
Ни для кого не секрет, что современные социальные сети представляют собой огромные БД, содержащие много интересной информации о частной жизни своих пользователей. Через веб-морду особо много данных не вытянешь, но ведь у каждой сети есть свой API… Так давай же посмотрим, как этим можно воспользоваться для поиска пользователей и сбора информации о них.
Есть в американской разведке такая дисциплина, как OSINT (Open source intelligence), которая отвечает за поиск, сбор и выбор информации из общедоступных источников. К одному из крупнейших поставщиков общедоступной информации можно отнести социальные сети. Ведь практически у каждого из нас есть учетка (а у кого-то и не одна) в одной или нескольких соцсетях. Тут мы делимся своими новостями, личными фотографиями, вкусами (например, лайкая что-то или вступая в какую-либо группу), кругом своих знакомств. Причем делаем это по своей доброй воле и практически совершенно не задумываемся о возможных последствиях. На страницах журнала уже не раз рассматривали, как можно с помощью различных уловок вытаскивать из соцсетей интересные данные. Обычно для этого нужно было вручную совершить какие-то манипуляции. Но для успешной разведки логичнее воспользоваться специальными утилитами. Существует несколько open source утилит, позволяющих вытаскивать информацию о пользователях из соцсетей.
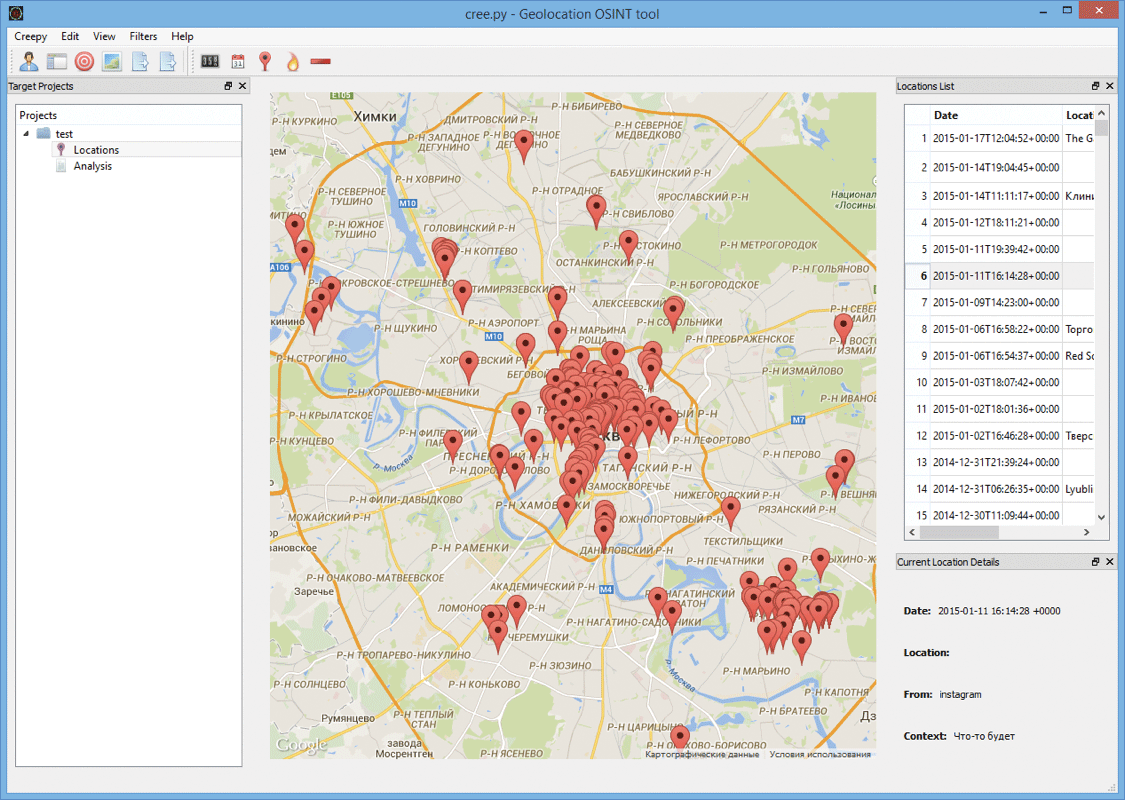
Creepy
Одна из наиболее популярных — Creepy. Она предназначена для сбора геолокационной информации о пользователе на основе данных из его аккаунтов Twitter, Instagram, Google+ и Flickr. К достоинствам этого инструмента, который штатно входит в Kali Linux, стоит отнести понятный интерфейс, очень удобный процесс получения токенов для использования API сервисов, а также отображение найденных результатов метками на карте (что, в свою очередь, позволяет проследить за всеми перемещениями пользователя). К недостаткам я бы отнес слабоватый функционал. Тулза умеет собирать геотеги по перечисленным сервисам и выводить их на Google-карте, показывает, кого и сколько раз ретвитил пользователь, считает статистику по устройствам, с которых писались твиты, а также по времени их публикации. Но за счет того, что это open source инструмент, его функционал всегда можно расширить самому.
Рассматривать, как использовать программу, не будем — все отлично показано в официальном видео, после просмотра которого не должно остаться никаких вопросов по поводу работы с инструментом.
fbStalker
Еще два инструмента, которые менее известны, но обладают сильным функционалом и заслуживают твоего внимания, — fbStalker и geoStalker.
fbStalker предназначен для сбора информации о пользователе на основе его Facebook-профиля. Позволяет выцепить следующие данные:
- видео, фото, посты пользователя;
- кто и сколько раз лайкнул его записи;
- геопривязки фоток;
- статистика комментариев к его записям и фотографиям;
- время, в которое он обычно бывает в онлайне.
Для работы данного инструмента тебе понадобится Google Chrome, ChromeDriver, который устанавливается следующим образом:
wget http://goo.gl/Kvh33W
unzip chromedriver_linux32_23.0.1240.0.zip
cp chromedriver /usr/bin/chromedriver
chmod 777 /usr/bin/chromedriver
Помимо этого, понадобится установленный Python 2.7, а также pip для установки следующих пакетов:
pip install pytz
pip install tzlocal
pip install termcolor
pip install selenium
pip install requests --upgrade
pip install beautifulsoup4
И наконец, понадобится библиотека для парсинга GraphML-файлов:
git clone https://github.com/hadim/pygraphml.git
cd pygraphml
python2.7 setup.py install
После этого можно будет поправить `fbstalker.py`, указав там свое мыло, пароль, имя пользователя, и приступать к поиску. Пользоваться тулзой достаточно просто:
python fbstalker.py -user [имя интересующего пользователя]
geoStalker
geoStalker значительно интереснее. Он собирает информацию по координатам, которые ты ему передал. Например:
- местные Wi-Fi-точки на основе базы `wigle.net` (в частности, их `essid`, `bssid`, `geo`);
- чекины из Foursquare;
- Instagram- и Flickr-аккаунты, с которых постились фотки с привязкой к этим координатам;
- все твиты, сделанные в этом районе.
Для работы инструмента, как и в предыдущем случае, понадобится Chrome & ChromeDriver, Python 2.7, pip (для установки следующих пакетов: google, python-instagram, pygoogle, geopy, lxml, oauth2, python-linkedin, pygeocoder, selenium, termcolor, pysqlite, TwitterSearch, foursquare), а также pygraphml и gdata:
git clone https://github.com/hadim/pygraphml.git
cd pygraphml
python2.7 setup.py install
wget https://gdata-python-client.googlecode.com/files/gdata-2.0.18.tar.gz
tar xvfz gdata-2.0.18.tar.gz
cd gdata-2.0.18
python2.7 setup.py install
После этого редактируем `geostalker.py`, заполняя все необходимые API-ключи и access-токены (если для какой-либо соцсети эти данные не будут указаны, то она просто не будет участвовать в поиске). После чего запускаем инструмент командой `sudo python2.7 geostalker.py` и указываем адрес или координаты. В результате все данные собираются и размещаются на Google-карте, а также сохраняются в HTML-файл.
Переходим к действиям
До этого речь шла о готовых инструментах. В большинстве случаев их функционала будет не хватать и придется либо их дорабатывать, либо писать свои тулзы — все популярные соцсети предоставляют свои API. Обычно они предстают в виде отдельного поддомена, на который мы шлем GET-запросы, а в ответ получаем XML/JSON-ответы. Например, для «Инстаграма» это `api.instagram.com`, для «Контакта» — `api.vk.com`. Конечно, у большинства таких API есть свои библиотеки функций для работы с ними, но мы ведь хотим разобраться, как это работает, да и утяжелять скрипт лишними внешними библиотеками из-за одной-двух функций не комильфо. Итак, давай возьмем и напишем собственный инструмент, который бы позволял искать фотографии из ВК и «Инстаграма» по заданным координатам и промежутку времени.
Используя документацию к API VK и Instagram, составляем запросы для получения списка фотографий по географической информации и времени.
Instagram API Request:
url = "https://api.instagram.com/v1/media/search?"
+ "lat=" + location_latitude
+ "&lng=" + location_longitude
+ "&distance=" + distance
+ "&min_timestamp=" + timestamp
+ "&max_timestamp=" + (timestamp + date_increment)
+ "&access_token=" + access_token
Vkontakte API Request:
url = "https://api.vk.com/method/photos.search?"
+ "lat=" + location_latitude
+ "&long=" + location_longitude
+ "&count=" + 100
+ "&radius=" + distance
+ "&start_time=" + timestamp
+ "&end_time=" + (timestamp + date_increment)
Здесь используемые переменные:
- location_latitude — географическая широта;
- location_longitude — географическая долгота;
- distance — радиус поиска;
- timestamp — начальная граница интервала времени;
- date_increment — количество секунд от начальной до конечной границы интервала времени;
- access_token — токен разработчика.
Как выяснилось, для доступа к Instagram API требуется access_token. Получить его несложно, но придется немного заморочиться (смотри врезку). Контакт же более лояльно относится к незнакомцам, что очень хорошо для нас.
Получение Instagram Access Token
Для начала регистрируешься в инстаграме. После регистрации переходишь по следующей ссылке:
instagram.com/developer/clients/manage
Жмешь **Register a New Client**. Вводишь номер телефона, ждешь эсэмэску и вводишь код. В открывшемся окне создания нового клиента важные для нас поля нужно заполнить следующим образом:
- OAuth redirect_uri: localhost
- Disable implicit OAuth: галочка должна быть снята
Остальные поля заполняются произвольно. Как только все заполнил, создавай нового клиента. Теперь нужно получить токен. Для этого впиши в адресную строку браузера следующий URL:
https://instagram.com/oauth/authorize/?client_id=[CLIENT_ID]&redirect_uri=http://localhost/&response_type=token
где вместо [CLIENT_ID] укажи Client ID созданного тобой клиента. После этого делай переход по получившейся ссылке, и если ты сделал все правильно, то тебя переадресует на localhost и в адресной строке как раз будет написан Access Token.
http://localhost/#access_token=[Access Token]
Более подробно про этот метод получения токена можешь почитать по следующей ссылке: jelled.com/instagram/access-token.
Автоматизируем процесс
Итак, мы научились составлять нужные запросы, но вручную разбирать ответ сервера (в виде JSON/XML) — не самое крутое занятие. Гораздо удобнее сделать небольшой скриптик, который будет делать это за нас. Использовать мы будем опять же Python 2.7. Логика следующая: мы ищем все фото, которые попадают в заданный радиус относительно заданных координат в заданный промежуток времени. Но учитывай один очень важный момент — выводится ограниченное количество фотографий. Поэтому для большого промежутка времени придется делать несколько запросов с промежуточными интервалами времени (как раз date_increment). Также учитывай погрешность координат и не указывай радиус в несколько метров. И не забывай, что время нужно указывать в timestamp.
Начинаем кодить. Для начала подключим все необходимые нам библиотеки:
import httplib
import urllib
import json
import datetime
Пишем функции для получения данных с API через HTTPS. С помощью переданных аргументов функции мы составляем GET-запрос и возвращаем ответ сервера строкой.
def get_instagram(latitude, longitude, distance, min_timestamp, max_timestamp, access_token):
get_request = '/v1/media/search?lat=' + latitude
get_request+= '&lng=' + longitude
get_request += '&distance=' + distance
get_request += '&min_timestamp=' + str(min_timestamp)
get_request += '&max_timestamp=' + str(max_timestamp)
get_request += '&access_token=' + access_token
local_connect = httplib.HTTPSConnection('api.instagram.com', 443)
local_connect.request('GET', get_request)
return local_connect.getresponse().read()
def get_vk(latitude, longitude, distance, min_timestamp, max_timestamp):
get_request = '/method/photos.search?lat=' + location_latitude
get_request+= '&long=' + location_longitude
get_request+= '&count=100'
get_request+= '&radius=' + distance
get_request+= '&start_time=' + str(min_timestamp)
get_request+= '&end_time=' + str(max_timestamp)
local_connect = httplib.HTTPSConnection('api.vk.com', 443)
local_connect.request('GET', get_request)
return local_connect.getresponse().read()
Еще накодим небольшую функцию конвертации timestamp в человеческий вид:
def timestamptodate(timestamp):
return datetime.datetime.fromtimestamp(timestamp).strftime('%Y-%m-%d %H:%M:%S')+' UTC'
Теперь пишем основную логику поиска картинок, предварительно разбив временной отрезок на части, результаты сохраняем в HTML-файл. Функция выглядит громоздко, но основную сложность в ней составляет разбиение временного интервала на блоки. В остальном это обычный парсинг JSON и сохранение нужных данных в HTML.
def parse_instagram(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment, access_token):
print 'Starting parse instagram..'
print 'GEO:',location_latitude,location_longitude
print 'TIME: from',timestamptodate(min_timestamp),'to',timestamptodate(max_timestamp)
file_inst = open('instagram_'+location_latitude+location_longitude+'.html','w')
file_inst.write('<html>')
local_min_timestamp = min_timestamp
while (1):
if ( local_min_timestamp >= max_timestamp ):
break
local_max_timestamp = local_min_timestamp + date_increment
if ( local_max_timestamp > max_timestamp ):
local_max_timestamp = max_timestamp
print timestamptodate(local_min_timestamp),'-',timestamptodate(local_max_timestamp)
local_buffer = get_instagram(location_latitude, location_longitude, distance, local_min_timestamp, local_max_timestamp, access_token)
instagram_json = json.loads(local_buffer)
for local_i in instagram_json['data']:
file_inst.write('<br>')
file_inst.write('<img src='+local_i['images']['standard_resolution']['url']+'><br>')
file_inst.write(timestamptodate(int(local_i['created_time']))+'<br>')
file_inst.write(local_i['link']+'<br>')
file_inst.write('<br>')
local_min_timestamp = local_max_timestamp
file_inst.write('</html>')
file_inst.close()
HTML-формат выбран не просто так. Он позволяет нам не сохранять картинки отдельно, а лишь указать ссылки на них. При запуске страницы результаты в браузере картинки автоматически подгрузятся.
Пишем точно такую же функцию для «Контакта».
def parse_vk(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment):
print 'Starting parse vkontakte..'
print 'GEO:',location_latitude,location_longitude
print 'TIME: from',timestamptodate(min_timestamp),'to',timestamptodate(max_timestamp)
file_inst = open('vk_'+location_latitude+location_longitude+'.html','w')
file_inst.write('<html>')
local_min_timestamp = min_timestamp
while (1):
if ( local_min_timestamp >= max_timestamp ):
break
local_max_timestamp = local_min_timestamp + date_increment
if ( local_max_timestamp > max_timestamp ):
local_max_timestamp = max_timestamp
print timestamptodate(local_min_timestamp),'-',timestamptodate(local_max_timestamp)
vk_json = json.loads(get_vk(location_latitude, location_longitude, distance, local_min_timestamp, local_max_timestamp))
for local_i in vk_json['response']:
if type(local_i) is int:
continue
file_inst.write('<br>')
file_inst.write('<img src='+local_i['src_big']+'><br>')
file_inst.write(timestamptodate(int(local_i['created']))+'<br>')
file_inst.write('http://vk.com/id'+str(local_i['owner_id'])+'<br>')
file_inst.write('<br>')
local_min_timestamp = local_max_timestamp
file_inst.write('</html>')
file_inst.close()
И конечно же, сами вызовы функций:
parse_instagram(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment, instagram_access_token)
parse_vk(location_latitude, location_longitude, distance, min_timestamp, max_timestamp, date_increment)
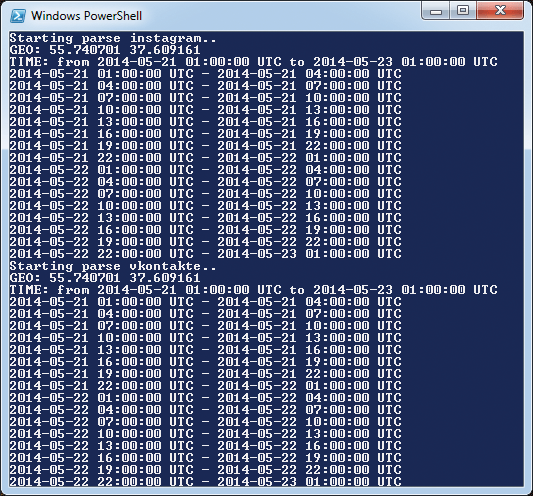
Результат работы нашего скрипта в консоли

Один из результатов парсинга Инстаграма

Результат парсинга «Контакта»
Боевое крещение
Скрипт готов, осталось его только опробовать в действии. И тут мне пришла в голову одна идея. Те, кто был на PHD’14, наверняка запомнили очень симпатичных промодевочек от Mail.Ru. Что ж, давай попробуем наверстать упущенное — найти их и познакомиться.
Собственно, что мы знаем об PHD14:
- место проведения — Digital October — 55.740701,37.609161;
- дата проведения — 21–22 мая 2014 года — 1400619600–1400792400.
Получаем следующий набор данных:
location_latitude = '55.740701'
location_longitude = '37.609161'
distance = '100'
min_timestamp = 1400619600
max_timestamp = 1400792400
date_increment = 60*60*3 # every 3 hours
instagram_access_token = [Access Token]
Полезные советы
Если в результате работы скрипта фотографий будет слишком мало, можешь пробовать изменять переменную `date_increment`, поскольку именно она отвечает за интервалы времени, по которым собираются фотографии. Если место популярное, то и интервалы должны быть частыми (уменьшаем `date_increment)`, если же место глухое и фотографии публикуют раз в месяц, то и сбор фотографий интервалами в час не имеет смысла (увеличиваем `date_increment`).
Запускаем скрипт и идем разбирать полученные результаты. Ага, одна из девочек выложила фотку, сделанную в зеркале в туалете, с привязкой по координатам! Естественно, API не простил такой ошибки, и вскоре были найдены странички всех остальных промодевочек. Как оказалось, две из них близняшки :).

Та самая фотография промо-девочки с PHD’14, сделанная в туалете
Поучительный пример
В качестве второго примера хочется вспомнить одно из заданий с финала CTF на PHD’14. Собственно, именно после него я заинтересовался данной темой. Суть его заключалась в следующем.
Есть злой хацкер, который разработал некую малварь. Нам дан набор координат и соответствующих им временных меток, из которых он выходил в интернет. Нужно добыть имя и фотку это хацкера. Координаты были следующие:
55.7736147,37.6567926 30 Apr 2014 19:15 MSK;
55.4968379,40.7731697 30 Apr 2014 23:00 MSK;
55.5625259,42.0185773 1 May 2014 00:28 MSK;
55.5399274,42.1926434 1 May 2014 00:46 MSK;
55.5099579,47.4776127 1 May 2014 05:44 MSK;
55.6866654,47.9438484 1 May 2014 06:20 MSK;
55.8419686,48.5611181 1 May 2014 07:10 MSK
Первым делом мы, естественно, посмотрели, каким местам соответствуют эти координаты. Как оказалось, это станции РЖД, причем первая координата — это Казанский вокзал (Москва), а последняя — Зеленый Дол (Зеленодольск). Остальные — это станции между Москвой и Зеленодольском. Получается, что он выходил в интернет из поезда. По времени отправления был найден нужный поезд. Как оказалось, станцией прибытия поезда является Казань. И тут встал главный вопрос: где искать имя и фотку. Логика заключалась в следующем: поскольку требуется найти фотку, то вполне разумно предположить, что искать ее нужно где-то в социальных сетях. Основными целями были выбраны «ВКонтакте», «Фейсбук», «Инстаграм» и «Твиттер». В соревнованиях помимо русских команд участвовали иностранцы, поэтому мы посчитали, что организаторы вряд ли бы выбрали «ВКонтакте». Решено было начать с «Инстаграма».
Никакими скриптами для поиска фотографий по координатам и времени мы тогда не обладали, и пришлось использовать публичные сервисы, умевшие это делать. Как выяснилось, их довольно мало и они предоставляют довольно скудный интерфейс. Спустя сотни просмотренных фотографий на каждой станции движения поезда наконец была найдена нужная.
В итоге, чтобы найти поезд и недостающие станции, а также логику дальнейшего поиска, понадобилось не больше часа. А вот на поиск нужной фотографии — очень много времени. Это еще раз подчеркивает, насколько важно иметь правильные и удобные программы в своем арсенале.
WWW
Исходный код рассмотренного скрипта ты можешь найти в моем Bitbucket-репозитории
Выводы
Статья подошла к завершению, и настало время делать вывод. А вывод простой: заливать фотографии с геопривязкой нужно обдуманно. Конкурентные разведчики готовы зацепиться за любую возможность получить новую информацию, и API социальных сетей им в этом могут очень неплохо помочь. Когда писал эту статью, я изучил еще несколько сервисов, в том числе Twitter, Facebook и LinkedIn, — есть ли подобный функционал. Положительные результаты дал только «Твиттер», что, несомненно, радует. А вот Facebook и LinkedIn огорчили, хотя еще не все потеряно и, возможно, в будущем они расширят свои API. В общем, будь внимательнее, выкладывая свои фото с геопривязкой, — вдруг их найдет кто-нибудь не тот. :)

Впервые опубликовано в журнале «Хакер» от 02/2015.
Автор: Аркадий Литвиненко (@BetepO_ok)
Подпишись на «Хакер»
