
Yandex Rate Limiter (далее просто YARL) — это сервис лимитирования нагрузки для распределённых сервисов. Его особенность в том, что он способен работать с миллионами квот, имея при этом очень низкие накладные расходы на проверку квоты. Если совсем кратко, это система распределённых Leaky Bucket'ов, с помощью которых можно ограничивать разные величины, связанные со временем: скорость передачи данных по сети, запросы в секунду и т. п.

Меня зовут Денис Кореневский, я работаю в службе разработки внутреннего хранилища Яндекса, и сегодня я расскажу, как YARL устроен внутри, почему мы вообще написали своё решение и с какими трудностями нам пришлось столкнуться в процессе создания. Добро пожаловать под кат.
Предпосылки создания YARL и контекст задачи
Компания Яндекс существует уже больше 20 лет. За эти годы мы научились обрабатывать огромные нагрузки: миллионы запросов в секунду, терабиты в секунду, миллионы уникальных адресов клиентов.
В общем, глупо было бы думать, что в Яндексе за столько лет не научились искусственно ограничивать нагрузку на сервисы по разным показателям. Разумеется, до появления YARL уже существовало несколько внутренних решений, предназначенных для ограничения нагрузки на сервис, так что сразу не понятно, зачем было придумывать ещё один.
Мы искали способ ограничить нагрузку на внутренний сервис S3. Это наша собственная реализация хранилища, совместимого со спецификацией Amazon S3. S3 предоставляет вам key-value-хранилище неограниченного размера с неограниченным количеством ключей. Лишь бы денег хватило :)
Внутренний S3 Яндекса вы никогда не видите, но постоянно им пользуетесь. Клиентами для нас являются целые сервисы Яндекса. У нас хранятся данные мобильных приложений, статика сайтов, видеофайлы и ещё много всякого разного. Когда вы заходите на КиноПоиск или открываете Яндекс.Клавиатуру у себя в телефоне, вы почти всегда хоть что-нибудь да скачиваете из S3 Яндекса.
В таких условиях критически важно ограничивать потребляемые клиентами ресурсы, чтобы поломка у одного из наших клиентов не влияла на S3, а за ним и на кучу других сервисов Яндекса.
С размером хранимых данных всё достаточно просто и понятно: ресурс накапливаемый, никак не связан со временем, считать его можно спокойно и рассудительно, а скорость реакции на превышение квоты большой роли не играет: петабайты места быстро не сожрёшь.
Гораздо сложнее с производными: запросы в секунду, трафик и т. п. Такие вещи могут «взмыть в небо» практически мгновенно и принести с собой очень много проблем. Реагировать на изменение нагрузки нужно быстро, чтобы уменьшить шансы превратиться в тыкву или хотя бы сократить время деградации.
Совсем крупными блоками архитектуру S3 в Яндексе можно представить следующим образом:
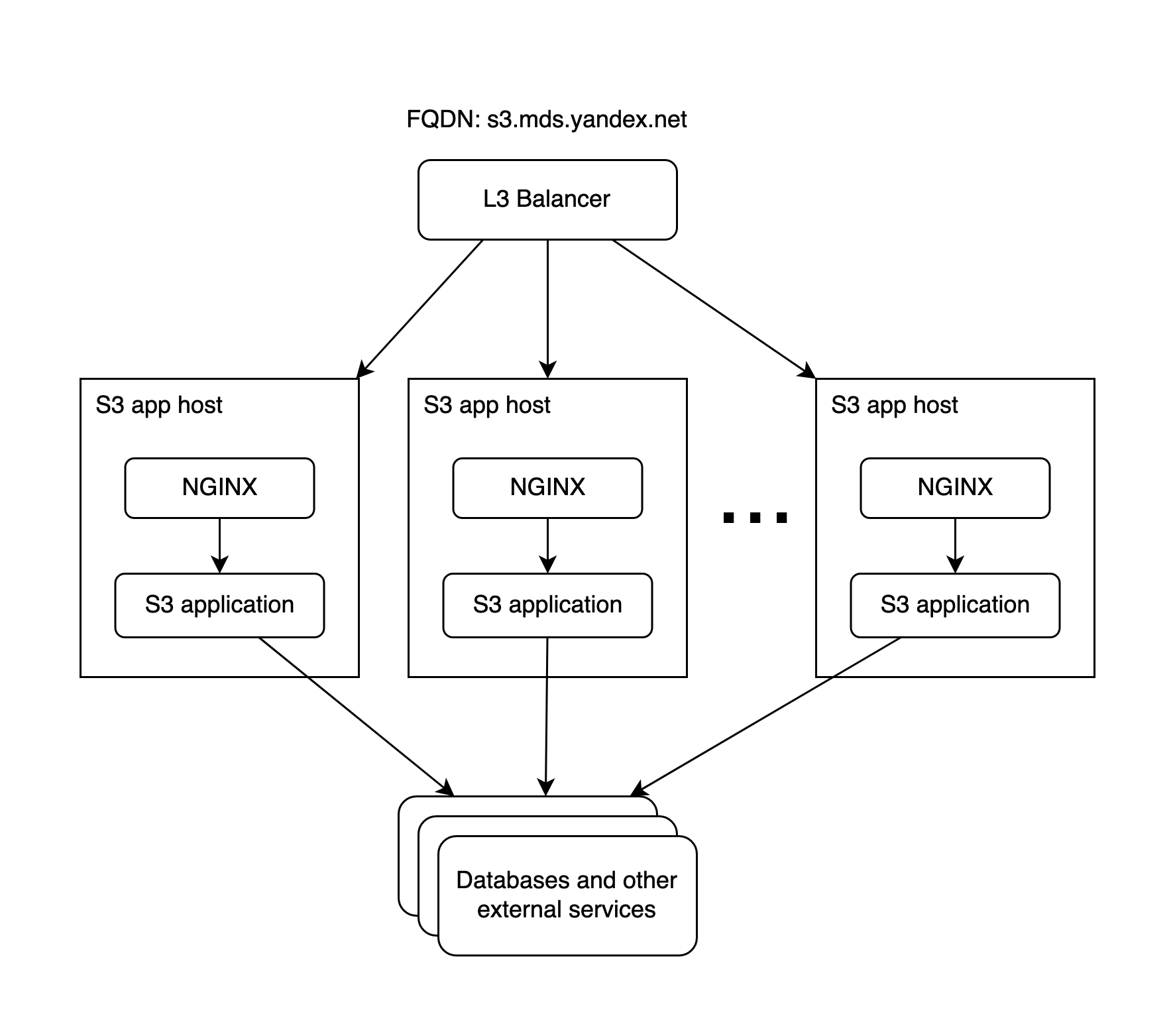
Все клиенты S3 приходят к нам через L3-балансер. Он не отличает запрос в бакет А от запроса в бакет B, так что ограничивать на нём трафик и RPS можно только очень грубо: сразу для всех и без разбора по типам запросов.
Каждый хост S3 состоит из nginx'а, под которым находится наше приложение. Nginx терминирует на себе HTTPS, предоставляет всякие полезные штуки типа кеша, буферизации запросов и поставки метрик для построения графиков. Обработку запросов, как обычно, выполняет приложение.
«В nginx же есть стандартный механизм лимитирования», — скажете вы, и будете совершенно правы! Именно его мы и использовали до появления YARL — и используем до сих пор. Как всегда, дьявол кроется в деталях.
Поскольку nginx у нас поднят на каждом хосте, лимиты в таких nginx'ах друг с другом никак не связаны, а nginx’ы ничего друг о друге не знают. Это значит, что, имея 100 хостов в ДЦ и возможность безболезненно обрабатывать ими суммарно  , мы получаем
, мы получаем  на сервер при равномерном «размазывании» нагрузки. Именно так мы и выставляем лимиты в nginx.
на сервер при равномерном «размазывании» нагрузки. Именно так мы и выставляем лимиты в nginx.
Проблемы начинаются при неравномерном распределении нагрузки. Можно запросто получить картину, когда после «выпадения» 10–20 машин (переналивка, проблемы с сетью, обновление версии и т. п.) возникнет перекос и на перегруженных серверах начнёт «постреливать» локальный лимитер nginx'а. Если узким местом является не само приложение, а его бэкенды (база, например), тогда важно следить за общей нагрузкой на кластер, а не за конкретными тачками. В таких условиях даже при живых 70 % кластера сервис всё ещё может обрабатывать те же  . Nginx ограничивает RPS своего хоста, так что уменьшение размера кластера закономерно уменьшает суммарный лимит на RPS. В итоге мы начинаем резать тот трафик, который вполне можно было безболезненно обработать.
. Nginx ограничивает RPS своего хоста, так что уменьшение размера кластера закономерно уменьшает суммарный лимит на RPS. В итоге мы начинаем резать тот трафик, который вполне можно было безболезненно обработать.
Ещё один сценарий: внезапно к нам приходит клиент с очень противными и тяжёлыми запросами. Это нагружает нашу базу или какой-то другой бэкенд, от чего страдают другие сервисы, использующие S3. Нам бы взять и «вот прям щас» срочно урезать этого клиента, чтобы другие не страдали. В схеме со встроенными лимитами nginx нам придётся быстро поменять конфигурацию, быстро раскатать её по серверам, сделать reload и убедиться, что изменения подействовали так, как мы хотим. Это время, которого в таких ситуациях уже нет.
Ко всем радостям, описанным выше, добавляется то, что во внутреннем S3 у нас десятки тысяч бакетов, а разные типы запросов в API имеют разную стоимость: сделать листинг бакета с парой миллионов объектов сильно дороже, чем создать один объект размером 5 мегабайт. Поэтому нужно как-то понимать стоимость запроса, прежде чем принимать решение кинуть в клиента HTTP 429.
Получается, что нам нужно не только раскладывать общий входной поток запросов по бакетам, но ещё и внутри одного бакета разделять его на группы. В идеальном мире хотелось бы иметь возможность ограничивать нагрузку вообще на конкретные объекты, но мы понимали, что число объектов исчисляется сотнями миллионов на бакет и триллионами на всю инсталляцию. И продолжает неуклонно расти. На такое никаких ресурсов не хватит.
Думаю, теперь стала понятна сложность задачи. Нам была нужна система, которая:
- способна поддерживать несколько сотен тысяч квот сейчас и несколько миллионов в будущем: нужен запас на рост, не хочется полностью переделывать конструкцию через пару лет;
- при поломке не утягивает за собой сам сервис: если сдохла система лимитирования, S3 должен просто лететь дальше как раньше, но уже без лимитов;
- позволяет править квоты на лету в единой точке, без перезагрузки демонов и раскатывания конфигураций по машинам;
- легко встраивается в Go-код: наше приложение S3 написано на Go и очень логично встроить основную логику лимитирования именно в него: оно уже обладает всеми необходимыми знаниями об API S3, умеет парсить запросы, в нём легко понять «вес» любого запроса без дополнительных телодвижений;
- обладает маленьким временем реакции на всплеск нагрузки — в пределах нескольких секунд;
- в любых условиях либо совсем не влияет на тайминги, либо влияет незначительно — чем меньше факторов могут увеличить наши тайминги, тем лучше.
Из-за последнего пункта мы не хотели ходить за разрешениями во внешний сервис. Было бы здорово просто спросить по HTTP какую-то систему лимитирования, получить в ответ вердикт «клиента можно пустить» и начать обрабатывать запрос. Но если такой внешний сервис ляжет, мы начнём ждать таймаутов и в этот момент S3 заметно просядет в скорости ответа.
Архитектура YARL и основные детали реализации
С вводной частью покончено, смысл задачи и требования понятны. Перейдём к делу.
Сервис, использующий YARL, выглядит примерно так:
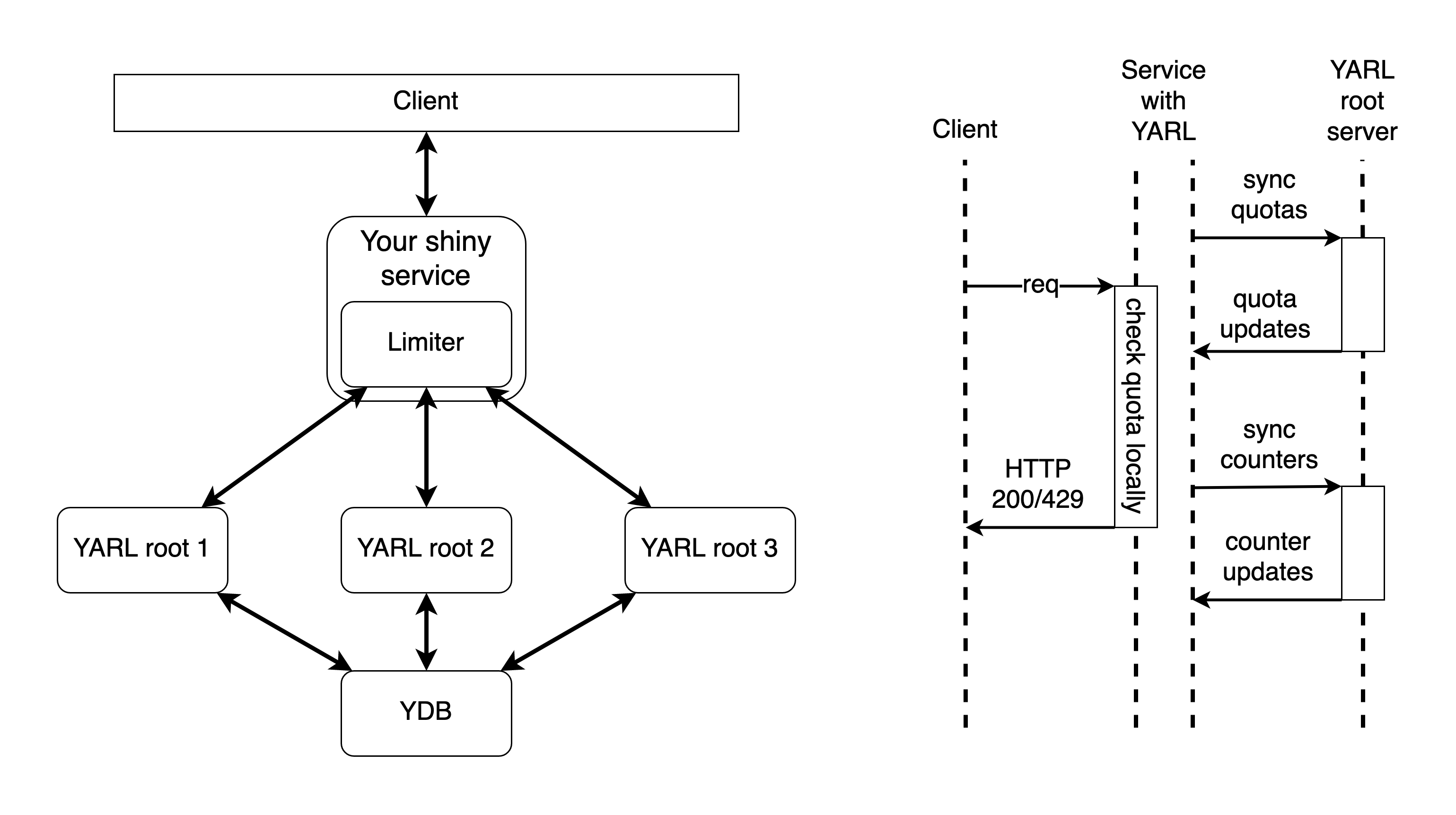
Главная прелесть YARL в том, что все проверки лимитирования он выполняет строго локально, и это значит, что:
- время ответа сервиса после внедрения YARL практически не меняется (конечно, есть накладные расходы, но они в основном сосредоточены в памяти и CPU, а в отношении времени ответа это мизерные расходы);
- отказ YARL никак не затрагивает работоспособность сервиса и время ответов — просто временно перестанет работать распределённое лимитирование, и восстановится само, как только инфраструктура YARL вновь станет доступна.
В начале статьи я упомянул, что YARL’ом можно лимитировать любую величину, нормированную по времени. Для этого достаточно добавить в интерфейс проверки лимита обязательное указание «веса» запроса. Вес — это величина, на которую нужно накрутить счётчик, чтобы обработать запрос. Так можно измерять нагрузку в тех величинах, которые нам привычны в конкретной задаче: в килобайтах, запросах, объектах… В общем, в том, что душа пожелает (или больная фантазия — тут у кого как). Для YARL это просто числа, которые он сравнивает, чтобы понять, какое из них больше. Например, можно выставить в YARL квоту в 100×1024×1024 байт в секунду (100 КБ/с), а для каждого входящего запроса накручивать счётчик квоты на размер запроса в байтах. Так мы можем управлять запросами с разным весом.
Чтобы не указывать на эту особенность каждые пару абзацев, говорить дальше я буду об ограничении запросов в секунду (RPS). Давайте просто условимся, что ровно всё то же самое применимо и к любой другой величине, которую можно охарактеризовать словом «скорость». Просто для подсчёта RPS мы всегда указываем вес запроса равным единице: один запрос → +1 к значению счётчика.
Квоты и счётчики
Итак, в YARL есть две основные сущности: счётчик и квота.
Представьте себе ведро, в котором просверлили дыру в дне. В это ведро постоянно поступает вода (запросы). Если запрос попал в ведро, он будет обработан сервисом. Ведро постепенно опустошается через дыру, так что в нём появляется место для новых запросов. Когда через дыру вытекает больше воды, чем наливается сверху, мы успеваем обработать все запросы. Если сверху начнёт течь больше, чем вытекает через дно, то ведро начинает потихоньку наполняться. В этом нет ничего страшного, ведь объёма ведра хватает для небольшого излишка. Когда поток уменьшится, всё постепенно придёт в норму: лишняя вода дотечёт до дна и выйдет из ведра. Но если сильный поток не угасает, то в какой-то момент ведро заполнится. Тогда вода начнёт переливаться через край. Это те запросы, которые мы ограничили, то есть не стали полноценно обрабатывать, а просто ответили клиенту: «Приходите позже».
Так выглядит технология Leaky Bucket, на базе которой работают квоты.
Важных полей у квоты немного:
- id — уникальный номер квоты. Нужен для идентификации квоты и её связи со счётчиком.
- parentID — ID родительской квоты. Позволяет выстраивать квоты в иерархию.
- epoch — эпоха, сквозной счётчик изменений всех квот в базе. Эта штука нужна для экономии трафика во время синхронизации данных.
- uniqueName — уникальное имя квоты.
- limit — величина утечки (диаметр той самой дыры в дне).
- lowBurst и highBurst — два показателя переполнения (показатели объёма ведра). Зачем два — объясню чуть позже.
Одна из частей YARL’а называется Limiter. Он встраивается в код приложения, исполняемого на сервере. Limiter хранит все квоты и счётчики в памяти и регулярно синхронизируется с корневым сервером (YARL root), получая от него оперативную информацию о свежих значениях.
Каждый раз, когда кто-то меняет квоту (обновляет лимиты, например), сервер обновляет её поле epoch так, чтобы оно стало на 1 больше всех других эпох в базе. Таким образом, при синхронизации Limiter может сообщить серверу свою самую свежую эпоху, а в ответ получит только обновления (квоты с большей эпохой). Так синхронизация почти не жрёт сеть. Трафик будет напрямую зависеть от того, сколько квот вы создаёте, изменяете или удаляете в секунду, обычно это значение близко к нулю.
Вторая важная сущность — счётчик.
Счётчик с помощью магии CRDT считает суммарную нагрузку на сервис. Зная значение счётчика, Limiter может посмотреть на связанную с ним квоту и понять, как поступить с запросом.
Суть CRDT сводится к тому, что мы разделяем значение счётчика на две части: ту, что считается локально, и ту, что насчитал весь остальной кластер.
Во время синхронизации Limiter отправляет серверу только то, что насчитал сам, а в ответ получает суммарное значение для всего кластера. Получается, что в каждый момент времени Limiter знает общую нагрузку на кластер, но изменяет только ту часть счётчика, которая хранится у него локально. Сервер, получая числа от всех клиентов, может в любой момент вычислить суммарную нагрузку, и никаких конфликтов при обновлении данных не возникнет: каждый клиент трогает только свою часть счётчика.
В синхронизации счётчиков тоже можно немного сэкономить, если не пересылать данные, которые не менялись с момента последней синхронизации. К сожалению, тут экономия уже не такая ощутимая, как с квотами.
Синхронизация и отказоустойчивость
На схеме видно, что в инсталляции YARL есть несколько root-серверов. Это вполне стандартное решение для обеспечения отказоустойчивости, но в нём есть несколько хитростей:
- Во время синхронизации счётчиков Limiter’ы шлют свои данные на все root-серверы, о которых знают. Тут нет master’а, все root-серверы одинаковые.
- Root-серверы ничего не знают друг о друге. Они смотрят только в базу и периодически читают оттуда квоты. Счётчики хранятся только в памяти каждого root. Получается, что счётчики между root-серверами не синхронизируются никак, а квоты синхронизируются через базу.
- Получая значения счётчиков от нескольких root-серверов, Limiter получает несколько разных значений для каждого счётчика (счётчик для одной и той же квоты в каждом root может чуть-чуть отличаться). Правильным Limiter считает наибольшее из полученных значений.
Чисто теоретически сама база квот YARL может быть вообще без резервирования. Все квоты хранятся в памяти root-серверов, так что при отказе базы root-сервер продолжит работать без базы до перезагрузки. Правда, изменять существующие квоты и создавать новые в таких условиях не получится: сохранить будет негде. Но в RO-режиме YARL может функционировать сколь угодно долго.
После перезагрузки root-сервер получает список квот из базы и создаёт для них счётчики у себя в памяти. Значения счётчиков сами собой приходят в актуальное состояние, когда в запущенный root-сервер начинают прилетать синхронизации от Limiter’ов, так что за 1–2 интервала синхронизации (у нас это 1–2 секунды) счётчики приходят к таким же значениям, как на соседних root’ах.
Схема с периодической синхронизацией в фоне даёт приятные плюшки в виде экономии служебного трафика и возможности делать проверки квот локально. Но она приносит с собой очень неприятную штуку — инертность всей системы. И с этим приходится бороться.
Борьба с инертностью, эффект пилы и сглаживание
В простейшем случае при тупом подходе «получил счётчики от root — лимитируй по ним до следующей синхронизации» мы не получим на графиках ничего хорошего: как только нагрузка на сервис превысит лимит, каждый из Limiter’ов должен будет начать отстреливать запросы. Логично, что всё, что выше лимита, подлежит сбросу. 100 % запросов? Опасно, мы вырубим клиенту сервис на целую секунду, а через секунду снова полностью откроем. В итоге из-за инертности системы, созданной задержками синхронизации, мы начнём получать на графиках «пилу»: превысили — зарезали — пустили — снова превысили…
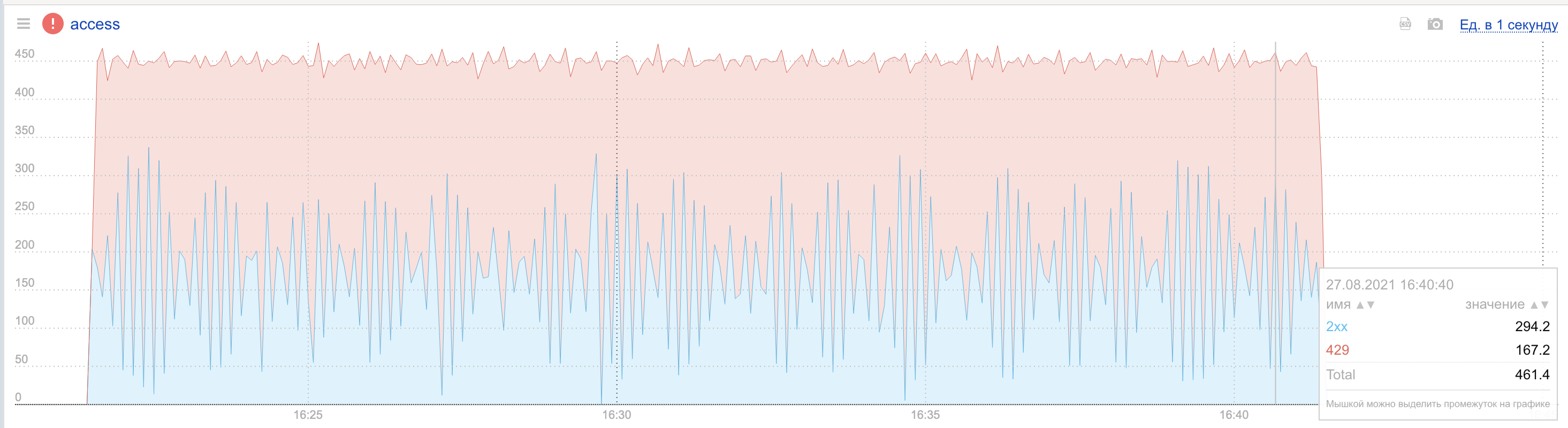
Гранулярность графика, который вы видите, — пять секунд. Интервал синхронизации — одна секунда, так что отстреливать 100 % мы должны примерно каждую вторую секунду. В кластере 50 машин, и они не синхронизируются с YARL root одновременно, а делают это в разные доли секунды. По всем этим причинам график двухсотых кодов (синяя линия) не опускается совсем до нуля. Видно, что сама нагрузка на сервис ровная: верхняя линия уровня RPS держится на одном уровне. Прыгает только величина запросов, которые проходят фильтр Limiter’а и доходят до обработки.
Чтобы не напарываться на такие «качели», придётся чем-то пожертвовать.
Управляя интервалом синхронизации, мы можем управлять скоростью реакции системы на всплески нагрузки. Чем чаще пересылать обновления счётчиков, тем больше будет служебного трафика, но тем более актуальными будут счётчики и тем чаще будут зубья пилы.
Это очень простой путь, но он же и самый неэффективный: серверу синхронизации придётся обслуживать много запросов от Limiter’ов, и в конце концов можно просто упереться в его физические возможности. Тупик.
Вместо увеличения частоты синхронизации можно внести в систему дополнительные механизмы, сглаживающие реакцию на нагрузку. Мы используем два:
- экстраполяция значений счётчиков;
- вероятностное лимитирование.
Экстраполяция значений счётчиков
Чтобы принимать правильные решения между синхронизациями, Limiter прикидывает текущее значение счётчика с помощью функции времени: зная последнее время синхронизации, текущее время и параметр limit, можно легко посчитать, каким примерно будет значение нашего счётчика в окне между синхронизациями.
<corrected_value> = <last_known_value> + <correction>
<correction> = (<time> - <last_update>) * <correction_ratio> * <quota_limit><last_known_value>— значение счётчика, полученное во время последней синхронизации<time>— текущее локальное время на хосте<last_update>— время последней синхронизации счётчика с root-сервером<correction_ratio>— поправочный коэффициент, влияющий на скорость заполнения счётчика<quota_limit>— параметр limit квоты, связанной со счётчиком
Параметр <correction_ratio> — это константа, которую мы вынесли в конфигурацию YARL. Разумеется, такое решение неидеально и было бы круто сделать <correction_ratio> динамическим: вычислять среднюю скорость в каком-то окне времени (за несколько интервалов синхронизации) и получить саморегулирующуюся систему с обратной связью. Но мы для начала использовали максимально простое решение, и внезапно его хватило.
Вероятностное лимитирование
Помните, я говорил про два показателя переполнения квоты — lowBurst и highBurst? Мы до них добрались!
Идея в том, чтобы отстреливать запрос случайным образом с определённой вероятностью.
Пока счётчик находится ниже значения lowBurst, нужно пропускать все запросы: наше ведро ещё не переполнилось. Как только счётчик перешагнул за пределы lowBurst, Limiter начинает отстреливать запросы с вероятностью, линейно зависящей от расстояния до lowBurst. Перешагивая за highBurst, Limiter начинает отстреливать 100 % запросов.
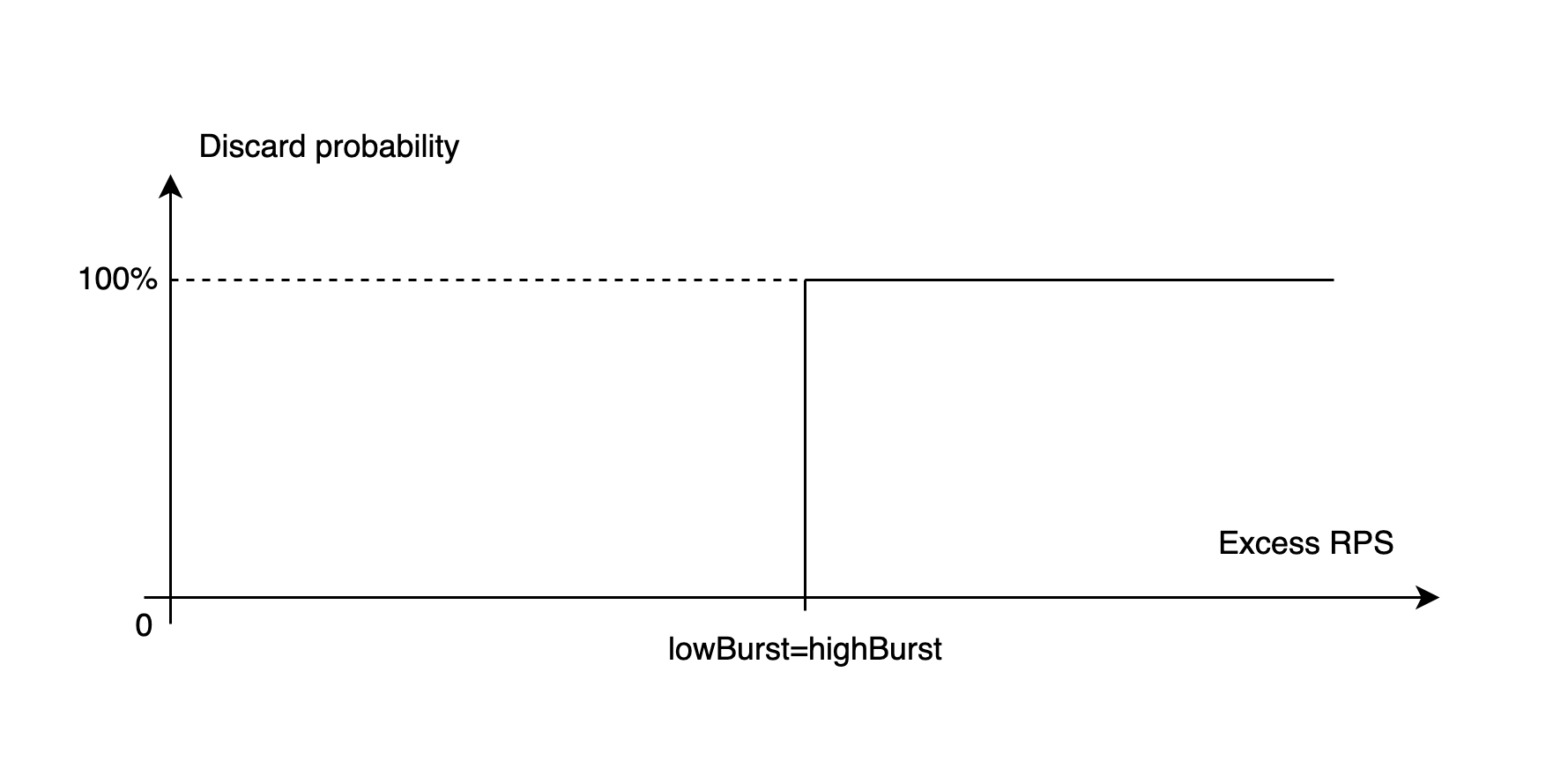
Получается кусочно-линейная функция, зависящая от клиентской нагрузки и определённая на интервале [0;+∞).
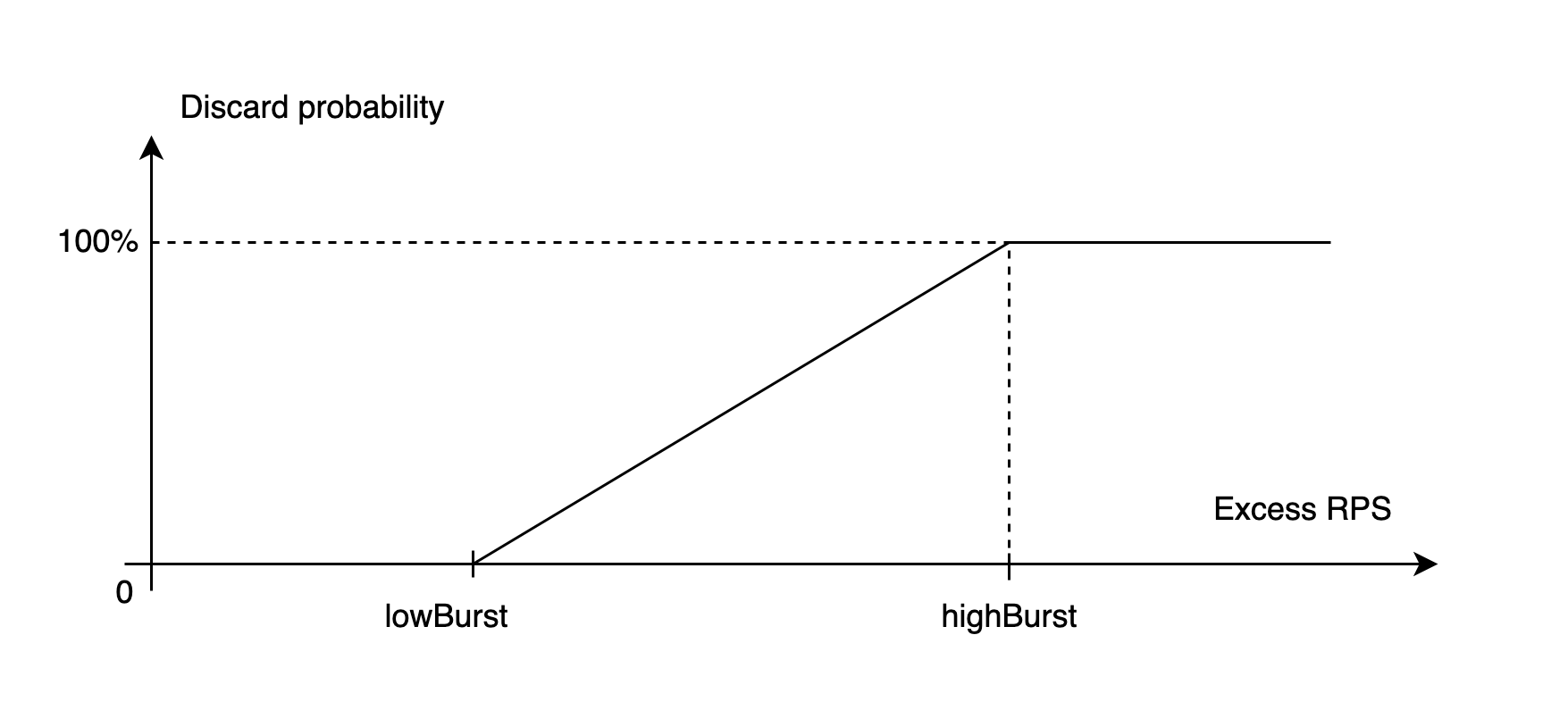
Мы пробовали использовать нелинейную функцию на участке между lowBurst и highBurst и пришли к выводу, что пользы от неё почти никакой, а сложность она увеличивает. В итоге побаловались и «оставили палку».
Благодаря вероятностной логике лимитирования, при приближении клиента к лимиту не возникает «пилы» на графиках: сервис не уходит в раскачку и не прыгает между «пропустить всё» и «зарезать всё». Доля блокируемых запросов плавно нарастает (или падает) и стабилизируется на таких значениях, при которых трафик от клиента уравновешивается лимитированием.

Кстати, график с «пилой» выше я рисовал тем же YARL’ом, просто выставив квоте настройки lowBurst=highBurst. Таким образом я превратил наклонную линию на диаграмме Discard probability в вертикальный отрезок.
К сожалению, эта дополнительная инертность, которую мы намеренно внесли в систему, работает в обе стороны: мы перестали видеть «пилу», но реакция системы замедлилась. На уход нагрузки мы реагируем с запозданием, продолжая какое-то время постреливать запросы клиента с убывающей вероятностью. В итоге эффект от активности клиента отдаётся эхом ещё какое-то время после того, как он успокоился. Длительность этого эха зависит от расстояния между lowBurst и highBurst, а также от того, насколько ниже квоты его обычная активность. На графике видно, что после ухода нагрузки есть ещё несколько секунд, когда мы отвечаем клиентам ошибками 429, хотя суммарный RPS уже явно находится в пределах лимита.
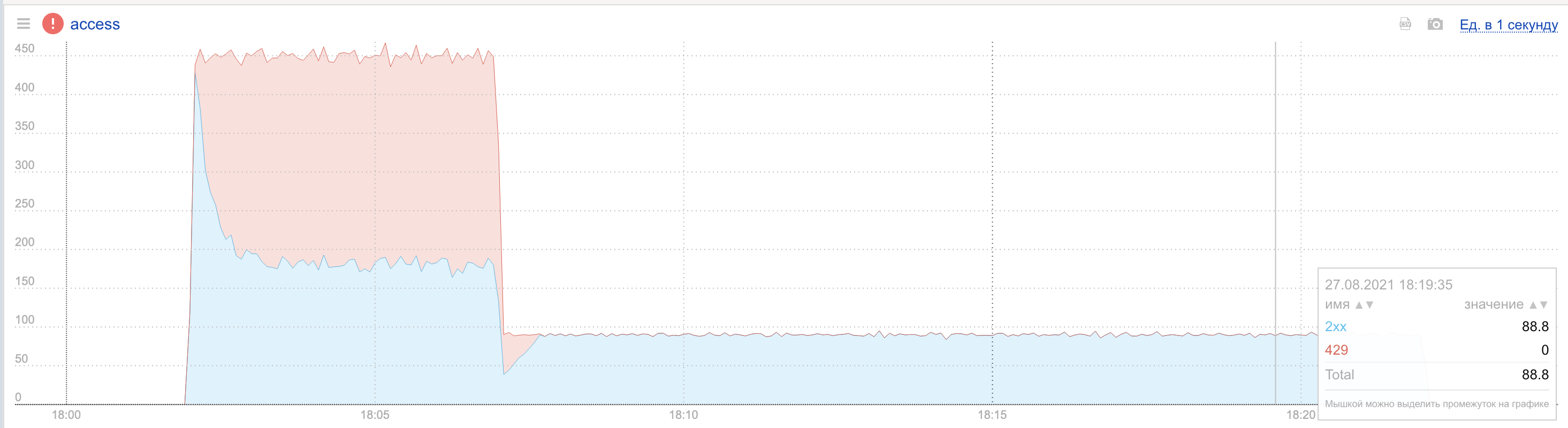
Вероятностного лимитирования и экстраполяции значений хватило для того, чтобы система вела себя стабильно. Осталось только одно ограничение, вызванное синхронизацией: минимальная скорость реакции определяется интервалом синхронизации. Если YARL обновляет информацию о полной нагрузке на кластер раз в секунду, то отдельные хосты в кластере просто не могут принять решение об ограничении запросов быстрее. Это очень хорошо видно на графике: при поступлении нагрузки мы какое-то время пропускаем слишком много запросов, из-за чего образуется явно заметный пик двухсотых кодов (синяя линия) в левой части графика.
Иерархические квоты
Зависимости между квотами — ещё одна полезная штука, которую мы добавили в YARL. В принципе, можно хорошо жить и без неё, но с зависимостями открывается больше возможностей.
Каждая квота YARL может иметь родителя. Когда Limiter проверяет какую-то квоту, он проверяет не только её, но и всех её родителей. С parentID в квотах мы получаем дерево, которое позволяет выстраивать взаимосвязи между квотами, в некоторой степени управляя поведением YARL’а без залезания в код. С помощью этого простого отношения между квотами можно выстраивать вот такие иерархии: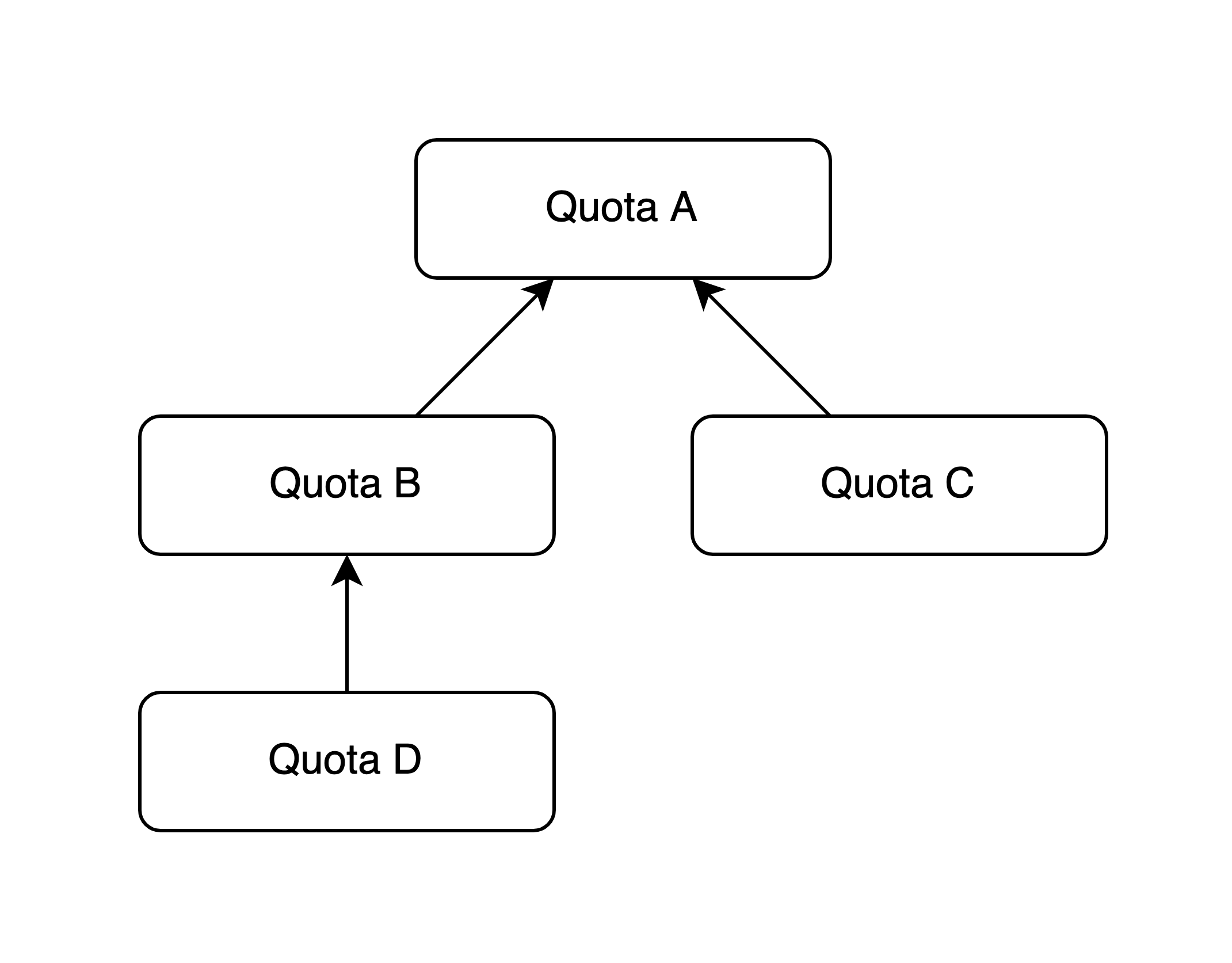
Проверяя квоту D, Limiter накручивает счётчик всей цепочки A – B – D. Благодаря этому мы можем настроить код приложения на проверку квот по их уникальным именам один раз, а затем уже на живом приложении (даже не перезапуская его) изменять связи в квотах и управлять таким образом связями между методами API. Почему бы не объединить все методы, пишущие что-то в базу, одной общей квотой? Или связать между собой несколько бакетов, если они принадлежат одному сервису и у него общий лимит на потребление ресурсов?
В общем, простая древовидная структура даёт достаточно высокую гибкость в управлении лимитами. Мы можем подстраивать настройки лимитирования под конкретную задачу без регулярного дописывания кода приложения.
В частности, с помощью этой штуки мы сделали так, чтобы nginx мог срезать чрезмерную нагрузку, не пропуская её в приложение, но при этом ему почти ничего не нужно было знать про внутренности S3 API.
Запросы в S3 имеют один из двух форматов:
- <bucket-name>.s3.yandex.net/<object-key>
- s3.yandex.net/<bucket-name>/<object-key>
Так что достать имя бакета из запроса можно стандартными средствами nginx, просто описав в конфигурации нужные map’ы. По типу запроса можно понять, чтение к нам летит или запись данных: PUT, POST и DELETE — модифицирующие запросы, GET, HEAD и OPTIONS — читающие. Этих двух параметров (бакет и тип запроса) достаточно для составления правильного имени квоты.
Limiter компилируется в .so с помощью cgo и подгружается в nginx. Там подключается с помощью lua-nginx-module и lua2go. Это даёт нам возможность в конфигурации nginx прописать что-то такое:
…
location / {
access_by_lua_block {
local plugin = require("yarl/yarl-go")
plugin.check_by_name("s3_" .. ngx.var.s3_bucket_name .. "_" .. ngx.var.s3_request_type, 1)
}
}Затем мы собираем из квот иерархию, похожую на схему ниже.
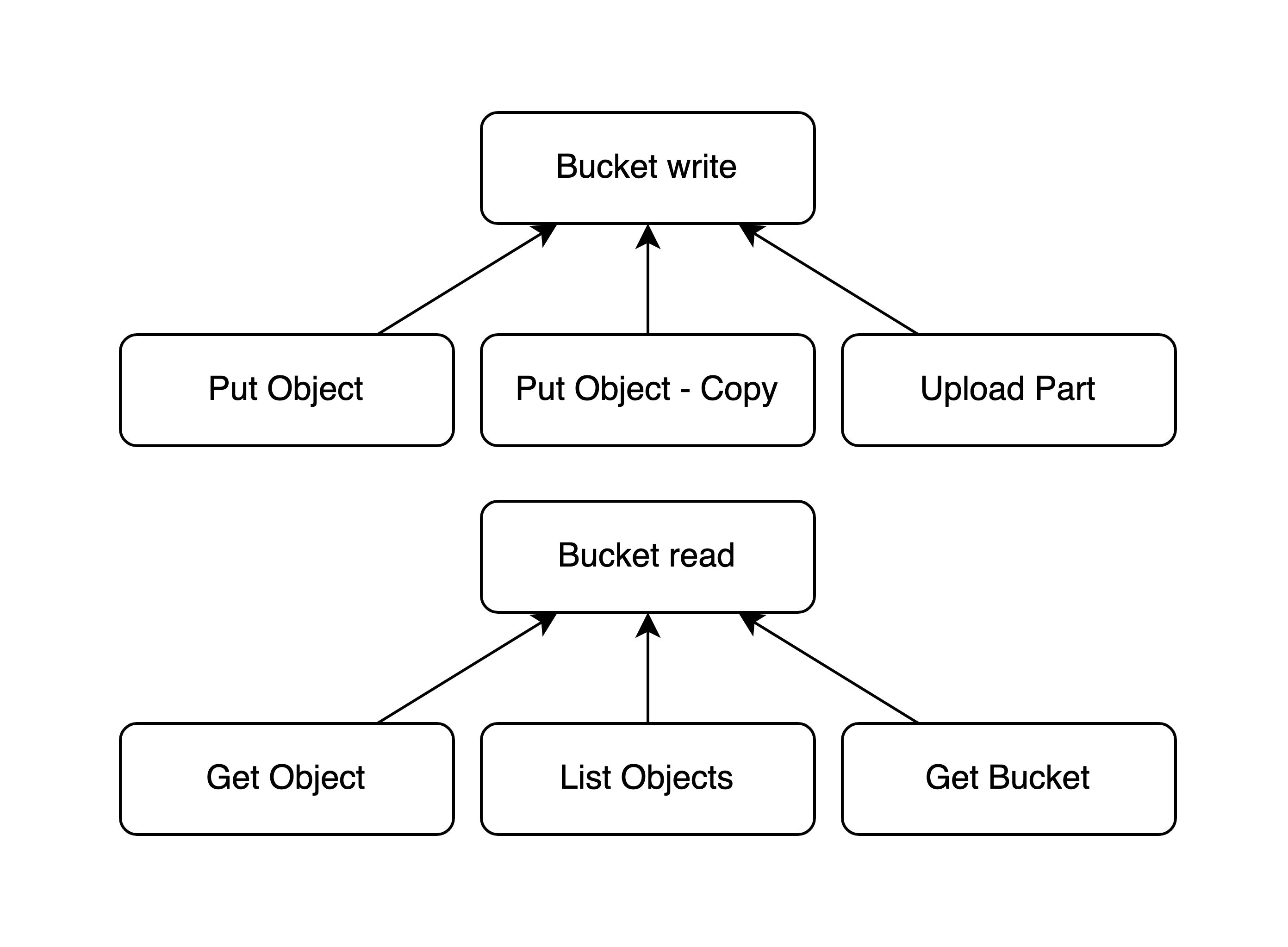
Приложение проверяет квоты конкретных ручек: Put Object, Upload Part… После проверки оно накручивает все счётчики в соответствующей цепочке.
Nginx со своей стороны проверяет только квоты верхнего уровня: Bucket write или read. При этом он вообще не накручивает счётчики, так что ему не нужно знать о стоимости каждого из запросов. Используя только значения счётчиков, полученные через синхронизацию, он может принять правильное решение о том, нужно ли отстреливать запрос или его можно пропустить.
Заключение
Вот такой у нас получился пепелац. Надеюсь, мне удалось сделать статью познавательной и полезной.
Подходы, описанные тут, можно применять и на задачах меньшего масштаба. Они хорошо работают как на кластерах из 2–3 машин, так и на сотнях хостов.
Мы проводили эксперименты и проверяли поведение YARL в довольно сложных условиях: он способен хорошо ограничивать нагрузку, даже когда запрос достаётся вообще не каждому серверу в кластере. При нагрузке 100 RPS на кластере из 300 машин в каждую конкретную секунду два из трёх хостов будут гарантированно сидеть без запросов, а между секундами машины с запросами будут каждый раз разные. Даже при такой «болтанке» общий график нагрузки на сервис остаётся ровным и YARL отстреливает только лишние запросы.
Из-за своей архитектуры YARL нельзя применять в условиях, когда для вас критически важно отреагировать на перегрузку в первые миллисекунды и начать ограничивать запросы почти мгновенно. Из-за задержек синхронизации YARL пропустит всплеск нагрузки, если тот будет длиться меньше секунды, даже если всплеск кратно превысит лимиты. При этом YARL будет успешно работать, если такие всплески происходят регулярно и в среднем нагрузка выходит за пределы выделенной квоты.
Спасибо, что добрались до конца. Надеюсь, было интересно.
