Приветствую всех!
Этот блог будет очень занимательным! Сегодня я расскажу об очень интересных особенностях последней версии CUBRID 8.4.0, о том, чего обычно не найдешь в мануале. Приведу очень важные рекоммендации по оптимизации запросов и индексов, приведу результаты тестов, а также примеры использования в реальных Веб сервисах.
Ранее я уже поверхностно рассказывал об изменениях в новой версии, о вдвое ускоренном движке базы данных, о расширенной поддержке MySQL синтаксиса, и т.д. А сегодня расскажу о них и других вещах более подробно, акцентируя на том, как мы смогли увеличить производительность CUBRID в два раза.
Основные направления, повлиявшие на производительность CUBRID, являются:
В CUBRID 8.4.0 размер тома базы данных уменьшился аж на целых 218%. Причиной этому является полностью измененнная структура для хранения индексов, что параллельно повлияло на производительность всей системы.
В следующем рисунке можно увидеть сравнение размера томов базы данных в предыдущей версии 8.3.1 и новой 8.4.0. В этом случае обе базы данных хранили по 64,000,000 записей с первичным ключем. Данные указаны в гигабайтах.

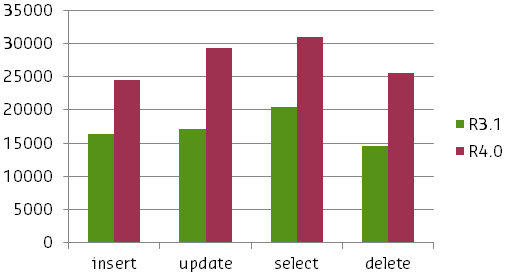
В CUBRID 8.4.0 улучшены параллельные вычисления в версии для Windows платформы с помощью усовершенствованных Мьютексов. В следующем графике указаны сравнительные результаты производительности предыдущей и новой версий.

Вот тут-то я расскажу Вам все очень подробно.
CUBRID 8.4.0 отличается от предыдущей версии вдвое ускоренным движком базы данных. Мы реализовали несколько очень важных оптимизаций индексов, как:
Теперь давайте посмотрим как организована структура индексов в CUBRID 8.4.0. В CUBRID индекс реализован в виде B+ дерева [ссылка на статью в Википедии], в котором значения ключей индекса хранятся в листьях дерева.
Для практического примера предлагаю посмотреть на следующую структуру таблицы (STRING = VARCHAR(1,073,741,823)):
Введем данные:
И создадим многоколоночный индекс. Кстати, заметьте, что индекс я создаю после того, как ввел данные. Это — рекоммендуемый способ, если Вы хотите вводить данные на начальном этапе или при их востановлении. Таким образом, вы можем избежать затраты времени и ресурсов на индексирования при каждом вводе. Более подробно о рекоммендациях при вводе больших данных вы можете прочитать здесь.
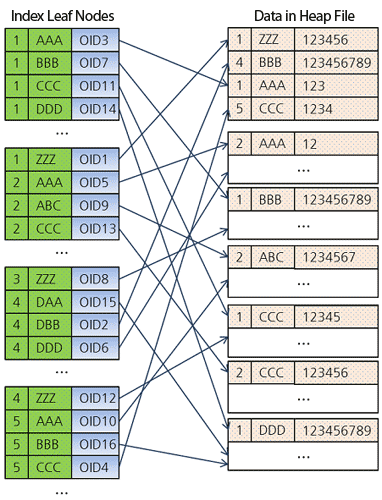
На рисунке ниже показана структура этого индекса, в листьях которого есть указатели (OID) на сами данные, находящиеся в куче-файле (heap file) на диске.
Теперь посмотрим, как обычно происходит поиск с использованием индексов. Учитывая выше созданную таблицу, мы запустим следующий запрос.

Теперь посмотрим, каким образом покрывающий индекс может значительно увеличить производительность CUBRID. В кратце, покрывающий индекс позволяет получить результаты запроса без необходимости обращения к куче на диске, что снижает количество операций ввода/вывода, что в свою очередь является самой дорогой операцией в плане затраченного времени.
Однако магия Покрывающего индекса можно применить только, когда все колонки, значения которых запрашиваются в запросе, находятся в одном составном индексе. Иначе говоря, их значения должны находиться в одном листе дерева индекса. Например, посмотрим на следующий запрос.
И так, если мы запустим этот запрос:

Давайте теперь посмотрим, насколько покрывающий индекс может улучшить производительность сервера. Для того же вышеуказаного примера мы предположим, что в базе хранится очень большое количество данных.
Q1. Ниже приведен запрос, который использует колонки, указанные в одном составном индексе.
Q2. А теперь запрос, где колонка a индексирована, а колонка c — нет.
Следующая график показывает, насколько быстро могут быть обработаны запросы, если они используют покрывающий индекс.

У CUBRID 8.4.0 — очень «умный» анализатор операторов LIMIT. Данный анализатор был очень оптимизирован, что позволяет обрабатывать только то количество записей, которое требуется в условии оператора LIMIT, при достижении которого сервер сразу возвращает результаты. К примеру, посмотрим на следующий запрос.

Оптимизация многодиапазонного сканирования является еще одним главным усовершенствованием в новом CUBRID 8.4.0. Когда пользователи заправшивают данные, которые лежат в определенном диапазоне, например, между a > 0 AND a < 5, задача является довольно легкой для большинства СУБД. Однако все становится намного сложнее, когда в условия включаются разбросанные диапазоны, например, a > 0 AND a < 5 AND a = 7 AND a > 10 AND a < 15. Здесь то CUBRID и отличается. Новая функция оптимизации in-place sorting (сортировка на лету) позволяет решить сразу две задачи:
К примеру, рассмотрим следующий запрос.
Благодаря этой возможности многодиапазонного сканирования с сортированием на лету, CUBRID может производить очень быстрый поиск среди большого количества данных.

В Корее есть очень популярный Веб сервис Me2Day, аналог Твиттера. Следующие результаты тестов были получены на основе реальных данных этого сервиса.
Как и в Твиттере, в Me2Day есть таблица posts, где хранятся все «твиты». Статистика пользователей и их отношений показывает, что:
Для этой таблицы создан следующий индекс.
Самый главный запрос, который чаще всего запрашивается и в сервисе Twitter, и в сервисе Me2Day — это "показать последние 20 случайных постов всех пользователей, за которыми я слежу". Ниже приведен этот самый запрос.
Тест был запущен на 10 минут, в период которых продолжительно обрабатывался этот запрос. Ниже приведет график результатов тестирования, в котором сравнивается оператор UNION в MySQL, который в среднем в 4 раза быстрее, чем IN оператор в MySQL, с оператором IN в CUBRID. За одно, сравнив с предыдущей версие, Вы можете посмотреть, насколько увеличилась производительность CUBRID 8.4.0 после реализации многодеапазонного сканирования.

После таких положительных результатов мы заменили MySQL сервера Me2Day, отвечающие за ежедневную работу сервиса, на сервера CUBRID. В следующий раз расскажу об этом тесте более подробно. А пока Вы можете также прочитать о нем на английском на главном сайте.
Новая версия CUBRID 8.4.0 значительно ускорила обработку запросов, содержащие ORDER BY и GROUP BY операторы. Когда в условиях ORDER BY и GROUP BY используются колонки, включенные в многоколоночный индекс, отпадает необходимость отсортировывать значения, так как они уже отсортированы в дереве индекса. Такая оптимизация позволяет значительно увеличить производительность обработки всего запроса. Можем посмотреть на работу следующего запроса.

Помимо улучшения производительности всей системы, новая версия CUBRID 8.4.0 поддерживает более 90% SQL синтаксиса СУБД MySQL. Мы также реализовали расширенную поддержку неявного преобразования типов, чтобы разработчики концентрировались на улучшение функциональности своих приложений, в то время как CUBRID будет делать все внутренние преобразования. Ниже приведу несколько примеров нового синтаксиса.
Всего в новой версии 23 новых DATE/TIME синтаксиса, 5 — связанных со строками, и 5 новых функций аггрегирования. Весь список нового синтаксиса можете найти в блоге на офф. сайте.
Также в версии CUBRID 8.4.0 значительно улучшили механизм блокировки, чтобы минимизировать появления застоев. Например, в среде Высокой Доступности застои не будут образовываться между транзакциями, которые вводят данные в одну и ту же таблицу в одно и то же время.
Как Вы, наверное, уже поняли, новая версия CUBRID 8.4.0 явно превосходит все предыдущие версии и в производительности, и в надёжности, и в удобстве разработки. CUBRID разрабатывается с целью использования в Веб приложениях и сервисах, посему все основные разработки, улучшения и оптимизации ведутся в сфере функций, часто используемых в Веб приложениях (например, как операторы IN, ограничения LIMIT, группировки и сортирование, а также Высокая Доступность), превосходство в производительности которых доказывается результатами сравнительных тестов.
Если у Вас есть определенные вопросы, пишите в комментариях. Буду очень рад все разъяснить!
Этот блог будет очень занимательным! Сегодня я расскажу об очень интересных особенностях последней версии CUBRID 8.4.0, о том, чего обычно не найдешь в мануале. Приведу очень важные рекоммендации по оптимизации запросов и индексов, приведу результаты тестов, а также примеры использования в реальных Веб сервисах.
Ранее я уже поверхностно рассказывал об изменениях в новой версии, о вдвое ускоренном движке базы данных, о расширенной поддержке MySQL синтаксиса, и т.д. А сегодня расскажу о них и других вещах более подробно, акцентируя на том, как мы смогли увеличить производительность CUBRID в два раза.
Основные направления, повлиявшие на производительность CUBRID, являются:
- Уменьшение размера тома базы данных
- Улучшенные параллельные вычисления в Windows версии
- Оптимизации индексов
- Оптимизации обработки условий в LIMIT
- Оптимизации обработки условий в GROUP BY
Уменьшение размера тома базы данных
В CUBRID 8.4.0 размер тома базы данных уменьшился аж на целых 218%. Причиной этому является полностью измененнная структура для хранения индексов, что параллельно повлияло на производительность всей системы.
В следующем рисунке можно увидеть сравнение размера томов базы данных в предыдущей версии 8.3.1 и новой 8.4.0. В этом случае обе базы данных хранили по 64,000,000 записей с первичным ключем. Данные указаны в гигабайтах.

Улучшенные параллельные вычисления в Windows версии
В CUBRID 8.4.0 улучшены параллельные вычисления в версии для Windows платформы с помощью усовершенствованных Мьютексов. В следующем графике указаны сравнительные результаты производительности предыдущей и новой версий.
Оптимизации индексов
Вот тут-то я расскажу Вам все очень подробно.
CUBRID 8.4.0 отличается от предыдущей версии вдвое ускоренным движком базы данных. Мы реализовали несколько очень важных оптимизаций индексов, как:
- Покрывающий индекс
- Оптимизация обработки условий в LIMIT
— Ограничение по ключям (Key Limit)
— Многодиапазонное сканирование (Multi Range)
- Оптимизация обработки условий в GROUP BY
- Сканирование индекса по убыванию
- Поддержка сканирования индекса в операторах LIKE
Теперь давайте посмотрим как организована структура индексов в CUBRID 8.4.0. В CUBRID индекс реализован в виде B+ дерева [ссылка на статью в Википедии], в котором значения ключей индекса хранятся в листьях дерева.
Для практического примера предлагаю посмотреть на следующую структуру таблицы (STRING = VARCHAR(1,073,741,823)):
CREATE TABLE tbl (a INT, b STRING, c BIGINT);Введем данные:
INSERT INTO tbl VALUES (1, ‘AAA, 123), (2, ‘AAA’, 12), …;И создадим многоколоночный индекс. Кстати, заметьте, что индекс я создаю после того, как ввел данные. Это — рекоммендуемый способ, если Вы хотите вводить данные на начальном этапе или при их востановлении. Таким образом, вы можем избежать затраты времени и ресурсов на индексирования при каждом вводе. Более подробно о рекоммендациях при вводе больших данных вы можете прочитать здесь.
CREATE INDEX idx ON tbl (a, b);На рисунке ниже показана структура этого индекса, в листьях которого есть указатели (OID) на сами данные, находящиеся в куче-файле (heap file) на диске.
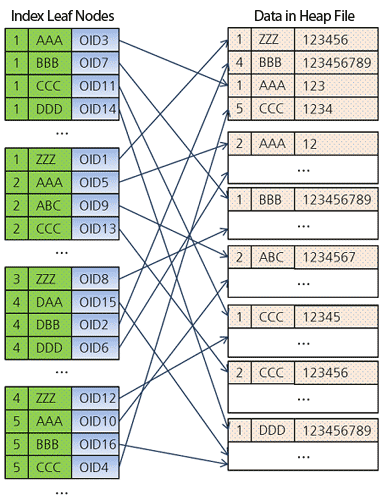
- Таким образом, значения ключей индекса (a и b) отсортированы по увеличению (по умолчанию).
- Каждый лист имеет указатель (указанный стрелкой) на соответсвующие данные (запись в таблице), находящиеся в куче на диске.
- Данные в куче расположены в случайном порядке, как указано на рисунке.
Сканирование индекса
Теперь посмотрим, как обычно происходит поиск с использованием индексов. Учитывая выше созданную таблицу, мы запустим следующий запрос.
SELECT * FROM tbl
WHERE a > 1 AND a < 5
AND b < ‘K’
AND c > 10000
ORDER BY b;- Сначала CUBRID найдет все листья, в которых a >1 и a < 5.
- Затем среди этого результата, он отберет листья, в которых b < 'K'.
- Так как колонка c не индексирована, для получения ее значений необходимо обратиться в кучу, который находится на диске.
- Каждый лист в дереве индекса содержит значение OID (Идентификатор Объекта), который указывает, где именно на диске хранятся данные определенной записи таблицы.
- Исходя из этих OID, сервер обратится в кучу для получения значений колонки c.
- Затем CUBRID найдет все те записи, в которых c > 10000.
- В результате все эти записи будут отсортированы по колонке b, как требуется в запросе.
- Затем полученные результаты отправляется к клиенту.
Покрывающий индекс
Теперь посмотрим, каким образом покрывающий индекс может значительно увеличить производительность CUBRID. В кратце, покрывающий индекс позволяет получить результаты запроса без необходимости обращения к куче на диске, что снижает количество операций ввода/вывода, что в свою очередь является самой дорогой операцией в плане затраченного времени.
Однако магия Покрывающего индекса можно применить только, когда все колонки, значения которых запрашиваются в запросе, находятся в одном составном индексе. Иначе говоря, их значения должны находиться в одном листе дерева индекса. Например, посмотрим на следующий запрос.
SELECT a, b FROM tbl
WHERE a > 1 AND a < 5
AND b < ‘K’
ORDER BY b;- Как Вы можете заметить, все колонки, используемые в данном запросе, находятся в одном многоколоночном индексе, который мы создали в самом начале.
- В условии оператора WHERE указаны только те колоки, которые находятся в одном многоколоночном индексе.
- Также в условии оператора ORDER BY указана только та колонка, которая находятся в том же многоколоночном индексе.
И так, если мы запустим этот запрос:
- Как часть обычного процесса сканирования индекса, CUBRID сначала найдет все листья в дереве индекса, в которых a >1 и a < 5.
- Затем среди этого результата, он отберет листья, в которых b < 'K'.
- Так как значения колонок a и b уже получены в процессе сканирования индекса, уже нет необходимости идти и смотреть в кучу на диске, чтобы получить эти значения. Таким образом, после второго шага сервер сразу приступает в сортированию результатов по колонке b.
- Затем возвращает значения.
Давайте теперь посмотрим, насколько покрывающий индекс может улучшить производительность сервера. Для того же вышеуказаного примера мы предположим, что в базе хранится очень большое количество данных.
Q1. Ниже приведен запрос, который использует колонки, указанные в одном составном индексе.
SELECT a, b FROM tbl WHERE a BETWEEN ? AND ?Q2. А теперь запрос, где колонка a индексирована, а колонка c — нет.
SELECT a, c FROM tbl WHERE a BETWEEN ? AND ?Следующая график показывает, насколько быстро могут быть обработаны запросы, если они используют покрывающий индекс.
Оптимизации обработки условий в LIMIT
Ограничение по ключям (Key Limit)
У CUBRID 8.4.0 — очень «умный» анализатор операторов LIMIT. Данный анализатор был очень оптимизирован, что позволяет обрабатывать только то количество записей, которое требуется в условии оператора LIMIT, при достижении которого сервер сразу возвращает результаты. К примеру, посмотрим на следующий запрос.
SELECT * FROM tbl
WHERE a = 2
AND b < ‘K’
ORDER BY b
LIMIT 3;- CUBRID сначала находит первый лист в дереве индекса, в котором a = 2.
- Так как индекс включает значения колонки b, которые уже отсортированы, нет необходимости отдельно отсортировывать результаты.
- Сервер проходит только по первым 3-м ключам индекса и на этом останавливается, так как нет необходимости возвращать больше 3 результатов.
- Затем сервер уже обрщается в кучу, чтобы получить значения всех остальных колонок. Таким образом только 3 записи будет затронуты на диске.
Многодиапазонное сканирование (Multi Range)
Оптимизация многодиапазонного сканирования является еще одним главным усовершенствованием в новом CUBRID 8.4.0. Когда пользователи заправшивают данные, которые лежат в определенном диапазоне, например, между a > 0 AND a < 5, задача является довольно легкой для большинства СУБД. Однако все становится намного сложнее, когда в условия включаются разбросанные диапазоны, например, a > 0 AND a < 5 AND a = 7 AND a > 10 AND a < 15. Здесь то CUBRID и отличается. Новая функция оптимизации in-place sorting (сортировка на лету) позволяет решить сразу две задачи:
- Ограничение по ключям (Key Limit)
- А также сортировка записей на лету
К примеру, рассмотрим следующий запрос.
SELECT * FROM tbl
WHERE a IN (2, 4, 5)
AND b < ‘K’
ORDER BY b
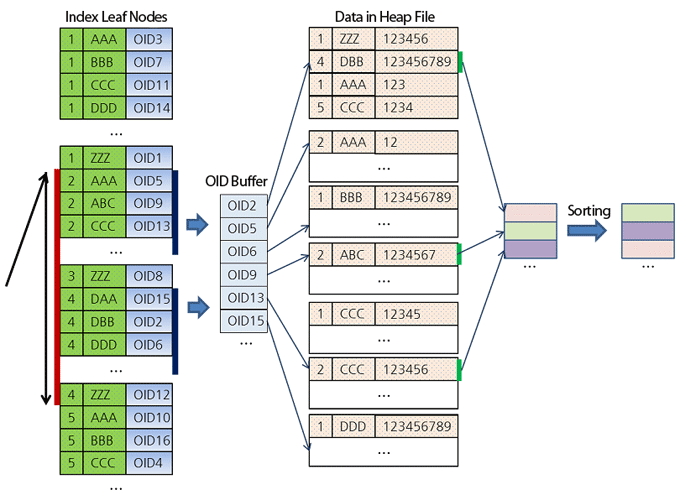
LIMIT 3;- Так как все ключи в дереве индекса отсортированы, сервер начнет сканирование, начиная с первого листа, где a = 2 (см. рисунок ниже).
- Так как необходимо получить только 3 строки таблицы, отсортированные по колонке b, сервер будет отсортировывать результаты, удовлетворяющие условию a IN (2, 4, 5) AND b < 'K', на лету.
1. В самом начале сервер найдет запись (2, AAA), что дает 1-й результат.
2. Затем находит запись (2, ABC), что дает 2-й результат.
3. Затем находит запись (2, CCC), что дает 3-й результат.
4. Так как сервер нашел уже 3 записи, он прыгает на следующий диапазон, в целях поиска записей, где значения колонки b будут меньше уже найденных значений.
- Сначала сервер найдет запись (4, DAA), который больше, чем последнее значение колонки b уже найденных записей. Поэтому этот диапазон сразу отпадает, и сервер прыгает на следующий диапазон.
- Находит запись (5, AAA), который меньше, чем ABC и CCC. Поэтому убирает последнюю запись и вставляет эту запись в подходящее место.
- Следующая запись (5, BBB) уже больше, чем последняя запись предварительных результатов. Поэтому на этом сканирование этого диапазона завершается. Также завершается и весь поиск, так как больше нет других диапазонов необходимые для сканирования.
- Так как все результаты уже отсортированы, остается только заглянуть в кучу и получить значения остальных колонок.
Благодаря этой возможности многодиапазонного сканирования с сортированием на лету, CUBRID может производить очень быстрый поиск среди большого количества данных.
Результаты тестов
В Корее есть очень популярный Веб сервис Me2Day, аналог Твиттера. Следующие результаты тестов были получены на основе реальных данных этого сервиса.
Как и в Твиттере, в Me2Day есть таблица posts, где хранятся все «твиты». Статистика пользователей и их отношений показывает, что:
- 50% пользователей следят за 1-50 пользователями.
- 40% пользователей следят за 51-2000 пользователями.
- 10% пользователей следят за 2001+ пользователями.
Для этой таблицы создан следующий индекс.
INDEX (author_id, registered DESC)Самый главный запрос, который чаще всего запрашивается и в сервисе Twitter, и в сервисе Me2Day — это "показать последние 20 случайных постов всех пользователей, за которыми я слежу". Ниже приведен этот самый запрос.
SELECT * FROM posts
WHERE author_id IN (?, ?, ..., ?) AND registered < :from ORDER BY reg_date DESC
LIMIT 20;Тест был запущен на 10 минут, в период которых продолжительно обрабатывался этот запрос. Ниже приведет график результатов тестирования, в котором сравнивается оператор UNION в MySQL, который в среднем в 4 раза быстрее, чем IN оператор в MySQL, с оператором IN в CUBRID. За одно, сравнив с предыдущей версие, Вы можете посмотреть, насколько увеличилась производительность CUBRID 8.4.0 после реализации многодеапазонного сканирования.
После таких положительных результатов мы заменили MySQL сервера Me2Day, отвечающие за ежедневную работу сервиса, на сервера CUBRID. В следующий раз расскажу об этом тесте более подробно. А пока Вы можете также прочитать о нем на английском на главном сайте.
Оптимизации обработки условий в GROUP BY
Новая версия CUBRID 8.4.0 значительно ускорила обработку запросов, содержащие ORDER BY и GROUP BY операторы. Когда в условиях ORDER BY и GROUP BY используются колонки, включенные в многоколоночный индекс, отпадает необходимость отсортировывать значения, так как они уже отсортированы в дереве индекса. Такая оптимизация позволяет значительно увеличить производительность обработки всего запроса. Можем посмотреть на работу следующего запроса.
SELECT COUNT(*) FROM tbl
WHERE a > 1 AND a < 5
AND b < ‘K’ AND c > 10000
GROUP BY a;- Как часть обычного процесса сканирования индекса, CUBRID сначала найдет все листья в дереве индекса, в которых a >1 и a < 5.
- Используя значения OID, сервер обратится в кучу для получения значений колонки c.
- Затем CUBRID найдет все те записи, в которых c > 10000.
- Так как все необходимые значения уже отсортированы, операция GROUP BY будет производиться сразу же без предварительной сортировки.
- Затем сервер возвращает полученные результаты.
Увеличение Продуктивности Разработчиков
Помимо улучшения производительности всей системы, новая версия CUBRID 8.4.0 поддерживает более 90% SQL синтаксиса СУБД MySQL. Мы также реализовали расширенную поддержку неявного преобразования типов, чтобы разработчики концентрировались на улучшение функциональности своих приложений, в то время как CUBRID будет делать все внутренние преобразования. Ниже приведу несколько примеров нового синтаксиса.
- Неявное преобразование типов
CREATE TABLE x (a INT);
INSERT INTO x VALUES (‘1’);
- Запросы SHOW
SHOW TABLES; SHOW COLUMNS; SHOW INDEX; …
- ALTER TABLE… CHANGE/MODIFY COLUMN…
CREATE TABLE t1 (a INTEGER);
ALTER TABLE t1 CHANGE a b DOUBLE;
ALTER TABLE t2 MODIFY col1 BIGINT DEFAULT 1;
- UPDATE… ORDER BY
UPDATE t
SET i = i + 1
WHERE 1 = 1
ORDER BY i
LIMIT 10;
- DROP TABLE IF EXISTS…
DROP TABLE IF EXISTS history;
Всего в новой версии 23 новых DATE/TIME синтаксиса, 5 — связанных со строками, и 5 новых функций аггрегирования. Весь список нового синтаксиса можете найти в блоге на офф. сайте.
Улучшение недёжности Высокой Доступности
Улучшение блокировки следующего ключа
Также в версии CUBRID 8.4.0 значительно улучшили механизм блокировки, чтобы минимизировать появления застоев. Например, в среде Высокой Доступности застои не будут образовываться между транзакциями, которые вводят данные в одну и ту же таблицу в одно и то же время.
Заключение
Как Вы, наверное, уже поняли, новая версия CUBRID 8.4.0 явно превосходит все предыдущие версии и в производительности, и в надёжности, и в удобстве разработки. CUBRID разрабатывается с целью использования в Веб приложениях и сервисах, посему все основные разработки, улучшения и оптимизации ведутся в сфере функций, часто используемых в Веб приложениях (например, как операторы IN, ограничения LIMIT, группировки и сортирование, а также Высокая Доступность), превосходство в производительности которых доказывается результатами сравнительных тестов.
Если у Вас есть определенные вопросы, пишите в комментариях. Буду очень рад все разъяснить!
