Comments 9
У меня вопрос по последнему пункту — Inference.
Во-первых, я понимаю и разделяю вашу боль с конвертацией pytorch (и аналогично MXNet) в ONNX и потом в TensorRT или ещё куда-то. Почти для каждой архитектуры сети это челенж ). И усложняет это крайне редкие обновления TensorRT.
Но вопрос в другом. Из того что вы описали, я понял что в проде вы запускаете модельки на С++? Сам я поддерживаю такой подход, но в настоящие время куча отечественных (довольно известных) и зарубежных компаний используют в проде питон код. Т.е. поднимаются докеры с питоном и там крутится инференс. И мол питон это всего лишь оркестрация, а код всёравно на куде исполняется. И вот собственно вопрос — как вы относитесь к такому подходу (питон в проде), и почему всё таки запускаете модели в проде на С++?
Во-первых, я понимаю и разделяю вашу боль с конвертацией pytorch (и аналогично MXNet) в ONNX и потом в TensorRT или ещё куда-то. Почти для каждой архитектуры сети это челенж ). И усложняет это крайне редкие обновления TensorRT.
Но вопрос в другом. Из того что вы описали, я понял что в проде вы запускаете модельки на С++? Сам я поддерживаю такой подход, но в настоящие время куча отечественных (довольно известных) и зарубежных компаний используют в проде питон код. Т.е. поднимаются докеры с питоном и там крутится инференс. И мол питон это всего лишь оркестрация, а код всёравно на куде исполняется. И вот собственно вопрос — как вы относитесь к такому подходу (питон в проде), и почему всё таки запускаете модели в проде на С++?
Смотри, есть два случая высоконагруженные сервисы и нет.
Для высоконагруженных надо оптимизировать все что можно. В частности
1) есть не только операции на GPU есть рисайзы, пре-процессинг, пост-процессинг. Все эти операции разумеется будут быстрее на С++, чем на питоне. Их не унести все на GPU и они бывают бутылочным горлышком
2) Плюс на высоких нагрузках питон не выдаст тебе столько запросов в секунду. У нас много бекендов на питоне, и в итоге из-за производительности мы их переписываем либо на Go, либо на C++.
Для низконагруженных — подход с докерами и питоном хорош, и мы используем его для экспериментов и не нагруженных моделей. Например, 9may.mail.ru сделан на питоне, но там нагрузки не 5000 запросов/с, как на моделей для Облака@. Для ускорения экспериментов планируем развивать этот подход с KubeFlow
Для высоконагруженных надо оптимизировать все что можно. В частности
1) есть не только операции на GPU есть рисайзы, пре-процессинг, пост-процессинг. Все эти операции разумеется будут быстрее на С++, чем на питоне. Их не унести все на GPU и они бывают бутылочным горлышком
2) Плюс на высоких нагрузках питон не выдаст тебе столько запросов в секунду. У нас много бекендов на питоне, и в итоге из-за производительности мы их переписываем либо на Go, либо на C++.
Для низконагруженных — подход с докерами и питоном хорош, и мы используем его для экспериментов и не нагруженных моделей. Например, 9may.mail.ru сделан на питоне, но там нагрузки не 5000 запросов/с, как на моделей для Облака@. Для ускорения экспериментов планируем развивать этот подход с KubeFlow
Спасибо за познавательную статью. Касательно кластеринга — два вопроса. Какова размерность изображения, позволяющая вам оперировать расстояниями, невзирая на проклятие размерности. Как известно в пространстве большой размерности максимальное расстояние стремится к минимальному. Второе. «Дальше мы выбираем самый большой кластер, предполагая, что аватарки пользователя в основном содержат именно его лицо». Вы смешиваете компакные данные об одном пользователе с шумом (непохожие лица) — зачем?
Свойство антимонотонности: если в подпространстве Sk кластера не существует, то
нет кластера ни в каких подпространствах высшей размерности, содержащих Sk.
Свойство антимонотонности: если в подпространстве Sk кластера не существует, то
нет кластера ни в каких подпространствах высшей размерности, содержащих Sk.
Хай.
1) Размерность обычно 128 или 512, это не так много, проблем не возникало
2) Не понял почему смешиваем. Мы просто кластеризуем с ужесточенным порогом (относительно обычного при принятии решения «один человек на этих двух фотках или нет»), чтобы кластер с большой вероятностью был не фолзовый. Поэтому мы наоборот откидываем шум, но также и реальные фотки пользователя, которые по мере улучшения модели перестанут откидываться.
1) Размерность обычно 128 или 512, это не так много, проблем не возникало
2) Не понял почему смешиваем. Мы просто кластеризуем с ужесточенным порогом (относительно обычного при принятии решения «один человек на этих двух фотках или нет»), чтобы кластер с большой вероятностью был не фолзовый. Поэтому мы наоборот откидываем шум, но также и реальные фотки пользователя, которые по мере улучшения модели перестанут откидываться.
Скажите, доводилось ли вам работать с OCR рукописного текста(HTR)? Не рукопечатного, а именно рукописного, в свободной или табличной форме?
Были ли задачи сегментации такого текста — блоков, слов или букв?
Были ли задачи сегментации такого текста — блоков, слов или букв?
Спасибо, Эдуард, за интересную статью.
Хочется уточнить, однако:
1. По поводу идеи Center Loss- не очень понятна оригинальность идеи, задача классификации в том и заключается, чтобы расфасовать образцы по кластерам, которые легко разрешимы. И если мы можем их «стянуть к центрам кластеров», то задача уже решена.
2. ArcFace- мы добавляем что-то в аргумент косинуса, чтобы при обучении искусственно увеличить расстояние между groundtruth и результатом опознавания. Это похоже на регуляризацию, мне кажется… А нет ли опасности, что задавая m, мы придём, наоборот, к уменьшению расстояния, ведь косинус- периодическая функция?
Хочется уточнить, однако:
1. По поводу идеи Center Loss- не очень понятна оригинальность идеи, задача классификации в том и заключается, чтобы расфасовать образцы по кластерам, которые легко разрешимы. И если мы можем их «стянуть к центрам кластеров», то задача уже решена.
2. ArcFace- мы добавляем что-то в аргумент косинуса, чтобы при обучении искусственно увеличить расстояние между groundtruth и результатом опознавания. Это похоже на регуляризацию, мне кажется… А нет ли опасности, что задавая m, мы придём, наоборот, к уменьшению расстояния, ведь косинус- периодическая функция?
1. Если использовать softmax + crossentropy, то это обеспечивает нам только лишь разделимость пространства, нет никакого сигнала для «сжимания кластера». Можно глянуть как это выглядит с и без center loss в оригинальной статье 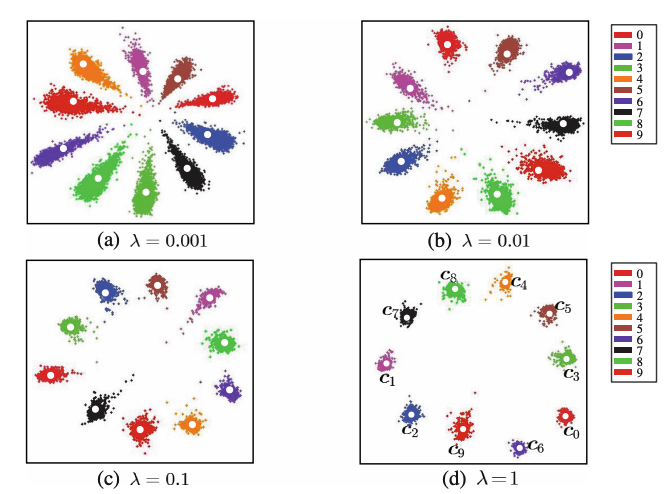
Почему это важно? а) мы фитимся на данные, на тесте/проде могут быть произвольные данные, и в таком случае чем компактнее наши классы в метрическом пространстве, тем меньше вероятность ошибки или пограничного случая на новых данных. б) на самом деле улучшается разделимость, т.к. граница прочищается
2) С косинусом есть проблема у оригинального SphereFace (AngularSoftmax), лосс которого модифицировали, чтобы он был монотонным, . И из-за перегибов куча проблем со сходимостью, с которыми надо бороться с помощью различных прогревов.
. И из-за перегибов куча проблем со сходимостью, с которыми надо бороться с помощью различных прогревов.
ArcFace этим не страдает, т.к. в рамках Пи косинус монотонный, а смещение лишь на пол радианы

Почему это важно? а) мы фитимся на данные, на тесте/проде могут быть произвольные данные, и в таком случае чем компактнее наши классы в метрическом пространстве, тем меньше вероятность ошибки или пограничного случая на новых данных. б) на самом деле улучшается разделимость, т.к. граница прочищается
2) С косинусом есть проблема у оригинального SphereFace (AngularSoftmax), лосс которого модифицировали, чтобы он был монотонным,
 . И из-за перегибов куча проблем со сходимостью, с которыми надо бороться с помощью различных прогревов.
. И из-за перегибов куча проблем со сходимостью, с которыми надо бороться с помощью различных прогревов. ArcFace этим не страдает, т.к. в рамках Пи косинус монотонный, а смещение лишь на пол радианы
На самом деле, обе сгенерированы. Если не присматриваться к мелким деталям, то отличия от реальности не заметить. Делаем мы это с помощью Blender (аналог 3dmax).
даже не особо приглядываясь сразу понял что обе картинки сгенерированные. Вы видимо либо не ходите в магизины, либо не можете адекватно оценить освещённость сцены. Сразу бросается в глаза слишком идеальная картинка, источников света очень мало, со всех сторон любой предмет одинаково освещён. такое освещение может быть только в студии, и то ещё постараться надо
Sign up to leave a comment.
Опыт моделеварения от команды Computer Vision Mail.ru