Предположим, у вас есть большое приложение написанное на Java. Это может быть web-сервлет размещенный в контейнере или standalone-сервис. В процессе разработки (да и во время эксплуатации) возникает необходимость отслеживать процессы, протекающие в JVM: работу garbage collector, использование памяти, жизненный цикл потоков, а так же иные специфичные для вашего проекта показатели посредством MBean. Самый простой вариант — использовать профилировщик. Но увы, проблемы не случаются по расписанию, и невозможно заранее знать, когда нужно подключить профилировщик, а держать его постоянно включенным тоже не вариант. В таких случаях идеальное решение — непрерывный мониторинг. О нем и пойдет речь. Но для начала пара слов о классической профилировке.
Пожалуй, самый простой и доступный метод мониторинга приложения. Профилировщики позволяют в реальном времени наблюдать за состоянием JVM, детально анализировать статистики ее работы, вплоть до анализа деятельности отдельно взятых потоков. На рынке существуют как бесплатные, так и платные решения:
У профайлеров есть один существенный недостаток — вы не можете держать его открытым 24 часа в сутки 7 дней в неделю. Он просто не предназначен для этого. Зачем нужен такой мониторинг? Затем, что вы никогда не знаете, когда у вашего приложения возникнут проблемы. Непрерывный мониторинг позволяет производить сводный анализ статистик за день, сутки, месяц, строить начальные предположения о причинах некорректной работы сервиса/приложения, базируясь на графиках использования памяти, потоков и прочих метриках. К примеру, на ночь вы запускаете QA-тесты, а утром анализируете поведение сервиса основываясь на непрерывном мониторинге.
Готовых систем приемлемого сочетания цены и качества я не находил, поэтому, имея богатый опыт работы с Zabbix решил приспособить его под свои нужды (для тех, кто знаком с Zapcat — пара слов о нем будет в конце статьи). Вы сразу можете спросить: “почему Zabbix, а не Nagios?”. Я люблю готовые продукты, работающие из коробки и не требующие ручной доводки и стыковки модулей.
Итак, приступим к серверной кулинарии ;-)! Для приготовления блюда “Непрерывный мониторинг JMX средствами Zabbix” нам понадобится:
Напомню, что все действия выполняются на свежеустановленной OS.
Если у вас уже имеется настроенный Zabbix-сервер с подключенными для мониторинга клиентскими машинами, то можете сразу перейти к следующему пункту.
Zabbix сервер и агент можно поставить как из репозитория, так и собрать из исходников. Обычно в репозиториях находятся очень старые версии zabbix, для тестов сгодятся и они, но для повседневного использования я рекомендую что-нибудь поновее. Итак, ставим из репозитория:
После установки зайдите на localhost/zabbix Входим под пользователем Admin с паролем zabbix. Идем во вкладку «Configuration -> Hosts» и кликаем по «Zabbix Server». Меняем статус с “Not monitored” на “Monitored”. Далее открываем в редакторе файл /etc/zabbix/zabbix_agentd.conf и заменяем его содержимое на предложенное:
В Zabbix UI переходим в «Monitoring -> Last Data» и проверяем, что с локальной машины начали собираться данные. На этом базовая настройка Zabbix завершена, переходим к препарированию JMX.
В качестве экспериментальной JVM будем использовать tomcat. Для того, чтобы не производить подключения к нему по RMI протоколу, а использовать HTTP, воспользуемся JMX-HTTP бриджом Jolokia. Для tomcat на официальном сайте доступена war-сборка. Переименовываем скаченный war-файл в jolokia.war и кладем в /var/lib/tomcat6/webapps. Перезапускаем tomcat. Открываем адрес localhost:8080/jolokia и, если все сделали правильно, видим следующую информацию:
Если у вас standalone-приложение то для подключения к нему jolokia следует добавить в строку запуска следующий параметр:
где $LIBDIR/jolokia-agent.jar — путь до Jolokia JVM-Agent
Сейчас у нас есть Zabbix и JVM с подключенным к ней JMX-HTTP бриджом. Нужно организовать сбор данных. Схема сбора данных будет выглядеть следующим образом:

Объясню, почему я не собираю метрики напрямую, а пользуюсь промежуточным буфером. Если настраивать схему без него, то на каждый запрос будет запускаться скрипт сбора JMX-статистики, что является более ресурсоемкой операцией, чем чтение из буфера. Поэтому я выбрал модель, в которой раз в N секунд собираются все метрики, размещаются по файлам, а затем считываются из файлов по мере необходимости.
Для сбора данных, мы будем использовать готовую библиотеку работы с JMX-HTTP бриджом. Библиотека написана на Perl и устанавливается средствами CPAN:
После успешной установки попробуем получить первые метрики с tomcat при помощи jmx4perl:
результат работы команды должен выглядеть примерно так:
Как вы можете догадаться, мы только что получили информацию об использовании Heap-памяти JVM Tomcat.
Теперь следует написать скрипт для сбора метрик, с последующим размещением их в файлы указанного каталога. Можете написать свой или воспользоваться моим примером:
Размещаем скрипт в /usr/local/sbin и называем jmx_grabber. Есть вероятность, что скрипт не заработает. Это связано с первыми четырьмя метриками: GC_COPY_COLLECTION_COUNT, GC_MARK_SWEEP_COLLECTION_COUNT, GC_COPY_COLLECTION_TIME, GC_MARK_SWEEP_COLLECTION_TIME. Метрики отображают ни что иное, как статистику «сборщика мусора» (GC). Названия сборщиков мусора, используемых в конкретной реализации JVM могут отличаться. Для JVM HotSpot я встречал две пары: PS Scavenge + PS MarkSweep и ConcurrentMarkSweep + Copy. Если у вас возникли сложности с определением имени вашего GC, то выполните команду
а затем поищите по ключевому слову «GarbageCollector». Вы найдете что-то наподобие:
Значение «java.lang:name» и является названием одного из «сборщиков мусора».
Теперь напишем сценарий на bash для получения данных из файлов:
Для работы написанных скриптов нам понадобятся следующие Perl библиотеки: File::Path, Module::Find, JSON, Error. Устанавливаем их:
Проверим, все ли сделано правильно. Вызовим скрипт со следующими параметрами:
Нам должна вернутся строка «Java HotSpot(TM) Client VM». Теперь создадим папку /var/jmx и вызовем скрипт с другими параметрами:
Проверим содержимое папки /var/jmx. В ней должен появится подкаталог 8080, содержащий файлы с метриками JVM, по одному файлу на каждую метрику. Не трудно догадаться, что 8080 — это локальный порт, который прослушивает либо jolokia-агент (standalone установка), либо tomcat с контейнером jolokia.
Настроив сбор и считывание метрик перейдем к процессу выгрузки их в Zabbix.
Добавим две строчки в файл /etc/zabbix/zabbix_agentd.conf:
После этого не забудьте перезапустить zabbix-агент. Добавленные строки позволяют обращаться к скриптам файловой системы как к обычным метрикам Zabbix. Существует и альтернативный путь: можно воспользоваться zabbix trapper, и отправлять статистику в активном режиме не использую zabbix-агент. Больших отличий нет. В случае использования Zabbix-agent периоды сбора данных выставляются в Zabbix через UI. В случае использования trapper вам придется раскидывать cron-сценарии отправки метрик через puppet (или его аналоги).
Теперь пришло вермя создания шаблонов. Не буду глубоко вдаваться в этот процесс и приложу готовый xml-файл шаблона, который нужно импортировать в Zabbix. Для этого откройте вкладку «Configuration -> Export/Import» (в последних версиях Zabbix импорт находится в «Configuration ->Templates » далее кнопка «Import Template») и выберите в списке «Import»:

Теперь нужно назначить добавленный шаблон на наш сервер. Зайдите во вкладку «Configuration -> Hosts» и кликните на «Zabbix Server». В панели «Linked templates» добавьте наш шаблон «Template_Multitenant_Tomcat_JMX_Toolkit». Нажмите на «Save», после чего перейдите в «Monitoring -> Last Data». Через секунд 20 вы получите первые статистические данные с JVM Tomcat. Если данные не приходят, проверьте, запущен ли zabbix-agent и правильно ли он сконфигурирован (см. выше). Через пол часика можете взглянуть на графики («Monitoring -> Graphs»), там вы увидите примерно следующее для «Tomcat JVM Memory»:
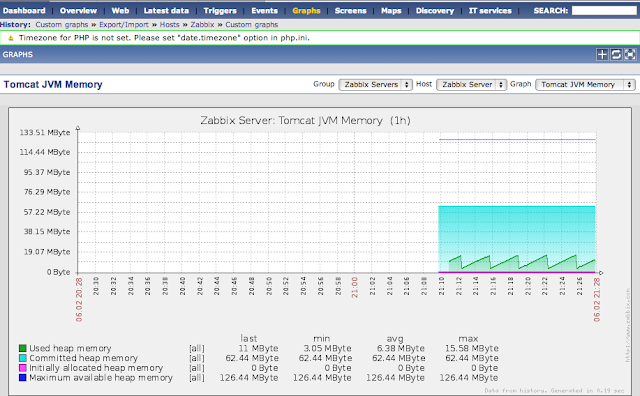
Скорее всего, у вас возникнет вопрос, а что делать, если на одной физической/виртуальной машине находятся несколько JVM? Ведь в шаблоне явно указан порт 8080. Да, это неприятная особенность, но чтобы добавить несколько JVM одной машины на мониторинг, нужно создавать отдельный шаблон под каждый порт jolokia, с которого будет осуществляться сбор данных.
Хорошо, у нас есть система сбора метрик с JVM Tomcat. Было бы здорово опробовать ее в действии. Для этих целей я написал небольшой сервис, создающий потоки, которые, в свою очередь, непрерывно порождают объекты в JVM вплоть до своей остановки. Внешне доступный интерфейс управления выглядит так:
Кнопки «Increase» и «Decrease» увеличивают и уменьшают число потоков, а Multiplier дает контроль за множителем интервала времени задержки потока перед генерацией следующего объекта. Сервис можно скачать здесь.
Разместим сервис в Tomcat, а затем произведем следующие манипуляции:
В результате мы получим следующие графики:
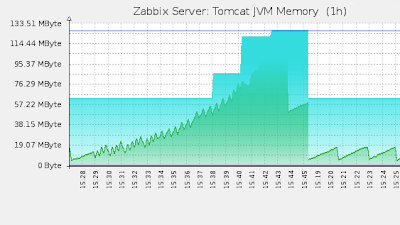
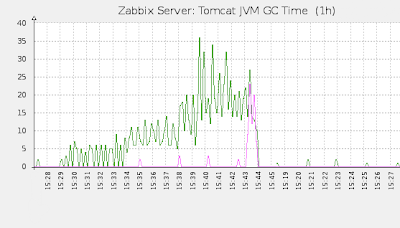
Когда я говорил, что не нашел приемлемых готовых решений, я немного слукавил. Одно решение существует — это Zapcat. И, кстати сказать, при помощи него скрестить tomcat и Zabbix не займет более 5 минут. Зачем же я изобретал велосипед? Причины здесь две:
Для того, чтобы решить, нужен ли вам описанный мной метод мониторинга, или вам будет достаточно zapcat, как простой в развертывании альтернативы, задайтесь следующими вопросами:
Предложенный мною вариант не столько готовая система мониторинга, сколько каркас для построения системы контроля жизнедеятельности сервиса исходя из конкретных задач и потребностей. В совокупности с умением Zabbix'а обнаруживать свои агенты и автоматически добавлять сетевые узлы на мониториг, задача контроля работы java-сервисов упрощается в разы.
Если у вас возникли трудности по настройке — пишите в личку или в комментариях, подскажу по мере возможности. Для тех, кто не хочет вручную настраивать тестовый стенд, предлагаю воспользоваться готовым образом для VirtualBox (логин red, пароль password).
Приятных экспериментов и стабильной работы JVM! ;-)
P.S.: отвечать на сообщения и комментарии смогу лишь в обед и по вечерам
Использование профилировщика
Пожалуй, самый простой и доступный метод мониторинга приложения. Профилировщики позволяют в реальном времени наблюдать за состоянием JVM, детально анализировать статистики ее работы, вплоть до анализа деятельности отдельно взятых потоков. На рынке существуют как бесплатные, так и платные решения:
- jconsole — утилита входящая в походный набор собирателей кофе “JDK Tools and Utils”. Дает доступ ко всем базовым статистикам JVM, включая прямую работу с MBeans.
- VisualVM — продвинутый аналоги jconsole. С некоторых пор (когда кто-то кого-то купил) тоже поставляется вместе с jdk. Про VisualVM и основы профилировки можете прочитать в этой статье. От себя лишь добавлю, что если у вас возникает необходимость подключить профилировщик к JVM на удаленном сервере, а заморачиваться не хочется, то просто найдите бинарник visualvm на нем, а затем вызовите его по ssh с трансляцией X-сессии:
ssh -X login@domain /usr/bin/jvisualvm
- JProfiler — лидер среди коммерческих профилировщиков (если у кого-то есть богатый опыт его применения — буду рад его перенять).
Непрерывный мониторинг
У профайлеров есть один существенный недостаток — вы не можете держать его открытым 24 часа в сутки 7 дней в неделю. Он просто не предназначен для этого. Зачем нужен такой мониторинг? Затем, что вы никогда не знаете, когда у вашего приложения возникнут проблемы. Непрерывный мониторинг позволяет производить сводный анализ статистик за день, сутки, месяц, строить начальные предположения о причинах некорректной работы сервиса/приложения, базируясь на графиках использования памяти, потоков и прочих метриках. К примеру, на ночь вы запускаете QA-тесты, а утром анализируете поведение сервиса основываясь на непрерывном мониторинге.
Готовых систем приемлемого сочетания цены и качества я не находил, поэтому, имея богатый опыт работы с Zabbix решил приспособить его под свои нужды (для тех, кто знаком с Zapcat — пара слов о нем будет в конце статьи). Вы сразу можете спросить: “почему Zabbix, а не Nagios?”. Я люблю готовые продукты, работающие из коробки и не требующие ручной доводки и стыковки модулей.
Итак, приступим к серверной кулинарии ;-)! Для приготовления блюда “Непрерывный мониторинг JMX средствами Zabbix” нам понадобится:
- Ubuntu Server 10.04 (в качестве заменителей можно использовать Debian и RedHat)
- PostgreSQL либо MySQL по вкусу
- Zabbix сервер
- Zabbix клиент
- Oracle Java (скрипты из данной статьи ориентированы на JVM HotSpot)
- Jolokia (JMX-HTTP бридж) — помогает избежать проблемы с настройкой JMX RMI подключений
Напомню, что все действия выполняются на свежеустановленной OS.
Быстрая настройка Zabbix
Если у вас уже имеется настроенный Zabbix-сервер с подключенными для мониторинга клиентскими машинами, то можете сразу перейти к следующему пункту.
Zabbix сервер и агент можно поставить как из репозитория, так и собрать из исходников. Обычно в репозиториях находятся очень старые версии zabbix, для тестов сгодятся и они, но для повседневного использования я рекомендую что-нибудь поновее. Итак, ставим из репозитория:
sudo apt-get install zabbix-agent zabbix-server-pgsql zabbix-frontend-php php5-pgsql tomcat6После установки зайдите на localhost/zabbix Входим под пользователем Admin с паролем zabbix. Идем во вкладку «Configuration -> Hosts» и кликаем по «Zabbix Server». Меняем статус с “Not monitored” на “Monitored”. Далее открываем в редакторе файл /etc/zabbix/zabbix_agentd.conf и заменяем его содержимое на предложенное:
Server=127.0.0.1
Hostname=redcraft
StartAgents=16
DisableActive=1
EnableRemoteCommands=1
DebugLevel=4
Timeout=30
PidFile=/var/run/zabbix-agent/zabbix_agentd.pid
LogFile=/var/log/zabbix-agent/zabbix_agentd.logВ Zabbix UI переходим в «Monitoring -> Last Data» и проверяем, что с локальной машины начали собираться данные. На этом базовая настройка Zabbix завершена, переходим к препарированию JMX.
Подключение JVM-агентов Jolokia
В качестве экспериментальной JVM будем использовать tomcat. Для того, чтобы не производить подключения к нему по RMI протоколу, а использовать HTTP, воспользуемся JMX-HTTP бриджом Jolokia. Для tomcat на официальном сайте доступена war-сборка. Переименовываем скаченный war-файл в jolokia.war и кладем в /var/lib/tomcat6/webapps. Перезапускаем tomcat. Открываем адрес localhost:8080/jolokia и, если все сделали правильно, видим следующую информацию:
{"timestamp":1328444565,"status":200,"request":{"type":"version"},"value":{"protocol":"6.1","agent":"1.0.2","info":{"product":"tomcat","vendor":"Apache","version":"6.0.24"}}}Если у вас standalone-приложение то для подключения к нему jolokia следует добавить в строку запуска следующий параметр:
-javaagent:$LIBDIR/jolokia-agent.jar=port=9090,host=localhostгде $LIBDIR/jolokia-agent.jar — путь до Jolokia JVM-Agent
Настройка сбора данных с Jolokia
Сейчас у нас есть Zabbix и JVM с подключенным к ней JMX-HTTP бриджом. Нужно организовать сбор данных. Схема сбора данных будет выглядеть следующим образом:
Объясню, почему я не собираю метрики напрямую, а пользуюсь промежуточным буфером. Если настраивать схему без него, то на каждый запрос будет запускаться скрипт сбора JMX-статистики, что является более ресурсоемкой операцией, чем чтение из буфера. Поэтому я выбрал модель, в которой раз в N секунд собираются все метрики, размещаются по файлам, а затем считываются из файлов по мере необходимости.
Для сбора данных, мы будем использовать готовую библиотеку работы с JMX-HTTP бриджом. Библиотека написана на Perl и устанавливается средствами CPAN:
sudo cpan -i JMX::Jmx4PerlПосле успешной установки попробуем получить первые метрики с tomcat при помощи jmx4perl:
jmx4perl localhost:8080/jolokia read java.lang:type=Memory HeapMemoryUsageрезультат работы команды должен выглядеть примерно так:
{
committed => 65470464,
init => 0,
max => 132579328,
used => 10264072
}Как вы можете догадаться, мы только что получили информацию об использовании Heap-памяти JVM Tomcat.
Теперь следует написать скрипт для сбора метрик, с последующим размещением их в файлы указанного каталога. Можете написать свой или воспользоваться моим примером:
#!/usr/bin/perl
use strict;
use warnings;
use Error qw( :try );
use JMX::Jmx4Perl;
use JMX::Jmx4Perl::Alias;
use File::Path qw(make_path remove_tree);
use Data::Dumper;
my %source = (
GC_COPY_COLLECTION_COUNT => ["java.lang:name=Copy,type=GarbageCollector", "CollectionCount"],
GC_MARK_SWEEP_COLLECTION_COUNT => ["java.lang:name=ConcurrentMarkSweep,type=GarbageCollector", "CollectionCount"],
GC_COPY_COLLECTION_TIME => ["java.lang:name=Copy,type=GarbageCollector", "CollectionTime"],
GC_MARK_SWEEP_COLLECTION_TIME => ["java.lang:name=ConcurrentMarkSweep,type=GarbageCollector", "CollectionTime"],
THREAD_COUNT => ["THREAD_COUNT"],
MEMORY_HEAP_COMITTED => ["MEMORY_HEAP_COMITTED"],
THREAD_COUNT_DAEMON => ["THREAD_COUNT_DAEMON"],
THREAD_COUNT_STARTED => ["THREAD_COUNT_STARTED"],
MEMORY_HEAP_INIT => ["MEMORY_HEAP_INIT"],
RUNTIME_VM_VENDOR => ["RUNTIME_VM_VENDOR"],
MEMORY_HEAP_MAX => ["MEMORY_HEAP_MAX"],
RUNTIME_VM_NAME => ["RUNTIME_VM_NAME"],
CL_TOTAL => ["CL_TOTAL"],
CL_LOADED => ["CL_LOADED"],
CL_UNLOADED => ["CL_UNLOADED"],
THREAD_COUNT_PEAK => ["THREAD_COUNT_PEAK"],
RUNTIME_UPTIME => ["RUNTIME_UPTIME"],
MEMORY_HEAP_USED => ["MEMORY_HEAP_USED"],
RUNTIME_VM_VERSION => ["RUNTIME_VM_VERSION"],
);
my $log_dir = "/var/jmx";
my $result = 0;
my $port = $ARGV[0];
my $cmd = $ARGV[1];
if(defined $cmd && defined $port) {
try {
my $jmx = JMX::Jmx4Perl->new(url => "http://localhost:$port/jolokia/");
if($cmd eq "DUMP") {
make_path("$log_dir/$port");
while(my($key, $value) = each %source) {
open FILE, ">$log_dir/$port/$key" or
throw Error::Simple("Could not open file");
print FILE $jmx->get_attribute(@$value) . "\n";
close FILE;
}
$result = 1;
}
else {
my $param = $source{$cmd};
$result = $jmx->get_attribute(@$param);
}
} catch Error with {
$result = 0;
# --- Uncomment for debug ---
#my $ex = shift;
#print $ex->{-text}."\n";
#print $ex->{-line}."\n";
# --- Debug block ended ---
};
}
else {
$result = 0;
}
print $result . "\n";
Размещаем скрипт в /usr/local/sbin и называем jmx_grabber. Есть вероятность, что скрипт не заработает. Это связано с первыми четырьмя метриками: GC_COPY_COLLECTION_COUNT, GC_MARK_SWEEP_COLLECTION_COUNT, GC_COPY_COLLECTION_TIME, GC_MARK_SWEEP_COLLECTION_TIME. Метрики отображают ни что иное, как статистику «сборщика мусора» (GC). Названия сборщиков мусора, используемых в конкретной реализации JVM могут отличаться. Для JVM HotSpot я встречал две пары: PS Scavenge + PS MarkSweep и ConcurrentMarkSweep + Copy. Если у вас возникли сложности с определением имени вашего GC, то выполните команду
jmx4perl localhost:8080/jolokia attributes | lessа затем поищите по ключевому слову «GarbageCollector». Вы найдете что-то наподобие:
java.lang:name=ConcurrentMarkSweep,type=GarbageCollector -- CollectionCount = 12
java.lang:name=ConcurrentMarkSweep,type=GarbageCollector -- LastGcInfo =
java.lang:name=ConcurrentMarkSweep,type=GarbageCollector -- CollectionTime = 0
java.lang:name=ConcurrentMarkSweep,type=GarbageCollector -- Name = ConcurrentMarkSweep
java.lang:name=ConcurrentMarkSweep,type=GarbageCollector -- Valid = [true]Значение «java.lang:name» и является названием одного из «сборщиков мусора».
Теперь напишем сценарий на bash для получения данных из файлов:
#!/bin/bash
JMX_DIR="/var/jmx"
if [ -r "$JMX_DIR/$1/$2" ]; then
cat "$JMX_DIR/$1/$2"
else
echo 0;
fi
Для работы написанных скриптов нам понадобятся следующие Perl библиотеки: File::Path, Module::Find, JSON, Error. Устанавливаем их:
sudo cpan -i File::Path
sudo cpan -i Module::Find
sudo cpan -i JSON
sudo cpan -i ErrorПроверим, все ли сделано правильно. Вызовим скрипт со следующими параметрами:
/usr/local/sbin/jmx-grabber 8080 RUNTIME_VM_NAMEНам должна вернутся строка «Java HotSpot(TM) Client VM». Теперь создадим папку /var/jmx и вызовем скрипт с другими параметрами:
/usr/local/sbin/jmx-grabber 8080 DUMPПроверим содержимое папки /var/jmx. В ней должен появится подкаталог 8080, содержащий файлы с метриками JVM, по одному файлу на каждую метрику. Не трудно догадаться, что 8080 — это локальный порт, который прослушивает либо jolokia-агент (standalone установка), либо tomcat с контейнером jolokia.
Настроив сбор и считывание метрик перейдем к процессу выгрузки их в Zabbix.
Выгрузка метрик JVM в Zabbix
Добавим две строчки в файл /etc/zabbix/zabbix_agentd.conf:
UserParameter=jmx_grabber[*],/usr/local/sbin/jmx-grabber $1 $2
UserParameter=jmx_reader[*],/usr/local/sbin/jmx-stats-reader $1 $2После этого не забудьте перезапустить zabbix-агент. Добавленные строки позволяют обращаться к скриптам файловой системы как к обычным метрикам Zabbix. Существует и альтернативный путь: можно воспользоваться zabbix trapper, и отправлять статистику в активном режиме не использую zabbix-агент. Больших отличий нет. В случае использования Zabbix-agent периоды сбора данных выставляются в Zabbix через UI. В случае использования trapper вам придется раскидывать cron-сценарии отправки метрик через puppet (или его аналоги).
Теперь пришло вермя создания шаблонов. Не буду глубоко вдаваться в этот процесс и приложу готовый xml-файл шаблона, который нужно импортировать в Zabbix. Для этого откройте вкладку «Configuration -> Export/Import» (в последних версиях Zabbix импорт находится в «Configuration ->Templates » далее кнопка «Import Template») и выберите в списке «Import»:
Теперь нужно назначить добавленный шаблон на наш сервер. Зайдите во вкладку «Configuration -> Hosts» и кликните на «Zabbix Server». В панели «Linked templates» добавьте наш шаблон «Template_Multitenant_Tomcat_JMX_Toolkit». Нажмите на «Save», после чего перейдите в «Monitoring -> Last Data». Через секунд 20 вы получите первые статистические данные с JVM Tomcat. Если данные не приходят, проверьте, запущен ли zabbix-agent и правильно ли он сконфигурирован (см. выше). Через пол часика можете взглянуть на графики («Monitoring -> Graphs»), там вы увидите примерно следующее для «Tomcat JVM Memory»:
Скорее всего, у вас возникнет вопрос, а что делать, если на одной физической/виртуальной машине находятся несколько JVM? Ведь в шаблоне явно указан порт 8080. Да, это неприятная особенность, но чтобы добавить несколько JVM одной машины на мониторинг, нужно создавать отдельный шаблон под каждый порт jolokia, с которого будет осуществляться сбор данных.
Проведение тестов
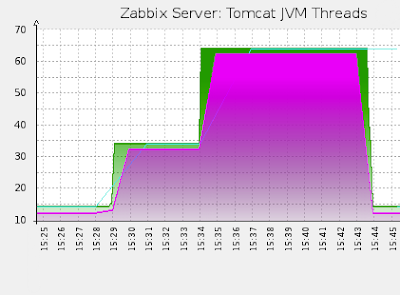
Хорошо, у нас есть система сбора метрик с JVM Tomcat. Было бы здорово опробовать ее в действии. Для этих целей я написал небольшой сервис, создающий потоки, которые, в свою очередь, непрерывно порождают объекты в JVM вплоть до своей остановки. Внешне доступный интерфейс управления выглядит так:
Кнопки «Increase» и «Decrease» увеличивают и уменьшают число потоков, а Multiplier дает контроль за множителем интервала времени задержки потока перед генерацией следующего объекта. Сервис можно скачать здесь.
Разместим сервис в Tomcat, а затем произведем следующие манипуляции:
- поднимем число потоков до 20 и подождем 5 минут
- поднимем число потоков до 50 и вновь подождем 5 минут
- уменьшим множитель задержки потока до 50 и ожидаем 5 минут
- сбрасываем число потоков до нуля
В результате мы получим следующие графики:
Zapcat
Когда я говорил, что не нашел приемлемых готовых решений, я немного слукавил. Одно решение существует — это Zapcat. И, кстати сказать, при помощи него скрестить tomcat и Zabbix не займет более 5 минут. Зачем же я изобретал велосипед? Причины здесь две:
- zapcat не обновляется с 2008 года. Не то что бы это совсе плохо — он до сих пор вполне сносно работал. Но использовать систему, которую никто не поддерживает, не очень хочется.
- к standalone сервисам zapcat агент подключатся непосредственно в коде приложения. Для меня это выглядит как если бы детям при рождении пришивали тонометр и прочие датчики, которые снять в дальнейшем можно было лишь через хирургическое вмешательство. Мне крайне не хотелось делать zapcat (который более не поддерживается) частью приложения. Это и не безопасно, и с точки зрения архитектуры — неграмотно. В теории, zapcat можно оформить в качестве javaagent, но готовых реализаций, которые можно подключить при помощи одноименной директивы, я не находил.
Для того, чтобы решить, нужен ли вам описанный мной метод мониторинга, или вам будет достаточно zapcat, как простой в развертывании альтернативы, задайтесь следующими вопросами:
- хочу ли я интегрировать в свое приложение средства мониторинга? (актуально лишь для standalone-сервисов)
- хочу ли я производить дополнительную обработку промежуточных данных, которые уже собраны в файловую систему (или в кеш). Возможно вы захотите вычислять средние суммарные показатели по всем копиям сервисов
- хочу ли я обращаться к сервису\приложению черз jmx-бридж при помощи иных инструментов, отличных от zabbix?
Напоследок
Предложенный мною вариант не столько готовая система мониторинга, сколько каркас для построения системы контроля жизнедеятельности сервиса исходя из конкретных задач и потребностей. В совокупности с умением Zabbix'а обнаруживать свои агенты и автоматически добавлять сетевые узлы на мониториг, задача контроля работы java-сервисов упрощается в разы.
Если у вас возникли трудности по настройке — пишите в личку или в комментариях, подскажу по мере возможности. Для тех, кто не хочет вручную настраивать тестовый стенд, предлагаю воспользоваться готовым образом для VirtualBox (логин red, пароль password).
Приятных экспериментов и стабильной работы JVM! ;-)
P.S.: отвечать на сообщения и комментарии смогу лишь в обед и по вечерам
