
Троллинг с помощью математики — вот о чем я собираюсь поговорить. Это не какие-то модные хакерские штучки, скорее это художественное самовыражение, забавная разумная технология для того, чтобы люди посчитали тебя придурком. Сейчас я проверю, готов ли мой доклад для отображения на экране. Вроде всё идёт нормально, так что я могу представиться.

Меня зовут Фрэнк Ту, пишется frank^2 и @franksquared в «Твиттере», потому что в Twitter тоже есть какой-то спамер по имени «frank 2». Я пытался применить к ним социальную инженерию, чтобы они удалили его учётную запись, потому что технически это спам и я имею право избавиться от него как от своего клона. Но видимо, если вы поступаете с ними честно, они не отвечают вам взаимностью, потому что не смотря на мою просьбу удалить спамерский аккаунт, они ничего с ним не сделали, так что я послал этот долбанный Twitter куда подальше.
Многие люди узнают меня по моей кепке. Я работаю в региональных группах DefCon DС949 и DC310. Я также работаю c Rapid7, но не могу рассказать здесь об этом без нецензурных выражений, а мой руководитель не хочет, чтобы я ругался. Итак, я приготовил это выступление для DefCon и собираюсь уложиться в 15 минут, хотя это довольно сложная тема. По существу это стандартная презентация, которая посвящена реверс-инжинирингу и связанным с ним смешным вещам.
При обсуждении этой темы в «Твиттере» образовалось два лагеря. Один парень высказался так: «я не имею понятия, о чем говорит этот долбанный frank^2, но это потрясающе»! Второй парень из Reddit увидел мои слайды и расстроился из-за ссылок на не относящиеся к теме вещи, разозлился, что такая серьёзная тема не была полностью освещена, поэтому пожелал, чтобы в моей презентации было «больше содержания и меньше фигни».

Поэтому я хочу сосредоточиться на этой цитате. Ничего личного, чувак из Reddit, — я говорю это не только на случай, если он присутствует в этом зале, но и потому, что это была справедливая критика. Потому что разговор, не содержащий достаточно полезного контента – это пустая болтовня.
Тема моего разговора представляет для хакеров стандартную рутину, но мне кажется, что на самом деле докладчики обычно не стараются представить свою информацию в занимательной форме, даже когда это возможно, предпочитая сухие, выхолощенные выводы. «Вот IP, вот ESP, вот как вы можете выполнить эксплойт, вот мой «нулевой день», теперь хлопайте!» — и все хлопают в ладоши.
Спасибо за аплодисменты, я ценю это! Мне кажется, что в моём материале есть много интересных моментов, поэтому он заслуживает быть изложенным в несколько развлекательной манере, что я и постараюсь проделать.
Вы увидите исключительно поверхностное отношение к компьютерной науке и совершенно детский юмор, так что я надеюсь, вы оцените то, что я собираюсь здесь показать. Мне очень жаль, если вы пришли сюда в поисках серьёзного разговора.
На слайде вы видите научный анализ моего прошлого доклада, сравнивающий долю строго научного подхода и долю «лекарства», обеспечивающего компьютерную безопасность.

Вы видите, что «лекарства» намного больше, но можете не волноваться, сейчас доля науки несколько увеличилась.

Итак, некоторое время назад мой друг Мерлин, сидящий здесь в первых рядах, написал удивительный бот на основе скрипта IRC Python, занимающий всего одну строку.
Это действительно потрясающее упражнение для обучения функциональному программированию, с которым очень весело возиться. Вы можете просто добавлять одну функцию за другой и получать комбинации всяких разных функций, и всё это рисуется на экране в виде радужной волны, в общем, это одна из самых глупых вещей, которую можно сделать.

Я подумал, что если применить этот принцип к двоичным файлам? Не знаю, откуда мне пришла в голову эта идея, но получилось офигенно! Тем не менее, я хочу разъяснить некоторые основные понятия.
Вполне возможно, что ваш учитель математики представил эти функции намного сложнее, чем они есть на самом деле.
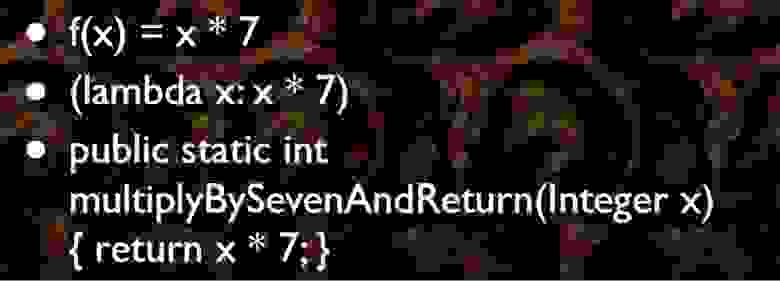
Итак, формула f(x) очень проста по своему смыслу, она работает как обычные функции. У вас есть X, у вас есть входные данные, и затем вы получаете X 7 раз, и это равно вашему значению. В Python вы можете сделать функцию (lambda x: x * 7). Если вы захотите работать с Java – извиняюсь, я надеюсь, вы никогда не захотите этого делать – то можете проделать что-то вроде:
Знаете, математические функции могут быть даже намного сложнее, но это всё, что мы должны о них знать на данный момент.
Если рассмотреть сборку кода, то можно заметить, что инструкции JMP и CALL не привязаны к конкретным значениям, они работают со смещением. Если использовать дебаггер, то видно, что JMP00401000 больше похож на инструкцию «перепрыгнуть на несколько байтов вперёд», чем на конкретное указание перепрыгнуть на 5 или 10 байтов. То же самое относится к функции CALL, за исключением того, что она пропихивает целую кучу вещей в ваш стек. Исключение составляет случай, когда вы «приклеивате» адрес к регистру, то есть обращаетесь к конкретному адресу. Здесь всё происходит совершенно иначе. После того, как вы цепляете адрес к регистру и делаете что-то вроде CALL EAX, функция обращается к конкретному значению в EAX. То же самое касается CALL [EAX] или JMP [EAX] — он просто разыменовывает EAX и переходит к этому адресу. При использовании дебаггера у вас может не быть возможности определить, к какому конкретному адресу обращается CALL. Это может стать проблемой, так что вы должны быть в курсе этого.
Давайте рассмотрим функцию «короткого прыжка» JMP SHORT. Это особая инструкция в архитектуре х86, позволяющая использовать смещение в 1 байт вместо смещения в 4 байта, что уменьшает используемое пространство памяти. Это будет иметь значение позже для всех манипуляций, которые будут происходить с индивидуальными инструкциями. Важно иметь в виду, что JMP SHORT имеет диапазон в 256 байт. Однако не существует такого понятия, как CALL SHORT.

Теперь рассмотрим колдовство компьютерной науки. В середине создания этих слайдов я понял, что фактически вы можете определить сборку как нулевое пространство, то есть технически между каждой инструкцией имеется нулевое пространство. Если вы посмотрите на индивидуальные инструкции, то увидите, что каждая выполняется по одной после другой инструкции. Технически это можно интерпретировать как безусловный прыжок к следующей инструкции. Это предоставляет нам пространство между каждой сборочной инструкцией, пока каждая инструкция соответственно связана с безусловным прыжком.
Если вы посмотрите на этот пример сборки, кстати, это очень простые вещи, которые я рекомендую декодировать с помощью ASCII, так вот, это просто набор обычных инструкций.
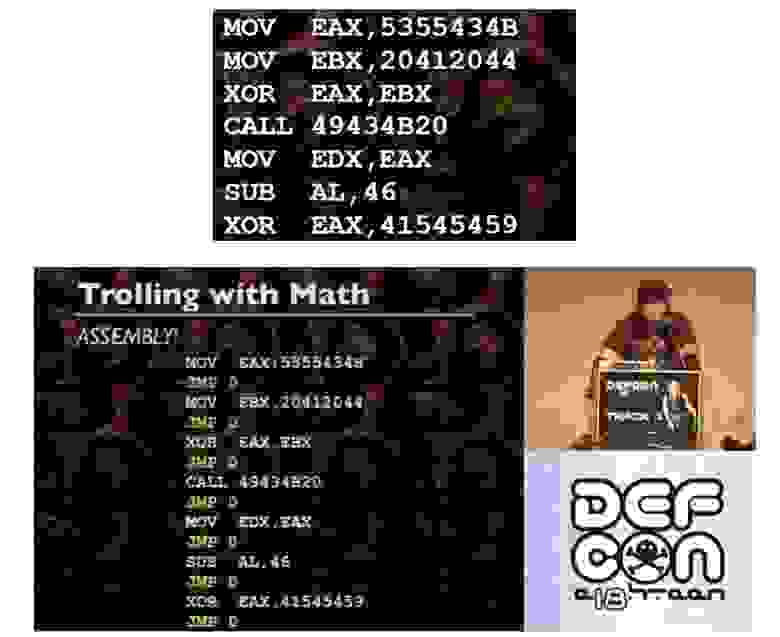
JMP 0, расположенные между каждой инструкцией, представляют собой безусловные прыжки, которые вы обычно не видите. Они следуют друг за другом после каждой инструкции. Поэтому можно разместить каждую отдельную сборочную инструкцию в произвольном месте памяти тогда и только тогда, когда каждая единичная инструкция сопровождается безусловным прыжком к следующей инструкции. Потому что если вы переносите сборку и вам нужно использовать тот же код, что и раньше, вы должны прикрепить безусловный прыжок к каждой инструкции.
Давайте посмотрим дальше. Одномерный массив технически может быть интерпретирован как двумерный массив, просто это потребует немного математики, ряды или что-то вроде них, не скажу точно, но это не слишком сложно. Это дает нам возможность интерпретировать расположение в памяти в виде решётки (x,y). В сочетании с интерпретацией пустого пространства между инструкциями как безусловных прыжков, которые могут быть связаны друг с другом, мы сможем буквально рисовать инструкции. Это потрясающе!
Для того, чтобы осуществить подобное на практике, нужно выполнить следующие шаги:
К сожалению, здесь возникает множество вопросов. Это как с гравитацией, которая работает только в теории, а на практике мы видим совершенно иное. Потому что в реальности x86 посылает к чёрту ваши JMP инструкции, CALL инструкции, искажает ваш самореференциальный код, самомодифицирующийся код, который использует итерацию.

Давайте начнём с JMP инструкций. Так как JMP инструкции имеют смещение, при размещении их в произвольном месте они больше не указывают туда, куда по-вашему, они должны указывать. SHORT JMP оказываются в аналогичном положении. Случайно размещённые вашей функцией (x,y), они не будут указывать на то, на что вы рассчитываете. Но в отличие от «длинных» JMP, «короткие» JMP легче пофиксить, особенно если вы имеете дело с одномерным массивом. SHORT JMP легко конвертировать в обычные JMP, но тогда вам придётся вычислять, каким стало новое смещение.
Работа с JMP на основе регистров – ещё та головная боль, и из-за того, что они требуют жёстких смещений и могут рассчитываться в процессе выполнения, не существует лёгкого способа узнать, куда они направляются. Чтобы автоматически определить каждый регистр, нужно использовать кучу знаний из теории компиляции. В процессе выполнения здесь могут быть указатели функций, указатели классов и тому подобное. Правда, если вы не хотите делать дополнительную работу ради того, чтобы проделать всё это, то можете её не делать. Функции f(x) работают в реальном коде не настолько элегантно, как на бумаге. Если вы хотите сделать это как следует, вам потребуется проделать кучу работы.
Для определения указателей классов и подобных вещей вам потребуется поколдовать с С и C++. Перед сохранением, во время деассемблирования, преобразуйте свои SHORT JMP в обычные JMP, потому что вам предстоит иметь дело смещением, это достаточно просто.
Пытаться вычислить фактические смещения – огромная головная боль. Все обнаруженные вами инструкции имеют смещения, которые будут перемещаться, при перемещении кода, и должны пересчитываться. Это означает, что вам необходимо следить за инструкциями и за тем, куда они перемещаются, как за целями. Мне трудно вам объяснить на слайдах, но пример, как это добиться, есть на компакт-диске с материалами этой конференции.
После того, как вы разместите все инструкции, замените старые смещения новыми смещениями. Если вы не повредили смещения, то всё получится. Теперь, когда вы подготовились, появляется реальная возможность воплощения идеи на высшем уровне. Для этого нужно:
Если вы всё правильно расставили по местам, то получаются странные вещи – всё перепутывается, инструкции прыгают в непонятные места памяти, и всё это выглядит просто феерично.

Имеет ли всё это какое-то практическое значение или это просто цирковое представление? Прикладное значение подобных преобразований заключается в следующем. Изоляция инструкций по сборке и несколько шагов для вычисления f(x) позволяет нам разместить эти сборочные инструкции в любом месте буфера без какого-либо взаимодействия с пользователем. Чтобы запутать пути выполнения кода, все, что вам нужно сделать, это математически написать функцию и указатели в каком-нибудь ассемблере, выбирая их случайным образом.
Это намного упрощает полиморфные методы кодирования. Вместо того, чтобы каждый раз писать код, который определённым способом манипулирует вашим кодом, вы можете написать ряд функций, которые случайно определят положение вашего кода, а затем выбрать эти функции как случайные и т. д.
Антиреверсирование не такая крутая и свежая штука, как техника антидебаггинга.
Антиверсирование заключается не в том, сколько удовольствия вы получите от того, что сделаете невозможным использования IDA и не в том, насколько затролите компьютер ревёрсера картинками Last Measure от GNAA, хотя это чертовски весело. Антиреверсирование – это значит просто быть мудаком, потому что если вы, как последний мудак, достанете ревёрсера, чувака, который ломает защиты разных систем, он просто разозлится, пошлёт к чертям эту вредоносную программу и уйдёт.
Между тем, вы сможете продать всех своих ботов русским деловым сетям, потому что своим ПО вы «опускаете» всех, кто занимается реверсивным инжинирингом. Все знают, как найти в Google техники для антидебаггинга, но они не найдут там решения проблем, возникающих от креативных вещей. Самые креативные антиревёрсеры заставят ревёрмеров обломать свои пальцы о клавиатуру и оставить в стенах дыры размером с кулак. Ревёрсеры будут кипеть от злости, они не поймут, какого черта ты сделал, потому что твой код все испортил.
Это своеобразная игра на нервах, психологическая штука, если вы творчески подойдёте к этому делу и создадите действительно потрясающий антиреверс, то сможете им гордиться. Но вы знаете, что на самом деле, просто пытаетесь отвадить их от вашего кода.
Итак, что я собираюсь делать? Я собираюсь взять функции запутывания и запутать их. Затем я собираюсь использовать вторую версию запутывания запутанных функций и снова применить запутывание. Итак, давайте вытянем код. Это образец математического троллинга, который я взял для примера.
Итак, я ввожу в открывшееся окно команду «запутать по формуле».
Далее вы видите сборочные инструкции, которые выполняют свою работу. Заметьте, что я использую здесь C++, хотя при малейшей возможности стараюсь избежать этого.
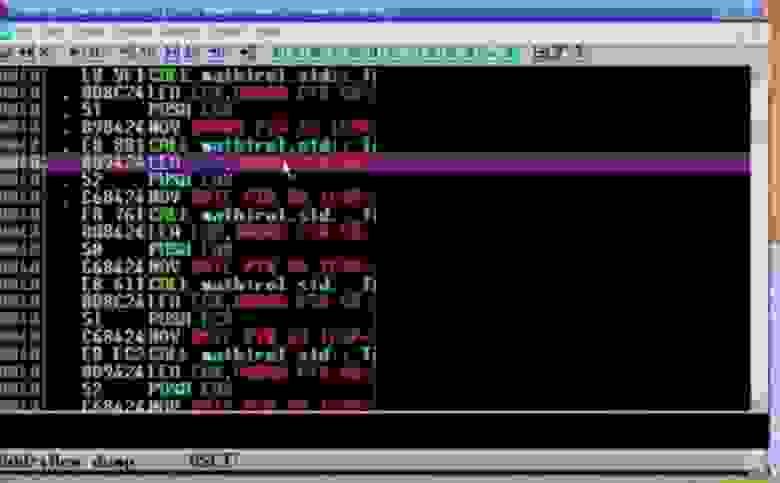
Вот здесь выделена активная функция CALL EAX, далее следует инструкция прыжка, которая будет применена, вы видите кучу всяких разных вещей в буфере, и всё это проделывается с каждой индивидуальной инструкцией.
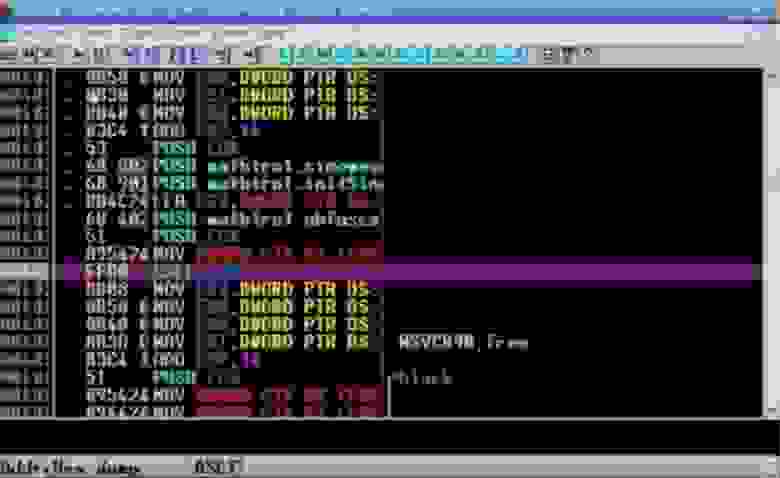
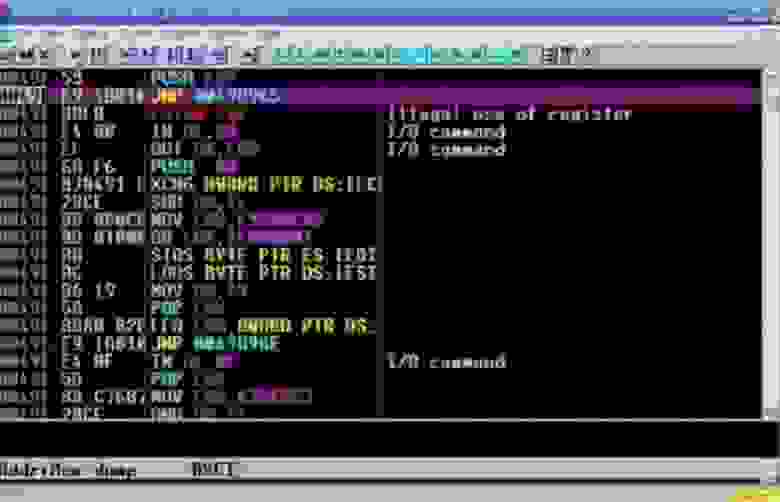
Сейчас я перемотаю программу до конца, и вы увидите результат. Итак, код всё ещё выглядит отлично, здесь собрана куча инструкций JMP, это выглядит запутанным, и в действительности оно запутано.
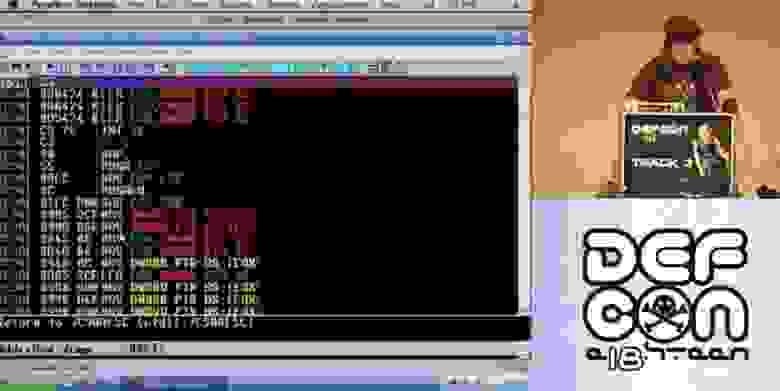
На следующем слайде показано графическое представление того, как выглядит стек.

Каждый раз, когда это происходит, я генерирую формулу случайной синусоидной волны, которая носит произвольную форму, вы видите тут кучу разных форм, и это круто. Я думаю, что код начинаете где-то вверху слева, но точно не помню. Вот так он всё закручивает, вы можете не только делать синусоиды, но и закручивать спирали.

Здесь работают всего две формулы, которые я включил в исходный код. На основе этого вы можете сделать множество креативных вещей, какие только захотите, по существу это просто DIFF от начального буфера к конечному буферу.
Проблема в том, что этот пример кода использует безусловные прыжки, что на самом деле плохо, потому что при этом код должен быть точно такой же, как раньше, то есть безусловные прыжки следуют только в одном направлении. Поэтому вам нужно пройти от точки входа до конца тем же путём, избавиться от инструкции прыжка и готово – вы получили свой код! Что же делать? Нужно превратить безусловные прыжки в условные. Условные прыжки совершаются по двум направлениям, это намного лучше, можно сказать, что это лучше на 50%.
Здесь у нас возникает интересная дилемма: если нам нужны условные прыжки, то нам ещё нужно использовать и безусловные прыжки…какого хрена? И что же нам делать? Нас спасут непрозрачные предикаты! Для тех, кто не знает, непрозрачный предикат – это по существу булево утверждение, которое всегда выполняется для определенной версии независимо ни от чего.
Итак, давайте рассмотрим расширение нулевого пространства, о котором я говорил ранее. Если у вас есть набор инструкций и они имеют безусловные прыжки переходы между каждой инструкцией, из этого следует, что серия сборочных инструкций, которые не имеют прямого влияния на нужные нам инструкции, может предшествовать или следовать одиночной инструкции.
Например, если вы написали очень специфичные инструкции, которые не изменяют основную сборку того, что вы пытаетесь запутать, то есть вы пытаетесь не связываться с регистрами до тех пор, пока поддерживаете состояние каждой инструкции по сборке. И это ещё более удивительно.
Вы можете рассмотреть каждую сборочную инструкцию, которую можно запутать, как преамбулу, данные сборки и постскриптум. Преамбула – это то, что предшествует сборочной инструкции, а постскриптум – то, что за ней следует. Преамбула обычно используется или может использоваться для двух вещей:
Но преамбула существенно ограничена, потому что вы не можете сделать слишком много.
Постскриптум более весёлая штука. Он может использоваться для:
Прямо сейчас я работаю над тем, чтобы осуществить возможность зашифровки и расшифровки каждой отдельной инструкции так, что при выполнении каждой инструкции она расшифровывает следующий раздел, следующий раздел, следующий и так далее. На следующем слайде показан пример этого.
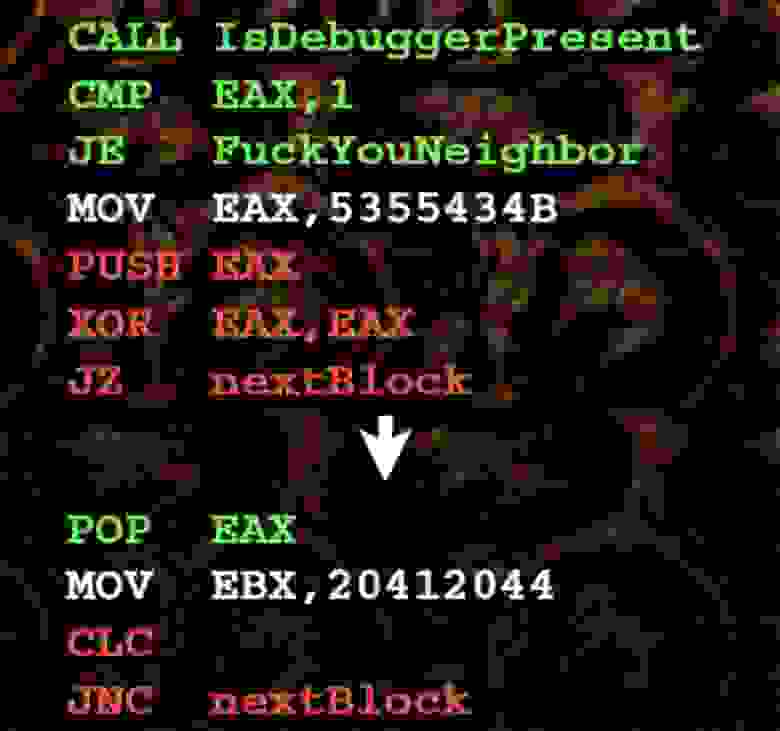
Зелёным цветом выделены строки преамбулы и вызов дебаггера. Всё, что делает этот вызов – это проверяет, имеется ли у нас отладчик, после чего осуществляется переход к произвольной секции кода.
Внизу у нас имеется очень простой непрозрачный предикат. Если вы поддерживаете значение EАX в постскриптуме к верхней инструкции, то следуете оператору XOR, так что ваше JZ думает: «хорошо, я, очевидно, могу пойти влево или вправо, я думаю, что лучше я пойду направо, потому что там 0». Затем выполняется POP EAX, ваше EAX возвращается назад, после чего обрабатывается следующая инструкция и так далее.
Это, очевидно, создаёт гораздо большие проблемы, чем наша базовая стратегия, такие, как остаточные эффекты и усложнение генерирования различных наборов инструкций. Поэтому будет очень сложно определить, как инструкция влияет на другую инструкцию. Можете кидать в меня тапками, потому что я ещё не закончил эту потрясающую программу, но за ходом разработки вы можете проследить в моём блоге.

Замечу, что наши формулы f(x) не обязательно должны вычисляется итеративно, например f (1), f(2),… f (n). Ничто не мешает вычислять их случайным образом. Если вы сообразительны, то сможете определить, сколько инструкций вам понадобится, а затем для каждой инструкции назначить, например, f (27), f(54), f (9), и это будет то место, где ваша инструкция разместиться случайным образом. Когда вы сделаете это, в зависимости от того, как именно написали свой код, то сможете заранее это прекратить, причём код будет по прежнему связывать ваши инструкции случайным образом.
Если ваш код генерируется на основе предсказуемой формулы, то из этого следует, что точка входа тоже предсказуема, так что вы можете взять на один уровень больше перед тем, как завершите получение кода, и существенно запутать точку входа в той или иной мере. Например, взять 300 сборочных инструкций, исходящих из одной точки входа.
Теперь поговорим о недостатках.

Этот метод требует тщательной компиляции кода, в основном с помощью GCC или не дай бог, с помощью C++. На самом деле C++ довольно крутой язык по нескольким причинам, но вы же знаете, что все компиляторы – отстой. Так что главное в этом деле – грамотная собственноручная компиляция, потому что если ваша попытка запутать собственную сборку вызовет одобрение банды, придумавшей червь Conficker, то вы облажались.
Вам потребуется большой объем памяти. Вспомните картинку с синусоидами. Красный цвет – это код, а синее пространство – память, необходимая для его работы, и её должно быть достаточно, чтобы всё работало как надо.
Вероятно, вы будете иметь дело с гигантским набором данных после того, как завершите код. И он значительно увеличится, если вы захотите запутать больше, чем одну функцию.
Указатели функций ведут себя непредсказуемо – иногда правильно, иногда нет. Это зависит от того, что вы делаете, и там определенно будет проблема, потому что вы не в состоянии предсказать, где и когда указатель функции срабатывает в вашей сборке.
Чем хитрее вы генерируете запутывание и манипулируете сборкой в преамбуле и постскриптуме, тем сложнее исправление и отладка. Так что написание такого кода – это как балансирование между «хорошо, я аккуратно вставлю сюда один или два JMP» и «как, черт побери, мне во всём этом разобраться за короткое время»? Так что вам просто приходится вставлять инструкции и потом несколько месяцев разбираться в том, что вы наделали.
Надеюсь, сегодня вы узнали что-то полезное. По-моему, я действительно напился и поэтому не очень понимаю, что сейчас произошло. На следующем слайде показаны мои контакты в «Твиттере», мой блог и сайт, так что заходите в гости или пишите.
На этом всё, спасибо, что пришли!
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps до января бесплатно при оплате на срок от полугода, заказать можно тут.
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?

Меня зовут Фрэнк Ту, пишется frank^2 и @franksquared в «Твиттере», потому что в Twitter тоже есть какой-то спамер по имени «frank 2». Я пытался применить к ним социальную инженерию, чтобы они удалили его учётную запись, потому что технически это спам и я имею право избавиться от него как от своего клона. Но видимо, если вы поступаете с ними честно, они не отвечают вам взаимностью, потому что не смотря на мою просьбу удалить спамерский аккаунт, они ничего с ним не сделали, так что я послал этот долбанный Twitter куда подальше.
Многие люди узнают меня по моей кепке. Я работаю в региональных группах DefCon DС949 и DC310. Я также работаю c Rapid7, но не могу рассказать здесь об этом без нецензурных выражений, а мой руководитель не хочет, чтобы я ругался. Итак, я приготовил это выступление для DefCon и собираюсь уложиться в 15 минут, хотя это довольно сложная тема. По существу это стандартная презентация, которая посвящена реверс-инжинирингу и связанным с ним смешным вещам.
При обсуждении этой темы в «Твиттере» образовалось два лагеря. Один парень высказался так: «я не имею понятия, о чем говорит этот долбанный frank^2, но это потрясающе»! Второй парень из Reddit увидел мои слайды и расстроился из-за ссылок на не относящиеся к теме вещи, разозлился, что такая серьёзная тема не была полностью освещена, поэтому пожелал, чтобы в моей презентации было «больше содержания и меньше фигни».

Поэтому я хочу сосредоточиться на этой цитате. Ничего личного, чувак из Reddit, — я говорю это не только на случай, если он присутствует в этом зале, но и потому, что это была справедливая критика. Потому что разговор, не содержащий достаточно полезного контента – это пустая болтовня.
Тема моего разговора представляет для хакеров стандартную рутину, но мне кажется, что на самом деле докладчики обычно не стараются представить свою информацию в занимательной форме, даже когда это возможно, предпочитая сухие, выхолощенные выводы. «Вот IP, вот ESP, вот как вы можете выполнить эксплойт, вот мой «нулевой день», теперь хлопайте!» — и все хлопают в ладоши.
Спасибо за аплодисменты, я ценю это! Мне кажется, что в моём материале есть много интересных моментов, поэтому он заслуживает быть изложенным в несколько развлекательной манере, что я и постараюсь проделать.
Вы увидите исключительно поверхностное отношение к компьютерной науке и совершенно детский юмор, так что я надеюсь, вы оцените то, что я собираюсь здесь показать. Мне очень жаль, если вы пришли сюда в поисках серьёзного разговора.
На слайде вы видите научный анализ моего прошлого доклада, сравнивающий долю строго научного подхода и долю «лекарства», обеспечивающего компьютерную безопасность.

Вы видите, что «лекарства» намного больше, но можете не волноваться, сейчас доля науки несколько увеличилась.

Итак, некоторое время назад мой друг Мерлин, сидящий здесь в первых рядах, написал удивительный бот на основе скрипта IRC Python, занимающий всего одну строку.
Это действительно потрясающее упражнение для обучения функциональному программированию, с которым очень весело возиться. Вы можете просто добавлять одну функцию за другой и получать комбинации всяких разных функций, и всё это рисуется на экране в виде радужной волны, в общем, это одна из самых глупых вещей, которую можно сделать.
Я подумал, что если применить этот принцип к двоичным файлам? Не знаю, откуда мне пришла в голову эта идея, но получилось офигенно! Тем не менее, я хочу разъяснить некоторые основные понятия.
Вполне возможно, что ваш учитель математики представил эти функции намного сложнее, чем они есть на самом деле.

Итак, формула f(x) очень проста по своему смыслу, она работает как обычные функции. У вас есть X, у вас есть входные данные, и затем вы получаете X 7 раз, и это равно вашему значению. В Python вы можете сделать функцию (lambda x: x * 7). Если вы захотите работать с Java – извиняюсь, я надеюсь, вы никогда не захотите этого делать – то можете проделать что-то вроде:
public static int multiplyBySevenAndReturn(Integer x)
{ return x * 7; }Знаете, математические функции могут быть даже намного сложнее, но это всё, что мы должны о них знать на данный момент.
Если рассмотреть сборку кода, то можно заметить, что инструкции JMP и CALL не привязаны к конкретным значениям, они работают со смещением. Если использовать дебаггер, то видно, что JMP00401000 больше похож на инструкцию «перепрыгнуть на несколько байтов вперёд», чем на конкретное указание перепрыгнуть на 5 или 10 байтов. То же самое относится к функции CALL, за исключением того, что она пропихивает целую кучу вещей в ваш стек. Исключение составляет случай, когда вы «приклеивате» адрес к регистру, то есть обращаетесь к конкретному адресу. Здесь всё происходит совершенно иначе. После того, как вы цепляете адрес к регистру и делаете что-то вроде CALL EAX, функция обращается к конкретному значению в EAX. То же самое касается CALL [EAX] или JMP [EAX] — он просто разыменовывает EAX и переходит к этому адресу. При использовании дебаггера у вас может не быть возможности определить, к какому конкретному адресу обращается CALL. Это может стать проблемой, так что вы должны быть в курсе этого.
Давайте рассмотрим функцию «короткого прыжка» JMP SHORT. Это особая инструкция в архитектуре х86, позволяющая использовать смещение в 1 байт вместо смещения в 4 байта, что уменьшает используемое пространство памяти. Это будет иметь значение позже для всех манипуляций, которые будут происходить с индивидуальными инструкциями. Важно иметь в виду, что JMP SHORT имеет диапазон в 256 байт. Однако не существует такого понятия, как CALL SHORT.

Теперь рассмотрим колдовство компьютерной науки. В середине создания этих слайдов я понял, что фактически вы можете определить сборку как нулевое пространство, то есть технически между каждой инструкцией имеется нулевое пространство. Если вы посмотрите на индивидуальные инструкции, то увидите, что каждая выполняется по одной после другой инструкции. Технически это можно интерпретировать как безусловный прыжок к следующей инструкции. Это предоставляет нам пространство между каждой сборочной инструкцией, пока каждая инструкция соответственно связана с безусловным прыжком.
Если вы посмотрите на этот пример сборки, кстати, это очень простые вещи, которые я рекомендую декодировать с помощью ASCII, так вот, это просто набор обычных инструкций.
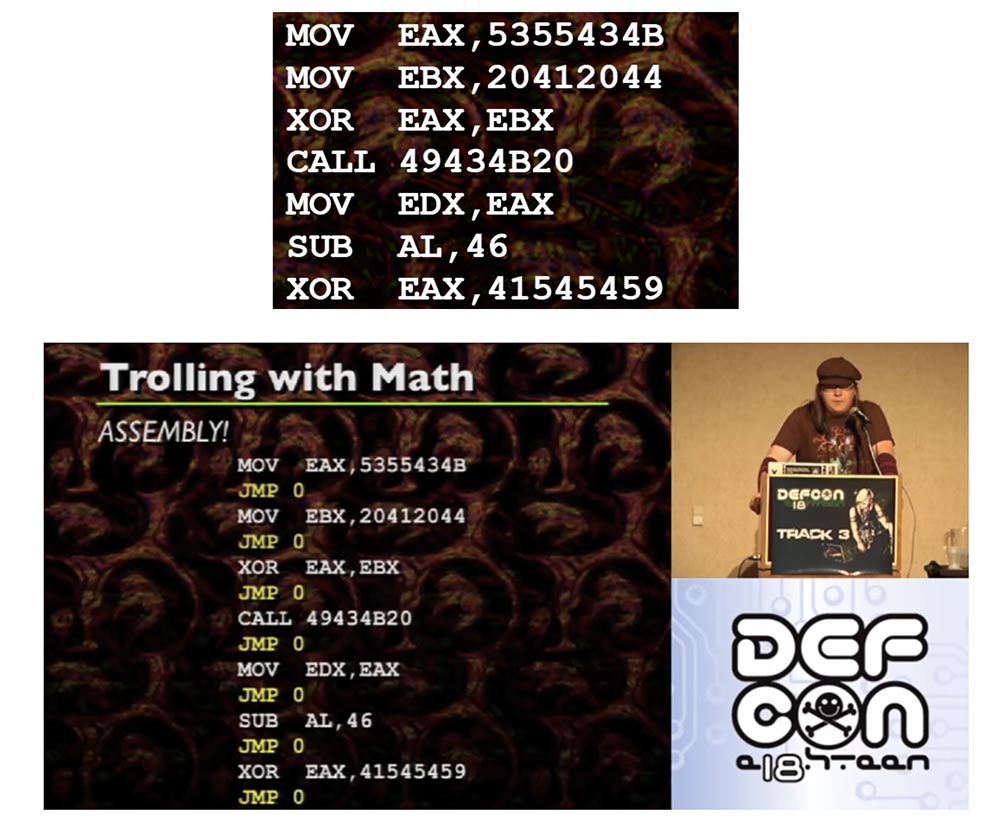
JMP 0, расположенные между каждой инструкцией, представляют собой безусловные прыжки, которые вы обычно не видите. Они следуют друг за другом после каждой инструкции. Поэтому можно разместить каждую отдельную сборочную инструкцию в произвольном месте памяти тогда и только тогда, когда каждая единичная инструкция сопровождается безусловным прыжком к следующей инструкции. Потому что если вы переносите сборку и вам нужно использовать тот же код, что и раньше, вы должны прикрепить безусловный прыжок к каждой инструкции.
Давайте посмотрим дальше. Одномерный массив технически может быть интерпретирован как двумерный массив, просто это потребует немного математики, ряды или что-то вроде них, не скажу точно, но это не слишком сложно. Это дает нам возможность интерпретировать расположение в памяти в виде решётки (x,y). В сочетании с интерпретацией пустого пространства между инструкциями как безусловных прыжков, которые могут быть связаны друг с другом, мы сможем буквально рисовать инструкции. Это потрясающе!
Для того, чтобы осуществить подобное на практике, нужно выполнить следующие шаги:
- деассемблировать каждую инструкцию, чтобы узнать, что собой представляет код;
- выделить место в памяти, размер которого значительно превышает размер набора инструкций. Обычно я резервирую памяти в 10 раз больше, чем размер кода;
- для каждой инструкции определить f(x);
- установить каждую инструкцию в соответствующее (x,y) местоположение в памяти;
- присоединить к инструкции безусловный прыжок;
- пометить память как исполняемую и запустить код.
К сожалению, здесь возникает множество вопросов. Это как с гравитацией, которая работает только в теории, а на практике мы видим совершенно иное. Потому что в реальности x86 посылает к чёрту ваши JMP инструкции, CALL инструкции, искажает ваш самореференциальный код, самомодифицирующийся код, который использует итерацию.

Давайте начнём с JMP инструкций. Так как JMP инструкции имеют смещение, при размещении их в произвольном месте они больше не указывают туда, куда по-вашему, они должны указывать. SHORT JMP оказываются в аналогичном положении. Случайно размещённые вашей функцией (x,y), они не будут указывать на то, на что вы рассчитываете. Но в отличие от «длинных» JMP, «короткие» JMP легче пофиксить, особенно если вы имеете дело с одномерным массивом. SHORT JMP легко конвертировать в обычные JMP, но тогда вам придётся вычислять, каким стало новое смещение.
Работа с JMP на основе регистров – ещё та головная боль, и из-за того, что они требуют жёстких смещений и могут рассчитываться в процессе выполнения, не существует лёгкого способа узнать, куда они направляются. Чтобы автоматически определить каждый регистр, нужно использовать кучу знаний из теории компиляции. В процессе выполнения здесь могут быть указатели функций, указатели классов и тому подобное. Правда, если вы не хотите делать дополнительную работу ради того, чтобы проделать всё это, то можете её не делать. Функции f(x) работают в реальном коде не настолько элегантно, как на бумаге. Если вы хотите сделать это как следует, вам потребуется проделать кучу работы.
Для определения указателей классов и подобных вещей вам потребуется поколдовать с С и C++. Перед сохранением, во время деассемблирования, преобразуйте свои SHORT JMP в обычные JMP, потому что вам предстоит иметь дело смещением, это достаточно просто.
Пытаться вычислить фактические смещения – огромная головная боль. Все обнаруженные вами инструкции имеют смещения, которые будут перемещаться, при перемещении кода, и должны пересчитываться. Это означает, что вам необходимо следить за инструкциями и за тем, куда они перемещаются, как за целями. Мне трудно вам объяснить на слайдах, но пример, как это добиться, есть на компакт-диске с материалами этой конференции.
После того, как вы разместите все инструкции, замените старые смещения новыми смещениями. Если вы не повредили смещения, то всё получится. Теперь, когда вы подготовились, появляется реальная возможность воплощения идеи на высшем уровне. Для этого нужно:
- деассемблировать инструкции;
- подготовить буфер памяти;
- инициализировать имеющиеся константы f(x);
- выполнить итерацию величин f(x) и определённых указателей данных, по которым будет написан ваш код во время отслеживания долбанных инструкций;
- приписать инструкции к соответствующим созданным указателям;
- исправить все условные прыжки;
- пометить новый раздел памяти как исполняемый;
- выполнить код.
Если вы всё правильно расставили по местам, то получаются странные вещи – всё перепутывается, инструкции прыгают в непонятные места памяти, и всё это выглядит просто феерично.

Имеет ли всё это какое-то практическое значение или это просто цирковое представление? Прикладное значение подобных преобразований заключается в следующем. Изоляция инструкций по сборке и несколько шагов для вычисления f(x) позволяет нам разместить эти сборочные инструкции в любом месте буфера без какого-либо взаимодействия с пользователем. Чтобы запутать пути выполнения кода, все, что вам нужно сделать, это математически написать функцию и указатели в каком-нибудь ассемблере, выбирая их случайным образом.
Это намного упрощает полиморфные методы кодирования. Вместо того, чтобы каждый раз писать код, который определённым способом манипулирует вашим кодом, вы можете написать ряд функций, которые случайно определят положение вашего кода, а затем выбрать эти функции как случайные и т. д.
Антиреверсирование не такая крутая и свежая штука, как техника антидебаггинга.
Антиверсирование заключается не в том, сколько удовольствия вы получите от того, что сделаете невозможным использования IDA и не в том, насколько затролите компьютер ревёрсера картинками Last Measure от GNAA, хотя это чертовски весело. Антиреверсирование – это значит просто быть мудаком, потому что если вы, как последний мудак, достанете ревёрсера, чувака, который ломает защиты разных систем, он просто разозлится, пошлёт к чертям эту вредоносную программу и уйдёт.
Между тем, вы сможете продать всех своих ботов русским деловым сетям, потому что своим ПО вы «опускаете» всех, кто занимается реверсивным инжинирингом. Все знают, как найти в Google техники для антидебаггинга, но они не найдут там решения проблем, возникающих от креативных вещей. Самые креативные антиревёрсеры заставят ревёрмеров обломать свои пальцы о клавиатуру и оставить в стенах дыры размером с кулак. Ревёрсеры будут кипеть от злости, они не поймут, какого черта ты сделал, потому что твой код все испортил.
Это своеобразная игра на нервах, психологическая штука, если вы творчески подойдёте к этому делу и создадите действительно потрясающий антиреверс, то сможете им гордиться. Но вы знаете, что на самом деле, просто пытаетесь отвадить их от вашего кода.
Итак, что я собираюсь делать? Я собираюсь взять функции запутывания и запутать их. Затем я собираюсь использовать вторую версию запутывания запутанных функций и снова применить запутывание. Итак, давайте вытянем код. Это образец математического троллинга, который я взял для примера.
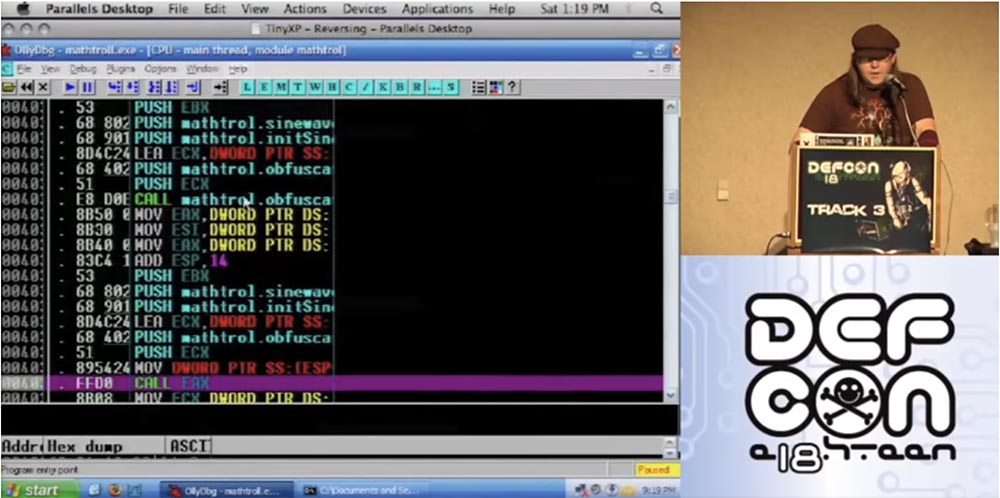
Итак, я ввожу в открывшееся окно команду «запутать по формуле».
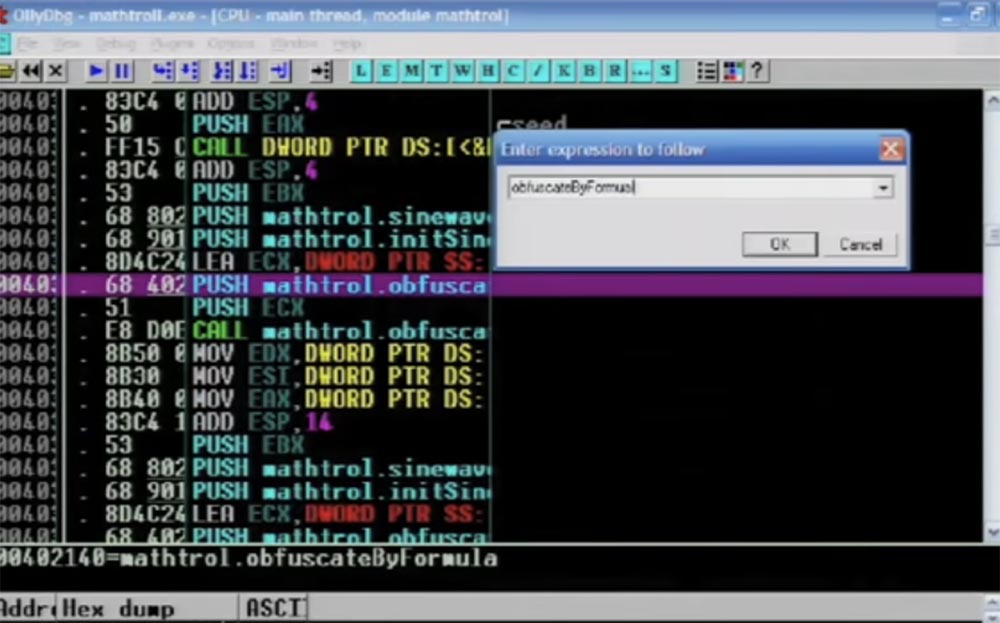
Далее вы видите сборочные инструкции, которые выполняют свою работу. Заметьте, что я использую здесь C++, хотя при малейшей возможности стараюсь избежать этого.
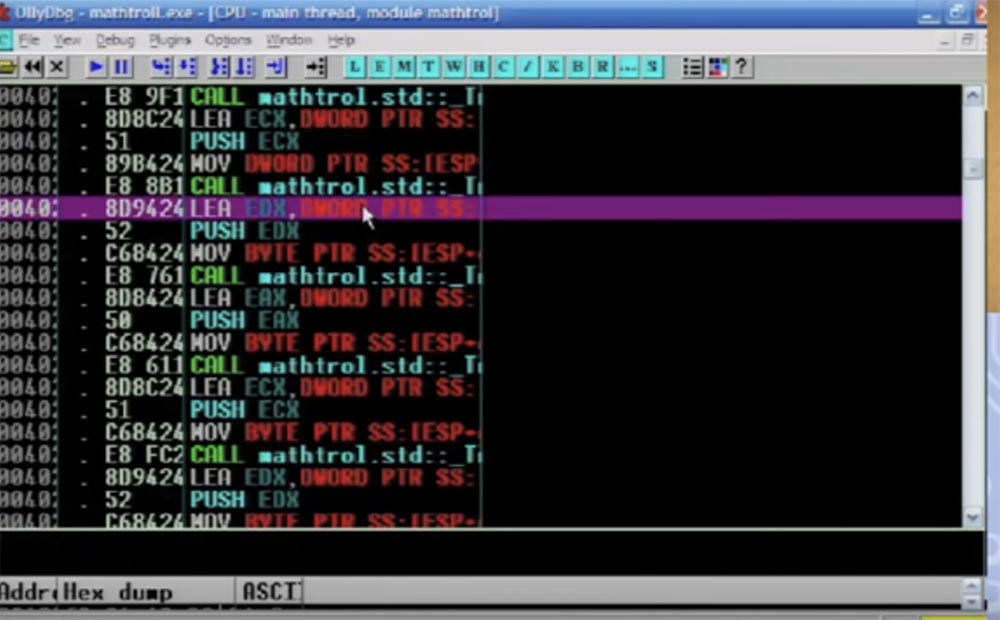
Вот здесь выделена активная функция CALL EAX, далее следует инструкция прыжка, которая будет применена, вы видите кучу всяких разных вещей в буфере, и всё это проделывается с каждой индивидуальной инструкцией.
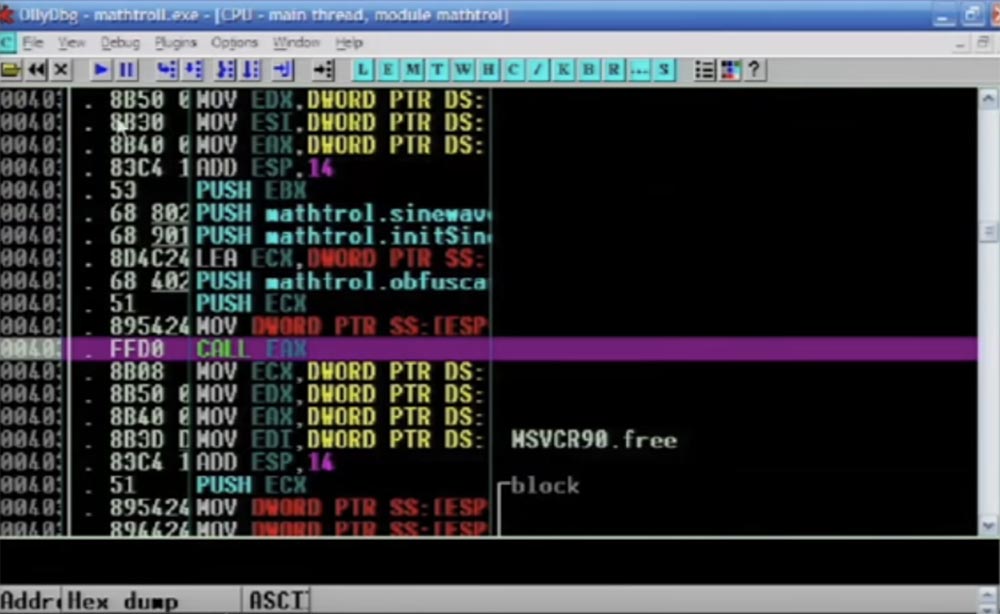

Сейчас я перемотаю программу до конца, и вы увидите результат. Итак, код всё ещё выглядит отлично, здесь собрана куча инструкций JMP, это выглядит запутанным, и в действительности оно запутано.
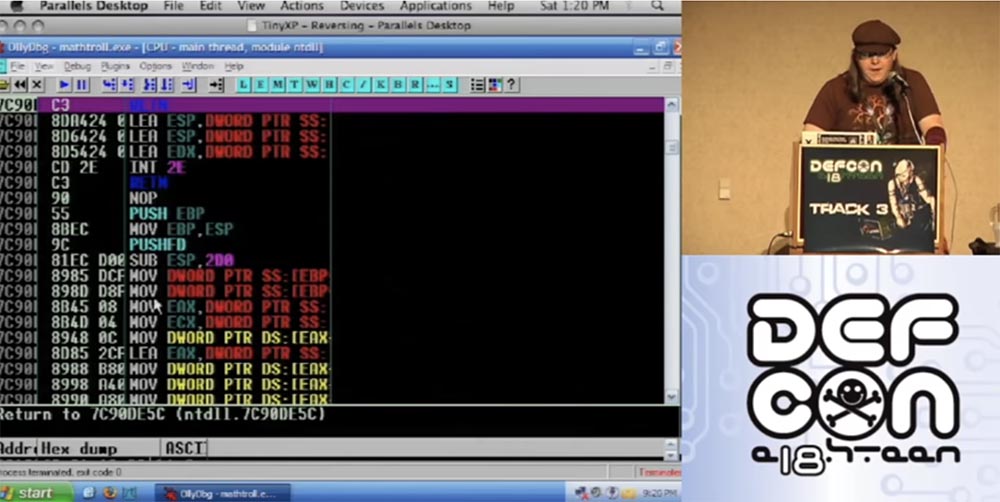
На следующем слайде показано графическое представление того, как выглядит стек.

Каждый раз, когда это происходит, я генерирую формулу случайной синусоидной волны, которая носит произвольную форму, вы видите тут кучу разных форм, и это круто. Я думаю, что код начинаете где-то вверху слева, но точно не помню. Вот так он всё закручивает, вы можете не только делать синусоиды, но и закручивать спирали.
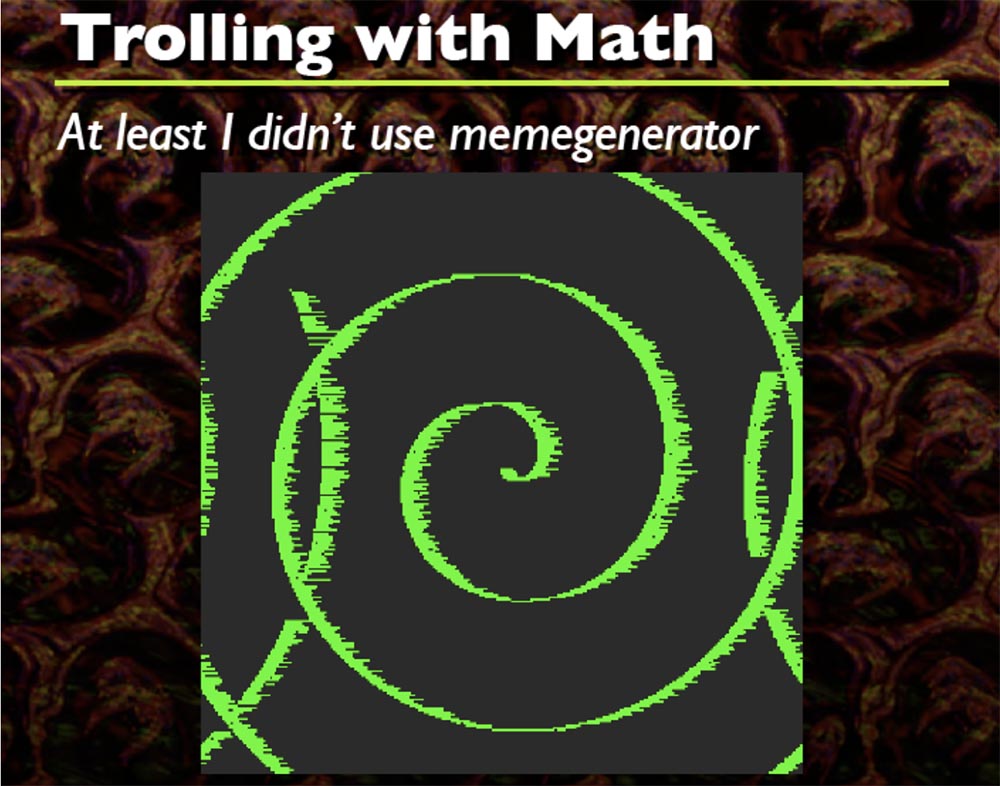
Здесь работают всего две формулы, которые я включил в исходный код. На основе этого вы можете сделать множество креативных вещей, какие только захотите, по существу это просто DIFF от начального буфера к конечному буферу.
Проблема в том, что этот пример кода использует безусловные прыжки, что на самом деле плохо, потому что при этом код должен быть точно такой же, как раньше, то есть безусловные прыжки следуют только в одном направлении. Поэтому вам нужно пройти от точки входа до конца тем же путём, избавиться от инструкции прыжка и готово – вы получили свой код! Что же делать? Нужно превратить безусловные прыжки в условные. Условные прыжки совершаются по двум направлениям, это намного лучше, можно сказать, что это лучше на 50%.
Здесь у нас возникает интересная дилемма: если нам нужны условные прыжки, то нам ещё нужно использовать и безусловные прыжки…какого хрена? И что же нам делать? Нас спасут непрозрачные предикаты! Для тех, кто не знает, непрозрачный предикат – это по существу булево утверждение, которое всегда выполняется для определенной версии независимо ни от чего.
Итак, давайте рассмотрим расширение нулевого пространства, о котором я говорил ранее. Если у вас есть набор инструкций и они имеют безусловные прыжки переходы между каждой инструкцией, из этого следует, что серия сборочных инструкций, которые не имеют прямого влияния на нужные нам инструкции, может предшествовать или следовать одиночной инструкции.
Например, если вы написали очень специфичные инструкции, которые не изменяют основную сборку того, что вы пытаетесь запутать, то есть вы пытаетесь не связываться с регистрами до тех пор, пока поддерживаете состояние каждой инструкции по сборке. И это ещё более удивительно.
Вы можете рассмотреть каждую сборочную инструкцию, которую можно запутать, как преамбулу, данные сборки и постскриптум. Преамбула – это то, что предшествует сборочной инструкции, а постскриптум – то, что за ней следует. Преамбула обычно используется или может использоваться для двух вещей:
- исправление последствий непрозрачного предиката предыдущей преамбулы;
- антидебаггинг фрагментов кода.
Но преамбула существенно ограничена, потому что вы не можете сделать слишком много.
Постскриптум более весёлая штука. Он может использоваться для:
- непрозрачных предикатов и запутанных прыжков к следующим разделам кода;
- антидебаггинга и запутывания общего выполнения кода;
- шифрования и дешифровки различных фрагментов кода в самой программе.
Прямо сейчас я работаю над тем, чтобы осуществить возможность зашифровки и расшифровки каждой отдельной инструкции так, что при выполнении каждой инструкции она расшифровывает следующий раздел, следующий раздел, следующий и так далее. На следующем слайде показан пример этого.

Зелёным цветом выделены строки преамбулы и вызов дебаггера. Всё, что делает этот вызов – это проверяет, имеется ли у нас отладчик, после чего осуществляется переход к произвольной секции кода.
Внизу у нас имеется очень простой непрозрачный предикат. Если вы поддерживаете значение EАX в постскриптуме к верхней инструкции, то следуете оператору XOR, так что ваше JZ думает: «хорошо, я, очевидно, могу пойти влево или вправо, я думаю, что лучше я пойду направо, потому что там 0». Затем выполняется POP EAX, ваше EAX возвращается назад, после чего обрабатывается следующая инструкция и так далее.
Это, очевидно, создаёт гораздо большие проблемы, чем наша базовая стратегия, такие, как остаточные эффекты и усложнение генерирования различных наборов инструкций. Поэтому будет очень сложно определить, как инструкция влияет на другую инструкцию. Можете кидать в меня тапками, потому что я ещё не закончил эту потрясающую программу, но за ходом разработки вы можете проследить в моём блоге.

Замечу, что наши формулы f(x) не обязательно должны вычисляется итеративно, например f (1), f(2),… f (n). Ничто не мешает вычислять их случайным образом. Если вы сообразительны, то сможете определить, сколько инструкций вам понадобится, а затем для каждой инструкции назначить, например, f (27), f(54), f (9), и это будет то место, где ваша инструкция разместиться случайным образом. Когда вы сделаете это, в зависимости от того, как именно написали свой код, то сможете заранее это прекратить, причём код будет по прежнему связывать ваши инструкции случайным образом.
Если ваш код генерируется на основе предсказуемой формулы, то из этого следует, что точка входа тоже предсказуема, так что вы можете взять на один уровень больше перед тем, как завершите получение кода, и существенно запутать точку входа в той или иной мере. Например, взять 300 сборочных инструкций, исходящих из одной точки входа.
Теперь поговорим о недостатках.

Этот метод требует тщательной компиляции кода, в основном с помощью GCC или не дай бог, с помощью C++. На самом деле C++ довольно крутой язык по нескольким причинам, но вы же знаете, что все компиляторы – отстой. Так что главное в этом деле – грамотная собственноручная компиляция, потому что если ваша попытка запутать собственную сборку вызовет одобрение банды, придумавшей червь Conficker, то вы облажались.
Вам потребуется большой объем памяти. Вспомните картинку с синусоидами. Красный цвет – это код, а синее пространство – память, необходимая для его работы, и её должно быть достаточно, чтобы всё работало как надо.
Вероятно, вы будете иметь дело с гигантским набором данных после того, как завершите код. И он значительно увеличится, если вы захотите запутать больше, чем одну функцию.
Указатели функций ведут себя непредсказуемо – иногда правильно, иногда нет. Это зависит от того, что вы делаете, и там определенно будет проблема, потому что вы не в состоянии предсказать, где и когда указатель функции срабатывает в вашей сборке.
Чем хитрее вы генерируете запутывание и манипулируете сборкой в преамбуле и постскриптуме, тем сложнее исправление и отладка. Так что написание такого кода – это как балансирование между «хорошо, я аккуратно вставлю сюда один или два JMP» и «как, черт побери, мне во всём этом разобраться за короткое время»? Так что вам просто приходится вставлять инструкции и потом несколько месяцев разбираться в том, что вы наделали.
Надеюсь, сегодня вы узнали что-то полезное. По-моему, я действительно напился и поэтому не очень понимаю, что сейчас произошло. На следующем слайде показаны мои контакты в «Твиттере», мой блог и сайт, так что заходите в гости или пишите.

На этом всё, спасибо, что пришли!
Спасибо, что остаётесь с нами. Вам нравятся наши статьи? Хотите видеть больше интересных материалов? Поддержите нас оформив заказ или порекомендовав знакомым, 30% скидка для пользователей Хабра на уникальный аналог entry-level серверов, который был придуман нами для Вас: Вся правда о VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps от $20 или как правильно делить сервер? (доступны варианты с RAID1 и RAID10, до 24 ядер и до 40GB DDR4).
VPS (KVM) E5-2650 v4 (6 Cores) 10GB DDR4 240GB SSD 1Gbps до января бесплатно при оплате на срок от полугода, заказать можно тут.
Dell R730xd в 2 раза дешевле? Только у нас 2 х Intel Dodeca-Core Xeon E5-2650v4 128GB DDR4 6x480GB SSD 1Gbps 100 ТВ от $249 в Нидерландах и США! Читайте о том Как построить инфраструктуру корп. класса c применением серверов Dell R730xd Е5-2650 v4 стоимостью 9000 евро за копейки?
