Предисловие
В этой статье я хотел рассказать о своем опыте построения отказоустойчивого Web-сервиса. Я разрабатывал внутреннюю систему управления предприятием на PHP+MySQL (корпоративный портал), и, так как почти вся жизнь предприятия зависит от работоспособности этой системы, вопросы отказоустойчивости приобретают большое значение. Вместе с тем предприятие небольшое, соответственно, позволить себе дорогое железо и технологии оно не может, да и простой системы в несколько часов для него тоже не смертелен. Поэтому я старался решить эту задачу с минимальными денежными вложениями и обходясь своими силами и небольшими знаниями в области администрирования.
Сразу хочу сказать, что специалистам, работающим с Heartbeat, DRBD, OCFS2, MySQL Cluster эта статья явно не будет интересна. Но если вы новичок в этом, деньги есть только на пару системников, а надежную систему построить хочется, то… читайте, что у меня получилось.
Задача
Поняв, что построить классическую отказоустойчивую систему, в которой при выходе из строя одного из серверов, работа автоматически переключается на рабочий сервер я пока не смогу, я поставил для себя следующую задачу. Построить систему из двух серверов, в которой один работает как Главный, а второй, как Подчиненный, при выходе из строя Главного сервера, системный администратор предприятия вручную переключает сетевые кабели на подчиненный и работа продолжается. Дальше можно не спеша восстановить работоспособность Главного и вернуть систему к штатному режиму функционирования без особого простоя. Такое вполне удовлетворяло требованиям заказчика.
Общая схема решения
Итак, для создания своей системы я приобрел 2 недорогих системных блока (общая стоимость составила немного больше 30 т. руб.) следующей конфигурации:
- Мат. плата Socket775 ASUS «P5Q-VM DO»
- Процессор Intel «Core 2 Duo E8400»
- ОЗУ DIMM DDR2 (6400) 2048Mb х 2
- Жесткий диск 320Gb WD SATA-II 7200rpm 16Mb, Raid Edition
- В главный сервер поставил 1 дополнительную сетевую карту, а в подчиненный – 2. Сетевые карты Intel Corporation 82541PI Gigabit Ethernet Controller.
Получился Главный сервер с 2-мя сетевыми интерфейсами и Подчиненный сервер с 3-мя сетевыми интерфейсами.
В качестве платформы, на которой работает корпоративный портал, я использую LAMP на базе Ubuntu Linux 8.04.4, которая работает в виде виртуальной машины VMWare. На самом деле я не большой специалист по настройке LAMP, поэтому доверяюсь профессионалам, и за основу беру готовую виртуальную машину 1С-Битрикс (http://www.1c-bitrix.ru/products/vmbitrix/).
Для того, чтобы запускать виртуальную машину на серверах, я остановился на варианте с установкой бесплатного гипервизора VMware vSphere HypervisorTM (ESXi) v. 4.1 на голое железо (bare metal), который и установил первым делом на оба сервера. Данный гипервизор представляет собой мини-операционную систему, функции которой сводятся к тому, что управлять виртуальными машинами. Установка прошла без проблем, однако, как я выяснил впоследствии, все-таки железо оказалось не совсем совместимо с ESXi. Хотя я проверял на этот предмет все комплектующие в найденных мной в Интернете white-листах (http://www.vm-help.com/esx40i/esx40_whitebox_HCL.php и http://ultimatewhitebox.com). Несовместимость выразилась в том, что ESXi не выводил полный спектр диагностической информации о состоянии серверного железа. Вроде не принципиально, но все-таки не очень хорошо.
Затем скопировал на оба сервера идентичные настроенные виртуальные машины с LAMP и своим корпоративным порталом. Затем настроил в ESXi сетевые интерфейсы. На Главном сервере (всего 2 LAN-интерфейса): 1 сетевой интерфейс настроил для доступа к ESXi и оба «привязал» к виртуальной машине. А на Подчиненном (всего 3 LAN-интерфейса): 1 интерфейс – для доступа к ESXi, а 2 других «привязал» к виртуальной машине.
Кабелем напрямую подключил оба сервера через сетевые интерфейсы, привязанные к виртуальным машинам. В виртуальных машинах назначил этим сетевым интерфейсам IP адреса (10.10.10.2 – для Главного и 10.10.10.3 – для Подчиненного) из подсети, отличной от сети LAN заказчика (172.20.15.0-255). Данное прямое соединение между серверами предназначено исключительно для «общения» виртуальных машин двух серверов между собой, а именно для репликации данных MySQL и синхронизации папок со скриптами.
Главный сервер через его второй интерфейс подключил в локальную сеть предприятия. Подчиненный сервер через интерфейс для работы с ESXi также подключил в локальную сеть, а третий его интерфейс, предназначенный для работы виртуальной машины, оставил не подключенным – в штатном режиме он не используется.
На Главном и Подчиненным серверах в виртуальных машинах назначил одинаковый IP для второго интерфейса, который «видит» виртуальная машина. В штатном режиме сетевой кабель подключен к этому интерфейсу на Главном сервере, а при его выходе из строя необходимо этот кабель переключить в соответствующий интерфейс Подчиненного сервера. Т.к. IP там задан одинаковый, никакие больше настройки не потребуются, и работа может быть продолжена.
Таким образом, получились следующие схемы работы системы в штатном режиме и при выходе из строя Главного сервера:
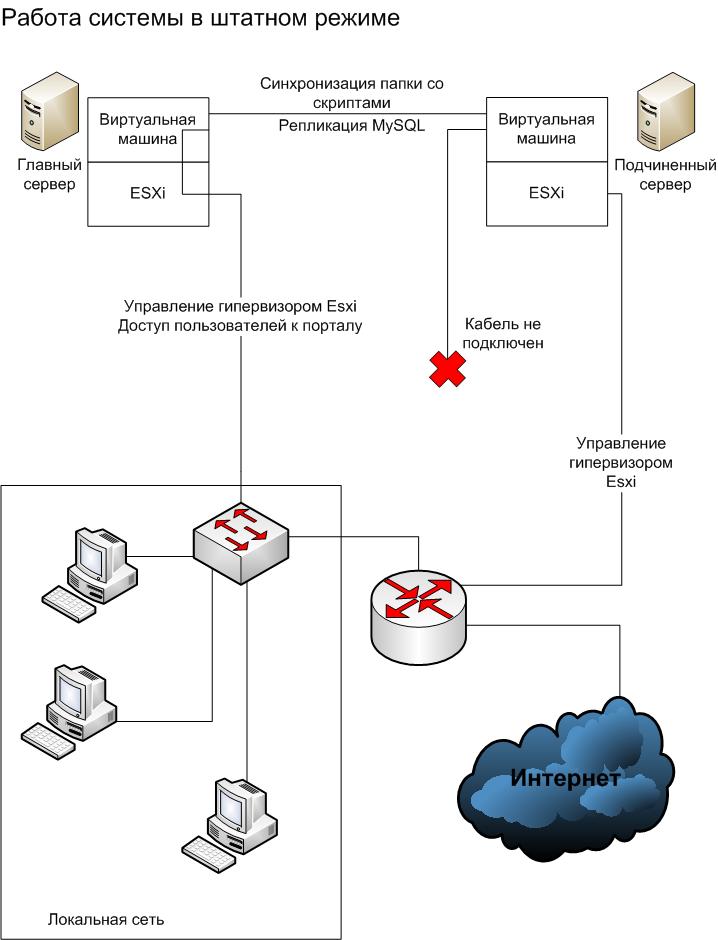

Теперь немного о нюансах.
Настроил стандартную репликацию в MySQL между Главным (сделал его мастером) и Подчиненным (сделал его рабом) серверами по кабелю, соединяющему сервера друг с другом. На эту тему есть много хороших материалов, описывать смысла не вижу. Хочу остановиться на некоторых моментах, которые, на мой взгляд, могут быть интересны.
Отслеживание состояния репликации MySQL.
При работе хотелось иметь возможность легко видеть, не прервалась ли репликация. Каждый раз заходить на подчиненный север через консоль в ESXi или через Главный сервер утомительно. Для решения этой задачи на подчиненный сервер я скопировал скрипт на PHP (checkslave.php), основная функция которого сводится к тому, чтобы получать статус репликации у МАСТЕРа и у РАБа и выводить их в виде таблицы. Главный сервер не может опрашивать подчиненный, т.к. в MySQL у него на это нет прав, права есть у подчиненного на доступ к главному, но не наоборот. Статус получается при выполнении команд:
SHOW SLAVE STATUSи
SHOW MASTER STATUSТ.к. пользователи имеют доступ только к Главному, на нем я в cron добавил команду:
wget --no-check-certificate 10.10.10.3/checkslave.php -O /var/www/checkslave.html, которая запрашивает с Подчиненного сервера checkslave.php и сохраняет его вывод в html-файл на Главном сервере. Соответственно можно смотреть на главном сервере в браузере этот файл и видеть, не ли проблем с репликацией.Защита от разрыва репликации.
По мере работы столкнулся с тем, что репликация легко разрывалась при любом SQL-запросе на изменение, запущенном на подчиненном сервере. Это сразу приводило к созданию дублей в уникальный ключах и вообще к несогласованности данных. Достаточно было войти корпоративный портал на нем и репликация прерывалась. Чтобы сделать репликацию более надежной я добавил следующее. На подчиненном сервере я добавил два PHP-скрипта: один давал права на изменения пользователю MySQL, под которым работают скрипты корпоративного портала, а второй отнимал эти права с помощью команд SQL
GRANT и REVOKE. Сами скрипты управления подключаются к MySQL под другим пользователем, под тем же, что работают скрипты опроса статуса МАСТЕРа и РАБа. Затем я написал маленький скрипт, который проверяет, есть ли связь у Подчиненного сервера с Главным и соответственно запускает скрипт открытия/закрытия базы данных Подчиненного сервера на изменения. Скрипт запускается по расписанию каждые 5 минут. Соответственно через 5 минут после разрыва связи пользователи смогут работать с подчиненным сервером, а если связь не была разорвана, то подчиненный сервер будет оставаться закрытым от изменений:
#!/bin/bash
count=$(ping -c 8 10.10.10.2 | grep 'received' | awk -F',' '{ print $2 }' | awk '{ print $1 }')
if [ $count -eq 0 ]; then
php -f /folder/slave_open.php
else
php -f /folder/slave_close.php
fi
Синхронизация скриптов.
Помимо синхронизации базы данных важно, чтобы PHP-скрипты и прочие рабочие файлы также менялись на подчиненном сервере при изменениях на Главном. Для решения этой задачи я на Подчиненном сервере по расписанию добавил команду:
rsync -avz 10.10.10.2:/var/www/ /var/wwwРабота корпоративного портала с файлами.
Помимо PHP-скриптов корпоративный портал управляет файлами пользователей, которые также должны быть доступны и на Главном и на Подчиненном серверах. Чтобы сделать это возможным я вынес хранение этих файлов на отдельный файловый сервер предприятия под управлением Windows Server 2008. Там завел отдельную папку, написал скрипт, который на обеих виртуальных машинах проверяет, есть ли эта папка в примонтированных дисках, и если нет, монтирует ее.
flag=0
mnt_path='/folder'
mnt_test=`mount -t cifs`
flag=`expr match "$mnt_test" '.*folder.*'`
if [ "$flag" = "0" ]
then mount -t cifs -o username=user,password=pass,uid=bitrix,gid=bitrix,iocharset=utf8,codepage=866 //172.20.15.21/portal_folder /folder
fi
Далее все PHP-скрипты сохраняют файлы пользователей по определенной системе в этой примонтированной папке. Если работа переключается на подчиненный сервер, он сразу тоже монтирует эту папку себе, когда в него включают сетевой кабель и все продолжают работать. А если даже оба сервера выйдут из строя, можно будет напрямую воспользоваться файлами на файловом сервере.
