Comments 40
По поводу английской версии — есть отличный стартап www.grammarly.com/, создается отечественными разработчиками, как ни парадоксально. Его можно прямо на сайте потестить, ребята проделали очень серьезную работу как раз в области синтаксиса.
Проверки синтаксиса часто очень не достает. С /грамматикой проще, достаточно часто просто перечитать написанное. А вот с синтаксисом беда бывает.
Другу как раз этого не хватало, всегда потом прохожусь и правлю за него ошибки, спасибо!
Плохость стиля 2
_______________
Плохой стиль (степень 2) — исправлений: 14
_______________
Плохой стиль (степень 2) — исправлений: 14
«плохость» — не совсем правильное слово, зато оно короче. Посчитал его допустимым вспомнив его использование в мультике при переводе — в фразе «здесь показана твоя плохость» (наверно так перевели «badness»).
Еще жалею что не сократил «Синтакс. анализ предложения закончен.» еще сильнее — не влезает фраза «Выполнено за ...» — и не видно за сколько! К счастью сейчас это можно поменять в файлике интерфейса.
Еще жалею что не сократил «Синтакс. анализ предложения закончен.» еще сильнее — не влезает фраза «Выполнено за ...» — и не видно за сколько! К счастью сейчас это можно поменять в файлике интерфейса.
Уточнение: получаемые фразы оцениваются по пяти параметрам; мне очень хотелось чтобы каждый был описан в общем стиле: не прилагательным («плохой стиль: 5»), а существительным — так появился «плохость стиля: 5». Плюс хотелось чтоб оценка для всех была положительной (чтоб не было визуальной путаницы с минусом): от нуля и чем больше тем значит вариант хуже.
Но ведь фразу в примере можно исправить двумя способами: «Эта компьютерная программа распознает простой текст» и «Это компьютерная программа, распознающая простой текст», а еще может быть так «Этой компьютерной программе распознавать простой текст» (ну, судьба у нее такая).
Вообще, что касается запятых, если бы из произвольной последовательности слов (пусть даже в нужных формах) можно было бы вывести однозначно расстановку запятых, тогда, согласитесь, запятые были бы не нужны. Расставляя запятые, вы обозначаете семантику высказывания. Хрестоматийный пример: «казнить нельзя помиловать». Компьютер не может читать ваши мысли, поэтому не может расставить за вас запятые. Так, например, деепричастные обороты в русском выделяются запятыми именно из-за неоднозначностей; в английском аналогичные по функции continuous формы запятыми не выделяются, потому что там неоднозначность разрешает порядок слов.
Я раньше пользовался Орфо и думаю, что лучше вряд ли что-то можно изобрести, но даже он фатально ошибается, поэтому я от него отказался. В какой-то момент я понял, что единственный способ писать грамотно — выучить грамматику.
Вообще, что касается запятых, если бы из произвольной последовательности слов (пусть даже в нужных формах) можно было бы вывести однозначно расстановку запятых, тогда, согласитесь, запятые были бы не нужны. Расставляя запятые, вы обозначаете семантику высказывания. Хрестоматийный пример: «казнить нельзя помиловать». Компьютер не может читать ваши мысли, поэтому не может расставить за вас запятые. Так, например, деепричастные обороты в русском выделяются запятыми именно из-за неоднозначностей; в английском аналогичные по функции continuous формы запятыми не выделяются, потому что там неоднозначность разрешает порядок слов.
Я раньше пользовался Орфо и думаю, что лучше вряд ли что-то можно изобрести, но даже он фатально ошибается, поэтому я от него отказался. В какой-то момент я понял, что единственный способ писать грамотно — выучить грамматику.
Программа предлагает варианты, соответствующие ее шаблону и БД словаря. В теперешнем шаблоне нет конструкции для Вашего вторго и третьего вариантов; так же не описано в словаре что такое «распознающая», а в шаблоне соответственно не описано как это использовать.
> Но ведь фразу в примере можно исправить двумя способами
В том то и дело, что для человека очевидны одни варианты, а если пытаешся программу «научить» их разбирать — для нее неожиданно более правильными оказываются другие варианты — по той самой логике которую ты в нее вложил.
Плюс не факт, что человек собирался написать какой-то из Ваших трех вариантов (для другого человека могут быть очевидны другие варианты); имхо «мои» 7 вариантов все еще выглядят логичными, правильными и поэтому претендуют на место того текста, что человек пытался ввести.
Кстати, в вашем третьем варианте вроде 8 отличий от входного текста; а программа выдала 5 вариантов с меньшим количеством исправлений.
> Но ведь фразу в примере можно исправить двумя способами
В том то и дело, что для человека очевидны одни варианты, а если пытаешся программу «научить» их разбирать — для нее неожиданно более правильными оказываются другие варианты — по той самой логике которую ты в нее вложил.
Плюс не факт, что человек собирался написать какой-то из Ваших трех вариантов (для другого человека могут быть очевидны другие варианты); имхо «мои» 7 вариантов все еще выглядят логичными, правильными и поэтому претендуют на место того текста, что человек пытался ввести.
Кстати, в вашем третьем варианте вроде 8 отличий от входного текста; а программа выдала 5 вариантов с меньшим количеством исправлений.
Интересная и полезная программа.
Однако, если вы хотите действительно сделать ее полезной, популярной и развивающейся, то следовало бы:
а) предоставлять ее в виде библиотеки
б) предоставлять ее под тремя платформами (под виндой большая часть пользователей и офисов, под линуксом и маками — разработчики).
Интерфейс тут вообще не нужен, такие вещи удобней использовать в третьих приложениях.
Однако, если вы хотите действительно сделать ее полезной, популярной и развивающейся, то следовало бы:
а) предоставлять ее в виде библиотеки
б) предоставлять ее под тремя платформами (под виндой большая часть пользователей и офисов, под линуксом и маками — разработчики).
Интерфейс тут вообще не нужен, такие вещи удобней использовать в третьих приложениях.
К сожалению эта программа предназначенна больше для демонстрации ее возможностей, а не для «нормального» использования (и тем более простыми пользователями) — до этого состояния программу нужно доводить (потратив на это много человеко-лет). И даже после этого возможны ситуации, когда программа не сможет «понять» фразу пользователя как правильную (у пользователя и у программы могут не совпадать мнения о правильности фразы) или когда пользователь будет писать одно, напишет второе, а в качестве исправленного варианта выберет третье — получится что программа не смогла помочь пользователю так как он надеялся.
Кроме того, заканчивая программу стали видны потолок и прочие неудобства ее развития; поэтому я планировал создать еще более гибкую версию — мульти-граммар (подробнее — в описании принципа действия программы).
Кроме того, заканчивая программу стали видны потолок и прочие неудобства ее развития; поэтому я планировал создать еще более гибкую версию — мульти-граммар (подробнее — в описании принципа действия программы).
Да я понимаю. И, собственно, поэтому и говорю, что если вы хотите привлечь внимание и интерес других разработчиков к программе, то следует оформить ее в другом стиле.
В текущем виде
а) неудобно писать автоматизированные комплекты тестов
б) нельзя быстро прогонять разные предложения и проверять результат
в) неуклюжий интерфейс, который, к тому же, еще и прибит гвоздями к одной ОС
г) на sourceforge что-то нет исходников
Такое чувство, что вы планируете программу просто выбросить со временем.
В текущем виде
а) неудобно писать автоматизированные комплекты тестов
б) нельзя быстро прогонять разные предложения и проверять результат
в) неуклюжий интерфейс, который, к тому же, еще и прибит гвоздями к одной ОС
г) на sourceforge что-то нет исходников
Такое чувство, что вы планируете программу просто выбросить со временем.
б) нельзя быстро прогонять разные предложения и проверять результат
— В основном окне можно нажать Clean, затем Paste — и вставить эти самые «разные предложения». Затем можно сделать быструю проверку для всех предложений разом, установив чекбокс «Показывать обозначенному предложению синтаксические и грамматические исправления» — попробуйте сделать это для начального текста — все предложения окрасятся красным (не распознаны); все, кроме трех.
Ну, и потом можно эти «разные предложения» по одномуковырять разбирать, нажимая кнопку «Анализировать...»
Если это не отвечает требованиям этого пункта, то я чего-то не понял.
в) неуклюжий интерфейс, который, к тому же, еще и прибит гвоздями к одной ОС
— Я Вам больше скажу: окна двух диалоговых экранов не растягиваются! И вообше написано не на последней версии Visual Studio (а на шестой — 1998 года). Зато, по слухам, программка теоретически может работать под эмуляторами — на Маке и под Линуксом.
г) на sourceforge что-то нет исходников
— Ваша правда; нету.
> Такое чувство, что вы планируете программу просто выбросить со временем.
— Программка с 2003 по 2011 была выброшенна раза три-четыре (смотря как считать); затем (почти заново) создавалась ее новая версия.
Первая версия создавала очередную комбинацию входного предложения и заново прогоняла ее через синтаксический анализатор — и так для всех комбинаций; а их могло быть например 14 миллионов для одного предложения из шести слов (24*24*12*7*24*12).
Теперяшняя третья с половиной версия использует ядро 2007 года, идею 2003 года, и (бегло; не глубоко) проверяет начальный текст из 334 слов примерно за 7 секунд.
— В основном окне можно нажать Clean, затем Paste — и вставить эти самые «разные предложения». Затем можно сделать быструю проверку для всех предложений разом, установив чекбокс «Показывать обозначенному предложению синтаксические и грамматические исправления» — попробуйте сделать это для начального текста — все предложения окрасятся красным (не распознаны); все, кроме трех.
Ну, и потом можно эти «разные предложения» по одному
Если это не отвечает требованиям этого пункта, то я чего-то не понял.
в) неуклюжий интерфейс, который, к тому же, еще и прибит гвоздями к одной ОС
— Я Вам больше скажу: окна двух диалоговых экранов не растягиваются! И вообше написано не на последней версии Visual Studio (а на шестой — 1998 года). Зато, по слухам, программка теоретически может работать под эмуляторами — на Маке и под Линуксом.
г) на sourceforge что-то нет исходников
— Ваша правда; нету.
> Такое чувство, что вы планируете программу просто выбросить со временем.
— Программка с 2003 по 2011 была выброшенна раза три-четыре (смотря как считать); затем (почти заново) создавалась ее новая версия.
Первая версия создавала очередную комбинацию входного предложения и заново прогоняла ее через синтаксический анализатор — и так для всех комбинаций; а их могло быть например 14 миллионов для одного предложения из шести слов (24*24*12*7*24*12).
Теперяшняя третья с половиной версия использует ядро 2007 года, идею 2003 года, и (бегло; не глубоко) проверяет начальный текст из 334 слов примерно за 7 секунд.
лично меня волнует прежде всего б) и в)
б) дело не в кнопках Clean и Paste, а в том, можно ли написать скрипт для тестирования сотен предложений разом, что было бы разумно в данном случае. Скрипт, скажем, на баше или Питоне. Сунул тысячу предложений, получил тысячу результатов.
в) эмуляторы… Ну это смешно. Хорошая либа на Си, движок которой не привязан к компилятору, запросто может компилироваться где угодно. Ваш случай, к примеру, вообще никак не привязан к платформе, ибо область абстракций, а не область специфичного API. Только интерфейс Видовса, и тот можно выбросить.
Вот я говорю. Вы все оформили так, будто… Ну очень мило, любовь в старым компиляторам. Это как писать на встроенном интерпретаторе Бэйсика под Спектрум. Как бы… И чего?
А польза и смысл были бы в качественном подходе. Опенсорс там, все дела, групповой разум. Ваша деятельность действительно достойна уважения, только придать бы ей некую осмысленность.
Кстати, родом я из Литвы, что забавно, полулитовец :) Привет Гядиминке.
б) дело не в кнопках Clean и Paste, а в том, можно ли написать скрипт для тестирования сотен предложений разом, что было бы разумно в данном случае. Скрипт, скажем, на баше или Питоне. Сунул тысячу предложений, получил тысячу результатов.
в) эмуляторы… Ну это смешно. Хорошая либа на Си, движок которой не привязан к компилятору, запросто может компилироваться где угодно. Ваш случай, к примеру, вообще никак не привязан к платформе, ибо область абстракций, а не область специфичного API. Только интерфейс Видовса, и тот можно выбросить.
Вот я говорю. Вы все оформили так, будто… Ну очень мило, любовь в старым компиляторам. Это как писать на встроенном интерпретаторе Бэйсика под Спектрум. Как бы… И чего?
А польза и смысл были бы в качественном подходе. Опенсорс там, все дела, групповой разум. Ваша деятельность действительно достойна уважения, только придать бы ей некую осмысленность.
Кстати, родом я из Литвы, что забавно, полулитовец :) Привет Гядиминке.
При написании основная цель проекта была создать инструмент, который бы показывал, что распознание и, более того, исправление, то есть распознание всех возможных (например ~14 миллионов) вариантов (чтоб предложить более правильный) входного предложения — возможно за приемлимое время. Первые версии этого не обеспечивали (да и компьютеры были медленнее).
Поэтому писал на том, на чем умею, и где могу получить максимальное быстродействие.
Какова была бы скорость распознания у программки написанной на скрипте — не знаю, но мне кажется медленнее.
> Сунул тысячу предложений…
— насколько я слышал, в России все еще существуютконторы фирмы, которые этим занимаются; и даже имеют «гигантскую базу данных из деревьев распознанных предложений».
Насколько я возился с этой программкой — основная сложность не в том чтоб «написать скрипт для тестирования сотен предложений разом» (для этого, имхо, вполне хватает скопировать и вставить их все в первое окно программки), а в том, чтоб сложить хотя бы 4-10 предложений в один шаблон.
… Теперь это может попробовать сделать каждый желающий ;)
Для этого сделаны окна графического представления деревьев и интерфейс перехода «В целом -> Детальнее» для распознанной фразы.
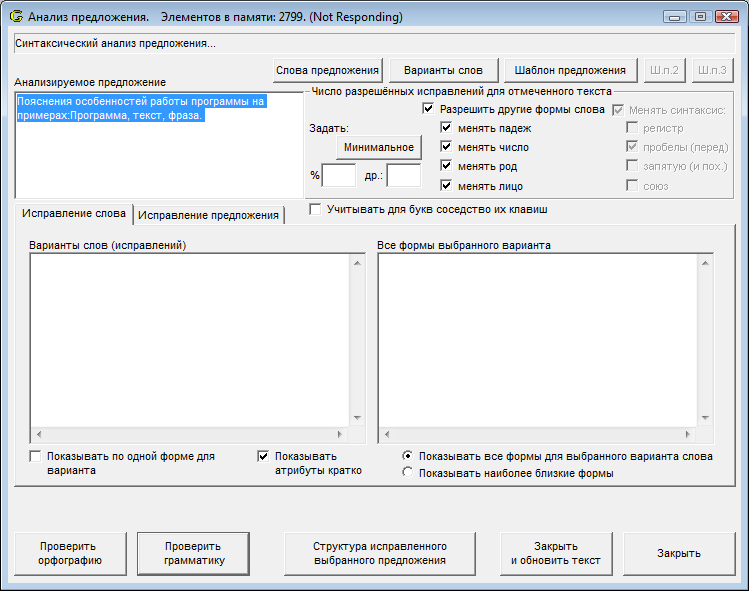
Другая сложность — как отобрать из 2779 полученных вариантов (как на втором скрин-шоте) один-единственный, который скорей всего пользователь и пытался написать (имел в виду).
Эмуляторы — для ознакомления думаю их хватит, а?
Поэтому писал на том, на чем умею, и где могу получить максимальное быстродействие.
Какова была бы скорость распознания у программки написанной на скрипте — не знаю, но мне кажется медленнее.
> Сунул тысячу предложений…
— насколько я слышал, в России все еще существуют
Насколько я возился с этой программкой — основная сложность не в том чтоб «написать скрипт для тестирования сотен предложений разом» (для этого, имхо, вполне хватает скопировать и вставить их все в первое окно программки), а в том, чтоб сложить хотя бы 4-10 предложений в один шаблон.
… Теперь это может попробовать сделать каждый желающий ;)
Для этого сделаны окна графического представления деревьев и интерфейс перехода «В целом -> Детальнее» для распознанной фразы.
Другая сложность — как отобрать из 2779 полученных вариантов (как на втором скрин-шоте) один-единственный, который скорей всего пользователь и пытался написать (имел в виду).
Эмуляторы — для ознакомления думаю их хватит, а?
К первому из абзацев.
Я ведь не про то, что пользователь теперь может засунуть предолжение, увидеть результат, порадоваться, нет. А про то, что с вашей программой не ясно, что делать программисту. Ни встроить куда-то, ни исходник изучить, ни автоматизировать тестирование.
Скрипт был простейшим примером того, что можно сделать, если по-серьезному такие вещи разрабатывать.
Вообще все равно, что этот черный ящик выплевывает в интерфейс. Кому какое дело до чужих интерфейсов?
Разработчику приятно было бы помочь с разработкой либы; но либы оформленной и удобной для включения в другие проекты.
Я ведь не про то, что пользователь теперь может засунуть предолжение, увидеть результат, порадоваться, нет. А про то, что с вашей программой не ясно, что делать программисту. Ни встроить куда-то, ни исходник изучить, ни автоматизировать тестирование.
Скрипт был простейшим примером того, что можно сделать, если по-серьезному такие вещи разрабатывать.
Вообще все равно, что этот черный ящик выплевывает в интерфейс. Кому какое дело до чужих интерфейсов?
Разработчику приятно было бы помочь с разработкой либы; но либы оформленной и удобной для включения в другие проекты.
Мне тоже не ясно, что делать программисту с этой программой. Ибо она для демонстрации а не для «промышленного» использования.
Имхо ей нужна помощь тех редких лингвистов, которые бы смогли расширить ее шаблон предложения.
Файл словаря имхо имеет сруктуру достаточно простую для его наполнения другими программами; правда возможность описывать все формы слова указывая в словаре только одну его форму и его склонение — для русского языка не подключена; поэтому есть неудобство в том, что надо описывать все 12-25-36 форм для гнезда одного слова.
Я надеюсь, что система меток, на которую я мечтаю перевести программу, позволитизящно элегантно решить и проблему со склонениями… и проблему синтеза/слияния синтаксического анализа с фонетическим; например когда в шаблоне для синтаксического анализа можно будет указать, что если следующее слово начинается с определенных букв, то предлог вместо «с» должен быть «со».
Имхо ей нужна помощь тех редких лингвистов, которые бы смогли расширить ее шаблон предложения.
Файл словаря имхо имеет сруктуру достаточно простую для его наполнения другими программами; правда возможность описывать все формы слова указывая в словаре только одну его форму и его склонение — для русского языка не подключена; поэтому есть неудобство в том, что надо описывать все 12-25-36 форм для гнезда одного слова.
Я надеюсь, что система меток, на которую я мечтаю перевести программу, позволит
Отличная штука, надеюсь, что смогу связаться с Вами, я сам лингвист.
а вы на свой сайт не пробовали ее натравить? ;)
Жалко их обоих! :) Текст сайта проверял встроенным спеллингом Хрома (оказалось полезно); после публикования здесь обнаружил на «своем сайте» одну ошибку согласования — пробыла там полгода; причем здесь опубликовал с этой ошибкой, но счас ее не замечаю.
Сюда (волею судеб) отвечаю с мака, на нем русский спеллинг Хрома включить не умею, так что возможно всякое…
Сюда (волею судеб) отвечаю с мака, на нем русский спеллинг Хрома включить не умею, так что возможно всякое…
Скачал. Посмотрел. Впечатление двоякое. С одной стороны — почтение разработчику за то, что взялся за интересную задачу, с другой стороны — интерфейс перегружен и, что хуже, результаты на моих тестах были неудовлетворительны. Вероятно, словарь слишком мал?
Ещё замечание: не стоит прикладной программе писать в \Windows\System32 — для этого есть более подходящие места.
Если качество работы действительно зависит от словаря, то было бы логично предоставить пользователю возможность непосредственно из программы расширять словарь. А в идеале — возможность объединять словари, созданные разными пользователями. Я не знаю, может быть такая возможность имеется, но я не могу разрешить писать «неизвестной» программе в \Windows\System32.
На мой взгляд — проект интересный, но ещё слишком сырой. Желаю вдохновения, удачи и терпения разработчику. Пожалуй, посмотрел бы следующие версии программы.
Ещё замечание: не стоит прикладной программе писать в \Windows\System32 — для этого есть более подходящие места.
Если качество работы действительно зависит от словаря, то было бы логично предоставить пользователю возможность непосредственно из программы расширять словарь. А в идеале — возможность объединять словари, созданные разными пользователями. Я не знаю, может быть такая возможность имеется, но я не могу разрешить писать «неизвестной» программе в \Windows\System32.
На мой взгляд — проект интересный, но ещё слишком сырой. Желаю вдохновения, удачи и терпения разработчику. Пожалуй, посмотрел бы следующие версии программы.
Цитирую описание по ссылке:
"Внимание! Литовская версия программы правильно распознаёт менее 5% предложений — из-за неполноты словаря программы (80,000 гнёзд слов) и несовершенства шаблона предложения. В русской версии процент распознания мизерный, словарь состоит всего из 710 слов (формы слов для 4 существительных, 3 прилагательных, 4 глаголов, 3 наречий), но при желании его можно дополнить, а универсальный шаблон предложения — улучшить."
Еще раз повторяю, что программа предназначена для демонстрации работы ее ядра; ибо 4 года разработки были потрачены именно на ядро, а не на наполнение БД слов и БД шаблона предложения.
Моя программа должна писать туда откуда ее запустили (и куда ее перед этим записал пользователь, соответственно). Если она пишет свои три текстовых файла в системный каталог — это серьезная проблема.
> А в идеале — возможность объединять словари, созданные разными пользователями.
— У меня была идея, чтобы это все еще происходило он-лайн; и не только со словарем (они есть в интернете в свободном доступе, но я не нашел быстро такого (кроме литовского), чтоб в нем указывались атрибуты формы слова), но и самое главное — с шаблонами: возможность объединять шаблоны, созданные разными пользователями, или вообще сделать создание шаблонов полуавтоматическим — по принципу обучения экспертной системы — когда ей объясняешь новое правило, а она прогоняет его по всем подходящим фразам, чтобы уточнить для каких фраз правило не действует — обычно человек этого не учитывает, когда вписывает в шаблон новое правило.
"Внимание! Литовская версия программы правильно распознаёт менее 5% предложений — из-за неполноты словаря программы (80,000 гнёзд слов) и несовершенства шаблона предложения. В русской версии процент распознания мизерный, словарь состоит всего из 710 слов (формы слов для 4 существительных, 3 прилагательных, 4 глаголов, 3 наречий), но при желании его можно дополнить, а универсальный шаблон предложения — улучшить."
Еще раз повторяю, что программа предназначена для демонстрации работы ее ядра; ибо 4 года разработки были потрачены именно на ядро, а не на наполнение БД слов и БД шаблона предложения.
Моя программа должна писать туда откуда ее запустили (и куда ее перед этим записал пользователь, соответственно). Если она пишет свои три текстовых файла в системный каталог — это серьезная проблема.
> А в идеале — возможность объединять словари, созданные разными пользователями.
— У меня была идея, чтобы это все еще происходило он-лайн; и не только со словарем (они есть в интернете в свободном доступе, но я не нашел быстро такого (кроме литовского), чтоб в нем указывались атрибуты формы слова), но и самое главное — с шаблонами: возможность объединять шаблоны, созданные разными пользователями, или вообще сделать создание шаблонов полуавтоматическим — по принципу обучения экспертной системы — когда ей объясняешь новое правило, а она прогоняет его по всем подходящим фразам, чтобы уточнить для каких фраз правило не действует — обычно человек этого не учитывает, когда вписывает в шаблон новое правило.
Еще раз повторяю, что программа предназначена для демонстрации работы ее ядра; ибо 4 года разработки были потрачены именно на ядро, а не на наполнение БД слов и БД шаблона предложения.
Понятно. Спасибо. Таким образом я бы посмотрел программу ещё раз, если бы кто-нибудь предложил более полный словарь.
Моя программа должна писать туда откуда ее запустили (и куда ее перед этим записал пользователь, соответственно). Если она пишет свои три текстовых файла в системный каталог — это серьезная проблема.

Разумеется, я не переписывал программу в system32. Судя по всему, это проблема Firefox, если программа запускается из «Списка загрузки».
У меня была идея, чтобы это все еще происходило он-лайн; и не только со словарем (они есть в интернете в свободном доступе, но я не нашел быстро такого (кроме литовского), чтоб в нем указывались атрибуты формы слова),
А что с литовским языком? Распознавание 5% процентов — это уже интересно.
Кстати, а в эстонском и латвийском языках шаблоны идентичны литовским?
но и самое главное — с шаблонами: возможность объединять шаблоны, созданные разными пользователями, или вообще сделать создание шаблонов полуавтоматическим — по принципу обучения экспертной системы — когда ей объясняешь новое правило, а она прогоняет его по всем подходящим фразам, чтобы уточнить для каких фраз правило не действует — обычно человек этого не учитывает, когда вписывает в шаблон новое правило.
Хочу такую версию. Интересно поиграться и, возможно, пополнить (её) лексикон. Если бы Ваша программа позволяла простым способом её обучать и хранить полученную информацию в какой либо базе данных — то это стало бы интересным. Кроме того — различным словам можно было бы в отдельных полях назначить контекст, предметную область, частоту употребляемости, этимологию и прочие атрибуты, которые, впоследствии могут пригодиться для более глубокого анализа текста. А ещё атрибуты жаргона и ненормативной лексики не помешали бы.
Фраза из Маяковского:
Я русский бы выучил только за то, что им разговаривал Ленин!
Дала восхитительные результаты:
ты вводил большой ( неполнота 10, плохость стиля 1, исправлений 7 )
ты вводил большое ( неполнота 10, плохость стиля 1, исправлений 7 )
А вот на таком предложении программа уходит в бесконечный цикл:
В принципе, я верю в Ваш движок, но без словарей (базы знаний экспертной системы) он не сможет заблистать в полную мощь. Вот если бы как-то централизованно собирать экспертные данные от различных пользователей в единую базу данных, то могло бы получиться весьма интересно.
> Разумеется, я не переписывал программу в system32. Судя по всему, это проблема Firefox, если программа запускается из «Списка загрузки».
— Ну… я привык не доверяться списку загрузки, а лично указывать что куда записать при скачивании; описаную Вами ситуацию я просто не проверял.
> А что с литовским языком?
— Имхо он ближе к русскому, чем к английскому — (почти) 6 падежей, два рода (почти), два числа; примерно те же части речи.
Но конструкция предложения несколько отличается от русского.
> Распознавание 5% процентов — это уже интересно.
— Просто где-то в 2005 я нашел свободный словарь для проекта iSpell, предназначенный для спеллинга литовского языка; я им воспользовался ибо там можно было выудить не только форму слова, но и ее атрибуты (род, число, падеж, лицо) — а именно это необходимо для проверки согласования.
А дальше — цитирую: «Внимание! Литовская версия программы правильно распознаёт менее 5% предложений — из-за неполноты словаря программы (80,000 гнёзд слов) и из-за несовершенства шаблона предложения.»
> Кстати, а в эстонском и латвийском языках шаблоны идентичны литовским?
— Этого я не знаю.
Повторяю: слышал, что шаблон предложения создавался для русского языка какими-то российскими институтами => фирмами. Какова ситауция с эстонским, латвийским и литовским языками — я просто не знаю; занимался ли кто-то созданием для них шаблонов.
Плюс, попробовав это, я острее понимаю, что: набрать базу предложений, распознать каждое в дерево, и на основе анализа деревьев создать универсальное (дерево, и прогнать все по новой) — это три большие разницы.… То есть, имхо, это самый сложный путь «распиливания» бюджета лингвистического иститута — я уверен, что таких немало, но мало кто на такое пойдет.
> Фраза из Маяковского… Дала восхитительные результаты…
— Цитирую: «В русской версии процент распознания мизерный, словарь состоит всего из… форм слов для 4 существительных, 3 прилагательных, 4 глаголов, 3 наречий». Защищая порядочность программы, могу предположить, что она просто подобрала ближайшие слова из словаря; безо всякого злого умыслу.
… И опять-таки, такой фразы я просто не тестировал…
> А вот на таком предложении программа уходит в бесконечный цикл:
— Время распознания (всех возможных вариантов предложения) остается приемлимым, если в предложении за одно распознание разрешено менять форму максимум для двух существительных (для остальных частей речи такое ограничение не обязательно — их другие формы не пораждают такого дикого количества вариантов начальной фразы).
Возможно у Вас были «разрешены другие формы слова» (чекбоксом) для всех 8 имен существительных в предложении; хотя словарь состоит всего из 4 имен существительных.
На мой взгляд в той ситуации было бы правильнее вручную добавить недостающие слова в словарь (по 12-48 форм для каждого слова) и усовершенствовать шаблон (хотя я бы не рискнул улучшать шаблон, тем более для Маяковского; учитывая мои потуги последних месяцев — дай бог простое английское предложение осилить).
— Ну… я привык не доверяться списку загрузки, а лично указывать что куда записать при скачивании; описаную Вами ситуацию я просто не проверял.
> А что с литовским языком?
— Имхо он ближе к русскому, чем к английскому — (почти) 6 падежей, два рода (почти), два числа; примерно те же части речи.
Но конструкция предложения несколько отличается от русского.
> Распознавание 5% процентов — это уже интересно.
— Просто где-то в 2005 я нашел свободный словарь для проекта iSpell, предназначенный для спеллинга литовского языка; я им воспользовался ибо там можно было выудить не только форму слова, но и ее атрибуты (род, число, падеж, лицо) — а именно это необходимо для проверки согласования.
А дальше — цитирую: «Внимание! Литовская версия программы правильно распознаёт менее 5% предложений — из-за неполноты словаря программы (80,000 гнёзд слов) и из-за несовершенства шаблона предложения.»
> Кстати, а в эстонском и латвийском языках шаблоны идентичны литовским?
— Этого я не знаю.
Повторяю: слышал, что шаблон предложения создавался для русского языка какими-то российскими институтами => фирмами. Какова ситауция с эстонским, латвийским и литовским языками — я просто не знаю; занимался ли кто-то созданием для них шаблонов.
Плюс, попробовав это, я острее понимаю, что: набрать базу предложений, распознать каждое в дерево, и на основе анализа деревьев создать универсальное (дерево, и прогнать все по новой) — это три большие разницы.… То есть, имхо, это самый сложный путь «распиливания» бюджета лингвистического иститута — я уверен, что таких немало, но мало кто на такое пойдет.
> Фраза из Маяковского… Дала восхитительные результаты…
— Цитирую: «В русской версии процент распознания мизерный, словарь состоит всего из… форм слов для 4 существительных, 3 прилагательных, 4 глаголов, 3 наречий». Защищая порядочность программы, могу предположить, что она просто подобрала ближайшие слова из словаря; безо всякого злого умыслу.
… И опять-таки, такой фразы я просто не тестировал…
> А вот на таком предложении программа уходит в бесконечный цикл:
— Время распознания (всех возможных вариантов предложения) остается приемлимым, если в предложении за одно распознание разрешено менять форму максимум для двух существительных (для остальных частей речи такое ограничение не обязательно — их другие формы не пораждают такого дикого количества вариантов начальной фразы).
Возможно у Вас были «разрешены другие формы слова» (чекбоксом) для всех 8 имен существительных в предложении; хотя словарь состоит всего из 4 имен существительных.
На мой взгляд в той ситуации было бы правильнее вручную добавить недостающие слова в словарь (по 12-48 форм для каждого слова) и усовершенствовать шаблон (хотя я бы не рискнул улучшать шаблон, тем более для Маяковского; учитывая мои потуги последних месяцев — дай бог простое английское предложение осилить).
— Просто где-то в 2005 я нашел свободный словарь для проекта iSpell, предназначенный для спеллинга литовского языка; я им воспользовался ибо там можно было выудить не только форму слова, но и ее атрибуты (род, число, падеж, лицо) — а именно это необходимо для проверки согласования.
А в не думали пойти немного дальше? Не просто хранить атрибуты, но и разбивать слова на составные части — корень, суффикс, окончание? Вероятно, при некотором везении, можно существенно сжать словарь.
Плюс, попробовав это, я острее понимаю, что: набрать базу предложений, распознать каждое в дерево, и на основе анализа деревьев создать универсальное (дерево, и прогнать все по новой) — это три большие разницы.… То есть, имхо, это самый сложный путь «распиливания» бюджета лингвистического иститута — я уверен, что таких немало, но мало кто на такое пойдет.
Не пробовали использовать эту тему в качестве базы предложений?
Скормить всю статью своей программе. Как только встретилось новое слово — тут же предложить пользователю анализ этого слова и ввод атрибутов. Неизвестная словоформа — предложить пользователю ввести/отредактировать шаблон словоформы.
Защищая порядочность программы, могу предположить, что она просто подобрала ближайшие слова из словаря; безо всякого злого умыслу.
… И опять-таки, такой фразы я просто не тестировал…
А если бы тестировали, то не поленились бы добавить эту фразу в базу знаний экспертной машины? А вот если бы дали такую возможность пользователям — непосредственно из программы, не изучая формат файлов dic.txt и rules.txt, то люди бы повнимательнее посмотрели на Ваш продукт.
На мой взгляд в той ситуации было бы правильнее вручную добавить недостающие слова в словарь (по 12-48 форм для каждого слова) и усовершенствовать шаблон (хотя я бы не рискнул улучшать шаблон, тем более для Маяковского; учитывая мои потуги последних месяцев — дай бог простое английское предложение осилить).
Думаете, с Пушкиным было бы проще? ;)
А если серьёзно, то во время распознавания хотя бы изредка проверяйте сообщения Windows:
if( GetMessage(&msg,NULL,0,0) != -1 ) { TranslateMessage(&msg); DispatchMessage(&msg); }Тогда Windows не будет считать, что программа зависла.
Кстати, спеллчекер из Microsoft Word какой-то там версии как-то справлялся с согласованием слов. Так что конкуренты у Вашего продукта есть. Ваша программа интересна тем, что с её разработчиком можно пообщаться, задать вопросы и внести предложения.
Немного поигрался со словарём и фразой «Передать другой текст компьютерной программе.» Почему-то отсекается «компьютерной программе». В то же время, фраза «Передать другой текст компьютерной программы.» разбирается корректно.
> А в не думали пойти немного дальше?
— Тут уже предлагали много различных направлений; куда на этот раз?
> Не просто хранить атрибуты, но и разбивать слова на составные части — корень, суффикс, окончание? Вероятно, при некотором везении, можно существенно сжать словарь.
— А, это все было реализовано в предыдущих версиях для литовского языка. Только там без суффикса было: окончание (из шаблона склонения), приставки («не» для прилагательных и куча для глаголов) и основная часть (корень + возможные суффиксы).
> Как только встретилось новое слово — тут же предложить пользователю анализ этого слова и ввод атрибутов.
— … А это было в моей курсовой 2001 года «автоматический переводчик с английского на литовский»; пока я решил оставить этот модуль «на потом» — помю что он сожрал неожиданно много проектного времени (так что сам переводчик в срок закончить не удалось).
> то люди бы повнимательнее посмотрели на Ваш продукт
— Я уверен, что в мире постоянно появляется огромное количество более достойных программ, которым почему-то уделяется недостаточное (тем более по мнению создателей) внимане; как не стараются их авторы и что они только не предпринимают.
{ TranslateMessage(&msg); DispatchMessage(&msg); } я вроде «был отключивши», ибо такой код делал возможным закрыть программу во время распознания, и она ломалась, потому что при закрытии clean-up запускался неуведомив ядро.
> Немного поигрался со словарём и фразой…
— Несовершенство шаблона в Вашей версии программы: попробуйте разобраться как работает шаблон, затем попробуйте модифицировать его так, чтобы то предложение подпадало под него; а затем самое сложное: попробовать другие примеры предложений и разъяснить программе, которые из них не подходят под это новое правило, и почему.
… Так, постепенно доходит и проясняется: второй вариант есть простейшая конструкция «сказуемое (Передать) + дополнение (другой текст комп...)», а Вы хотите, чтоб был распознан вариант «сказуемое (Передать) + дополнение (что?-текст) + что-то еще от сказуемого (кому? чему?-компьютерной программе)» — в таком случае придется описать программе разницу, с какими глаголами и после каких дополнений можно ставить вот это вот "что-то еще от сказуемого", и что может быть в его роли. Чтобы не появлялись варианты типа «вижу текст компьютерной программе».
— Тут уже предлагали много различных направлений; куда на этот раз?
> Не просто хранить атрибуты, но и разбивать слова на составные части — корень, суффикс, окончание? Вероятно, при некотором везении, можно существенно сжать словарь.
— А, это все было реализовано в предыдущих версиях для литовского языка. Только там без суффикса было: окончание (из шаблона склонения), приставки («не» для прилагательных и куча для глаголов) и основная часть (корень + возможные суффиксы).
> Как только встретилось новое слово — тут же предложить пользователю анализ этого слова и ввод атрибутов.
— … А это было в моей курсовой 2001 года «автоматический переводчик с английского на литовский»; пока я решил оставить этот модуль «на потом» — помю что он сожрал неожиданно много проектного времени (так что сам переводчик в срок закончить не удалось).
> то люди бы повнимательнее посмотрели на Ваш продукт
— Я уверен, что в мире постоянно появляется огромное количество более достойных программ, которым почему-то уделяется недостаточное (тем более по мнению создателей) внимане; как не стараются их авторы и что они только не предпринимают.
{ TranslateMessage(&msg); DispatchMessage(&msg); } я вроде «был отключивши», ибо такой код делал возможным закрыть программу во время распознания, и она ломалась, потому что при закрытии clean-up запускался неуведомив ядро.
> Немного поигрался со словарём и фразой…
— Несовершенство шаблона в Вашей версии программы: попробуйте разобраться как работает шаблон, затем попробуйте модифицировать его так, чтобы то предложение подпадало под него; а затем самое сложное: попробовать другие примеры предложений и разъяснить программе, которые из них не подходят под это новое правило, и почему.
… Так, постепенно доходит и проясняется: второй вариант есть простейшая конструкция «сказуемое (Передать) + дополнение (другой текст комп...)», а Вы хотите, чтоб был распознан вариант «сказуемое (Передать) + дополнение (что?-текст) + что-то еще от сказуемого (кому? чему?-компьютерной программе)» — в таком случае придется описать программе разницу, с какими глаголами и после каких дополнений можно ставить вот это вот "что-то еще от сказуемого", и что может быть в его роли. Чтобы не появлялись варианты типа «вижу текст компьютерной программе».
А, это все было реализовано в предыдущих версиях для литовского языка. Только там без суффикса было: окончание (из шаблона склонения), приставки («не» для прилагательных и куча для глаголов) и основная часть (корень + возможные суффиксы).
Продолжаете ли развивать литовскую версию и почему в русской версии отказались от разбиения?
{ TranslateMessage(&msg); DispatchMessage(&msg); } я вроде «был отключивши», ибо такой код делал возможным закрыть программу во время распознания, и она ломалась, потому что при закрытии clean-up запускался неуведомив ядро.
Такая проблема решается довольно просто. Анализируете сообщение и в случае WM_CLOSE корректно завершаете программу. Как вариант, если это сообщение придёт где-то в глубине рекурсивного обхода дерева, можно бросить исключение и перехватить его в удобном месте.
Спасибо за дельные советы.
> Продолжаете ли развивать литовскую версию
— Нет, не вижу смысла. После ее выкладывания пришло только одно письмо (через год после «презентации») от секретарши какой-то фирмы: «мы готовы купить вашу программу, если она будет дешевле чем у конкурентов» — то есть за 30 евро, и то после того как она будет доведена до ума — а я не представляю, сколько лет на это понадобится потратить.
Надо бы ее сделать более открытой, как русскую; тогда стала бы видна краткая запись словаря; но все руки не доходят (находятся «более важные» дела).
> и почему в русской версии отказались от разбиения?
— Чтобы не возится с ним — ради экономии времени; чтобы поскорей представить программу интересующимся. Все равно, думаю, многие будут сравнивать ее с лучшими спеллчекерами, а она не может с ними равняться — ни по скорости, ни по полноте словаря, ни по эффективности его сжатия/оптимизации.
Мне бы английскую версию закончить (уж очень интересно, почему у моей программки (до презентации сдесь) треть скачиваний приходилось на Испанию); и начать бы следующую версию, в которой (я надеюсь) не будет «жесткости» теперешней версии.
> Продолжаете ли развивать литовскую версию
— Нет, не вижу смысла. После ее выкладывания пришло только одно письмо (через год после «презентации») от секретарши какой-то фирмы: «мы готовы купить вашу программу, если она будет дешевле чем у конкурентов» — то есть за 30 евро, и то после того как она будет доведена до ума — а я не представляю, сколько лет на это понадобится потратить.
Надо бы ее сделать более открытой, как русскую; тогда стала бы видна краткая запись словаря; но все руки не доходят (находятся «более важные» дела).
> и почему в русской версии отказались от разбиения?
— Чтобы не возится с ним — ради экономии времени; чтобы поскорей представить программу интересующимся. Все равно, думаю, многие будут сравнивать ее с лучшими спеллчекерами, а она не может с ними равняться — ни по скорости, ни по полноте словаря, ни по эффективности его сжатия/оптимизации.
Мне бы английскую версию закончить (уж очень интересно, почему у моей программки (до презентации сдесь) треть скачиваний приходилось на Испанию); и начать бы следующую версию, в которой (я надеюсь) не будет «жесткости» теперешней версии.
Пожалуйста, добавьте в пост ссылку на исходники. Если не жалко. Спасибо.
Уважаемий Либерман Лидер-ман, Вы знаете — почему-то жалко. Ну, как бы это объяснить, чтоб не выглядеть негодяем: я думаю редко люди раздают то, на что потратили года 4 жизни; например заработанную за 4 года зарплату, а?
Дамы и господа,партизаны и партизанки, товарисчи и комрады. Программа не может работать полноценно. Для этого ей не хватает мощности шаблона и словаря. Поэтому делать ее библиотечной (чтоб ею пользовались другие программы) я не вижу смысла.
Выкладывать исходники… я бы пока этого не хотел; а Вы не могли бы мне объяснить, дремучему, а зачем могут быть нужны исходники этой программы?
Дамы и господа,
Выкладывать исходники… я бы пока этого не хотел; а Вы не могли бы мне объяснить, дремучему, а зачем могут быть нужны исходники этой программы?
Вас никто, конечно, не должен считать негодяем, и со своим кодом Вы имеете полное право делать все, что угодно.
Но постараюсь разъяснить все же немного позицию противоположную: если человек отдал зарплату за 4 года, то у него больше нет зарплаты за 4 года. Если человек открыл исходники, то у него исходники остались и он может продолжать делать с ними все, что угодно. Кроме того, появляются дополнительные плюсы: при условии достаточного качества этих исходников и их полезности/интересности (в постиндустриальный век имеется тенденция к тому, что писателей больше, чем читателей — впрочем, в IT пока это особых проблем не создает) можно просто так получить помощь в разработке, проверку в различных условиях, выявление скрытых багов. Пополнение словаря и шаблонов, в конце концов, чтоб мощности хватало.
Это все не говоря о пользе для человечества) Надоест Вам делать эту программу, останется только на 80% работающий экзешник, демка, которая никому не нужна, разве что поставить раз, сказать «вах», закрыть и больше не запускать никогда, сколько проектов так умерло — а при открытом с самого начала коде с либеральной лицензией может и пригодится кому-нибудь, может что-то из этого вырастет, и не одно.
Исходники — понятно, чтоб рассмотреть возможность их модификации для использования как библиотеки. Или чтоб посмотреть алгоритмы, или как внутри устроено. Интересно, полезно для самообразования.
У меня отец — доктор наук, и мы с ним иногда это обсуждаем — почему в научном мире все так секретничают, закрывают результаты или открывают их лишь формально, почему часто так сложно получить доступ к разработкам ученых (втч состоящих на гос. службе), почему часто делают полурабочий прототип, который в чем-то может и крут, но практически непригоден, и потом до нормального состояние ничего так и не доводят (помечтали, что-то сделали, отчитались — пошли дальше), и т.д., при том, что у айтишников принято код открывать под лицензией «делайте с ним, что хотите», знаниями делиться, выкладывать все в общий доступ, стараться привлечь к разработке как можно больше людей.
Вы, конечно, имеете полное моральное право делать со своим кодом все, что угодно, ничего плохого в этом нет, просто стараюсь другую позицию прояснить.
Наверное, тут еще такая штука — тут много программистов и люди от поста из хабре ожидали узнать что-то полезное, а увидели описание демки, от которой им ни тепло, ни холодно.
Но постараюсь разъяснить все же немного позицию противоположную: если человек отдал зарплату за 4 года, то у него больше нет зарплаты за 4 года. Если человек открыл исходники, то у него исходники остались и он может продолжать делать с ними все, что угодно. Кроме того, появляются дополнительные плюсы: при условии достаточного качества этих исходников и их полезности/интересности (в постиндустриальный век имеется тенденция к тому, что писателей больше, чем читателей — впрочем, в IT пока это особых проблем не создает) можно просто так получить помощь в разработке, проверку в различных условиях, выявление скрытых багов. Пополнение словаря и шаблонов, в конце концов, чтоб мощности хватало.
Это все не говоря о пользе для человечества) Надоест Вам делать эту программу, останется только на 80% работающий экзешник, демка, которая никому не нужна, разве что поставить раз, сказать «вах», закрыть и больше не запускать никогда, сколько проектов так умерло — а при открытом с самого начала коде с либеральной лицензией может и пригодится кому-нибудь, может что-то из этого вырастет, и не одно.
Исходники — понятно, чтоб рассмотреть возможность их модификации для использования как библиотеки. Или чтоб посмотреть алгоритмы, или как внутри устроено. Интересно, полезно для самообразования.
У меня отец — доктор наук, и мы с ним иногда это обсуждаем — почему в научном мире все так секретничают, закрывают результаты или открывают их лишь формально, почему часто так сложно получить доступ к разработкам ученых (втч состоящих на гос. службе), почему часто делают полурабочий прототип, который в чем-то может и крут, но практически непригоден, и потом до нормального состояние ничего так и не доводят (помечтали, что-то сделали, отчитались — пошли дальше), и т.д., при том, что у айтишников принято код открывать под лицензией «делайте с ним, что хотите», знаниями делиться, выкладывать все в общий доступ, стараться привлечь к разработке как можно больше людей.
Вы, конечно, имеете полное моральное право делать со своим кодом все, что угодно, ничего плохого в этом нет, просто стараюсь другую позицию прояснить.
Наверное, тут еще такая штука — тут много программистов и люди от поста из хабре ожидали узнать что-то полезное, а увидели описание демки, от которой им ни тепло, ни холодно.
> можно просто так получить помощь в разработке, проверку в различных условиях, выявление скрытых багов. Пополнение словаря и шаблонов, в конце концов, чтоб мощности хватало.
— Ок, для этого имхо идеально подходит выложенная (бесплатная) программка; а код для чего выкладывать?
На мой взгляд точка зрения зависит от человека и от его позиции…
Есть программеры, которые пишут что-то в свое свободное время: одни из них за деньги, другие бесплатно и еще и код выкладывают.
У программесть бывают пользователи (программеры и не обязательно): естествено, они хотят получить чем получше и бесплатно; думаю, у пользователей и у разработчиков скорей всего бывает разное мнение об одной и той же программе, разная точка зрения на то как оно работает и как оно должно работать. :)
… Имхо для абстрактного человека больше вероятность, что он будет «за» свободный код, если этот человек доктор наук, да уже и с сыном, да еще и со взрослым и зарабатывающим; а если этот человек — нищий программер на съемной квартире и без перспектив (семьи, недвижимости и более лучшей жизни), то идея «пописать еще» в свободное время «на благо всего человечества» думаю будет не так близка его сердцу, как для состоявшегося доктора наук. С уважением.
— Ок, для этого имхо идеально подходит выложенная (бесплатная) программка; а код для чего выкладывать?
На мой взгляд точка зрения зависит от человека и от его позиции…
Есть программеры, которые пишут что-то в свое свободное время: одни из них за деньги, другие бесплатно и еще и код выкладывают.
У программ
… Имхо для абстрактного человека больше вероятность, что он будет «за» свободный код, если этот человек доктор наук, да уже и с сыном, да еще и со взрослым и зарабатывающим; а если этот человек — нищий программер на съемной квартире и без перспектив (семьи, недвижимости и более лучшей жизни), то идея «пописать еще» в свободное время «на благо всего человечества» думаю будет не так близка его сердцу, как для состоявшегося доктора наук. С уважением.
Вы почему-то считаете, что выкладывать код в open-source программисту невыгодно, что это какой-то акт самопожертвования) Это выгодно и интересно. У меня после того, как стал выкладывать код в open source, з/п выросла раз в 10, HR'ы интересуются постоянно (например, на прошлой неделе в фейсбук звали поговорить, и так и написали, что их заинтересовал мой крайне небольшой вклад в python-фреймворк tornado; постоянно предложения разные идут), и причинно-следственная связь тут прямая: код — это резюме + тебя уже более-менее знают, если твоим кодом пользуются, это стабильность и уверенность. Эти очевидные плюсы для разработчика — помимо того, что это все интересно, полезно для саморазвития (т.к. учишься смотреть вокруг и слушать других людей), полезно для окружающих, всего человечества, да и просто приятно. Если код пишешь для какой-то фирмы, то и для фирмы тоже полезно в open-source выкладывать разные штуки, т.к. со своими open-source проектами проще найти разработчиков (часть людей с частью кодовой базы уже знакомы, отношение к компании тоже лучше) + есть помощь от коммьюнити.
Конечно, ситуации разные бывают, и я больше варюсь в веб-разработке, где конечные продукты тиражируемы слабы, и в open source выкладываются штуки от программистов для программистов, но все же для хорошего провинциального неустроенного программиста я вижу больше предпосылок увлечься open source, чем для устроенного в жизни московича (при прочих равных), хотя, конечно, от человека зависит, и от ситуации, + если это не интересно делать просто так, то смысла ровно 0 этим заниматься.
Конечно, ситуации разные бывают, и я больше варюсь в веб-разработке, где конечные продукты тиражируемы слабы, и в open source выкладываются штуки от программистов для программистов, но все же для хорошего провинциального неустроенного программиста я вижу больше предпосылок увлечься open source, чем для устроенного в жизни московича (при прочих равных), хотя, конечно, от человека зависит, и от ситуации, + если это не интересно делать просто так, то смысла ровно 0 этим заниматься.
Sign up to leave a comment.
Программа проверки грамматики