Comments 22
Таки первые 2 формулы должгы идти в обратном порядке — сначала формула Байеса, а потом — формула полной вероятности свидетельства ;)
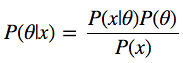{kind=link}
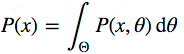{kind=link}
Отличный выбор статьи для перевода — было здорово в похожем ключе разобрать-описать задачку в духе: "А вот тут аналитического решения нет (потому что распределения не сопряженные итд), и нам ничего не остается, кроме как использовать MCMC и вот смотрите, как здорово получается"
В догонку: ELI5 (с веселым матаном и картинками) MCMC можно прочитать тут.
В догонку: ELI5 (с веселым матаном и картинками) MCMC можно прочитать тут.
Стесняюсь спросить, а где ссылка на оригинал?
Спасибо за пост, прочитал и кажется что-то понял про MCMC!
Небольшой вопрос — выглядит, что начальная точка может сбить сэмплинг posterior distribution, если она далека от его центра. В посте немного говорится о выборе proposal width, но ведь и начальную точку надо где-то выбирать. Или типа на практике где значение по умолчанию довольно очевидно?
Небольшой вопрос — выглядит, что начальная точка может сбить сэмплинг posterior distribution, если она далека от его центра. В посте немного говорится о выборе proposal width, но ведь и начальную точку надо где-то выбирать. Или типа на практике где значение по умолчанию довольно очевидно?
И вопрос немного в сторону — а как вообще не практике выбирают prior distribution для параметров, т.е. распределение до того как мы вообще хоть какие-то данные видели? В статье так весело сказали, что мол возьмем для мю нормальное с центром в нуле и с неким std, но разве это не означает уже некоторое откуда-то взявшееся предположение?
Какие распределения используют для prior на практике и почему?
Какие распределения используют для prior на практике и почему?
Присоединяюсь, этот вопрос в статье совсем не раскрыт, неясно даже, откуда берутся
prior_current prior_proposal и для чего нужны. Что если взять их равными 1.0?В статье так весело сказали, что мол возьмем для мю нормальное с центром в нуле и с неким std, но разве это не означает уже некоторое откуда-то взявшееся предположение?
Означает, в этом и смысл байесовской статистики. Например, мы хотим оценить результат президентских выборов, в которых участвует 2 кандидата — А и Б. А — политик с 20-летним стажем, никогда президентом не избирался, но всегда находился в "верхах", часто появляется на радио и ТВ. Б — тоже политик, но с гораздо меньшим стажем, практически неизвестный широкому кругу избирателей. Мы ещё ничего не знаем о текущих предпочтениях избирателей, но можем предположить, что кандидат А имеет примерно в 3 раза больше шансов победить, чем кандидат Б. Вот это предположение и будет нашей априорной вероятностью, т.е.
P(A wins) = theta = 0.75
P(B wins) = 1 - theta = 0.25Здесь мы моделируем выборы через распределение Бернулли, т.е. простое бинарное распределение с единственным параметром
theta, показывающим вероятность победы кандидата А (вероятность победы кандидата Б, соответсвенно, равна 1 - theta). Если бы кандидатов было больше 2, то нам пришлось бы использовать уже категориальное распределение.А вот если мы после нашего предположения проведём ещё соцопрос, то его результаты и будут нашим evidence (всё-таки бьёт по ушам это "свидетельство"). И если прогнать априорное распределение и evidence через формулу Байеса, то как раз и получится апостериорное распределение.
Однако, если мы хотим быть тру байесовцами, то мы никак не можем считать theta константой, а обязательно должны сделать его случайной переменной! Это, в общем-то, вполне логично: наша оценка победы кандидата А на выборах вряд ли равна строго 0.75. Скорее, мы верим, что скорее всего его шансы равны 0.75, но готовы согласиться (хотя и с меньшей вероятность) и на 0.7 или 0.8, или даже, чем чёрт не шутит, на 0.5, хотя в это мы верим и меньше. Т.е. наша предварительная вера сама по себе является непрерывной случайной переменной.
Вопрос: какое распределение будет иметь параметр theta (теперь его уже корректней звать случайной переменной theta — ещё одна отличительная особенность в терминологии частотного и байесовского подходов)? Отбросим на секунду выборы и возьмём монетку, потому что её мы можем бросать сколько угодно, а вот кидать кандидатов в президенты, пожалуй, не стоит. Допустим, мы бросили монетку 10 раз, 7 из которых она упала орлом — записываем: theta[1] = 0.7. theta[1] — это наша первая оценка параметра theta. Повторим эксперимент ещё 9 раз — получим, скажем, такой набор измерений параметра: theta[1:10] = [.8, .6, .9, .8, .7, .5, .8, .8, .7, .9]. Если попробовать сгладить и нарисовать такое распределение, то получится как-то так:
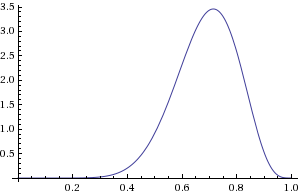
При этом такое распределение как раз и соответсвует нашей оценке для возможных параметров theta — наиболее вероятно, что theta лежит в окресности значения 0.75, с меньшей вероятность — больше или меньше этого значения. К нашему набору экспертиментов можно подойти формально через биномиальное распределение (которое является всего лишь распределением не одного, а нескольких бросков монетки) как это описано в Википедии, а можно сразу заметить, что функция плотности вероятности для theta уж очень напоминает Beta распределение. Тут важно понимать, что это не задача предполагает точно и однозначно Beta распределение, а это мы его выбрали, потому что удобно.
Возвращаясь к выборам и собирая всё вместе, получаем такую модель. Есть 2 переменные: theta — вероятность победы кандидата А, и x — количество голосов за каждого кандидата, которое мы узнаем после опроса. Есть 4 вероятности: P(theta) — предварительная вероятность победы кандидата А, т.е. наша вера до соцопроса; P(x|theta) — правдоподобие, вероятность получить такие данные при таком значении theta; P(x) — вероятность получить такие данные вообще и наша искомая P(theta|x) — вероятность победы кандидата A уже после соцопроса.
Как видите, мы выбрали априорное распределение не "потому что", а "для того, чтобы". Если бы кандидатов у нас было больше, то вместо бета-распределения мы бы могли взять распределение Дирехле. Если бы моделировали отклонение от графика для автобуса, то могли бы предположить, что оно примерно нормальное. Или равномерное, или то же бета — тут уже зависит от того, что подсказывает интуиция (или прежний опыт или общие соображения) и с чем нам удобней работать.
В контексте MCMC нужно все же отметить, что выбор a priori не влияет на полученное равновесное a posteriory распределение, а только лишь на скорость сходимости семлирования. Чем ближе наше a priory к a posteriory, тем меньше МСМС шагов нужно будет просчитать для получения результата с заданной точностью. На примере данной статьи, можно было вообще приравнять
prior_current = prior_proposal = 1 и всё будет работать аналогично (часто так и делают). Выбор начального значения mu_current вообще значения не имеют, так как на практике первые N шагов выкидывают.Уф, честно говоря, я не особо понял ваш комментарий, поэтому давайте по частям.
Сам MCMC имеет мало отношения к априорному и апостериорному распределению, как и вообще к байесовской статистике. Если брать конкретно алгоритм Метрополиса-Хастинга (кстати, кто знает, где ударение в имени "Метрополис"?), то ему для работы нужно только уметь получать плотность вероятности в каждой точке. Что это за вероятность — ему глубоко всё равно, но чаще всего это правдоподобие данных, т.е.
Априорная вероятность — это немного другое. Автор этой статьи изначально исходит из задачи статистического вывода в байесовских сетях, которые постоянно используют понятия априорного и апостериорного распределения. И вот в таких сетях априорное распределение очень даже влияет на апостериорное: во-первых, зачастую одно определяет форму другого, а во-вторых, если априорная "вера" высока, то она может очень сильно повлиять на параметры апостериорного распределния (если "вера" слаба, то апостериорное распределение в основном определяется данными, что совпадает с частотным подходом).
Т.е. теорема Байеса (вместе с априорным и апостериорным распределением) и MCMC — это ортогональные понятия, и даже на странице про алгоритм Метрополиса-Хастинга в Википедии нет ни одного упоминания про "prior distribution".
Опять же, не понял, что вы хотели сказать.
В общем, наверное я что-то не так понял, поэтому появните, пожалуйста.
выбор a priori не влияет на полученное равновесное a posteriory распределение
Сам MCMC имеет мало отношения к априорному и апостериорному распределению, как и вообще к байесовской статистике. Если брать конкретно алгоритм Метрополиса-Хастинга (кстати, кто знает, где ударение в имени "Метрополис"?), то ему для работы нужно только уметь получать плотность вероятности в каждой точке. Что это за вероятность — ему глубоко всё равно, но чаще всего это правдоподобие данных, т.е.
P(x | theta), где theta — это параметры, которые алгоритм варьирует. Соответсвенно, скорость сходимости зависит от того, насколько мы сходу угадали значения параметров theta. Априорная вероятность — это немного другое. Автор этой статьи изначально исходит из задачи статистического вывода в байесовских сетях, которые постоянно используют понятия априорного и апостериорного распределения. И вот в таких сетях априорное распределение очень даже влияет на апостериорное: во-первых, зачастую одно определяет форму другого, а во-вторых, если априорная "вера" высока, то она может очень сильно повлиять на параметры апостериорного распределния (если "вера" слаба, то апостериорное распределение в основном определяется данными, что совпадает с частотным подходом).
Т.е. теорема Байеса (вместе с априорным и апостериорным распределением) и MCMC — это ортогональные понятия, и даже на странице про алгоритм Метрополиса-Хастинга в Википедии нет ни одного упоминания про "prior distribution".
можно было вообще приравнять prior_current = prior_proposal = 1 и всё будет работать аналогично
Опять же, не понял, что вы хотели сказать.
prior_current и prior_proposal — это вычисляемые значения, приравнивать их чему-то как бы нет смысла. Возможно, вы имели ввиду mu_current и mu_proposal, из которых они вычисляются. Но и их приравнивать чему-то нет смысла, разве что на шаге инициализации: mu_proposal вычисляется как случайное отклонение от mu_current, а mu_current, соотвественно, принимает или не принимает новое значение mu_proposal на каждом новом шаге. Если вдруг мы в коде по ошибке сделаем mu_current == mu_proposal, то наш алгоритм вообще не будет двигаться и никогда не найдёт… эээ, назовём это mu_optimal. В общем, наверное я что-то не так понял, поэтому появните, пожалуйста.
скорость сходимости зависит от того, насколько мы сходу угадали значения параметров theta.
При генерации Марковой Цепи с помощью Metropolis-Hastings форма a priori не влияет на форму a posteriori (при условии достаточного семплинга), поэтому часто выбирают a priori = 1 (см §1.4). Обычно Metropolis-Hastings используется для того, что бы получить p(theta | x), то есть плотность вероятности параметров, принимая во внимание данные. Скорость сходимости этой процедуры от начального значения параметра theta (`mu_init`) почти не зависит, а зависит от выбранного шага (`proposal_width`) и того, на сколько удачно выбрана форма a priori. В рассматриваемом примере форма a priori задана формой выбранного (нормального) распределения и его параметрами
` mu_proposal = norm(mu_current, proposal_width).rvs()… prior_current = norm(mu_prior_mu, mu_prior_sd).pdf(mu_current) prior_proposal = norm(mu_prior_mu, mu_prior_sd).pdf(mu_proposal) `. Тут важно обратить внимание, что mu_proposal выбрано не как-нибудь, а из нормального распределения! Для того, что бы "скомпенсировать" этот конкретный выбор, нужно посчитать `prior_current/prior_proposal`
Замена кода из статьи на
` mu_proposal = random.uniform(mu_current-proposal_width, mu_current+proposal_width)… prior_current = 1 prior_proposal = 1 `
, не повлияет на результат семплинга, кроме той части, что нужно будет сделать несколько больше шагов. Чем ближе a priori и a posteriori, тем меньше шагов понадобится (при прочих равных) для что бы получить a posteriori с необходимой точностью.
Ну вот, так гораздо понятней. Только, боюсь, вы не совсем поняли смысл статьи (ну или я его совсем-совсем не понял).
A priori, про который вы говорите, относится к изначальным знаниям, которые позволяют оптимизировать сам алгоритм случайного блуждания. Дословно из статьи:
Если следовать нотации из Википедии, Metropolis-Hastings работает с двумя распределениями: целевым
Статья же концентрируется на распределени
Весь алгоритм Метрополиса-Хастингса в рамках данной статьи сводится всего к паре шагов:
Соответсвенно,
A priori, про который вы говорите, относится к изначальным знаниям, которые позволяют оптимизировать сам алгоритм случайного блуждания. Дословно из статьи:
The a priori information gleaned from this analytical work can then be used to propose exactly those (large) moves which are compatible with the system.
Если следовать нотации из Википедии, Metropolis-Hastings работает с двумя распределениями: целевым
P и вспомогательным Q, из которого делается сэмплирование для определения направления и длины шага. A priori, про который вы говорите, помогает выбрать более оптимальную длину и направление, при этом, конечно, при большом количестве шагов его значение уменьшается. Статья же концентрируется на распределени
P. Более того, речь идёт о статистическом выводе в байесовских сетях. И вот в байесовских сетях есть своя a priori (в статье это априорное распределение значений параметра — P(theta)), которая никакого отношения к распределению Q (как и вообще к методам MCMC) не имеет (равно как и статья, на которую вы ссылаетесь, не имеет никакого отношения и ни разу не упоминает байесовские сети). Весь алгоритм Метрополиса-Хастингса в рамках данной статьи сводится всего к паре шагов:
- Взять случайное значение mu, измерить, насколько он хорош.
- Передвинуться в случайном направлении (в данном конкретном случае — согласно нормальному распределению с центром в mu, но вообще на этом автор нигде не концентрируется).
- Если стало лучше, то остаться, если хуже, то с некоторой вероятностью вернуться назад.
- Повторить.
Соответсвенно,
mu_current и mu_proposal относятся к значению параметра, который мы оптимизируем, и ну никак не могут быть равны. A priori, про который вы говорите, относится к изначальным знаниям, которые позволяют оптимизировать сам алгоритм случайного блуждания
Именно этот a pripori и упоминается (вскользь) в этом посте, именно это a pripori и обуславливает строки:
mu_proposal = norm(mu_current, proposal_width).rvs()
....
# Вычисляем априорное распределение вероятностей для текущего и предлагаемого mu
prior_current = norm(mu_prior_mu, mu_prior_sd).pdf(mu_current)
prior_proposal = norm(mu_prior_mu, mu_prior_sd).pdf(mu_proposal)байесовских сетях есть своя a priori
Которая в посте Thomas Wiecki вообще не упоминается. В контексте Metropolis-Hastings, эту a priori вообще редко упоминают (она, обычно, не важна), наверное, что бы не путаться.
Соответсвенно, mu_current и mu_proposal относятся к значению параметра, который мы оптимизируем, и ну никак не могут быть равны.
Я и не предлагал их приравнивать к 1. Я предлагал приравнивать prior_current = prior_proposal = 1:
mu_proposal = random.uniform(mu_current-proposal_width, mu_current+proposal_width)
....
# Вычисляем априорное распределение вероятностей для текущего и предлагаемого mu
prior_current = 1
prior_proposal = 1Этот подход называют uninformative prior.
Спасибо за подробный ответ!
Хочу прояснить два момента
Хочу прояснить два момента
- В приведенных примерах есть какие-то данные до и после измерения (предшествующие рейтинги кандидатов, броски монетки итд). Но что делать, когда более ранних данных вообще нет? Вот только сейчас мы вообще получили нового кандидата, про которого ничего не знаем. Или начали сэмплировать новое распределение, которого раньше не видели (так что даже не знаем, в каком диапазоне может быть скажем среднее). Откуда берется интуиция в этом случае?
- Был сделан вывод, что в качестве prior для theta может подойти распределение, которое похоже на распределение случайного процесса с параметром theta. Вот здесь тонкий момент — то что есть некое распределение, у которого есть параметр, формально не дает права утверждать, что значение параметра распределено похожим образом. Или в этом и заключается стандартный баейсовский переход? Я не чтобы спорить, а чтобы понять.
начали сэмплировать новое распределение, которого раньше не видели
Любое предположение подойдёт, от него зависит только скорость сходимости. Можно попытаться проанализировать распределение и выбрать a priory и таким образом улучшить сходимость.
то что есть некое распределение, у которого есть параметр, формально не дает права утверждать, что значение параметра распределено похожим образом
А никто этого и не утверждает, в случае MCMC форма a priori не влияет на форму a posteriori.
Но что делать, когда более ранних данных вообще нет?
Допустим, вы играете в русскую рулетку, но вам даже не сказали, сколько патронов в револьвере. Какова вероятность, что при первом нажатии курка револьвер выстрелит? А чёрт его знает, пятьдесят на пятьдесят! На практике, при отсутствии предварительных знаний, интуиции и общих соображений, равномерное распределение вероятности между всеми значениями работает довольно хорошо. Правда, в этом случае байесовская статистика полностью совпадает с частотной, которая опирается только на наблюдаемые данные (evidence).
Был сделан вывод, что в качестве prior для theta может подойти распределение, которое похоже на распределение случайного процесса с параметром theta.
Уф, нет, здесь что-то не так. Обычно при объяснении я сразу рисую графы, но рисовать на форуме довольно проблематично, поэтому попробую обойтись псевдографикой.
Для начала нужно понять отличительные черты нотации частотной и байесовской статистики. Частотники, когда описывают распределение случайной переменной Y, которая зависит от параметра theta, пишут:
")
в то время как байесовцы заменяют это на:
")
Эта незначательная, казалось бы, деталь раскрывает очень важное различие между двумя подходами: в отличие от частотников, байесовцы часто выносят параметры распределения в отдельную случайную переменную с собственным (возможно, тоже параметризованным) распределением. Т.е. в байесовском подходе мы уже работаем не с одной случайной переменной
Y, а с двумя, связанными в граф: Theta -> Y Чтобы окончательно убрасть двоякость, заменим
Theta на X — по иксу сразу видно, что он — случайная переменная, а не просто константный параметр: X -> Yэтот граф можно параметризовать двумя распределениями: поскольку
X у нас ни от чего не зависит, то для него достаточно определить P(X), а вот Y зависит от X, так что для него понадобится условное распределение — P(Y | X). В общем случае, эти два распределения никак не связаны и представляют собой 2 абсолютно независимые функции. Однако, если мы ничего не знаем о системе, то и сделать с ней ничего не можем, поэтому обычно мы делаем несколько упрощений: - считаем, что
P(X)иP(Y|X)принадлежат к какому-нибудь красивому и хорошо изученному распределению; - по возможности стараемся сделать
P(X)иP(Y|X)сопряжёнными.
Первое, обычно, не создаёт проблем, а вот если не получается применить второе упрощение, то и приходится использовать всякие приближённые методы вывода типа MCMC (или наоборот, использовать точный вывод в приближённых графах, чем и занимаются вариационные методы).
Я надеюсь, это отвечает на ваш вопрос?
По первому пункту — ок. Единственное, как применять равномерное распределение, если даже диапазон не определен? От -inf до +inf?
По второму — я понимаю логику, но хочу процитировать ваше прошлое сообщение.
Вот этот график — он же определяется и P(X), и P(Y | X). Глядя на этот график нельзя сказать, что если он похож на какое-то распределение, то назначим P(X) таким-то. Я видимо не так понял, и под за отсылкой к Википедии скрывается какой-то дополнительный логический переход.
P.S. Наконец-то есть человек, готовый объяснять байесовскую статистику неподготовленным! Ура!
По второму — я понимаю логику, но хочу процитировать ваше прошлое сообщение.
Допустим, мы бросили монетку 10 раз, 7 из которых она упала орлом — записываем: theta[1] = 0.7. theta[1] — это наша первая оценка параметра theta. Повторим эксперимент ещё 9 раз — получим, скажем, такой набор измерений параметра: theta[1:10] = [.8, .6, .9, .8, .7, .5, .8, .8, .7, .9]. Если попробовать сгладить и нарисовать такое распределение, то получится как-то так:
[график]
При этом такое распределение как раз и соответсвует нашей оценке для возможных параметров theta — наиболее вероятно, что theta лежит в окресности значения 0.75, с меньшей вероятность — больше или меньше этого значения. К нашему набору экспертиментов можно подойти формально через биномиальное распределение (которое является всего лишь распределением не одного, а нескольких бросков монетки) как это описано в Википедии, а можно сразу заметить, что функция плотности вероятности для theta уж очень напоминает Beta распределение.
Вот этот график — он же определяется и P(X), и P(Y | X). Глядя на этот график нельзя сказать, что если он похож на какое-то распределение, то назначим P(X) таким-то. Я видимо не так понял, и под за отсылкой к Википедии скрывается какой-то дополнительный логический переход.
P.S. Наконец-то есть человек, готовый объяснять байесовскую статистику неподготовленным! Ура!
Единственное, как применять равномерное распределение, если даже диапазон не определен? От -inf до +inf?
В этом случае
P(Y|X) = P(Y), в каком бы интервале не был определён X. Смотрите: Но для начала 2 базовые вещи, про которые иногда забывают
Нужно помнить, что если
Сама же формула Байеса является всего лишь простым разложением формулы совместной вероятности. Мы знаем, что вероятность одновременного наступления событий A и B (например, вероятность, что
X и Y — непрерывные величины, то P(X) описывает плотность вероятности, т.е. такую скользкую штуку, которая в каждой конкретной точке X=x, вообще говоря, равна нулю (потому что размер точки равен нулю), поэтому точную вероятность посчитать нельзя. Тем не менее, это не мешает нам оперировать плотностями точно так же, как обычными вероятностями, т.е. делить и умножать их, а значит и передавать в формулу Байеса.Сама же формула Байеса является всего лишь простым разложением формулы совместной вероятности. Мы знаем, что вероятность одновременного наступления событий A и B (например, вероятность, что
X = x && Y = y для дискретных или соответствующие плотности для непрерывных переменных X и Y) равна вероятности одного события умноженная на верноятность второго при условии наступления первого (что, в принипе, довольно логично), т.е. P(X, Y) = P(X)P(Y|X) или P(X, Y) = P(Y)P(X|Y). Приравняв правые части двух последний уравнений и перенеся P(X) в знаменатель другой стороны, мы и получаем знаменитую формулу Байеса:P(Y|X) = P(Y)P(X|Y) / P(X)Про
X мы кое-что знаем: он распределён равномерно. Равномерно вне зависимости от каких-то условий, т.е. P(X|Y) = P(X). Подставим его в формулу: P(Y|X) = P(Y)P(X|Y) / P(X) = P(Y)P(X) / P(X)Убираем одинаковые части из числителя и знаменателя и получаем:
P(Y|X) = P(Y)Вуа-ля! В итоге это эквивалентно тому, что
Y не зависит от X, а также эквивалентно частотному подходу в статистике. Вот этот график — он же определяется и P(X), и P(Y | X).
График, в общем-то, является всего лишь графическим представлением
P(X), причём только его — про Y этот график вообще ничего не говорит (даже если в своих рассуждениях мы получили его при изучении Y, но про это смотрите следущий пункт). Глядя на этот график нельзя сказать, что если он похож на какое-то распределение, то назначим P(X) таким-то
Я бы сказал, что у вас тут изначально неправильный подход к вопросу. Смотрите: мы знаем, что значения
X распределены примерно как на графике. Мы это узнали по набору экспериментов, но для анализа нам нужна аналитическая форма P(X). Это касается не только этого конкретного случая, но и вообще любых распределений любых случайных переменных: мы всегда хотим найти простой способ работать с такой сложной штукой как P(X). Ещё одно маленькое отступление
Надо понимать, что
P(X) — это не график (график — это всего лишь визуализация плотности вероятности) и не число (хотя числом является P(X=x) или P(x1 <= X <= x2)). Распределение вероятности P(X) — это функция, которая ставит в соответсвие каждому возможному значения x какое-то число от 0 до 1. И эта функция может быть абсолютно любой. Например, она может быть задана покусочно для каждого из 100000 подинтервалов области определения. Однако работать с такими некрасивыми распределения тяжело и неудобно, поэтому гораздо проще заменить его — точно или приближённо — каким-нибудь аналитически простым. Например, есть исследование, которое утвреждает, что почти ничто в мире на самом деле не следует нормальному распределению… что не мешает приближённо описывать им очень и очень много естественных процессов. Вообще, тут мы могли бы просто сказать "ок, мы знаем, что график
P(X) похож на график бета-распределения, так давайте его им и аппроксимируем". И этого уже будет достаточно — вместо какого-то непонятного покусочного распределения без точных параметров мы бы получили простую аналитическую формулу, которая полностью определяется двумя параметрами (в бета-распределении они называются alpha и beta). Можно пойти и другим путём и проанализировать возможную форму
P(X). Довольно хорошо это сделано, например, здесь (там есть некоторые пробелы в объяснении, но наверное я и сам их сейчас не заполню). Основная идея в том, чтобы найти априорное распределение, которое в комбинации с функцией правдоподобия, будет давать распределение, пропорциональное апостериорному. Уж, звучит немного мозговзрывательно, но если посмотреть на слайд 7 в презентации, должно стать немного понятней. Такой трюк работает далеко не всегда, поэтому на практике все просто знают наиболее популярные сопряжённые распределения (вот, кстати, хорошая диаграмма с наиболее популярными из них) и используют их направо и налево.
Sign up to leave a comment.
MCMC-сэмплинг для тех, кто учился, но ничего не понял