Comments 20
Отличная статья, спасибо.
Подумываю о реализации на Python.
Подумываю о реализации на Python.
спс, тут кстати есть реализация на питоне deeplearning.net/tutorial/rbm.html#contrastive-divergence-cd-k
Ого. Как много всего интересного, оказывается, в нейросетеводстве.
Спасибо за статью. Для себя сделал вывод, что следующий курс по нейронным сетям пропустить нельзя.
Спасибо за статью. Для себя сделал вывод, что следующий курс по нейронным сетям пропустить нельзя.
Узнал из статьи действительно много нового. Понимание принципов работы таких сетей здорово помогло при работе с библиотекой Accord.NET. В своём проекте использую инициализацию по PCA, проведенному на начальном этапе, т.к. обрабатываемые данные принципиально далеки от изображений. Скажите, какие реализации/подвиды данных сетей хорошо применимы для действительных, не бинарных данных?
Спасибо, жду продолжения!
Спасибо, жду продолжения!
для моделирования действительных значений используется немного другая функция энергии сети
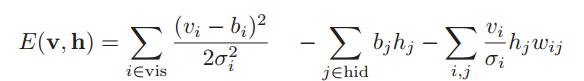
в данном случае видимые нейроны действительны, а скрытые — бинарные (gaussian-binary rbm), аналогично можно ввести и энегрию для gaussian-gaussian rbm.
про это можно почитать как у самого Хинтона www.cs.toronto.edu/~hinton/absps/guideTR.pdf
так и тут на хабре habrahabr.ru/post/186368/
проблема тут в другом, пока нет достаточно эффективного алгоритма обучения таких сетей, хотя за не имением чего то крутого, сам же Хинтон использует свой же contrastive-divergence, хотя и говорит что вопрос открытый и следует разработать более эффективный алгоритм

в данном случае видимые нейроны действительны, а скрытые — бинарные (gaussian-binary rbm), аналогично можно ввести и энегрию для gaussian-gaussian rbm.
про это можно почитать как у самого Хинтона www.cs.toronto.edu/~hinton/absps/guideTR.pdf
так и тут на хабре habrahabr.ru/post/186368/
проблема тут в другом, пока нет достаточно эффективного алгоритма обучения таких сетей, хотя за не имением чего то крутого, сам же Хинтон использует свой же contrastive-divergence, хотя и говорит что вопрос открытый и следует разработать более эффективный алгоритм
Интересна такая ситуация. Допустим, есть обычная сеть со следующими количествами скрытых слоёв: 7-4-2 (взято наобум). Вопрос, эффективно ли будет предобучение, если мы сначала обучим сеть типа бутылочного горла вида 7-4-7 и перенесем веса из слоя с 4 нейронами в исходную сеть, ну и так далее.

Еще один вопрос. Насколько я понимаю, автоэнкодер осуществляет сжатие данных до меньшей размерности. И если центральный слой сделать состоящим из одного нейрона, можно ли будет использовать такую сеть для вычисления «рейтинга» чего-либо, к примеру, банка, по его финансовым показателям?
Или для этого (т.е. для получения первой нелинейной главной компоненты, простите, не знаю, как это точно называется) лучше использовать другие методы, отбросив нейронные сети.
Или для этого (т.е. для получения первой нелинейной главной компоненты, простите, не знаю, как это точно называется) лучше использовать другие методы, отбросив нейронные сети.
ну почему бы нет, можно (за адекватность не отвечаю =)
но тут как я понимаю вот какая ситуация, когда мы говорим о рейтинге, то это уже задача регрессии в рамках обучения с учителем (есть множество пар вход-выход, где выход это одно число-рейтинг), тогда будет иметь структуру n1-n2-...-nk-1, т.е. на выходе один нейрон и мы ее обучаем
когда мы говорим о фичах (или о главных конмонентах, линейных или не линейных) то это уже задача обучения без учителя, тут уже можно и автоенкодером пользоваться, и rbm ну и другими методами.
не могу ответить какими методами лучше или хуже использовать при уменьшении размерности, с линейными компонентами Пирсона все ясно, там можно расчитать variance explained, но с нелинейными я не в курсе (думаю есть какие нибудь аналогичные способы оценки, ноя не в курсе), я как практик скажу что все сильно зависитот данных, и необходимо тестировать методы на конкретных данных
но тут как я понимаю вот какая ситуация, когда мы говорим о рейтинге, то это уже задача регрессии в рамках обучения с учителем (есть множество пар вход-выход, где выход это одно число-рейтинг), тогда будет иметь структуру n1-n2-...-nk-1, т.е. на выходе один нейрон и мы ее обучаем
когда мы говорим о фичах (или о главных конмонентах, линейных или не линейных) то это уже задача обучения без учителя, тут уже можно и автоенкодером пользоваться, и rbm ну и другими методами.
не могу ответить какими методами лучше или хуже использовать при уменьшении размерности, с линейными компонентами Пирсона все ясно, там можно расчитать variance explained, но с нелинейными я не в курсе (думаю есть какие нибудь аналогичные способы оценки, ноя не в курсе), я как практик скажу что все сильно зависитот данных, и необходимо тестировать методы на конкретных данных
Ну я исхожу из предположения, что если финансовые характеристики преобразовать таким образом, что большие входные значения будут соответствовать тем банкам, которые лучше, то главная компонента (линейна она или нет) должна будет идти в многомерном пространстве от банков с наихудшими показателями к банкам с наилучшими. И, по идее, выход единичного нейрона в центре автоэнкодера должен максимально совпасть с главной компонентой, т.к. из нее и именно из нее можно с наименьшими потерями восстановить исходные данные. Т.о. обучение с учителем нам не нужно, мы просто обучим автоэнкодер, а потом «обрежем» его, взяв первую половину слоев.
Добрый день. Заранее скажу, что вполне возможно, что я не прав. Тем не менее, считаю, что вы не совсем правильно реализовали алгоритм. У Хинтона в статье написано, что для градиента берутся «expectations under the distribution...», а исходя из определения ожидания, — это значение, умноженное на его вероятность. Таким образом, как на deeplearning.net (ссылка у вас в статье) и написано, обе части градиента вычисляются как вероятность * значение. У вас же в коде, если я не ошибаюсь, перемножпются значения самих юнитов без вероятностей.
А как же hiddenLayer.Neurons[i].LastState = _r.NextDouble() <= hiddenLayer.Neurons[i].LastState? 1d: 0d;? (Прошу прощения, что как текст написал — с телефона пишу)
Судя по этой строчке, в значение записывается не сигмоид, а либо 1, либо 0.
Судя по этой строчке, в значение записывается не сигмоид, а либо 1, либо 0.
вот тут в практических советах http://www.cs.toronto.edu/~hinton/absps/guideTR.pdf он пишет и объясняет почему лучше семплировать скрытый, но не семплировать видимый
Я вам не про это говорю. Вы говорите, что перемножается у вас сигмоида (условная вероятность скрытого нейрона) и значение соответствующего нейрона видимого слоя. Я говорю, что из кода этого не видно, так как есть строчка, в которой последним значениям, в зависимости от вероятности, присваивается 0 или 1. А потом мы перемножаем значения видимого и скрытого нейронов. Возможно, я просто не увидел этот код, тогда, пожалуйста, укажите мне на него.
так а в чем ошибка то? перемножаем значение видимого и скрытого, вроде как так и надо; у видимого значение — это вероятность, у скрытого засемплированное значение из бернулли распределения
Sign up to leave a comment.
Реализация Restricted Boltzmann machine на c#