
Команда VK Cloud перевела конспект доклада с конференции Data+AI Summit 2022. В своём выступлении Чжоу Цзян и Ааруна Годти из Apple описывают, как построили централизованный кластер Apache Spark на базе Kubernetes, который обрабатывает свыше 380 тыс. заданий Spark в день. Такой объем заданий поддерживает аналитические процессы и эксперименты дата-сайентистов компании Apple. Доклад целиком можно посмотреть здесь.
Кратко о главном

Ежедневный объём заданий Spark на платформе данных Apple
Разные типы рабочей нагрузки («вширь», «вглубь», «вширь и вглубь» — дальше мы поясним, что это означает) предъявляют разные требования к ресурсам кластера и обработке данных. У Apple есть единый интерфейс (панель управления), доступный как в локальном облаке, так и в облаке заказчика. При этом процесс онбординга кластера проходит легко и быстро.
Большое количество одновременно работающих приложений Spark создаёт заметное давление на кластер Kubernetes. У этого есть несколько несколько решений:
- Настройка Kubernetes для масштабных рабочих нагрузок Spark: увеличение размера хранилища ETCD, автомасштабирование кластера, приоритетность и вытеснение, использование IPv6.
- Spark Orchestration для масштабных задач: глобальный лимит максимального количества одновременно выполняемых заданий, бригадное планирование, тайм-ауты на стороне оператора, очистка истории переходов.
- Использование метрик Spark из предыдущих запусков для формирования рекомендаций по ресурсам для повторного выполнения такого же задания.
- Активация функции Dynamic Allocation для оптимизации использования ресурсов.
- Сервер истории масштабирования — хранит агрегированное представление большинства недавних заданий.
Платформа данных в Apple

Стейкхолдеры, инструменты и сценарии использования
Изначально платформа данных в Apple была спроектирована так, чтобы с ней могли работать специалисты разного профиля. Дата-инженеры, дата-сайентисты, инженеры по машинному обучению, работающие с Big Data, и бизнес-аналитики — все они могут реализовывать разные сценарии в разных предметных областях.
Чтобы рабочая среда лучше отвечала требованиям дата-инженеров и дата-сайентистов, мы в MSAI разделяем работу с большими данными на Big Data и Big Data Science. При соблюдении требований законодательства эта структура обеспечивает оптимальный инструментарий и адекватные ресурсы под конкретные задачи специалистов. Представьте себе разницу между расчётом индекса продуктивности пользователя и Smart-Composing сообщений.
Полный жизненный цикл приложения Spark

E2E-инфраструктура, которая гарантирует надежный рутинный деплоймент кода, а заодно поддерживает инструменты для комплексного тестирования, мониторинга и безопасности — это не чудо. Это результат качественной серьёзной работы по созданию платформы обработки данных для успешного бизнеса.
Выполнение масштабных заданий Spark с Kubernetes
Типы рабочих нагрузок в Spark
Можно выделить следующие типы:
- «вширь» — одновременно запланировано 5000–10 000 приложений Spark с небольшим количеством исполнителей;
- «вглубь» — запланировано несколько заданий с 1000–8000 исполнителей с высокой пропускной способностью ввода-вывода для внешней файловой системы;
- «вширь и вглубь» — постоянно планируем порядка 2000 приложений в минуту, при этом каждому приложению требуются сотни исполнителей;
- приложения с неравномерным объёмом пакетной обработки и задания, планируемые ежедневно или еженедельно;
- требования к планированию совместной или пакетной обработки.
Для грамотного масштабирования платформы нужно правильно определить тип рабочей нагрузки: у вас «много маленьких заданий» или «несколько больших»? Обычно с помощью пакетной обработки удаётся превратить «много маленьких заданий» в «несколько больших» — а это лучше для кластера и компонентов планирования. Но в некоторых случаях объединить маленькие задания нельзя — например, при обучении мультитенантной модели, для которой требуется полная изоляция при извлечении знаний. Тогда какой подход к рабочим нагрузкам «вширь» работает лучше всего?
Spark Orchestrator приходит на помощь

Spark Orchestrator — поддержка мультиоблачных решений и корректная работа планировщика
Обучая внедряемые сущности графа мультитенантной модели, мы больше всего сталкиваемся с трудностями при типе рабочей нагрузки «вширь»: по сути, нам нужно сконструировать десятки тысяч графов совершенно разного размера. Хотя количество пользователей может разниться в тысячи раз, фактическая длительность конструирования графа различается всего на пару часов.
Вот пара проблем, с которыми MSAI столкнулась при обработке рабочей нагрузки «вширь»:
- Непроизводительные потери: изменения длительности процесса менее ожидаемого уровня доказывают, что на непроизводительные потери при выполнении задания, возможно, приходится приличная часть всей длительности процесса.
- Планирование и очереди заданий: в HDInsights нет внешнего планировщика, то есть для буферизации неравномерного трафика используется внутренний планировщик YARN или очередь сессий Livy. И работает всё это плохо.
- Наблюдаемость: законодательные требования к обработке контента заказчика затрудняют доступ к логам и метрикам.
Одновременно выполняемые задания и управление масштабными ресурсами
Для платформы данных Apple очень удачно подобрали внешний планировщик, который в основном обходит некоторые перечисленные проблемы, используя старомодные настройки. Spark Orchestrator обеспечивает Apple несколько преимуществ:
- Мультиоблачная поддержка с быстрым развёртыванием.
- Глобальный контроль одновременно выполняемых заданий — критически важен, когда нужно соответствовать высокому уровню SLA при загруженном кластере, избежать взаимоблокировки заданий и уменьшить нехватку ресурсов.
- Улучшение наблюдаемости для оптимизации требований к ресурсам для заданий.
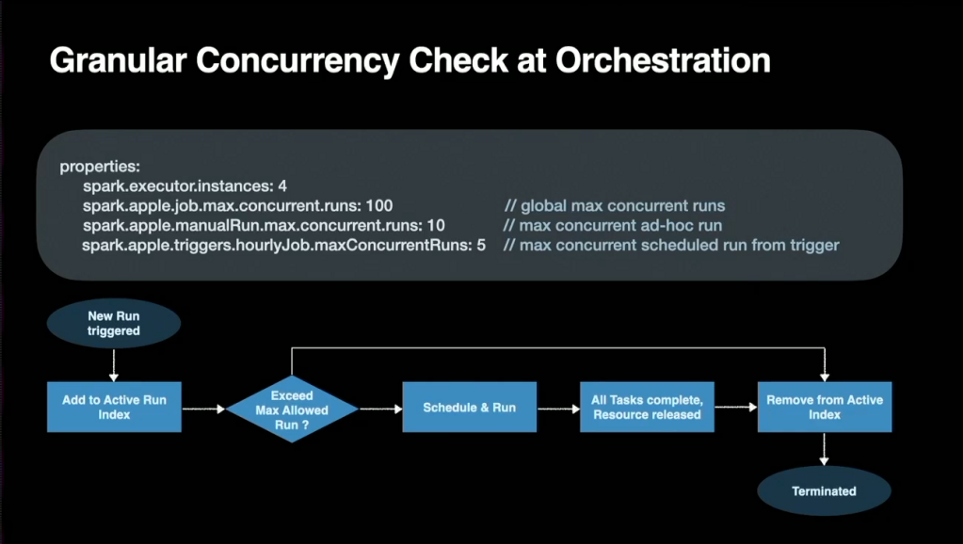
Контроль распараллеливания спасает ситуацию (SLA)

Тайм-аут играет ключевую роль, когда нужно избежать взаимоблокировки и уменьшить нехватку ресурсов

Динамическое распределение высвобождает ресурсы в периоды неактивности задания

Использование метрик Spark для рекомендаций по ресурсам — блестящая идея!
Попробуйте Kubernetes as a Service на платформе VK Cloud. Мы даём новым пользователям 3000 бонусных рублей на тестирование кластера или любых других сервисов.
