Comments 349
Звучит так, будто Страуструп рекомендует Rust.
как нужно умудриться прочитать статью, чтобы сделать такой вывод?
Страуструп предлагает писать программы, используя безопасное подмножество языка обложившись статическим анализом. И лишь в тех местах, для которых это не работает, нарушать/обходить эти правила, переходя на ручной режим.
В Rust по сути тоже самое, только удобнее. У вас есть безопасное подмножество языка с достаточно строгими правилами, которые проверяются на этапе компиляции. И есть ручной режим, в котором вы перекладываете ответственность с компилятора на себя. Различие только в том, что переход между тем и этим явный. При этом вы получаете безопасный вариант по умолчанию (с точки зрения кривой обучения), а к более сложным вещам приступаете только при возникновении необходимости. В C/C++ получается зеркально, сначала вы учитесь делать всё подряд, а только потом приходит понимание, знания, опыт.
А ответ на ваш вопрос написан у меня в профиле прямо под ником. ¯\_(ツ)_/¯
Страуструп предлагает писать программы, используя безопасное подмножество языка обложившись статическим анализом. И лишь в тех местах, для которых это не работает, нарушать/обходить эти правила, переходя на ручной режим.
,. Нет? Он просто говорит развивать и использовать стат анализаторы. Остальное вы додумали. А насчет раста говорит, что делать акцент на "безопасности в области памяти", когда проблемы с безопасностью вообще то совсем не на этом уровне - абсурд.
Слово безопасность здесь вообще не подходит, это рекламный ход и только. Взломы происходят через физический доступ и людей, а "безопасность по памяти" это лишь меньше число багов связанных с сегфолтами(опять же меньшее ли - вопрос) за счет ухудшения всех остальных аспектов языка и программы
Not everyone prioritizes “safety” above all else. For example, in application domains where performance is the main concern, the P2687R0 approach lets you apply the safety guarantees only where required and use your favorite tuning techniques where needed. Partial adoption of some of the rules (e.g., rules for range checking and initialization) is likely to be important. Gradual adoption of safety rules and adoption of differing safety rules will be important. If for no other reason than the billions of lines of C++ code will not magically disappear, and even “safe” code (in any language) will have to call traditional C or C++ code or be called by traditional code that does not offer specific safety guarantees.
Нет, не додумал. Вот прямая цитата. Опять же рекомендую и отчёт АНБ прочитать.
Атаки через уязвимости в ПО существуют. И встречаются достаточно часто, чтоб считать это реальной проблемой. Что плохого в том, чтоб заранее избавиться от части из них и сосредоточиться на других векторах атаки (или на чём либо ещё)? Что плохого в использовании более подходящих инструментов для этого?
Возможно, несколько из другой области:
одни говорят: зачем столько языков (человеческих)? Давайте сделаем один универсальный! Эсперанто! Он лучше любого.
другие говорят: давайте унифицируем все разъёмы! scart (помните такой?)! Он объединяет всё.
третьи говорят: пусть будет единая система измерений! метр, секунда, килограмм! Это очень универсально.
ethernet ipv4 устарел, адресов не хватает. Давайте atm, давайте ipv6!
В результате: говорят на русском, английском, китайском; разъёмов - их легион; диагональ мониторов меряют в дюймах; ipv4 живее всех живых.
В общем, универсальность почему-то не работает: не знаю почему, но время подтверждает.
Так что выдохните и забудьте!
Почему то много кого напрягают Чистый C и C++ - их не пытаются потеснить, их хотят сразу "убить" (и привнести много нового и полезного). Если новое настолько хорошее, то зачем кого-то "убивать"? Вот javascript не пытается "убить" C/C++ и отлично живёт. Ну а что rust ... судя по использованию, ничего выдающегося там не водится; это всё попытки переплюнуть C++ ... упс. А конкуренты в это время бегут вперёд.
Это проблемы не универсальности, а миграции дремучего легаси. Нет достаточного стимула, потому легаси и дальше тянется. Система СИ так-то используется в науке и промышленности во всю. Потребительское легаси - совсем мелочи.
С системой СИ не все так просто. В теоретической физике до сих пор довольно широко СГС используется (мне, честно говоря, всегда трудно писать электродинамику в СИ), не говоря уж о более специализированных системах для конкретных задач. Плюс традиционно используется довольно много единиц, которые в СИ не входят: то же давление в торрах и барах, энергии частиц в электронвольтах, расстояния в астрономических единицах и парсеках.
Да, вроде как, не "до сих пор", а никто от неё не собирался и не собирается отказываться (в физике). СИ всегда считалась системой для иженерии. СГС(Э) удобна для физики что не требует каких-то дополнительных искусственных констант типа ε₀ или μ₀ а использует во всех уравнениях только фундаментальные c и ħ.
Строго говоря, с и ℏ - такие же "искусственные константы", как и ε_0, поскольку просто индуцированны системой единиц :)
Тут не соглашусь. Скорость света и постоянная планка имеют вполне ясный физический смысл - скорость распространения электромагнитной волны в ваккууме и квант энергии колебательной системы с единичной частотой. А диэлекрическая и магнитная постоянные требуются только из-за того, что в СИ кулон и ампер определены типа как "от балды". Если, допустим, 1 кулон определялся бы как "заряд который на расстоянии 1 метра действует на такой же заряд с силой 1 ньютон", то они были бы не нужны.
Ну да, ровно так же, как и метр, который был исторически выбран от балды как 1/4e8 какой-то большой окружности какой-то планеты и килограмм, который исторически сначала опирался на тот же произвольно определенный метр и произвольно взятую жидкость.
Ну, справедливости ради, это была наиболее распространённая на планете жидкость.
Для уточнения, изначально метр опирался на ускорение свободного падения в какой-то точке на поверхности какой-то планеты и на времени оборота этой планеты вокруг своей оси. Это потом пришлось ради большей точности переопределять, и не один раз. Современное определение тоже от вашего отличается (и основывается как раз на скорости света, но с легаси в виде произвольного множителя).
Занудства ради замечу, что СГС очень близка к СИ - те же базовые величины, только в разных размерностях. Да, немного другие постоянные в формулах, но если вы скажете, что у вас скорость 23 см/с - то мне не составит труда понять, что это 0,23 м/с. Сравните это с предыдущим имперским зоопарком, где одних только миль с десяток, а единицы соотносятся друг с другом как примерно огурец с пшёл нахрен.
Прочитайте внимательнее отчёт АНБ. Они говорят о том, что вот же куча разных ЯП, оставьте няшную сишечку и плюсы для специальных случаев.
А насчёт универсальности - она работает, но только тогда, когда имеет очевидное превосходство. Опять же USB вполне себе стал стандартом, как контрпример про разъёмы. Английский язык в некоторых областях тоже что-то вроде негласного стандарта (например в научном мире). Система СИ так или иначе используется везде в технической/научной среде. Во всех этих случаях оно работает только в областях, где есть какие-то причины для этого.
Скажем, нет какой-то особой разницы между дюймами, миллиметрах или бананами в дисплеях. Когда вы их продаёте. А вот когда вы производите дисплеи, то там будут использоваться единицы СИ.
Ну а что rust ... судя по использованию, ничего выдающегося там не водится; это всё попытки переплюнуть C++ ... упс.
Полагаю, это уже лично мне претензия. Не очень понимаю, с чего вы взяли, что Rust вообще в принципе предлагает что-то выдающееся. С моей точки зрения это хорошо сделанный инструмент. Весьма неплохо себя показывает, если вам нужно достичь надёжности и производительности одновременно, но вы готовы заплатить сложностью. Опять же как и у любого другого ЯП, у Rust есть области, для которых оный подходит плохо. Например для приложений, где нативный GUI является очень важной частью, я Rust крайне не рекомендую.
Полагаю, я всё же должен уточнить о вашем опыте использования Rust. Здесь есть относительно высокий порог вхождения. Как минимум прочитать основную документацию (включая оффициальные учебные пособия) и написать некоторое количество кода. Впрочем это характерно и для многих других ЯП, которые содержат какие-то новые для вас парадигмы. Borrow checker не смотря на кажущуюся простоту концепции достаточно сложная для понимания штука.
А конкуренты в это время бегут вперёд.
О каких конкурентах идёт речь? D? Zig? Haskell? Idris? Go?
Из быстро, вкусно и недорого обычно можно выбрать лишь 2 варианта.
Из быстро, безопасно и недорого - тоже
как-то попробовал написать небольшую прогу на расте и на с++ ( да из-за нехватки опыта на расте писал раз так в 2-3 дольше) но это не проблема, с опытом быстрее будет, но вот сравнение скорости не порадовало, с++ раз так в 7-9 быстрее оказался ... хотя проблема может лежит и во мне и он не оптимизирован. но и потребность ресурсов ниже. думаю раст подходит где очень ограниченное количество памяти и нужна надежность, а скорость +/- нужна (хотя не уверен)
Тут стандартный вопрос — а запускали вы в релизе? cargo run --release?
Можете поделиться пожалуйста что это за библиотеки такие?
Гуй на расте писать не стоит, это правда. Впрочем уже лет 10 не приходится писать под десктоп, чему неимоверно рад. Изучаешь нормальные технологии и можно использовать то, что нужно, а не то, что на икспишных машинах клиента пойдет.
OpenCV — лет 5 назад писал враппер на расте, то что покрывало лично мои задачи я покрыл, но это заняло прилично времени, чтобы проработать паттерны и подходы: пришлсоь делать сначала врапперы плюсов на СИ, потом FFI unsafe Rust -> C, и потом безопасный интерфейс на расте. Если есть желание — поставьте плюси к и откомментите в ишшуе: https://github.com/opencv/opencv/issues/11666
Собственно, суть моего изначально комментария была не в том, что «какой-то козёл (я) не нашёл нужные ему три библиотеки, ну и хрен с ним». Речь о том, что какие-то языки, возможно, концептуальны, безопасны и с прекрасным синтаксисом, уберегающим от всех ошибок всегда везде и дающим гарантии всего. А начнёшь прикидывать, как бы на таком языке чего написать — того нету, этого нету, и не предвидится, похоже — либо пили свой кривой враппер сишных библиотек, покрывающий лично твои задачи, либо сам с нуля пиши (ага, ага), либо так и чахни над этими гарантиями безопасности, как пушкинский Кощей над златом. Paul Graham в 2004 году написал своё широко известное в узких кругах эссе «The Python Paradox», о том, что разработчики на Питоне дофига умные, потому что учат Питон не для работы, а для души — если не вспомнить, сколько времени прошло, то даже смешно сейчас читать, когда, куда ни плюнь, скорее всего попадёшь в питониста-датасайентиста. Как-то вот превратился в один из самых практичных языков, не смотря на свой duck typing и отсутствие гарантий чего бы то ни было вообще. Потому что какую библиотеку ни загадай, для каких языков она есть? Для C++ и для Python точно, ну, для Джавы с дотнетом, возможно, будет что-то своё, а дальше всё, дальше очень вряд ли, если только совсем сильно повезёт. Ладно, Питону 31 год а Расту 12, возможно, это всё объясняет. Но Хаскелль какой-нибудь старше Питона, там та же фигня во все поля. Лиспы всякие ещё гораздо старше, там всё ещё гораздо хуже.
pip install opencv-python, оно, как правило, устанавливается и работает. Когда я вспоминаю, что произошло после того, как я несколько лет назад написал там же cabal install repa, у меня до сих пор несильно, но всё же дёргается правый глаз. А написать cabal install opencv-haskell или как-то так я не мог, потому что её не было под Хаскелль (хотя с тех пор, вроде, запилили? проверять, как оно работает я, конечно, не буду). Гуёвые библиотеки (байндинги тех же Qt и wxWidgets), знаю, существуют довольно давно, последнюю я даже щупал, вроде, даже работала. VTK я ни тогда, ни сейчас найти не смог — с одной стороны, оно бы и ладно, штука специфисская и не так много кому нужная, но, с другой стороны, в этом и состоит разница между «библиотек там немало» в том смысле что устанешь листать каталог и в том смысле, что если такая библиотека вообще есть, то она точно есть под этот язык.Почему на расте не стоит писать гуй?
Потому что все популярные на планете гуй либы построенны на оопшном принципе
Button extends ButtonBase extends ControlBase
который в расте не работает. Альтернативные подходы вроде ECS не проработаны дальше сырых прототипов. а других сколько-нибудь известных способов организации контролов человечество пока не придумало.
Кроме того, что библиотек нет — их же, я так понимаю, ни для чего толком нет, и тогда получается, что на расте ничего писать не стоит, кроме совсем каких-то алгоритмов-алгоритмов, которые надо самому пилить с нуля? Речь о том, что какие-то языки, возможно, концептуальны, безопасны и с прекрасным синтаксисом, уберегающим от всех ошибок всегда везде и дающим гарантии всего. А начнёшь прикидывать, как бы на таком языке чего написать — того нету, этого нету, и не предвидится, похоже — либо пили свой кривой враппер сишных библиотек, покрывающий лично твои задачи, либо сам с нуля пиши (ага, ага), либо так и чахни над этими гарантиями безопасности, как пушкинский Кощей над златом.
Это не так — библиотек хватает, все зависит от ваших задач. Мне для моих задач (поднять веб-сервер, сервить опенапи доку, ходить по графам, считать генетику, взаимодействовать в телегой, ...) например есть все, если для ваших задач чего-то не хватает, то нужно оценить насколько это ценно и насколько больше раст дает по сравнению с необходимостью в него делать ФФИ из либ которые есть и прочий бойлер. Если выгоды меньше, ну значит раст не подходит, берите более подходящий стек, вопросов ровно ноль.
Насколько часто это возникает? На мой вкус нечасто, даже библиотека которая приводит адреса 0xaaaabbbccc в заборчик вида 0xaAAbbBCCc (эфировский hashsum-checked address) нашлась. Хотя это лефтпад по сути.
Для гуя можете посмотреть что нибудь отсюда
Но там много проектов ещё в начальной стадии, и не проработаны нормально. Хотя концепты прикольные (типа того же Slint, бывшего SixtyFPS)
Сишечка ни в коем случае не божественная, но раст тоже таковым не является. Тут всё как обычно: баги будут, но вопрос в том, где именно, и насколько дорого жить с их (неискоренимым) присутствием.
Это в принципе лейтмотив многих людей, которые топят что раньше трава была зеленее, а щас смузихлебы тащут ненужную фигню, без которой и раньше прекрасно обходились. Факт в том, что некоторого класса багов с растом у вас не будет. Например в сишке невозможно засунуть строку в переменную типла дабла, язык защищает от этого, в отличие от скажем питона (я сейчас не буду вдаваться в детали про «монотип», будем считать что они разные для простоты). Точно так же раст скажем защитит от состояния гонки данных, а сишка — никак. Обложиться миллиардов СПЕЦИАЛЬНЫХ КОММЕНТАРИЕВ и следовать гайдлайнам — это по сути и есть создать свой язык, только хрупкий и неудобный.
Вы забыли в вашем комментарии про деньги. Мой же комментарий сводится к балансу деньги-деньги.
Относительно плюсов раст кажется даже более экономный по времени. Если сравнивать с языками с ГЦ типа жабы там да, раст менее продуктивный. Но с плюсами — раст по сути это те же плюсы, только который чуть подкрутили, чтобы статический анализатор работал корректно. Можно полистать как раст выглядел в 2010 году, как промежуточная форма эволюции уши плюсов там торчат буквально отовсюду.
Если конечно не считать auto foo(int x) -> fn foo(x: i32) огромным изменением
Менее продуктивный в плане сервисы писать сложнее и/или некрасивее или про что речь?
Приходится думать о том, о чем в сервисах часто думать не надо — например о расположении данных в памяти и тп. Тривиальнейший код уровня:
async function logger(fn) {
console.log("Start");
const result = await fn();
console.log("Finish");
return result
}Превращается в неконтролируемого монстра с трудно поддерживаемыми лайфтаймами
use actix_web::{web, App, HttpRequest, HttpServer, HttpResponse};
use serde_json::json;
use futures::Future;
trait MyFn<T>: FnOnce(T) -> <Self as MyFn<T>>::Fut {
type Fut: Future;
}
impl<T, F: FnOnce(T) -> Fut, Fut: Future> MyFn<T> for F { type Fut = Fut; }
fn logger<F: Future<Output=HttpResponse>, FN: FnOnce(HttpRequest) -> F>(inner: FN) -> impl MyFn<HttpRequest> {
move |req| async move {
println!("Start");
let result = inner(req).await;
println!("Finish");
result
}
}(Надо ли говорить, что этот код не компилируется иззза лайфтаймов, его нужно дальше дописывать/править, но мне стало лениво, чтобы оценить обьем требуемых усилий кажется достаточно. На это ушло минут 20 экспериментов, на код который выдает меньше всего ошибок. Офк боксинг не предлагать).
В общем, забивать микроскопом гводи плохая идея, и в молоток рассматривать микробов — тоже.
async fn logger<MyFut, MyFun, R>(func: MyFun) -> R
where
MyFut: Future<Output = R>,
MyFun: Fn() -> MyFut,
{
println!("Start");
let result = func().await;
println!("End");
result
}
Без явных лайфтаймов и финтов ушами
Вы потеряли аргумент функции. В изначальном коде сигнатура
FnOnce(HttpRequest) -> FА вы нписали:
Fn() -> FЭто совсем другое дело. Если вы на жс код смотрели, то извиняюсь, я там неправильно написал, аналогом будет:
function logger(fn) {
return async (req) => {
console.log("Start");
const result = await fn(req);
console.log("Finish");
return result
}
}Собственно эту проблему должна решить фича impl_trait_in_fn_trait_return, но она пока в настолько сыром состоянии что надеяться на нее не стоит.
Потому что на них невозможно писать безопасный код, которому можно было бы доверять.
Есть мнение, что не надо мешать C и C++ в одну кучу. Если писать на современном C++ без сишных костылей, то надо прям постараться себе выстрелить в ногу. Вот от сишного наследия в плюсах надо избавляться, это да.
P.S.: Из "безопасных" языков вроде бы еще в 70-х годах придумали Ada, вот только не взлетело. Интересный вопрос почему, видимо не словили волну хайпа как сейчас.
то надо прям постараться себе выстрелить в ногу
ой та я вас умоляю. используйте спаны говорили они
const char* somecstr = nullptr_t;
....
std::string_view view(somecstr); // держи мужик сегфолт
И такие мелочи раскиданы по всем плюсам. Поэтому люди и плюются то на бусты, то на stl и пишут свои костыли, порастающие ещё большим легаси.
Не ну настоящий программист так не напишет же...
Как-то странно писать такое... Но и я тоже один раз так ошибся: использовал shared_ptr на структуру с данными программы, но забыл его инициализировать. Потом удивлялся, почему не работает? Скомпилировал с флагом -g, открыл gdb, а там SEGFAULT на лицо.
ну вот как-то так без Valgrindов-ASANов-CppCheckов и прочего обвеса пользоваться безопасными плюсами довольно больно. А местами ещё и медленно. А там ещё сборочную инфраструктуру к pain point добавить, когда ты вроде прописал флаг "сделать безопасно", а он у тебя где-нибудь в третьей папке пятой пятки этот флаг выключило или частично настройки сменило или оверрайд из env не сработал или ещё что-нибудь. А там ещё библиотеку добавить надо, только неизвестно есть в ней CVE или нет. И инструментов по типу cargo-audit проверить это особо тоже нема.
одни говорят: зачем столько языков (человеческих)? Давайте сделаем один универсальный!
Что-то ужасно знакомое!

В Расте есть ряд гарантий, связанных с памятью и с многозадачностью без ущерба для производительности. Это, в общем-то, прорывная вещь. Если Вы не считаете это выдающимся, то, боюсь, это Ваше недопонимание. Ну и в остально это довольно хорошо продуманный язык.
А "убивать" C/C++ вовсе не Раст хочет. Сообщество Раста вообще довольно дружелюбное. Избавиться от C/C++ хотят те, кому учень не нравятся ошибки, в том числе критические ошибки уязвимости, связанные с тем, что в C и C++ очень легко делать такие ошибки, а выявлять иэ нелегко.
Просто до Раста во многих контекстах альтернативы C/C++ не было, приходилось терпеть; теперь же есть альтернатива, есть возможность не терпеть, не передвигаться по минному полю с машинами для разминирования, а жить сразу спокойно.
К сожалению ("пардонте" за мою иносказательность):
боюсь, это Ваше недопонимание
Очевидно, что в каждом мало-мальски популярном языке есть что-то особенное и прорывное. Другие (э-э-э, Brainfuck — Википедия (wikipedia.org) ?) рассматривать смысла нет.
И про rust тоже можно сказать: в его ТХ есть что-то прорывное (и по мнению многих, даже выдающееся), однако некоторое "большинство" в это не верит (если судить по рейтингам и т.п.). Пока, во всяком случае.
Или вот ещё пример: в эскимосском языке названий разного типа снега 40+ (Сколько названий снега в эскимосском языке | Новости переводов (flarus.ru) ). Вот это прорыв (... во многих контекстах ...)! Давайте все с английского/китайского/русского перейдём на эскимосский? Очевидный ответ: нет. - Почему "Нет"? Он хорошо продуманный! - Ну так мало ли в Испании донов Педро?
Поэтому, ну да, альтернатива есть. Супер, Отлично, и ... ?
Ещё интересное наблюдение: столкнулся недавно с raspberry pi pico (одноплатный компьютер, вычислительно довольно слабый, ресурсов мало, ОЗУ 264 кБайт). Так там примеры кода уже даются на micropython (MicroPython - Python for microcontrollers )!
MicroPython на микроконтроллере, Карл!
Так что Python впереди планеты всей; "убийца" чистого C и C++. - Так он же медленный!!! - Нуичо? - Так там есть уязвимости и нет гарантий!!! - Дважды нуичо! - Куда катится мир (facepalm)!
Не очень понял поход в минусА. Страдаю за правду?
питон всё поглощает (и rust и C/C++ и другое) - ну вроде очевидно;
rust не уникальный - тоже наблюдаемая тенденция. То ли гарантии не нужны (см. пункт 1); то ли скорость не важна (см. пункт 1) - не знаю.
Повторюсь, эти умозаключения сделаны не на основе свойств языка (на rust не писал), а через "время показало" - и вот оно сейчас так.
Эсперанто жив и здравствует, пусть и не как универсальный международный язык, нг таким стал английский. К унификации все пришли в виде usb, а затем и usb-type c, в дюймах меряют только диагонали, да пожалуй и все, и это никак не мешает универсальности системы СИ, которая изучается во всех школах во всех странах мира (вы бы ещё пинты пива вспомнили). Ipv4 не устарел, но адреса закончились в 2011 году, а с тех пор костыли типа NAT просто стали нормой, а ipv6 медленно, но верно приходит в каждый дом, и причем тут вообще универсальность? Ipv4 ни капли не менее универсальный, чем ipv6.
Так что не знаю, где у вас универсальность не работает, все ваши примеры как раз говорят об обратном.
Честно говоря, странно это комментировать, но попробую:
запрос на самые популярные языки выдаёт Китайский. Английский на 2-3 месте. Где-то недалеко Русский: 4-6 место (всё в зависимости от года подсчёта). Эсперанто он вообще где?
usb универсален, наверное, только для флешек, клавиатур и мышей. Остальное (например, звук) - ставьте драйвер. Малоприменимо, чтобы видео по usb гоняли - там скорее vga, dvi, hdmi и др. Сеть? - Неа, только как коннект к сетевой плате. Отмечу, что скарт в своё время хотел объединить и видео и звук и информационку. И всё в одном разъёме.
про СИ выше писали, на всякий случай добавлю: месяц - это СИ? Сутки, Час? Лист А4? Типографский лист? Чайная/столовая ложка? Примеров - имя им легион.
ipv6 медленно, но верно ... Честно, не ощутил. У нас есть отраслевой стандарт на ipv6, так все от него отбрыкиваются, внедрять не хотят. Делают аналогичные протоколы, но на ipv4.
Эх, счастливый Вы человек!
По мне, отсутствие драйверов и является той целью, к которой нужно идти. Ради этого можно даже согласиться на различные разъёмы.
Когда вы делаете своё устройство, пишете свою операционную систему или ... ну в общем выходите за круг windows-word-chrome то вдруг, ВНЕЗАПНО, вопросы драйверов начинают вас очень сильно бить.
Например, если у вас есть проигрыватель/ игровая приставка, который может выдавать видео через hdmi - вы подключаете телевизор через шнурок и у вас всё работает. Супер!
Переходный пример: беспроводные наушники - тут уже мало просто купить (особенно для нестандартных устройств), желательно ещё поизучать версию блютуза и поддерживаемые кодеки. Ну-у-у, Ок ...
Гипотетический!!! пример с драйверами: купи для компьютера роутер, подключи его через usb и дальше ищи драйвера, которые смогут завестись на компьютере. Иначе роутер - бесполезен. Э-э-э, а оно надо, такой подход?
PS: истории, что "производитель должен сам всё поддержать" лучше не рассказывать - от выпуска устройства может пройти 5-10 лет и, вдруг, производитель считает его устаревшим (покупайте новое), производители ОС вообще разводят руками.
отсутствие драйверов и является той целью
Просто оставлю это здесь

Когда-то, проапгрейдив свой 486DX4-100 до Pentium MMX 200, долго смеялся над шедшим в комплекте с процессором диском с драйверами для Win95 - мол, ога, даже для процессора уже драйвер нужен... шли годы, выходили процессоры, несовместимые "из коробки" с некоторыми ОС (никогда не забуду, как приятелю помогал прогрейдиться на AM2), появлялись разные фичи (спидстэп, тротлинг, да я и половины не знаю, как называются), и вот - драйвер уже нужен даже для столь фундаментальных устройств, как процессор и, порой, даже оперативная память...
запрос на самые популярные языки выдаёт Китайский. Английский на 2-3 месте.
Это, вероятно, по числу людей, для которых это первый язык. По общему числу говорящих английский давно держит уверенное первое место. https://en.wikipedia.org/wiki/List_of_languages_by_total_number_of_speakers
По-вашему, "живые" языки - это только топ-10? На эсперанто пишутся книги, звучит радио, печатаются журналы. Этот язык передается детям, есть носители. По разным прикидкам, на нем говорят 500к - 3кк человек, что даже в самом плохом случае побольше многих естественных языков. Главный признак "живости" языка - передаваемость детям, с эсперанто тут полный порядок. Небезызвестный Сорос как раз из таких детей, у него эсперанто родной.
У вас очень ограниченное представление о usb и его возможностях. Этот коммент я пишу, находясь в vr-гарнитуре, подключенной к компу через обычный usb 2.0, не type-c. Звук, видео, данные отслеживания, кадры синхронизации и т.п. спокойно идут по нему. Ethernet over USB тоже живет и здравствует, даже любой современный телефон, как и комп, спокойно понимает стандартный Ethernet-кабель, подключенный через usb. Да и HDMI over USB не проблема, гуглите usb-хабы на озоне или али. И всё это БЕЗ драйверов из коробки. Вообще не помню, когда последний раз ставил какие-либо драйвера на винду, лет 5 может назад. Регулярно шью разные платы, пользуюсь достаточно экзотическими устройствами.
Ваш коммент про СИ не понятен. Кто сказал, что СИ должна стать стандартом всего? Секунда - это СИ. Остальное - ISO. Типографские листы туда же. Большая часть из того, чем мы пользуемся, стандартизирована.
У меня в глубоком захолустье за 8к км от столицы выдается ipv6. В столице менял 5 разных провайдеров - только у одного не было из коробки, но по запросу было. Знакомый недавно в Таджикистане был - там, при максимальной скорости в 5 мбит тоже выдают ipv6. Все мобильные операторы выдают, а это большая часть потребительских устройств. Можете прям щас с мобильника зайти и проверить. Кто отбрыкивается-то? Уже давно новое сетевое оборудование без поддержки ipv6 практически не производится, старое меняют на новое, уже с поддержкой. "Делают аналогичные протоколы, но на ipv4" - переведите, пожалуйста. Протоколы чего кого? Вы с моделью OSI знакомы?
Как-то Вы припозднились. Также не очень понятна причина Вашего "недовольства" и "я-всё-знаю". Да, это есть сарказм, прошу меня извинить.
Итак:
про "живые" языки разговор не шёл. Разговор был про то, что эсперанто, на данный момент (по моему скромному мнению), не является универсальным языком общения. И ДА! Если вопрос идёт про универсальное средство общения, то нужно смотреть на top-10. Поправьте?
про ограниченное представление о usb. Возможно, Вы правы, я не очень его хорошо знаю, в основном с позиции API. Однако, сталкивался с такой ситуацией: железячники создают некоторое устройство, и в качестве интерфейса выдаётся usb/pci-ex/etc. Это всё хозяйство втыкается в компьютер и вдруг оказывается, что для корректной работы устройства нужно что-то дописать, т.к. Linux/Windows начинают говорить, что они такого устройства не знают. Естественно не знают, это ведь кастомное устройство, под стандартные типы не подлезающее. И? Драйверы не нужны? Особенно, как выше указывалось, что есть операционные системы не только Ubuntu и Windows. То, что Вы не ставите драйвера это не значит, что они не требуются (Или Вам очень везёт). А если требуются драйвера, то выставляемая автором статьи/комментаторами идеология про универсальное средство слегка проседает. Подискутируем?
Про СИ - это другие товарисчи пытаются всё перевести к новым и универсальным средствам. Вот тоже можете им объяснить, что это не есть правильно (или не объяснять). Ещё один гневный комментарий (только вот в кого)?
Протоколы, OSI и др. Вот в самой столице провайдер выдал белый ip-адрес и он IPv4. Может у нас столицы разные? Или необходимо отъехать километров на 8+? Про стандарт: есть семейство стандартов ED-137 (там и 138 и др.) и он явно требует, чтобы устройства адресовались через ipv6. Вот требует, хочется ему. Отдельные товарищи даже хотели освоить х-м-м ... деньги и даже выстроить отдельный интернет на отдельно взятой территории (там несколько стран; и России там нет, хе-хе). Только вот почему-то другие пользователи этого стандарта сильно предпочитают ipv4 (во всяком случае, пока) - т.е. данные гоняются те же самые, адресация другая. Соответственно, Вы можете читнуть, откомментировать. Не понял, причём здесь OSI - там и ipv4 и ipv6 находятся не далее, как на одном уровне. Хотя у нас может не только столицы разные, но и уровни osi ... всё бывает.
Прошу прощения за сарказм, но по-моему, Вы сами напрашивались.
в дюймах меряют только диагонали, да пожалуй и все
А как же размеры шин тех же?
одни говорят: зачем столько языков (человеческих)? Давайте сделаем один универсальный! Эсперанто! Он лучше любого.
У Эсперанто немного другая задача: это легковесный fallback-язык, который не заменяет родные языки, а позволяет общаться, когда у собеседников нет совпадения по родным языкам.
Страуструп это не предлагает. Он говорит о том что С++ и его подход тоже вполне имеет право на жизнь. А проблемы безопасности шире и разнообразней, чем только работа с памятью.
<юмор>
А это нужно умудриться очень внимательно прочитать статью и заметить, что в документе от NSA в качестве примеров предлагают 6 языков – C#, Go, Java®, Ruby™, Rust®, and Swift®, а Страуструп в своём письме "критикует" необходимость втюхивания только 5 из перечисленных языков – C#, Go, Java, Ruby™, and Swift® :)
</юмор>
Однажды у театрального пожарного спросили: чем отличается скрипка от контрабаса? Тот немного подумал, и ответил: – Контрабас дольше горит!
для этого достаточно всего лишь самую чуть протечь памятью
Скорее он хочет сделать из C++ Rust, но "через заднее крыльцо": по-умолчанию не безопасный язык, но с возможностью вкраплять safe подмножество.
Звучит так, как будто Страуструп рукомендует Java.
JVM же написана на плюсах, сл-но каждая программа на Java это огромная программа на плюсах с небольшой добавкой в виде кода на Java.
А вот интересно, на чем он написан.
Можно вот эту статью, например, посмотреть: How the 8086 processor's microcode engine works.
Это какого года фото?
А то там Windows NT, кажется?
справа хрюндель, слева не винда, в центре озеро. :)
Вроде 2008 года. Интересно было бы посмотреть на его современное рабочее место.
Вот относительно свежее из его личного твита за 2021 год:
https://pbs.twimg.com/media/FBgXWw8WQAgU21w?format=jpg&name=4096x4096
Слева KDE 3 (или 2, но это маловероятно), справа Windows XP
Если предположить, что на левом мониторе открыт более-менее актуальный список входящих сообщений (мне в заголовке активного окна привиделось "bigmail.research.alt.com:INBOX...", хотя могло и просто привидеться), а выделенное сообщение датировано четвергом, 7 февраля, что за последние годы было в 2019 и 2008 годах, то получается, что на этом мониторе скорее не WinNT, а какая-то иксовая DE (у liveCD с GParted на базе какого-то Debian ровно такая же отрисовка рабочего стола), показывающая в трее 10:47, среда 20 февраля... странно, что в правом мониторе, как верно заметили, WindowsXP в стандартной теме, но с фоновым рисунком какого-то озера - для 2019 как-то некрофилично смотрится (и опять - список сообщений, но уже другой)...
UPD: обновил комментарии, поддержу версию 2008 года от @codecity
Бардак, он не в языках, а в головах.
Безопасный код в принципе можно писать на чем угодно, если все время думать о безопасности. Использовать для этого специальные языки, которые берут на себя часть проблем - приятно, но надо помнить, что они же забирают часть контроля над происходящим за это. Тем более, что помимо проблем с менеджментом памяти, которые помогают решать некоторые языки, есть еще куча проблем с менеджментом остальных ресурсов, например времени выполнения или параллелизации, которые все равно приходится решать своей головой, и решая их неправильно можно получить кучу проблем в безопасности.
Если об утечках памяти говорить, то достаточно какой нибудь очереди сообщений, которая растет быстрее, чем обрабатывается. Это же тоже утечка ресурсов по сути своей
Бъерн говорит что можно снизить количество багов используя анализаторы, которые мало кто использует.
И как часто на их результаты реально смотрели?
Так и растовском чекере могут быть ошибки, разве его боги пишут?
Мне просто не удастся сделать check in кода, если анализаторы не согласятся.
Под динамическими asan, msan, tsan гоняются все тесты (кроме некоторых слишком тяжёлых для них). Анализаторы потоков просто часть компилятора (https://clang.llvm.org/docs/ThreadSafetyAnalysis.html).
Но ошибок обращения к памяти всё равно достаточно. Наверное есть ещё анализаторы которые мы не используем, и которые возможно помогли бы найти ещё часть проблем (пропорционально усложнив и замедлив разработку), но часто задумываюсь, не проще уж на Rust перейти.
Можно, конечно, рассуждать, что ядро Linux пишут идиоты, GCC пишут идиоты, Apache пишут идиоты, Nginx пишут идиоты, LibC пишут идиоты, PostgreSQL пишут идиоты, Firefox и Chromium пишут идиоты - но тогда встает вопрос, а кто не идиот-то?
Во всех этих проектах используются все доступные в мире анализаторы + пишутся самописные.
И как, помогает?
Если встроить анализатор в язык, то единственное что изменится - это то что он будет использован по-дефолту. Ну, я бы не сказал что это настолько глубокое изменение что меняет всю игру.
Но Раст идет дальше - его синтаксис затачивается для того чтобы было проще удовлетворить анализатор. И вот это уже меняет (волей-неволей) то, как будут писать код программисты.
С одной стороны, я этому мог бы порадоваться: если я работаю в команде, можно будет получить какие-то гарантии что мидлов компилятор заставлял думать о безопасности.
А с другой стороны, если я точно знаю что хочу сделать, то возьня с целью удовлетворить компилятор - слишком большая роскошь. Особенно если это не наемная работа, где время оплачивается, а свой проект, где time-to-market решает все.
Вот и получается что Раст становится языком выбора для средне-профессиональных команд, а не для индивидуалистов, рассчитывающих обгонять индустрию.
Эти команды конечно подрастут, станут профессионалами, но до этого пройдут годы. А жизнь идет сейчас. И если я хочу в одиночку делать больше чем средне-профессиональная команда, то, вероятно, нужно выбирать не Раст. И даже не С++
Идея не в том, чтобы встроить анализатор в язык (это ничем не отличается от того, чтобы гонять анализатор после компиляции), а в том, чтобы сам язык изменить так, чтобы анализ проводить было проще. Например, хотим избавиться от проблемы что ожидали строку а пришел дабл. Как чинить? Изменить язык, потребовав от разработчика указывать типы. Никакой самый умный чекер питона не проверит что передается инт там где ожидался инт, если в изначальной программе этого текста нет. Можно придумать эвристику, но легко видеть что она не всегда будет нормально работать.
У меня студенты сдают решения лабораторных работ под пятью компиляторами и трёмя ОС (в сумме 15 режимов), включая все пришедшие мне в голову санитайзеры и valgrind. А также, конечно, cppcheck, clang-tidy и все предупреждения на каждом компиляторе. И всё равно в решениях иногда остаётся undefined behavior, который надо ловить хитрыми тестами или даже глазами.
А вот тут подробнее, очень интересно стало, как вы UB ловите?
для раскрытия вопроса: лично я когда-то (30 лет назад) сильно сомневался в своём c/c++ коде, потом уверенность в нём (20 лет назад) очень сильно выросла, достигла пика, а вот лет десять назад опять сильно просела, и теперь меееедленно снова растёт, но по такому, очень логарифмическому закону :)
Пока что дешевле жить с неуверенностью; уверенность же штука вообще непростая. Насколько вы уверены, что вывод компилятора раста (вы же про него говорите?) соотвествует вашему коду?
Дедфуд - хаскелист, но в целом вопрос вполне законный :))) В общем случае нет никаких гарантий, что цомпелятор хаскеля не добавляет к его коду что-нибудь "от себя".
К компиляторам и софту подобного уровня просто дается аксиоматическое доверие. Просто по факту потраченного количества денег. Там хитрая зависимость от обьема кодбазы и потраченных баксов, но эмпирически можно признать всякие опенсслы, компиляторы и прочее настолько более безопасным, чем прикладной код который на них пишется, что их ошибка меркнет и учитывать её смысла нет. Точно так же, как если у вас программа сбоит не очень правильно первым делом заподозрить errata в процессоре.
Речь тут не об ошибке, а, скажем так, о намеренной закладке от того же АНБ.
А, ну опасенцам рептилоидов ничего не поможет.
Так и запишем - такого не может быть потому, что не может быть никогда.
Я прост не очень понимаю что предлагается с этим делать? Делать полностью замкнутую на себя систему производства всего, начиная от выплавки стали, а то мало ли какие бекдоры туда влили, может при определенной частоте направленного излучения крышка сделанная из такой стали начнет вибрировать и передавать данные о вычислениях? Повеситься с горя? Я не вижу способа с этим что-то сделать, а значит и обсуждать смысла нет.
Говорить о таких проблемах — хорошо и правильно, но имхо в миллионах строках кода можно запрятать что угодно при желании, условную стеганографию никто не отменял, и что безобидные на первый взгляд функции в определенном порядке образуют определенный функционал проверить в такой кодбазе нереально. Поэтому не вижу что можно тут сделать, честно говоря.
при определенной частоте направленного излучения крышка сделанная из такой стали начнет вибрировать и передавать данные о вычислениях
Рептилоиды не так просты. Они заложили закладку в машинные коды процессора, чтобы не важно было на каком языке вы пишете и каким компилятором пользуетесь, все равно на этапе исполнения программы, исполняться все их закладки!
Не уверен насчёт именно убийц C++, но однобуквенные имена для языков программирования действительно закончились.
Я просто в качестве примера привёл то, что вы с трудом можете быть уверены в качестве бинарного кода даже при том, что лично ваш исходный код прекрасен. Не зря ведь вливают деньги в проекты типа CompCert. Ещё раз моя мысль: ни в чём на этой планете нельзя быть на 100% уверенным, всё упирается в цену разработки, сопоставленной с ценой вероятной катастрофы.
Вообще говоря, авторы компилятора и сообщество Раста довольно сильно заморачиваются обеспечением корректности языка и компилятора, в том числе переписыванием рукописных компонентов на формально задаваемые, формальными доказательствами корректности и т.п. Понятно, что хотелось бы большего, но тем не менее - забота о безопасности в Расте системная, borrow-checker'ом она не исчерпывается.
Есть обязательное code review и полуавтоматические скрытые тесты, на них и ловим. Например, чтобы поймать static initialization order fiasco надо компилировать с единицами трансляции в разном порядке в зависимости от решения. То есть надо заранее подумать, что в решениях такая проблема будет и составить задание так, чтобы была сборка не как обычно через CMake, а руками.
А вот некорректные названия (двойные нижние подчёркивания, подчёркивания в начале глобальных переменных, типы заканчивающиеся на _t) и нарушения strict aliasing или левые const_cast ловятся только глазами. Ну, __ и _foo умеет ловить clang-tidy, а вот foo_t не умеет.
Что ловится разными компиляторами и санитайзерами: отличия int и long, разные переводы строк под Windows/Linux, почти все переполнения массивов и переполнения знаковых типов.
А что не так с типами, которые заканчиваются на _t?
Они зарезервированы POSIX, как и куча чего другого. Как я это выяснил: мне как-то сдали решение, которое у меня на компьютере не компилировалось с ошибкой "переопределение типа". Оказалось, что на моей ОС такой тип в стандартных заголовках есть, а у студента — нет. И у студента честно компилировалось.
С тех пор рассказываю, что зарезервированное под POSIX тоже лучше не использовать глобально. В идеале, конечно, всё в отдельный namespace заворачивать, но до namespace'ов не сразу доходим, и это тоже надо проверять глазами или писать свой отдельный инструмент.
Поддерживаю предыдущего комментатора: а что не так с типами, заканчивающимимся на _t?
Можно. Но у анализаторов есть небольшая проблема: статические пытаются угадывать что-то по контексту, которого может и не быть, а рантаймовые требуют, чтобы код был выполнен, то есть полного покрытия тестами.
В результате общая трудоёмкость по обвешиванию хинтами и написанию тестов на каждую ветку кода становится сравнимой с использованием языка, где делать правильно сразу заставляет компилятор.
в любом софте "в разное время находили ошибки". Непонятно зачем тут вообще управление памятью упоминать.
Серебряной пули нет. Языки якобы избавленные от проблем с памятью, во-первых по большей части не избавлены от этой проблемы, просто проблема размазана по другим слоям языка. Во-вторых имеют свои проблемы, которые приводят к тому, что в прогах написанных на них "в разное время находили ошибки".
Я вот тоже пишу на плюсах и не думаю о памяти. Потому что использую ровно 0 сырых указателей.
Кстати, как вы выражаете передачу ссылки на потенциально отсутствующий объект, не подразумевающую передачу владения?
std::optional<std::reference_wrapper<T>>. Но на C++ так никто не пишет.
А почему так никто не пишет? Антипаттерн или людям не охота обрабатывать optional?
Чтобы была охота обрабатывать maybe/optional, надо синтаксис над ним самим и его обработкой максимально упростить. По сути это должно быть продумано на этапе создания языка, как в котлине. Ну а когда для имплементации работы с этим optional надо городить кучу многословных конструкций, действительно становится неохота. Да и читаемость кода ухудшается.
std::optional не может хранить ссылки, так что приходится их оборачивать в иной тип. В std есть std::reference_wrapper, но это очень вербозно. Ну и ещё в C++ подобный тип будет нести оверхед по памяти на хранение признака наличия значения, в отличие от Rust.
Там вроде может зависеть от данных, нет? Я не силён в Расте, так что поправьте меня если что, но Option не будет иметь оверхеда в случаях либо когда значение укладывается в 32 бита, или когда это ссылка (чтобы можно было сделать оптимизацию за счёт non-nullable pointers), нет? Но да, если именно о ссылках, то есть оптимизация.
Опшн не будет иметь оверхеда если у типа есть ниша, куда можно поместить бит отсутствия значения. Например у i32 такой ниши нет, а у NonZeroI32 — есть.
std::weak_ptr ?
Не, ну безусловно, си позволяет выстрелить себе в ногу с любой изящностью, этого никто не оспаривал :)
Вы задали вопрос, я ответил вполне стандартной практикой. Другой вопрос, что эту практику сильно лихорадит в последние годы, ну да поглядим, куда кривая вывезет...
Насколько я понимаю, если мы говорим о C++, само наличие стека - штука весьма призрачная. Стандарт C/C++ не говорит о том, где и как хранятся данные.
Стандарт или нет, вы с таким ограничением теперь не сможете вызвать функцию, передав туда значение со стека, не скопировав его предварительно в кучу просто чтобы вызвать функцию. Вся практика в этом случае заключается в использовании некорректного, но "в целом близкого" типа. То есть плохая в общем-то практика, из разряда использовать double для индекса в массиве.
Что значит - стандарт или нет? Стандарт в си вообще не говорит о таких вещах, как стек или куча.
Как говорил Линус "фак стандарт". Стандарт это шашечки.
Главное что в физической железке под названием "компутер" эти штуки различаются, на стеке аллокать не стоит ничего, но нужно следить за размеров обьектов, у кучи другие трейдофы. Если стандарт это не учитывает то это минус к стандарту же, потому что он должен описывать жизнь, а не жизнь под него подстраиваться.
Зато стандарте есть вот такое понятие:
automatic storage duration. The storage for the object is allocated at the beginning of the enclosing code block and deallocated at the end. All local objects have this storage duration, except those declared static, extern or thread_local.
Его-то и называют "стеком", чтобы не сломать язык о постоянное повторение трёхсловного термина.
Кстати, как вы выражаете передачу ссылки на потенциально отсутствующий объект, не подразумевающую передачу владения?
указатель тут отлично подходит. Потому что владеющие указатели это плохой код. А раз он точно не владеющий, то он просто вью на какой то объект, которого потенциально нет
А как тогда выражается невладеющий, но (ввиду логики кода) гарантированно корректный указатель?
это называется ссылка
Ссылки бывают висячими, так что гарантия так себе.
По такой логике в расте тоже ссылка может быть висячей, так себе гарантии. Если она висит и вы обращаетесь - это уб
Ну, про раст я ничего не говорил, я лишь указал, что вы неправильно ответили на вопрос. Ссылки не дают гарантии валидности.
Насколько я помню, невалидная ссылка — это UB. Так что, в некотором смысле, они эту гарантию всё же дают.
Гхм. Ну тогда и сырой указатель даёт такую же гарантию :)
Неа, сырой указатель как раз может быть висячим, UB тут возникнет только при попытке разыменования.
Я могу ошибаться, но само наличие висячей ссылки это не UB, а вот её использование - точно UB:
If the object to which the glvalue refers is not an object of type T and is not an object of a type derived from T, or if the object is uninitialized, a program that necessitates this conversion has undefined behavior.
ссылки дают гарантию валидности. Согласно стандарту С++ обращение по "висящей" ссылке это УБ и программа более не является С++ и никогда не являлась. Большей гарантии чем ссылка никто обеспечить не сможет. В расте ссылка абсолютно такая же в этом плане, а несёте вы чушь
Нет прям я серьёзно в шоке:
А как тогда выражается невладеющий, но (ввиду логики кода) гарантированно корректный указатель?
ГАРАНТИРОВАННО КОРРЕКТНО
И ты пишешь
Ссылки бывают висячими
То есть ты всерьёз предлагаешь считать, что переданная в функцию ссылка может быть висячей и это как-то обрабатывать
Уточню. В Rust ссылки висячими не бывают. Вы или компилятор обязаны гарантировать это.
Потому что владеющие указатели это плохой код
Так и запишем, std::unique_ptr — это антипаттерн.
А что плохого в сырых указателях при отсутствии явных new/delete и арифметики над ними? Проверять отсутствие опасных операций не то чтобы сложнее, чем проверять отсутствие самих указателей.
P.S. Собственно, применение сырых указателей в такой семантике предлагается в тех самых Core Guidelines, о которых статья.
Управление ресурсами, действительно, ни при чём. Моя основная претензия в другом.
Ошибки в однопоточном коде на Java/Python приводят к тому, что код с момента возникновения ошибки работает с невалидными данными и на выходе получается либо мусор, либо падение с ошибкой. При этом до возникновения ошибки программа работает корректно. Другие потоки продолжают работать корректно. Структуры данных, с которыми не работает код с ошибкой, остаются без изменений. Можно просто по исходному коду проследить и доказать, что будет происходить, и это будет детерминировано.
Но как только в Си или C++ на горизонте маячит обязательный undefined behavior или ill-formed-no-diagnostics-required, любые гарантии исчезают. Могут испортиться данные, которые код не трогал последние три дня. Баг может исчезать от включения отладчика или добавления логирования. Программа может упасть до строчки, где ошибка реально происходит (подробнее). Программа может упасть в функции, которая сама по себе абсолютно корректна (подробнее). Программа из пяти строк может начать падать просто от смены флагов компилятора с динамической сборки на статическую и никакие анализаторы это не ловят (подробнее).
Такое поведение нельзя предсказать и гораздо сложнее отлаживать. Если в языке принципиально нет undefined behavior (кроме однопоточности), то даже при возникновении ошибок в программе можно что-то гарантировать про её состояние. В Си и C++ при undefined behavior гарантировать уже ничего нельзя. Можно только надеяться, что "здравый смысл" компилятор совпадает и всегда будет совпадать с вашим, что почти никогда не является правдой — смотрим на количество боли, которое требуется при смене одного компилятора на другой.
Вообще, ситуация с C++ напоминает вот этот божественный отрывок из "Автостопом по Галактике":
Внезапная тишина накрыла Землю. Гигантские суда недвижно зависли в небе — огромные, тяжелые, настоящий вызов природе.
Затем пронесся слабый шепоток, легчайшее дуновение, неожиданный и едва уловимый вездесущий звук: то включились все магнитофоны в мире, все телевизоры, приемники и усилители, все пищалки, среднечастотники и басовики. Каждая консервная банка, каждое мусорное ведро, каждый автомобиль, бокал и лист проржавленного металла — все они вдруг зазвучали не хуже идеально отрегулированной акустической системы.
— Люди Земли! — раздался голос — чудесный квадрофонический звук с таким низким коэффициентом искажений, что любой знаток отдал бы полжизни за возможность услышать это еще один раз. — Говорит Простатник Джельц из Галактического бюро планирования гиперпространственных трасс. Как вам, безусловно, известно, развитие отдаленных районов Галактики требует прокладки гиперпространственного экспресс-маршрута, проходящего через вашу звездную систему. К сожалению, ваша планета подлежит ликвидации. На это уйдет чуть меньше двух земных минут. Благодарю за внимание.
Невообразимый ужас завладел сердцами завороженных людей. Страх передавался от человека к человеку, словно магнит двигался под листом с железными опилками. Вновь возникла паника, отчаянная нужда спасаться бегством, хотя бежать было некуда.
Заметив это, вогоны опять включили свою громкоговорящую систему:
— Сейчас бесполезно прикидываться дурачками. Проекты трассы и планы взрывных работ были выставлены для всеобщего ознакомления в местном Отделе планирования на Альфе Центавра еще пятьдесят земных лет назад — достаточный срок, чтобы подать жалобу по надлежащим каналам.
Чудовищные корабли с обманчивой легкостью развернулись в небе. В днище каждого открылся люк — зияющий черный провал.
В это время кто-то где-то, вероятно, включил передатчик и от имени Земли обратился к вогонам с мольбой. Никто так и не услышал этих слов, зато ответ услышали все. Со щелчком ожила громкоговорящая система, и раздраженный голос произнес:
— Что значит "не были на Альфе Центавра"? Помилуй Бог, туда всего-то четыре световых года, рукой подать! Если вы настолько не интересуетесь общественной жизнью, то это ваше личное дело!.. Включить подрывные лучи!
Люки извергли поток света.
— Прямо не знаю, — капризно пожаловался голос, — какая-то апатичная планета… Ни капли не жаль.
Воцарилась чудовищная, кошмарная тишина.
Раздался чудовищный, кошмарный грохот.
Воцарилась чудовищная, кошмарная тишина.
Флот вогонов медленно уплыл в чернильно-звездную пустоту.
Человек не может писать код без багов, но можно сократить их до возможного минимума. Проблемы GCC, glibc и других программ не в том что их пишут идиоты, а в том что они имеют лишнии функции, которые просто раздувают код, а раздувание кода вызывает баги и проблемы с безопасностью. Вот здесь - https://suckless.org/sucks/ это разобрано
щВ этом и суть. У них нет таких переусложненных проектов, их проекты максимально упрощены. А раз ниже сложность проекта, то необходимости использовать для нескольких файлов кода cmake нет. Усложнять не надо, если кратно, упрощать надо. И это облегчит дальнейшую поддержку в разы.
Нюанс в том, что упрощать можно только до некоторого предела. Софт, который предназначен для решения больших и сложных задач будет большим и сложным. Postgresql невозможно сделать маленьким. А с ростом кодовой базы сложность поддержки может расти нелинейно без должной декомпозиции и архитектуры, а это тоже раздувает код.
Проекты suckless конечно известны за то, что хорошо выполняют свой круг задач, но этот круг ограничен. Сколько человек установит dwm вместо полноценного DE?
Я предлагаю не реализовывать ненужных функций. Для упрощения дальнейшей поддержки кода, для уменьшения количества багов, для улучшения безопасности. А если еще и при этом придерживаться стандартов, то будет вообще замечательно. Многие из программ suckless.org являются законченными продуктами и при этом что замечательно имеют небольшое количество потенциальных багов и их проще поддерживать. Никакого раздутого ненужного кода нет. Не надо писать код ради написания кода, пожалуйста.
Это Gnome, вид сбоку: урезание рабочего кода от релиза к релизу, чтобы меньше мейнтейнить + а все сверху - пользовательские extensions, прямой аналог - патчи для компонентов dwm. И то и другое отваливается при каждом апдейте основного проекта.
Вы немного не понимаете о чем я говорю. Я говорю про такую практику - https://vc.ru/dev/440224-kak-pisat-kod-chtoby-tebya-ne-uvolili
Только suckless он не про это. Он про "80% результата достигаются 20% кода, так давайте только эти 20% кода и писать, остальное ненужное переусложнение! Особенно весело будет вам попасть в те 20% нереализованного функционала. Скажем вот это
There is libdrw in suckless now, which still uses xft and fontconfig. Fontconfig and xft are ugly and require too much internal knowledge to be useful. The next logical layer evolved as pango and cairo. Both of course added HTML formatting and vector drawing. This is not needed to simply draw some text somewhere. And this is what a suckless font rendering library should do: Give it a font string and render at some position the given font without having to care about font specifics.
Что нам говорят? Нафиг эти ваши новомодные шрифты, есть таймс нью роман, чтоб текст отрендерить хватит, остальное все от лукавого. Засечки эти, интервалы всякие,… Слишком suckful.
Когда вы покупаете ботинок, вы наверное предпочтете тот, который вам нравится, а не тот где 80% удобно сидит а остальная часть рубцами царапает ногу, потому что производителю так проще и дешевле его сделать.
Вы неправы. На Suckless.org именно про отсутствие реализации ненужных функций в одной программе. То есть не пихать всё в одну огромную программу, а сделать несколько простых программ. Не реализовывать каждый раз в каждой программе абсолютно всё, а только то что нужно. Например для вкладок у них используется tabbed, И у их терминала st нет вкладок , у их браузера surf нет реализации вкладок. И tabbed может использоваться и с surf и с st. Для запуска программ у них нет встроенного меню в dwm, там используется dmenu. Пишете одну реализацию для сотни программ, а не сотню реализаций в сотне программ. И в итоге получается меньше кода. И это приводит к тому что такой код проще поддерживать, меньше потенциальных багов, лучше безопасность.
Я не думаю, что это то, что имеется в виду. То что вы описываете в мелких масштабах называется SOLID и около того (сингл респонсабилити, и вот это все), в больших масштабах — юникс вей. К сожалению я уже не найду прямой речи на сайте самого саклесс, видимо этот пассаж был удален, но раньше там было написано буквально "эдж кейсы не нужны почти никому но почти весь код занимается ими, давайте просто не будем его писать". Это уже достаточно отличается от солид/юникс вей, но не бьется с тем, что вы пишете.
Я бы предпочел не заниматься выпиливанием функций, а с нуля спроектировать и написать. Мне было бы так проще сделать, чем разгребать этот код.
Залез посмотреть, что у них там в разделе /rocks и обнаружил менеджер паролей, который держит их на диске в открытом виде. И браузеры, которые поддерживают аж HTML 4.01.
Я бы очень осторожно относился к мнению этих людей о безопасности чего бы то ни было и о том, какие функции лишние.
Человек несовершенен и даже "постоянно думая о безопасности" все равно не может писать код без багов. Просто не может и все.
Если кому сильно надо без багов - он может обратить свой взор на Idris
Речь шла про человека "самого по себе", т.е. без средств статического анализа. В примере использовалась сишка, в которой их почти нет, недаром его иногда называют портируемым ассемблером.
А с помощью анализа конечно же можно обеспечить себе сколь угодно большое количество гарантий, в пределах всяких умных теорем. Но и даже их часто можно обойти, убрав квантор универсальности и оставив "достаточно хорошие случаи".
Можно и с другой стороны посмотреть:
ОПАсный код тоже можно написать на чем угодно, кажется!
А если еще начать рассуждать для чего код может быть опасный, оно ведь не сводится только к ошибкам работы с памятью... наверно это тоже получится совсем не однозначная тема.
Количество вероятных ошибок и безопасность кода, наверно и все таки, не совсем одно и то же.
А вот Страуструп предлагает военным программистам думать... комплексно, взвешенно, разбираясь в парадигмах и понимая цель. А это, блин, дорого!
Нет, это категорически неправильный подход. На стройке надо ходить в каске и использовать страховочные канаты; движущиеся части станков надо закрывать кожухами; в автомобилях использовать ремни безопасности и кузовы с запрограммированной деформацией; органы управления снабжать защитой от дурака - а не говорить, что это просто у трупа бардак в голове был, а не в инструменте. Для безопасности надо не просто о ней думать, но и инструменты безопасные выбирать.
в приложениях, в которых производительность важнее безопасностиЗвучит как «в приложениях, в которых производительность важнее корректности результата».
Всё это звучит как "Не заставляйте нас искать ваши уникальные уязвимости, пользуйтесь нашими готовыми!"
По вопросу - Java/C#/Go/Dart/Swift - как бы вопросов нет, они не могут заменить там где требуется низкоуровневое использование. Вопрос только с Rust. Но он еще слишком мало применяется, даже до 1 процента не дотягивает. На первый взгляд хорош, но дьявол как всегда в деталях.
Да эта Rust секта поражает, упорно и весьма агрессивно бросаются на всех кто начинает язык критиковать и что вот вот придет будущее. Существует с 2006 года и при этом сделал какие то микро шаги в индустрии. Чуть более молодой Go куда больше прижился, чуть более старший C# еще более. Где наше великое Rust будущее - непонятно
особенно это забовно читать в контексте ембедед и промышленной разработки scada ПО, где прошивка контроллеров и железа может не обновлятся десятилетиями, а поддерживать и писать новый функционал нужно "сегодня", где наличие С++11 это уже отличная новость, и какой нибудь rust там появится ещё лет через 30 в лучшем случае если он доживёт.
при чём тут "деды страдали"? Ни кто в промышленности не обновляет ОС каждый год, например qnx6.5 до сих пор активно используется, много производственных железок до сих пор на ядре 2.6 или 3.12 с соответсвующим glibc, это не желание меня писать под этот древний кал это факт. Рад за тех кто может каждый выпуск компиль обновлять но оромное количество железа которые обслуживают канализации, заводы, приборы учёта и прочее обновляются ОООчень медленно, и все эти маня фантазии о "безопастности" за счёт перехода на другой язык не возможны там где эта безопастность реально нужна. Ты не запихнёшь раст в кардиостимулятор например и хз когда это станет возможным. Тоже самое и с банковской сферой и авиационной. А так же там где нужна реальная кроссплатформенность, На текущий момент нет другого такого языка на которм возможно написать код который одновременно работает на mips/elbrus/arm/x86/risc-v c десятком вариаций linux систем, различными версиями windows, а то и вовсе для baremetal.
Не нужно использовать С/С++, нужно использовать языки, написанные на С/С++
Л-2 (логика второго уровня)
Это малополезное заявление. Если мы возьмём условный "безопасный язык", то в программах на этом языке не будет (некоторых) проблем. Тщательно проверить код компилятора и стандартной библиотеки намного проще, чем если уязвимости могут быть вообще везде.
Плюс в "написанные на С/С++" тоже есть передёргивание: ни один из перечисленных языков (разве что в Ruby я не уверен) не написан целиком на С/С++. В JVM есть сишный код, но его доля далеко нe 100%. А Go даже не полается на LLVM.
Не нужно использовать IP, нужно использовать TCP (который основан на IP, получаем гарантированную доставку и гарантированный порядок).
Л-2 (логика второго уровня)
А С на чем написан? Только не говорите что на си, а то у нас получается рекурсия без выхода или что его боги с небес спустили. Это логика какого уровня?
На Бэйсике ))
Ну известно же как это делается. Сначала на ассемблере (если он уже есть, если нет, надо сначала сделать асм, написав его на машинных кодах) написали интерпретатор типа бэйсика. Потом на нем написали примитивный компилятор очень-очень упрощенного си, который не может почти ничего. Дорабатывали в течении нескольких итераций, получили си, который все ещё очень примитивный, но уже может кое-что, и на нем уже писали следующие версии си, пока не дописались до полноценного языка.
Первые компиляторы С писались на языке B
Страуструп заверил, что в сообществе C++ не игнорируются вопросы безопасности, так как это нанесло бы значительный ущерб многим проектам. А сосредоточившись исключительно на безопасности трудно сделать что-то удобное и рабочее, которое приживётся в проектах сразу.
Так о том и речь, что на C/C++ необходимо больше внимания уделять безопасности, он же по сути сам подтверждает то, с чем спорит.
Речь про то, что делать язык, ставящий во главу угла только лишь "безопасность" и только лишь в области "памяти" невероятно глупая затея, потому что приоритеты в реальной разработке совершенно другие.
Если первый приоритет безопасность, то легче ничего не написать - точно багов не будет
Замените "язык" на что угодно, например "лифт" или "мост" и посмотрите, изменится ли ваше мнение или быстрый лифт который иногда падает это не лучшая идея.
Как на счет самолетов - которые иногда падают. Готовы от них отказаться в целях безопасности. Мы пишем на С - т.к. нам так надо. Конкуренты пишут на Rust, Go, Java. Посмотрим. Единственно что точно - в команде на С не должно быть дилетантов.
На безопасности самолетов уж точно не экономят — так что пример плохой. Кроме того, самолеты безопаснее других видов транспорта (В 4 раза меньше смертность по сравнению с автомобилем, по статистике которую я смотрел в последний раз). Наконец, среди двух самолетов я предпочту тот, который безопаснее на 1% даже если это будет означать 10% подорожание билета.
Зря вы так думаете. Экономят и ещё как. У самолётов можно увеличить запас прочности, но это приведет к его утяжелению, а значит и расходу топлива и это сделает самолёт экономически неэффективным по сравнению с конкурентами.
Ну, например, резервная пара турбин, по одной с каждой стороны крыла могла бы решить проблему с отказом одного из двигателей. А дополнительная герметичная капсула салона препятствовала бы его разгерметизации.
А на случай аварийной посадки на воду явно не лишним было бы иметь на борту надувную, армированную, герметичную спасательную шлюпку, с радиомаяком и запасом сухарей и таблеток для опреснения воды, а не просто несчастные жилеты.
в команде на С не должно быть дилетантов
А код кто писать-то будет? /ш
Например, в приложениях, в которых производительность важнее безопасности, подобный подход даёт возможность выборочного применения средств, гарантирующих безопасность только там, где это необходимо.
Если у вас память освобождает не тот код, который ее должен освобождать, то тут не важно, быстрая у вас программа или нет, она просто неправильная. Что толку, что ваша программа быстро упадет? А именно это и проверяет растовский borrow checker, и ничего более. Не понимаю, как можно сознательно ратовать за его отсутствие, как будто его отключение сделает падающий (а потому некомпилируемый в расте) код не падающим.
Причем это ведь проверки только времени компиляции, в бинарник никаких проверок не вставляется (ну, может только в отладочном режиме). Если же вы считаете себя умнее компилятора (и коллектива из сотен людей, стоящих за ним), то можете воспользоваться unsafe, но и помощи от компилятора тогда не ждите, в лучших традициях C++ UB. Не забывайте правда, что если код пишите не только вы один, то умнее компилятора должны быть и все остальные люди, которые этот код будут поддерживать.
эх, ещё бы вы понимали о чем говорите. так называемый "бороу чекер" делает ошибкой компиляции невероятное количество абсолютно валидного и правильного кода.
А насчет программ которые ценят больше перфоманс чем формальное доказывание того что их код не содержит уб - посмотрите на игры, например.
С точки зрения юзера при обращении по неправильному индексу в массив С++ код упадёт(сегфолт или проверка от опции компилятора)
Раст код упадёт(будет исключение) или сегфолт(если был _unchecked доступ)
Насчёт утечек - раст никак от них не защищает вообще, утечки это "сейф" код в расте
невероятное количество абсолютно валидного и правильного кода.
Пожалуйста в процентах и примеры, с доказательствами "абсолютной правильности".
формальное доказывание того что их код не содержит уб
А они и не содержат этих доказательств. С другой стороны, вы же первый будите плеваться и костерить "тупых разработчиков", когда там какой-нибудь "меч +100500" на самом деле будет не учитывать эти плюсы, или боты будут вас через стены убивать, а вы их — нет.
Раст код упадёт(будет исключение) или сегфолт(если был _unchecked доступ)
Он не скомпилируется.
Насчёт утечек — раст никак от них не защищает вообще,
А он обещал?
ожалуйста в процентах и примеры, с доказательствами "абсолютной правильности
Это прикол или что? Вам серьёзно неочевидно что существование двух ссылок может быть валидно? Может вы ещё весь unsafe код в расте считаете не существующим? Зачем-то же отключили гарантии в этом месте, иначе просто нереализуемы становятся 99% кода?
Просьба привести примеры, доказательства и охват проблемой в процентах, вроде бы ясно написано.
Подскажите, какие именно гарантии отключены в unsafe?
Вам серьёзно неочевидно что существование двух ссылок может быть валидно?
Мистер Борров никогда и не запрещал иметь несколько алиас-ссылок в один момент времени )
Если хотите изменять один объект из нескольких мест, то вам в любом случае придётся убедиться в безопасности своих намерений, хоть в расте, хоть в плюсах, хоть где. В расте берёте подходящий iterior-mutability и через него получаете доступ на изменение в сколь угодном количестве мест. Для вас как пользователя этого API — всё в safe подмножестве, включать голову даже не нужно, никаких опасных вещей по недосмотру сделать не выйдет. Ну мечта же!
Может вы ещё весь unsafe код в расте считаете не существующим?
Какая разница сколько там unsafe кода? Главное что можно самому оставаться в safe окружении и спокойно писать код.
Все эти претензии — вообще несерьёзно. В расте есть реальные проблемы, например отсутствие TAIT и подобных штук. Но никто из хэйтеров раста про это почему-то не упоминает, видимо просто не успевают с этим столкнуться в процессе изучения языка. Но зато уже идёт набрасывать на форуме о том что раст не нужен, ведь "там unsafe и уникальные ссылки нельзя шарить!!!".
Да, оно самое. В целом, полезная штука, скоро уже вроде как должны стабилизировать. С учётом недавней стабилизации GAT'ов, это несколько облегчит асинк в расте (хотя наверное не на много), с которым работать довольно больно. Позволит использовать async трэйты без костылей в виде сторонних крейтов, и, возможно, уйдёт необходимость везде обмазываться Pin'ами и Box'ами.
И хотя, всё это существует уже довольно давно в nightly-версии компилятора, многие всё равно сидят на stable-версии по многим причинам, и очень этого ждут.
И хотя, всё это существует уже довольно давно в nightly-версии компилятора, многие всё равно сидят на stable-версии по многим причинам, и очень этого ждут.
Очень жаль этих товарищей. Просто глянул список своих расширений в открытом щас проекте:
#![allow(incomplete_features)]
#![feature(allocator_api)]
#![feature(associated_type_defaults)]
#![feature(backtrace)]
#![feature(concat_idents)]
#![feature(const_option)]
#![feature(const_result_drop)]
#![feature(const_trait_impl)]
#![feature(const_try)]
#![feature(core_intrinsics)]
#![feature(generic_associated_types)]
#![feature(generic_const_exprs)]
#![feature(inline_const)]
#![feature(let_else)]
#![feature(map_first_last)]
#![feature(try_blocks)]
#![feature(type_alias_impl_trait)]
#![feature(scoped_threads)]Ну… Мээ… Ждать мне до второго присшествия пока все стабилизируют. Раст на стейбле это не раст, а какая-то смешная игрушка, уж извините все, Кого обидел.
Что-то кстати стабилизировали в последние полгода, список можно подсократить на пару позиций, но все равно писать без этого больно.
Да, за мкадом на стэйбле жизни нет — это довольно популярная концепция, но я всё же почти всегда использую стэйбл. Ну а язык в принципе игрушечный, это и так понятно ))
Что-то кстати стабилизировали в последние полгода
Можно убрать let_else, map_first_last и scoped_threads. Возможно, можно убрать и generic_associated_types, но это зависит уже от конкретного кода.
И да, для чего тебе интринсики потребовались? Неужели ради likely/unlikely?
> Он не скомпилируется.
Абсолютный бред, вы не знаете о чем говорите. Обращение по индексу в расте проверяется на рантайме, оно скомпилируется и даст исключение, если индекс слишком большой
какой-нибудь "меч +100500" на самом деле будет не учитывать эти плюсы, или боты будут вас через стены убивать, а вы их — нет.
Зато разработчики сделали игру не за 25 лет, а за 3 года, потому что не нужно было доказывать компилятору, что тут то, тут сё. И всего лишь меч не работает, а не падение с "паникой" растовой
и даст исключениеНу… если обращаться с помощью квадратных скобок — да, оно таки запаникует при выходе за границу. Но во-первых у Vec есть замечательные get() и get_mut() которые возвращают Option<> (то есть вы легко проверите, удалось вам что-то получить или нет), а во-вторых, даже если вы используете квадратные скобки, вышли за границы, и ваша программа запаниковала — она сделала это сразу (а не через полчаса работы в непонятном месте, потому что всё это время обрабатывала какой-то мусор) и сама (а не была пристрелена по SIGSEGV).
Вы сначала признайте, что сказали фигню про то что "не скомпилируется".
В С++ можно
1. использовать .at которое даст исключение, если неправильный индекс
проверить индекс, вау
поставить флаг компилятора, так чтобы кидалось исключение по умолчанию.
Невероятно, раст чем лучше ? Хуже получается, возможностей то меньше
Почему, если возможностей выстрелить в ногу меньше — то это хуже?
let arr = [0; 25];
println!("{}", arr[25]); // error: this operation will panic at runtimeVec.Теперь по пунктам:
.at которое даст исключение, если неправильный индексВместо «У нас такого нет» (
Option::None) — сразу «Пшёл отсюда!» (std::out_of_range) — ну такое, конечно, очень сомнительное удовольствие сразу в исключение падать. В Rust же у вас просто не сойдётся тип и придётся этот Option распаковывать (да, можно и с помощью .unwrap(), что будет равнозначно C++-коду if(index >= size) std::abort();. А нет, не будет — abort не пишет стек-трейс в STDERR, придётся корку ковырять в отладчике).проверить индекс, вауВы так говорите, будто в Rust проверять индексы запрещено. Кстати, вы же в C++ везде используете
std::array вместо C-массивов (чтоб всегда знать размер и никогда не забывать проверять какую-то отдельную внешнюю переменную), верно?поставить флаг компилятора, так чтобы кидалось исключение по умолчанию.Или забыть, или перетереть кривыми скриптами сборки, или перейти с GCC на MSVC у которого другие флаги и забыть изменить, или… Для поведения, отдалённо похожего на Rust, вам нужно по меньшей мере
-Wall -Wextra -Werror — у вас это есть в каждом проекте на C++, включая утилиты, которыми пользуется полтора землекопа раз в квартал?В конечном счёте, всё сводится к «люди делают так, чтобы тратить меньше усилий». К сожалению, в C++ «меньше усилий» = «больше ошибок», многие из которых в Rust невозможны из-за «злого компилятора с borrow-checker'ом». К сожалению для С++, типичные ошибки типа null pointer dereference в Rust требуют много усилий для намеренного воспроизведения (например, использование
unsafe, который должен быть как красная тряпка для ревьюверов).И всё же это не фигня: если у вас именно массив, то примитивное обращение по неверному индексу не скомпилируется
Скомпилируется, скомпилируется:
fn p(a : &[i32])
{
println!("{}", a[25]);
}
fn main()
{
let arr = [0; 25];
p(&arr);
}Scope немного другой - и все, приплыли.
ну такое, конечно, очень сомнительное удовольствие сразу в исключение падать.
В C++ есть нормальная обработка исключений. В расте же паника - это unrecoverable error. Сомнительное удовольствие как раз паниковать вместо выбрасывания исключения, которое можно обработать.
К сожалению для С++, типичные ошибки типа null pointer dereference в Rust требуют много усилий для намеренного воспроизведения (например, использование
unsafe, который должен быть как красная тряпка для ревьюверов).
В реальном коде на расте (а не в сферическом safe-only коде в вакууме) ошибки при работе с памятью вполне себе встречаются (это из относительно свеженького), и последствия вполне себе фатальны - всякие там use-after-free, out-of-bounds reads/writes, полный букет. Да по-другому и не могло быть. И количество подобных проблем будет только расти с увеличением массы кода на расте (невольный каламбур получился, хехе). И хертблиды разные никуда не денутся, будут у раста свои собственные (а скорее всего уже есть, просто о них пока никто не знает - ну может кроме АНБ :)).
придётся корку ковырять в отладчике
Кстати, иметь корку куда полезнее, чем иметь просто стектрейс. В стектрейсе слишком много чего тупо нет.
Есть что-то забавное в том, что в последнем примере всё решилось удалением unsafe-кода. Соблюдать правило "не писать unsafe без крайней необходимости" проще, чем следить за UB в C++ коде. Намного проще. На порядки.
Опять же важно не наличие подобных ошибок и даже не их количество, а простота их обнаружения и исправления. Проверка условного десятка строк с пометкой unsafe сильно дешевле полного аудита всего кода.
И кстати, вы не совсем правы на счёт того, что паники нельзя отловить. Всё немножечко сложнее, чем просто можно/нельзя. За подробностями рекомендую читать документацию. Ну и замечу, что не смотря сильное сходство, паники не являются аналогом исключений.
Соблюдать правило "не писать unsafe без крайней необходимости" проще, чем следить за UB в C++ коде. Намного проще. На порядки.
Если бы можно было обойтись без unsafe, его бы не добавляли в раст. Но увы и ах в реальности совсем обойтись без него нельзя, и результат как известно на лице. Впрочем в расте до сих пор есть проблемы с лайфтаймами, приводящие к use-after-free без всяких unsafe.
Ну и замечу, что не смотря сильное сходство, паники не являются аналогом исключений.
Конечно, не являются. И в целом без исключений трудно нормально обрабатывать к примеру ошибки в реализациях перегруженных операторов - разве что и в них обмазываться Option или Result. Кстати напомните, почему в расте до сих пор нет адекватного аналога плюсовому placement new? Не потому ли, в том числе, что нет механизма дать вызывающему коду понять, был ли все-таки сконструирован объект или нет? В C++ конструктор может выбросить исключение (со всеми RAII гарантиями), а в расте такого механизма нет.
Я не говорю о том, что unsafe применять нельзя вообще. Это очень важный и очень сложный инструмент. Но нужен подобный инструментарий редко и требует дополнительной квалификации. Тоже самое в разной степени касается, например, перегрузки операторов и процедурных макросов (впрочем и обычных макросов это тоже касается). Почти всегда вы избегаете использования подобных инструментов. Кроме тех случаев, когда без них не обойтись. Это как наклейка "осторожно, высокое напряжение" на трансформаторной будке. Перед тем, как полезть внутрь, убедитесь что вы электрик.
Немного другой пример. Трейты являются практически полноценной реализацией ООП со всеми стандартными наворотами включая множественное наследование. При этом Rust определённо не является ООП языком.
И в целом без исключений трудно нормально обрабатывать к примеру ошибки в реализациях перегруженных операторов - разве что и в них обмазываться
OptionилиResult.
Нет. Вместо этого вы делаете метод, который возвращает Option/Result. Я всё понимаю, микроскоп красивый, новенький, блестящий. Однако всё же не стоит забивать им гвозди.
Вообще это довольно важная часть дизайна на мой взгляд. Rust старается оградить вас от неправильного использования собственного инструментария. В некотором смысле это также реализация принципа "не плати за то, что не используешь", но в плане когнитивной сложности.
Вместо того, чтоб писать какие-то хитрые штуки с возвратом ошибок из перегруженный операторов вы просто паникуете там + пишете методы. А оператор может быть тупо вызовом метода + unwrap. Ну или не перегружать ничего. И вам не нужно держать в голове особенности поведения конкретной реализации определённого оператора. Вместо этого вы можете один раз запомнить общий случай.
Паники отличаются от исключений тем, что единственный адекватный способ их "обработать" - написать корректный код. При схожести механизма работы, парадигма совершенно другая. Но у вас всё ещё есть возможность их ловить в очень специфических случаях.
Кстати напомните, почему в расте до сих пор нет адекватного аналога плюсовому placement new? Не потому ли, в том числе, что нет механизма дать вызывающему коду понять, был ли все-таки сконструирован объект или нет?
Понятия не имею если честно. Не изучал этот вопрос. Буду рад, если вы приведёте реалистичный пример, где это вообще может быть нужно, std::mem::MaybeUninit недостаточно, а другими способами не реализуемо.
Нет. Вместо этого вы делаете метод, который возвращает
Option/Result
и получаете
1. потерю производительности, потому что теперь ветвление всегда
потерю читаемости кода, потому что unwrap или match теперь просто везде
ухудшение интерфейса
потеря copy elision
В общем то можно было сразу вернуться к корням - еррор кодам из С, суть та же самая.
Вам сказали: "как я могу реализовать оператор+ для строк, ведь может не хватить памяти и кинется исключение?"
Вы отвечаете: " сделайте метод возвращающий Option"
Итого имеем вместо A + B
A.trait_add::add(B).unwrap();
Это и называется - нет инструмента для этого.
потерю производительности, потому что теперь ветвление всегда
Обработка исключений может быть гораздо дороже. На некоторых архитектурах настолько, что вообще нет возможности их использовать. Опять же куча оптимизаций есть, которые могут превратить бранч во что-то условно бесплатное. В современных архитектурах есть branch prediction, а в современных компиляторах LTO, PGO и прочие ништяки.
потерю читаемости кода, потому что unwrap или match теперь просто везде
Да не, просто один оператор ?. Алсо чем match вас смущает в сравнении с try-catch? Полагаю, тем, что match это гораздо более мощный и гораздо более удобный инструмент.
ухудшение интерфейса
Тем, что всегда требуем явно писать возможные ошибки? Так это наоборот улучшение. Явное лучше неявного.
потеря copy elision
Бессмыслено натягивать эти термины на Rust с его move-семантикой. Лучше сходите и напишите ещё один копирующий конструктор.
как я могу реализовать оператор+ для строк, ведь может не хватить памяти и кинется исключение?
Никак. Математические операторы предназначены для штук, подобных математическим примитивам. Строки математическими примитивами не являются. Об этом всём сказано в документации. Для хитрой конкатерации строк есть макрос format_args! и куча разных штук поверх него.
Математические операторы предназначены для штук, подобных математическим примитивам.
Ахахаха, т.е. мяу. ОК, как в рамках раста обработать ошибки типа знакового переполнения или целочисленного деления на 0 при использовании математических операторов "для штук, подобных математическим примитивам"?
А вообще конечно забавно наблюдать попытки выдать откровенно убогое решение за какой-то прорыв. Аргументы типа "перегрузка операторов теоретически есть, но практически использовать её нельзя" просто умиляют. Многие верят (С).
Ахахаха, т.е. мяу.
Начинаю беспокоиться о вашем ментальном здоровье. Старайтесь соблюдать рекомендации психиатра. Я свои таблетки принял и рекомендую вам сделать тоже самое. Иначе опять санитар стучаться в палату будет.
как в рамках раста обработать ошибки типа знакового переполнения или целочисленного деления на 0 при использовании математических операторов "для штук, подобных математическим примитивам"
В зависимости от контекста. В большинстве случаев писать нормальный код, который заранее валидирует входные данные. Компилятор скорее всего оценит ваши старания и хорошенько соптимизирует. Есть всякие checked_div/overflowing_div/saturating_div для некоторых специальных случаев.
Если вы привыкли использовать перегрузку операторов для странного, то это это плохая привычка.
Если вы привыкли использовать перегрузку операторов для странного
Сложить два числа с возможностью корректной обработки потенциальных ошибок - это "странное"? Для этого не должны использоваться арифметические операторы? Ваше упорство даже по-своему забавляет меня. Ладно, опять-таки, все ясно.
Сложить два числа - не странное. Сложить две строки - странное.
Тот факт, что интерфейс работы с числовой арифметикой не идентичен у Rust и C++ не является проблемой Rust или C++. Здесь только ваши заблуждения.
Тоже самое и в контексте перегрузки операторов. Семантика и практика применения другая. Вы упорно утверждаете, что оно обязано быть идентичным.
Многие инструменты при использовании приносят не только пользу, но и вред. Так у механизма исключений есть проблемы по части производительности и переносимости. Нецелевое использование перегрузки операторов порождает код, работа которого неочевидна. Тоже самое и для некоторых других штук.
Rust пытается своим дизайном предотвратить часть неправильного использования подобных инструментов. Может не всегда, но достаточно часто у него это получается. В конце концов для самых упоротых упорных есть инструменты для воплощения своих фантазий. Использование подобного будет сложнее использования более подходящего инструмента. И это сделано намерено.
Сложить две строки — странноеЭто не странно, это неоднозначно, потому как операция сложения по определению коммутативна, а конкатенация строк — нет. Если и абстрагировать конкатенацию строк в математическую операцию, то разумнее использовать некоммутативные операции, алгебраические манипуляции с которыми не приведут к искажению результата (возведение в степень например). А вот если брать объединение наборов строк — то там использовать сложение вполне логично.
операция сложения по определению коммутативна, а конкатенация строк — нет
Скажите, пожалуйста, а операция умножения по определению коммутативна?
В Mathematica, например, некоммутативное умножение — это отдельный оператор
**, который несколько ограничивает допустимые алгебраические преобразования. Для умножения матриц там определено скалярное умножение записываемое как точка, обычное умножение применительно к матрицам означает поэлементное умножение.В других языках программирования
** может значить возведение в степень, сложение и умножение часто предполагаются некоммутативными, но могут стать коммутативными в режиме «оптимизирующая компиляция». А чтобы было ещё веселее, в некоторых компиляторах с++ дополнительно предусмотрен выбор Floating Point Model, чтобы лишнего не оптимизировать, и результат вычислений в Debug не будет отличаться от Release (но не факт). Поэтому до сих пор сохранились любители писать математические вычисления непосредственно на ассемблере и даже в FPU, стековая организация которого даёт хоть какую-то уверенность в соответствии заявленной последовательности операций исполняемым.Ну а отличия
= от == от === от := в зависимости от контекста, приоритета операций и языка программирования радуют уже не одно поколение программистов. #define true false и счастливой отладки, как говорится.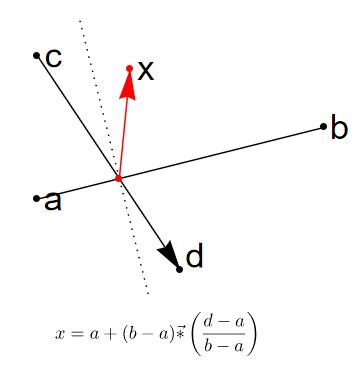
- если условие всегда выполняется, то бранч предиктор легко его проглотит без замедления времени работы. Если условие то туда, то сюда, то дешевый DU дешевле механизма исключений
- Только у вас читаемость не ухудшается, а улучшается, потому что теперь вы явно видите точки где может произойти ошибка, и где её быть не может
- То же самое: ошибки являются частью интерфейса. Хорошо когда оно в типах, а не только в документации (которую никто не читает пока все не сломается, а может и тогда)
- Это вообще каким образом тут?
В общем то можно было сразу вернуться к корням — еррор кодам из С, суть та же самая.
Так у них единственная проблема была в том, чтоб удобно с этим работать — в сишке нет тегированных DU. В остальном одни плюсы. Например — я могу спокойно вызвать 10 функций и остановиться если в любой из них произошла ошибка. Просто трайкетч влепить? А теперь если в многопотоке делать — в расте я добавлю один par_iter() и теперь все то же самое делается параллельно, и соседние треды автоматически остановятся когда я в любом из них наткнусь на ошибку.
В общем, много преимуществ у такого подхода.
Итого имеем вместо A + B
И как читающему код человеку понять, может тут быть ошибка или нет? Или вы считаете что ему такими нюансами голову не нужно забивать? Я лучше увижу a.checked_add(b) и буду точно видеть что оказывается сложение может не сработать, и это ожидаемое поведение, чем скопирую подобный код будучи уверенным что он работает как я думаю, а оказывается челоек неявно полагался на эксепшоны. Фразу "не стройте логику на эксепшнах" придумали не в расте, а это именно что логика.
Буду рад, если вы приведёте реалистичный пример, где это вообще может быть нужно
Потрясающее знание вопроса, в следующий раз подумайте зачем Box это ключевое слово и что происходит когда создаётся значение в "куче".
в C++ std::make_shared конструирует значение сразу на месте, в расте конструирует и потом нужно копировать, потому что нет механизма создать на месте
Вместо того, чтоб писать какие-то хитрые штуки с возвратом ошибок из перегруженный операторов вы просто паникуете там + пишете методы. А оператор может быть тупо вызовом метода + unwrap. Ну или не перегружать ничего.
Ну да, как я и сказал. "Потребности в колбасе сегодня нет" (С) древний анекдот.
Буду рад, если вы приведёте реалистичный пример, где это вообще может быть нужно
Например, чтобы реализовать аналог emplace из плюсового std::vector для Vec. Т.е. не создавать сначала объект на куче/стеке, а потом копировать или перемещать его в Vec, а создавать сразу там на месте, в неинициализированном куске памяти, предвыделенном Vec. Естественно, без необходимости оборачивания этого в unsafe, ведь это нибизапастно. Как думаете, почему такой возможности до сих пор нет?
Ну да, как я и сказал. "Потребности в колбасе сегодня нет" (С) древний анекдот.
Выше ответил. В Rust перегрузка операторов используется сильно реже и только в тех местах, где это необходимо. Скажем, складывание строк выглядит достаточно глупо.
Естественно, без необходимости оборачивания этого в unsafe, ведь это нибизапастно.
Вы используете unsafe тогда и только тогда, когда компилятор не имеет возможности доказать что-то. unsafe fn или там unsafe trait означает, что помимо гарантий, предоставляемых Rust, вы ещё должны помнить о дополнительных ограничениях. Использование unsafe {} означает, что вы удовлетворяете эти ограничения самостоятельно. Но ничего сверх этого. Механика unsafe не является инструментом оптимизаций или способом хакнуть систему. Только тем, что написано на этикетке.
Т.е. не создавать сначала объект на куче/стеке, а потом копировать или перемещать его в
Vec, а создавать сразу там на месте, в неинициализированном куске памяти, предвыделенномVec.
Приведите пример, когда это необходимо. В большинстве случаев всё равно нужно некое инициализирующее значение и его в любом случае придётся перемещать откуда-то. Часть простых случаев скорее всего итак оптимизируется. Для другой части есть MaybeUninit (включая инициализацию нулями).
Как думаете, почему такой возможности до сих пор нет?
По той причине, что эту возможность ещё не реализовали.
Скажем, складывание строк выглядит достаточно глупо.
Потребности в колбасе нет.
Приведите пример, когда это необходимо. В большинстве случаев всё равно нужно некое инициализирующее значение и его в любом случае придётся перемещать откуда-то.
Да в большинстве случаев это необходимо :) Скажем вместо того чтобы перемещать "инициализирующее значение" (а в случае подов перемещение по сути = копирование) сначала на стек, а потом в вектор можно было бы переместить их сразу в вектор.
По той причине, что эту возможность ещё не реализовали.
Ну и по какой же причине эту возможность так до сих пор и не реализовали, не задумывались?
Ладно, в общем, ясно.
Потребности в колбасе нет.
Колбасу принято пихать в рот. Более того, на колбасе написано, что её в рот. Если вы, как разработчик, привыкли пихать колбасу в непредназначенные для этого отверстия, то чтож, вы всё ещё можете продолжать делать это. Кто я такой, чтоб осуждать вас. Но прошу вас, пожалуйста, не делайте этого на людях. И уж точно не стоит обвинять колбасу в том, что её диаметр не соответствует вашим ожиданиям. Тут я могу посоветовать только продолжать разработку.
Да в большинстве случаев это необходимо
Лишнее копирование на стек удаляется компилятором. Я не поленился и сходил проверить простенький случай. Потому и прошу вас привести пример, когда это не работает.
Ну и по какой же причине эту возможность так до сих пор и не реализовали, не задумывались?
Поверхностный поиск показывает, что корректнее говорить не о том, что не реализовали, а о том, что не стабилизировали. Увы, детали пояснить не могу. Не являюсь тем, кто реализует эту фичу. Раз вы знаете больше, так объясните.
Ну и по какой же причине эту возможность так до сих пор и не реализовали, не задумывались?
Не задумывался. Но теперь мне интересно и я готов послушать. Могу лишь предположить, что фича достаточно сложная, с нюансами.
Например, чтобы реализовать аналог emplace из плюсового std::vector для Vec. Т.е. не создавать сначала объект на куче/стеке, а потом копировать или перемещать его в Vec, а создавать сразу там на месте, в неинициализированном куске памяти, предвыделенном Vec
Вот как раз для этого никакого placement new не требуется. Достаточно MaybeUninit внутри Vec, инлайнинга и немного удачи.
Причём инлайнинг и удача в плюсах тоже нужны, ведь без них emplace вам навызывает конструкторов перемещения.
Для функционирования emplace никакая "удача" в плюсах не нужна.
Нужна. Вот откажется компилятор ваш emplace инлайнить — и что делать будете?
Вставляемое в вектор значение и правда будет собрано на месте — но вот все аргументы конструктора один фиг окажутся на стеке.
То есть такой способ инициализации работает только если вы значениями по умолчанию инициализируете, а это не общий случай.
А какая разница, инлайнит он их или нет? Промежуточный объект при emplace все равно не создаётся, аргументы конструктора копируются/перемещаются ровно один раз сразу на место, а не как в расте - сначала создаётся объект на стеке, а потом он копируется/перемещается в вектор. Понятное дело что в расте компилятор тоже может подшаманить, и вот тут-то и нужна удача, а в плюсах все и так работает.
но вот все аргументы конструктора один фиг окажутся на стеке.
В расте они окажутся на стеке как минимум на один раз больше :)
Проблема в том, что если вам только не повезло столкнуться с упрощённой задачей, объём всех передаваемых аргументов скорее всего будет равен объёму сконструированного объекта. И вот эти-то аргументы вам всё равно передавать нужно...
В случае если аргументы передаются в "конструктор" по значению и являются подами:
В расте: копирование значений в аргументы "конструктора", копирование их в поля временного объекта, копирование их в вектор. Итого 3 копирования.
В плюсах: копирование значения в аргументы конструктора, затем копирование их сразу в вектор. Итого 2 копирования.
Если сам объект является подом — в расте у него можно никакой конструктор не вызывать, и будет тоже 2 копирования. И даже если не является, конструктор — кандидат номер 1 на встраивание.
Но да, если надо отслеживать каждое лишнее перекладывание байтика — Rust будет плохим выбором.
Только нужно учитывать, что в расте мало что является копируемым, по умолчанию действует перемещение. Копируемыми обычно объявляются типы, для которых это дешевле. Так что то, что в коде для плюсовика выглядит как копирование, им может не являться. Я не настоящий сварщик, но по-моему здесь все конструируется по месту: https://godbolt.org/z/r4eEGhfPs (со строки 539 в левой части diff-а).
В дебаге слева действительно вызывается push и вероятно происходит копирование, а справа по-моему все еще конструирование по-месту
Гражданин, осторожнее, осторожнее! У вас в котёнке дверца! :)
Для языка программирования важно не только что именно на нём удобно написать, но и что в нём намеренно сделано неудобным. Развитие парадигм языков программирования в основном идёт в напралении грамотного выбора ограничений. Например, уход от goto, инкапсуляция. А ведь тоже были люди, которые говорили, что постоянное использование goto и глобальных переменных - это правильно, а кому не нравится - у того просто руки не из того места rustут. Но жизнь убедительно показала, что эти ограничения убеньшают количество ошибок, ускоряют разработку и помогают поддерживать и развивать большие проекты. Ряд ограничений в Расте - сделаны из подобных соображений. Оптимально ли соблюдён баланс? Не возьму на себя смелость уверенно утверждать, но мне кажется, что приближение неплохое.
Очередное использование баек про то, что можно проверить только unsafe часть и гарантированно проблем нет. Это просто ложь, нужно проверять всё равно весь код даже чтобы избежать ошибок только с памятью, любое unsafe полагается на какой то инвариант, а его нарушение может произойти при просто вызове функции из safe кода.
И не надо говорить, что мы тут всё на месте с unsafe проверим и интерфейс будет не полагаться ни на какие инварианты, это просто невозможно реализовать вот и всё
Вы хотите сказать, что кеширования не существует?
unsafe означает, что вы обязаны проверить все инварианты вручную. Полностью внутри блока unsafe. Всё, что покидает блок unsafe, обязано соответствовать save-гарантиям.
Очередное использование баек про то, что можно проверить только unsafe часть и гарантированно проблем нет. Это просто ложь, нужно проверять всё равно весь код даже чтобы избежать ошибок только с памятью, любое unsafe полагается на какой то инвариант, а его нарушение может произойти при просто вызове функции из safe кода.
Не может. Сейф функция гарантирует корректную работу на ЛЮБЫХ входных данных (В рамках даваемых языком гарантий офк). Функция которая требует особых условия на инпуте не может быть сейф (например, unwrap_unchecked)
Сомнительное удовольствие как раз паниковать вместо выбрасывания исключения, которое можно обработать.
Поэтому для тех ошибок, которые можно обработать — возвращается Result или Option, который по семантике ближе. И для обращений по индексу как раз есть метод get, возвращающий Option. Скобочки просто сахар над условным `.get().expect("Index out of range")`, для случаев когда выход за пределы массива не должен происходить (а если произошел, то это баг, и надо немедленно об этом сигнализировать)
Панику для обработки ошибок не используют, паника это когда уже всё, приплыли
// Допишу тут заодно
Scope немного другой - и все, приплыли.
Ну нет же. У вас тут тип другой. Для &[T] размер при компиляции неизвестен
Ну нет же. У вас тут тип другой. Для
&[T]размер при компиляции неизвестен
Неизвестен в конкретно этой функции. Ну ОК, так больше нравится:
fn p(i : usize)
{
let arr = [0; 25];
println!("{}", arr[i]);
}
fn main()
{
p(25);
}? Тут размер известен.
В обоих ваших примерах вы переносите проверку в runtime — и её, конечно же, компилятор не может выполнить во время сборки, не используя полного встраивания кода функции в место её вызова.
К предыдущему комментарию:
Кстати, иметь корку куда полезнее, чем иметь просто стектрейс.Если вам хочется всего лишь падать в корку — можете использовать
-C panic=abort при сборке, заодно на размере бинаря сэкономите. Или используйте std::panic::catch_unwind чтоб получить нечто похожее на catch из C++. Или вообще определите свой хук для паник с помощью std::panic::set_hook чтоб получить лучшее из миров стектрейсов и корок:fn p(i: usize) {
let arr = [0; 25];
println!("{}", arr[i]);
}
fn main() {
std::panic::set_hook(Box::new(|panic_info| {
println!("Panic occurred: {:#?}", panic_info);
println!("{:?}", backtrace::Backtrace::new());
}));
let result = std::panic::catch_unwind(|| {
p(25);
});
if let Err(_) = result {
println!("Oh no, something went wrong!");
std::process::abort();
}
}
В обоих ваших примерах вы переносите проверку в runtime — и её, конечно же, компилятор не может выполнить во время сборки, не используя полного встраивания кода функции в место её вызова.
Да неужели. А вот выше в ответ на утверждение
С точки зрения юзера при обращении по неправильному индексу в массив С++ код упадёт(сегфолт или проверка от опции компилятора)
Раст код упадёт(будет исключение) или сегфолт(если был _unchecked доступ)
человек ответил
Он не скомпилируется.
Неужели соврал? Да не, не может быть. Скорее пошло какое-то типичное для раст-адептов преувеличение блейзингли фастанутости и секурности, доходящее до подобного абсурда. Просто на подсознательном уровне. Не в первый раз уже замечаю, кстати. Ну да ладно.
Не ну если чисто формально подходить тогда конечно всё можно проверять:
use typenum::{N1000, IsGreater};
use generic_array::{ArrayLength, GenericArray, arr};
fn p<F: ArrayLength<i32> + IsGreater<N1000>>(a: &GenericArray<i32, F>)
{
println!("{}", a[1000]);
}
fn main()
{
let a = arr![i32; 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, ];
p(&a);
}Другое дело что так конечно никто не пишет.
Чуть более адекватный вариант мог бы выглядеть так:
const fn p<const N: usize>(a : &[i32; N]) -> i32
{
a[1000]
}
fn main()
{
const a: [i32; 25] = [0; 25];
const _: i32 = p(&a);
}Но на одних константах далеко не уедешь, а без полноценных завтипов проверять рантайм значения не выйдет.
Впрочем, очевидно изначально человек чутка приукрасил действительнность и выдал проверки уровня "1 экспрешн" за какую-то более умную систему. На практике такие случаи умел детектировать даже паскаль.
Скомпилируется, скомпилируется:
Scope немного другой — и все, приплыли.
С точки зрения типов, вы обращаетесь не к массиву, а к срезу, размер которого в компайл-тайме не известен. Если бы был именно массив, то раст бы, очевидно, компиляцию завернул.
Да, конкретно этот случай можно было бы отловить и подсветить строчку p(&arr); как проблемную, но это уже выглядит как задача для статического анализатора (clippy), а не для rustc.
В C++ есть нормальная обработка исключений. В расте же паника — это unrecoverable error. Сомнительное удовольствие как раз паниковать вместо выбрасывания исключения, которое можно обработать.
В расте ошибки принято делить на фатальные и обрабатываемые.
Фатальные — это когда всё плохо и непонятно что дальше делать и как жить, а потому самый разумный выбор — сразу же запаниковать и упасть (при этом записать в лог или ещё кого уведомить — не возбраняется).
Обрабатываемые же ошибки указываются прямо в сигнатуре функции как возможное возвращаемое значение из этой функции. Используя комбинацию структур Option\Result, оператор ? и автоматически вызываемый последним типаж Into<T>, в расте становится очень удобно обрабатывать любые ошибки без всяких паник. Да и сразу обрабатывать ошибки комбинаторами map*\default* тоже очень удобно:
int value = 42;
try {
value = std::stoi("asdf", nullptr, 10);
} catch (exception e) {
log(e);
}
let mut value = 42;
match i32::from_str("asd") {
Ok(v) => {
value = v;
},
Err(e) => {
// будет записано что конкретно пошло не так,
// то есть один из вариантов: https://doc.rust-lang.org/src/core/num/error.rs.html#88-115
log(e);
}
}
// для таких простых вещей разумеется никто так многословно не пишет, будет вот так:
// let value = i32::from_str("asd").unwrap_or(42);Замечу, что это общепринятый подход к error handling в расте, именно так пишут везде. Удобно, что сама сигнатура вызываемого метода нам говорит про все возможные ошибки, которые она нам может вернуть. Не приходится прилагать никаких усилий для поддержания документации (та, которая чаще всего в виде комментариев над функций) в актуальном состоянии, ведь теперь сам код нам обо всём говорит.
В плюсах же и то, и другое, может делаться через исключения. И хотя в C++ обработку ошибок можно было бы делать также как в расте, но каждый делает API так, как он привык, то есть по-разному. Это может быть простое числовое значение возвращаемое из функции, или возвращение указателя (валидный\нулевой), или установка значения по ссылке переданной как аргумент при вызове функции. В общем, бардак.
Замечу, что это общепринятый подход к error handling в расте, именно так пишут везде.
Замечу, что это ложь. Прям везде все одинаковые, прям все растеры это один и тот же организм.
Хотя, если судить по комментариям в интернетах, они ведут себя действительно одинаково
Это на 99% правда. Найдите на crates.io хоть сколько-нибудь используемую библиотеку, в которой НЕ объявлен свой LibError и алиас вида type LibResult<T> = <Result<T, LibError>>. Это просто повсеместная практика обработки ошибок и выдачи значений.
Все знают что такое Result, все знают что try_* методы должны выдавать Result, все привыкли к такого рода API и сообщество старается поддерживать единообразие.
Более того, отсутствие unsafe/panic-free считается хорошим знаком и библиотеки выносят это наверх описания как плюс.
"Ложь"? Ну как сказать, я бы использование подавляющим процентом сообщества ряда подходов всё таки назвал общепринятым, если ограничивать общепринятость 100%, а не хотя бы на 99%, то ничто в мире не является общепринятым.
В реальном коде на расте (а не в сферическом safe-only коде в вакууме) ошибки при работе с памятью вполне себе встречаются (это из относительно свеженького), и последствия вполне себе фатальны — всякие там use-after-free, out-of-bounds reads/writes, полный букет. Да по-другому и не могло быть. И количество подобных проблем будет только расти с увеличением массы кода на расте (невольный каламбур получился, хехе). И хертблиды разные никуда не денутся, будут у раста свои собственные (а скорее всего уже есть, просто о них пока никто не знает — ну может кроме АНБ :)).
Глянул ссылку — везде в глаза бросается ансейф и его некорректное использование. Что ж, это конечно печально, но хорошо когда есть кейфорд по которому можно грепнуть и посмотреть все места где может быть ошибка. Сильно экономит время.
Если бы можно было обойтись без unsafe, его бы не добавляли в раст. Но увы и ах в реальности совсем обойтись без него нельзя, и результат как известно на лице. Впрочем в расте до сих пор есть проблемы с лайфтаймами, приводящие к use-after-free без всяких unsafe.
Можно пример такой проблемы? По первой ссылке что вы привели если что не оно — там лайфтайм так же ансейфом крафтится, и соответственно его корректность полностью на совести разработчика, так же как если ансейф код вместо nonzerou32 вернул 0 то не виноват язык который будет считать вне скоупа что значение 0 никогда не принимает и использует это для оптимизаций.
Кстати напомните, почему в расте до сих пор нет адекватного аналога плюсовому placement new? Не потому ли, в том числе, что нет механизма дать вызывающему коду понять, был ли все-таки сконструирован объект или нет? В C++ конструктор может выбросить исключение (со всеми RAII гарантиями), а в расте такого механизма нет.
Так вроде есть. Почему не стабилизируют можно почитать там же в комментах.
Ну как бы сложновастенько написать такую штуку как аллокатор на safe подмножестве, об этом и речь. А если бы можно было просто "грепнуть и посмотреть", то все бы так и делали, и ошибок было бы ровно 0. Но, видимо, процесс как-то посложнее выглядит, ибо многие из таких ошибок обнаруживаются лишь спустя месяцы и годы :)
Ну как бы сложновастенько написать такую штуку как аллокатор на safe подмножестве, об этом и речь.
Есть трейдофы. Сейф подмножество ради сейфти вносит ограничения, которые могут влиять. Упирается ли написание аллокатора на них — наверняка, насколько сильно? Вопрос
А если бы можно было просто "грепнуть и посмотреть", то все бы так и делали, и ошибок было бы ровно 0.
Не было бы. От того, что ошибку легко грепнуть и исправить не значит, что они исчезли. Просто условно вместо 200 открытых ишшуев с мемори сейфти проблемами в проекте будет 20. И пока эти 20 будут чинить найдут ещё 30 (а в параллельной вселенной без этого открыли бы 300).
Так вроде есть. Почему не стабилизируют можно почитать там же в комментах.
Во-первых нет. Это всего лишь обсуждение какого-то возможного синтаксиса для Box
placement new это ГОРАЗДО шире чем просто "синтаксис для std::unique_ptr"
Это буквально костыль для одного конкретного случая, как часто в расте бывает городят синтаксический сахарок вместо генерализации и реального решения проблем. Допустим сделают синтаксис для бокс, как при выделении памяти из другого источника использовать это? Как при конструировании при вставке в контейнер? Да никак.
Только заметил, что вы кое-что дописали.
Можно пример такой проблемы?
Да, пожалуйста. Последний Nightly до сих пор не способен найти здесь ошибку и предотвратить обращение к уже уничтоженной переменной.
Не, нету. Это ad-hoc костыль для Box, "жалкое подобие левой руки" (C), а не общее решение проблемы.
Да, пожалуйста. Последний Nightly до сих пор не способен найти здесь ошибку и предотвратить обращение к уже уничтоженной переменной.
А, это да, известная багуля. Неприятная.
Не, нету. Это ad-hoc костыль для Box, "жалкое подобие левой руки" ©, а не общее решение проблемы.
В принципе согласен, однако если есть пример где бокса в куче недостаточно то можно продемонстрировтать на практике? Я практически не припомню случаев где нужно было делать аллокаций обьекта не в боксе, как-либо ещё.
В расте же паника — это unrecoverable error.
Если в контексте приложения (а не библиотеки), то это не совсем так.
А, извините, вы отнесли текст в новом абзаце к тексту в предыдущем. Обычно для этого мысль упаковывают в один абзац. Я решил, что если вы уж сделали новый, значит мысль про массивы закончились и вы говорите про разыменовывания указателей.
Зато разработчики сделали игру не за 25 лет, а за 3 года, потому что не нужно было доказывать компилятору, что тут то, тут сё.
За более чем полугода работы над одним Rust проектом почти каждый день ни разу ничего не доказывал компилятору раста, это вообще глупая затея спорить с детерминированным алгоритмом. Ваше заявление, что 88% работы ((25-3)/25) — это борьба с компилятором, явно неправда. Кажется, вы даже не пытались на расте ничего писать и транслируете страшилки.
И всего лишь меч не работает, а не падение с "паникой" растовой
Так, стоп. Почему если на расте, то паника, а если на плюсах, то "меч не работает", а не сегфоулт? Выше же вы же приравняли паники к сегфолтам? Значит и на расте просто меч не будет работать (но больше вероятность, что все-таки будет).
Зато разработчики сделали игру не за 25 лет, а за 3 года, потому что не нужно было доказывать компилятору, что тут то, тут сё.
Это на самом деле смешно, потому что Юнити, позволяющий клепать игры с бешеной скоростью, вообще использует C#.
понятия не имею причем тут С#, на С++ разрабатывается +- также быстро.
Разница в скорости обучения языку, стоимости и количестве разработчиков. А раст сильно сложнее С++, так что делайте выводы
Вы понимаете, что если в попытках "отстоять честь С++" (которую никто не трогает, в треде просто обсуждаются технологии и их трейдофы) вы начинаете говорить очевидные ложные утверждения, то это как раз ложится пятном на репутацию того, о чем вы говорите?
Найдите мне хотя бы 1 разработчика на скажем анриле или скажем Godot скажите ему в лицо, что на юнити разрабатывать по времени столько же. Мне интересно, что он вам ответит, и ответит ли вообще.
Справедливости ради, в Godot абсолютное большинство разработчиков используют Python-подобный GodotScript, примерно 20% — C#(который там ещё заметно свежее, чем в Unity, там уже в 4.0 сидит рантайм dotnet 6, когда в Unity на него планируют перебираться в течении этого-следующего года ), и только сравнительно небольшой остаток — что-то другое через GDNative, навроде C++ и Rust
Да, я писал как-то в коментах что на C/C++ практически невозможно написать код у которого нету удаленного выполнения кода, так моя карма до сих пор хварает. Взять хотя-бы использования после освобождения памяти, чтобы не допустить, нужно всегда проверять документацию по каждой вызываемой функции и по всем функциям которые она вызывает, до последнего уровня вложенности, вдруг где-то освобождается передаваемый ей указатель. И главное, просто невнимательность, которую сложно заметить, ведь освобождение происходить на 10 уровне вложенности, приводит к выполнению кода. Лично мне сложно представить этих богов программирования, которые будут все это держать в голове и главное, что мне не понятно зачем, появились другие инструменты, более безопасные и с малым оверхедом по производительности.
на C/C++ практически невозможно написать код у которого нету удаленного выполнения кода
У вас явно своё понимание "удалённого выполнения кода"
по каждой вызываемой функции и по всем функциям которые она вызывает, до последнего уровня вложенности, вдруг где-то освобождается передаваемый ей указатель
не знаю, возможно вы делаете в асм jmp из одной функции в другую, но вообще то, если передать валидный указатель в функцию, то вплоть до конца функции он остаётся валиден. Вы можете это испортить либо сделав многопоточную программу - что конечно нужно умудриться написать, либо сохранив указатель куда-то для использования в каком-то будущем. Но начнём с того, что "освободить указатель" не актуально в С++ лет так 10, явный delete/ free / new / malloc в коде это гарантия, что вы пишете что-то не то, сразу на ревью идёт на переделку
Забавно, учитывая что в том же Эппл основной вектор взломов был через Джава. Так что тут, скорее, не языки виноваты, а культура написания кода. В принципе о чем он и сказал.
Я не ошибся в своих ожиданиях. Как обычно, больше всего интересной информации о Rust можно почерпнуть из комментариев к статье о C++. :)
АНБ: есть небезопасные языки
Бьерн: (тушит огонь на стуле) нет небезопасных языков, есть криворукие программисты
Вся суть.
АНБ в данном случае право.
Безопасных языков не существует.
Давайте формально: гарантии безопасности (и.е. статистического анализа по обнаружению) некоторых классов ошибок в различных языках отличаются. Есть языки, более приспособленные к анализу ошибок (хаскель, раст, идрис), менее приспособленные (джава, шарп), производящие только базовые проверки (С++, си) и не проверяющие практически ничего (жс, питон и иже с ними).
Учитывая ограниченность человеческого внимания (магическое число 7+-2) и рост производительности железа логично было бы переложить часть ментальных затрат на анализ кода с бедных разработчиков на компьютер. Что означает постепенный переход "вверх" от менее безопасных языков — к более.
А Бьёрн Страуструп занимается вообще продуктовым программированием? Чтобы была толпа коллег разного уровня подготовки, чтобы требования периодически менялись, чтобы техдолг и легаси копилось, вот со всем этим. А то не сложно давать советы в духе "зачем вы пишете софт с багами, пишите нормально", сложнее их на практике применять.
Бьёрн Страуструп ответил АНБ США по поводу рекомендации ведомства отказаться от использования языков C и C++