
Разработчик инфраструктуры качества поиска Яндекса Ильнур Хузиев ilnurKh взял простую задачу — скалярное произведение двух векторов — и попробовал выжать все соки производительности кода. Из доклада вы узнаете, как использовать возможности процессора, настройки компилятора (и даже попробовать превзойти его), какой была бы правильная постановка задачи, как выбирать приоритеты и архитектуру. Да, вопрос выбора абстракций может встать даже на примере настолько простой задачи.
— Сегодня мы рассмотрим достаточно простую функцию — скалярное произведение двух векторов, и попробуем провести различные оптимизации. Надеюсь, что приёмы, которые мы рассмотрим, будут применены не только в этой задаче, но и в других.
В докладе четыре основных секции:

Мы будем рассматривать задачу, которая часто возникает в ситуациях, близких к ML, когда у нас есть много элементов — сотни тысяч или сотни миллионов, которые нам представлены некоторыми векторными представлениями — эмбедами.
Часто эти эмбеды берутся с помощью нейросетей. Либо это текстовые представления, свернутые в векторные числовые представления, либо нам свернули картинки или другой медиаконтент. Дальше нам необходимо для некоторого подмножества базы — в рамках нашего доклада это будет случайное подмножество — вычислить Dot Product с входящим эмбедом-запросом.
Это может быть другой элемент той же природы в задаче, когда нам нужно найти сколько-то элементов, близких к данному, либо это может быть другой объект, который, тем не менее, можно свернуть в похожее представление, где Dot Product является некоторой метрикой близости таких объектов. Некоторые сети, которые нам дают векторное представление, специально так обучают.
Код самого Dot Product максимально простой. Прежде чем приступить к тому, что мы будем оптимизировать, и ко всяким замерам, поясню, как будут выглядеть все диаграммы.

Во всех случаях у нас будет три группы столбцов, каждая из них будет соответствовать разной размерности — 64, 128 и 1024. Чтобы данные были сравнимы, мы нормируем второй и третий столбец — делим результаты на 2 и 16, чтобы они были в одной шкале с первым и мы могли видеть производительность на условную размерность. У нас столбцах всегдабудет представлено время, которое требуется на умножение входящего запроса на 10 тысяч случайных элементов из базы. Это время — среднее по измерениям, которые делались с помощью Google Benchmark.
В основном я буду говорить про размерность 64, потому что обычно такие размерности, несколько десятков или сотен, используются в текстах в моей практике. Если говорить про изображения, то, наверное, более интересным размером будет 1024. Все замеры выполнялись на модели процессора, которая написана на слайде.
В данном случае представлены замеры разных типы сборок, и видно, что релизная сборка достаточно сильно улучшает производительность. Если говорить про размер 64 и 128 — видимо там есть какие-то второстепенные операции, которые в debug-сборке не оптимизируются, и их вклад в нерелизной сборке достаточно высок, но по мере увеличения размерности тоже становится незначительным. Поэтому на размерности 64 разница больше чем в два раза, а на размерности 1024 она составляет всего лишь 30%.

Перейдем к конкретике. Первое, что нам нужно понять в любой задаче оптимизации: нужно ли что-то делать, есть ли потенциал для улучшений? Возможно, всё и так хорошо или достаточно хорошо. Причем такая задача, посчитать скалярное произведение двух векторов, встречается в куче мест. Поскольку функция настолько простая — семь-восемь строк кода, которые делают понятную вещь, — то естественно ожидать, что современные компиляторы способны оптимизировать такой код и ничего особенного с ним делать не нужно.
Хорошо, когда есть хорошие референсы, которые быстро выполняют нужную вам задачу. В нашем случае в MKL или в Eigen можно найти функции, которые максимально оптимизированы для данной задачи, но я хочу представить более общий подход, чтобы его можно было применить не только к задаче, в которой есть хороший референс. Потому что когда он есть — возможно, надо не заниматься самостоятельной оптимизацией, а взять готовые функции.
Наша функция берет две последовательности чисел, на каждой итерации цикла загружает их из памяти в регистры, делает над ними некоторую операцию и результат опять сохраняет в регистр. Убеждаемся, что во второй строчке объявленная переменная хранится именно в регистре, убеждаемся в compiler explorer, поэтому дополнительной записи памяти не происходит нигде, есть только чтения из памяти. То есть профиль нагрузки здесь такой, что идет количество чтений, равное количеству элементов в последовательностях, после этого идут действия в регистрах.
Я решил взять из библиотеки libc стандартные функции, на слайдах они обозначены как Сlib. Они почти всегда подключаются с помощью динамических библиотек, и, как правило, максимально оптимизированы. Я взял функцию memchr, которая, если в последовательности нет нулей, по профилю нагрузки сильно похожа на нашу функцию — она вынуждена пробежаться по всей последовательности элементов, просмотреть их, что-то с ними сделать и в зависимости от того, что там лежит, сформировать свой результат. Я специально удалил из тестовых данных нулевые байты, сделал это так, чтобы не ломать float, не получать nan или другие ненормальные float, и написал простую функцию, которая по профилю нагрузки должна быть частично похожа.
Мы ожидаем, что эти две функции будут производиться примерно одинаково, потому что тут сильно оптимизированный memchr, а Dot Product достаточно простая, чтобы мы ожидали, что компилятор справится.

Когда мы измеряем — видим, что ожидания не оправдались: разница для размерности 64 больше чем в три раза, и почти в четыре раза разница для размерности 1024, что немного неожиданно. Первый вопрос, который стоит себе задать: почему так получилось, почему компилятор не справился?
Основной фактор, за счет которого современные компиляторы выполняют микрооптимизации, за счет которого растет производительность современных процессоров, — это векторизация. Первое, что стоило бы проверить: верно ли, что векторизация не применилась?
Методов такой проверки несколько. Во-первых, можно пойти в compiler explorer и посмотреть, сколько там идет итераций, выполнил ли компилятор раскрытие циклов и применил ли векторизацию.

Код в Compiler Explorer
Можно поступить иначе — написать векторизацию вручную и проверить, получится ли какое-то улучшение.
Сразу замечу: так как у нас практически все современные платформы умеют в 128-битные регистры, то сборка была с параметром SSE4.2, который даже на ARM имеет смысл. Поэтому компилятор имел право векторизовать, но он этого не сделал.
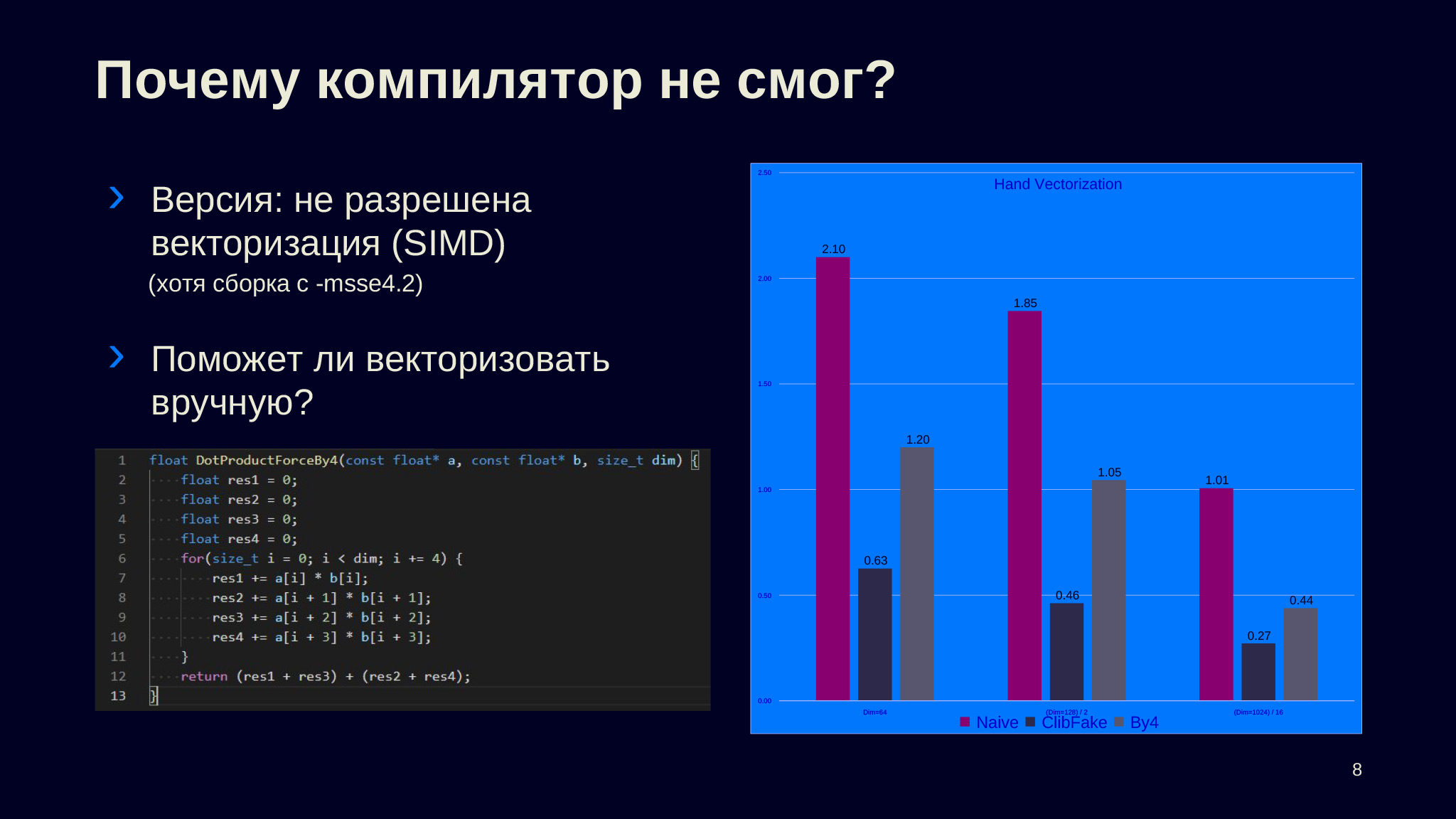
Вот код, где вручную раскрыты циклы по четыре элемента за раз. Замечу, что я здесь не учел хвосты, чтобы они влезали на слайды, и это будет касаться большого количества разных сниппетов. Специально выбраны удобные размерности — проблем с корректностью в рамках доклада не будет. Видим, что векторизация, которую мы сделали вручную, помогла. Она практически в два раза улучшила для размерности 64 и примерно во столько же раз в остальных ситуациях. То есть наша гипотеза о том, что векторизация по какой-то причине не смогла примениться, правильная.

Код в Compiler Explorer
Разгадка, почему так получилось, проста. Это связано с тем, что мы используем числа с плавающей точкой. Для чисел с плавающей точкой у нас не выполнена ассоциативность сложения или умножения, не выполнены хорошие свойства групп над умножением и сложением, которые позволяют делать разные полезные оптимизации, делать реордер. И так как в стандарте есть правило as-if, компилятор вынужден порождать код, который в точности соответствует тому, что мы написали. Поэтому он вынужден аккумулировать в единственный буфер (там у нас была переменная float res) промежуточные суммы в той последовательности, в которой мы их написали в коде, а это по одной паре элементов из последовательностей a и b за раз.
Есть workaround — параметр unsafe math optimization. Он позволяет компилятору применить те же оптимизации, которые он бы делал, если бы это были целые числа, в которых операции ведут себя намного лучше. На диаграмме четвертый столбец соответствует тому, что мы скомпилировали первый вариант с дополнительной опцией unsafe math optimization. Понятно, что был включен -msse4.2, который включен во всех столбцах.
Мы видим, что получили примерно то же самое, что и наша ручная оптимизация, когда мы делали по четыре элемента. Но получилось даже чуть лучше. Видимо, компилятор смог дополнительные неоптимальности, которые мы не учли, сделать лучше. Наверное, это хорошо, что мы смогли от компилятора добиться, чтобы он сделал свою работу и применил векторизацию.
Мы разобрались, что делать с векторизацией по четыре элемента со 128-битными регистрами. Давайте включим более новые возможности: для регистров в 256 и 512 бит.

Это AVX, AVX2 и AVX512, которые позволяют работать с регистрами соответствующего размера, 256 для AVX, AVX2 и 512 для AVX512. Вот столбцы, они отличаются от предыдущих только тем, что изменились флаги компиляции: AVX и AVX2 скомпилировались с -mavx и -mavx2 соотвественно, а AVX512 с целой кучей разных опций — я включил всё, что было доступно.
Мы видим, что последний столбец, который скомпилировался с AVX512, достиг того же числа, которое мы себе задали нашей заглушкой — не настоящей реализацей через libc функции memchr. Наверное, это хорошо, что мы смогли добиться от компилятора своего рода оптимального подхода, то есть компилятор (в нашем случае clang) смог сделать DotProduct не хуже, чем некоторые другие, хорошо оптимизированные функции.
Видно, что мы достигли цели только для раздела 64. Видимо, для 128 и 1024 начинает влиять разница в том, какая операция работает: все-таки для memchr требуется лишь работать с целочисленным объектом, возможно, там проще. Но unsafe math optimizations стоит применять очень осторожно. Потому что когда мы начинаем применять эту опцию, результат работы — бинарный выхлоп нашей программы — начинает сильно зависеть от того, какие мы применили флаги компиляции, что порождает множество проблем.
Наверное, самые заметные из них — это сложности тестирования. Многие системы тестирования завязаны на проверку того, что выход программы соответствует тому, который ожидается. Если нет бинарной совместимости, то нам начинает требоваться проверять, не просто что ответ совпал, а что он достаточно близок к тому, который требовался, или какие-то другие условия. Предположим, у нас написана дополнительная логика. Например, мы делаем дополнительную сортировку объектов. Тогда у нас еще и порядок объектов может поменяться, что еще больше усложнит способ, которым нужно валидировать, выдала ли наша программа корректный ответ. Еще из самых понятных проблем: debug и релиз сборки начинают существенно отличаться по выхлопу, а это очень неудобно.
По последней паре слайдов можно сделать вывод: следует убеждаться, что векторизация случилась.
Лирическое отступление по поводу того, что мы обсудили только что. Мы использовали несколько разных типов сборок под разные наборы инструкций. Отсюда вопрос: как доставлять код, который требует различных типов сборок, до рантайма, до продакшена?
В чем тут проблема? Если мы будем использовать наборы параметров компиляции по минимуму, набор, который работает на всех машинах, то мы будем использовать неполные возможности своего железа. Причем, как правило, надо учитывать: если мы используем облачные платформы, то они зачастую выдают не просто сырые ядра, а некоторые нормированные ядра. То есть размеры слотов, которые вы получаете в смысле логических ядер на машинах, могут быть меньше, чем вы заказывали, потому что в этом облачном провайдере считают производительность относительно какой-то одной модели процессоров. Поэтому на более новых, более производительных ядрах вам могут выдавать меньше ядер. Например, вы заказываете два ядра, а вам выдают 1,8, потому что для данной модели процессора таков коэффициент размена у этого облачного провайдера. Если включать максимальную опцию, будут получаться не работоспособные на младших платформах программы, которые будут падать с тем, что illegal instruction попытался выполниться.
Рассмотрим два способа решать эту проблему. Первый — делать несколько вариантов сборок, когда мы собираем несколько артефактов, склеиваем их в один архив, доставляем на нужные машины, нужные версии и проверяем, чтобы на них запустилась правильная версия нашего исполняемого файла. Проблемы у этого подхода следующие. Во-первых, сложность уносится со стадии разработки на стадию deploy. Во-вторых, это усложняет тестирование, потому что всегда приходится тестировать несколько программ и проверять их консистентность. У нас нет возможности запустить несколько версий кода в рамках одного процесса, что не позволяет нам юнит-тестами проверять, что несколько реализаций делают правильные вещи.
Второй вариант решения — runtime CPU dispatching, когда мы в рантайме пытаемся определить, какие наборы инструкций поддерживаются, и вывести правильную версию кода. Сразу оговорюсь, что мы работаем в рамках одной платформы на x86, но у нас разные модели процессоров. Если у нас есть разные типы инструкций, мы хотим компилироваться и на x86, и на ARM, то нам, скорее всего, придется все-таки делать несколько сборок. Этот подход лишен сложностей deploy, которые были выше: он оставляет проблему в руках разработчиков. Проблемы runtime CPU dispatching заключаются в том, что могут быть накладные расходы. Если реализовать этот подход неаккуратно, мы будем получать ухудшение производительности.

Так как уже был подготовлен стенд для замеров, то я сделал несколько разных вариантов реализации CPU dispatching и замерил их. Какой бы мы ни выбрали подход к runtime CPU dispatching, нам всегда нужно будет сделать несколько translation-юнитов, собрать каждый из них с нужным набором flag сборки, чтобы включить в них требуемый набор инструкций, слинковать их вместе. И дальше реализовать некоторую логику выбора конечной реализации, то есть сделать код, который выберет, какую из нескольких функций позвать.
Я сделал два простых варианта, которые сохранятся в глобальной памяти, флажки, которые проставляются перед вызовом main в инициализации глобальных объектов.
Первый вариант оптимистичный — он сначала проверяет старшие наборы инструкций. Второй пессимистичный — сначала проверяет, что на данной машине доступны только самые младшие из доступных вариантов.

Ещё один способ — сделать виртуальный вызов, то есть объявить некоторый интерфейс, сделать несколько его реализаций, а в глобальный объект инициализировать уже instance некоторой конечной реализации. Есть несколько других способов, но для иллюстрации, мне кажется, этого будет достаточно.
Так как замеры делались на машине, на которой был AVX512, то оптимистичный вариант показывает себя лучше всех, а пессимистичный хуже всех. Из этого делаем вывод: если у вас есть if'ы, которые вы не берете, делаете их несколько, в пессимистичном варианте — три, то это дорого. У нас, с одной стороны, большое замедление.
С другой, виртуальный вызов не так плох, здесь не такой большой проигрыш производительности, и это может быть хорошим дефолтом, потому что ваш налог на runtime CPU dispatching оказывается одинаковым и для старых, и для новых аппаратных платформ. Это делает вашу программу более предсказуемой в выполнении.
Тривиальный вывод: чем меньше доля кода, который выполняет runtime CPU dispatching, и чем больше доля кода, который непосредственно делает работу, — тем меньше накладные расходы. Еще видно, что по мере того, как увеличивается размерность, накладные расходы уменьшаются, и все варианты в RCD склеиваются в одинаковое число. Это конец лирического отступления.
Вернемся к нашей задаче, к оптимизации. Поговорим про то, что можно сделать, если рассматривать не маленькие участки кода, а работать с бóльшими блоками кода.

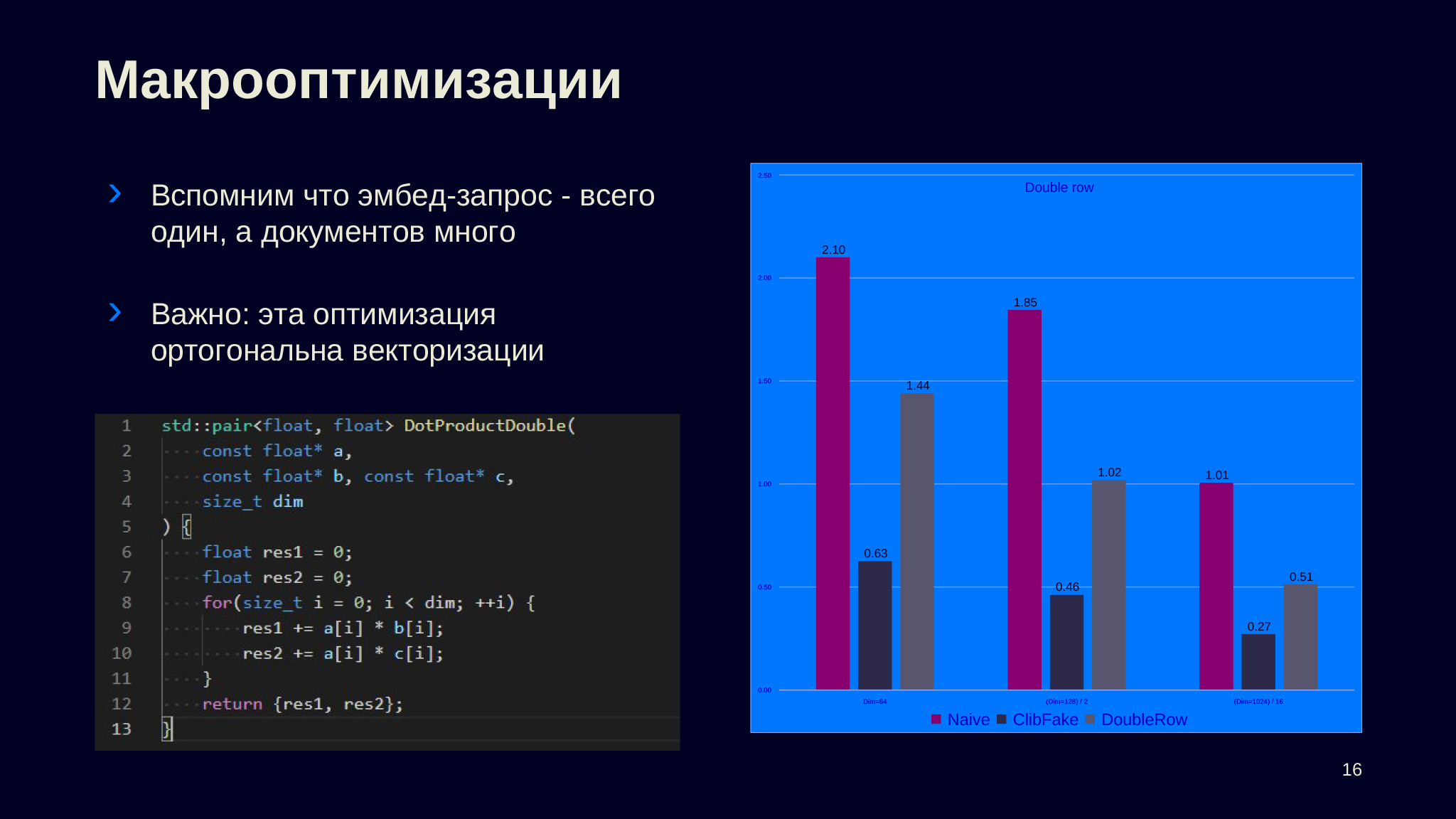
Как вы помните, задача строилась так: у нас один запросный эмбед и несколько документных. Но я, не замечая этого, стал сразу работать с функцией, которая всегда принимала один запрос-эмбед и один документный объект и умножала.
Но можно попытаться сделать оптимизацию, которая использовала бы тот факт, что запросный эмбед у нас один и тот же для всех документных. Чтобы проиллюстрировать, я написал простую функцию, которая принимает один запросный эмбед, два документных и возвращает не одно скалярное произведение, а два — А с В и А с C.
Как видно на замерах, мы получили заметное ускорение в сравнении с базовым вариантом, когда мы делали два вызова Dot Product на двух документных эмбедах. Важно, что эта оптимизация ортогональна векторизации. Значит, если мы все-таки будем работать с исходной задачей, когда мы получаем отдельно запросный эмбед и отдельно все документные эмбеды, то это откроет нам некоторый потенциал для улучшений.

Код в Compiler Explorer
Я подобрал, сколько объектов нужно брать за раз. Предположим, мы возьмем по четыре элемента за раз и включим все те оптимизации, которые мы получили на предыдущей стадии: то есть скомпилируем под AVX512, с unsafe math optimization. Оказалось, тогда мы получим 20% выигрыша по сравнению с тем, что было, когда мы работали с другой сигнатурой функции, когда мы всегда получали по два объекта: один запросный и один документный эмбеды.
Быстро скажу, что у нас здесь получает функция, потому что с данной сигнатурой мы будем работать и дальше. Первым аргументом она получает буфер, в котором лежат элементы запросного вектора. Дальше все документные эмбеды, которые сложены в dense-матрицу. Размерность — третьим аргументом, как было в предыдущих вариантах. Номера строк в матрице, с которой нам нужно сделать умножение, — в четвертом аргументе. Размер этой последовательности и куда сложить результаты — пятым и шестым аргументами.
Вот ссылка на Compiler Explorer на godbolt.org. Можно посмотреть, что происходит и за счет чего получается выигрыш.

Код в Compiler Explorer
Ещё один метод, который позволяет выжать ещё немного, — это prefetch. Иногда он применим. У нас работа с памятью асинхронна, более того, память и кэш многоканальные, можно попросить процессор подгрузить в кэш некоторый участок памяти с помощью __builtin_prefetch так, чтобы, когда он понадобится уже для загрузки в регистры, он оказался в cash и мы не ждали, пока нам ответила память.
Код здесь переписан на библиотеку интринсиков от Intel, то есть напрямую используются векторные переменные и векторные инструкции. Здесь ничего сложного нет, можно взять Compiler Explorer с предыдущего слайда и посмотреть, как это сделано, написать на нем. Вместо того чтобы делать builtin-операции типа оператора плюс, надо звать mm_reduce_add_ps, чтобы сложить, или fm_add_ps, чтобы умножить два объекта, сложить их с третьим. Иногда такой трюк с prefetch помогает.
На основе этого — небольшое лирическое отступление. Зачем писать на ассемблере? Первое: оптимизация не всегда справляется, и напрямую написав, что вам нужно сделать, вы можете обогнать компилятор. Мне кажется, иногда более важно, что вы, сделав так, можете точно задать семантику. В частности, отказаться от этого unsafe math optimization. Предположим, у вас есть четкий порядок того, что вы вычисляете, что с чем складываете. Тогда, если вы целитесь в максимальную производительность на старших аппаратных платформах, вы можете для более слабых попытаться сделать эмуляцию более старших.
Обычно вам вместо того, чтобы иметь один набор регистров, нужно в два раза больше. Например, если вы пытаетесь AVX-инструкции вычислять с помощью SSE-инструкций, то таким образом вы можете получить бинарно совместимые реализации на разных аппаратных платформах. Это сложно и дорого, но если это core-часть вашего приложения, иногда можно на это потратиться.
Оптимизируем память, которую потребляет наша задача умножения запросного эмбеда на некоторое подмножество документов. Почему нам может захотеться оптимизировать память? То, сколько места в памяти занимает наша база объектов, определяет, сколько объектов мы можем хранить у себя.
Представим: к нам приходят люди, которые занимаются продуктом, и говорят, что хотят хранить не 100 миллионов объектов, а 400 миллионов или миллиард. Понятно, почему это может быть важно: потому что, скорее всего, мы делаем ML-приложение и в нем есть размен: вы более точно вычисляете близости с хорошо отобранными объектами — или менее точно вычисляете близости между бóльшим множеством объектов и добираете в качестве продукта за счет полноты.
Какие есть варианты решения задачи увеличения количества объектов в базе? Первый вариант — налить больше железа: увеличить размер доступной памяти в инстансах, а если это уже невозможно, если мы достигли вертикального предела, то требуется сделать шардирование. Во-первых, это всегда увеличивает стоимость, потому что вы просите более тяжелые поды. Во-вторых, шардирование — это всегда сложно, потому что возникает множество попутных проблем: шардированные базы нужно правильно выкладывать, уже должен быть объект, который делает опрос в режиме broadcast к нескольким инстансам и правильно дожидается ответов. Сделать шардирование всегда намного сложнее, чем иметь один инстанс, внутри у которого есть вся полнота информации.
Второй вариант — сжимать векторы. Это ухудшит точность и, возможно, будет стоить больше по CPU. Давайте рассмотрим второй вариант, потому что, если он применим, то, конечно, стоит на нем остановиться. Так дешевле и проще в эксплуатации.

Какие есть способы сжимать векторные представления? В наших задачах применим простой метод: равномерное преобразование в один байт в UInt8. Почему оно хорошее? Во-первых, это fixed-length-преобразование, у нас размер координаты эмбеда сначала был четыре байта, стал один байт. Таким образом по номеру объекта, если данные непрерывно разложены в памяти, мы всегда можем найти, где находится участок конкретного документа. Восстановление, то есть обратное преобразование, — это линейная операция, значит, она простая и не будет стоить много.
Третье, самое важное: полученной точности, по крайней мере в наших задачах, зачастую хватает. При этом стоит понимать, что есть разные варианты улучшения точности. Как правило, у нас есть некоторое распределение значений всех координат, мы находим минимум, максимум и из этого вычисляем, каковы коэффициенты преобразования, сжатия в целое число от нуля до 255. Если полученное число не входит в интервал, мы меняем на ноль ниже границы интервала и на 255 — выше, а потом оставшееся преобразуем в int и получаем сжатое целочисленное значение, отбрасывая часть после точки.
Можно улучшать сжатие. Например, не брать глобальный минимум и максимум, а взять первую и 99-ю квантили и отсекать хвосты, таким образом увеличить точность сжатия для середины распределения. Можно сделать то же самое, но не для всей матрицы целиком, а для каждого коэффициента отдельно.
Справа написан простой способ «вылить воду из чайника»: мы, чтобы сделать умножение, сначала разжимаем каждый элемент во временный буфер, а затем вызываем одну из версий функции, которую мы рассматривали в первой части доклада и которая принимает два буфера и размерность. Что еще поменялось тут с точки зрения сигнатуры? Третья строчка: у нас теперь не float*, а uint8*, которая представляет все объекты.

Базовый вариант, четыре умножить на размерность объектов, в них обычные float. Второй столбец — лучшая версия, которую мы получали в этом подходе. Третий столбец — тот же, что был на предыдущем слайде. Последний вариант почти не отличается от третьего, только в качестве функции умножения разжатых векторов выступает самая быстрая версия. То есть в третьем столбце мы после разжатия для вычисления произведения векторов вызываем вариант из первого столбца, а в четвертом — из второго.
Видим значительное увеличение стоимости по сравнению с самой оптимизированной функцией. Но если рассматривать первый и третий столбец, видим, что стало даже лучше. Это, может быть, немного контринтуитивно, но понятно, почему так может произойти. Потому что, если говорить про размерность 64, мы стали высчитывать не 64 на четыре байта из памяти, чтобы сделать умножение одного документного эмбенда-запроса, а всего 64. Вернее, мы высчитываем их в буфер, но наверное, буфер у нас почти в кэше, поэтому в среднем мы можем здесь выиграть.

Код в Compiler Explorer
Можно попробовать вспомнить математику. Линейное преобразование, которое написано в скобках, можно записать на листочке, сделать нехитрое преобразование, перестановку переменных и придумать такую оптимизацию как в варианте справа, когда мы разжимаем не каждый элемент прежде, чем его умножить, а результат умножения.
Теоретически, нужно сделать меньше каких-либо операций и это должно помогать. Но, как мы видим по замерам, стало даже хуже. То есть четвертый столбец, где мы применили эту оптимизацию выносом действий за скобки, — хуже по метрикам. Это как раз тот пример, когда наши умные действия в некотором роде помешали компилятору, усложнили его работу.
Возможно, стоит остановиться и сделать вывод: если мы хотим в четыре раза выигрывать память сжатием в один байт, то будем в несколько раз проигрывать по производительности. Если смотреть самые оптимизированные версии 0,47, то на предыдущем слайде у нас была версия 1,52, это примерно в три раза хуже.
Но я тут призываю вас не позволить компилятору обмануть себя. Потому что мы все-таки помним, что фактически основным узким местом для всего процесса было именно общение с памятью, как часто бывает для число-дробительных задач, а необходимый foot print для работы со сжатыми данными в четыре раза меньше.

Код в Compiler Explorer
Если переписать то, что сам компилятор выдает в Compiler Explorer на интринсиках, и аккуратно следить, чтобы мы не делали лишних походов в память, а все необходимые преобразования делались уже на регистрах, то окажется, что мы выиграем относительно самой оптимизированной версии на четырех байтах.
Пару пояснений по коду. Во-первых, здесь опущены некоторые дублирования. Во-вторых, в строке 26 идет загрузка для 512 байт, мы здесь загружаем один 128-битный регистр; потом разжимаем его в 256-битный, где перемешаны байты, чтобы были представлены 16-битные целые числа; потом байты опять перемешиваются; и мы получаем 512-битный регистр.
Все эти преобразования между целочисленными типами — простые операции перестановки битов, а конвертация из epi32 в ps — это уже сложная операция: нужно посчитать для каждого из запакованных значений мантиссу, порядок и потом получить представление для чисел с плавающей точкой. Это примерное изменение, которое делалось с лучшей версией из первого раздела. Напомню, что на замерах она нам давала 0,47 мс, а данная версия дает 0,37 мс. То есть мы смогли сделать такую версию, которая в четыре раза лучше по памяти и еще на 20% лучше по CPU, чем эта же оптимизированная версия, что не может не радовать.

Примеры библиотек: half и float16 в CatBoost
Прежде чем перейти к завершающей части — небольшое отступление про float 16. Это другой метод сжатия данных с потерей точности, который широко применяется: почти все современные нейронные сети на GPU учатся на float 16, потому что точности хватает для работы. Сама модель, конечно, становится хуже. С другой стороны, так как числа стали в два раза меньше, вы можете сделать ее заметно больше. И этот размен, в котором вы делаете модель больше, но отдельные ее компоненты, отдельные веса, пусть будут сделаны менее точно, позволяет вам строить модели гораздо лучше. Более того: во float 16 вы можете быстрее их учить, в GPU хорошая аппаратная поддержка float 16, поэтому на нем почти всегда учат нейронные сети.
Это очень хороший дефолт, чтобы сжимать FP32-числа, если вы их предварительно загнали в интервал (-1; 1). Предположим, у вас есть числа, для которых вам, с одной стороны, нужно сохранять точность на значениях, близких к нулю. А с другой стороны, у вас бывают выбросы, заметно большие по значению объекты, и там вы тоже не хотите совсем уходить в максимум, сжимать всё в одну точку.
FP32 — это всего 65 536 значений. И это мало, поэтому лучше сжать в интервал (-1; 1). Вы потеряете один бит, знак мантиссы всегда будет не положительным, но вы сможете использовать все остальное. Это удобно.
Замечу, что в современном железе есть соответствующая поддержка — в процессорах x86 это флаг FP16C, инструкция, которая позволяет конвертировать представления float 16 в регистры float 32. И дальше работать с ними, как с обычными данными float 32. По своему опыту скажу, что с данными float 16 можно ожидать того же эффекта, который мы получили с uint8. То есть вы остаетесь в плюсе за счет уменьшения foot print и того, что вы потратили немного времени процесса на преобразование из неудобного формата FP16 в родной формат FP32.
К сожалению, в языке нет прямой поддержки, то есть нет built in-типа, который представлял бы данные float 16. Понятно, почему: там много разных сложностей. Когда вы складываете два числа FP16, непонятно, должны ли вы их складывать как числа FP32 с обратным преобразованием результата в FP16 или, например, делать всё над FP16. Современные процессы x86 не умеют эффективно вычислять второй вариант.
Есть часто используемые библиотеки, например half. Или можно посмотреть кастомные реализации, например ту, что доступна в репозитории CatBoost. Это всё, что мне хотелось сказать про float 16.

Мы подходим к концу доклада. Что нужно не забыть, если мы оптимизируем код?
В качестве девиза предлагаю такой: оптимизируйте на всю глубину — от постановки до инструкций. Хорошо, что мы с вами работаем на языке С++, который позволяет это делать. Нам удобно, с одной стороны, описывать бизнес-логику, объекты высокого уровня, с которыми мы работаем, а с другой — опускаться до уровня инструкций и выедать каждый процент перфоманса.
— Сегодня мы рассмотрим достаточно простую функцию — скалярное произведение двух векторов, и попробуем провести различные оптимизации. Надеюсь, что приёмы, которые мы рассмотрим, будут применены не только в этой задаче, но и в других.
В докладе четыре основных секции:
- Постановка и первые оптимизации
- Лирическое отступление
- Оптимизации lvl-2
- Оптимизации памяти
Постановка и первые оптимизации

Мы будем рассматривать задачу, которая часто возникает в ситуациях, близких к ML, когда у нас есть много элементов — сотни тысяч или сотни миллионов, которые нам представлены некоторыми векторными представлениями — эмбедами.
Часто эти эмбеды берутся с помощью нейросетей. Либо это текстовые представления, свернутые в векторные числовые представления, либо нам свернули картинки или другой медиаконтент. Дальше нам необходимо для некоторого подмножества базы — в рамках нашего доклада это будет случайное подмножество — вычислить Dot Product с входящим эмбедом-запросом.
Это может быть другой элемент той же природы в задаче, когда нам нужно найти сколько-то элементов, близких к данному, либо это может быть другой объект, который, тем не менее, можно свернуть в похожее представление, где Dot Product является некоторой метрикой близости таких объектов. Некоторые сети, которые нам дают векторное представление, специально так обучают.
Код самого Dot Product максимально простой. Прежде чем приступить к тому, что мы будем оптимизировать, и ко всяким замерам, поясню, как будут выглядеть все диаграммы.
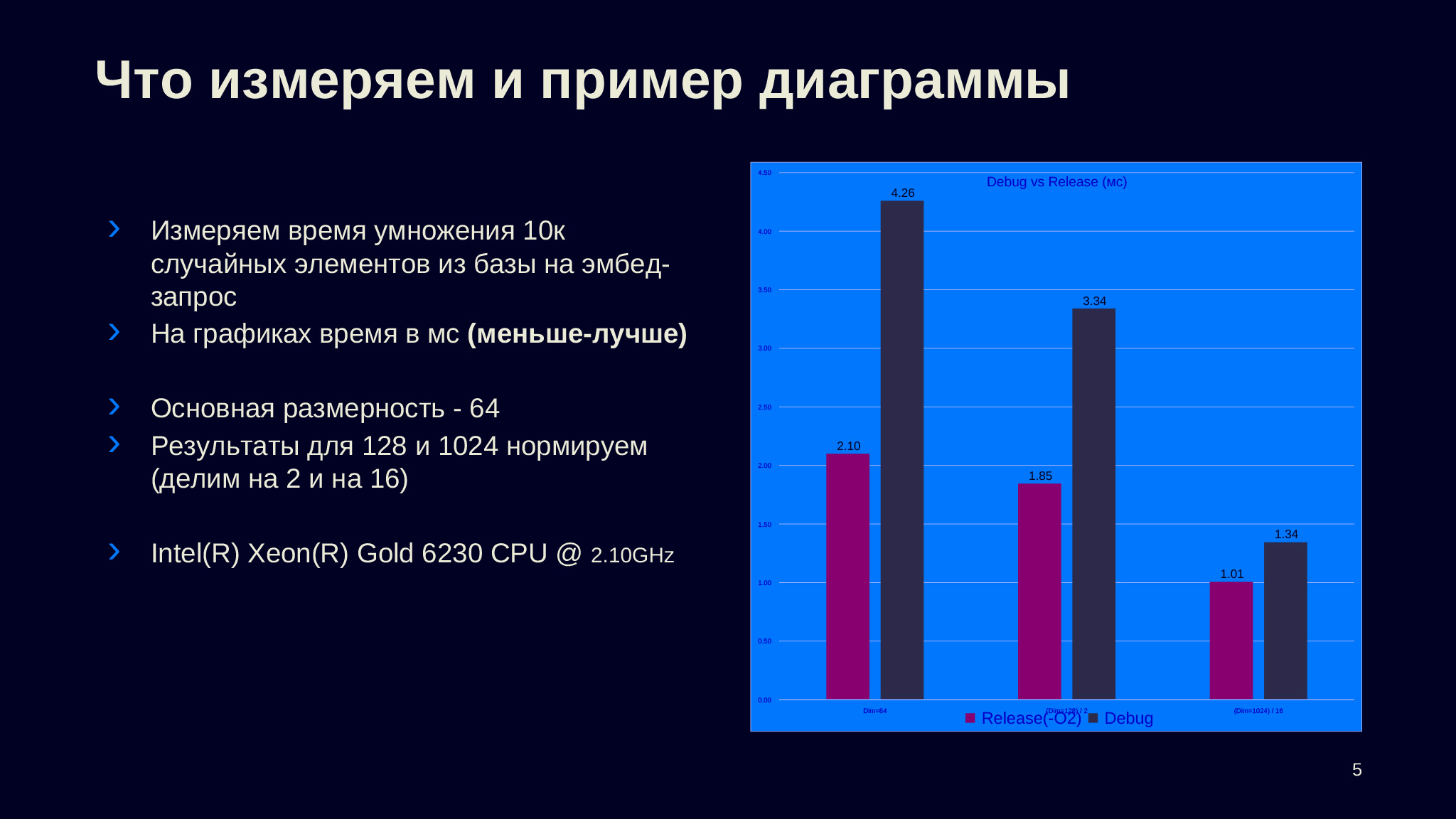
Во всех случаях у нас будет три группы столбцов, каждая из них будет соответствовать разной размерности — 64, 128 и 1024. Чтобы данные были сравнимы, мы нормируем второй и третий столбец — делим результаты на 2 и 16, чтобы они были в одной шкале с первым и мы могли видеть производительность на условную размерность. У нас столбцах всегдабудет представлено время, которое требуется на умножение входящего запроса на 10 тысяч случайных элементов из базы. Это время — среднее по измерениям, которые делались с помощью Google Benchmark.
В основном я буду говорить про размерность 64, потому что обычно такие размерности, несколько десятков или сотен, используются в текстах в моей практике. Если говорить про изображения, то, наверное, более интересным размером будет 1024. Все замеры выполнялись на модели процессора, которая написана на слайде.
В данном случае представлены замеры разных типы сборок, и видно, что релизная сборка достаточно сильно улучшает производительность. Если говорить про размер 64 и 128 — видимо там есть какие-то второстепенные операции, которые в debug-сборке не оптимизируются, и их вклад в нерелизной сборке достаточно высок, но по мере увеличения размерности тоже становится незначительным. Поэтому на размерности 64 разница больше чем в два раза, а на размерности 1024 она составляет всего лишь 30%.

Перейдем к конкретике. Первое, что нам нужно понять в любой задаче оптимизации: нужно ли что-то делать, есть ли потенциал для улучшений? Возможно, всё и так хорошо или достаточно хорошо. Причем такая задача, посчитать скалярное произведение двух векторов, встречается в куче мест. Поскольку функция настолько простая — семь-восемь строк кода, которые делают понятную вещь, — то естественно ожидать, что современные компиляторы способны оптимизировать такой код и ничего особенного с ним делать не нужно.
Хорошо, когда есть хорошие референсы, которые быстро выполняют нужную вам задачу. В нашем случае в MKL или в Eigen можно найти функции, которые максимально оптимизированы для данной задачи, но я хочу представить более общий подход, чтобы его можно было применить не только к задаче, в которой есть хороший референс. Потому что когда он есть — возможно, надо не заниматься самостоятельной оптимизацией, а взять готовые функции.
Наша функция берет две последовательности чисел, на каждой итерации цикла загружает их из памяти в регистры, делает над ними некоторую операцию и результат опять сохраняет в регистр. Убеждаемся, что во второй строчке объявленная переменная хранится именно в регистре, убеждаемся в compiler explorer, поэтому дополнительной записи памяти не происходит нигде, есть только чтения из памяти. То есть профиль нагрузки здесь такой, что идет количество чтений, равное количеству элементов в последовательностях, после этого идут действия в регистрах.
Я решил взять из библиотеки libc стандартные функции, на слайдах они обозначены как Сlib. Они почти всегда подключаются с помощью динамических библиотек, и, как правило, максимально оптимизированы. Я взял функцию memchr, которая, если в последовательности нет нулей, по профилю нагрузки сильно похожа на нашу функцию — она вынуждена пробежаться по всей последовательности элементов, просмотреть их, что-то с ними сделать и в зависимости от того, что там лежит, сформировать свой результат. Я специально удалил из тестовых данных нулевые байты, сделал это так, чтобы не ломать float, не получать nan или другие ненормальные float, и написал простую функцию, которая по профилю нагрузки должна быть частично похожа.
Мы ожидаем, что эти две функции будут производиться примерно одинаково, потому что тут сильно оптимизированный memchr, а Dot Product достаточно простая, чтобы мы ожидали, что компилятор справится.
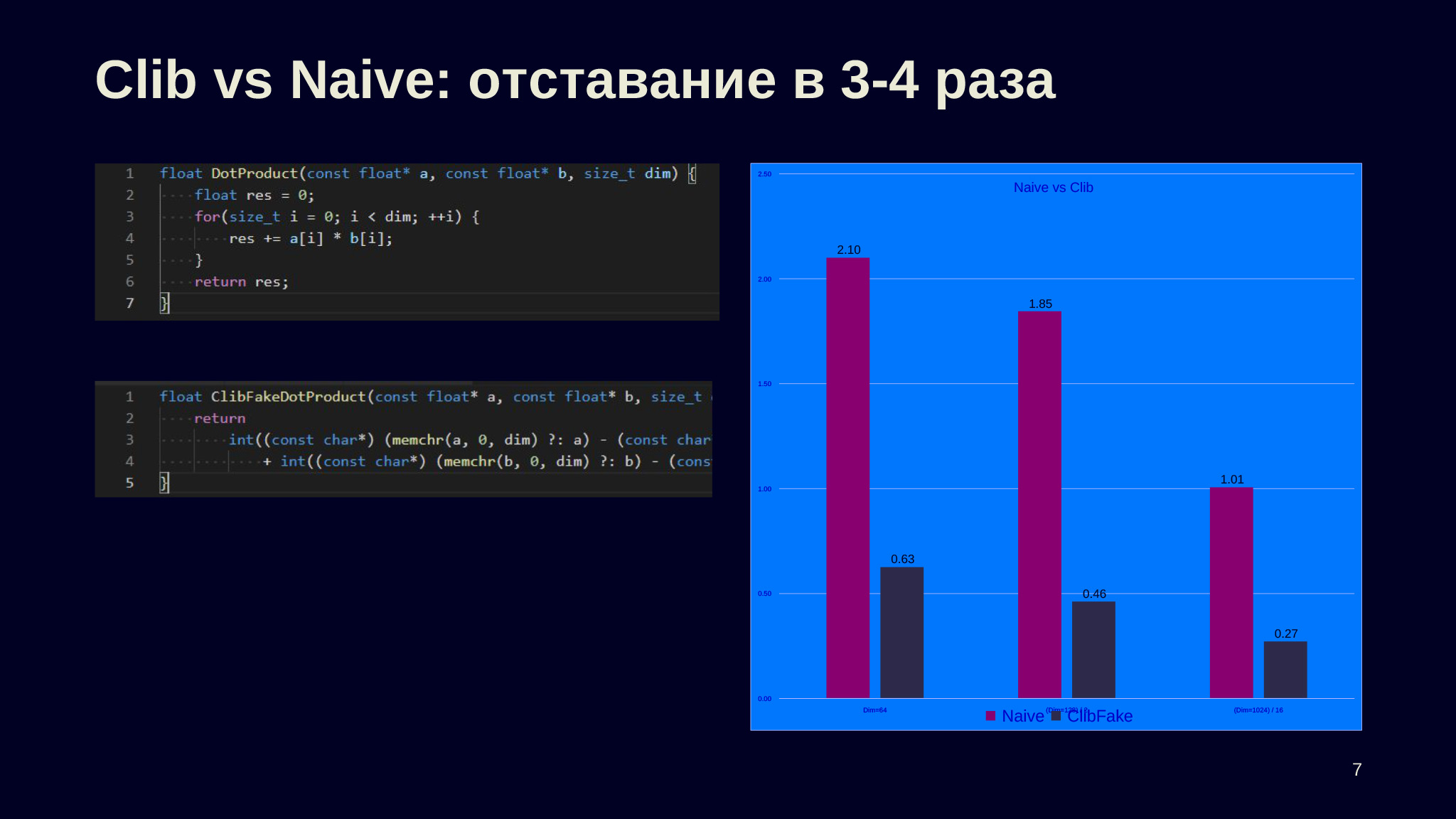
Когда мы измеряем — видим, что ожидания не оправдались: разница для размерности 64 больше чем в три раза, и почти в четыре раза разница для размерности 1024, что немного неожиданно. Первый вопрос, который стоит себе задать: почему так получилось, почему компилятор не справился?
Основной фактор, за счет которого современные компиляторы выполняют микрооптимизации, за счет которого растет производительность современных процессоров, — это векторизация. Первое, что стоило бы проверить: верно ли, что векторизация не применилась?
Методов такой проверки несколько. Во-первых, можно пойти в compiler explorer и посмотреть, сколько там идет итераций, выполнил ли компилятор раскрытие циклов и применил ли векторизацию.
Код в Compiler Explorer
Можно поступить иначе — написать векторизацию вручную и проверить, получится ли какое-то улучшение.
Сразу замечу: так как у нас практически все современные платформы умеют в 128-битные регистры, то сборка была с параметром SSE4.2, который даже на ARM имеет смысл. Поэтому компилятор имел право векторизовать, но он этого не сделал.
Вот код, где вручную раскрыты циклы по четыре элемента за раз. Замечу, что я здесь не учел хвосты, чтобы они влезали на слайды, и это будет касаться большого количества разных сниппетов. Специально выбраны удобные размерности — проблем с корректностью в рамках доклада не будет. Видим, что векторизация, которую мы сделали вручную, помогла. Она практически в два раза улучшила для размерности 64 и примерно во столько же раз в остальных ситуациях. То есть наша гипотеза о том, что векторизация по какой-то причине не смогла примениться, правильная.

Код в Compiler Explorer
Разгадка, почему так получилось, проста. Это связано с тем, что мы используем числа с плавающей точкой. Для чисел с плавающей точкой у нас не выполнена ассоциативность сложения или умножения, не выполнены хорошие свойства групп над умножением и сложением, которые позволяют делать разные полезные оптимизации, делать реордер. И так как в стандарте есть правило as-if, компилятор вынужден порождать код, который в точности соответствует тому, что мы написали. Поэтому он вынужден аккумулировать в единственный буфер (там у нас была переменная float res) промежуточные суммы в той последовательности, в которой мы их написали в коде, а это по одной паре элементов из последовательностей a и b за раз.
Есть workaround — параметр unsafe math optimization. Он позволяет компилятору применить те же оптимизации, которые он бы делал, если бы это были целые числа, в которых операции ведут себя намного лучше. На диаграмме четвертый столбец соответствует тому, что мы скомпилировали первый вариант с дополнительной опцией unsafe math optimization. Понятно, что был включен -msse4.2, который включен во всех столбцах.
Мы видим, что получили примерно то же самое, что и наша ручная оптимизация, когда мы делали по четыре элемента. Но получилось даже чуть лучше. Видимо, компилятор смог дополнительные неоптимальности, которые мы не учли, сделать лучше. Наверное, это хорошо, что мы смогли от компилятора добиться, чтобы он сделал свою работу и применил векторизацию.
Мы разобрались, что делать с векторизацией по четыре элемента со 128-битными регистрами. Давайте включим более новые возможности: для регистров в 256 и 512 бит.
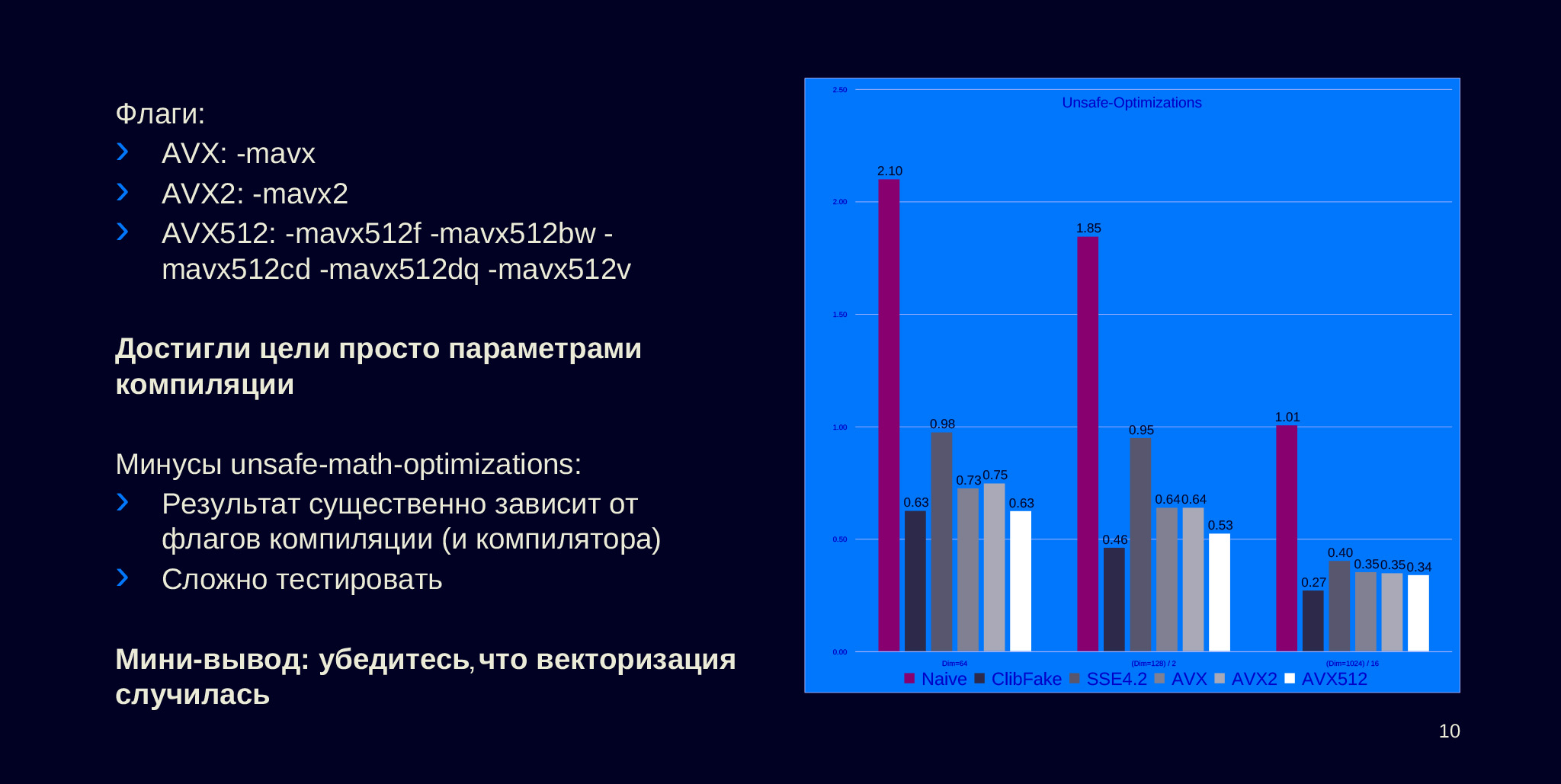
Это AVX, AVX2 и AVX512, которые позволяют работать с регистрами соответствующего размера, 256 для AVX, AVX2 и 512 для AVX512. Вот столбцы, они отличаются от предыдущих только тем, что изменились флаги компиляции: AVX и AVX2 скомпилировались с -mavx и -mavx2 соотвественно, а AVX512 с целой кучей разных опций — я включил всё, что было доступно.
Мы видим, что последний столбец, который скомпилировался с AVX512, достиг того же числа, которое мы себе задали нашей заглушкой — не настоящей реализацей через libc функции memchr. Наверное, это хорошо, что мы смогли добиться от компилятора своего рода оптимального подхода, то есть компилятор (в нашем случае clang) смог сделать DotProduct не хуже, чем некоторые другие, хорошо оптимизированные функции.
Видно, что мы достигли цели только для раздела 64. Видимо, для 128 и 1024 начинает влиять разница в том, какая операция работает: все-таки для memchr требуется лишь работать с целочисленным объектом, возможно, там проще. Но unsafe math optimizations стоит применять очень осторожно. Потому что когда мы начинаем применять эту опцию, результат работы — бинарный выхлоп нашей программы — начинает сильно зависеть от того, какие мы применили флаги компиляции, что порождает множество проблем.
Наверное, самые заметные из них — это сложности тестирования. Многие системы тестирования завязаны на проверку того, что выход программы соответствует тому, который ожидается. Если нет бинарной совместимости, то нам начинает требоваться проверять, не просто что ответ совпал, а что он достаточно близок к тому, который требовался, или какие-то другие условия. Предположим, у нас написана дополнительная логика. Например, мы делаем дополнительную сортировку объектов. Тогда у нас еще и порядок объектов может поменяться, что еще больше усложнит способ, которым нужно валидировать, выдала ли наша программа корректный ответ. Еще из самых понятных проблем: debug и релиз сборки начинают существенно отличаться по выхлопу, а это очень неудобно.
По последней паре слайдов можно сделать вывод: следует убеждаться, что векторизация случилась.
Лирическое отступление: гетерогенный парк и runtime-cpu-dispatching
Лирическое отступление по поводу того, что мы обсудили только что. Мы использовали несколько разных типов сборок под разные наборы инструкций. Отсюда вопрос: как доставлять код, который требует различных типов сборок, до рантайма, до продакшена?
В чем тут проблема? Если мы будем использовать наборы параметров компиляции по минимуму, набор, который работает на всех машинах, то мы будем использовать неполные возможности своего железа. Причем, как правило, надо учитывать: если мы используем облачные платформы, то они зачастую выдают не просто сырые ядра, а некоторые нормированные ядра. То есть размеры слотов, которые вы получаете в смысле логических ядер на машинах, могут быть меньше, чем вы заказывали, потому что в этом облачном провайдере считают производительность относительно какой-то одной модели процессоров. Поэтому на более новых, более производительных ядрах вам могут выдавать меньше ядер. Например, вы заказываете два ядра, а вам выдают 1,8, потому что для данной модели процессора таков коэффициент размена у этого облачного провайдера. Если включать максимальную опцию, будут получаться не работоспособные на младших платформах программы, которые будут падать с тем, что illegal instruction попытался выполниться.
Рассмотрим два способа решать эту проблему. Первый — делать несколько вариантов сборок, когда мы собираем несколько артефактов, склеиваем их в один архив, доставляем на нужные машины, нужные версии и проверяем, чтобы на них запустилась правильная версия нашего исполняемого файла. Проблемы у этого подхода следующие. Во-первых, сложность уносится со стадии разработки на стадию deploy. Во-вторых, это усложняет тестирование, потому что всегда приходится тестировать несколько программ и проверять их консистентность. У нас нет возможности запустить несколько версий кода в рамках одного процесса, что не позволяет нам юнит-тестами проверять, что несколько реализаций делают правильные вещи.
Второй вариант решения — runtime CPU dispatching, когда мы в рантайме пытаемся определить, какие наборы инструкций поддерживаются, и вывести правильную версию кода. Сразу оговорюсь, что мы работаем в рамках одной платформы на x86, но у нас разные модели процессоров. Если у нас есть разные типы инструкций, мы хотим компилироваться и на x86, и на ARM, то нам, скорее всего, придется все-таки делать несколько сборок. Этот подход лишен сложностей deploy, которые были выше: он оставляет проблему в руках разработчиков. Проблемы runtime CPU dispatching заключаются в том, что могут быть накладные расходы. Если реализовать этот подход неаккуратно, мы будем получать ухудшение производительности.

Так как уже был подготовлен стенд для замеров, то я сделал несколько разных вариантов реализации CPU dispatching и замерил их. Какой бы мы ни выбрали подход к runtime CPU dispatching, нам всегда нужно будет сделать несколько translation-юнитов, собрать каждый из них с нужным набором flag сборки, чтобы включить в них требуемый набор инструкций, слинковать их вместе. И дальше реализовать некоторую логику выбора конечной реализации, то есть сделать код, который выберет, какую из нескольких функций позвать.
Я сделал два простых варианта, которые сохранятся в глобальной памяти, флажки, которые проставляются перед вызовом main в инициализации глобальных объектов.
Первый вариант оптимистичный — он сначала проверяет старшие наборы инструкций. Второй пессимистичный — сначала проверяет, что на данной машине доступны только самые младшие из доступных вариантов.

Ещё один способ — сделать виртуальный вызов, то есть объявить некоторый интерфейс, сделать несколько его реализаций, а в глобальный объект инициализировать уже instance некоторой конечной реализации. Есть несколько других способов, но для иллюстрации, мне кажется, этого будет достаточно.
Так как замеры делались на машине, на которой был AVX512, то оптимистичный вариант показывает себя лучше всех, а пессимистичный хуже всех. Из этого делаем вывод: если у вас есть if'ы, которые вы не берете, делаете их несколько, в пессимистичном варианте — три, то это дорого. У нас, с одной стороны, большое замедление.
С другой, виртуальный вызов не так плох, здесь не такой большой проигрыш производительности, и это может быть хорошим дефолтом, потому что ваш налог на runtime CPU dispatching оказывается одинаковым и для старых, и для новых аппаратных платформ. Это делает вашу программу более предсказуемой в выполнении.
Тривиальный вывод: чем меньше доля кода, который выполняет runtime CPU dispatching, и чем больше доля кода, который непосредственно делает работу, — тем меньше накладные расходы. Еще видно, что по мере того, как увеличивается размерность, накладные расходы уменьшаются, и все варианты в RCD склеиваются в одинаковое число. Это конец лирического отступления.
Оптимизации lvl2
Вернемся к нашей задаче, к оптимизации. Поговорим про то, что можно сделать, если рассматривать не маленькие участки кода, а работать с бóльшими блоками кода.
Как вы помните, задача строилась так: у нас один запросный эмбед и несколько документных. Но я, не замечая этого, стал сразу работать с функцией, которая всегда принимала один запрос-эмбед и один документный объект и умножала.
Но можно попытаться сделать оптимизацию, которая использовала бы тот факт, что запросный эмбед у нас один и тот же для всех документных. Чтобы проиллюстрировать, я написал простую функцию, которая принимает один запросный эмбед, два документных и возвращает не одно скалярное произведение, а два — А с В и А с C.
Как видно на замерах, мы получили заметное ускорение в сравнении с базовым вариантом, когда мы делали два вызова Dot Product на двух документных эмбедах. Важно, что эта оптимизация ортогональна векторизации. Значит, если мы все-таки будем работать с исходной задачей, когда мы получаем отдельно запросный эмбед и отдельно все документные эмбеды, то это откроет нам некоторый потенциал для улучшений.

Код в Compiler Explorer
Я подобрал, сколько объектов нужно брать за раз. Предположим, мы возьмем по четыре элемента за раз и включим все те оптимизации, которые мы получили на предыдущей стадии: то есть скомпилируем под AVX512, с unsafe math optimization. Оказалось, тогда мы получим 20% выигрыша по сравнению с тем, что было, когда мы работали с другой сигнатурой функции, когда мы всегда получали по два объекта: один запросный и один документный эмбеды.
Быстро скажу, что у нас здесь получает функция, потому что с данной сигнатурой мы будем работать и дальше. Первым аргументом она получает буфер, в котором лежат элементы запросного вектора. Дальше все документные эмбеды, которые сложены в dense-матрицу. Размерность — третьим аргументом, как было в предыдущих вариантах. Номера строк в матрице, с которой нам нужно сделать умножение, — в четвертом аргументе. Размер этой последовательности и куда сложить результаты — пятым и шестым аргументами.
Вот ссылка на Compiler Explorer на godbolt.org. Можно посмотреть, что происходит и за счет чего получается выигрыш.
Код в Compiler Explorer
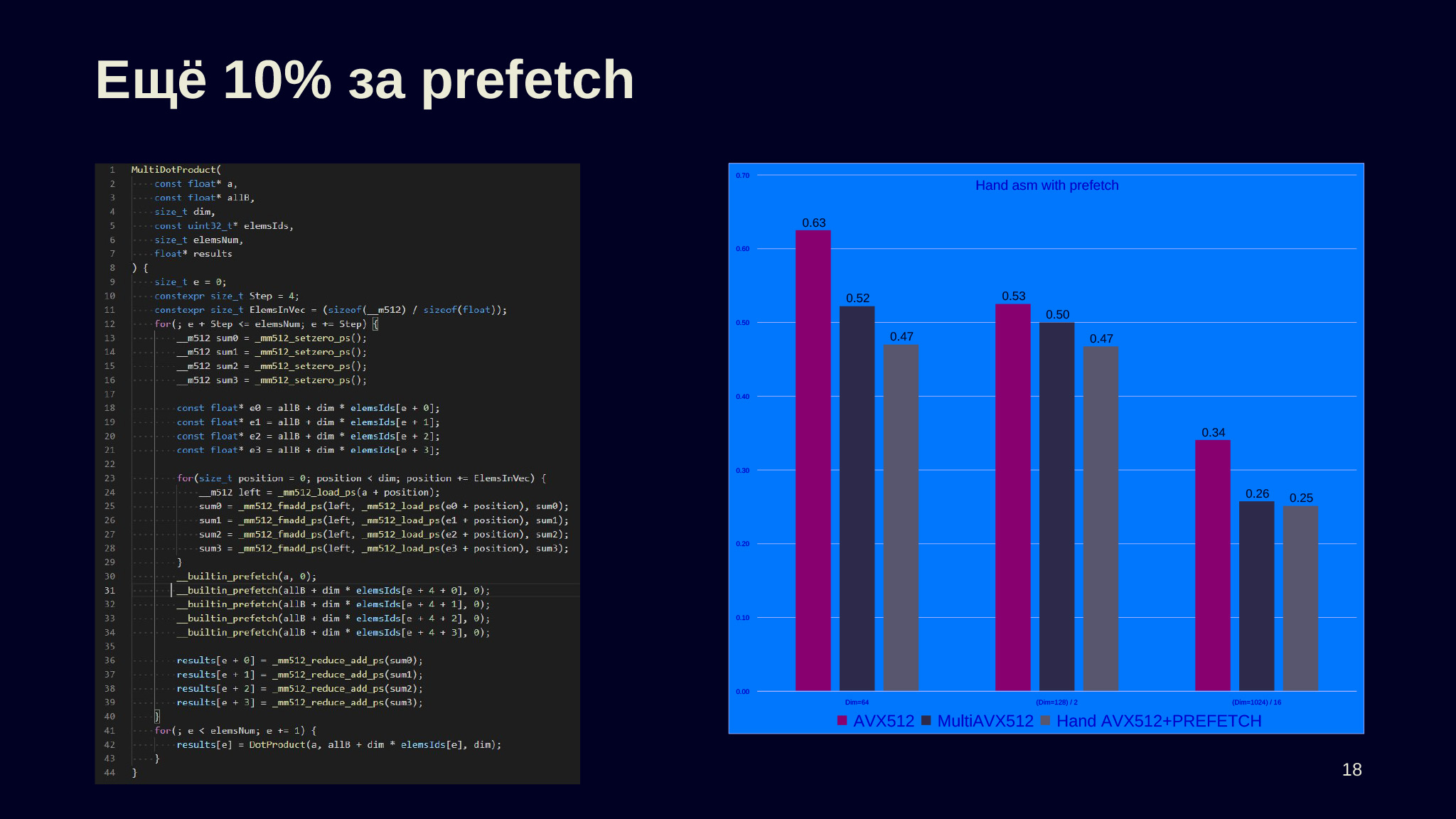
Ещё один метод, который позволяет выжать ещё немного, — это prefetch. Иногда он применим. У нас работа с памятью асинхронна, более того, память и кэш многоканальные, можно попросить процессор подгрузить в кэш некоторый участок памяти с помощью __builtin_prefetch так, чтобы, когда он понадобится уже для загрузки в регистры, он оказался в cash и мы не ждали, пока нам ответила память.
Код здесь переписан на библиотеку интринсиков от Intel, то есть напрямую используются векторные переменные и векторные инструкции. Здесь ничего сложного нет, можно взять Compiler Explorer с предыдущего слайда и посмотреть, как это сделано, написать на нем. Вместо того чтобы делать builtin-операции типа оператора плюс, надо звать mm_reduce_add_ps, чтобы сложить, или fm_add_ps, чтобы умножить два объекта, сложить их с третьим. Иногда такой трюк с prefetch помогает.
На основе этого — небольшое лирическое отступление. Зачем писать на ассемблере? Первое: оптимизация не всегда справляется, и напрямую написав, что вам нужно сделать, вы можете обогнать компилятор. Мне кажется, иногда более важно, что вы, сделав так, можете точно задать семантику. В частности, отказаться от этого unsafe math optimization. Предположим, у вас есть четкий порядок того, что вы вычисляете, что с чем складываете. Тогда, если вы целитесь в максимальную производительность на старших аппаратных платформах, вы можете для более слабых попытаться сделать эмуляцию более старших.
Обычно вам вместо того, чтобы иметь один набор регистров, нужно в два раза больше. Например, если вы пытаетесь AVX-инструкции вычислять с помощью SSE-инструкций, то таким образом вы можете получить бинарно совместимые реализации на разных аппаратных платформах. Это сложно и дорого, но если это core-часть вашего приложения, иногда можно на это потратиться.
Оптимизируем память
Оптимизируем память, которую потребляет наша задача умножения запросного эмбеда на некоторое подмножество документов. Почему нам может захотеться оптимизировать память? То, сколько места в памяти занимает наша база объектов, определяет, сколько объектов мы можем хранить у себя.
Представим: к нам приходят люди, которые занимаются продуктом, и говорят, что хотят хранить не 100 миллионов объектов, а 400 миллионов или миллиард. Понятно, почему это может быть важно: потому что, скорее всего, мы делаем ML-приложение и в нем есть размен: вы более точно вычисляете близости с хорошо отобранными объектами — или менее точно вычисляете близости между бóльшим множеством объектов и добираете в качестве продукта за счет полноты.
Какие есть варианты решения задачи увеличения количества объектов в базе? Первый вариант — налить больше железа: увеличить размер доступной памяти в инстансах, а если это уже невозможно, если мы достигли вертикального предела, то требуется сделать шардирование. Во-первых, это всегда увеличивает стоимость, потому что вы просите более тяжелые поды. Во-вторых, шардирование — это всегда сложно, потому что возникает множество попутных проблем: шардированные базы нужно правильно выкладывать, уже должен быть объект, который делает опрос в режиме broadcast к нескольким инстансам и правильно дожидается ответов. Сделать шардирование всегда намного сложнее, чем иметь один инстанс, внутри у которого есть вся полнота информации.
Второй вариант — сжимать векторы. Это ухудшит точность и, возможно, будет стоить больше по CPU. Давайте рассмотрим второй вариант, потому что, если он применим, то, конечно, стоит на нем остановиться. Так дешевле и проще в эксплуатации.

Какие есть способы сжимать векторные представления? В наших задачах применим простой метод: равномерное преобразование в один байт в UInt8. Почему оно хорошее? Во-первых, это fixed-length-преобразование, у нас размер координаты эмбеда сначала был четыре байта, стал один байт. Таким образом по номеру объекта, если данные непрерывно разложены в памяти, мы всегда можем найти, где находится участок конкретного документа. Восстановление, то есть обратное преобразование, — это линейная операция, значит, она простая и не будет стоить много.
Третье, самое важное: полученной точности, по крайней мере в наших задачах, зачастую хватает. При этом стоит понимать, что есть разные варианты улучшения точности. Как правило, у нас есть некоторое распределение значений всех координат, мы находим минимум, максимум и из этого вычисляем, каковы коэффициенты преобразования, сжатия в целое число от нуля до 255. Если полученное число не входит в интервал, мы меняем на ноль ниже границы интервала и на 255 — выше, а потом оставшееся преобразуем в int и получаем сжатое целочисленное значение, отбрасывая часть после точки.
Можно улучшать сжатие. Например, не брать глобальный минимум и максимум, а взять первую и 99-ю квантили и отсекать хвосты, таким образом увеличить точность сжатия для середины распределения. Можно сделать то же самое, но не для всей матрицы целиком, а для каждого коэффициента отдельно.
Справа написан простой способ «вылить воду из чайника»: мы, чтобы сделать умножение, сначала разжимаем каждый элемент во временный буфер, а затем вызываем одну из версий функции, которую мы рассматривали в первой части доклада и которая принимает два буфера и размерность. Что еще поменялось тут с точки зрения сигнатуры? Третья строчка: у нас теперь не float*, а uint8*, которая представляет все объекты.

Базовый вариант, четыре умножить на размерность объектов, в них обычные float. Второй столбец — лучшая версия, которую мы получали в этом подходе. Третий столбец — тот же, что был на предыдущем слайде. Последний вариант почти не отличается от третьего, только в качестве функции умножения разжатых векторов выступает самая быстрая версия. То есть в третьем столбце мы после разжатия для вычисления произведения векторов вызываем вариант из первого столбца, а в четвертом — из второго.
Видим значительное увеличение стоимости по сравнению с самой оптимизированной функцией. Но если рассматривать первый и третий столбец, видим, что стало даже лучше. Это, может быть, немного контринтуитивно, но понятно, почему так может произойти. Потому что, если говорить про размерность 64, мы стали высчитывать не 64 на четыре байта из памяти, чтобы сделать умножение одного документного эмбенда-запроса, а всего 64. Вернее, мы высчитываем их в буфер, но наверное, буфер у нас почти в кэше, поэтому в среднем мы можем здесь выиграть.

Код в Compiler Explorer
Можно попробовать вспомнить математику. Линейное преобразование, которое написано в скобках, можно записать на листочке, сделать нехитрое преобразование, перестановку переменных и придумать такую оптимизацию как в варианте справа, когда мы разжимаем не каждый элемент прежде, чем его умножить, а результат умножения.
Теоретически, нужно сделать меньше каких-либо операций и это должно помогать. Но, как мы видим по замерам, стало даже хуже. То есть четвертый столбец, где мы применили эту оптимизацию выносом действий за скобки, — хуже по метрикам. Это как раз тот пример, когда наши умные действия в некотором роде помешали компилятору, усложнили его работу.
Возможно, стоит остановиться и сделать вывод: если мы хотим в четыре раза выигрывать память сжатием в один байт, то будем в несколько раз проигрывать по производительности. Если смотреть самые оптимизированные версии 0,47, то на предыдущем слайде у нас была версия 1,52, это примерно в три раза хуже.
Но я тут призываю вас не позволить компилятору обмануть себя. Потому что мы все-таки помним, что фактически основным узким местом для всего процесса было именно общение с памятью, как часто бывает для число-дробительных задач, а необходимый foot print для работы со сжатыми данными в четыре раза меньше.
Код в Compiler Explorer
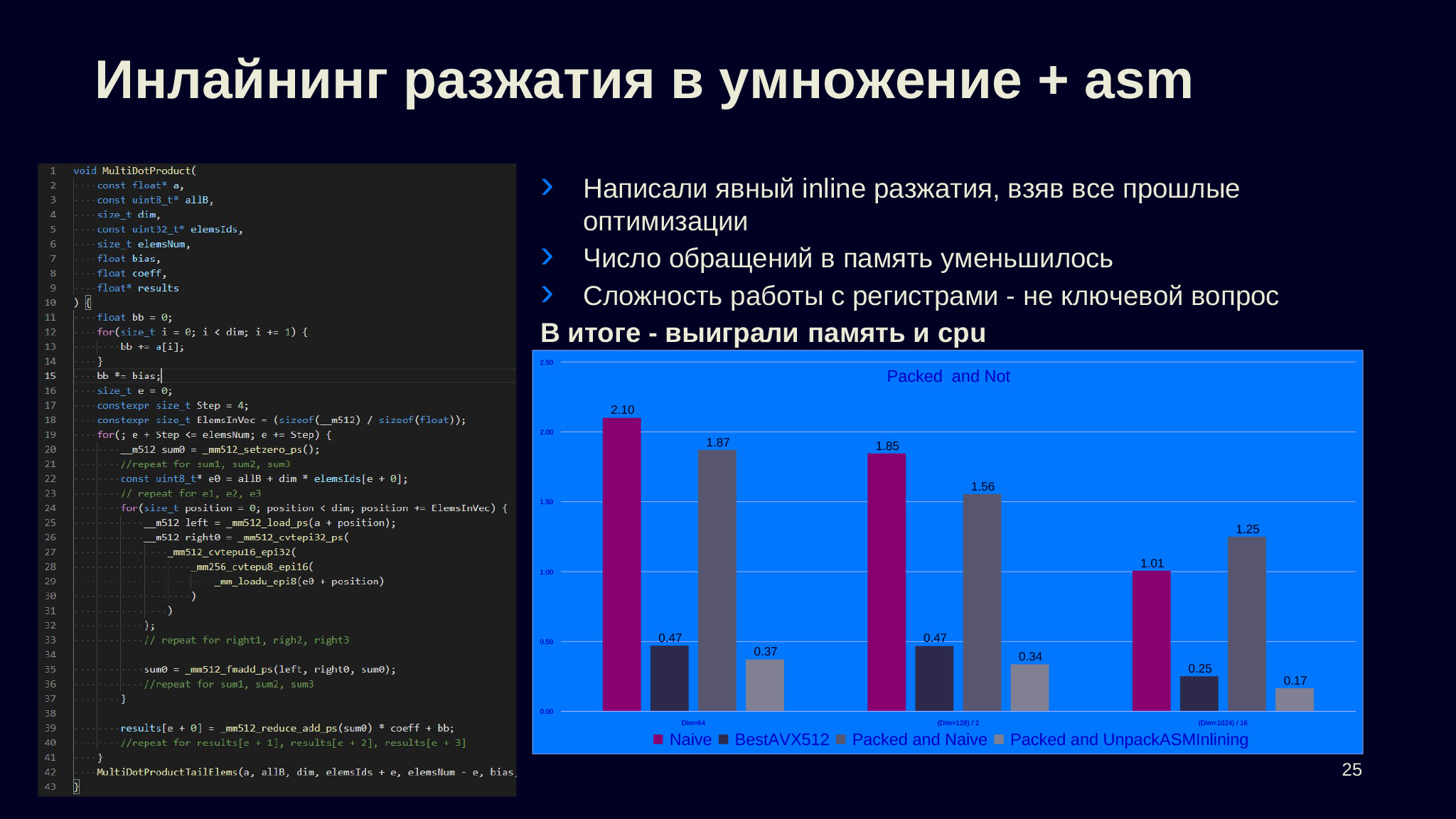
Если переписать то, что сам компилятор выдает в Compiler Explorer на интринсиках, и аккуратно следить, чтобы мы не делали лишних походов в память, а все необходимые преобразования делались уже на регистрах, то окажется, что мы выиграем относительно самой оптимизированной версии на четырех байтах.
Пару пояснений по коду. Во-первых, здесь опущены некоторые дублирования. Во-вторых, в строке 26 идет загрузка для 512 байт, мы здесь загружаем один 128-битный регистр; потом разжимаем его в 256-битный, где перемешаны байты, чтобы были представлены 16-битные целые числа; потом байты опять перемешиваются; и мы получаем 512-битный регистр.
Все эти преобразования между целочисленными типами — простые операции перестановки битов, а конвертация из epi32 в ps — это уже сложная операция: нужно посчитать для каждого из запакованных значений мантиссу, порядок и потом получить представление для чисел с плавающей точкой. Это примерное изменение, которое делалось с лучшей версией из первого раздела. Напомню, что на замерах она нам давала 0,47 мс, а данная версия дает 0,37 мс. То есть мы смогли сделать такую версию, которая в четыре раза лучше по памяти и еще на 20% лучше по CPU, чем эта же оптимизированная версия, что не может не радовать.
Второе лирическое отступление

Примеры библиотек: half и float16 в CatBoost
Прежде чем перейти к завершающей части — небольшое отступление про float 16. Это другой метод сжатия данных с потерей точности, который широко применяется: почти все современные нейронные сети на GPU учатся на float 16, потому что точности хватает для работы. Сама модель, конечно, становится хуже. С другой стороны, так как числа стали в два раза меньше, вы можете сделать ее заметно больше. И этот размен, в котором вы делаете модель больше, но отдельные ее компоненты, отдельные веса, пусть будут сделаны менее точно, позволяет вам строить модели гораздо лучше. Более того: во float 16 вы можете быстрее их учить, в GPU хорошая аппаратная поддержка float 16, поэтому на нем почти всегда учат нейронные сети.
Это очень хороший дефолт, чтобы сжимать FP32-числа, если вы их предварительно загнали в интервал (-1; 1). Предположим, у вас есть числа, для которых вам, с одной стороны, нужно сохранять точность на значениях, близких к нулю. А с другой стороны, у вас бывают выбросы, заметно большие по значению объекты, и там вы тоже не хотите совсем уходить в максимум, сжимать всё в одну точку.
FP32 — это всего 65 536 значений. И это мало, поэтому лучше сжать в интервал (-1; 1). Вы потеряете один бит, знак мантиссы всегда будет не положительным, но вы сможете использовать все остальное. Это удобно.
Замечу, что в современном железе есть соответствующая поддержка — в процессорах x86 это флаг FP16C, инструкция, которая позволяет конвертировать представления float 16 в регистры float 32. И дальше работать с ними, как с обычными данными float 32. По своему опыту скажу, что с данными float 16 можно ожидать того же эффекта, который мы получили с uint8. То есть вы остаетесь в плюсе за счет уменьшения foot print и того, что вы потратили немного времени процесса на преобразование из неудобного формата FP16 в родной формат FP32.
К сожалению, в языке нет прямой поддержки, то есть нет built in-типа, который представлял бы данные float 16. Понятно, почему: там много разных сложностей. Когда вы складываете два числа FP16, непонятно, должны ли вы их складывать как числа FP32 с обратным преобразованием результата в FP16 или, например, делать всё над FP16. Современные процессы x86 не умеют эффективно вычислять второй вариант.
Есть часто используемые библиотеки, например half. Или можно посмотреть кастомные реализации, например ту, что доступна в репозитории CatBoost. Это всё, что мне хотелось сказать про float 16.

Мы подходим к концу доклада. Что нужно не забыть, если мы оптимизируем код?
- Если мы занимаемся микрооптимизациями, то очень желательно иметь опорную точку, бенчмарк, по которому вы понимаете, хорошо вы сделали свою работу или нет. Важно следить за числом походов в память, постоянно говорится, что это один из самых главных моментов, на которые стоит обращать внимание при оптимизации для современных платформ. И, конечно, векторизация — я много о ней говорил в докладе.
- Оптимизация возможна и на уровне архитектуры. Часть оптимизации, которую мы выполнили, была бы невозможна, если бы мы остановились на функции с первого слайда на семи строках, где она принимала три аргумента. Очень важно выбирать уровни абстракции, которые, с одной стороны, позволяют удобно оперировать объектами, делать несколько разных оптимизаций, а с другой — не дают вам налога за неправильно выбранную границу между разными компонентами.
Например, если уровнем деления является вариант сигнатуры от трех аргументов, то в RCD мы бы получали много налогов и не могли выполнять те оптимизации, которые сделали в ситуации с одновременным умножением на несколько объектов. - И самое важное. Предположим, мы не можем отойти от концепции zero-diff-оптимизации, не меняем результат работы программы, а жестко завязаны на требуемую логику, черный ящик: при заданном входе выход не должен поменяться. Тогда мы часто не способны сделать некоторые вещи, которые в разы эффективнее. Да, здесь мы говорили про float-числа, но тем не менее.
Например, когда мы смогли отказаться от работы с float-представлениями объектов, а согласились на возможность сжатия данных, то сильно уменьшили объем нашей базы и в итоге даже получили увеличение производительности по CPU.
В качестве девиза предлагаю такой: оптимизируйте на всю глубину — от постановки до инструкций. Хорошо, что мы с вами работаем на языке С++, который позволяет это делать. Нам удобно, с одной стороны, описывать бизнес-логику, объекты высокого уровня, с которыми мы работаем, а с другой — опускаться до уровня инструкций и выедать каждый процент перфоманса.
