 С завидной регулярностью на Хабре появляются статьи, рассказывающие о тех или иных методах распознавания лиц. Мы решили не просто поддержать эту замечательную тему, но выложить наш внутренний документ, который освещает пусть и не все, но многие подходы к распознаванию лиц, их сильные и слабые места. Он был составлен Андреем Гусаком, нашим инженером, для молодых сотрудников отдела машинного зрения, в образовательных, так сказать, целях. Сегодня предлагаем его все желающим. В конце статьи – впечатляющих размеров список литературы для самых любознательных.
С завидной регулярностью на Хабре появляются статьи, рассказывающие о тех или иных методах распознавания лиц. Мы решили не просто поддержать эту замечательную тему, но выложить наш внутренний документ, который освещает пусть и не все, но многие подходы к распознаванию лиц, их сильные и слабые места. Он был составлен Андреем Гусаком, нашим инженером, для молодых сотрудников отдела машинного зрения, в образовательных, так сказать, целях. Сегодня предлагаем его все желающим. В конце статьи – впечатляющих размеров список литературы для самых любознательных.Итак, начнем.
Несмотря на большое разнообразие представленных алгоритмов, можно выделить общую структуру процесса распознавания лиц:
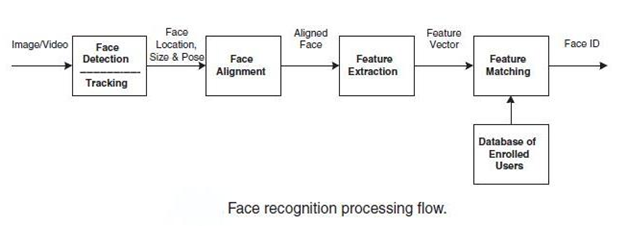
Общий процесс обработки изображения лица при распознавании
На первом этапе производится детектирование и локализация лица на изображении. На этапе распознавания производится выравнивание изображения лица (геометрическое и яркостное), вычисление признаков и непосредственно распознавание – сравнение вычисленных признаков с заложенными в базу данных эталонами. Основным отличием всех представленных алгоритмов будет вычисление признаков и сравнение их совокупностей между собой.
1. Метод гибкого сравнения на графах (Elastic graph matching) [13].
Суть метода сводится к эластичному сопоставлению графов, описывающих изображения лиц. Лица представлены в виде графов со взвешенными вершинами и ребрами. На этапе распознавания один из графов – эталонный – остается неизменным, в то время как другой деформируется с целью наилучшей подгонки к первому. В подобных системах распознавания графы могут представлять собой как прямоугольную решетку, так и структуру, образованную характерными (антропометрическими) точками лица.
а)

б)

Пример структуры графа для распознавания лиц: а) регулярная решетка б) граф на основе антропометрических точек лица.
В вершинах графа вычисляются значения признаков, чаще всего используют комплексные значения фильтров Габора или их упорядоченных наборов – Габоровских вейвлет (строи Габора), которые вычисляются в некоторой локальной области вершины графа локально путем свертки значений яркости пикселей с фильтрами Габора.

Набор (банк, jet) фильтров Габора

Пример свертки изображения лица с двумя фильтрами Габора
Ребра графа взвешиваются расстояниями между смежными вершинами. Различие (расстояние, дискриминационная характеристика) между двумя графами вычисляется при помощи некоторой ценовой функции деформации, учитывающей как различие между значениями признаков, вычисленными в вершинах, так и степень деформации ребер графа.
Деформация графа происходит путем смещения каждой из его вершин на некоторое расстояние в определённых направлениях относительно ее исходного местоположения и выбора такой ее позиции, при которой разница между значениями признаков (откликов фильтров Габора) в вершине деформируемого графа и соответствующей ей вершине эталонного графа будет минимальной. Данная операция выполняется поочередно для всех вершин графа до тех пор, пока не будет достигнуто наименьшее суммарное различие между признаками деформируемого и эталонного графов. Значение ценовой функции деформации при таком положении деформируемого графа и будет являться мерой различия между входным изображением лица и эталонным графом. Данная «релаксационная» процедура деформации должна выполняться для всех эталонных лиц, заложенных в базу данных системы. Результат распознавания системы – эталон с наилучшим значением ценовой функции деформации.

Пример деформации графа в виде регулярной решетки
В отдельных публикациях указывается 95-97%-ая эффективность распознавания даже при наличии различных эмоциональных выражениях и изменении ракурса лица до 15 градусов. Однако разработчики систем эластичного сравнения на графах ссылаются на высокую вычислительную стоимость данного подхода. Например, для сравнения входного изображения лица с 87 эталонными тратилось приблизительно 25 секунд при работе на параллельной ЭВМ с 23 транспьютерами [15] (Примечание: публикация датирована 1993 годом). В других публикациях по данной тематике время либо не указывается, либо говорится, что оно велико.
Недостатки: высокая вычислительная сложность процедуры распознавания. Низкая технологичность при запоминании новых эталонов. Линейная зависимость времени работы от размера базы данных лиц.
2. Нейронные сети
В настоящее время существует около десятка разновидности нейронных сетей (НС). Одним из самых широко используемых вариантов являться сеть, построенная на многослойном перцептроне, которая позволяет классифицировать поданное на вход изображение/сигнал в соответствии с предварительной настройкой/обучением сети.
Обучаются нейронные сети на наборе обучающих примеров. Суть обучения сводится к настройке весов межнейронных связей в процессе решения оптимизационной задачи методом градиентного спуска. В процессе обучения НС происходит автоматическое извлечение ключевых признаков, определение их важности и построение взаимосвязей между ними. Предполагается, что обученная НС сможет применить опыт, полученный в процессе обучения, на неизвестные образы за счет обобщающих способностей.
Наилучшие результаты в области распознавания лиц (по результатам анализа публикаций) показала Convolutional Neural Network или сверточная нейронная сеть (далее – СНС) [29-31], которая является логическим развитием идей таких архитектур НС как когнитрона и неокогнитрона. Успех обусловлен возможностью учета двумерной топологии изображения, в отличие от многослойного перцептрона.
Отличительными особенностями СНС являются локальные рецепторные поля (обеспечивают локальную двумерную связность нейронов), общие веса (обеспечивают детектирование некоторых черт в любом месте изображения) и иерархическая организация с пространственными сэмплингом (spatial subsampling). Благодаря этим нововведениям СНС обеспечивает частичную устойчивость к изменениям масштаба, смещениям, поворотам, смене ракурса и прочим искажениям.
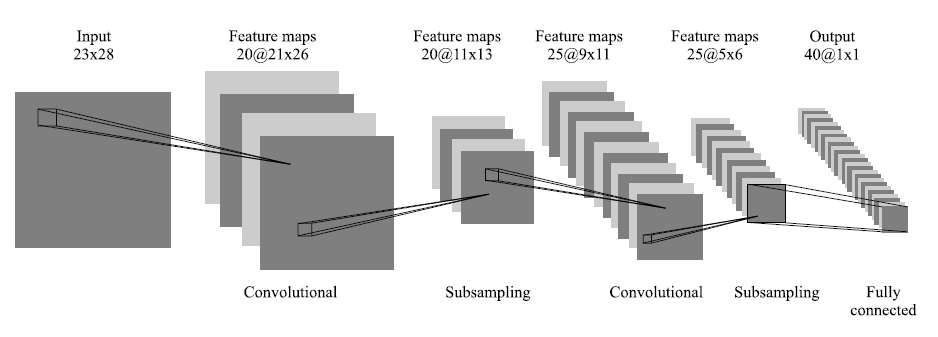
Схематичное изображение архитектуры сверточной нейронной сети
Тестирование СНС на базе данных ORL, содержащей изображения лиц с небольшими изменениями освещения, масштаба, пространственных поворотов, положения и различными эмоциями, показало 96% точность распознавания.
Свое развитие СНС получили в разработке DeepFace [47], которую приобрел
Facebook для распознавания лиц пользователей своей соцсети. Все особенности архитектуры носят закрытый характер.
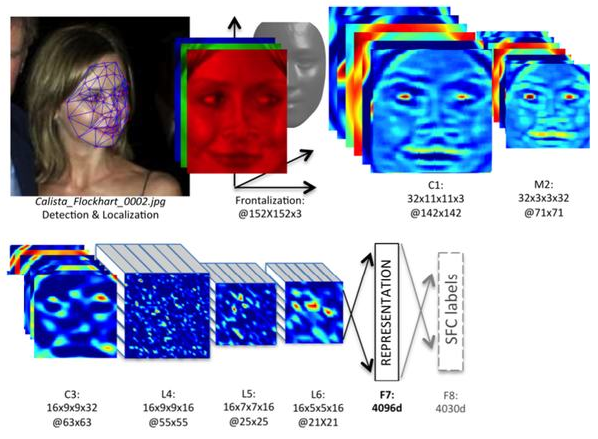
Принцип работы DeepFace
Недостатки нейронных сетей: добавление нового эталонного лица в базу данных требует полного переобучения сети на всем имеющемся наборе (достаточно длительная процедура, в зависимости от размера выборки от 1 часа до нескольких дней). Проблемы математического характера, связанные с обучением: попадание в локальный оптимум, выбор оптимального шага оптимизации, переобучение и т. д. Трудно формализуемый этап выбора архитектуры сети (количество нейронов, слоев, характер связей). Обобщая все вышесказанное, можно заключить, что НС – «черный ящик» с трудно интерпретируемыми результатами работы.
3. Скрытые Марковские модели (СММ, HMM)
Одним из статистических методов распознавания лиц являются скрытые Марковские модели (СММ) с дискретным временем [32-34]. СММ используют статистические свойства сигналов и учитывают непосредственно их пространственные характеристики. Элементами модели являются: множество скрытых состояний, множество наблюдаемых состояний, матрица переходных вероятностей, начальная вероятность состояний. Каждому соответствует своя Марковская модель. При распознавании объекта проверяются сгенерированные для заданной базы объектов Марковские модели и ищется максимальная из наблюдаемых вероятность того, что последовательность наблюдений для данного объекта сгенерирована соответствующей моделью.
На сегодняшний день не удалось найти примера коммерческого применения СММ для распознавания лиц.
Недостатки:
— необходимо подбирать параметры модели для каждой базы данных;
— СММ не обладает различающей способностью, то есть алгоритм обучения только максимизирует отклик каждого изображения на свою модель, но не минимизирует отклик на другие модели.
4. Метод главных компонент или principal component analysis (PCA) [11]
Одним из наиболее известных и проработанных является метод главных компонент (principal component analysis, PCA), основанный на преобразовании Карунена-Лоева.
Первоначально метод главных компонент начал применяться в статистике для снижения пространства признаков без существенной потери информации. В задаче распознавания лиц его применяют главным образом для представления изображения лица вектором малой размерности (главных компонент), который сравнивается затем с эталонными векторами, заложенными в базу данных.
Главной целью метода главных компонент является значительное уменьшение размерности пространства признаков таким образом, чтобы оно как можно лучше описывало «типичные» образы, принадлежащие множеству лиц. Используя этот метод можно выявить различные изменчивости в обучающей выборке изображений лиц и описать эту изменчивость в базисе нескольких ортогональных векторов, которые называются собственными (eigenface).
Полученный один раз на обучающей выборке изображений лиц набор собственных векторов используется для кодирования всех остальных изображений лиц, которые представляются взвешенной комбинацией этих собственных векторов. Используя ограниченное количество собственных векторов можно получить сжатую аппроксимацию входному изображению лица, которую затем можно хранить в базе данных в виде вектора коэффициентов, служащего одновременно ключом поиска в базе данных лиц.
Суть метода главных компонент сводится к следующему. Вначале весь обучающий набор лиц преобразуется в одну общую матрицу данных, где каждая строка представляет собой один экземпляр изображения лица, разложенного в строку. Все лица обучающего набора должны быть приведены к одному размеру и с нормированными гистограммами.
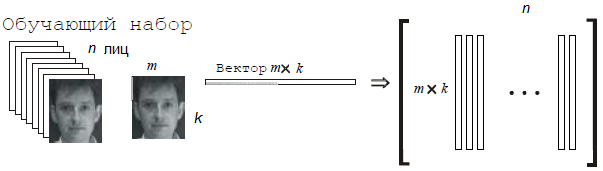
Преобразования обучающего набора лиц в одну общую матрицу X
Затем производится нормировка данных и приведение строк к 0-му среднему и 1-й дисперсии, вычисляется матрица ковариации. Для полученной матрицы ковариации решается задача определения собственных значений и соответствующих им собственных векторов (собственные лица). Далее производится сортировка собственных векторов в порядке убывания собственных значений и оставляют только первые k векторов по правилу:


Алгоритм РСА

Пример первых десяти собственных векторов (собственных лиц), полученных на обучаемом наборе лиц
 = 0.956*
= 0.956* -1.842*
-1.842* +0.046
+0.046  …
…Пример построения (синтеза) человеческого лица с помощью комбинации собственных лиц и главных компонент
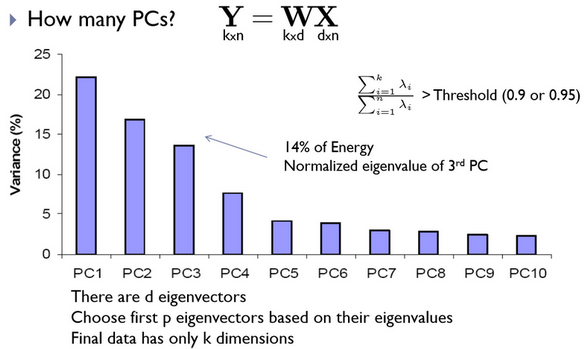
Принцип выбора базиса из первых лучших собственных векторов
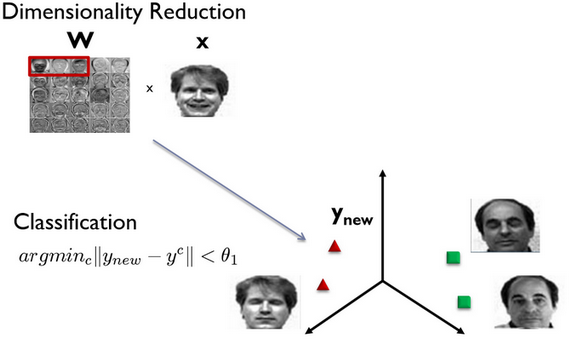
Пример отображения лица в трехмерное метрическое пространство, полученном по трем собственным лицам и дальнейшее распознавание

Метод главных компонент хорошо зарекомендовал себя в практических приложениях. Однако, в тех случаях, когда на изображении лица присутствуют значительные изменения в освещенности или выражении лица, эффективность метода значительно падает. Все дело в том, что PCA выбирает подпространство с такой целью, чтобы максимально аппроксимировать входной набор данных, а не выполнить дискриминацию между классами лиц.
В [22] было предложено решение этой проблемы с использование линейного дискриминанта Фишера (в литературе встречается название “Eigen-Fisher”, “Fisherface”, LDA). LDA выбирает линейное подпространство, которое максимизирует отношение:
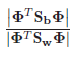
где
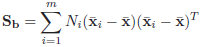
матрица межклассового разброса, и

Матрица внутриклассового разброса; m – число классов в базе данных.
LDA ищет проекцию данных, при которой классы являются максимально линейно сепарабельны (см. рисунок ниже). Для сравнения PCA ищет такую проекцию данных, при которой будет максимизирован разброс по всей базе данных лиц (без учета классов). По результатам экспериментов [22] в условиях сильного бакового и нижнего затенения изображений лиц Fisherface показал 95% эффективность по сравнению с 53% Eigenface.
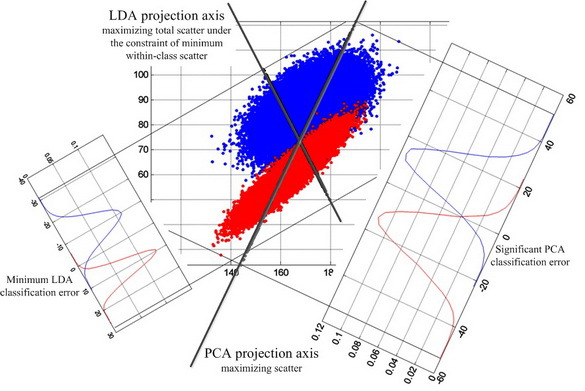
Принципиальное отличие формирования проекций PCA и LDA
Отличие PCA от LDA

5. Active Appearance Models (AAM) и Active Shape Models (ASM) (Хабраисточник)
Active Appearance Models (AAM)
Активные модели внешнего вида (Active Appearance Models, AAM) — это статистические модели изображений, которые путем разного рода деформаций могут быть подогнаны под реальное изображение. Данный тип моделей в двумерном варианте был предложен Тимом Кутсом и Крисом Тейлором в 1998 году [17,18]. Первоначально активные модели внешнего вида применялись для оценки параметров изображений лиц.
Активная модель внешнего вида содержит два типа параметров: параметры, связанные с формой (параметры формы), и параметры, связанные со статистической моделью пикселей изображения или текстурой (параметры внешнего вида). Перед использованием модель должна быть обучена на множестве заранее размеченных изображений. Разметка изображений производится вручную. Каждая метка имеет свой номер и определяет характерную точку, которую должна будет находить модель во время адаптации к новому изображению.

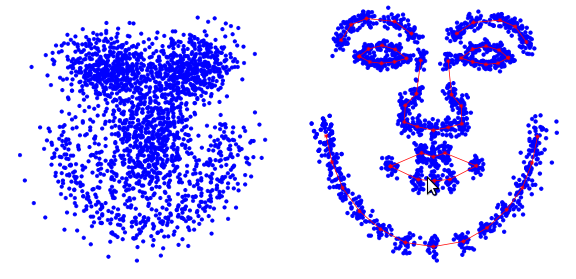
Пример разметки изображения лица из 68 точек, образующих форму AAM.
Процедура обучения AAM начинается с нормализации форм на размеченных изображениях с целью компенсации различий в масштабе, наклоне и смещении. Для этого используется так называемый обобщенный Прокрустов анализ.
Координаты точек формы лица до и после нормализации
Из всего множества нормированных точек затем выделяются главные компоненты с использованием метода PCA.
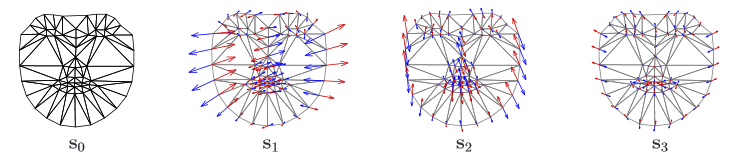
Модель формы AAM состоит из триангуляционной решетки s0 и линейной комбинации смещений si относительно s0
Далее из пикселей внутри треугольников, образуемых точками формы, формируется матрица, такая что, каждый ее столбец содержит значения пикселей соответствующей текстуры. Стоит отметить, что используемые для обучения текстуры могут быть как одноканальными (градации серого), так и многоканальными (например, пространство цветов RGB или другое). В случае многоканальных текстур векторы пикселов формируются отдельно по каждому из каналов, а потом выполняется их конкатенация. После нахождения главных компонент матрицы текстур модель AAM считается обученной.

Модель внешнего вида AAM состоит из базового вида A0, определенного пикселями внутри базовой решетки s0 и линейной комбинации смещений Ai относительно A0

Пример конкретизации AAM. Вектор параметров формы
p=(p_1,p_2,〖…,p〗_m )^T=(-54,10,-9.1,…)^T используется для синтеза модели формы s, а вектор параметров λ=(λ_1,λ_2,〖…,λ〗_m )^T=(3559,351,-256,…)^Tдля синтеза внешнего вида модели. Итоговая модель лица 〖M(W(x;p))〗^ получается как комбинация двух моделей – формы и внешнего вида.
Подгонка модели под конкретное изображение лица выполняется в процессе решения оптимизационной задачи, суть которой сводится к минимизации функционала
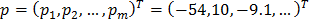
методом градиентного спуска. Найденные при этом параметры модели и будут отражать положение модели на конкретном изображении.


Пример подгонки модели на конкретное изображение за 20 итераций процедуры градиентного спуска.
С помощью AAM можно моделировать изображения объектов, подверженных как жесткой, так и нежесткой деформации. ААМ состоит из набора параметров, часть которых представляют форму лица, остальные задают его текстуру. Под деформации обычно понимают геометрическое преобразование в виде композиции переноса, поворота и масштабирования. При решении задачи локализации лица на изображении выполняется поиск параметров (расположение, форма, текстура) ААМ, которые представляют синтезируемое изображение, наиболее близкое к наблюдаемому. По степени близости AAM подгоняемому изображению принимается решение – есть лицо или нет.
Active Shape Models (ASM)
Суть метода ASM [16,19,20] заключается в учете статистических связей между расположением антропометрических точек. На имеющейся выборке изображений лиц, снятых в анфас. На изображении эксперт размечает расположение антропометрических точек. На каждом изображении точки пронумерованы в одинаковом порядке.
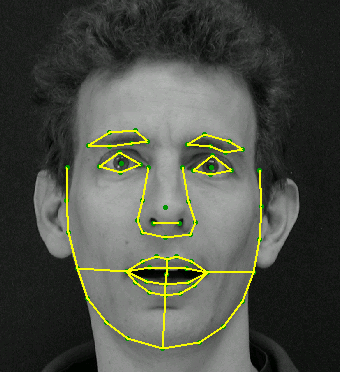

Пример представления формы лица с использованием 68 точек
Для того чтобы привести координаты на всех изображениях к единой системе обычно выполняется т.н. обобщенный прокрустов анализ, в результате которого все точки приводятся к одному масштабу и центрируются. Далее для всего набора образов вычисляется средняя форма и матрица ковариации. На основе матрицы ковариации вычисляются собственные вектора, которые затем сортируются в порядке убывания соответствующих им собственных значений. Модель ASM определяется матрицей Φ и вектором средней формы s ̅.
Тогда любая форма может быть описана с помощью модели и параметров:
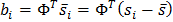
Локализации ASM модели на новом, не входящем в обучающую выборку изображении осуществляется в процессе решения оптимизационной задачи.

а) б) в) г)
Иллюстрация процесса локализации модели ASM на конкретном изображении: а) начальное положение б) после 5 итераций в) после 10 итераций г) модель сошлась
Однако все же главной целью AAM и ASM является не распознавание лиц, а точная локализация лица и антропометрических точек на изображении для дальнейшей обработки.
Практически во всех алгоритмах обязательным этапом, предваряющим классификацию, является выравнивание, под которым понимается выравнивание изображения лица во фронтальное положение относительно камеры или приведение совокупности лиц (например, в обучающей выборке для обучения классификатора) к единой системе координат. Для реализации этого этапа необходима локализация на изображении характерных для всех лиц антропометрических точек – чаще всего это центры зрачков или уголки глаз. Разные исследователи выделяют разные группы таких точек. В целях сокращения вычислительных затрат для систем реального времени разработчики выделяют не более 10 таких точек [1].
Модели AAM и ASM как раз и предназначены для того чтобы точно локализовать эти антропометрические точки на изображении лица.
6. Основные проблемы, связанные с разработкой систем распознавания лиц
Проблема освещенности

Проблема положения головы (лицо – это, все же, 3D объект).

С целью оценки эффективности предложенных алгоритмов распознавания лиц агентство DARPA и исследовательская лаборатория армии США разработали программу FERET (face recognition technology).
В масштабных тестах программы FERET принимали участие алгоритмы, основанные на гибком сравнении на графах и всевозможные модификации метода главных компонент (PCA). Эффективность всех алгоритмов была примерно одинаковой. В этой связи трудно или даже невозможно провести четкие различия между ними (особенно если согласовать даты тестирования). Для фронтальных изображений, сделанных в один и тот же день, приемлемая точность распознавания, как правило, составляет 95%. Для изображений, сделанных разными аппаратами и при разном освещении, точность, как правило, падает до 80%. Для изображений, сделанных с разницей в год, точность распознавания составило примерно 50%. При этом стоит заметить, что даже 50 процентов — это более чем приемлемая точность работы системы подобного рода.
Ежегодно FERET публикует отчет о сравнительном испытании современных систем распознавания лиц [55] на базе лиц более одного миллиона. К большому сожалению в последних отчетах не раскрываются принципы построения систем распознавания, а публикуются только результаты работы коммерческих систем. На сегодняшний день лидирующей является система NeoFace разработанная компанией NEC.
Список литературы (гуглится по первой ссылке)
1. Image-based Face Recognition — Issues and Methods
2. Face Detection A Survey.pdf
3. Face Recognition A Literature Survey
4. A survey of face recognition techniques
5. A survey of face detection, extraction and recognition
6. Обзор методов идентификации людей на основе изображений лиц
7. Методы распознавания человека по изображению лица
8. Сравнительный анализ алгоритмов распознавания лиц
9. Face Recognition Techniques
10. Об одном подходе к локализации антропометрических точек.
11. Распознавание лиц на групповых фотографиях с использованием алгоритмов сегментации
12. Отчет о НИР 2-й этап по распознаванию лиц
13. Face Recognition by Elastic Bunch Graph Matching
14. Алгоритмы идентификации человека по фотопортрету на основе геометриче-ских преобразований. Диссертация.
15. Distortion Invariant Object Recognition in the Dynamic Link Architecture
16. Facial Recognition Using Active Shape Models, Local Patches and Support Vector Machines
17. Face Recognition Using Active Appearance Models
18. Active Appearance Models for Face Recognition
19. Face Alignment Using Active Shape Model And Support Vector Machine
20. Active Shape Models — Their Training and Application
21. Fisher Vector Faces in the Wild
22. Eigenfaces vs. Fisherfaces Recognition Using Class Specific Linear Projection
23. Eigenfaces and fisherfaces
24. Dimensionality Reduction
25. ICCV 2011 Tutorial on Parts Based Deformable Registration
26. Constrained Local Model for Face Alignment, a Tutorial
27. Who are you – Learning person specific classifiers from video
28. Распознавание человека по изображению лица нейросетевыми методами
29. Face Recognition A Convolutional Neural Network Approach
30. Face Recognition using Convolutional Neural Network and Simple Logistic Classifier
31. Face Image Analysis With Convolutional Neural Networks
32. Методы распознавания лиц на основе скрытых марковских процессов. Авторе-ферат
33. Применение скрытых марковских моделей для распознавания лиц
34. Face Detection and Recognition Using Hidden Markovs Models
35. Face Recognition with GNU Octave-MATLAB
36. Face Recognition with Python
37. Anthropometric 3D Face Recognition
38. 3D Face Recognition
39. Face Recognition Based on Fitting a 3D Morphable Model
40. Face Recognition
41. Robust Face Recognition via Sparse Representation
42. The FERET Evaluation Methodology For Face-Recognition Algorithms
43. Поиск лиц в электронных коллекциях исторических фотографий
44. Design, Implementation and Evaluation of Hardware Vision Systems dedicated to Real-Time Face Recognition
45. An Introduction to the Good, the Bad, & the Ugly Face Recognition Challenge Prob-lem
46. Исследование и разработка методов обнаружения человеческого лица на циф-ровых изображениях. Диплом
47. DeepFace Closing the Gap to Human-Level Performance in Face Verification
48. Taking the bite out of automated naming of characters in TV video
49. Towards a Practical Face Recognition System Robust Alignment and Illumination by Sparse Representation
50. Алгоритмы обнаружения лица человека для решения прикладных задач анализа и обработки изображений
51. Обнаружение и локализация лица на изображении
52. Модифицированный мотод Виолы-Джонса
53. Разработка и анализ алгоритмов детектирования и классификации объектов на основе методов машинного обучения
54. Overview of the Face Recognition Grand Challenge
55. Face Recognition Vendor Test (FRVT)
56. Об эффективности применения алгоритма SURF в задаче идентификации лиц
