Comments 22
Зачем вам промисы, если есть атомы? http://habrahabr.ru/post/235121/
Эээ, даже не знаю как ответить, но никаких «атомов» нет в браузере, а вот «Обещания» есть. Во вторых, я так и не понял, как они решаю те задачи, для которых предназначены «Обещания»?
Обещания есть только в некоторых браузерах. И то появились они там лишь потому, что повсеместно используются. Если все начнут пользоваться атомами, то и они появятся в браузерах. Другое дело, что я не представляю как бороться против хайпа вокруг обещаний, заниматься отладкой кода на которых — то ещё удовольствие. В то время как есть более debug-friendly подход — fibers, но они есть только на ноде и то в виде стороннего расширения.
Атомы — обобщение над обещаниями. Или, вернее сказать, обещания — это одноразовые атомы. При этом атомы позволяют писать код в стиле fibers (с инкапсулированной асинхронностью), даже без этих самых fibers. Собственно атом можно использовать и как promise (then,catch) и как eventEmitter (on), но это скорее для совместимости, ибо куда практичней использовать их как frp-переменные (get,set), которые сами умеют вычислять своё состояние (в том числе и асинхронно), поддерживать его актуальность и освобождать память, когда в них больше нет необходимости.
Простой пример: http://jsfiddle.net/aro1fc8n/4/
Атомы — обобщение над обещаниями. Или, вернее сказать, обещания — это одноразовые атомы. При этом атомы позволяют писать код в стиле fibers (с инкапсулированной асинхронностью), даже без этих самых fibers. Собственно атом можно использовать и как promise (then,catch) и как eventEmitter (on), но это скорее для совместимости, ибо куда практичней использовать их как frp-переменные (get,set), которые сами умеют вычислять своё состояние (в том числе и асинхронно), поддерживать его актуальность и освобождать память, когда в них больше нет необходимости.
Простой пример: http://jsfiddle.net/aro1fc8n/4/
Простите, но мне вы путаете теплое с мягким, даже не буду говорить, что издревле есть соответствующий паттерн программирования, но да ладно. Допустим, на минутку, что я согласен с вами и «атомы» лучше, тогда покажите, как мне решить следующий пример на атомах:
По поводу примера. Ваш подход очень напоминает FRP, но лично для меня, выглядит очень перегруженным. На том же RxJS/BaconJS задача будет решаться проще, а главное понятнее для человека со стороны, который ничего не слышал о подобном подходе, а это немаловажно.
fetch("/path/to")
.then(response => response.json())
.then(json => processingServerData, parseErrorToLog)
.catch(processingErrorToLog)
;
По поводу примера. Ваш подход очень напоминает FRP, но лично для меня, выглядит очень перегруженным. На том же RxJS/BaconJS задача будет решаться проще, а главное понятнее для человека со стороны, который ничего не слышал о подобном подходе, а это немаловажно.
О каком паттерне идёт речь?
Примерно так:
var processedData = new $jin.atom.prop({ pull: prev => {
var data = resource.json( '/path/to' ).get()
// собственно процессим
return data
}})
И далее, где потребуется:
processedData.get()
А если не потребуется, то и запроса не будет. При этом неперехваченные ошибки будут залогированы автоматом.
У меня встречный вопрос — легко ли вам будет реализовать параллельную подгрузку двух файлов и третьего, если включена соответствующая опция конфига, а если выключена, то при включении, чтобы подгрузились лишь недостающие данные? На атомах можно не задумываясь:
var mapInfo = new $jin.atom.prop({ pull: prev => {
var [ svg, regions, stat ] = $jin.atom.get([
resource.xml( 'map.svg' ),
resource.json( 'regions.json' ),
config.isStatsShowing().get()? resource.csv( 'stats.csv' ): null
])
// работаем с полученными данными
}})
И это frp и есть, а вот подход Rx/Bacon — совсем не frp. Подробности в продолжении: http://habrahabr.ru/post/240773/
Примерно так:
var processedData = new $jin.atom.prop({ pull: prev => {
var data = resource.json( '/path/to' ).get()
// собственно процессим
return data
}})
И далее, где потребуется:
processedData.get()
А если не потребуется, то и запроса не будет. При этом неперехваченные ошибки будут залогированы автоматом.
У меня встречный вопрос — легко ли вам будет реализовать параллельную подгрузку двух файлов и третьего, если включена соответствующая опция конфига, а если выключена, то при включении, чтобы подгрузились лишь недостающие данные? На атомах можно не задумываясь:
var mapInfo = new $jin.atom.prop({ pull: prev => {
var [ svg, regions, stat ] = $jin.atom.get([
resource.xml( 'map.svg' ),
resource.json( 'regions.json' ),
config.isStatsShowing().get()? resource.csv( 'stats.csv' ): null
])
// работаем с полученными данными
}})
И это frp и есть, а вот подход Rx/Bacon — совсем не frp. Подробности в продолжении: http://habrahabr.ru/post/240773/
Эээ, вот:
и задумываться не пришлось, а ведь всё это только на native api, который будет понятен каждому разработчику.
За статью спасибо, добротно написано. Но всё равно не понимаю, зачем из простого делать сложное, т.е. идея мне понятна, я вижу где её можно было бы применить, но в итоге и в тех местах всё решается через банальную подписку на события. Ну и отладка такого приложения будет то ещё веселей, хотя и с Обещаниями не всё так радужно, как хотелось бы, но всё же браузер меня предупредит о непойманном catch.
В моем понимании, технология/подход должны делать разработку проще, код легко читаемым и интуитивно понятным. Но смотря на подобные примеры, из серии «вывести координаты», я не понимаю зачем мне это, какую задачу пытался решить автор.
Я понимаю, мне хотят показать что-то большее, но увы, вижу только переусложнение.
Promise.all([
fetch('map.svg').then(toXML)
fetch('regions.json').then(toJSON),
config.isStatsShowing() ? fetch('stats.csv').then(toCSV) : null
]).then([svg, json, cvs] => {
// готово
});
и задумываться не пришлось, а ведь всё это только на native api, который будет понятен каждому разработчику.
За статью спасибо, добротно написано. Но всё равно не понимаю, зачем из простого делать сложное, т.е. идея мне понятна, я вижу где её можно было бы применить, но в итоге и в тех местах всё решается через банальную подписку на события. Ну и отладка такого приложения будет то ещё веселей, хотя и с Обещаниями не всё так радужно, как хотелось бы, но всё же браузер меня предупредит о непойманном catch.
В моем понимании, технология/подход должны делать разработку проще, код легко читаемым и интуитивно понятным. Но смотря на подобные примеры, из серии «вывести координаты», я не понимаю зачем мне это, какую задачу пытался решить автор.
Я понимаю, мне хотят показать что-то большее, но увы, вижу только переусложнение.
Ваш код работает неправильно:
1. конфиг — это свойство пользователя, хранится в профиле, его тоже нужно асинхронно подгрузить (как нужно изменить код, чтобы добавить тут асинхронность? в случае атомов код использования конфига не поменяется), причём так как меняется он редко, то имеет смысл брать его из localStorage и в фоне подгрузив новую версию налету обновить приложение (с атомами опять же этот код не поменяется — изменится лишь реализация isStatsShowing)
2. когда конфиг изменится этот код у вас не будет перезапущен
3. даже если будете кидать событие и по нему перезапускать все такие цепочки, которые зависят от конфига, то у вас всё равно будет 3 запроса, вместо одного и скорее всего обновление состояния половины приложения
В том-то и дело, что атомы инкапсулируют сложность событийной системы в простой абстракции — реактивный контейнер с формулой вычисления значения. Достаточно в ней разобраться (а она весьма не сложная) и можно строить приложения любой сложности без экспоненциального увеличения багоёмкости (как из кубиков лего). Да, на простых примерах атомы не нужны. Об этом собственно и первая статья — по мере взросления приложения оно обрастает грудой костылей. Появляется необходимость кэшировать, вручную следить за необходимыми подписками, бороться с утечками, обновлять только то, что реально могло поменяться (и речь тут не только про дом).
Я могу и более реальный пример привести, с выделением абстрактных компонент, точечным изменением дома, автоматическими анимациями, лёгкой адаптацией под новые требования: https://github.com/nin-jin/pms-jin2/tree/master/demo/list
Но его же фиг поймёшь, не разобравшись в основах на простом примере.
1. конфиг — это свойство пользователя, хранится в профиле, его тоже нужно асинхронно подгрузить (как нужно изменить код, чтобы добавить тут асинхронность? в случае атомов код использования конфига не поменяется), причём так как меняется он редко, то имеет смысл брать его из localStorage и в фоне подгрузив новую версию налету обновить приложение (с атомами опять же этот код не поменяется — изменится лишь реализация isStatsShowing)
2. когда конфиг изменится этот код у вас не будет перезапущен
3. даже если будете кидать событие и по нему перезапускать все такие цепочки, которые зависят от конфига, то у вас всё равно будет 3 запроса, вместо одного и скорее всего обновление состояния половины приложения
В том-то и дело, что атомы инкапсулируют сложность событийной системы в простой абстракции — реактивный контейнер с формулой вычисления значения. Достаточно в ней разобраться (а она весьма не сложная) и можно строить приложения любой сложности без экспоненциального увеличения багоёмкости (как из кубиков лего). Да, на простых примерах атомы не нужны. Об этом собственно и первая статья — по мере взросления приложения оно обрастает грудой костылей. Появляется необходимость кэшировать, вручную следить за необходимыми подписками, бороться с утечками, обновлять только то, что реально могло поменяться (и речь тут не только про дом).
Я могу и более реальный пример привести, с выделением абстрактных компонент, точечным изменением дома, автоматическими анимациями, лёгкой адаптацией под новые требования: https://github.com/nin-jin/pms-jin2/tree/master/demo/list
Но его же фиг поймёшь, не разобравшись в основах на простом примере.
Эээ, так не пойдет, условие задачи я выполнил, но оказывается, они намного объемнее и ваш пример имеем очень высокий уровень абстракции. Давайте лучше вы сделаете реально пример этой задачи на jsbin.com (значение конфига можно меня по клику по кнопке), а я сделаю точно такой-же, но так, как делал бы его обычно. Мне так было бы намного проще понять ваш подход.
Ну так оно часто так и оказывается, что задача куда объёмнее, чем кажется на первый взгляд :-)
Ок, вот небольшой пример: http://jsfiddle.net/1y10hpgs/3/
При переключении настройки происходит либо догрузка недостающих данных, либо выгрузка ненужных.
Ок, вот небольшой пример: http://jsfiddle.net/1y10hpgs/3/
При переключении настройки происходит либо догрузка недостающих данных, либо выгрузка ненужных.
Будем честными, чаще это оговорено в условиях, что конкретное место должно реагировать на изменения, чаще такие места просто каскадно обновляют в зависимости от других факторов. Да, конечно, всегда можно разработать решение, которое будет всегда реагировать на все изменения, но нужно ли это? Возьмем пример из жизни: Ангуляр (да, я понимаю что это из другой области, но) по умолчанию реагировал на любые изменения, это стало его прорывом и проклятьем, очень быстро люди, а потом уже разработчики, поняли, что нужен контроль над этим механизмом и ввели одноразовые связки.
Реактивность выглядит очень круто и выводит разработку на новый уровень, но какой ценой? Оверхед космический.
По поводу примера. Подобная задача у нас решалась бы подобным образом (увы в действии могу только видео показать, т.к. это не open source). Я понимаю, что сейчас вы можете указать на различия и усложнить условия, но поверьте, всё нормально «ляжет», просто разные подходы, у нас этого продвинутые модели и коллекции.
У меня к вам ещё один вопрос, допустим есть список, который нужно перерисовывать только при добавлении и удалении элемента, если элемент изменился, то нужно обновить только связанный элемент. Как такая задача будет решаться при помощи атомов? Как я понимаю, родительский атом, который строит список по любому получит сигнал, что внутри кто-то обновился и цепочка таких нотификаций может быть очень длинной, что даст оверхед. Не думали что делать в таких ситуация?
Реактивность выглядит очень круто и выводит разработку на новый уровень, но какой ценой? Оверхед космический.
По поводу примера. Подобная задача у нас решалась бы подобным образом (увы в действии могу только видео показать, т.к. это не open source). Я понимаю, что сейчас вы можете указать на различия и усложнить условия, но поверьте, всё нормально «ляжет», просто разные подходы, у нас этого продвинутые модели и коллекции.
У меня к вам ещё один вопрос, допустим есть список, который нужно перерисовывать только при добавлении и удалении элемента, если элемент изменился, то нужно обновить только связанный элемент. Как такая задача будет решаться при помощи атомов? Как я понимаю, родительский атом, который строит список по любому получит сигнал, что внутри кто-то обновился и цепочка таких нотификаций может быть очень длинной, что даст оверхед. Не думали что делать в таких ситуация?
Нет, Ангуляр именно из этой области, просто в Ангуляре бестолковая реализация frp. Чтобы узнать изменилось ли что ангуляру приходится в цикле исполнять все вотчеры. Фактически это пересчёт всего состояния приложения. Из-за такой реализации приходится минимизировать число вотчеров (в частности используя одноразовые биндинги) и максимально локализовывать обновления (например, не вызывать $timeout, а вручную дёргать те скоупы изменения в которых ожидаются). С атомами такой проблемы нет — они максимально эффективно уведомляют друг друга об изменениях, так что спящие атомы кушать не просят (но создание их большого числа не бесплатно, так что и увлекаться ими не стоит, например, разумно выделять на один дом узел не более 1-2 атомов).
Что-то я не смог разобраться в вашем интуитивно понятном коде, тупой я наверное :-)
Обсуждали обещания, стримы, а в коде ни того, ни другого.
Да и функционал не повторили (нет загрузки настроек, нет очистки памяти).
Ещё и программный код в шаблонах, фу-фу-фу :-)
Нет, атом, хранящий список, ничего не знает про состояние элементов списка, если, конечно, сам список не зависит от их состояния. Например, если у нас есть список задач (tasks) и есть список задач отсортированный по названию (sortedTasks), то второй список зависит как от исходного списка задач (tasks) так и от имён (task.name) входящих в него задач, но не зависит от имён задач в список (tasks) не входящий и не зависит от времени создания (task.created) задач. Но стоит включить сортировку по времени создания, как зависимости обновятся и отсортированный список (sortedTasks) будет уже зависеть от исходного списка задач (tasks) и их времени создания (task.created), но не от имён (task.name). При этом сам исходный список (tasks) может зависеть, например, от вебсокет канала «tasks/creator=me» и совершенно не зависеть от состояния самих задач.
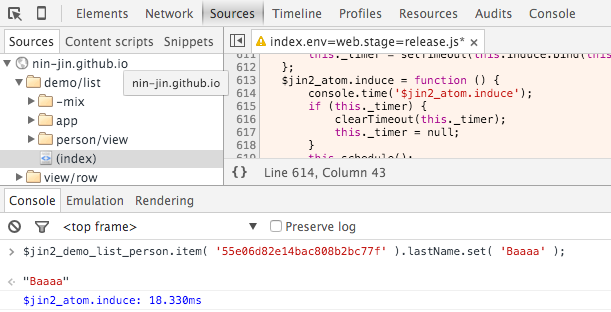
Если открыть пример: http://nin-jin.github.io/demo/list/
Включить логирование: $jin2_log_filter=/./
И, например, поскроллить правый список, то можно заметить, что пересчёт идёт по кратчайшему пути:
$jin2_demo_list_app.widget_all.widgetByLetter_.scrollTop_ 40 — изменилась позиция скроллинга
$jin2_demo_list_app.widget_all.widgetByLetter_.rowGroup_A.offsetTopView_ 40 — изменилась позиция плашки группы «А»
$jin2_demo_list_app.widget_all.widgetByLetter_.rowGroup_A.version_ 1 — обновилось состояние дом-узла плашки группы «А»
Что-то я не смог разобраться в вашем интуитивно понятном коде, тупой я наверное :-)
Обсуждали обещания, стримы, а в коде ни того, ни другого.
Да и функционал не повторили (нет загрузки настроек, нет очистки памяти).
Ещё и программный код в шаблонах, фу-фу-фу :-)
Нет, атом, хранящий список, ничего не знает про состояние элементов списка, если, конечно, сам список не зависит от их состояния. Например, если у нас есть список задач (tasks) и есть список задач отсортированный по названию (sortedTasks), то второй список зависит как от исходного списка задач (tasks) так и от имён (task.name) входящих в него задач, но не зависит от имён задач в список (tasks) не входящий и не зависит от времени создания (task.created) задач. Но стоит включить сортировку по времени создания, как зависимости обновятся и отсортированный список (sortedTasks) будет уже зависеть от исходного списка задач (tasks) и их времени создания (task.created), но не от имён (task.name). При этом сам исходный список (tasks) может зависеть, например, от вебсокет канала «tasks/creator=me» и совершенно не зависеть от состояния самих задач.
Если открыть пример: http://nin-jin.github.io/demo/list/
Включить логирование: $jin2_log_filter=/./
И, например, поскроллить правый список, то можно заметить, что пересчёт идёт по кратчайшему пути:
$jin2_demo_list_app.widget_all.widgetByLetter_.scrollTop_ 40 — изменилась позиция скроллинга
$jin2_demo_list_app.widget_all.widgetByLetter_.rowGroup_A.offsetTopView_ 40 — изменилась позиция плашки группы «А»
$jin2_demo_list_app.widget_all.widgetByLetter_.rowGroup_A.version_ 1 — обновилось состояние дом-узла плашки группы «А»
Путь то может и кратчайший, а вот числа говорят сами за себя: dl.dropboxusercontent.com/s/snwhpszlck3sxel/Screenshot%202015-11-29%2020.07.37.png?dl=0
И это с учетом, что вас там используются спец. абстракции над элементами, списком, строкой и т.д. Не скажу, что это уже слишком большие числа, ожидал более существенной просадки. Но, если учесть кол-во кода, который это всё обслуживает и использование специализированных компонентов под задачу, все это как-то не радужно выглядит. Это всё напоминает путь ExtJS и подобных, у него есть свои плюсы и минусы, но в массы его не вывести.
Но спасибо за ликбез.
P.S. О, ещё один маленький вопрос, при разработке атомов вы пытались найти что-то подобное? Какие ещё есть решения? По ключевым словам frp только Bacon, Rx, Kefir и т.п., а вот подобного нет (максимум видел статью, которая в общих чертах описывала реализацию в Метеор).
{kind=link}
И это с учетом, что вас там используются спец. абстракции над элементами, списком, строкой и т.д. Не скажу, что это уже слишком большие числа, ожидал более существенной просадки. Но, если учесть кол-во кода, который это всё обслуживает и использование специализированных компонентов под задачу, все это как-то не радужно выглядит. Это всё напоминает путь ExtJS и подобных, у него есть свои плюсы и минусы, но в массы его не вывести.
Но спасибо за ликбез.
P.S. О, ещё один маленький вопрос, при разработке атомов вы пытались найти что-то подобное? Какие ещё есть решения? По ключевым словам frp только Bacon, Rx, Kefir и т.п., а вот подобного нет (максимум видел статью, которая в общих чертах описывала реализацию в Метеор).
В данном случае путь не кратчайший. Если включить логи, то можно заметить, что происходит пересчёт всех списков. Чтобы этого не происходило, нужно использовать для списков специальные атомы (о которых во второй статье в конце).
Там используется наследование компонент, чтобы продемонстрировать расширяемость — можно взять готовую компоненту и изменить любой аспект её поведения. Конечно можно было бы и вообще всё приложение в одну компоненту засунуть в «лучших» традициях ангуляра :-)
KnockoutJS — ближайший аналог атомов, только с крайне неэффективным распространением изменений и без поддержки прототипного наследования, обещаний, автоуничтожения и пр.
Там используется наследование компонент, чтобы продемонстрировать расширяемость — можно взять готовую компоненту и изменить любой аспект её поведения. Конечно можно было бы и вообще всё приложение в одну компоненту засунуть в «лучших» традициях ангуляра :-)
KnockoutJS — ближайший аналог атомов, только с крайне неэффективным распространением изменений и без поддержки прототипного наследования, обещаний, автоуничтожения и пр.
А я вот одного не пойму, откуда в атомах буква F? Сколько не смотрел нигде этой буквы не увидел. Для многих она значит — отсутствие сайд-эффектов, во время вызова функций, но ведь атомы это и есть один большой сайд-эффект, разве нет?
Плюс запись
$jin2_demo_list_app.widget_all.widgetByLetter_.rowGroup_A.version_ 1
Явный признак нарушения закона деметры.
Плюс запись
$jin2_demo_list_app.widget_all.widgetByLetter_.rowGroup_A.version_ 1
Явный признак нарушения закона деметры.
Атомы инкапсулируют в себе сайд эффекты. Ну, на сколько это возможно в императивном языке. Можно считать их монадами :-)
Не нарушает, компонента $jin2_demo_list_app владеет компонентой widget_all, которая владеет компонентой widgetByLetter_, которая владеет компонентой rowGroup_A, которая владеет атомом version_. При этом путь до объекта собирается путём склеивания идентификатора объекта и пути до властвующего над ним объекта. Это очень удобно иметь в идентификаторах элементов, логах и множествах такие пути :-)
https://habrastorage.org/files/2c6/8f4/252/2c68f4252fc84433bd1214bad03bb550.png
Не нарушает, компонента $jin2_demo_list_app владеет компонентой widget_all, которая владеет компонентой widgetByLetter_, которая владеет компонентой rowGroup_A, которая владеет атомом version_. При этом путь до объекта собирается путём склеивания идентификатора объекта и пути до властвующего над ним объекта. Это очень удобно иметь в идентификаторах элементов, логах и множествах такие пути :-)
https://habrastorage.org/files/2c6/8f4/252/2c68f4252fc84433bd1214bad03bb550.png
Дошли руки починить пример.
Теперь, используются специальные атомы для списков, так что теперь пути действительно кратчайшие: https://gist.github.com/nin-jin/33f744f60a5da7c10151
Реализовывать эту логику руками, без реактивного программирования — проще застрелиться.
Теперь, используются специальные атомы для списков, так что теперь пути действительно кратчайшие: https://gist.github.com/nin-jin/33f744f60a5da7c10151
Реализовывать эту логику руками, без реактивного программирования — проще застрелиться.
Не смотрели в сторону dojo + dstore + dmodel? У них на первый взгляд все почти есть, а если нету то допиливается.
Смотрел, не скажу, что внимательно, но видел. Всё же для нас самое близко был CanJS, но он очень тормозной оказался, ну и опять же Dojo. А как там с целостностью, особенно для коллекций? Ну и основная задача была объединить и интегрировать общую бизнес логику и кодовую часть «малой кровью».
Там есть персистентность и подписка на обновления модели. Правда мы не используем этот функционал.
Да, вчера посмотрел реализацию заметил это. Но если объективно сравнивать с нашими моделями, DModel отстает по функциональности, притом ещё критичной для нас, ну и сама реализация не шибко шустрая, а для нас это было очень важно, нам приходится работать с коллекциями до десятков тысяч моделей. Вот актуальные бенчмарки на сегодня: модель, коллекция.
{kind=link}
{kind=link}
Мне кажется, Вы rxjs переизобрели.
А почему, кстати, фреймворк не в open-source?
А почему, кстати, фреймворк не в open-source?
Не, с RxJS у нас ничего общего, хотя есть ветка по интеграции, только не с ним, а с Beacon, но пока так и осталось веткой.
Не опенсорнсим, потому что задача была объединить кодовую базу, создать SDK с общими сущностями, которые можно шарить между проектами. Так что опенсорсить практически нечего, разве только Emitter, request, Model и Model.List, но подобных решений и так полно (Bacnbone, CanJS и д.р.), а та специфика, которая заложена в наши, будет не нужна для 90% разработчиков.
Не опенсорнсим, потому что задача была объединить кодовую базу, создать SDK с общими сущностями, которые можно шарить между проектами. Так что опенсорсить практически нечего, разве только Emitter, request, Model и Model.List, но подобных решений и так полно (Bacnbone, CanJS и д.р.), а та специфика, которая заложена в наши, будет не нужна для 90% разработчиков.
Sign up to leave a comment.
Разработка собственного решения: риски и ответственность