Comments 36
А можно результат склеивания в aff и dic форматах?
Насколько я понимаю это панацея для, исторически кривого, спелчеккера OSX!
Насколько я понимаю это панацея для, исторически кривого, спелчеккера OSX!
Скрин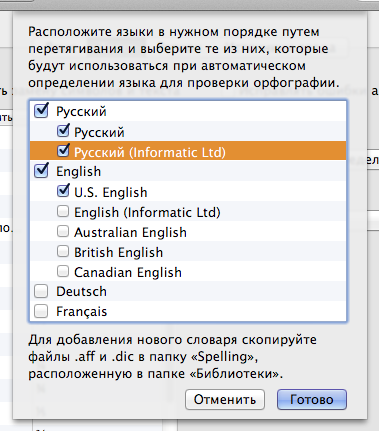

Результат склеивания нужен просто так для проверки или нужен для конкретных языков?
Дело в том, что если программа использующая Hunspell словари позволяет своими средствами проверять на нескольких языках одновременно, то утилита вовсе не требуется.
Дело в том, что если программа использующая Hunspell словари позволяет своими средствами проверять на нескольких языках одновременно, то утилита вовсе не требуется.
1. В osx оооочень кривой русский словарь, настолько, что в нем находили орфографические ошибки.
2. Штатный словарь очень маленький.
3. Мультиподдержка есть, но лучше-бы ее не было:

4. Прошу хороший смешанный словарь русско-английских слов.
5. Заодно потестить как один словарь работает для 2х языков в OSX.
2. Штатный словарь очень маленький.
3. Мультиподдержка есть, но лучше-бы ее не было:

4. Прошу хороший смешанный словарь русско-английских слов.
5. Заодно потестить как один словарь работает для 2х языков в OSX.
Слил 5 русских и 4 английских словаря, взятых из OpenOffice и Mozilla расширений, воедино.
Вот что вышло (*.aff и *.dic) в zip архиве.
sendfile.su/708140
Жду результата, у меня к сожалению проверить на MacOS пока нет.
Вот что вышло (*.aff и *.dic) в zip архиве.
sendfile.su/708140
Жду результата, у меня к сожалению проверить на MacOS пока нет.
По-моему — шикарно! Огромное спасибо.
Результат
Текст в Mail.app:

Тащим вверх и включаем только синтезированный словарь:
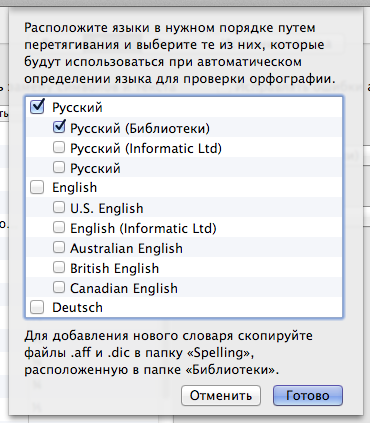
Убираем кривое автоопределение языков указав конкретный словарь:


Тащим вверх и включаем только синтезированный словарь:

Убираем кривое автоопределение языков указав конкретный словарь:

Добрый день!
Пожалуйста, перезалейте куда-нибудь zip-архив. Ссылка нерабочая :(
Пожалуйста, перезалейте куда-нибудь zip-архив. Ссылка нерабочая :(
Привет!
Не буду утверждать, что это именно та сборка. Но это то что есть у меня.
Времени много прошло.
mega.nz/file/qYMXnADI#dmj0OAtVJ6TVoJwqY6hLu-_iuIAErGyiY5Ut3cWF_aY
Не буду утверждать, что это именно та сборка. Но это то что есть у меня.
Времени много прошло.
mega.nz/file/qYMXnADI#dmj0OAtVJ6TVoJwqY6hLu-_iuIAErGyiY5Ut3cWF_aY
Попробовал склеить по максимуму английские и русские словари по ссылкам, программа обрывала работу с сообщением о нехватке памяти. Исключил явные дубликаты и словари с разницей в несколько десятков слов, всё равно не получается.
Стал соединять постепенно. Сначала весь американский английский, потом британский, потом оба варианта. Русский с «е», русский с «ё», русский с «её». Потом соединил «е» и «ё». Но при попытке соединить этот гибрид с изначальными гибридами «её» — опять нехватка памяти (два файла в UTF-8 по 13 и 11 мегабайт каждый).
Windows XP, Java 7.0.90.5. Сообщение в консоли начинается с:
j:\temp\HunspellMerge>java -cp HunspellMerge.jar hunspell.merge.HunspellMerge
Exception in thread «AWT-EventQueue-0» java.lang.OutOfMemoryError: Java heap spa
ce
потом идёт длинный список файлов. Свободной памяти в это время ещё мегабайтов семьсот. Ко времени сбоя уже есть папка output с файлом аффиксов.
Стал соединять постепенно. Сначала весь американский английский, потом британский, потом оба варианта. Русский с «е», русский с «ё», русский с «её». Потом соединил «е» и «ё». Но при попытке соединить этот гибрид с изначальными гибридами «её» — опять нехватка памяти (два файла в UTF-8 по 13 и 11 мегабайт каждый).
Windows XP, Java 7.0.90.5. Сообщение в консоли начинается с:
j:\temp\HunspellMerge>java -cp HunspellMerge.jar hunspell.merge.HunspellMerge
Exception in thread «AWT-EventQueue-0» java.lang.OutOfMemoryError: Java heap spa
ce
потом идёт длинный список файлов. Свободной памяти в это время ещё мегабайтов семьсот. Ко времени сбоя уже есть папка output с файлом аффиксов.
Сколько оперативки в наличии? И еще — можно ссылки на использованные словари?
Простите, промахнулся, чуть ниже ответил.
Понятно. Я уже вижу пути оптимизации использования памяти. На днях реализую.
Пока что могу предложить попробовать увеличить размер Java heap при запуске утилиты.
Добавить ключи в строку запуска Java
Например:
Вот здесь на всякий случай есть информация по проблемам при установке установке Java Heap
Пока что могу предложить попробовать увеличить размер Java heap при запуске утилиты.
Добавить ключи в строку запуска Java
-Xms<size>set initial Java heap size -Xmx<size> set maximum Java heap sizeНапример:
java -Xmx1024m -cp HunspellMerge.jar hunspell.merge.HunspellMergeВот здесь на всякий случай есть информация по проблемам при установке установке Java Heap
Да, с таким ключом соединяется, спасибо.
Но, к сожалению, есть другая проблема. Словарь аффиксов почему-то от соединения к соединению иногда существенно уменьшается.
Конечный словарь для английского вышел всего на 543 байта, тогда как исходные достигали десятков килобайт.
Конечный для русского вышел на 38 килобайт, раз в десять меньше некоторых исходных.
Когда я объединил русский словарь аффиксов с английским, получилось всего семь килобайт. После установки такой словарь начинает помечать как ошибки множество правильных русских словоформ, которые обычный словарь в Firefox не помечает.
Но, к сожалению, есть другая проблема. Словарь аффиксов почему-то от соединения к соединению иногда существенно уменьшается.
Конечный словарь для английского вышел всего на 543 байта, тогда как исходные достигали десятков килобайт.
Конечный для русского вышел на 38 килобайт, раз в десять меньше некоторых исходных.
Когда я объединил русский словарь аффиксов с английским, получилось всего семь килобайт. После установки такой словарь начинает помечать как ошибки множество правильных русских словоформ, которые обычный словарь в Firefox не помечает.
Спасибо за информацию.
Нужно будет посмотреть, возможно тут дело в порядке соединения словарей и алгоритме игнорирования дубликатов слов. Я буду изучать. Как будут результаты — я отпишу тут.
Нужно будет посмотреть, возможно тут дело в порядке соединения словарей и алгоритме игнорирования дубликатов слов. Я буду изучать. Как будут результаты — я отпишу тут.
Доработал утилиту (v.1.1).
Добавлено окно лога, чтобы не было скучно ждать, улучшено соединение аффиксов.
code.google.com/p/hunspell-merge/downloads/
Можно пробовать.
Добавлено окно лога, чтобы не было скучно ждать, улучшено соединение аффиксов.
code.google.com/p/hunspell-merge/downloads/
Можно пробовать.
Попробовал объединить словари британского английского для начала.
На выходе файл аффиксов из трёх строчек:
SET UTF-8
TRY
FLAG NUMBER
Лог:
Loading: british_english_dictionary_updated-1.19.3-fx+sm+tb.xpi / en-GB (ISO-8859-1)…
Merging 0 affixes…
Merging 46280 words…
Done!
Loading: en_GB-oed.zip / en_GB-oed (ISO-8859-1)…
Merging 0 affixes…
Merging 46113 words…
Done!
Loading: en_GB-pack.zip / en_GB (ISO-8859-1)…
Merging 0 affixes…
Merging 46146 words…
Done!
Loading: en_GB_oxt.zip / en_GB (UTF-8)…
Merging 0 affixes…
Merging 56506 words…
Done!
Checking unused affixes…
Saving affix file: en_gb.aff
Saving dictionary file: en_gb.aff
Result 0 affixes, 65733 words
Work time (min:sec) = 00:02
Output folder: j:\temp\HunspellMerge\output\
Merging 0 affixes…
Merging 46280 words…
Done!
Loading: en_GB-oed.zip / en_GB-oed (ISO-8859-1)…
Merging 0 affixes…
Merging 46113 words…
Done!
Loading: en_GB-pack.zip / en_GB (ISO-8859-1)…
Merging 0 affixes…
Merging 46146 words…
Done!
Loading: en_GB_oxt.zip / en_GB (UTF-8)…
Merging 0 affixes…
Merging 56506 words…
Done!
Checking unused affixes…
Saving affix file: en_gb.aff
Saving dictionary file: en_gb.aff
Result 0 affixes, 65733 words
Work time (min:sec) = 00:02
Output folder: j:\temp\HunspellMerge\output\
На выходе файл аффиксов из трёх строчек:
SET UTF-8
TRY
FLAG NUMBER
Словари иногда не содержат файла аффиксов. В английских словарях это часто встречается.
Приложите прямые ссылки на исходные словари — тогда я смогу посмотреть в чем причина.
Приложите прямые ссылки на исходные словари — тогда я смогу посмотреть в чем причина.
Еще бывает, что файл аффиксов не содержит никаких аффиксов, а только указывает на кодировку словаря.
Это не является нарушением формата словарей.
Это не является нарушением формата словарей.
Да, это был баг. Исправил. Взять можно там же (v.1.2).
Поправил. Еще нужно будет поработать над дополнительными типами аффиксов, встречающимися в этих словарях.
Поправил. Еще нужно будет поработать над дополнительными типами аффиксов, встречающимися в этих словарях.
Да, похоже, ещё можно дорабатывать. Попробовал опять пройтись в таком порядке:
en-gb
en-us
en-gb-us
ru-yo
ru-ie
ru-yoie
ru-yoie-yo-ie
ru-en
Иногда аффиксы нормально соединяются (результирующее число чуть меньше суммы), но иногда опять происходит разительное сокращение (вроде 250+44=18). На этапе ru-yoie-yo-ie программа зависла, через минут пять максимальной нагрузки процессора пришлось её насильно выключать.
Вот с этим набором словарей я работал (некоторые oxt я раздербанил, чтобы выбрать только нужные варианты английского). Может, пригодится, если вы пройдётесь в том же порядке соединения.
en-gb
en-us
en-gb-us
ru-yo
ru-ie
ru-yoie
ru-yoie-yo-ie
ru-en
Иногда аффиксы нормально соединяются (результирующее число чуть меньше суммы), но иногда опять происходит разительное сокращение (вроде 250+44=18). На этапе ru-yoie-yo-ie программа зависла, через минут пять максимальной нагрузки процессора пришлось её насильно выключать.
Вот с этим набором словарей я работал (некоторые oxt я раздербанил, чтобы выбрать только нужные варианты английского). Может, пригодится, если вы пройдётесь в том же порядке соединения.
Изменил алгоритм обработки аффиксов (v.1.3). Возможно пока будет некоторое количество излишней информации. Я думаю над возможностями «безвредного» удаления дубликатов.
Находится где обычно.
Если будут проблемы — можно в личку или на почту (там в проекте на гуглокоде есть она), чтобы тут не разводить диспуты.
Находится где обычно.
Если будут проблемы — можно в личку или на почту (там в проекте на гуглокоде есть она), чтобы тут не разводить диспуты.
Спасибо. Проверю попозже и напишу. Лучше, конечно, излишняя информация, чем потери.
Всё ещё проблемы с аффиксами.
Заметил закономерность: пока программа соединяет посторонние словари, аффиксы соединяются нормально. Но как только она начинает соединять промежуточные словари, созданные ею самой, начинаются проблемы:
И даже при обёртывании одного словаря в xpi происходит странное:
Заметил закономерность: пока программа соединяет посторонние словари, аффиксы соединяются нормально. Но как только она начинает соединять промежуточные словари, созданные ею самой, начинаются проблемы:
Лог 1
Loading: en_gb.dic / en_gb (UTF-8)…
Merging 326 affixes…
Merging 60590 words…
Done!
Loading: en_us.dic / en_us (UTF-8)…
Merging 171 affixes…
Merging 70372 words…
Done!
Checking unused affixes…
Saving affix file: en_gb_us.aff
Saving dictionary file: en_gb_us.aff
Result 20 affixes, 82834 words
Work time (min:sec) = 00:14
Output folder: j:\temp\HunspellMerge\output\
Merging 326 affixes…
Merging 60590 words…
Done!
Loading: en_us.dic / en_us (UTF-8)…
Merging 171 affixes…
Merging 70372 words…
Done!
Checking unused affixes…
Saving affix file: en_gb_us.aff
Saving dictionary file: en_gb_us.aff
Result 20 affixes, 82834 words
Work time (min:sec) = 00:14
Output folder: j:\temp\HunspellMerge\output\
Лог 2
Loading: ru_ie.dic / ru_ie (UTF-8)…
Merging 258 affixes…
Merging 476711 words…
Done!
Loading: ru_yo.dic / ru_yo (UTF-8)…
Merging 74 affixes…
Merging 153255 words…
Done!
Checking unused affixes…
Saving affix file: ru_ie_yo.aff
Saving dictionary file: ru_ie_yo.aff
Result 18 affixes, 490665 words
Work time (min:sec) = 00:47
Output folder: j:\temp\HunspellMerge\output\
Merging 258 affixes…
Merging 476711 words…
Done!
Loading: ru_yo.dic / ru_yo (UTF-8)…
Merging 74 affixes…
Merging 153255 words…
Done!
Checking unused affixes…
Saving affix file: ru_ie_yo.aff
Saving dictionary file: ru_ie_yo.aff
Result 18 affixes, 490665 words
Work time (min:sec) = 00:47
Output folder: j:\temp\HunspellMerge\output\
Лог 3
Loading: ru_ieyo.dic / ru_ieyo (UTF-8)…
Merging 375 affixes…
Merging 637637 words…
Done!
Loading: ru_ie_yo.dic / ru_ie_yo (UTF-8)…
Merging 18 affixes…
Merging 490665 words…
Done!
Checking unused affixes…
Saving affix file: ru_ieyo_ie_yo.aff
Saving dictionary file: ru_ieyo_ie_yo.aff
Result 19 affixes, 720552 words
Work time (min:sec) = 01:07
Output folder: j:\temp\HunspellMerge\output\
Merging 375 affixes…
Merging 637637 words…
Done!
Loading: ru_ie_yo.dic / ru_ie_yo (UTF-8)…
Merging 18 affixes…
Merging 490665 words…
Done!
Checking unused affixes…
Saving affix file: ru_ieyo_ie_yo.aff
Saving dictionary file: ru_ieyo_ie_yo.aff
Result 19 affixes, 720552 words
Work time (min:sec) = 01:07
Output folder: j:\temp\HunspellMerge\output\
Лог 4
Loading: en_gb_us.dic / en_gb_us (UTF-8)…
Merging 20 affixes…
Merging 82834 words…
Done!
Loading: ru_ieyo_ie_yo.dic / ru_ieyo_ie_yo (UTF-8)…
Merging 19 affixes…
Merging 720552 words…
Done!
Checking unused affixes…
Saving affix file: en_gb_us_ru_ieyo.aff
Saving dictionary file: en_gb_us_ru_ieyo.aff
Result 20 affixes, 803386 words
Work time (min:sec) = 00:21
Output folder: j:\temp\HunspellMerge\output\
Merging 20 affixes…
Merging 82834 words…
Done!
Loading: ru_ieyo_ie_yo.dic / ru_ieyo_ie_yo (UTF-8)…
Merging 19 affixes…
Merging 720552 words…
Done!
Checking unused affixes…
Saving affix file: en_gb_us_ru_ieyo.aff
Saving dictionary file: en_gb_us_ru_ieyo.aff
Result 20 affixes, 803386 words
Work time (min:sec) = 00:21
Output folder: j:\temp\HunspellMerge\output\
И даже при обёртывании одного словаря в xpi происходит странное:
Лог 5
Loading: en_gb_us_ru_ieyo.dic / en_gb_us_ru_ieyo (UTF-8)…
Merging 20 affixes…
Merging 803386 words…
Done!
Checking unused affixes…
Saving affix file: en_gb_us_ru_ieyo.aff
Saving dictionary file: en_gb_us_ru_ieyo.aff
Create XPI: en-gb-us-ru-ieyo.xpi
Result 11 affixes, 803386 words
Work time (min:sec) = 00:30
Output folder: j:\temp\HunspellMerge\output\
Merging 20 affixes…
Merging 803386 words…
Done!
Checking unused affixes…
Saving affix file: en_gb_us_ru_ieyo.aff
Saving dictionary file: en_gb_us_ru_ieyo.aff
Create XPI: en-gb-us-ru-ieyo.xpi
Result 11 affixes, 803386 words
Work time (min:sec) = 00:30
Output folder: j:\temp\HunspellMerge\output\
Странно. Попробовал без промежуточных словарей, всё вроде бы получается хорошо:
Спасибо. Погоняю немного этот словарь, если будут проблемы, напишу.
Лог для 14-ти словарей сразу
Loading: addon-0.4.4.1-sm+tb+fx+fn.xpi / ru (KOI8-R)…
Merging 25 affixes…
Merging 146270 words…
Done!
Loading: british_english_dictionary_updated-1.19.3-fx+sm+tb.xpi / en-GB (ISO-8859-1)…
Merging 63 affixes…
Merging 46280 words…
Done!
Loading: dict_ru_RU-0.3.7.oxt / hyph_ru_RU (KOI8-R)…
Merging 25 affixes…
Merging 3875 words…
Done!
Loading: dict_ru_RU-AOT-0.2.7-ieyo.oxt / russian-aot-ieyo (KOI8-R)…
Merging 364 affixes…
Merging 379323 words…
Done!
Loading: dict_ru_RU-rk-ieyo-0.4.2.oxt / russian-rk-ieyo (KOI8-R)…
Merging 11 affixes…
Merging 322129 words…
Done!
Loading: en_GB-oed.zip / en_GB-oed (ISO-8859-1)…
Merging 63 affixes…
Merging 46113 words…
Done!
Loading: en_GB-pack.zip / en_GB (ISO-8859-1)…
Merging 61 affixes…
Merging 46146 words…
Done!
Loading: en_GB_oxt.zip / en_GB (UTF-8)…
Merging 712 aliases…
Merging 150 affixes (712 aliases)…
Merging 56506 words…
Done!
Loading: en_US_oxt.zip / en_US (UTF-8)…
Merging 589 aliases…
Merging 152 affixes (589 aliases)…
Merging 52890 words…
Done!
Loading: russian_hunspell_dictionary-1.0.20120501-sm+fn+fx+tb.xpi / ru_RU (UTF-8)…
Merging 236 affixes…
Merging 174304 words…
Done!
Loading: ru_RU.zip / ru_RU (KOI8-R)…
Merging 24 affixes…
Merging 128905 words…
Done!
Loading: ru_RU_ye.zip / ru_RU_ie (KOI8-R)…
Merging 11 affixes…
Merging 321998 words…
Done!
Loading: ru_RU_yo.zip / ru_RU_yo (KOI8-R)…
Merging 24 affixes…
Merging 129167 words…
Done!
Loading: united_states_english_spellchecker-6.0-fx+sm+tb.xpi / en-US (ISO-8859-1)…
Merging 24 affixes…
Merging 62119 words…
Done!
Checking unused affixes…
Saving affix file: en_ru.aff
Saving dictionary file: en_ru.aff
Create XPI: en-ru.xpi
Result 1213 affixes, 803396 words
Work time (min:sec) = 00:56
Output folder: j:\temp\HunspellMerge\output\
Merging 25 affixes…
Merging 146270 words…
Done!
Loading: british_english_dictionary_updated-1.19.3-fx+sm+tb.xpi / en-GB (ISO-8859-1)…
Merging 63 affixes…
Merging 46280 words…
Done!
Loading: dict_ru_RU-0.3.7.oxt / hyph_ru_RU (KOI8-R)…
Merging 25 affixes…
Merging 3875 words…
Done!
Loading: dict_ru_RU-AOT-0.2.7-ieyo.oxt / russian-aot-ieyo (KOI8-R)…
Merging 364 affixes…
Merging 379323 words…
Done!
Loading: dict_ru_RU-rk-ieyo-0.4.2.oxt / russian-rk-ieyo (KOI8-R)…
Merging 11 affixes…
Merging 322129 words…
Done!
Loading: en_GB-oed.zip / en_GB-oed (ISO-8859-1)…
Merging 63 affixes…
Merging 46113 words…
Done!
Loading: en_GB-pack.zip / en_GB (ISO-8859-1)…
Merging 61 affixes…
Merging 46146 words…
Done!
Loading: en_GB_oxt.zip / en_GB (UTF-8)…
Merging 712 aliases…
Merging 150 affixes (712 aliases)…
Merging 56506 words…
Done!
Loading: en_US_oxt.zip / en_US (UTF-8)…
Merging 589 aliases…
Merging 152 affixes (589 aliases)…
Merging 52890 words…
Done!
Loading: russian_hunspell_dictionary-1.0.20120501-sm+fn+fx+tb.xpi / ru_RU (UTF-8)…
Merging 236 affixes…
Merging 174304 words…
Done!
Loading: ru_RU.zip / ru_RU (KOI8-R)…
Merging 24 affixes…
Merging 128905 words…
Done!
Loading: ru_RU_ye.zip / ru_RU_ie (KOI8-R)…
Merging 11 affixes…
Merging 321998 words…
Done!
Loading: ru_RU_yo.zip / ru_RU_yo (KOI8-R)…
Merging 24 affixes…
Merging 129167 words…
Done!
Loading: united_states_english_spellchecker-6.0-fx+sm+tb.xpi / en-US (ISO-8859-1)…
Merging 24 affixes…
Merging 62119 words…
Done!
Checking unused affixes…
Saving affix file: en_ru.aff
Saving dictionary file: en_ru.aff
Create XPI: en-ru.xpi
Result 1213 affixes, 803396 words
Work time (min:sec) = 00:56
Output folder: j:\temp\HunspellMerge\output\
Спасибо. Погоняю немного этот словарь, если будут проблемы, напишу.
По всем вашим трём ссылкам все русские и все английские (только американский и британский английский) словари. Но для проверки можно только русскими ограничится, потому что уже с ними проблема.
Оперативки — восемь гигов, но система видит только три с хвостиком, в остальном рамдиск. Во время соединения свободно ещё мегабайт семьсот. В программе мониторинга ресурсов никакого скачка потребления памяти в момент сбоя не заметно.
Оперативки — восемь гигов, но система видит только три с хвостиком, в остальном рамдиск. Во время соединения свободно ещё мегабайт семьсот. В программе мониторинга ресурсов никакого скачка потребления памяти в момент сбоя не заметно.
у меня в убунте большинство программ поддерживают hunspell с двуязычным словарём. Про то, как этого добиться, я даже пост написал: двуязычная русско-английская проверка правописания в ubuntu
TortoiseGIT и TortoiseSVN проверяют орфографию в log message при коммите всеми словарями из C:\Program Files\TortoiseGit\Languages одновременно
Отлично, то, что я искал. Спасибо.
Использую в Windows для Firefox, Thundebrird, Skype и Emacs.
Использую в Windows для Firefox, Thundebrird, Skype и Emacs.
… и так же Miranda IM.
Сегодня были внесены некоторые изменения, связанные со склейкой. Можно попробовать обновление.
На всякий случай завел лог изменений.
На всякий случай завел лог изменений.
Sign up to leave a comment.
Многоязыковая проверка орфографии для программ, использующих Hunspell