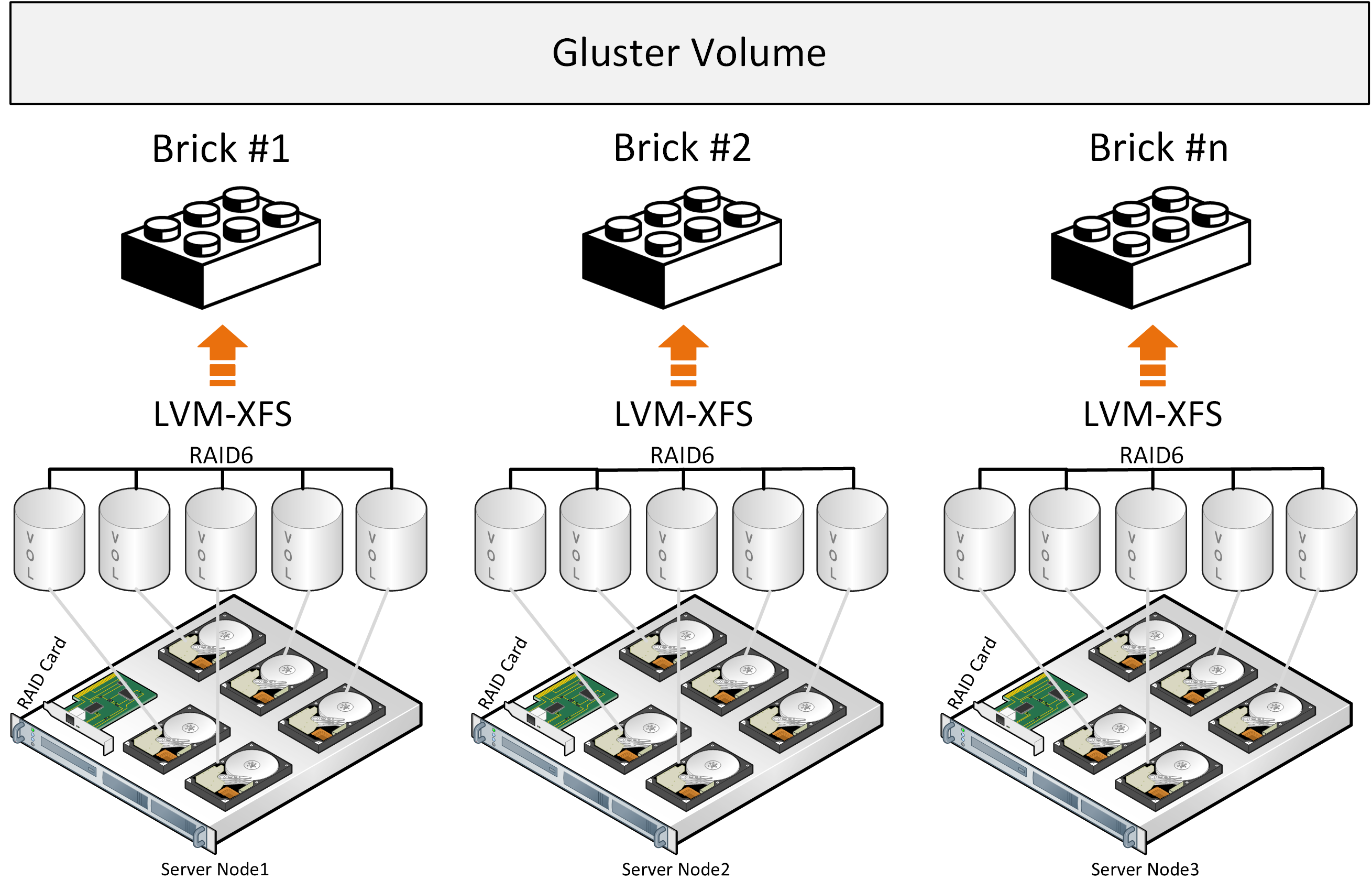
Types of smart traffic lights: adaptive and neural networks
Adaptive works at relatively simple intersections, where the rules and possibilities for switching phases are quite obvious. Adaptive management is only applicable where there is no constant loading in all directions, otherwise it simply has nothing to adapt to – there are no free time windows. The first adaptive control intersections appeared in the United States in the early 70s of the last century. Unfortunately, they have reached Russia only now, their number according to some estimates does not exceed 3,000 in the country.
Neural networks – a higher level of traffic regulation. They take into account a lot of factors at once, which are not even always obvious. Their result is based on self-learning: the computer receives live data on the bandwidth and selects the maximum value by all possible algorithms, so that in total, as many vehicles as possible pass from all sides in a comfortable mode per unit of time. How this is done, usually programmers answer – we do not know, the neural network is a black box, but we will reveal the basic principles to you…
Adaptive traffic lights use, at least, leading companies in Russia, rather outdated technology for counting vehicles at intersections: physical sensors or video background detector. A capacitive sensor or an induction loop only sees the vehicle at the installation site-for a few meters, unless of course you spend millions on laying them along the entire length of the roadway. The video background detector shows only the filling of the roadway with vehicles relative to this roadway. The camera should clearly see this area, which is quite difficult at a long distance due to the perspective and is highly susceptible to atmospheric interference: even a light snowstorm will be diagnosed as the presence of traffic – the background video detector does not distinguish the type of detection.