
Разверните в продакшене вашу первую ML-модель. Для этого вам понадобится очень простой технологический стек

Фото Рэнди Фэза с Unsplash
В отрасли машинного обучения сегодня считается, что специалист по изучению данных (Data Scientist) решает одну или обе следующие широко известные задачи:
- Получив методами data science некоторый дамп данных, применяет к этим данным некоторый алгоритм машинного обучения и сообщает полученные данные в виде презентации или отчета.
- При помощи data science создает некоторый функциональный софт для заказчика, и этот софт позволяет принимать и обрабатывать модели машинного обучения.
В этой статье я постараюсь на примере разобрать второй из вышеприведенных аспектов работы – то есть, опишу, как создать программу для работы с ML-моделями, которая может отвечать потребностям заказчика. Конкретно, мы с вами напишем веб-сервис, который можно будет запрашивать и получать в ответ прогнозы, сделанные моделью машинного обучения. Пост ориентирован в основном на практикующих специалистов по машинному обучению, которым интересно заняться чем-нибудь кроме разработки моделей.
Технический стек: Python, Flask, Docker, AWS ec2
Весь рабочий процесс можно разделить на следующие основные этапы:
- Обучение модели на локальной системе.
- Обертывание логики вывода закономерностей в приложение Flask.
- Укладка приложения Flask в контейнер Docker.
- Вынос контейнера Docker на инстанс AWS ec2 и потребление веб-сервиса.
ДИСКЛЕЙМЕР: от представленной здесь системы плыть и плыть до полноценного решения, которое сегодня можно было бы применять в продакшене. Этот пост призван продемонстрировать, как строится поток задач при разработке, познакомить вас с технологическим стеком и помочь составить первое впечатление о том, как строится ML-система для использования в продакшене.
Теперь давайте все по порядку.
Обучение модели на локальной системе
Нам нужна некоторая модель машинного обучения, которую мы сможем обернуть в веб-сервис. Для демонстрационной цели я создал модель логистической регрессии, которая выполняет многоклассовую классификацию ирисов Фишера (Ага, проще простого! #Лень). Я обучал модель на локальной системе при помощи Python 3.6.
Воспользовавшись знакомой мне библиотекой scikit-learn, смог быстро обучить вышеупомянутую модель. Разработка модели описана в блокноте ‘Model_training.ipynb’ в репозитории к этой статье. В разработке этой модели есть всего 2 важных аспекта, которые я хотел бы акцентировать:
- Файл модели, сгенерированный после обучения, сохранен в формате pickle (это сериализованный формат для хранения объектов). В репозитории этот файл называется ‘iris_trained_model.pkl’.
- Для вызова (.predict()), обеспечивающего логический вывод требуется по 4 признака на каждый тестовый образец. Они представлены в виде массива numpy.
Обертываем логику вывода в веб-сервис flask
Итак, теперь у нас есть файл с обученной моделью, и мы готовы запросить у модели метку класса для тестового образца. Вывод в данном случае сводится к вызову функции predict() для обученной модели с тестовыми данными. Однако, мы хотели бы выстроить вывод в виде веб-сервиса. Для этого воспользуемся Flask.
Flask – это мощный фреймворк-микровебсервер на Python, позволяющий быстро писать веб-сервисы, которые работают по принципу REST API, тратя минимум усилий на конфигурацию. Давайте подробно рассмотрим код:
1. Сначала определим функцию, которая будет загружать файл с обученной моделью.
model = None
def load_model():
global model
# model variable refers to the global variable
with open('iris_trained_model.pkl', 'rb') as f:
model = pickle.load(f)Здесь мы определяем глобальную переменную под названием ‘model’ и заполняем ее функцией load_model(). Скоро станет понятнее, зачем здесь используется глобальная переменная.
2. Далее создаем экземпляр объекта Flask под названием ‘app’:
app = Flask(__name__)c. Теперь определим «домашнюю» конечную точку, в ответ на попадание в которую вернется сообщение ‘Hello World!’.
@app.route('/')
def home_endpoint():
return 'Hello World!'Обратите внимание: здесь используется декоратор для app.route.
d. Далее определяем ‘прогностическую’ конечную точку. Эта конечная точка принимает запрос ‘POST’ в момент, когда конечная точка получает тестовые данные, по которым мы хотим получить прогноз. Проще говоря, функция работает лишь в случае, когда нужно спрогнозировать всего один тестовый образец (и не сработает, если в рамках единственного вызова к конечной точке потребуется спрогнозировать множество образцов).
@app.route('/predict', methods=['POST'])
def get_prediction():
# Работает только для одного образца
if request.method == 'POST':
data = request.get_json() # Get data posted as a json
data = np.array(data)[np.newaxis, :] # преобразует фигуру из (4,) в (1, 4)
prediction = model.predict(data) # применяет с данными глобально загруженную модель
return str(prediction[0])
Notice the direct call to the predict function through the ‘model’ variable.e. Наконец, объявляем главную функцию:
if __name__ == '__main__':
load_model() # load model at the beginning once only
app.run(host='0.0.0.0', port=80)Здесь вызов функции load_model() гарантирует, что переменная ‘model’ будет заполнена атрибутами обученной модели (именно поэтому и нужна глобальная переменная). Итак, нет нужды повторять загрузку модели при каждом вызове прогнозирующей конечной точки. Поэтому веб-сервис получается быстрым. Ответ возвращается в виде строки, представляющей собой метку спрогнозированного класса.
Ниже приведен весь flask-специфичный код:
# Выдать модель как приложение для flask
import pickle
import numpy as np
from flask import Flask, request
model = None
app = Flask(__name__)
def load_model():
global model
# model относится к глобальной переменной
with open('iris_trained_model.pkl', 'rb') as f:
model = pickle.load(f)
@app.route('/')
def home_endpoint():
return 'Hello World!'
@app.route('/predict', methods=['POST'])
def get_prediction():
# Работает лишь в случае, если образец один
if request.method == 'POST':
data = request.get_json() # Получает отправляемые данные в формате json
data = np.array(data)[np.newaxis, :] # преобразует фигуру из (4,) в (1, 4)
prediction = model.predict(data) # применяет к данным глобально загруженную модель
return str(prediction[0])
if __name__ == '__main__':
load_model() # load model at the beginning once only
app.run(host='0.0.0.0', port=80)В данный момент веб-сервис уже готов для локального запуска. Давайте это проверим.
Выполним команду
python app.py в консоли. Перейдите в браузер, введите в нем url 0.0.0.0:80, чтобы отобразилось сообщение Hello World!. Это означает, что конечная точка ответила на сообщение.ПРИМЕЧАНИЕ: на данном этапе может быть получена ошибка о недостатке прав доступа. В таком случае измените в команде
app.run()в файле app.py номер порта на 5000. (Порт 80 – привилегированный, поэтому нужно заменить его на некоторый непривилегированный порт, например, на 5000).Далее давайте проверим, удастся ли нам получать прогнозы при помощи этого веб-сервиса. Для этого выполним в консоли при помощи curl следующий post-запрос:
curl -X POST \
0.0.0.0:80/predict \
-H 'Content-Type: application/json' \
-d '[5.9,3.0,5.1,1.8]'Этот запрос отправляет на наш веб-сервер следующий тестовый образец
[5.9,3.0,5.1,1.8]и возвращает единственную метку класса.Укладка сервиса Flask в контейнер Docker
Вплоть до данного момента у нас был веб-сервис, работающий локально. Наша конечная цель – добиться, чтобы разрабатываемый нами код работал на облачной виртуальной машине.
В мире разработки ПО есть знаменитое оправдание, приписываемое некому разработчику, чей код якобы сломал тестировщик: «Но у меня на машине это работало!» Проблема, выраженная в этом анекдоте, обычно связана с несогласованностью окружений для выполнения программы, так как от машины к машине такие окружения отличаются. В идеале наш код как таковой не должен зависеть от того аппаратного обеспечения/ОС, где он работает. Такую изоляцию удобно обеспечивать, заключая код в контейнеры.
Почему в данном случае это так важно?
Мы собираемся использовать наш вею-сервис на облачной виртуальной машине. Сама облачная виртуальная машина может быть оснащена любой ОС. Укладывая наш веб-сервис в контейнер, мы избавляемся от проблем, которые могли бы быть обусловлены тем или иным окружением. Если контейнеризованный код работает на нашей машине, то он определенно будет работать и на любой другой, независимо от ее характеристик. Docker – самая известная из существующих технологий контейнеризации, и здесь мы будем работать именно с Docker. Краткое руководство по Docker дается здесь.
Давайте подробно разберем файл Dockerfile, в котором содержится набор команд для демона docker. Выполняя эти команды, демон создает образ Docker.
FROM python:3.6-slim
COPY ./app.py /deploy/
COPY ./requirements.txt /deploy/
COPY ./iris_trained_model.pkl /deploy/
WORKDIR /deploy/
RUN pip install -r requirements.txt
EXPOSE 80
ENTRYPOINT ["python", "app.py"]Вытягиваем базовый образ Docker из репозитория dockerhub на Python. В этом образе выполняются конкретные сборочные инструкции. Команды COPY просто берут конкретные файлы из текущего каталога и копируют их в каталог ‘deploy’ внутри того образа Docker, который мы пытаемся собрать. Кроме app.py и файла модели нам также нужен файл с требованиями, в котором перечислены конкретные версии пакетов Python, при помощи которых мы выполняем наш код. Команда WORKDIR меняет рабочий каталог на ‘deploy/’ в рамках данного образа. Затем дается команда RUN для установки конкретных пакетов Python при помощи файла с требованиями. Команда EXPOSE открывает порт 80 для доступа из внешнего мира (наш сервис Flask работает на порту 80; таким образом, порт с таким номером, работающий внутри контейнера, должен быть доступен и извне контейнера).
Выдаем команду сборки, чтобы в итоге у нас получился образ Docker:
docker build -t app-iris .(Не забудьте поставить точку в конце этой команды).
При помощи команды ‘docker images’ увидим, что создан образ Docker с репозиторием Docker под названием ‘app-iris’ (здесь также будет виден другой репозиторий под названием python, поскольку это базовый образ, на основе которого мы выстраиваем наш специализированный образ image.)
Теперь образ собран и готов к запуску. Запустить его можно при помощи следующей команды:
docker run -p 80:80 app-iris .В вышеприведенной команде флаг -p используется для того, чтобы соотнести порт 80 локальной системы с портом 80 контейнера Docker. Это нужно для переадресации трафика с локального HTTP-порта 80 на порт 80 контейнера. (Если вы используете локальный порт 5000, а не 80, то в вышеприведенной команде измените часть, отвечающую за соотнесение портов, на 5000:80).
Давайте проверим, как это работает. Введем в браузере URL http://0.0.0.0:80 – и мы должны увидеть сообщение ‘Hello World!’, которое будет выведено нашей домашней конечной точкой (в случае, если используется порт 5000, то в url изменим http-порт на 5000). Также воспользуемся вышеупомянутым запросом curl, чтобы проверить, возвращается ли спрогнозированная метка класса.
Размещаем контейнер Docker на инстансе AWS EC2
Итак, у нас есть контейнеризованное приложение, работающее на нашей локальной системе. Что, если использовать этот сервис захочет кто-нибудь еще? Что делать, если мы захотим выстроить вокруг этого сервиса архитектурную экосистему, для которой потребуется обеспечить доступность, масштабируемость, а также автоматизировать ее? Уже понятно, что идея обустроить веб-сервис для работы на локальной машине была очень плоха. Итак, мы хотим разместить веб-сервис где-нибудь в Интернете, чтобы он соответствовал вышеперечисленным требованиям. В этой статье расскажем, как разместить сервис на инстансе AWS EC2.
Чтобы пользоваться инстансом EC2, предварительно нужно завести аккаунт на AWS. Для новых пользователей существует несколько AWS-ресурсов, предоставляемых бесплатно на период до 1 года (обычно они лимитированы). В этой статье мы будем рассматривать инстанс EC2 типа ‘t2.micro’, рассчитанный на временное бесплатное использование (пометка «free tier eligible»). Для пользователей AWS, исчерпавших такой временный бесплатный период, такой инстанс обходится примерно в 1 цент в час – просто ничтожная сумма.
Приступим.
Залогинимся в консоль управления AWS и найдем через поисковую строку EC2, чтобы перейти в панель управления EC2.

Поиск ec2 в управляющей консоли AWS
Поищите в нижней секции окна вариант ‘Key Pairs’, выберите его и создайте пару ключей.
Вариант Key Pairs для просмотра имеющихся пар ключей и создания новых
В результате скачается файл ‘.pem’, это и есть ключ. Сохраните его где-нибудь в надежном месте. Далее перейдите к расположению этого файла в вашей системе и выполните следующую команду, заменив приведенное здесь имя ключа на ваше:
chmod 400 key-file-name.pemЭта команда меняет права доступа к вашему файлу с парой ключей на private. О том, как пользоваться парами ключей, рассказано ниже.
Далее щелкните ‘Launch Instance’ («Запустить инстанс») на панели инструментов EC2:

Запуск инстанса EC2
Выберите из списка вариантов «Amazon Machine Instance (AMI)». AMI задает, на какой ОС будет работать данная виртуальная машина (а также еще некоторые аспекты, которые нас в данный момент не волнуют). В данной статье я выберу вариант ‘Amazon Linux 2 AMI’, который задан в системе по умолчанию.
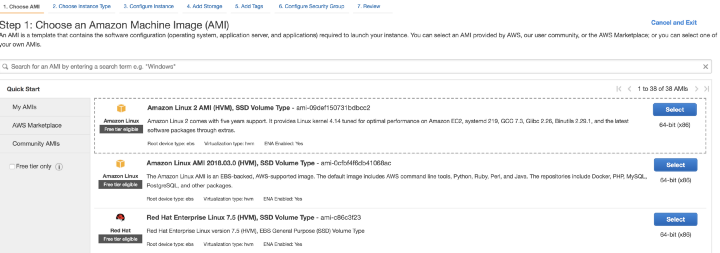
Выбор AMI
На следующем экране выбирается тип инстанса. Именно здесь можно выбрать аппаратную часть виртуальной машины. Как упоминалось выше, мы будем работать с инстансом ‘t2.micro’.
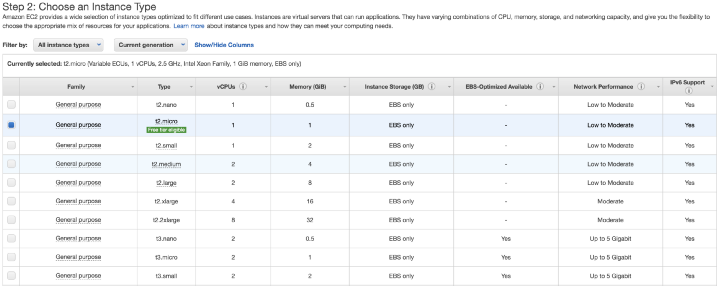
Выбор типа инстанса
Можно выбрать вариант ‘Review and Launch’ («Проверить и запустить»), который выедет вас к экрану ‘Step 7: Review Instance Launch’ («Шаг 7: Проверка запуска инстанса»). Здесь нужно нажать на ссылку ‘Edit Security Groups’ («Отредактировать группы безопасности»):
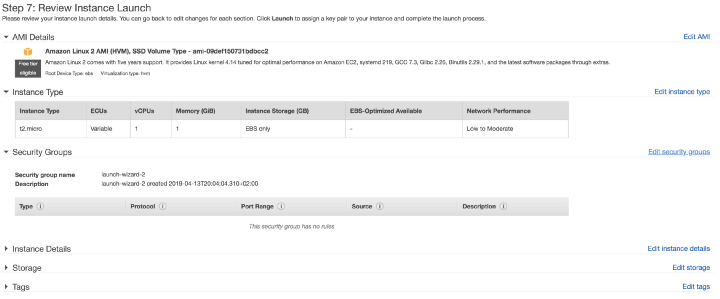
Группы безопасности
Теперь нужно изменить группу безопасности так, чтобы разрешить доступ извне системы к HTTP-трафику, поступающему на порт 80 вашего инстанса. Это можно сделать, создав специальное правило. В конце концов, вы должны увидеть такой экран:

Добавление HTTP-правила к группе безопасности
Если это правило не прописать, то ваш сервис так и останется недоступен. Подробнее о группах безопасности и о конфигурации почитайте в документации по AWS. Если щелкнуть по ярлыку «Launch» («Пуск»), то откроется всплывающее окно, в котором требуется подтвердить, что у вас есть пара ключей. Воспользуйтесь сгенерированной ранее парой ключей и запустите виртуальную машину.
Вы будете перенаправлены на экран запуска (Launch):

Статус запуска для инстанса EC2
Нажав на кнопку ‘View Instance’ («Просмотреть инстанс») перейдите на экран, где отобразится запускаемый инстанс EC2. Когда состояние инстанса изменится на ‘running’, это значит, что он готов к использованию.
Теперь подключимся по протоколу SSH к машине EC2 через терминал нашей локальной системы. Для этого в поле ssh public-dns-name запишем имя нашего инстанса EC2 (в виде: ec2–x–x–x–x.compute-1.amazonaws.com) и путь к pem-файлу с парой ключей, который мы сохранили ранее.
ssh -i /path/my-key-pair.pem ec2-user@public-dns-nameДалее перед нами откроется приглашение от того инстанса, на котором мы в самом начале работы установили Docker. В рамках нашего рабочего процесса это необходимо, так как мы собрали образ Docker на инстансе EC2 (здесь есть и более оптимальные варианты, но они несколько сложнее). С выбранным нами AMI можно использовать следующий набор команд:
sudo amazon-linux-extras install docker
sudo yum install docker
sudo service docker start
sudo usermod -a -G docker ec2-userВсе эти команды подробнее объяснены в документации.
Выйдите из инстанса EC2 командой ‘exit’ и вновь залогиньтесь при помощи команды ssh. Проверьте, работает ли Docker, выдав команду ‘docker info’. Вновь выйдите из системы и откройте еще одно окно терминала.
Теперь давайте скопируем на инстанс EC2 те файлы, которые понадобятся нам для сборки образа docker. Выполните следующую команду с вашего локального терминала (а не с EC2):
scp -i /path/my-key-pair.pem file-to-copy ec2-user@public-dns-name:/home/ec2-userНам потребуется скопировать файлы requirements.txt, app.py, файл с обученной моделью и Dockerfile. Этого достаточно, чтобы собрать образ Docker так, как мы это делали ранее. Вновь залогиньтесь на инстансе EC2 и при помощи команды ‘ls’ проверьте, существуют ли на нем скопированные файлы. Далее соберите и запустите образ Docker при помощи все тех же команд, которые мы использовали на локальной системе (на сей раз используйте порт 80 везде, где требуется его указать в коде и командах).
Выйдите через браузер на вашу домашнюю конечную точку, воспользовавшись публичным dns-именем – и увидите знакомое сообщение ‘Hello World!’:

Домашняя конечная точка работает прямо из браузера (я воспользовался именем public-dns-name с EC2, указав его в адресной строке)
Теперь отправим к нашему веб-сервису curl-запрос. Сделаем это с локального терминала, воспользовавшись данными с тестового образца. Перед этим замените public-dns-name на имя, актуальное в вашем случае:
curl -X POST \
public-dns-name:80/predict \
-H 'Content-Type: application/json' \
-d '[5.9,3.0,5.1,1.8]'В результате вы должны получить ту же спрогнозированную метку класса, которую получили локально.
И на этом все! Теперь можете поделиться этим curl-запросом с кем угодно, что хотел бы потреблять ваш веб-сервис при работе со своими тестовыми образцами.
Когда этот веб-сервис больше не будет вам нужен, не забудьте остановить или завершить ваш инстанс ec2:
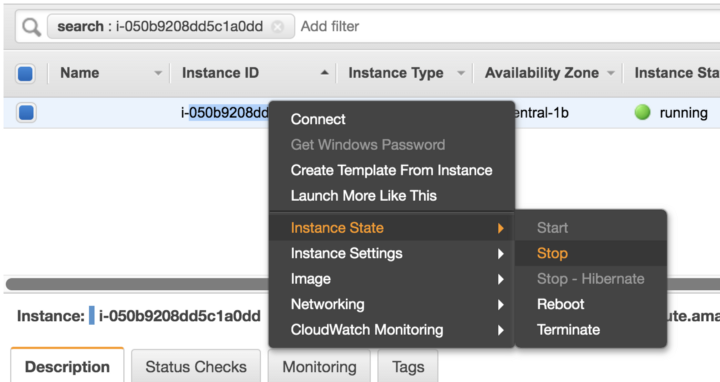
Остановите или завершите работу инстанса EC2, чтобы не переплачивать впустую
Еще некоторые мысли
Это предельно упрощенный поток задач, который нужно освоить ML-практикам, которым не терпится заняться чем-то более серьезным, чем просто разработка моделей. В этой системе требуется изменить еще массу всего, чтобы она в большей степени отвечала требованиям продакшена. Вот некоторые пожелания по улучшению (список далеко не полон):
- Используйте шлюзовой интерфейс веб-сервера (WSGI), например, gunicorn, для взаимодействия с приложением Flask. Отдельной похвалы заслуживает работа с обратными прокси nginx и асинхронными рабочими потоками.
- Укрепляйте безопасность инстанса EC2. В настоящее время сервис открыт всему миру. Рекомендую ограничить доступ к набору IP.
- Пишите для приложения тестовые кейсы. Создавать софт, пренебрегая тестами – все равно, что стрелять себе в ногу, а затем бросаться в клетку с голодными львами и дожидаться, пока тебя там не побьют камнями. (Мораль: не выводите софт в продакшен, предварительно как следует его не протестировав).
Этот список можно было бы еще продолжать и продолжать, но, пожалуй, это уже тема для другого поста.
Весь код выложен в репозитории на Github: github.com/tanujjain/deploy-ml-model

