Comments 38
Эх, эту бы статью да месяц назад. Я бы всех в Каггле порвал про планктон!
А если серьёзно — спасибо большое, очень интересно.
А если серьёзно — спасибо большое, очень интересно.
думаю на планктонах бы это не прокатило, тк там серые изображения; у меня коллега участвовал в том конкурсе, он брал топологию VGG и обучал с нуля все, занял где то 30 (±) место
а для того что бы использовать трансфер лернинг, он пробовал аугментировать изображения, преобразовывая их различными способами в трехканальные
а для того что бы использовать трансфер лернинг, он пробовал аугментировать изображения, преобразовывая их различными способами в трехканальные
А где вы, кстати, узнаёте про все эти весёлые челленджи? Интересно было бы поучаствовать.
А вы тренировали сверточную сеть с нуля, без претренировки? Хотелось бы понять, насколько здесь заметен вклад именно transfer learning. Статья вроде как об этом. По моему опыту иногда проще и лучше тренировать под задачу, чем использовать претренированную модель. Хотя, я слышал у некоторых получалось лучше с претренингом.
На счет активации — не очень понятно зачем вы накручивали сигмоид на relu, если можно просто убрать relu слой.
На счет активации — не очень понятно зачем вы накручивали сигмоид на relu, если можно просто убрать relu слой.
А вы тренировали сверточную сеть с нуля, без претренировки?
в том то и проблема, что в рамках моего эксперимента, у меня есть база не размеченных изображений, а тренировать автоенкодер на выходах сверточной сети как то не правильно наверное, все таки там присутствует изрядная доля инвариантности
думаю позже я еще попробую такую штуку — Stacks of Convolutional Restricted Boltzmann Machines for Shift-Invariant Feature Learning, с нее не начал так тут придется код писать, не нашел нормальных реализаций
Статья вроде как об этом. По моему опыту иногда проще и лучше тренировать под задачу, чем использовать претренированную модель.
еще лучше претренировать, а потом делать fine turning -) вот тут, на днях, Эндрю Нг на конфе nvidia GTC рассказал, что они в байду для модели генерации описания изображений использовали трансфер из обученной модели для классификации изображений
На счет активации — не очень понятно зачем вы накручивали сигмоид на relu, если можно просто убрать relu слой.
моя мотивация следующая, хотя не претендует на абсолютную истину: релу придает спарсность выходу сети, скажем сигмоид от -1 будет равен 0.2689, а в моем случае это будет ноль
Про второй пункт статья в тему с последнего нипса — papers.nips.cc/paper/5347-how-transferable-are-features-in-deep-neural-networks
Клун в разговоре обещал, что у них будет продолжение, где они будут более внимательно оценивать переносимость фичей на датасеты совсем иной природы.
Клун в разговоре обещал, что у них будет продолжение, где они будут более внимательно оценивать переносимость фичей на датасеты совсем иной природы.
Осталось дождаться «библиотеки» натренированных под разные задачи шаблоны нейронных сетей и использовать их при разработке своей нейронной сети.
Вопрос к автору: а может уже существуют эти «библиотеки»? Вы случайно не искали?
Вопрос к автору: а может уже существуют эти «библиотеки»? Вы случайно не искали?
я не видел, но думаю не исключено что когда-нибудь будет не только библиотека, то и что то типа Transfer Learning Market, все таки тренировка сети дело не дешевое, VGG пишут что тренировали сеть 3 недели
а если скажем кто то соберет качественны датасет (что действительно не тривиально), затем месяцок потренит сеть на кластере, то пожно и продавать -)
а если скажем кто то соберет качественны датасет (что действительно не тривиально), затем месяцок потренит сеть на кластере, то пожно и продавать -)
<минутка_футурологии>Пока бесплатно раздают. Но скоро появится профессия «тренер искуственного интеллекта» и такие пакеты будут для него рабочими инструментами.</минутка футурологии>
все таки тренировка сети дело не дешевое
Не согласен. Есть ряд частных случаев, когда обучение нейронной сети можно распараллелить.
Распределенные вычисления можно «накрутить» :)
да можно параллелить, но зависимость прироста скорости от количества гпу не линейная, вот к примеру слайд и недавнего выступления Нг на GTC conf
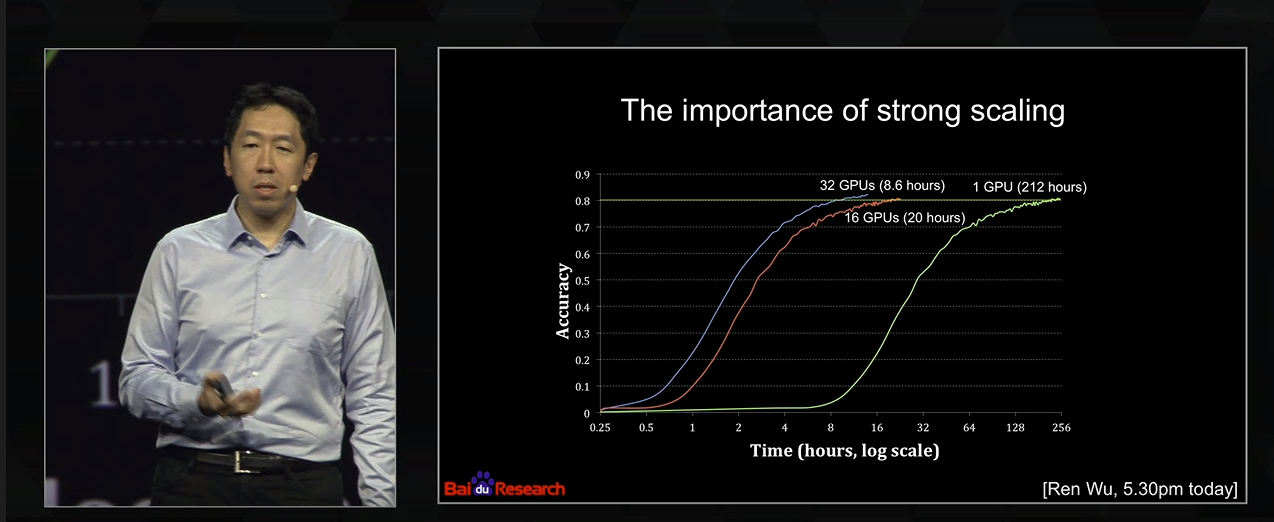
например если юзать распараллеливание по батчам, то если для каждого батча будет своя гпу, и после расчета все аккумулируется, то это уже будет не стохастический спуск, ну как бы не совсем он, а это как раз и замедлит сходимость

например если юзать распараллеливание по батчам, то если для каждого батча будет своя гпу, и после расчета все аккумулируется, то это уже будет не стохастический спуск, ну как бы не совсем он, а это как раз и замедлит сходимость
Скорее всего продаваться такие фрагменты будут в виде обучающего набора и микропрограммы которая уже имеющуюся сеть будет подстраивать, используя несколько имеющихся в ней нейронов. А потом вы будете накладывать на свою сеть такие паттерны обучения.
Я, кстати, думаю, что поскольку это знание тиражируемо и станет критически важным для обучения сетей скоро начнутся попытки законодательно ограничивать права на такого рода информацию, и вводить контракты, фиксирующие, что обучающие паттерны, которым научился наш станок на вашем производстве принадлежат нам. Некоторый такой современный аналог присвоения прибавленной стоимости.
По крайней мере если я создам фирму, которая будет производить мозговитые станки у меня в контракте такой пункт будет. :)
Я, кстати, думаю, что поскольку это знание тиражируемо и станет критически важным для обучения сетей скоро начнутся попытки законодательно ограничивать права на такого рода информацию, и вводить контракты, фиксирующие, что обучающие паттерны, которым научился наш станок на вашем производстве принадлежат нам. Некоторый такой современный аналог присвоения прибавленной стоимости.
По крайней мере если я создам фирму, которая будет производить мозговитые станки у меня в контракте такой пункт будет. :)
Жесть, нейропластичность для нейронных сетей!
В целях самообразования интересуюсь темой нейропластичности и вообще работы мозга (в разрезе использования знания, для понимания как научить ребенка с ЗПР говорить).
После прочтения появилась мысль организовать некий девайс с парой кнопок, типа, хочу пить, гулять и т.д.
Может это окажется эффективным (хотя и не научит говорить) для изъяснения мыслей.
В целях самообразования интересуюсь темой нейропластичности и вообще работы мозга (в разрезе использования знания, для понимания как научить ребенка с ЗПР говорить).
После прочтения появилась мысль организовать некий девайс с парой кнопок, типа, хочу пить, гулять и т.д.
Может это окажется эффективным (хотя и не научит говорить) для изъяснения мыслей.
Статья актуальная и интересная!
Я так и не понял, а где же transfer learning?
Из того что я видел:
Self-taught Learning: Transfer Learning from Unlabeled Data
Еще во второй части лекции от яндекса, где сетка похожая на рогатину
Так же не понял, вы обучали глубокую сверточную сеть сами на своих данных или вы взяли готовую уже обученную?
Если второе, то как я понял это был трюк аля берем обученную на ImageNet сверточную сеть, отрубаем ей голову, далее можем этот обрубок использовать как выделятор фич, а можем еще и дообучить на нашем датасете(некий такой finetuning).
Как вы в итоге сравниваете качество работы алгоритма? на глаз?
Я так и не понял, а где же transfer learning?
Из того что я видел:
Self-taught Learning: Transfer Learning from Unlabeled Data
Еще во второй части лекции от яндекса, где сетка похожая на рогатину
Так же не понял, вы обучали глубокую сверточную сеть сами на своих данных или вы взяли готовую уже обученную?
Если второе, то как я понял это был трюк аля берем обученную на ImageNet сверточную сеть, отрубаем ей голову, далее можем этот обрубок использовать как выделятор фич, а можем еще и дообучить на нашем датасете(некий такой finetuning).
Как вы в итоге сравниваете качество работы алгоритма? на глаз?
Я так и не понял, а где же transfer learning?
он как раз в том что знания нейросети, обученной для решения задачи классификации какого то одного датасета, переносятся в другую модель, которая решает другую задачу на других данных
Так же не понял, вы обучали глубокую сверточную сеть сами на своих данных или вы взяли готовую уже обученную?
именно сверточную сеть я взял готовую, тк мои данные не размечены, и как я упоминал в коменте выше, в принципе есть вариант unsupervised pretraining'а для сверточной сети, но это будет следующий эксперимент
а можем еще и дообучить на нашем датасете(некий такой finetuning).
ага, это и делается на извлеченных фичал, но уже используя deep belief network; в этом случае конечно веса сверток не дообучаются, происходит семантик хэшинг, их статьи Хинтона
Как вы в итоге сравниваете качество работы алгоритма? на глаз?
ага -) это все эксперименты без какой то конкретной задачи, как появится более четкая задача, то и будет более точная мера оценки качества; если до этого дойдет, то вероятно запилю еще один пост
Спасибо. Очень интересная статья. Трансфер, правда, грубоват если слоями дёргать, но идея крайне перспективная если даже в таком варианте получается. :)
В процессе вы ссылаетесь на вот эту статью про предобучение.
habrahabr.ru/post/163819/
Там фигурирует предположение, что в процессе обучения происходит затухание примерно так выглядящее:
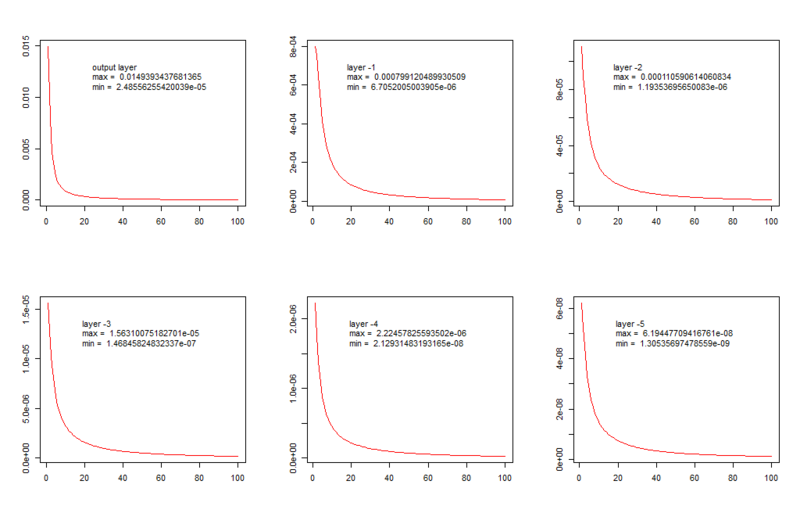
Однако так грустно и однообразно веса изменяются только если их округлять тысячами. Если посмотреть визуализацию подчёркивающую изменения отдельных весов при слабо меняющихся остальных становится видно, что изменения в сети предельно далеки от постепенно затухающего приближения к оптимуму:
habrahabr.ru/post/221049/
В процессе вы ссылаетесь на вот эту статью про предобучение.
habrahabr.ru/post/163819/
Там фигурирует предположение, что в процессе обучения происходит затухание примерно так выглядящее:
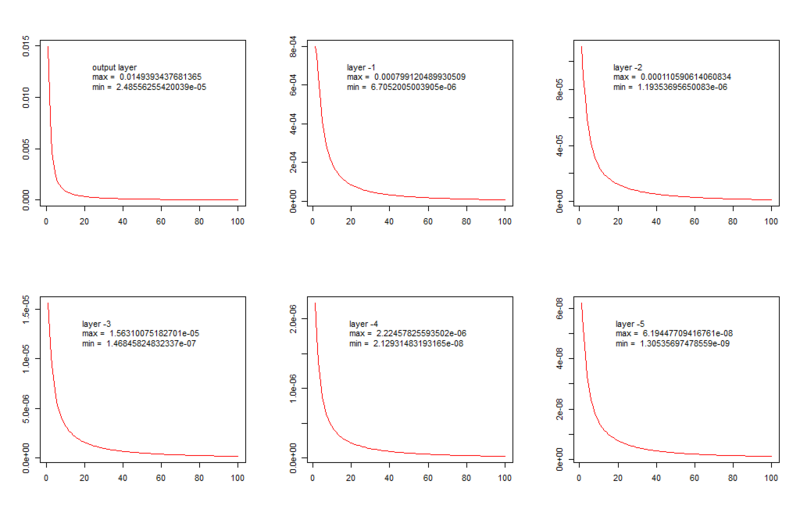
Однако так грустно и однообразно веса изменяются только если их округлять тысячами. Если посмотреть визуализацию подчёркивающую изменения отдельных весов при слабо меняющихся остальных становится видно, что изменения в сети предельно далеки от постепенно затухающего приближения к оптимуму:
habrahabr.ru/post/221049/
Там фигурирует предположение
вообще это не предположение, а математика
наглядно легко увидеть это если решить простую задачку вычисления градиентов для такой вот сети

а формально можно почитать тут например
- Understanding the difficulty of training deep feedforward neural networks
- On the difficulty of training Recurrent Neural Networks
или погуглить saturation vanishing and exploding gradients
И если мы знаем, что теоретически должно быть так, а в эксперименте видим, что всё совсем не так, это говорит о чём? О том, что мы где-то неправильно применили математику или смотрим на плохую визуализацию. Или и то и другое одновременно.
В случае простой задачки существует прямой градиентный путь от точки начала до точки конца. Если вы сделаете хотя бы по два нейрона в слое уже возникнет ситуация, когда глобальный минимум из выбранного начала простым спуском вообще недостижим, то есть уже не так всё просто. Однако в реальной практике ландшафт эффективности на много более пересечённый. Точка достижимая из начального состояния по не слишком кривой траектории, как правило, является очень убогим минимумом. Реальной сети приходится пробираться по очень пересечённому рельефу, грубо говоря, не первому, а второму:
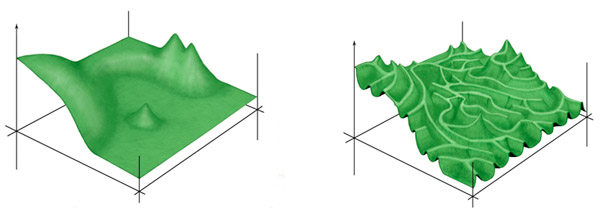
Картинка, кстати, из очень хорошей статьи по биологии, где рассмотрели ту же проблему: elementy.ru/news/432406
Я это к чему вспомнил, к тому, что трансфер обученности позволяет передать новой сети знания, полученные предыдущей сети проползшей по всем каньонам и оврагам и вышедшей на хорошее относительно плоское место.
А невидите вы этого потому что визуализация плохая. Если вам моя визуализация не нравится вы можете сделать по другому. Это же, теоретически, степенная зависимость? Так вот нарисуёте на графике не значение скорости изменения, а степень графика приближающего на локальном участке эту скорости. Понятно, что её изменине даже процентов на 40 будет на исходном степенном графике почти незаметным. Вы обнаружите что она не только сильно скачет, но и скачет не случайно. Тоесть пока сеть идёт по аврагу в бок степень может сильно упасть. Через 20-30 эпох когда она из оврага выйдет степень может скакнуть вверх и долго оставаться большей. ПРичём не у всех синапсов, а только у некоторых.
Чрезвычайно интересное зрелище. Поразгладывайте его — не пожалеете.
В случае простой задачки существует прямой градиентный путь от точки начала до точки конца. Если вы сделаете хотя бы по два нейрона в слое уже возникнет ситуация, когда глобальный минимум из выбранного начала простым спуском вообще недостижим, то есть уже не так всё просто. Однако в реальной практике ландшафт эффективности на много более пересечённый. Точка достижимая из начального состояния по не слишком кривой траектории, как правило, является очень убогим минимумом. Реальной сети приходится пробираться по очень пересечённому рельефу, грубо говоря, не первому, а второму:

Картинка, кстати, из очень хорошей статьи по биологии, где рассмотрели ту же проблему: elementy.ru/news/432406
Я это к чему вспомнил, к тому, что трансфер обученности позволяет передать новой сети знания, полученные предыдущей сети проползшей по всем каньонам и оврагам и вышедшей на хорошее относительно плоское место.
А невидите вы этого потому что визуализация плохая. Если вам моя визуализация не нравится вы можете сделать по другому. Это же, теоретически, степенная зависимость? Так вот нарисуёте на графике не значение скорости изменения, а степень графика приближающего на локальном участке эту скорости. Понятно, что её изменине даже процентов на 40 будет на исходном степенном графике почти незаметным. Вы обнаружите что она не только сильно скачет, но и скачет не случайно. Тоесть пока сеть идёт по аврагу в бок степень может сильно упасть. Через 20-30 эпох когда она из оврага выйдет степень может скакнуть вверх и долго оставаться большей. ПРичём не у всех синапсов, а только у некоторых.
Чрезвычайно интересное зрелище. Поразгладывайте его — не пожалеете.
И если мы знаем, что теоретически должно быть так, а в эксперименте видим, что всё совсем не так, это говорит о чём? О том, что мы где-то неправильно применили математику или смотрим на плохую визуализацию. Или и то и другое одновременно.
так в эксперименте мы и видим описанные проблемы
Мы возьмём сеть, состоящую из 3 слоёв по 15 нейронов в каждом
а в этом эксперименте вы это и не увидите, все это действительно только для больших и глубоких моделей, а модель из трех слоев по 15 нейронов как бы не назвать ни глубокой ни большой
а вот возьмите архитектуру такого вот автоэнкодера как в статье Хинтона
DBN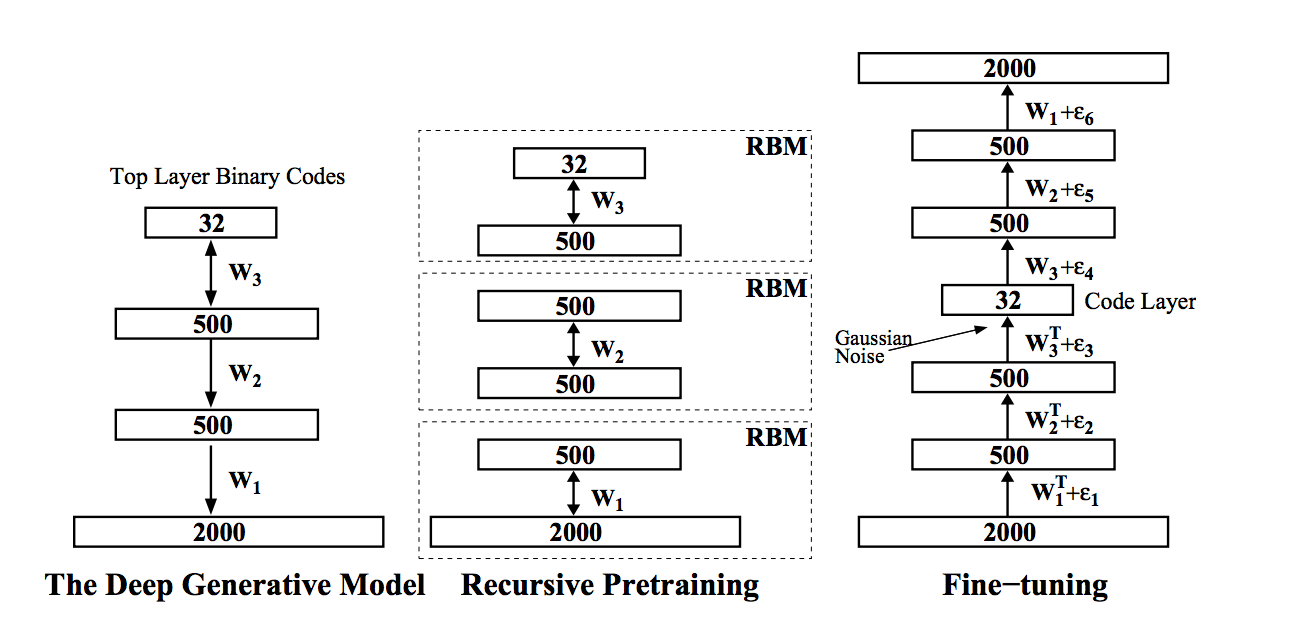
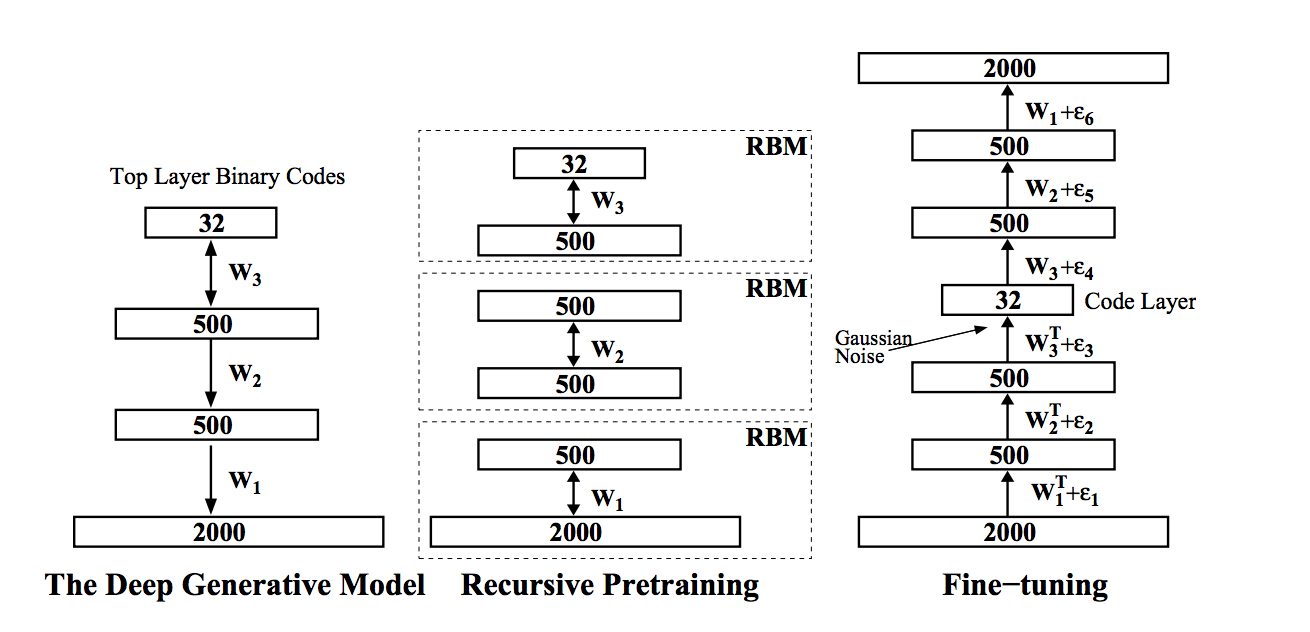
и попробуем подсчитать количество параметров для небольшой картинки 256 на 256, получится 264 819 136 связей, против вашего эксперимента в котором 604 (вроде как) параметра
Сдаётся мне, что и на двухстах миллиардах связей закономерности были бы те же, вопрос только в том, что соотношение «сигнал-шум» было бы сильно хуже. В своих экспериментах я видел как значения скорости меняются на три порядка в норме, и до 7-8 порядков в пределе. Я экспериментировал и с большими сетями, но всё же не на столько большими. При числе синапсов на 6 порядков больше такой сигнал действительно может утонуть в шуме.
Но тут уж, как говорится. Я наблюдением, которое, как мне кажется, связано, вы на него посмотрели. Встретится оно вам или нет, и есть ли оно всегда или только в малых сетях — кто знает.
Но тут уж, как говорится. Я наблюдением, которое, как мне кажется, связано, вы на него посмотрели. Встретится оно вам или нет, и есть ли оно всегда или только в малых сетях — кто знает.
3 слоя по 15 нейронов это только для статьи было. Так то я занимаюсь сетями в которых слоёв десятки. В сети из третьей статьи если подходить формально, слоёв 28. Но нейронов действительно не много по сравнению с этими монстрами. Явление присутствует.
Чем больше размерность — тем «лучше» ландшафт. В одномерном случае градиентный спуск вообще сразу же увязнет, в двумерном тоже всё сложно.
Ваша картинка — двухмерная, от неё у вас возникает иллюзия понимания.
«Локальные минимумы» в сильно-многомерном ландшафте возникают около глобальных минимумов, причём, чем ближе к глобальному минимуму, тем больше локальных минимумов, и наоборот.
Проблемы, конечно, есть, поэтому и придумывают всякие Dropout, RMSProp и улучшают начальную оптимизацию.
Вообще, я бы сравнил это со знанием языков: в одном языке одну вещь можно сказать точнее, чем в другом, поэтому сеть застревает на одном понятии, а для выучивания одновременно двух понятий нейронов ей уже не хватает — понятий очень много, а нейронов слишком мало.
И именно поэтому сеть, обученная без учителя и одним и тем же количеством нейронов, будет лучше доучиваться, чем сеть, обученная с учителем, которую потом перенесли в другую предметную область.
Ваша картинка — двухмерная, от неё у вас возникает иллюзия понимания.
«Локальные минимумы» в сильно-многомерном ландшафте возникают около глобальных минимумов, причём, чем ближе к глобальному минимуму, тем больше локальных минимумов, и наоборот.
Проблемы, конечно, есть, поэтому и придумывают всякие Dropout, RMSProp и улучшают начальную оптимизацию.
Вообще, я бы сравнил это со знанием языков: в одном языке одну вещь можно сказать точнее, чем в другом, поэтому сеть застревает на одном понятии, а для выучивания одновременно двух понятий нейронов ей уже не хватает — понятий очень много, а нейронов слишком мало.
И именно поэтому сеть, обученная без учителя и одним и тем же количеством нейронов, будет лучше доучиваться, чем сеть, обученная с учителем, которую потом перенесли в другую предметную область.
Хороший комментарий. Приятно комментировать.
Не так всё просто. Чем многомернее ландшафт тем больше шансов что путь существует. Однако при этом рельех в целом значительно уплощается, градиенты становятся меньше и для большинства алгоритмов ландшафт становится из-за этого непроходим, при том, что с бесконечно малой скоростью сквозь него вероятно можно прорваться. Сделайте простое действие — возмите сеть, например, с 4 скрытыми солями, и добавьте нейронам предпоследнего слоя синапсы на первый слой. Формально мерность пространства сильно возросла, а фактически качество приближения может упасть.
На самом деле я смотрю на фазовое состояние сети, как описал в своей статье, упоминавшейся выше, оно на 2d только проецируется. И даёт очень неплохое представление о ландшафте. Там видно, что ландшафт на реальных задачах гораздо чаще похож на ту двумерную картинку с большим количеством неглубоких и непрямых оврагов с довольно крутыми стенами связывающих области локальных минимумов, расположенных друг от друга на характерных расстояниях заметно больших, чем размеры самих скоплений минимумов. То есть мы имеем дело скорее с лабиринтом, чем с системой, где есть большой хороший минимум к которому мы идём по области всё более частых локальных минимумов.
Алгоритмы Dropout, RMSProp гляну, сходу не прокомментирую, но я боле чем уверен, то что начальная оптимизация решает дело даже не на четверть. Например посмотрите на вот такое видео обучения: www.youtube.com/watch?v=09wHERJnnEA, вы увидите, что изучать строение второго крыла (ближе к концу видео) сеть начала только после того, как освоила форму первого. Чтобы конечное состояние сети из этого примера стало доступно по схеме «предобучение плюс тонкая подстройка» нужно было бы, чтобы предобучение успешно научило сеть рисовать тушку и первое крыло. Сдаётся мне, что алгоритмы предобучения такого не умеют.
Обучение без учителя я, впрочем, пока, ещё только начал изучать, так что возможно вы в чём-то абсолютно правы.
Чем больше размерность — тем «лучше» ландшафт.
Не так всё просто. Чем многомернее ландшафт тем больше шансов что путь существует. Однако при этом рельех в целом значительно уплощается, градиенты становятся меньше и для большинства алгоритмов ландшафт становится из-за этого непроходим, при том, что с бесконечно малой скоростью сквозь него вероятно можно прорваться. Сделайте простое действие — возмите сеть, например, с 4 скрытыми солями, и добавьте нейронам предпоследнего слоя синапсы на первый слой. Формально мерность пространства сильно возросла, а фактически качество приближения может упасть.
Ваша картинка — двухмерная, от неё у вас возникает иллюзия понимания.
На самом деле я смотрю на фазовое состояние сети, как описал в своей статье, упоминавшейся выше, оно на 2d только проецируется. И даёт очень неплохое представление о ландшафте. Там видно, что ландшафт на реальных задачах гораздо чаще похож на ту двумерную картинку с большим количеством неглубоких и непрямых оврагов с довольно крутыми стенами связывающих области локальных минимумов, расположенных друг от друга на характерных расстояниях заметно больших, чем размеры самих скоплений минимумов. То есть мы имеем дело скорее с лабиринтом, чем с системой, где есть большой хороший минимум к которому мы идём по области всё более частых локальных минимумов.
«Локальные минимумы» в сильно-многомерном ландшафте возникают около глобальных минимумовА вот далеко не всегда. У вам может быть в одной части пространства огромная трещётка из локальных минимумов с высотой 0.45, а гораздо более серьёзный минимум дающий в ошибку в 0,2 находится далеко от этого места, и рядом с ним локальных минимумов сильно меньше. Такая картинка у меня в третей птице, например. Такое очень часто возникает когда какой-то один нейрон из первого слоя обучается какому-нибудь хорошему полезному преобразованию координат. Вокруг такого состояния сети отдельных пиков мало, потому что его преобразование легко сломать, а искания соседей влияют на результат несопоставимо слабее чем он. Напротив ситуация, когда локальных минимумов много и они близко к глобальному — типична для неглубоких сетей, для которых роль одиночного нейрона не может быть велика.
Алгоритмы Dropout, RMSProp гляну, сходу не прокомментирую, но я боле чем уверен, то что начальная оптимизация решает дело даже не на четверть. Например посмотрите на вот такое видео обучения: www.youtube.com/watch?v=09wHERJnnEA, вы увидите, что изучать строение второго крыла (ближе к концу видео) сеть начала только после того, как освоила форму первого. Чтобы конечное состояние сети из этого примера стало доступно по схеме «предобучение плюс тонкая подстройка» нужно было бы, чтобы предобучение успешно научило сеть рисовать тушку и первое крыло. Сдаётся мне, что алгоритмы предобучения такого не умеют.
Обучение без учителя я, впрочем, пока, ещё только начал изучать, так что возможно вы в чём-то абсолютно правы.
Такая картинка у меня в третей птице, например
Извините, ещё раз напомню: у вас, кажется, 50 нейронов в птице. Это ближе к одномерному и двумерному случаю, чем к 500-мерному пространству.
Представьте, что у вас всего 50 понятий(нейронов), и вам нужно ими описать любую точку на птице. Много вы сможете описать? Безусловно, в такой ситуации всё зависит от особенностей функции ошибок и её гладкости.
Но дело в том, что если у вас 50 нейронов, проще решить задачу аналитически, чем напрягать компьютер.
А вот 10 миллионов нейронов и 1 миллиард связей — более типично для существующих практически полезных систем, нежели ваши 50 нейронов.
Чем многомернее ландшафт тем больше шансов что путь существует.
Можно считать, что пути до цели нет никогда — просто данные не идеальны и противоречивы в мелочах (обращать ли внимание на желто-коричневый цвет льва — и тогда лев похож на пчелу — или на зубы — и тогда не похож?).
Но в многомерном случае вы приблизитесь к цели гораздо ближе, прежде чем эта противоречивость отдельных примеров начнёт существено влиять.
Обучение без учителя я, впрочем, пока, ещё только начал изучать, так что возможно вы в чём-то абсолютно правы.
Я вам ещё рекомендую ознакомиться с методом переноса знаний от одной (большей) сети к другой (меньшей) — мне кажется, данный способ даст больше результатов, чем обучение непосредственно маленькой сети.
Во всяком случае, применение этого метода для работы с изображениями даёт всего небольшое (несколько процентов) ухудшение качества при переносе в десятки и сотни раз меньшую сеть, на десятки процентов превышая результаты обучения маленькой сети «с нуля».
Я думаю, это одновременно соответствует передаче символьного «дистиллированного знания» между людьми, и процессу стирания запомненных деталей в мозгу во время сна (стирается до 99% полученной информации — можно считать это своеобразным «сжатием»).
Ключевая работа в данной области — Dark Knowledge by Geoff Hinton, www.ttic.edu/dl/dark14.pdf
Извините, ещё раз напомню: у вас, кажется, 50 нейронов в птице. Это ближе к одномерному и двумерному случаю, чем к 500-мерному пространству.
Представьте, что у вас всего 50 понятий(нейронов), и вам нужно ими описать любую точку на птице. Много вы сможете описать? Безусловно, в такой ситуации всё зависит от особенностей функции ошибок и её гладкости.
Но дело в том, что если у вас 50 нейронов, проще решить задачу аналитически, чем напрягать компьютер.
А вот 10 миллионов нейронов и 1 миллиард связей — более типично для существующих практически полезных систем, нежели ваши 50 нейронов.
Чем многомернее ландшафт тем больше шансов что путь существует.
Можно считать, что пути до цели нет никогда — просто данные не идеальны и противоречивы в мелочах (обращать ли внимание на желто-коричневый цвет льва — и тогда лев похож на пчелу — или на зубы — и тогда не похож?).
Но в многомерном случае вы приблизитесь к цели гораздо ближе, прежде чем эта противоречивость отдельных примеров начнёт существено влиять.
Обучение без учителя я, впрочем, пока, ещё только начал изучать, так что возможно вы в чём-то абсолютно правы.
Я вам ещё рекомендую ознакомиться с методом переноса знаний от одной (большей) сети к другой (меньшей) — мне кажется, данный способ даст больше результатов, чем обучение непосредственно маленькой сети.
Во всяком случае, применение этого метода для работы с изображениями даёт всего небольшое (несколько процентов) ухудшение качества при переносе в десятки и сотни раз меньшую сеть, на десятки процентов превышая результаты обучения маленькой сети «с нуля».
Я думаю, это одновременно соответствует передаче символьного «дистиллированного знания» между людьми, и процессу стирания запомненных деталей в мозгу во время сна (стирается до 99% полученной информации — можно считать это своеобразным «сжатием»).
Ключевая работа в данной области — Dark Knowledge by Geoff Hinton, www.ttic.edu/dl/dark14.pdf
Но в многомерном случае вы приблизитесь к цели гораздо ближе, прежде чем эта противоречивость отдельных примеров начнёт существено влиять.
Кстати теорема Ковера, 1965 год:
A complex pattern-classification problem, cast in a high-dimensional space nonlinearly, is more likely to be linearly separable than in a low-dimensional space, provided that the space is not densely populated.
У Хайкина в книге приведено доказательство, а так же формула, на сколько вероятнее будет линейная разделимость в пространстве высокой размерности n, по сравнению с пространством размерности m, где n > m.
Строго говоря у меня пространство чуть больше чем 460-мерное, по количеству синапсов. А 50 нейронов это не пятьдесят понятий. При применении эффективных алгоритмов — больше. Но в остальном вы, конечно, правы.
С нетерпением жду когда появится время обучить что-нибудь большое на каких нибудь типовых общеизвестных данных. А то мне часто поминают, что я работаю с малюсенькими сетями, а мне и возразить то толком нечего. К сожалению, не раньше чем через пару месяцев.
С нетерпением жду когда появится время обучить что-нибудь большое на каких нибудь типовых общеизвестных данных. А то мне часто поминают, что я работаю с малюсенькими сетями, а мне и возразить то толком нечего. К сожалению, не раньше чем через пару месяцев.
Вспомнил, что такое Дропаут. Ну да, в частности.
Не успел до конца отредактировать.
уже возникнет ситуация, когда глобальный минимум из выбранного начала простым спуском может быть вообще недостижим.
уже возникнет ситуация, когда глобальный минимум из выбранного начала простым спуском может быть вообще недостижим.
упд: промазал веткой
Спасибо за статью.
Но собственно вопрос в том, получилось ли обученную VGG использовать для улучшения результатов в другой задаче?
Или может при её подключении результаты неожиданно ухудшились.
Например это может произойти из-за того, что датасет ImageNet существенно не похож на датасет новой задачи. А VGG натренировала внутри себя какие-нибудь шумящие признаки, которые будут мешать, а не помогать новой нейронной сети.
Но собственно вопрос в том, получилось ли обученную VGG использовать для улучшения результатов в другой задаче?
Или может при её подключении результаты неожиданно ухудшились.
Например это может произойти из-за того, что датасет ImageNet существенно не похож на датасет новой задачи. А VGG натренировала внутри себя какие-нибудь шумящие признаки, которые будут мешать, а не помогать новой нейронной сети.
пока рано сравнивать тк нет реальной задачи, это все делается в рамках исследования; пробовали вставлять такие признаки, вместе с другими имеющимися, в классификатор, результат уже не хуже
в реальную задачу я попробую вставить не те признаки что вернула VGG, а результат сжимания этого вектора многотысячной размерности в вектор размерности 50-100 с помощью DBN
например на нашем датасете есть фичи которые на всех картинках нули, т.е. это значит, что в том датасете присутствовал какой то объект, которого в нашем нет, как раз все это ДБН должна и почистить
Но собственно вопрос в том, получилось ли обученную VGG использовать для улучшения результатов в другой задаче?
в реальную задачу я попробую вставить не те признаки что вернула VGG, а результат сжимания этого вектора многотысячной размерности в вектор размерности 50-100 с помощью DBN
например на нашем датасете есть фичи которые на всех картинках нули, т.е. это значит, что в том датасете присутствовал какой то объект, которого в нашем нет, как раз все это ДБН должна и почистить
> например на нашем датасете есть фичи которые на всех картинках нули, т.е. это значит, что в том датасете присутствовал какой то объект, которого в нашем нет, как раз все это ДБН должна и почистить
Может случится так, что на всех картинках из нового датасета все старые фичи равны нулю и всё почистится.
А еще хуже — то, что останется, будет непонятно что, какой-то слабый шум, который больше вредит.
Например, если у нас 1000 объектов, то было бы неплохо разбить датасет по объектам 500 + 500 и посмотреть, как обученная VGG на первых 500 объектах (после сжатия до размерности 50-100 с помощью DBN) помогает улучшать классификацию других 500 объектов (считаем это новым датасетом). Будут ли там фичи, которые выдержат чистку и будут ли эти фичи вредить или улучшать.
Может случится так, что на всех картинках из нового датасета все старые фичи равны нулю и всё почистится.
А еще хуже — то, что останется, будет непонятно что, какой-то слабый шум, который больше вредит.
Например, если у нас 1000 объектов, то было бы неплохо разбить датасет по объектам 500 + 500 и посмотреть, как обученная VGG на первых 500 объектах (после сжатия до размерности 50-100 с помощью DBN) помогает улучшать классификацию других 500 объектов (считаем это новым датасетом). Будут ли там фичи, которые выдержат чистку и будут ли эти фичи вредить или улучшать.
ну так для этого и проводится приведенный эксперимент с поиском, я беру готовую VGG, которая никогда не видела мой датасет и вычисляю признаки, бинаризирую для простоты по порогу 0.95, и затем выбираю рандомную картинку, и ищу для нее близжайших соседей, в смысле расстояния Хэмминга
затем сморю на результат, и вижу что результат поиска не просто шум, а реально что то осмысленное, это дает основания для продолжения эксперимента — подать извлеченные признаки в ДБН и обучить ее, но уже на своих картинках
тут уже не будет никаких оценок на глаз, а четкая функция стоимости
затем сморю на результат, и вижу что результат поиска не просто шум, а реально что то осмысленное, это дает основания для продолжения эксперимента — подать извлеченные признаки в ДБН и обучить ее, но уже на своих картинках
тут уже не будет никаких оценок на глаз, а четкая функция стоимости
Caffe комманда прикольные, интересно, а что если брать не DAG архитектуру, а, наоборот, петель обратно на уровень выше навешать.
Оказывается это еще domain adaptation называется.
sites.skoltech.ru/compvision/projects/grl
sites.skoltech.ru/compvision/projects/grl
Sign up to leave a comment.
Нейропластичность в искусственных нейронных сетях