OpenAI опубликовала исходный код системы распознавания речи Whisper. Открыты код эталонной реализации на базе фреймворка PyTorch и набор уже обученных моделей для использования под лицензией MIT.

Разработчики утверждают, что система распознаёт речь на английском языке практически как человек.
Для обучения модели использовали 680 тысяч часов речевых данных, собранных из нескольких коллекций по разным темам и на разных языках (около трети от общего объёма данных).
Whisper может корректно воспринимать произношение с акцентом, распознавать фоновые шумы, а также технические термины и жаргон. Система способна переводить речь с произвольного языка на английский язык и определять появление речи в звуковом потоке.

В OpenAI представили две модели: для английского языка и многоязычную, которая, в частности, поддерживает русский, украинский и белорусский языки. Каждая модель делится на пять вариантов в зависимости от размеров и числа параметров. Самая маленькая модель обучена на 39 млн параметров и требует 1 ГБ видеопамяти, а сама большая прошла обучение на 1550 млн параметров и требует 10 ГБ видеопамяти.
Whisper работает на архитектуре нейросети Transformer, которая включает кодировщик и декодировщик. Звук разбивается на 30-секундные отрывки, которые преобразуются в log-Mel-спектограмму и передаются кодировщику. Затем данные направляются в декодировщик, который предсказывает текстовое представление.
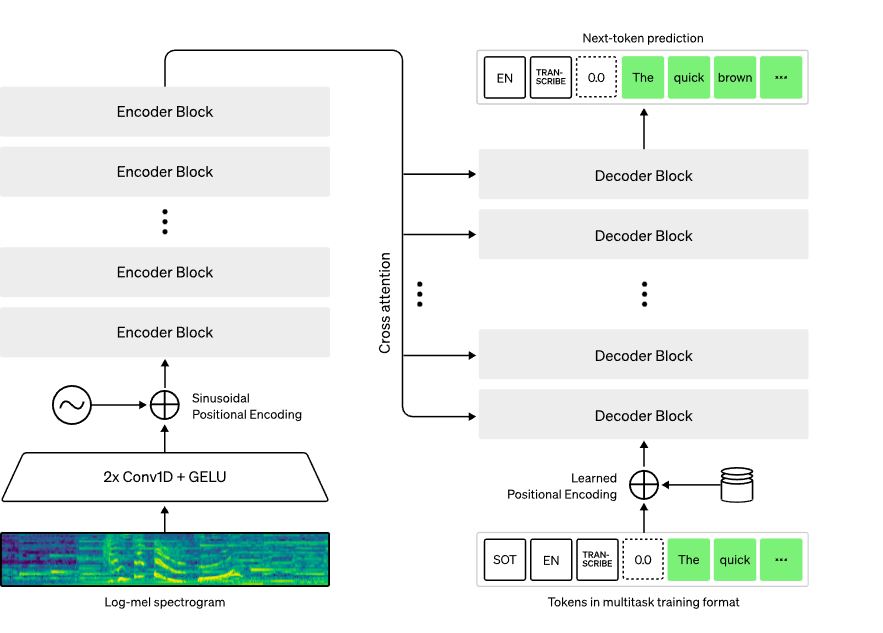
Оно смешано со специальными токенами, позволяющими в одной общей модели решать такие задачи, как определение языка, учёт хронологии произношения фраз, транскрипция речи на разных языках и перевод на английский язык.

Более подробный разбор Whisper можно прочитать здесь.
В июле OpenAI открыла доступ к нейросети генерации изображений DALL-E 2 для пользователей из списка ожидания. Одновременно компания ввела частично платное её использование по системе кредитов.
