Comments 75
Скопипастил из их блога в Google Translate:
В ноябре прошлого года люди из Бразилии в Турцию в Японию обнаружили, что Google Translate для их языка стал более точным и понятным. Это потому, что мы ввели нейронный машинный перевод — используя глубокие нейронные сети для перевода целых предложений, а не просто фраз — на восемь языков в целом. В течение следующих нескольких недель эти улучшения появятся в Google Translate на многих других языках, начиная с хинди, русского и вьетнамского языков.
Нейронный перевод намного лучше, чем наша предыдущая технология, потому что мы переводим целые предложения за раз, а не части предложения. (Разумеется, есть масса машин, изучающих магию, которые подпитывают это под капотом, о котором вы можете прочитать в блоге Исследования.) Это делает переводы, которые обычно более точны и звучат ближе к тому, как люди говорят на этом языке.
Вы получите эти новые переводы автоматически в большинстве мест. Переводчик Google доступен: в приложениях для iOS и Android, на сайте translate.google.com, а также через Google Поиск и приложение Google. В ближайшие несколько недель мы переводим нейро-машинный перевод на еще большее количество языков, поэтому следите за более плавным и более быстрым переводом.
Наконец, продолжайте вносить вклад в трансляцию сообщества! Наши переводы по-прежнему далеки от совершенства, и это помогает всем, кто использует Google Translate, предлагать улучшения.
Ну будет с чем сравнить изменения через пару недель))
так нейронная сеть для русского УЖЕ работает.
Google Translate в своём переводе утаил этот факт, вот и ввёл человека в заблуждение.
Да ладно, неужели это машинный перевод? Больно уж ладно предложения скроены. Хотя смысл конечно иногда теряется…
Да, странно как он целую фразу «starting right now» куда-то проглотил при переводе.
Что довольно забавно старый вариант переводчика несмотря на намного более низкое качество перевода в целом этот момент не упустил:
«начиная прямо сейчас с хинди, Россия и Вьетнама. „
Но зато абсолютно не понял, что речь идет о языках, а не странах, а нейросеть это сразу уловила.
«начиная прямо сейчас с хинди, Россия и Вьетнама. „
Но зато абсолютно не понял, что речь идет о языках, а не странах, а нейросеть это сразу уловила.
Но ей ведь еще нужно пару недель на обучение.
По-моему, результат отличный. Может быть, я давно не пользовался гугл-транслейтом, но вот этот текст выглядит очень впечатляюще для машинного перевода, как по мне.
Завтра ждите ТАКОЕ на всех хабрах страны!
Вот для сравнения, что напереводило Андроид-приложение в оффлайне:
в ноябре прошлого года, люди из Бразилии в Турцию в Японию обнаружил, что Google перевести их язык был вдруг более точной и легче понять. это, потому что мы введена нейронных машинный перевод-помощью глубоко нейросетей перевести все предложения, скорее, чем просто фразы-за восемь языках в целом. в течение следующих нескольких недель, эти улучшения приходят к Google перевести во многих больше языках, начиная прямо сейчас с хинди, Россия и Вьетнама.
нейронных перевод много лучше, чем наши предыдущая технологии, потому что мы перевести все предложения на время, вместо того, куски приговор. (конечно, есть много машина обучения магия питания этом под капот, которые вы можете прочитать о на исследования блог.) это делает для переводы, что, как правило, более точной и звук ближе к образом люди говорят язык. вот один пример, чтобы показать, насколько это улучшение:
вы получите эти новые переводы автоматически в большинстве мест Google перевести доступно: в иос и человекоподобный робот приложения, по крайней translate.google.com, и с помощью Google поиск и Google приложение. мы будем введения нейронных машинный перевод в еще более языках в течение следующих нескольких недель, так что Следите за гладкой, более свободно переводы.
в конце концов, пожалуйста, имейте способствуя перевести сообщество! наши переводы все еще далеко не совершенным, и это помогает каждый с использованием Google переводчик, когда вы предложить улучшений.
Никогда бы не подумал что не было языковой пары «Английский-Японский». Я, когда нужно прочитать что-то на японском, специально перевожу на английский, так как с японского на русской вообще фигня получается.
Наверное имелась ввиду пара прямого перевода. Очень многие пары используют «средний» язык, т.е. например есть пара «Японский-Китайский» и «Китайский-Английский», таким образом если вы захотите перевести с японского на английский, то японский сначала переведется в китайский, а уже китайский на английский.
Если текст дважды пропустить через машинный переводчик журналиста-копирайтера, то и не такие приколы могут образоваться.
В оригинале эта картинка использовалась для иллюстрации того, как появился прямой перевод в паре Японский <==> Корейский из изначально всегда присутствовавших пар «Японский <==> Английский» и «Корейский <==> Английский».
До подключения нейронных сетей в прошлом году с Корейского на Японский (и обратно) перевод шел транзитом через английский из-за чего качество очень сильно страдало. Как и в любых других двойных машинных переводах.
Из-за этого же переводы на русский с большинства языков кроме английского ужасны по качеству — т.к. идет двойной перевод через английский.
И вот в этом плане для русского прямые пары на базе нейросетей похоже еще подключить не успели…
Сейчас поиздевался над переводчиком — с английским действительно заметно лучше. А вот с немецкого или китайского на русский попробовал — по прежнему качество перевода хромает на обе ноги. Настолько хромает, что перевод с языка Х на английский читать и понятнее и приятней одновременно, чем перевод с языка Х сразу на русский.
В оригинале эта картинка использовалась для иллюстрации того, как появился прямой перевод в паре Японский <==> Корейский из изначально всегда присутствовавших пар «Японский <==> Английский» и «Корейский <==> Английский».
До подключения нейронных сетей в прошлом году с Корейского на Японский (и обратно) перевод шел транзитом через английский из-за чего качество очень сильно страдало. Как и в любых других двойных машинных переводах.
Из-за этого же переводы на русский с большинства языков кроме английского ужасны по качеству — т.к. идет двойной перевод через английский.
И вот в этом плане для русского прямые пары на базе нейросетей похоже еще подключить не успели…
Сейчас поиздевался над переводчиком — с английским действительно заметно лучше. А вот с немецкого или китайского на русский попробовал — по прежнему качество перевода хромает на обе ноги. Настолько хромает, что перевод с языка Х на английский читать и понятнее и приятней одновременно, чем перевод с языка Х сразу на русский.
Непонятно почему нельзя переводить на универсальный семантический язык (скажем строить какие-то графы, соответствующие предполагаемому смыслу предложения) и затем переводить с него на любой другой язык? Все равно же такие графы строятся при переводе, почему ими напрямую нельзя воспользоваться а нужно что-то делать «через английский»?
UFO just landed and posted this here
Потому что этот язык сначала нужно придумать (разработать). И он должен быть на самом деле универсальным — хорошо подходить в пару к любому другому произвольному языку, а языки очень разные, т.ч. и семантика кардинально может различаться. Общую структуру скажем английского, немецкого и испанского разработать не очень сложно. А общую и универсальную для английского, китайского, японского и какого-нибудь суахили — сложно.
И все-равно это будет промежуточный язык/лишний этап по сравнению с прямой парой, хотя конечно намного лучше чем двойной перевод через английский, который совсем плохо подходит в качестве такого промежуточного посредника.
Но если прочитаете предыдущую статью (когда впервые запускали перевод при помощи нейросетей), то внутри нейросети что-то наподобие такого универсального языка(понятного правда только самой сети) в результате и сформировалось. Его специально никто не разрабатывал, но он сформировался сам как связи в нейросети в процессе ее обучения/тренировки.
И все-равно это будет промежуточный язык/лишний этап по сравнению с прямой парой, хотя конечно намного лучше чем двойной перевод через английский, который совсем плохо подходит в качестве такого промежуточного посредника.
Но если прочитаете предыдущую статью (когда впервые запускали перевод при помощи нейросетей), то внутри нейросети что-то наподобие такого универсального языка(понятного правда только самой сети) в результате и сформировалось. Его специально никто не разрабатывал, но он сформировался сам как связи в нейросети в процессе ее обучения/тренировки.
И как обучать нейросеть на нём? Если этот виртуальный язык больше нигде не используется.
Уж лучше тогда было бы в самом английском попытаться сделать пометки. Но опять же, по текущей схеме их негде взять.
Уж лучше тогда было бы в самом английском попытаться сделать пометки. Но опять же, по текущей схеме их негде взять.
Жаль, что не много людей в паре русский-английский помогает там с переводом. Я всего сотню-полторы коммитов сделал в прошлом году и попал в топ 5% (гугл письма рассылал).
А там — это где именно? Можно линк, где коммиты делают?
Тоже в топ 5% попал.
Но последнее время там какой-то шлак пошел. Вместо улучшения качества перевода, шел какой-то сплошной поток чего-то похожего на надписи из гугл-мэпс или каких-то справочников типа желтых страниц (названия магазинов, ресторанов, организаций, местности/географических пунктов и т.д.).
Забросил это дело, халявных работников занимающихся вычиткой их карт пусть в других местах ищут.
Но последнее время там какой-то шлак пошел. Вместо улучшения качества перевода, шел какой-то сплошной поток чего-то похожего на надписи из гугл-мэпс или каких-то справочников типа желтых страниц (названия магазинов, ресторанов, организаций, местности/географических пунктов и т.д.).
Забросил это дело, халявных работников занимающихся вычиткой их карт пусть в других местах ищут.
Ну, мне попадалось вырванное из контекста название яойной манги ¯\_(ツ)_/¯ Всякое бывает.
Ну это-то как раз легко кто-то из пользователей translate.google.ru мог пихнуть на перевод. Да и разовое не показатель. А когда десятками подряд идут название с карт или из правочника организаций — это админы гугла соответствующую базу подключили.
Сейчас заглянул, уже нет, идут нормальные тексты. Видимо всю эту базу волонтеры уже обработали. А так несколько недель это продолжалось.
Сейчас заглянул, уже нет, идут нормальные тексты. Видимо всю эту базу волонтеры уже обработали. А так несколько недель это продолжалось.
Всё, переводчики-люди не нужны, если только совсем уж узкоспециализированные. Статьи с phys.org например переводит вполне адекватно, совсем откровенного бреда практически нет.
Вообще скачок качественный, никаких и близко похожих переводчиков ещё не было, всем сомневающимся в скором исчезновении всех профессий, рекомендую попробовать.
ru -> en
en -> ru
Вообще скачок качественный, никаких и близко похожих переводчиков ещё не было, всем сомневающимся в скором исчезновении всех профессий, рекомендую попробовать.
ru -> en
All translators-people are not needed, if only very narrowly specialized. Articles with phys.org for example translates quite adequately, quite frank delirium practically is not present.
In general, the leap is qualitative, there were not any similar translators yet, everyone who doubted the imminent disappearance of all professions, I recommend to try.
en -> ru
Все переводчики — люди не нужны, если только узкоспециализированные. Статьи с phys.org например переводит вполне адекватно, довольно откровенного бреда практически нет.
В общем, скачок качественный, подобных переводчиков еще не было, все, кто сомневался в неизбежном исчезновении всех профессий, рекомендую попробовать.
Вот бы ещё оно читать нормально научилось. А с переводом очень прикольно стало, да.
Всё, переводчики-люди не нужны
А ещё контентщики для наполнения говносайтов. Взял чужой текст, перевёл туда — обратно. Получилось тоже самое, но другими словами.
все, кто сомневался в неизбежном исчезновении всех профессий, рекомендую попробовать
Сильный ИИ спалился?
/хмыкая/
Взял кусок общехудожественного текста, перевел… В общем, как раз узкоспециализированных оно может быть и заменит, но всё равно — обнять и плакать, до сносного состояния дорабатывать большим напильником.
Взял кусок общехудожественного текста, перевел… В общем, как раз узкоспециализированных оно может быть и заменит, но всё равно — обнять и плакать, до сносного состояния дорабатывать большим напильником.
да нет, быть такого не может -> Yes no, this can not be. Переводчики-люди, пока не расходитесь.
По факту — всё тот дословный перевод, просто более согласованный.
Кстати, запятые вокруг "например" гугль так и не вставил.
По факту — этот хотя бы пытается, не всегда успешно, но пытается. Из всех доступных сервисов, включая яндекс-переводчик (а там тоже не дураки сидят и нейросети в хвост и гриву юзают), у гугла сейчас объективно лучшее качество, можно легко самому убедиться. До людей конечно не дотягивает, смысл текста в целом не понимает.
Всё, переводчики-люди не нужны, если только совсем уж узкоспециализированные.А кто тогда будет проверять и корректировать гугловский перевод? Даже люди временами воротят что-то дикое, за ними перепроверять приходится более опытному переводчику.
jp -> ru
時論公論「東日本大震災6年 次の大災害にどう備えるのか」松本浩司解説委員
東日本大震災からまもなく6年。巨額の予算を投じた復興は道半ばだが、その経験を踏まえ、南海トラフ地震など次の大災害にどう備えるべきか、財源をどうするかを考える。
Современное мнение общественное мнение ", предусматривает ли если Великий Восток Японии землетрясения шесть лет после крупной катастрофы," Коджи Мацумото комментатор
Вскоре после того, как 6 лет со дня Великой Восточной Японии землетрясения. Это середина реконструкции дороги, которая инвестировала огромный бюджет, но, основываясь на опыте, что делать, чтобы подготовиться к следующей крупной катастрофы, такие как землетрясения Нанкай корыто, рассмотреть, что делать с финансовыми ресурсами.
— Ужасно, как и раньше. Ничего не поменялось.
時論公論「東日本大震災6年 次の大災害にどう備えるのか」松本浩司解説委員
東日本大震災からまもなく6年。巨額の予算を投じた復興は道半ばだが、その経験を踏まえ、南海トラフ地震など次の大災害にどう備えるべきか、財源をどうするかを考える。
Современное мнение общественное мнение ", предусматривает ли если Великий Восток Японии землетрясения шесть лет после крупной катастрофы," Коджи Мацумото комментатор
Вскоре после того, как 6 лет со дня Великой Восточной Японии землетрясения. Это середина реконструкции дороги, которая инвестировала огромный бюджет, но, основываясь на опыте, что делать, чтобы подготовиться к следующей крупной катастрофы, такие как землетрясения Нанкай корыто, рассмотреть, что делать с финансовыми ресурсами.
— Ужасно, как и раньше. Ничего не поменялось.
А если так?
Поделюсь секретом лайфхака, только никому не рассказывайте: переводим по схеме jp -> en -> ru
Я думаю это мелкое недоразумение с jp ->ru напрямую, пофиксят в ближайшие дни.
Обсуждение публичных дебатов «Как вы подготовитесь к следующей большой катастрофе в 6-ом землетрясении в Восточной Японии?» Комментатор Коджи Мацумото
Это произойдет через шесть лет после Большого Восточного землетрясения в Японии. Перестройка огромного бюджета идет на полпути, но я рассмотрю, как подготовиться к следующей крупной катастрофе, такой как землетрясение в Нанкай-Тору, и как финансировать ее на основе опыта.
Поделюсь секретом лайфхака, только никому не рассказывайте: переводим по схеме jp -> en -> ru
Я думаю это мелкое недоразумение с jp ->ru напрямую, пофиксят в ближайшие дни.
Такое со всеми языками (я немецкий и китайский пробовал).
Похоже нейросети подключили только к паре русский <==> английский. По крайней мере с другими языками я качественных изменений в лучшую сторону не обнаружил. А вот с английским — да. Правда он мне и не нужен — это наоборот я гугл иногда учу лучше это направление переводить.
Похоже нейросети подключили только к паре русский <==> английский. По крайней мере с другими языками я качественных изменений в лучшую сторону не обнаружил. А вот с английским — да. Правда он мне и не нужен — это наоборот я гугл иногда учу лучше это направление переводить.
Да, показательно. Двойной перевод туда-обратно это обычно был лютый фейл для всех машинных переводчиков.
Ну сейчас
«Как стрелять из лука»
Переводится как
«How to shoot an onion»
«Как стрелять из лука»
Переводится как
«How to shoot an onion»
У нейросети нет нехватки в данных для обработки и обучения. По статистике поискового гиганта, через Google Translate ежедневно переводится до 140 млрд слов на 103 языках.
Вот этот момент я не очень понял. Переводов много, но как это поможет натренировать сеть? Речь о кнопке «Предложить свой перевод»?
GIF-ка из блога Google:

Scientists Claim to Have Found Our Planet’s Oldest Fossils
Встроенный в Chrome переводчик пока переводит по-старому.

В отличии от сайта Google Translate.

Scientists Claim to Have Found Our Planet’s Oldest Fossils
Встроенный в Chrome переводчик пока переводит по-старому.

В отличии от сайта Google Translate.

Туда-обратно:
Вполне нормально, основная масса ошибок произошла при перевода из русского в английский.
Онлайн-переводчик Google Translator теперь предоставляет нейронную сеть для перевода на русский, вьетнамский и хинди, согласно официальному блогу поискового гиганта.
Напомним, в сентябре 2016 года Google объявила о подключении к своему онлайн-переводчику Google Neural Machine Translation (GNMT). Сеть была разработана с помощью углубленного обучения и составления единой базы данных значений слов человеческих языков. По мнению специалистов компании, это должно улучшить качество перевода с одного языка на другой.
После запуска проекта шесть месяцев назад, инженеры Google увеличили пул языков нейронной сети. Сначала нейронная сеть начала обрабатывать немецкий, французский, испанский, португальский и другие европейские языки. Кроме того, изучали китайский, корейский и турецкий языки. В целом, нейронная сеть была охвачена 35% населения мира в первой волне.
Вполне нормально, основная масса ошибок произошла при перевода из русского в английский.
Пользуюсь Google Translate для перевода с японского, после подключения нейросети, действительно, стал намного лучше переводить, но теперь он стал выбрасывать куски предложений которые не может перевести, а раньше выдавал не пойми что в таких случаях.
Проверил — та же абракадабра:
Японский → Русский
お疲れ様です。 → Является ли веселит за хорошую работу.
以上、よろしくお願いします。 → Или больше, спасибо.
以上です。よろしくお願いします。 → Она закончилась. Большое спасибо заранее.
С учетом того, что это общепринятые дефолтные фразы, которые встречаются в каждом письме, нейросеть явно халтурит.
Японский → Русский
お疲れ様です。 → Является ли веселит за хорошую работу.
以上、よろしくお願いします。 → Или больше, спасибо.
以上です。よろしくお願いします。 → Она закончилась. Большое спасибо заранее.
С учетом того, что это общепринятые дефолтные фразы, которые встречаются в каждом письме, нейросеть явно халтурит.
А можно как надо, для тех, кто японский не знает?
Фраза「お疲れ様です。」 примерно переводится как «благодарю за проделанную работу», является общепринятым началом любого делового письма или как устное приветствие коллеги в конце рабочего дня. Пусть профессиональные переводчики поправят меня, если имеют более точный русский перевод. Остальные две фразы — варианты окончания письма, что-то вроде «На этом у меня всё. Надеюсь на дальнейшее сотрудничество». Насколько мне известно, гуглтранслейт прогонял (и, судя по всему, все еще прогоняет) перевод через английский язык, поэтому такой перевод звучит как бессмысленный бред. И, несмотря на новшества в работе переводчика, разницы я пока что не заметил.
Авто перевод сайтов тоже через нейросеть или пока как обычно?
И кто сейчас лучше промт или гугл?
Может лет через 20 можно будет просто загнать в переводчик книгу и получить адекватный перевод.
за несколько минут.
Или вообще смотреть в онлайне любое видео на любом языке и понимать его благодаря автопереводу и озвучиванию. Ведь Гугл проект синтезатора речи тоже вроде пилит.
И кто сейчас лучше промт или гугл?
Может лет через 20 можно будет просто загнать в переводчик книгу и получить адекватный перевод.
за несколько минут.
Или вообще смотреть в онлайне любое видео на любом языке и понимать его благодаря автопереводу и озвучиванию. Ведь Гугл проект синтезатора речи тоже вроде пилит.
UFO just landed and posted this here
Он всё равно не понимает стилистику и культурные различия, но для передачи смысла вполне подходит :)
Прогресс большой, но до «переводчики больше не нужны» еще далеко. Лично я субъективно качество машинного перевода с английского на русский оцениваю так:
1. Полный бред, ничего не понять, но иногда смешно.
2. Сильно напрягшись, можно уловить какую-то часть общего смысла
3. Можно понять, о чем речь, но все-таки проще читать англоязычный вариант, чем такой перевод.
4. Примерно одинаковые усилия нужны на чтение оригинала и перевода.
5. Перевод читается легче.
Как правило, хороший художественный перевод, сделанный профессиональным переводчиком-человеком, однозначно попадает в категорию 5. Любительский перевод технического текста (многие переводные статьи в блогах, например) — в категорию 4. А Google сейчас для меня перешел из категории 2 в 3, и пока это все.
1. Полный бред, ничего не понять, но иногда смешно.
2. Сильно напрягшись, можно уловить какую-то часть общего смысла
3. Можно понять, о чем речь, но все-таки проще читать англоязычный вариант, чем такой перевод.
4. Примерно одинаковые усилия нужны на чтение оригинала и перевода.
5. Перевод читается легче.
Как правило, хороший художественный перевод, сделанный профессиональным переводчиком-человеком, однозначно попадает в категорию 5. Любительский перевод технического текста (многие переводные статьи в блогах, например) — в категорию 4. А Google сейчас для меня перешел из категории 2 в 3, и пока это все.
В последние пару месяцев, заметил, что сервис гугла переводит с русского на английский и наоборот просто откровенный бред. И это был далеко не самый сложный текст, без сложных грамматических конструкций. Даже простые фразы и предложения коверкает так, что страшно после этого пользоваться таким сервисом. Вернулся к традиционному словарному переводу с lingvo. Еще заметил, что если раньше перевод по контексту был похож на исходный текст, то теперь это… просто ЭТО, даже жаль времени чтобы править такой кусок госсэ. Может есть нормальная вменяемая альтернатива?
Туда и обратно:
За последние пару месяцев я заметил, что служба Google переводит с русского на английский и наоборот, просто глупости. И это был далеко не самый сложный текст, без сложных грамматических конструкций. Даже простые фразы и предложения искажаются, так что после этого страшно пользоваться такой услугой. Я вернулся к традиционному словарному переводу с lingvo. Он также заметил, что если раньше контекстный перевод был похож на исходный текст, теперь это… это просто ЭТО, даже жалко редактировать такой кусок госсета. Может есть нормальный разумный вариант?
Поэтому лось на латыни — это Юлий Цезарь?
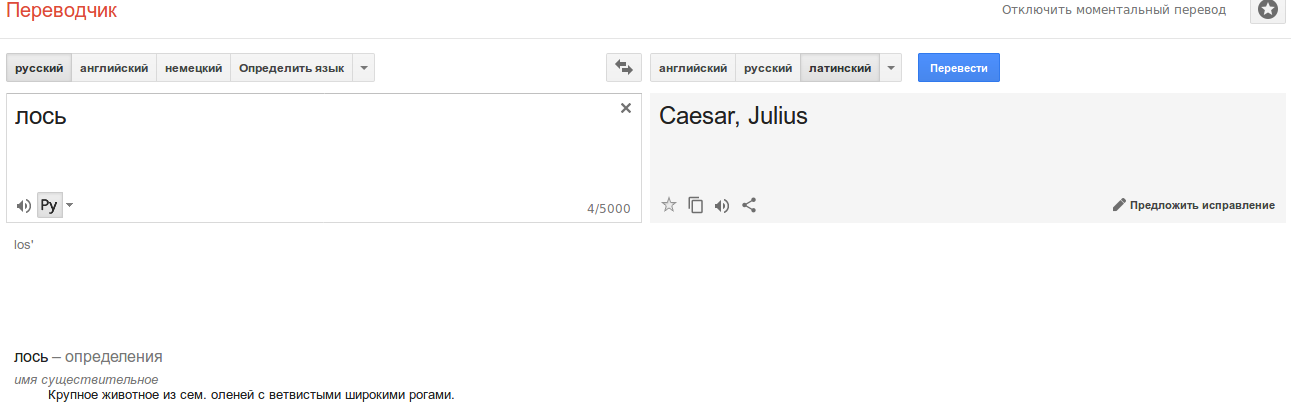
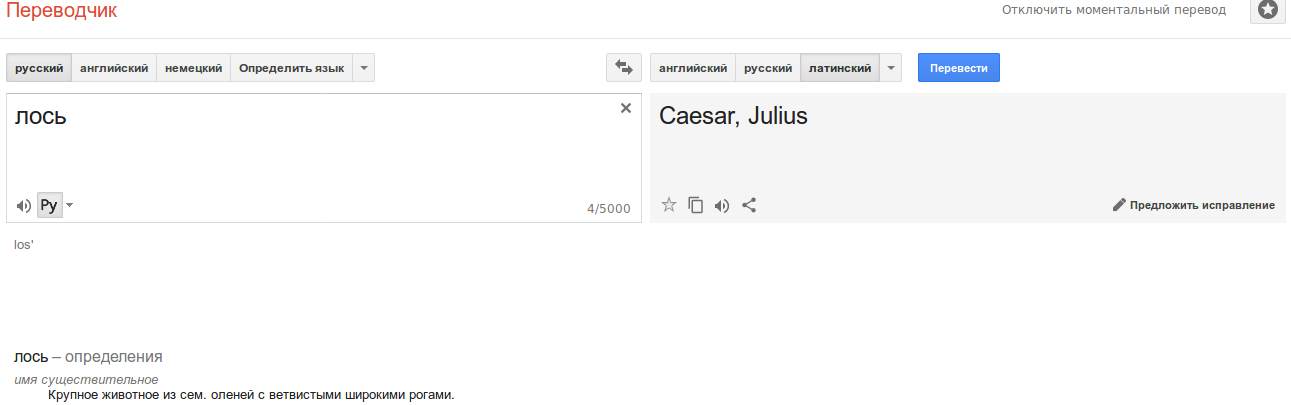
Уже поправили на «Elk»
У меня вроде бы все по-старому, даже в приватном режиме. https://translate.google.ru/#ru/la/%D0%BB%D0%BE%D1%81%D1%8C
Заметил, что «циклические» переводы часто отлично сохраняют текст на исходном языке, но выдают неверный перевод в промежуточном. Примеры ru -> en -> ru:
«Я чувствую себя хорошо» -> «I feel myself good» -> «Я чувствую себя хорошо»
«Он перевёл бабушку через дорогу» -> «He transferred his grandmother across the road» -> «Он перевел свою бабушку через дорогу»
«В нашей группе много Иванов» -> «In our group there are many Ivanovs» -> «В нашей группе много Иванов»
И т.д.
Так что хоть, качество перевода стало сильно выше, точно так же выросла незаметность ошибок.
«Я чувствую себя хорошо» -> «I feel myself good» -> «Я чувствую себя хорошо»
«Он перевёл бабушку через дорогу» -> «He transferred his grandmother across the road» -> «Он перевел свою бабушку через дорогу»
«В нашей группе много Иванов» -> «In our group there are many Ivanovs» -> «В нашей группе много Иванов»
И т.д.
Так что хоть, качество перевода стало сильно выше, точно так же выросла незаметность ошибок.
А во 2м примере что не понравилось? Что просто абстрактная бабушка превратилась в свою(родную) бабушку?
Так это не косяк переводчика, а разница в языках и культурах — в английском бабушка это только родственник, посторонних пожилых женщин бабушками не называют.
В 1м и 3м смысл передан правильно, претензия к грамматике как понимаю. Ошибочными я бы их не назвал — корявыми в плане стиля/правильности построения предложения — да.
Так это не косяк переводчика, а разница в языках и культурах — в английском бабушка это только родственник, посторонних пожилых женщин бабушками не называют.
В 1м и 3м смысл передан правильно, претензия к грамматике как понимаю. Ошибочными я бы их не назвал — корявыми в плане стиля/правильности построения предложения — да.
Sign up to leave a comment.
Google Translate подключил русский язык к переводу с глубинным обучением