Я продолжаю цикл статей по применению текстмайнинг-методов для решения различных задач, возникающих в рекомендательной системе веб-страниц. Сегодня я расскажу о двух задачах: автоматическое определение категорий для страниц из RSS-лент и поиск дубликатов и плагиата среди веб-страниц. Итак, по порядку.
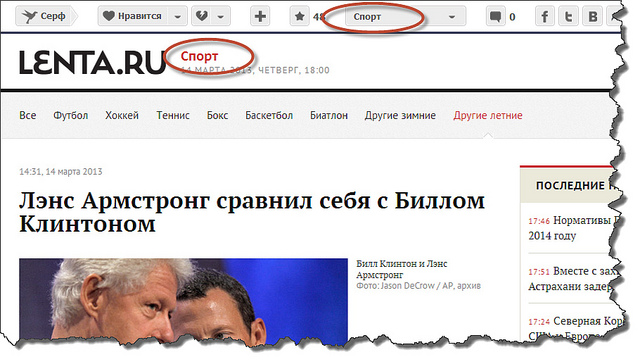
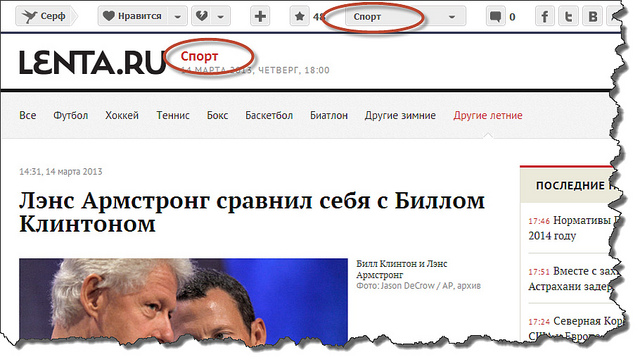
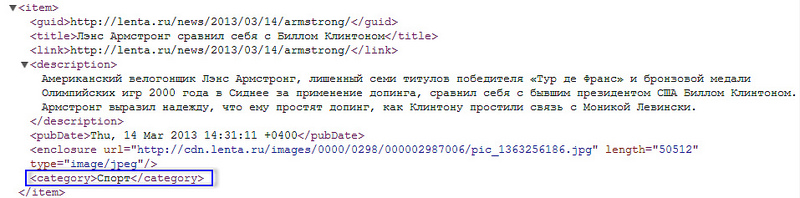
Обычная схема добавления веб-страниц (вернее, ссылок на них) в Surfingbird такова: при добавлении новой ссылки пользователь должен указать до трёх категорий, к которым принадлежит эта ссылка. Понятно, что в такой ситуации задача автоматического определения категорий не стоит. Однако, кроме ручного добавления, ссылки попадают в базу и из RSS-потоков, которые предоставляют многие популярные сайты. Поскольку ссылок, поступающих через RSS-потоки, очень много, зачастую модераторы (а в этом случае именно они вынуждены проставлять категории) просто не справляются с таким объёмом. Возникает задача создания интеллектуальной системы автоматической классификации по категориям. Для ряда сайтов (например, lenta.ru или sueta.ru) категории можно вытащить непосредственно из rss-xml и вручную привязать к нашим внутренним категориям:

Дела обстоят хуже для RSS-потоков, в которых отсутствуют фиксированные категории, а вместо этого указаны пользовательские теги. Введенные произвольным образом теги (типичный пример — теги в постах ЖЖ) невозможно вручную связать с нашими категориями. И здесь уже включается более тонкая математика. Из страницы извлекается текстовый контент (тайтл, теги, полезный текст) и применяется LDA-модель, краткое описание которой можно найти в моей предыдущей статье. В результате вычисляется вектор вероятностей принадлежности веб-страницы к тематическим LDA-топикам. Полученный вектор LDA-топиков сайта используется как вектор признаков для решения задачи классификации по категориям. При этом объектами классификации являются сайты, классами являются категории. В качестве метода классификации использовалась логистическая регрессия, хотя можно применить любой другой метод, например наивный байесовский классификатор.
Для тестирования метода обучение моделей происходило на 5 тысячах классифицированных модератором сайтах из RSS-рассылок, для которых также было известно распределение по LDA-топикам. Результаты обучения на тестовой выборке представлены в таблице:
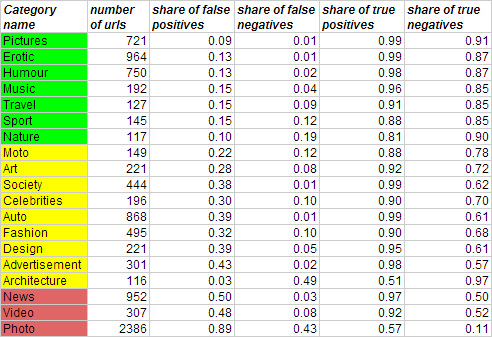
В результате приемлемое качество классификации (по доле ложных обнаружений и доле ложных пропусков) получилось только по следующим категориям: Pictures, Erotic, Humour, Music, Travel, Sport, Nature. По слишком общим категориям, например Photo, Video, News, ошибки большие.
В заключение можно сказать, что если в случае жёсткой привязки к внешним категориям классификация в принципе возможна в полностью автоматическом режиме, то классификацию по текстовому контенту неизбежно приходится вести в полуавтоматическом режиме, когда наиболее вероятные категории затем предлагаются модератору. Наша цель здесь – максимально упростить работу модератора.
Еще одна задача, которую позволяет решить текстмайнинг, — это поиск и фильтрация ссылок с повторяющимся контентом. Повтор контента возможен по одной из следующих причин:
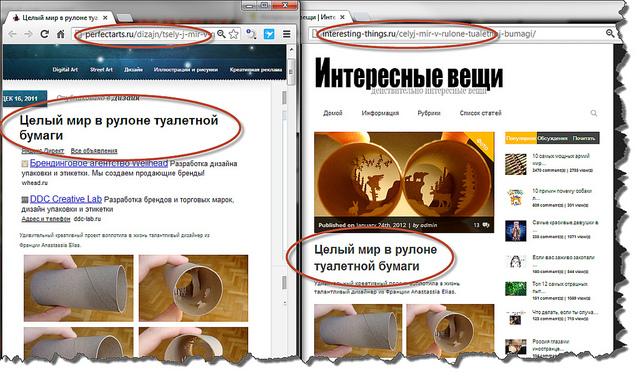
Первый и второй пункты являются техническими и решаются получением конечных ссылок и буквальным сравнением полезного контента для всех страниц в базе. Однако даже при полном копипасте формальное сравнение полезного текста может не пройти по понятным причинам (например, попали случайные символы или слова из меню сайта), а текст может быть и слегка изменён. Этот третий вариант мы и рассмотрим более подробно. Типичный двойник может выглядеть так:
Задача определения заимствований в широком смысле слова довольно сложна. Нас же она интересует в более узкой постановке: нам не нужно искать плагиат в каждой фразе текста, а нужно просто сравнить документы по контенту целиком.
Для этого можно эффективно использовать уже имеющуюся модель «мешка слов» (bag of words) и посчитанные веса TF-IDF всех термов сайта. Существует несколько различных техник.
Для начала введем обозначения:
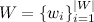 — cловарь всех различных слов;
— cловарь всех различных слов;
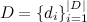 — корпус текстов (контент веб-страниц);
— корпус текстов (контент веб-страниц);
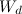 — множество слов в документе.
— множество слов в документе.
Для сравнения двух документов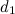 и
и 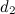 сначала нужно построить объединённый вектор слов
сначала нужно построить объединённый вектор слов 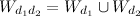 из слов, которые встречаются в обоих документах:
из слов, которые встречаются в обоих документах:
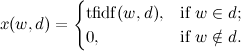
Сходство текстов рассчитывается как скалярное произведение с нормализацией:
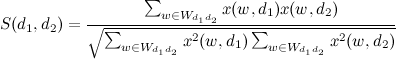
Если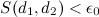 (порог сходства), то страницы считаются двойниками.
(порог сходства), то страницы считаются двойниками.
Другой подход не учитывает веса TF-IDF, а строит сходство по бинарным данным (есть слово в документе или нет). Для оценки различия страниц используется коэффициент Жаккара:
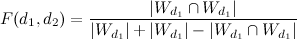 ,
,
где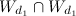 — множество общих слов в документах.
— множество общих слов в документах.
В результате применения этих методов выявлено несколько тысяч двойников. Для формальной оценки качества необходимо экспертным образом разметить двойников на обучающей выборке.
На этом пока всё, надеюсь, статья окажется вам полезной. А мы будем рады новым идеям о том, как применить text mining для улучшения рекомендаций!
Автоматическое определение категорий для веб-страниц из RSS-лент
Обычная схема добавления веб-страниц (вернее, ссылок на них) в Surfingbird такова: при добавлении новой ссылки пользователь должен указать до трёх категорий, к которым принадлежит эта ссылка. Понятно, что в такой ситуации задача автоматического определения категорий не стоит. Однако, кроме ручного добавления, ссылки попадают в базу и из RSS-потоков, которые предоставляют многие популярные сайты. Поскольку ссылок, поступающих через RSS-потоки, очень много, зачастую модераторы (а в этом случае именно они вынуждены проставлять категории) просто не справляются с таким объёмом. Возникает задача создания интеллектуальной системы автоматической классификации по категориям. Для ряда сайтов (например, lenta.ru или sueta.ru) категории можно вытащить непосредственно из rss-xml и вручную привязать к нашим внутренним категориям:
Дела обстоят хуже для RSS-потоков, в которых отсутствуют фиксированные категории, а вместо этого указаны пользовательские теги. Введенные произвольным образом теги (типичный пример — теги в постах ЖЖ) невозможно вручную связать с нашими категориями. И здесь уже включается более тонкая математика. Из страницы извлекается текстовый контент (тайтл, теги, полезный текст) и применяется LDA-модель, краткое описание которой можно найти в моей предыдущей статье. В результате вычисляется вектор вероятностей принадлежности веб-страницы к тематическим LDA-топикам. Полученный вектор LDA-топиков сайта используется как вектор признаков для решения задачи классификации по категориям. При этом объектами классификации являются сайты, классами являются категории. В качестве метода классификации использовалась логистическая регрессия, хотя можно применить любой другой метод, например наивный байесовский классификатор.
Для тестирования метода обучение моделей происходило на 5 тысячах классифицированных модератором сайтах из RSS-рассылок, для которых также было известно распределение по LDA-топикам. Результаты обучения на тестовой выборке представлены в таблице:
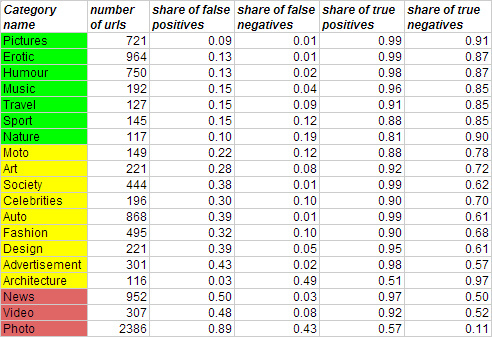
В результате приемлемое качество классификации (по доле ложных обнаружений и доле ложных пропусков) получилось только по следующим категориям: Pictures, Erotic, Humour, Music, Travel, Sport, Nature. По слишком общим категориям, например Photo, Video, News, ошибки большие.
В заключение можно сказать, что если в случае жёсткой привязки к внешним категориям классификация в принципе возможна в полностью автоматическом режиме, то классификацию по текстовому контенту неизбежно приходится вести в полуавтоматическом режиме, когда наиболее вероятные категории затем предлагаются модератору. Наша цель здесь – максимально упростить работу модератора.
Поиск дубликатов и плагиата среди веб-страниц
Еще одна задача, которую позволяет решить текстмайнинг, — это поиск и фильтрация ссылок с повторяющимся контентом. Повтор контента возможен по одной из следующих причин:
- по нескольким разным ссылкам происходит редирект на одну и ту же конечную ссылку;
- контент полностью скопирован на различных веб-страницах;
- контент скопирован частично или слегка изменён.
Первый и второй пункты являются техническими и решаются получением конечных ссылок и буквальным сравнением полезного контента для всех страниц в базе. Однако даже при полном копипасте формальное сравнение полезного текста может не пройти по понятным причинам (например, попали случайные символы или слова из меню сайта), а текст может быть и слегка изменён. Этот третий вариант мы и рассмотрим более подробно. Типичный двойник может выглядеть так:
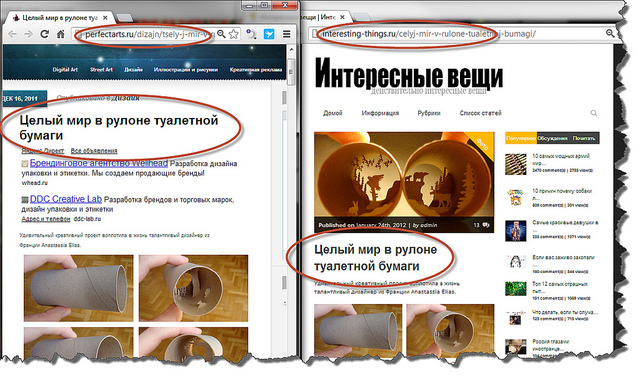
Задача определения заимствований в широком смысле слова довольно сложна. Нас же она интересует в более узкой постановке: нам не нужно искать плагиат в каждой фразе текста, а нужно просто сравнить документы по контенту целиком.
Для этого можно эффективно использовать уже имеющуюся модель «мешка слов» (bag of words) и посчитанные веса TF-IDF всех термов сайта. Существует несколько различных техник.
Для начала введем обозначения:
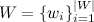 — cловарь всех различных слов;
— cловарь всех различных слов;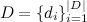 — корпус текстов (контент веб-страниц);
— корпус текстов (контент веб-страниц);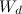 — множество слов в документе.
— множество слов в документе.Для сравнения двух документов
 и
и 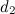 сначала нужно построить объединённый вектор слов
сначала нужно построить объединённый вектор слов 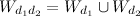 из слов, которые встречаются в обоих документах:
из слов, которые встречаются в обоих документах: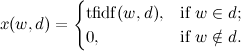
Сходство текстов рассчитывается как скалярное произведение с нормализацией:
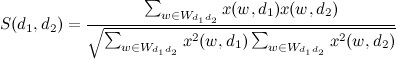
Если
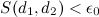 (порог сходства), то страницы считаются двойниками.
(порог сходства), то страницы считаются двойниками.Другой подход не учитывает веса TF-IDF, а строит сходство по бинарным данным (есть слово в документе или нет). Для оценки различия страниц используется коэффициент Жаккара:
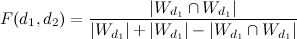 ,
,где
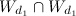 — множество общих слов в документах.
— множество общих слов в документах.В результате применения этих методов выявлено несколько тысяч двойников. Для формальной оценки качества необходимо экспертным образом разметить двойников на обучающей выборке.
На этом пока всё, надеюсь, статья окажется вам полезной. А мы будем рады новым идеям о том, как применить text mining для улучшения рекомендаций!
