

Почти все любят Git. Я тоже. Он работает, он эффективен, в нём изумительная модель данных, и в нём есть все возможные инструменты. За 13 лет использования не было случая, чтобы я не находил в Git нужный мне инструмент. До недавнего времени. Но сначала давайте поговорим о GitHub.
Есть три группы пользователей GitHub, которые различаются по предпочитаемому способу внесения запросов на внесение изменений (pull request):
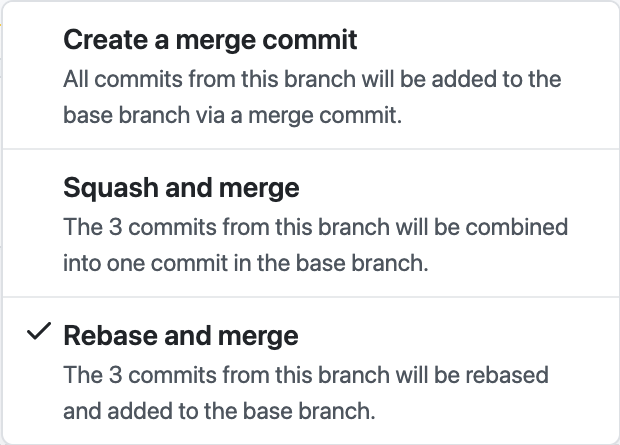
Merge-коммит, squash коммитов в один или rebase? На этот вопрос нет однозначного ответа. При выборе стратегии слияния приходится учитывать ряд факторов: тип и размер проекта, рабочий процесс и предпочтения команды, бизнес-условия и прочее. Возможно, у вас есть собственные предпочтения, если вы использовали GitHub для работы с командой.
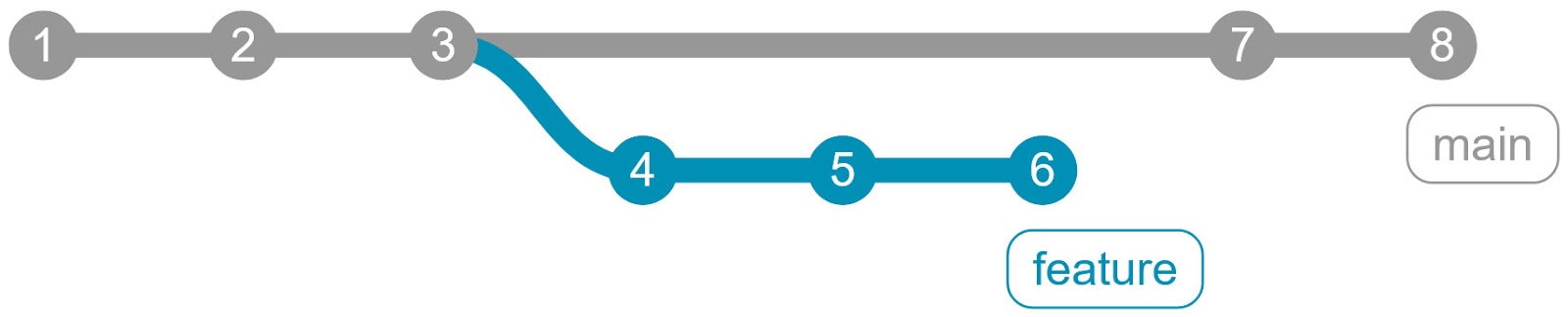
Мы немного поговорим о достоинствах и недостатках каждого подхода. Но сначала опишу исходные условия. Пусть у вашего проекта есть ветка main, от которой когда-то ответвилась ветка feature. C тех пор обе ветки развивались, сейчас feature уже проверена, протестирована и готова к слиянию с main:
Создаём merge-коммит
Merge-коммиты — это исходный способ объединения изменений в Git. У такого коммита две и более родительских веток, он собирает все изменения из них и их предшественников:

В этом примере Git создал новый коммит под номером 9, в котором объединились коммиты 6 и 8. На него теперь ссылается ветка main, в этом коммите содержатся все изменения из коммитов 1—8.
Merge-коммиты универсальны и хорошо масштабируются, особенно в случае со сложными рабочими процессами с многочисленными участниками, каждый из которых отвечает за свою часть кода. Например, такие коммиты повсеместно используют разработчики ядра Linux. Но для маленьких Agile-команд (особенно в контексте бизнеса) они избыточны и могут доставить неприятности. В подобных командах обычно используют одну вечную ветку, на основе которой создают эксплуатационные релизы и в которую добавляют изменения из временных веток. При такой организации работы трудно оценить развитие проекта. GitFlow, популярный инструмент для работы с Git, рекомендует везде использовать merge-коммиты, и люди с этим не согласны. Приведу визуальный аргумент из одной темы:

Отбросив факт, что эта история наполнена merge-коммитами, автор обращает наше внимание на то, что найти что-либо в таком запутанном графе практически невозможно. Правда это или нет, решайте сами, но доводы в пользу линейной истории изменений определённо есть.
Есть и другая, часто упускаемая из виду особенность. Взгляните ещё раз на схему с merge-коммитом под номером 9. Можете ли вы сказать, какой коммит был последним в ветке main до слияния? Конечно, это должен быть 8, потому что он изображён на серой линии, верно? Ага, на картинке это показано так. Но если вы взглянете на сам коммит, это будет вовсе не так очевидно. Вот что в нём говорится:
Merge: 8 6
Коммит сообщает, что эти две родительские ветки объединены, но здесь не сказано, какой коммит относится к ветке main. Вы можете предположить, что это 8, поскольку значение находится слева, но вы не можете быть уверены (ветки в Git — это лишь номера коммитов). Единственный (известный мне) способ удостовериться, это использовать reflog, но он не долговечен: Git время от времени удаляет из reflog старые записи. То есть вы не можете с уверенностью ответить на вопрос «какая фича была выпущена в заданный период времени?» или «каково было состояние main на указанную дату?» В том числе и поэтому вы не можете применить команду git revert к коммиту слияния, если не скажете Git'у, какие из родительских коммитов вы хотите сохранить, а какие отбросить.
Слияние без связи с источником
В случае с merge-коммитами мы не переписываем историю: сделанный коммит остаётся неизменным, репозиторий лишь разрастается. Другие два вида коммитов используют возможность Git переписывать историю. Как мы увидим ниже, суть у них та же, а отличаются эти коммиты только подробностью изменений.
Вернёмся к нашему примеру. В случае со слиянием без связи с источником (squash) мы объединяем изменения из коммитов 4, 5 и 6 в один коммит (S), а затем применяем его поверх main.

Ветка feature осталась, но я не показал её на иллюстрации, потому что он больше не релевантна и обычно удаляется при слиянии (что может быть не лучшим решением, как мы увидим ниже). У этого подхода много достоинств, и некоторые команды его популяризируют. Пожалуй, самым заметным и значительным достоинством является то, что история становится очень удобочитаемой. Она линейна, между коммитами в main и запросами на внесение изменений есть прямое соответствие (как и в случае с большинством фич и исправлений багов). Такая история очень помогает в управлении проектом: можно очень легко ответить на вопросы, на которые практически невозможно дать ответ в случае с merge-коммитами.
Накат изменений из одной ветки в другую
Этот подход аналогичен предыдущему, только мы не объединяем коммиты 4—6, а накатываем их прямо поверх main.

Но сначала длинное отступление. По скриншоту в начале статьи вы могли предположить, что я придерживаюсь этого подхода, и будете правы. Раньше я пользовался squash-коммитами, но перешёл на rebase после того как появилась фича, больше всего повлиявшая на качество моей работы за последние годы: я начал писать осмысленные коммит-сообщения.
Ещё недавно мои сообщения были однострочными, например, как в истории Skyscraper. Эти первые строки не сильно изменились, но теперь я стараюсь добавлять в них объяснения причин изменений. При исправлении бага объясняю, что его вызвало и как изменения исправили баг. При реализации фичи я подчёркиваю особенности реализации. Возможно, я не стал писать больше кода, но точно стал писать больше текста: я вполне могу написать два-три абзаца про какое нибудь изменение +1/−1. То есть теперь мои коммит-сообщения выглядят так (взял случайный недавний пример из репозитория приложения Fy!):
app/tests: allow to mock config
Tests expected the code-push events to fire, but now that I’ve
disabled CP in dev, and the tests are built with the dev aero profile,
they’d fail.
This could have been fixed by building them with AERO_PROFILE=staging
in CI, but it doesn’t feel right: I think tests shouldn’t depend on
varying configuration. If a test requires a given bit of configuration
to be present, it’s better to configure it that way explicitly.
Hence this commit. It adds a wrap-config mock and a corresponding
:extra-config fixture, which, when present (and it is by default),
will merge the value onto generated-config.
Я очень серьёзно отношусь к чистоте истории. Стараюсь делать каждый коммит маленьким (не больше +20/−20 строк) и вносить последовательное, логичное изменение. Конечно, не всегда так разрабатываю. Если применить
git log к моей рабочей ветке, то можно увидеть подобное:5d64b71 wip
392b1e0 wip
0a3ad89 more wip
3db02d3 wip
Но прежде чем объявлять pull request готовым к рецензированию, я удаляю эту историю (с помощью
git reset --mixed $(git merge-base feature main)) и заново коммичу изменения, делю их на логические блоки и пишу обоснования, бит за битом. В результате неукоснительного следования этой методике вы можете применять git annotate где угодно и понять, почему любая строка кода написана именно так.Я не могу передать словами, насколько велико влияние этой возможности на благополучие разработчика. Когда я спустя недели или месяцы читаю подобные сообщения в коммитах, работая над чем-то совсем другим, но связанным с этим кодом, то словно читаю маленькие любовные записки себе сегодняшнему от себя из прошлого. Эти комментарии снижают до нуля время поиска нужной информации.

Они также помогают и при проверке кода. В моих примечаниях к запросам на внесение изменений обычно написано: «пожалуйста, читайте каждый коммит отдельно». Я выяснил, что разобраться в pull request’e легче, если он рассказывает тебе какую-то историю, и каждый коммит — это новый указатель на твоём пути.
Заканчиваю своё отступление: теперь вы понимаете, почему вместо слияния без связи с источником (squash) я предпочитаю накат изменений из одной ветки в другую? Потому что несмотря на все преимущества, в первом случае безвозвратно теряется контекст.
И теперь вместо того, чтобы каждая строка вносила маленькое изменение, +20/−20, вы можете сказать лишь, что это часть набора подобных изменений. Возможно, десятка, или пятидесяти. Неизвестно. Конечно, можно посмотреть исходную ветку, но это уже перебор, и что если её вообще удалили? Так что да, повсеместное размещение этих любовных записок, каждая из которых тщательно написана и не привязана к другим, — это слишком большая удача, чтобы её упускать. Однако у накатки изменения из ветки в ветку есть и недостатки.
К примеру, тоже сложно сказать, сколько фич было разработано за определённый период времени. Более того, откатить их даже сложнее: обычно хочется действовать на уровне фич. При squash-коммитах для отката баговой фичи достаточно команды
git revert, а в случае с rebase нужно знать диапазон.Ещё хуже то, что squash-коммиты с большей вероятностью будут отменены (или вырезаны) чище, чем серия маленьких коммитов. Иногда я намеренно коммичу ошибочные или незавершённые решения, которые изменяю в последующих коммитах, лишь для более убедительного рассказа истории; каждое из этих изменений может доставить неприятности, но они отменяют друг друга при squash-коммитах.
В общем, у меня есть претензии к каждому из трёх подходов. И это привело меня к идее четвёртого подхода, который в Git отсутствует (пока?):
Накатка изменений из ветки в ветку, группирование и слияние
Вам известна функция «группирования» в векторных графических редакторах? Рисуешь несколько объектов, выделяешь их, группируешь вместе, а затем разом трансформируешь всю группу, оперируя ею как единым объектом. И при необходимости можно её «разгруппировать» и работать с исходными объектами по отдельности. Эта функция полезна, потому что иногда нужно видеть более «высокоуровневую» картину, а иногда приходится углубляться в подробности. Это нормально, всё зависит от обстоятельств, с которыми мы сталкиваемся.
Мне хотелось бы увидеть воплощение этой идеи применительно к Git. Группы коммитов могли бы представлять собой именованные и аннотированные диапазоны коммитов:
feature-a может быть тем же, что и 5d64b71..3db02d3. Каждая Git-команда, которая сейчас принимает диапазон коммитов, могла бы принимать и названия групп. У групп могут быть описания, чтобы git log, git blame и т.д. могли принимать опции --grouped или --ungrouped и работать соответствующе.Конечно, нужно ещё продумать подробности (могут ли группы пересекаться? может ли группа быть частью другой группы?), я не знаком с устройством Git и не могу с уверенностью утверждать, что идея реализуема. Но чем больше я о ней думаю, тем больше она мне нравится. Я считаю, что группирование в сочетании с rebase-коммитами поможет взять всё лучшее из трёх подходов.
