::Update из своего Update.
AI должен получать сообщения о происходящем, например о том, что на него напали. Для этого мы сделали его потомком от ISpaceShipNotifyReciver и TSpaceShip отправляет ему необходимые данные. Иными словами, правильное архитектурное решение позволило нам полностью унифицировать общение модуля Space с владельцем корабля, будь то игрок или AI.
В заключение привожу диаграмму классов на рис.4 (для большей наглядности диаграмма несколько упрощена).
Модуль Quest.
На этапе выбора реализации квестовой системы первой мыслью было использование какого-то скриптового языка типа LUA, который бы позволил «писать что угодно». Но для работы с LUA все равно необходимо экспортировать методы и колбеки в саму машину LUA, а это очень неудобно и приводит к написанию большого количества дополнительного кода, который ничего не делает, кроме как является медиатором. Учитывая, что квестовая система у нас очень простая (в итоге у нас всего 25 команд), одновременно может быть не более одного квеста, никаких ветвлений в квестах нет, мы решили сделать свой парсер квестов. Вот пример из квестового файла пролога tutor.xmq:
show reel 1
then
flyto 1000 -1900 insys StartSystem
then
show reel 2
then
flyto 950 -1450 insys StartSystem
then
show reel 3
then
spawn_oku ship 1 000_nrds near_user -400 200 insys StartSystem
Навскидку и так все понятно: показать ролик 1, полететь в точку с координатами 1000;-1900 в стартовой системе, потом показать ролик 2 и т.д. Файл настолько простой, что нам удалось даже гейм-дизайнера научить его править и дописывать квесты и балансировать нужные ему параметры.
Архитектурно это выглядит так. Есть класс TQuestParser который собственно парсит квестовые файлы и содержит в себе фабрику для классов-потомков TQuestCondition. Для каждой команды есть свой потомок от TQuestCondition, который и реализует необходимый функционал. При этом сами квестовые классы-команды не содержат никаких данных (кроме загруженных непосредственно из квестового файла), все их методы объявлены как const. Данные содержатся в классе TQuest. Это позволяет содержать только одну копию квестовых команд, «подсовывая» их необходимые данные, специфичные для конкретного пользователя (например, сколько он уже убил номадов заданного типа). Так же это упрощает сохранение квестовых данных в БД – они все собранны в одном месте.
Объект-owner объекта TQuest должен реализовывать интерфейс IQuestUser (который содержит такие команды, как, например, AddQuestMoney) и должен сообщать в TQuest о происходящих событиях (например, когда уничтожается любой корабль, в TQuest отправляется сообщение с его сигнатурой, чтобы квестовая команда могла сравнить тот ли это корабль, который нужно было уничтожить). TQuest же переправляет это событие непосредственно в квест-команду и если квест-команда закончилась, то переходит к следующей команде.
В общем, этот модуль насколько прост, что даже нет смысла приводить его диаграмму классов :).
RPC клиент<->сервер (и модуль Packets).
При проектировании сетевой подсистемы первым желанием было использовать json или AMF (т.к. клиент на флеше, а это родной бинарный формат флеша). Практически сразу обе эти идеи были отброшены: игра в реальном времени и используется TCP соединение, поэтому необходимо минимизировать размер пакета, чтобы шанс потери пакета (и его повторной передачи, TCP же все-таки :) был минимальный. Потеря пакета в TCP и его ретрансляция – это довольно долгий процесс, который может привести к лагам. Конечно, этого хотелось избежать. Второй, не менее важный момент – это ограниченная пропусканная способность сетевой карты. Это может показаться смешным, но мне приходилось делать аудит одной игры, в которой из-за использования json и системы polling-based, а не event-based, разработчики уперлись именно в пропускную способностью сетевой карты. И после этого все читаемые и красиво названные поля в json пришлось называть в стиле A, B и т.д. для того, чтобы минимизировать размер пакета. Что касается AMF, то это закрытый формат от Adobe, поэтому мы решили с ним не связываться – мало ли что там решат изменить, а нам потом ищи проблему.
В итоге мы реализовали очень простой формат пакета. Он состоит из заголовка, содержащего полную длину пакета и типа пакета. Но ведь нужен ещё код, который будет упаковывать/распаковывать в/из бинарного вида сами структуры данных, а так же сигнализировать о приходящих пакетах. И делать это одинаково и на сервере и на клиенте. Писать всю эту кучу кода руками на двух языках (клиент и сервер), а потом поддерживать – это слишком хлопотно. Поэтому мы написали на РНР скрипт, который принимает XML с описанием всех пакетов и генерирует по ним необходимые классы для клиента и сервера. Кроме генерации собственно самих классов пакетов и сериализации в них, для сервера генерируется ещё один специальный дополнительный класс TStdUserProcessor. Этот класс содержит колбеки для каждого типа пакета (что позволяет централизованно управлять типами принимаемых пакетов на данной стадии работы), а каждый колбек создает экземпляр класс пакета и загружает в него бинарные данные, после чего вызывает его обработчик. В коде это выглядит так:
virtual void OnClientLoginPacket(TClientLoginPacket& val)=0;
void OnClientLoginPacketRecived(TByteOStream& ba);
void TStdUserProcessor::OnClientLoginPacketRecived(TByteOStream& ba) { TClientLoginPacket p; ba>>p; OnClientLoginPacket(p); }
То есть для класса-потомка от TStdUserProcessor реализуется прозрачный мост «клиент<->сервер», где отправка пакета из клиента – это простой вызов метода в TUserProcessor.
А кто вызывает эти колбеки? TStdUserProcessor – потомок от класса TBaseUserProcessor, который и выполняет m_xSocket.Recv, а так же выполняет разбиение бинарного потока на пакеты, находит в заголовке тип пакета и по этому типу находит необходимый колбек. Выглядит это так:
void TStdUserProcessor::AddCallbacks() {
AddCallback( NNNetworkPackets::ClientLogin, &TStdUserProcessor::OnClientLoginPacketRecived );
}
void TBaseUserProcessor::RecvData() {
if( !m_xSocket || m_xSocket->State()!=NNSocketState::Connected ) return;
if( !m_xSocket->AvailData() ) return;
m_xReciver.RecvData();
if( !m_xReciver.IsPacketRecived() ) return;
// а теперь найдем колбек и вызовем его по типу, заодно "отрезав" данные служебный хедер
int type = m_xReciver.Data()->Type;
if( type>=int(m_vCallbacks.size()) ) _ERROR("NoCallback for class "<<type);
SLocalCallbackType cb = m_vCallbacks[type];
if(cb==NULL) _ERROR("NoCallback for class "<<type);
TStdUserProcessor* c_ptr = (TStdUserProcessor*)this;
const uint8* data_ptr = (const uint8*)m_xReciver.Data();
data_ptr += sizeof(TNetworkPacket);
TByteOStream byte_os( data_ptr, m_xReciver.Data()->Size-sizeof(TNetworkPacket) );
if( m_xIgnoreAllPackets==0 ) {
(*c_ptr.*cb)( byte_os );
}
m_xReciver.ClearPacket();
}
Сокетная модель.
Теперь мы поговорим, пожалуй, о самом интересном – об используемой сокетной модели. Есть два «классических» подхода к работе с сокетами: асинхронный и многопоточный. Первый в общем-то, быстрее, чем многопоточный (т.к. нет переключения контекста потока) и с ним меньше проблем: все в одном потоке и никаких проблем с рассинхронизацией данных или dead lock'ами. Второй дает более быстрый отклик на действие пользователя (если не все ресурсы съели большим количеством потоков), но несет кучу проблем с многопоточным обращением к данным. Ни один из этих подходов нас не устроил, поэтому мы выбрали смешанную модель – асинхронного-многопоточную. Поясню подробнее.
«Звездные Призраки» — игра про космос, поэтому игровой мир разбит на локации изначально. Каждая солнечная система – отдельная локация, перемещение между системами происходит с помощью гипер-врат. Это деление игрового мира нам и подсказало архитектурное решение – на каждую солнечную систему выделяется отдельный поток, работа с сокетами в этом потоке выполняется асинхронно. Так же создается несколько потоков для обслуживания планет и переходных состояний (гиперпространства, загрузки/выгрузки данных и прочего). Фактически гиперпрыжок – это перемещение объекта пользователя из одного потока в другой. Такое архитектурное решение позволяет не только легко масштабировать систему (вплоть до выделения отдельного сервера на каждую солнечную систему), но и существенно упрощает взаимодействие пользователей в пределах одной солнечной системы. А ведь именно полеты и бои в космосе для игры являются критически важными. Бонусом идет автоматическое использование многоядерной архитектуры и практически полное отсутствие объектов синхронизации – игроки из разных систем между собой практически не взаимодействуют, а, находясь в одной системе, они находятся в одном потоке.
Работа с БД.
В «Звездных Призраках» все данные игрока (да и вообще все данные) хранятся в памяти до завершения сессии. И сохранение в БД происходит только в момент завершения сессии (например, выхода игрока из игры). Это позволяет существенно снизить нагрузку на БД. Так же объект TSQLObject выполняет проверку изменения полей и делает UPDATE только реально измененным полям. Реализуется это следующим образом. При загрузке из БД создается копия всех загруженных данных в объекте. При вызове SaveToDB() выполняется проверка, значение каких полей не равно значениям, изначально загруженным, и только они добавляются в запрос. После выполнения UPDATE в БД, копии полей так же апдейтятся новыми значениями.
MySQL выполняет команду INSERT дольше, чем команду UPDATE, поэтому мы стремились снизить кол-во INSERT’ов. В первой реализации сохранения данных пользователя в БД, данные обо всех предметах в БД стирались и заново заносились. Очень быстро игроки накопили сотни (а некоторые – тысячи) предметов и такая операция стала очень накладной и долгой. Тогда алгоритм пришлось изменить – не измененные объекты не трогать. Кроме того, новым объектам, которым необходимо делать INSERT, сразу пытаются найти место в подписанных на удаление, чтобы не вызывать пару INSERT/DELETE, а выполнить UPDATE.
Отдельно нужно сказать про запись значения «NULL» в БД. В связи с особенностями реализации нашего TSQLObject, мы не можем записывать и читать «NULL» в/из БД. Если поле в классе типа «int», то «NULL» в него запишется как «0» и, соответственно, именно «0» будет стоять в запросе UPDATE в БД (а не «NULL», как должно быть). И это может привести к проблемам – или данные будут не верные, или, если это поле БД foreign key, то запрос будет вообще ошибочным. Для решения этой проблемы нам пришлось добавить TRIGGER’ы BEFORE UPDATE на необходимые таблицы, которые бы «0» превращали в «NULL».
Сохранение/загрузка объектов в/из БД.
Одна из проблем С++, это невозможность узнать во время выполнения строковые названия полей и обратиться к ним по строковому названию. Например, в ActionScript без проблем можно узнать названия всех полей объекта, вызвать любой метод или обратиться к любому полю. Этот механизм позволяет существенно упростить работу с БД – вам не нужно писать отдельный код для каждого класса, максимум перечислить список полей, который необходимо сохранять/загружать в/из БД, и в какую таблицу это сделать. К счастью, в С++ есть такой мощный механизм, как template, что, совместно с <cxxabi>, позволяет решить проблему отсутствия Reflection API применительно к задаче работы с БД.
Использование нашей библиотеки Reflection (как она работает разберем ниже) выглядит так:
- Необходимо отнаследоваться от класса TSQLObject.
- Необходимо в самом классе-потомке написать в public секции DECL_SQL_DISPATCH_TABLE(); (это макрос).
- В .cpp файле класса-потомка перечислить какие поля класса на какие поля таблицы отображаются, а так же название самого класса и название таблицы в БД. На примере класса TDevice это выглядит так:
BEGIN_SQL_DISPATCH_TABLE(TDevice, device) ADD_SQL_FIELD(PrototypeID, m_iPrototypeID) ADD_SQL_FIELD(SharpeningCount, m_iSharpeningCount) ADD_SQL_FIELD(RepairCount, m_iRepairCount) ADD_SQL_FIELD(CurrentStructure, m_iCurrentStructure) ADD_SQL_FIELD(DispData, m_sSQLDispData) ADD_SQL_FIELD(MicromoduleData, m_sMicromodule) ADD_SQL_FIELD(AuthorSign, m_sAuthorSign) ADD_SQL_FIELD(Flags, m_iFlags) END_SQL_DISPATCH_TABLE()
- Теперь во время выполнения можно вызвать методы void LoadFromDB(int id), void SaveToDB() и void DeleteFromDB(). При вызове будут сформированы соответствующие SQL-запросы к таблице БД device и будут загружены/сохранены данные из указанных в пп.3 полей.
Вся работа Reflection основана не следующих идеях:
- По указателю на поле, используя <cxxabi>, можно получить строковое название типа этого поля. А так же для класса — список его предков.
- Если создать указатель на объект, приравнять его к 0 и от этого указателя взять указатель на поле, то мы получим смещение данного поля относительно указателя на объект. Конечно, это может не работать в случае применения виртуального наследования, поэтому к таким классам Reflection нужно применять с осторожностью.
- Используя один класс-темлпейт, можно, для любого типа, у которого определены операторы new, delete, =, и == создать фабрику, которая может создавать, удалять, присваивать и сравнивать объекты данного типа. Добавим этой фабрике предка с виртуальными методами, которые принимают в себя указатель на объект, но не типизированный, а типа void*, и static_cast в сам темплейт, который приведет переданный void* к указателю на тип, с которым оперирует фабрика. И мы получим возможность оперировать объектами не зная их типа.
Теперь заглянем внутрь макросов.
Макрос DECL_SQL_DISPATCH_TABLE() делает следующее:
- virtual const string& SQLTableName(); — перегрузка соответствующего метода из TSQLObject
- static void InitDispatchTable(); — метод инициализации данных, необходимых Reflection для работы с этим объектом
Макрос BEGIN_SQL_DISPATCH_TABLE(ClassType, TableName); делает следующее:
- Реализует метод SQLTableName();
- Объявляет статический класс TCallFunctionBeforMain, который в конструкторе вызывает InitDispatchTable. Задача такой конструкции – проинциализировать необходимые для Reflection данные до входа в int main(), а так же избавиться от необходимости вручную прописывать в int main() вызов всех InitDispatchTable из всех классов.
- Создает фабрику объекта
- Объявляет переменную ClassType* class_ptr = 0; (используется в макросах ADD_SQL_FIELD).
Макрос ADD_SQL_FIELD(VisibleName, InternalName); делает следующее:
- Рассчитывает offset поля от начала объекта
- Добавляет в список полей данного объекта offset поля, видимое (внешнее) название для него и строковое название типа поля.
За кадром осталось создание собственно фабрик типов и создание конверторов string<->объект, а так же место хранения всех данных Reflection. Для хранения существует класс-синглтон TGlobalDispatch. Этот же класс в своем конструкторе инициализирует фабрики и строковые конвертеры для большинства простых типов.
Работа TSQLObject базируется на той идее, что используя <cxxabi> можно получить настоящие строковое название объекта во время выполнения. По этому имени запросить у TGlobalDispatch список всех опубликованных полей этого класса и его предков. Имя таблицы можно получить через вызов SQLTableName(). Строковые конвертеры для полей так же предоставит TGlobalDispatch. Теперь не составляет труда создать необходимый SQL запрос и загрузить/выгрузить объект.
БД и ID предметов.
У всех предметов в игре есть уникальный ID, который позволяет идентифицировать предмет. Но сохранение данных в БД происходит только по завершении сессии, а предмет может быть создан в любой момент. Как быть с ID предмета? Можно убрать проверку целостности данных на уровне БД (отключить AUTO_INCREMENT и PRIMARY KEY) и генерировать уникальные ключи на уровне С++. Но это плохой путь. Во-первых, вы не сможете добавлять/забирать/просматривать предметы игроков через админку на РНР, необходимо будет писать на С++ какой-то дополнительный код для этого. А, во-вторых, вероятность ошибки в вашем сервере существенно выше, чем в СУБД. В результате ошибки данные могут потерять целостность (ведь целостность теперь контролирует не БД). И потом эту целостность прийдется восстанавливать вручную, под общий вой игроков «у меня пропала супер-шмотка, которую я сегодня выбил». В общем, ID сохраненного объекта в БД должен быть равен уникальному ID предмета в игре. И снова возвращаемся к вопросу: откуда брать этот ID у вновь созданного предмета? Можно, конечно, сразу же сохранять предмет в БД, но это противоречит идее «все в памяти, сохранение в конце сессии» и, что самое главное, вызовет остановку потока, в котором может находиться не один пользователь, до окончания сохранения. И остановка может превысить то самое максимальное время отклика сервера на действия игрока (50мс), которое задано в ТЗ. Асинхронное сохранение тянет за собой иные проблемы: у нас некоторое время будет существовать объект без ID.
Идея решения проблемы с ID появилась достаточно быстро. ID задается типом «int». Все сохраненные в БД предметы имеют ID больше нуля, а все вновь созданные – меньше. Конечно, это означает, что в какой-то момент времени ID объекта измениться и это могло бы привести к проблемам. Могло бы, если бы предмет жил дальше. Но сохранение происходит в момент завершения сессии, когда предметы уже стоят в очереди на уничтожение и с ними ничего нельзя сделать.
Игра «про эльфов».
Допустим, нам необходимо сделать игру, в которой у игрока есть персонаж, которого он может одевать, есть навыки, есть магия, можно варить зелья, персонаж может бегать по локациям и убивать других персонажей, получать уровни и торговать с другими персонажами. Что необходимо сделать с текущим сервером «Звездных Призраков» чтобы создать требуемое?
Переименуем TShip в TBody и это будет любая тушка с НР, на которую можно напасть, будь то PC или NPC. TDevice так и оставим – это будет предмет, которым можно одеть на тушку (кольцо, плащ, кинжал и т.д.). Микромодули переименуем в руны, и ими можно будет усилять одеваемый шмот. TAmmoPack тоже так и оставим – ведь у эльфа может быть лук, а луку нужны стрелы. TGoodsPack так же без изменений – это любые ресурсы, а ведь ведьмакам нужны всякие цветочки и корешки мандрагоры для варки зелий. Осталось только решить вопрос с магией. Добавим один динамический параметр Mana в тушку (TBody), создадим класс TSpellProto и TSpell, а так же класс TSpellBook, потомка от TCargoBay. В TSpellBook можно положить только TSpell, а сам TSpellBook добавим в TBody. Возможность кастовать (cast) заклинания – это метод, аналогичный TShip::FireSlot. Теперь мы можем создать эльфа или дракона (или кабана или кто там нам нужен), одеть его и «записать» в его spell book заклинания. Фактически все изменения в этом модуле сводятся к переименовыванию классов и небольшой правке для добавления магии.
Переименуем модуль Space в World, а класс TSystem в TLocation. Перемещение между локациями сделаем с помощью телепортов. Телепорт, как вы догадались, это бывший TStarGate. Дальше, TSpaceObject переименуем в TWorldObject, а TSpaceShip в TWorldBody. Теперь у нашего эльфа (или дракона) появились текущие координаты и ему можно отдать команду на перемещение. Правда, он не проверяет препятствия, а при повороте нарезает круги и норовит сделать «бочку». Логику поведения TSystem и команд движения придется полностью переделать, и это будет самая затратная и трудная часть работы по адаптации сервера под игру про эльфов.
Если в модуле Space были переделаны в том числе и Actions, то модуль AI заработает практически сразу, правда без использовании магии. Если NPC должны использовать магию, то прийдется дописать код, аналогичный использованию спец.оружия на уровне TBaseAI.
Модуль Quest будет слабо изменен при условии, что квестовая система не измена. Максимум — придется что-то поменять в спауне предметов в космосе (вернее, уже в локации).
Модуль Main и Packets останутся практически без изменений. Там добавятся какие-то пакеты на использование магии, уберется ангар и это, собственно, все. Замена рецептов крафта, типов бафов и т.д. – это все гейм-дизайнерская работа, выполняется через админку и к программированию отношения не имеет.
Вот и все, сервер для игры про эльфов готов. Осталось только подождать полгода, пока нарисуют графику и сделают клиент :).
