Введение
Любой прогресс и оптимизация приветствуется кем угодно. Сегодня хотелось бы поговорить про прекрасную вещь, значительно облегчающую жизнь – очереди. Внедрение best practices в этом вопросе не только улучшают производительность приложения, но и успешно готовят ваше приложение к архитектуре «в стиле» Cloud Computing. Тем более, что не использовать уже готовые решения от провайдеров облачных технологий просто глупо.
В этой статье мы рассмотрим Amazon Web Services с точки зрения проектирования архитектуры средних и больших веб приложений.
Рассмотрим схему такого приложения:
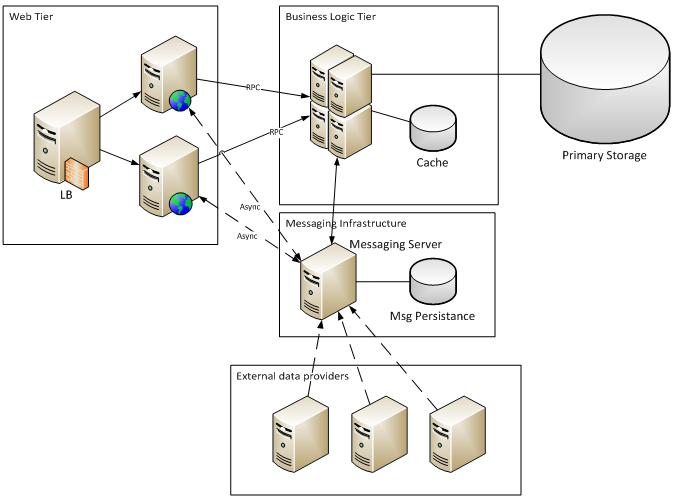
Примерами такой организации могут быть различного рода агрегаторы: новости, курсы валют, котировки бирж и т.д.
External data providers генерируют поток сообщений, которые, проходя постобработку, сохраняются в базе.
Пользователи через web-tier делают выборку информации из базы по определённым критериям (фильтры, группировка, сортировка), а затем опциональная обработка выборок (различные статистические функции).
Amazon старается определить наиболее типовые компоненты приложений, затем автоматизирует и предоставляет компонент-сервис. Сейчас таких сервисов уже более двух десятков и с полным списком можно ознакомиться на сайте AWS: http://aws.amazon.com/products/. На хабре уже была статья с описанием ряда популярных сервисов: Популярно об Amazon Web Services. Привлекательно это в первую очередь тем, что отпадает необходимость в самостоятельной установке и конфигурации, а так же более высокой надёжностью и сдельной оплатой
И если использовать AWS, то схема проекта будет выглядеть так:
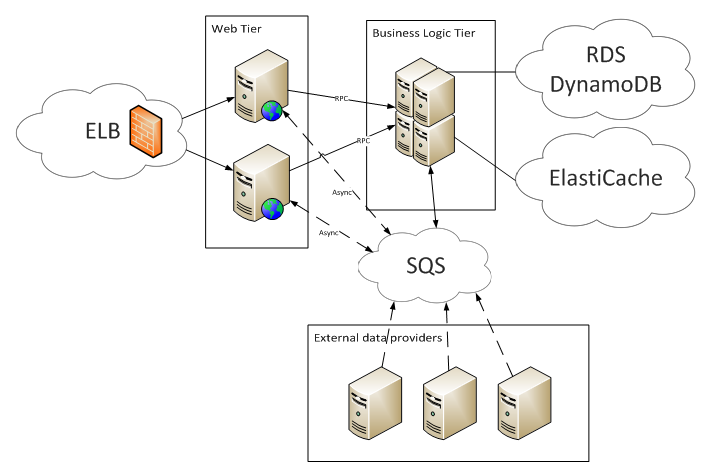
Несомненно, этот подход востребован и у него есть свой рынок. Но часто возникают вопросы о финансовой составляющей:
- Сколько можно сэкономить, используя AWS?
- Можно ли самостоятельно реализовать сервис с теми же свойствами, но за меньшие деньги?
- Где та грань, которая разделяет AWS от своего аналога?
Далее мы постараемся ответить на эти вопросы.
1. Обзор аналогов
Для сравнения будем рассматривать следующие компоненты:
- Message-oriented middleware – RabbitMQ
- Аналог вышеуказанного сервиса от AWS, который называется SQS
Сервис SQS оплачивается из расчета количества запросов к API + трафик
Рассмотрим каждый сервис подробнее.
1.1. SQS
Amazon SQS – это сервис позволяющий создавать и работать с очередями сообщений. Стандартный цикл работы с готовой очередью SQS следующий:
- Producer для отправки сообщения в очередь должен знать её URL. Затем, используя команду SendMessage, добавляет сообщение.
- Consumer получает сообщение используя команду ReceiveMessag.
- Как только сообщение будет получено, оно будет заблокировано для повторного получения на некоторое время.
- После успешной обработки сообщения Consumer использует команду DeleteMessage для удаления сообщения из очереди. Если во время обработки произошла ошибка или не была вызвана команда DeleteMessage, то по истечению таймаута сообщение вернётся обратно в очередь.
Таким образом, в среднем для отправки и обработки одного сообщения необходимо 3 вызова API.
Используя SQS, вы платите за количество вызовов API + трафик между регионами. Стоимость 10к вызовов составляет 0.01$, т.е. в среднем за 10к сообщений (х3 вызова API) вы платите 0.03$. Расценки в других регионах вы можете посмотреть тут.
Существует большое количество вариантов организации сервиса отправки сообщений:
- RabbitMQ
- ActiveMQ
- ZMQ
- OpenMQ
- ejabbered (XMPP)
Каждый вариант имеет свои плюсы и минусы. Мы выберем RabbitMQ, как одну из самых популярных реализацию протокола AMQP.
1.2. RabbitMQ
1.2.1. Схема деплоймента
Сервер с установленным RabbitMQ и настройками по умолчанию выдаёт очень хорошую производительность. Но такой вариант деплоймента нас не устраивает, т.к. в случае падения этого узла мы можем получить сразу ряд проблем:
- Потеря важных данных в сообщениях;
- «Скапливание» информации на Producer-ах, что может привести к перегрузке Consumer-ов после восстановления работы очереди;
- Остановка работы всего приложения на время решения проблемы.
В тестировании будем использовать 2 узла в режиме active-active с репликацией очередей между узлами. В рамках RabbitMQ это называется mirrored queues.
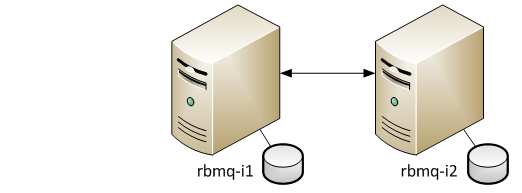
Для каждой такой очереди определяется мастер и набор слейвов, где хранится копия очереди. В случае падения мастер-узла, один из слейвов выбирается мастером.
Что бы создать такую очередь задаётся параметр «x-ha-policy» при декларировании, который указывает, где должны храниться копии очереди. Возможны 2 значения параметра
- all: копии очереди будут хранится на всех узлах кластера. При добавлении нового узла в кластер, на нём будет создана копия;
- nodes: копии будут созданы только на узлах, заданных параметром «x-ha-policy-params».
Детальнее о mirrored queues можно почитать тут: http://www.rabbitmq.com/ha.html.
1.2.2. Техника замера производительности
Ранее мы рассмотрели, как будет организовано тестовое окружение. Теперь давайте рассмотрим, что и как мы будем мерять.
Для всех измерений использовались m1.small инстансы (AWS).
Будем проводить ряд замеров:
Скорость отправки сообщений до определённого значения, потом скорость получения – тем самым мы проверим деградацию производительности с увеличением очереди.
1. Скорость отправки сообщений до определённого значения, потом скорость получения – тем самым мы проверим деградацию производительности с увеличением очереди.
2. Одновременная отправка и получение сообщений из одной очереди.
3. Одновременная отправка и получение сообщений из разных очередей.
4. Асимметричная нагрузка на очередь:
- a. Отправляют в очередь в 10 раз больше потоков, чем принимают;
- b. Получают из очереди в 10 раз больше потоков, чем отправляют.
- a. 16 байт;
- b. 1 килобайт;
- c. 64 килобайта (max for SQS).
Все тесты кроме первого будут проводиться в 3 этапа:
- Прогрев 2 секунды;
- Прогон теста 15 секунд;
- Очистка очереди.
Подтверждение и получение сообщений (Message Acknowledgement)
Это свойство используется для подтверждения доставки и обработки сообщения. Существует два режима работы:
- Auto acknowledge – сообщение считается успешно доставленным сразу после того, как оно будет отправлено получателю; в этом режиме для получения одного сообщения достаточно всего одного обращения к серверу.
- Manual acknowledge – сообщение считается успешно доставленным после того, как получатель вызовет соответствующую команду. Этот режим позволяет обеспечить гарантированную обработку сообщения, если подтверждать доставку только после обработки. В этом режиме требуется два обращения к серверу.
В тесте выбран второй режим, т.к. он соответствует работе SQS, где обработка сообщения делается двумя командами: ReceiveMessage и DeleteMessage.
Batch processing
Что бы не тратить на каждом сообщении время для установки соединения, авторизации и прочего, RabbitMQ и SQS позволяют обрабатывать сообщения пакетами. Это доступно как для отправки, так и для получения сообщения. Т.к. пакетная обработка по умолчанию отключена и в RabbitMQ и в SQS, мы так же не будем её использовать для сравнения.
1.2.3. Результаты тестирования
Load-Unload Test
Сводные результаты:
| Load-Unload Test | msg/s | Время запроса | ||||
| avg, ms | min, ms | max, ms | 90%, ms | |||
| SQS | Consume | 198 | 25 | 17 | 721 | 28 |
| Produce | 317 | 16 | 10 | 769 | 20 | |
| RabbitMQ | Consume | 1293 | 3 | 0 | 3716 | 3 |
| Produce | 1875 | 2 | 0 | 14785 | 0 | |
Из таблицы видно, что SQS работает значительно стабильнее, чем RabbitMQ, в котором возможны провалы при отправке сообщения на 15 секунд! К сожалению, сразу причину такого поведения найти не удалось, а в тесте стараемся придерживаться стандартных настроек. При этом средняя скорость у RabbitMQ примерно в 6 раз выше, чем у SQS, а время выполнения запроса в несколько раз ниже.
Далее приведены графики с распределением средней скорости в зависимости от времени.
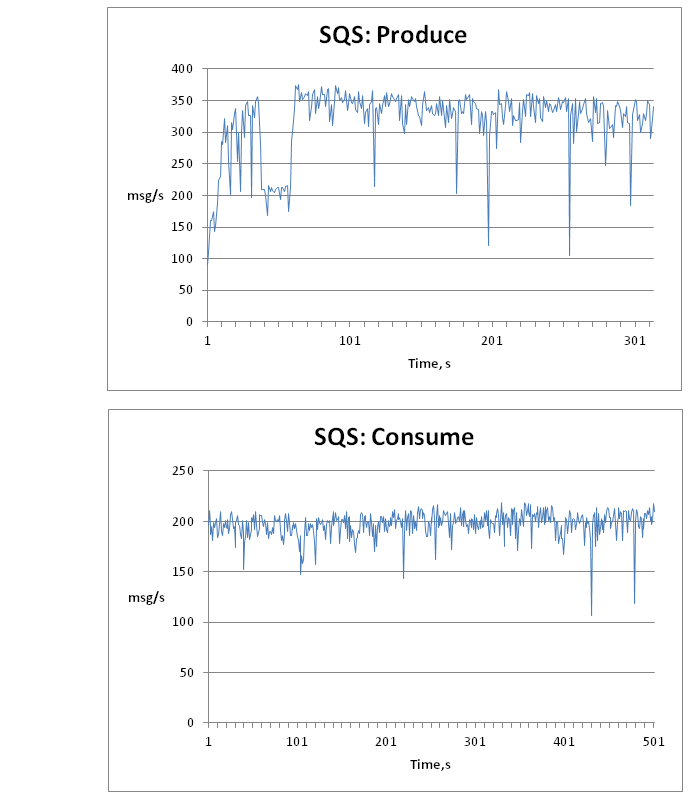
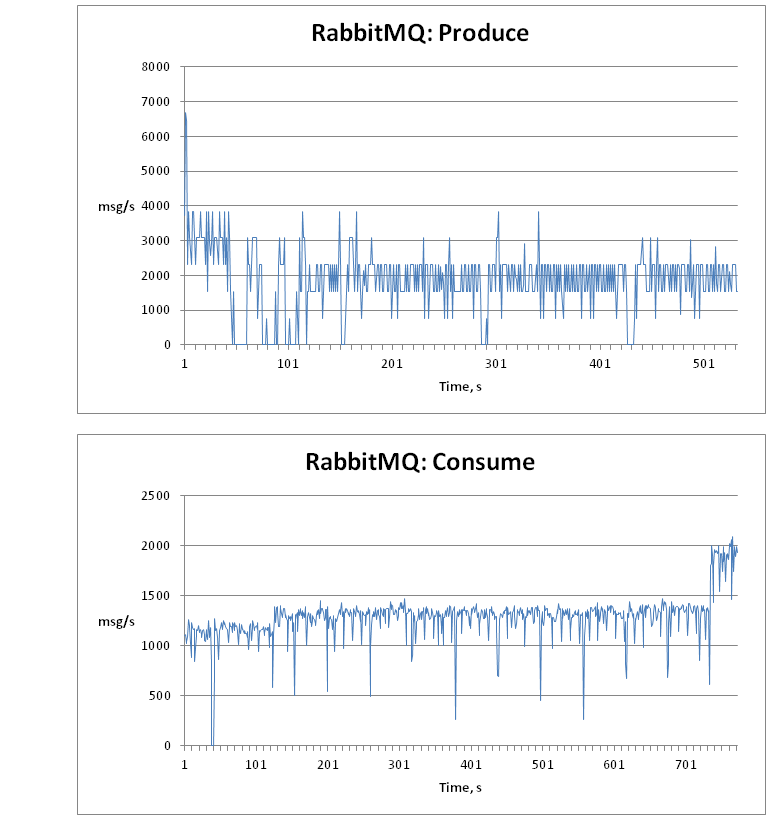
В целом, не падения производительности с ростом количества сообщений в очереди не замечено, а значит можно не бояться, что при падении принимающих узлов очередь станет узким местом.
Parallel
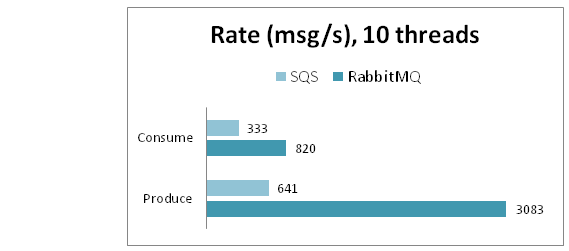
Не менее интересен тест зависимости скорости работы от количества одновременно работающих потоков. Результаты теста SQS можно легко предугадать: поскольку работа идёт по HTTP протоколу и большую часть времени занимает установка соединения, то, предположительно, результаты должны расти с количеством потоков, что хорошо иллюстрирует следующая таблица:
| SQS msg/s |
Threads | |||
| 1 | 5 | 10 | 40 | |
| Produce | 65 | 324 | 641 | 969 |
| Consume | 33 | 186 | 333 | 435 |
Так же видно, что для 1, 5 и 10 потоков зависимость линейная, но при увеличении до 40 потоков, средняя скорость возрастает на 50% для отправки и 30% для получения, но при этом значительно возрастает среднее время запроса: 43мс и 98мс соответственно.
Для RabbitMQ насыщение по скорости происходит значительно быстрее, уже при 5 потоках достигается максимум:
| RabbitMQ Threads | Threads | ||||
| 1 | 5 | 10 | 40 | ||
| Produce | speed, msg/s | 3086 | 3157 | 3083 | 3200 |
| latency, ms | 0 | 1 | 3 | 11 | |
| Consume | speed, msg/s | 272 | 811 | 820 | 798 |
| latency, ms | 3 | 6 | 12 | 51 | |
При тестировании обнаружилась особенность: если одновременно работают 1 поток на отправку и 1 поток на получение, то скорость получения сообщений падает практически до 0, при этом поток отправки показывает максимальную производительность. Проблема решается, если принудительно переключать контекст после каждой итерации теста, при этом падает пропускная способность отправки, но значительно снижается верхняя граница времени выполнения запроса. Из локальных тестов при 1 потоке (отправка/чтение): 11000/25 против 5000/1000.
Дополнительно провели тест для RabbitMQ с несколькими очередями для 5 потоков:
| RabbitMQ | Queues | |
| 1 | 5 | |
| Produce | 3157 | 3489 |
| Consume | 811 | 880 |
Видно, что скорость для нескольких очередей немного выше. Сводные результаты для 10 потоков представлены на следующей диаграмме:
Size
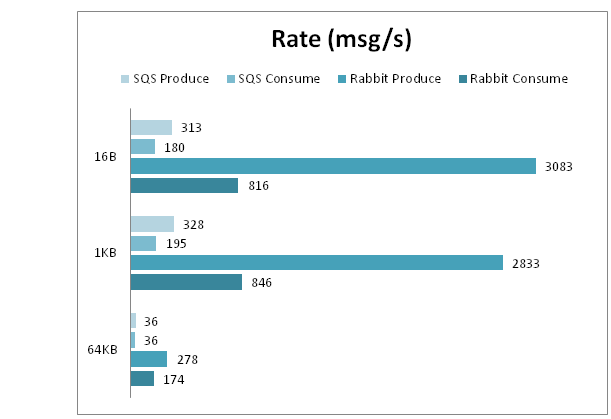
В этом тесте рассмотрим зависимость скорости от размера передаваемых данных.
И RabbitMQ и SQS показали ожидаемое ухудшение скорости отправки и получения с ростом размера сообщения. Помимо этого, очередь в RabbitMQ с ростом размера сообщения чаще «зависает» и не отвечает на запросы. Это косвенно подтверждает догадку о том, что это связанно с работой с жестким диском.
Сравнительные результаты скорости:
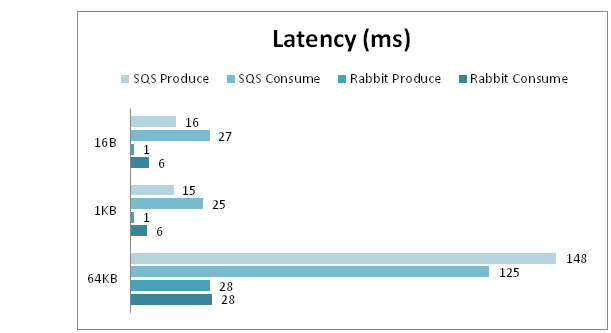
Сравнительные результаты времени запроса:
2. Расчёт стоимости и рекомендации
Из расчётной стоимости 0.08$ за один small instance в европейском регионе получаем стоимость в 0.16$ за RabbitMQ в конфигурации из двух узлов + стоимость трафика. В SQS стоимость отправки и получения 10000 сообщений составляет 0.03$. Получаем следующую зависимость:
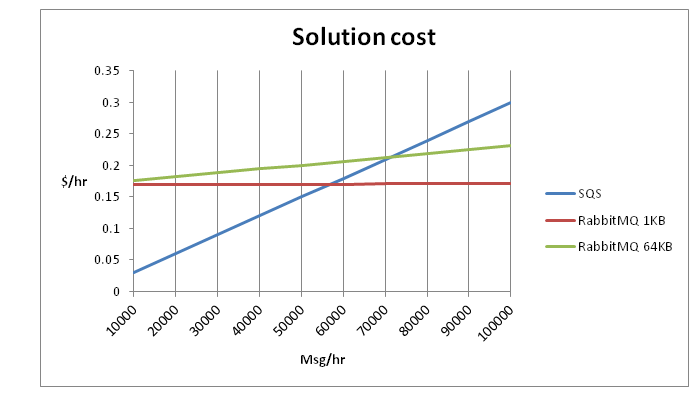
60 тысяч сообщений в час – это примерно 17 сообщений в секунду, что значительно меньше, чем скорость, которую могут обеспечить SQS и RabbitMQ.
Таким образом, если вашему приложению требуется скорость в среднем меньше 17 сообщений в секунду, то предпочтительным будет использовать SQS. Если потребности приложения становятся выше, то стоит рассмотреть пути миграции на выделенные messaging сервера.
Важно понимать, что эти рекомендации справедливы только для средних скоростей, и расчёты надо проводить на всём периоде цикла колебаний нагрузки, но если вашему приложению в пике требуется скорость значительно выше, чем позволяет SQS, то это так же повод задуматься о смене провайдера.
Ещё одной причиной использовать RabbitMQ может стать требование к latency запроса, которая на порядок ниже, чем у SQS.
2.1. Можно ли снизить стоимость RabbitMQ решения?
Есть два пути снижения стоимости:
- Не использовать кластер.
- Использовать micro instance.
В первом случае теряется HA кластера в случае падения узла или всей активной зоны, но это не страшно, если всё приложение хостится только в одной зоне.
Во втором случае micro instance могут быть урезаны ресурсы, если в течение некоторого времени утилизация ресурсов близка к 100%. Это может повлиять на работу очереди, когда используется persistence очереди.
3. Вывод
Таким образом мы видим, что однозначного ответа на вопрос «А какое же решение использовать мне?» просто нет. Все зависит от множества факторов: от размера вашего кошелька, от количества сообщений в секунду и времени отправки этих сообщений. Тем не менее, на основании метрик, приведенных в этом материале, можно просчитать поведение для конкретного случая.
Спасибо!
Статья написана и адаптированна по материалам исследования Максима Брунера (minim), для EPAM Cloud Computing Competency Center
