
Чем крупнее и сложнее становится сервис, тем больше времени приходится уделять тестированию. Поэтому желание автоматизировать и формализовать этот процесс вполне законно.
Чаще всего для автоматизации тестирования веб-сервисов применяется Selenium WebDriver. Как правило, с его помощью пишут функциональные тесты. Но, как всем хорошо известно, функциональные тесты не могут решить задачу тестирования верстки сервиса, что требует проведения дополнительных ручных, зачастую кроссбраузерных, проверок. Как тест может оценить корректность верстки? Чтобы обнаружить регрессионные ошибки верстки, тесту потребуется некоторый эталон, в качестве которого может выступать изображение корректной верстки, взятой, например, с продакшен-версии сервиса. Этот подход носит название screenshot-based testing. Подход этот применяется достаточно редко, и чаще всего верстку все же тестируют вручную. Причина этому – ряд достаточно строгих требований к сервису, к среде выполнения тестов и к самим тестам.
Расширенные ответы сервисов Яндекса в результатах поиска — мы у себя внутри по старой традиции называем их «колдунщиками» — дополнительное звено, в котором что-то может сломаться.
На примере тестирования колдунщиков в поиске мы расскажем, какими особенностями должен обладать тестируемый сервис, какие проблемы возникают у нас при использовании screenshot-based testing, и как мы их решаем.
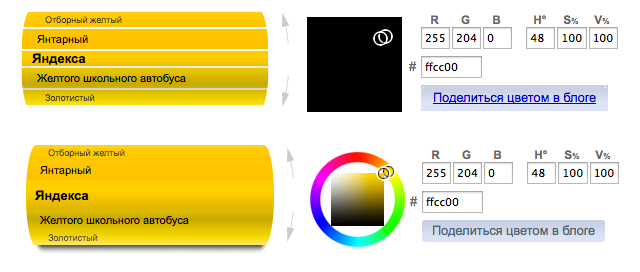
На проверки колдунщиков уходит большая часть времени, отведенного на регрессионное тестирование десктопного поиска. Важно убедиться в корректном отображении колдунщиков во всех основных браузерах (Firefox, Chrome, Opera, IE9+). Какие бы качественные функциональные тесты мы не написали, значительно сократить время регрессии нам не удавалось. К счастью, благодаря некоторым особенностям колдунщики вполне походят для screenshot-based testing:
Чтобы тестирование было эффективным, в Selenium Grid должно быть как можно больше браузеров различных версий. Выгода от каждого теста умножается на количество браузеров, в котором он выполняется. На создание screenshot-based тестов уходит много времени и ресурсов, поэтому нужно стараться проводить их с максимальной степенью эффективности. Иначе выигрыш во времени по сравнению с ручным тестированием может оказаться совсем незначительным. Для нужд автоматизации тестирования мы развернули Selenium Grid, предоставляющий тысячи браузеров нужных нам типов.
Другая проблема, о которой нужно подумать «на берегу» – стабильность сервиса в целом. Когда сервис бурно живет и развивается (значительно меняется дизайн, функциональность), борьба с таким уровнем шума потребует поддержки и может не окупиться от обновления до обновления сервиса. Как было отмечено выше, колдунщики достаточно стабильны.
Итак, мы хотим тестировать колдунщики с помощью скриншотов, эмулируя при этом действия пользователей: кликать по активным элементам, вводить текст в поля ввода, переключать табы и прочее. Но, помимо самого колдунщика, на странице есть другие элементы, в том числе нестатические: сниппеты, реклама, врезки вертикалей. В подавляющем большинстве случаев бета и продакшен поиска имеют видимые отличия. Значит, сравнение страницы целиком бессмысленно. Но все эти элементы никак не влияют на функциональность колдунщика. Можно было скрывать отдельные элементы страницы, но так как их у нас слишком много, мы решили скрывать все элементы страницы, кроме тестируемого колдунщика, с помощью JavaScript. Это несет и косвенную выгоду: страница «сжимается», скриншот снимается и передается по сети быстрее, занимает меньше места в памяти. Кроме того, опять же с помощью JavaScript, мы научились определять координаты области, в которой непосредственно располагается колдунщик, и производить сравнение только этой области.
Но даже одинаковые для человеческого глаза скриншоты оказались отличимыми при попиксельном сравнении. Не вдаваясь в причины такого поведения браузеров, мы ввели экспериментальный порог для различий в RGB-каналах, при котором срабатывание происходит только для видимых человеческому глазу отличий в отображении.
На пути к полной кроссбраузерности тестов было решено много проблем, вызванных прежде всего особенностями OperaDriver и IEDriver (описание которых выходит за рамки данной статьи).
Но, несмотря на все усилия, в значительном проценте случаев тесты давали ложные срабатывания по случайным причинам: лаг сети, задержки при выполнении JavaScript и AJAX. И хотя подобные ошибки случаются и с функциональными тестами, в screenshot-based тестах их влияние выше: если функциональный тест проверяет элемент A, а проблема возникла в элементе B, то ложного срабатывания может и не возникнуть, чего нельзя сказать о screenshot-based тесте.
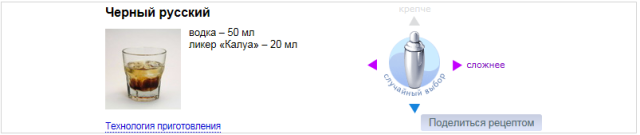
Приведем пример. При выборе другого коктейля в колдунщике «бармен», отрисовка нового рецепта не происходит мгновенно: требуется время на получение данных по сети с помощью AJAX и на JavaScript перерисовки элементов колдунщика. В результате, на бете скрипт не привел колдунщик в нужное состояние:
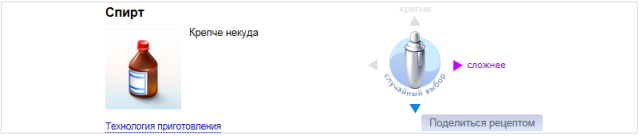
Тогда как в продакшене у скрипта проблем не возникло и колдунщик выглядит иначе:
Чтобы исключить элемент случайности, мы перезапускаем тесты несколько раз, пока не убедимся в стабильном воспроизведении проблемы. Это приводит к еще одному требованию к Selenium Grid: у вас должно быть много браузеров каждого типа. Потому что только параллельный запуск сможет дать приемлемую продолжительность выполнения тестов. В нашем случае более трех часов при последовательном запуске превратились в 12-15 минут после распараллеливания. Еще мы рекомендуем длинные сценарии разбивать на независимые короткие: вероятность случайных срабатываний снизится, а анализировать отчет станет проще.
К упомянутому отчету также предъявляются особые требования: когда тест возвращает много скриншотов, важно правильно их представить. Бесконечные клики по подстраницам отчета займут едва ли не столько же времени, что и ручная проверка сервиса. Универсального рецепта отчета нет, мы остановились на следующем:
В отчет попадают только ожидаемые исходы работы теста: успех, обнаружение различий, невозможность выполнить сценарий. Необходимо исключить любые ошибки теста, не позволяющие прийти к одному из этих исходов.
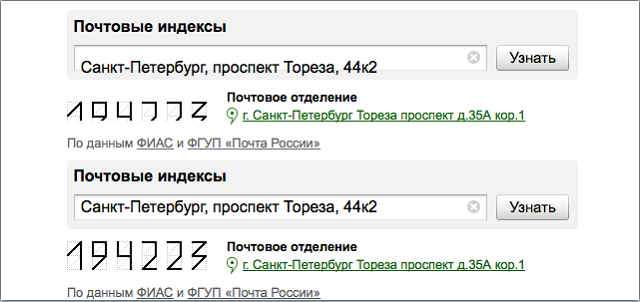
Сравнивая изображения-состояния колдунщиков, мы смогли обнаружить баги различных типов (далее первый скриншот – бета, второй – продакшен):

В качестве бонуса мы получили возможность находить изменения в переводах. Поиск представлен на русском, украинском, белорусском, казахском, татарском, английском, турецком языках. Уследить за корректностью всех версий весьма непросто, а на скриншотах различия в текстах сразу видны.
Итак, screenshot-based testing может быть весьма полезен. Но будьте осторожны в оценках: далеко не каждый сервис позволяет применить такой подход, и ваши усилия могут пропасть даром. Если же вам удастся найти подходящую функциональность, есть все шансы сократить время на ручное тестирование.
30 ноября в Санкт-Петербурге мы проведём Тестовую среду — своё первое мероприятие специально для тестировщиков. Там мы расскажем, как у нас устроено тестирование, что мы сделали для его автоматизации, как работаем с ошибками, данными и графиками и о многом другом. Участие бесплатное, но мест всего 100, поэтому надо успеть зарегистрироваться.
Чаще всего для автоматизации тестирования веб-сервисов применяется Selenium WebDriver. Как правило, с его помощью пишут функциональные тесты. Но, как всем хорошо известно, функциональные тесты не могут решить задачу тестирования верстки сервиса, что требует проведения дополнительных ручных, зачастую кроссбраузерных, проверок. Как тест может оценить корректность верстки? Чтобы обнаружить регрессионные ошибки верстки, тесту потребуется некоторый эталон, в качестве которого может выступать изображение корректной верстки, взятой, например, с продакшен-версии сервиса. Этот подход носит название screenshot-based testing. Подход этот применяется достаточно редко, и чаще всего верстку все же тестируют вручную. Причина этому – ряд достаточно строгих требований к сервису, к среде выполнения тестов и к самим тестам.
Расширенные ответы сервисов Яндекса в результатах поиска — мы у себя внутри по старой традиции называем их «колдунщиками» — дополнительное звено, в котором что-то может сломаться.
На примере тестирования колдунщиков в поиске мы расскажем, какими особенностями должен обладать тестируемый сервис, какие проблемы возникают у нас при использовании screenshot-based testing, и как мы их решаем.
Тестирование колдунщиков в поиске
На проверки колдунщиков уходит большая часть времени, отведенного на регрессионное тестирование десктопного поиска. Важно убедиться в корректном отображении колдунщиков во всех основных браузерах (Firefox, Chrome, Opera, IE9+). Какие бы качественные функциональные тесты мы не написали, значительно сократить время регрессии нам не удавалось. К счастью, благодаря некоторым особенностям колдунщики вполне походят для screenshot-based testing:
- Колдунщик – довольно обособленная функциональность страницы, он слабо зависит от соседних элементов.
- Большая часть колдунщиков статична.
- Изменения в колдунщики вносятся относительно редко, так что в большинстве случаев в качестве эталона можно использовать продакшен-версию поиска.
Чтобы тестирование было эффективным, в Selenium Grid должно быть как можно больше браузеров различных версий. Выгода от каждого теста умножается на количество браузеров, в котором он выполняется. На создание screenshot-based тестов уходит много времени и ресурсов, поэтому нужно стараться проводить их с максимальной степенью эффективности. Иначе выигрыш во времени по сравнению с ручным тестированием может оказаться совсем незначительным. Для нужд автоматизации тестирования мы развернули Selenium Grid, предоставляющий тысячи браузеров нужных нам типов.
Другая проблема, о которой нужно подумать «на берегу» – стабильность сервиса в целом. Когда сервис бурно живет и развивается (значительно меняется дизайн, функциональность), борьба с таким уровнем шума потребует поддержки и может не окупиться от обновления до обновления сервиса. Как было отмечено выше, колдунщики достаточно стабильны.
Итак, мы хотим тестировать колдунщики с помощью скриншотов, эмулируя при этом действия пользователей: кликать по активным элементам, вводить текст в поля ввода, переключать табы и прочее. Но, помимо самого колдунщика, на странице есть другие элементы, в том числе нестатические: сниппеты, реклама, врезки вертикалей. В подавляющем большинстве случаев бета и продакшен поиска имеют видимые отличия. Значит, сравнение страницы целиком бессмысленно. Но все эти элементы никак не влияют на функциональность колдунщика. Можно было скрывать отдельные элементы страницы, но так как их у нас слишком много, мы решили скрывать все элементы страницы, кроме тестируемого колдунщика, с помощью JavaScript. Это несет и косвенную выгоду: страница «сжимается», скриншот снимается и передается по сети быстрее, занимает меньше места в памяти. Кроме того, опять же с помощью JavaScript, мы научились определять координаты области, в которой непосредственно располагается колдунщик, и производить сравнение только этой области.
Но даже одинаковые для человеческого глаза скриншоты оказались отличимыми при попиксельном сравнении. Не вдаваясь в причины такого поведения браузеров, мы ввели экспериментальный порог для различий в RGB-каналах, при котором срабатывание происходит только для видимых человеческому глазу отличий в отображении.
На пути к полной кроссбраузерности тестов было решено много проблем, вызванных прежде всего особенностями OperaDriver и IEDriver (описание которых выходит за рамки данной статьи).
Но, несмотря на все усилия, в значительном проценте случаев тесты давали ложные срабатывания по случайным причинам: лаг сети, задержки при выполнении JavaScript и AJAX. И хотя подобные ошибки случаются и с функциональными тестами, в screenshot-based тестах их влияние выше: если функциональный тест проверяет элемент A, а проблема возникла в элементе B, то ложного срабатывания может и не возникнуть, чего нельзя сказать о screenshot-based тесте.
Приведем пример. При выборе другого коктейля в колдунщике «бармен», отрисовка нового рецепта не происходит мгновенно: требуется время на получение данных по сети с помощью AJAX и на JavaScript перерисовки элементов колдунщика. В результате, на бете скрипт не привел колдунщик в нужное состояние:

Тогда как в продакшене у скрипта проблем не возникло и колдунщик выглядит иначе:

Чтобы исключить элемент случайности, мы перезапускаем тесты несколько раз, пока не убедимся в стабильном воспроизведении проблемы. Это приводит к еще одному требованию к Selenium Grid: у вас должно быть много браузеров каждого типа. Потому что только параллельный запуск сможет дать приемлемую продолжительность выполнения тестов. В нашем случае более трех часов при последовательном запуске превратились в 12-15 минут после распараллеливания. Еще мы рекомендуем длинные сценарии разбивать на независимые короткие: вероятность случайных срабатываний снизится, а анализировать отчет станет проще.
К упомянутому отчету также предъявляются особые требования: когда тест возвращает много скриншотов, важно правильно их представить. Бесконечные клики по подстраницам отчета займут едва ли не столько же времени, что и ручная проверка сервиса. Универсального рецепта отчета нет, мы остановились на следующем:
- Отчет состоит из одной html-страницы.
- Колдунщики сгруппированы в блоки. Содержимое блоков можно сворачивать. Сначала идут блоки с ошибками.
- Внутри блока колдунщика отображаются сценарии. Успешные сценарии свернуты.
- Доступны логи сценария: с какими элементами производилось взаимодействие, чтобы можно было воспроизвести проблему.
- При перемещении указателя мыши по скриншоту, попеременно показываются изображения с беты и продакшена, чтобы человек мог быстро обнаружить отличие.
В отчет попадают только ожидаемые исходы работы теста: успех, обнаружение различий, невозможность выполнить сценарий. Необходимо исключить любые ошибки теста, не позволяющие прийти к одному из этих исходов.
Примеры найденных багов
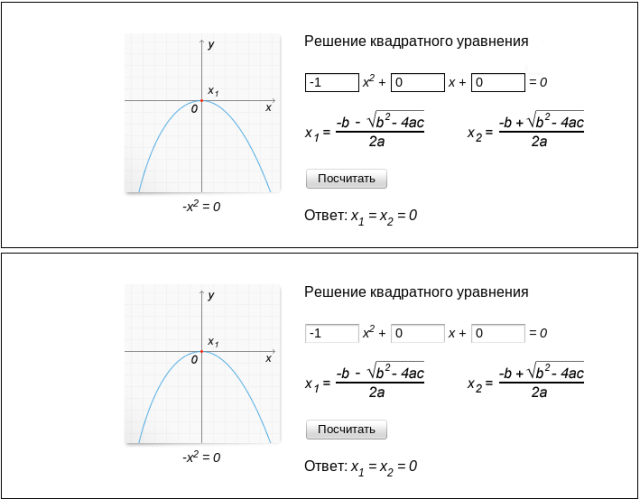
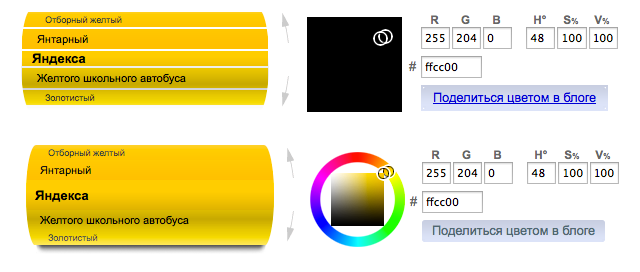
Сравнивая изображения-состояния колдунщиков, мы смогли обнаружить баги различных типов (далее первый скриншот – бета, второй – продакшен):
- Съехавший текст (колдунщик почтового индекса);

- Изменение масштабирования изображения (колдунщик афиша-событие);

- Регрессия в css (черная рамка у полей ввода математического колдунщика);

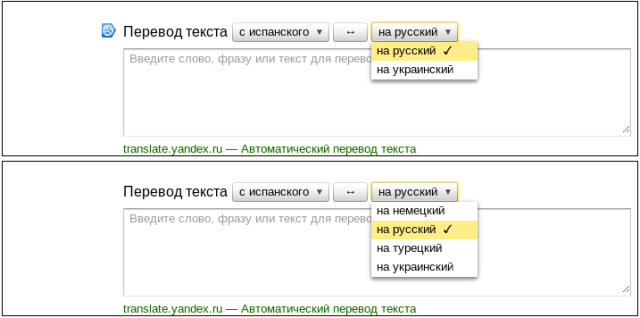
- Регрессия в данных (колдунщик переводов).

В качестве бонуса мы получили возможность находить изменения в переводах. Поиск представлен на русском, украинском, белорусском, казахском, татарском, английском, турецком языках. Уследить за корректностью всех версий весьма непросто, а на скриншотах различия в текстах сразу видны.
Итак, screenshot-based testing может быть весьма полезен. Но будьте осторожны в оценках: далеко не каждый сервис позволяет применить такой подход, и ваши усилия могут пропасть даром. Если же вам удастся найти подходящую функциональность, есть все шансы сократить время на ручное тестирование.
30 ноября в Санкт-Петербурге мы проведём Тестовую среду — своё первое мероприятие специально для тестировщиков. Там мы расскажем, как у нас устроено тестирование, что мы сделали для его автоматизации, как работаем с ошибками, данными и графиками и о многом другом. Участие бесплатное, но мест всего 100, поэтому надо успеть зарегистрироваться.
