Comments 82
А не проще язык поменять? В PHP всё выглядит крайне многословным и даже запутанным.
Предложи фейсбуку поменять язык.
Речь о разработчике, а не о проекте.
В PHP на самом деле выгоднее всего придерживаться процедурного стиля, да и в обычном объектно-ориентированном стиле программировать можно.
А если очень нравится функциональный стиль, это повод сменить и язык, и проект.
В PHP на самом деле выгоднее всего придерживаться процедурного стиля, да и в обычном объектно-ориентированном стиле программировать можно.
А если очень нравится функциональный стиль, это повод сменить и язык, и проект.
>> В PHP на самом деле выгоднее всего придерживаться процедурного стиля
С чего бы?
С чего бы?
Вы не учитываете факт популярности языка. Это очень важный момент. Он влияет на цену на рынке, на количество готовых библиотек (yf выгрузку с базы TecDoc есть готовые скрипты, на интеграцию с любым сервисом всегда есть пример на PHP). Не учитываете скорость на гугление ошибки. Потому фраза я буду кодить на этом языке потому что мне нравится синтаксис хорошо себя показывает только в вакууме. Или если вы одарен. Но тогда все пойдет.
Откройте глаза, php не единственный язык, применяемый сейчас на планете. Ну сколько можно уже этот бред множить, дескать на других языках работы нет, разработчиков нет.
Тут вопрос сколько работы есть и сколько есть разработчиков.
А разработчику сменить язык на тот, который ему нравится без потерь в зарплате далеко не всегда представляется возможным. Грубо говоря, смена языка означает переход с Senior на Junior, даже если «предметная область» одна (веб-разработка).
А разработчику сменить язык на тот, который ему нравится без потерь в зарплате далеко не всегда представляется возможным. Грубо говоря, смена языка означает переход с Senior на Junior, даже если «предметная область» одна (веб-разработка).
Речи нет про использование языка. Вы конечно можете перейти на Ruby. И делать те же задачи. Но (к примеру) вам нужно сделать выгрузку в xls и встает проблема. На php это решается за 20 минут (найти библиотеку + разобраться в ней). На руби к примеру может занять неделю. Или нужно сделать выгрузку из TecDoc. Да даже интеграцию с платежной системой нужно изучить сначала на php и потому переписать на руби.
Вам как разработчику плевать на эти причины. Вы с радостью будете клепать выгрузку в ексель хоть месяц получая за это свои 10$ в час. А мне как работодателю это совершенно не нравится. Именно по этому мне нужны PHP программисты.
Я разделил мнения на 2 типа что бы лучше показать различные требования. Работа идет ради работы или ради результата.
Вам как разработчику плевать на эти причины. Вы с радостью будете клепать выгрузку в ексель хоть месяц получая за это свои 10$ в час. А мне как работодателю это совершенно не нравится. Именно по этому мне нужны PHP программисты.
Я разделил мнения на 2 типа что бы лучше показать различные требования. Работа идет ради работы или ради результата.
Простите, даже не смешно. Вобоще не знаю Руби, вбил в гугл «ruby write xls», открыл первый же результат. Прошел по ссылке, на странице библиотеки запустил одну команду из параграфа Installing. Скопировал код из ответа на stackoverflow, запустил. Получил «uninitialized constant Spreadsheet (NameError)». Открыл еще раз страницу библотеки, из первого же примера скопировал первую строчку «require 'roo'», запустил еще раз. Получил «undefined local variable or method `input' for main:Object (NameError)», посмотрел код, увидел, как используется input, дописал в начало:
input = [['foo', 'bar', 'tar'], [1, 2, 3]]
Все! 10 минут, и на рабочем столе лежит вот такой документ:
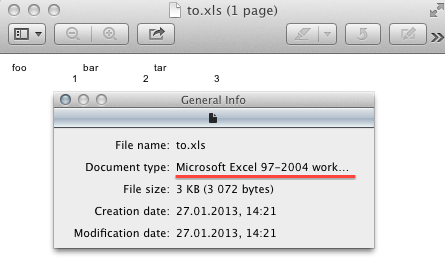
Я прекрасно понимаю, что вы взяли это просто как пример. Но положение дел сейчас таково, что для не самой распространенной задачи на php вы скорее всего найдете пару полурабочих библиотек, хорошо если написанных на ооп (про psr-0 и не мечтайте).
input = [['foo', 'bar', 'tar'], [1, 2, 3]]
Все! 10 минут, и на рабочем столе лежит вот такой документ:

Я прекрасно понимаю, что вы взяли это просто как пример. Но положение дел сейчас таково, что для не самой распространенной задачи на php вы скорее всего найдете пару полурабочих библиотек, хорошо если написанных на ооп (про psr-0 и не мечтайте).
Речи нет про использование языка. Вы конечно можете перейти на Ruby. И делать те же задачи. Но (к примеру) вам нужно сделать выгрузку в xls и встает проблема. На php это решается за 20 минут (найти библиотеку + разобраться в ней). На руби к примеру может занять неделю. Или нужно сделать выгрузку из TecDoc. Да даже интеграцию с платежной системой нужно изучить сначала на php и потому переписать на руби.
Полностью поддерживаю ваше заблуждение. Я когда после 8 лет работы на PHP, только сел на питон, притом на живом проекте, с реальной задачей. А не за пивом в выходной. Задача была схожа с вашей. Сграбить «название-цена» с 3х достаточно крупных инет-магазинов. А потом выгрузить их в xls файлы. На пхп я написал задачу за сутки где-то.
Потом переносил на питон неделю.
И так же как и вы плевался на Python и боготворил PHP.
Но месяц не прошёл, когда я понял что такое питон, и осознал ущербность PHP. Только тогда я изменил своё мнение. Потом, спустя пару месяцев, я под новый инет-магазин писал условия граббинга уже за час-два. На Python`e.
И да, я как и вы почти месяц, токо попробовав, но не поняв, ругал «другие языки» и хвалил «удобный и понятный пхп».
З.Ы. У того же питона «библиотеки» ищутся, ставятся и используются в разы быстрее и проще, да и кода в разы меньше писать приходится. Минусы свои тоже есть.
Вот только в контексте топика, такой «php» это совсем не php, наймете вы человека, будете считать что он знает php и сможет работать в команде с другими php программистами, а тут облом, на самом деле он знает свой язык, который по синтаксису является php, но использует такую нестандартную логику что другие разработчики воспринимают ее далеко не сразу.
Т.е. такой программист применим только для задач типа: сделал — получил результат — выбросил код. Ну или задач в которых код никогда не меняется и не поддерживается (а такие бывают?). Иначе либо вам искать еще таких же нестрадратных программистов, либо забыть о возможности расширить команду проекта которым занимался этот программисти, или передать этот проект другому без кардинальной переделки.
Т.е. такой программист применим только для задач типа: сделал — получил результат — выбросил код. Ну или задач в которых код никогда не меняется и не поддерживается (а такие бывают?). Иначе либо вам искать еще таких же нестрадратных программистов, либо забыть о возможности расширить команду проекта которым занимался этот программисти, или передать этот проект другому без кардинальной переделки.
Начнем с того что я не буду нанимать такого человека =) А даже если он запудрит мне мозги при собеседовании через месяц его уволят. Тем более что практически все проекты разрабатывают на фреймворках своих или чежих. И он сможет или писать код в стиле фреймворка или не писать его вообще.
А с точки зрения мы наняли человека и пиши как хочешь то на любом языке можно писать непонятный и ужасный код. Непонятно почему вы упомянули только PHP. Ну да. На нем много говнокодеров. Но их элементарно отбраковывают. А на проекты всегда ставится определенный стандарт написания кода. Это общая проблема всех языков.
А с точки зрения мы наняли человека и пиши как хочешь то на любом языке можно писать непонятный и ужасный код. Непонятно почему вы упомянули только PHP. Ну да. На нем много говнокодеров. Но их элементарно отбраковывают. А на проекты всегда ставится определенный стандарт написания кода. Это общая проблема всех языков.
Я сам пишу на PHP, никаких холиваров. Просто ветка началась с «А не проще язык поменять?», а Вы начали приводить примеры насыщенности рынка программистами и области готовыми решениями. Я лишь уточнил что ни то что у такого программиста есть знания php, ни готовые решения в данном случае ничего не дадут, потому что он фактически пишет на своем языке. И лучше уже ему поменять язык, потому что тогда он хотя-бы будет не один такой уникум.
Речь ведь шла именно о смене языка программистом (раз уж ему нравится функциональное), а не проектом.
Речь ведь шла именно о смене языка программистом (раз уж ему нравится функциональное), а не проектом.
Скажу по себе: что в PHP есть возможности ФП я знал ещё во времена PHP3, и был готов с ними встретиться в чужом коде, хотя их использования избегал. Да даже сам использовал всякие array_* ради семантической частоты. И ни разу не составляло труда перевести его в термины for(each) или наоборот.
Имхо, человек который не может сопоставить «чистый» array_walk() c foreach (и наоборот) и обосновать свой выбор, звания PHP-программиста не достоин.
Имхо, человек который не может сопоставить «чистый» array_walk() c foreach (и наоборот) и обосновать свой выбор, звания PHP-программиста не достоин.
вы видите разницу между может разобраться и комфортно работать? я и в лапше, и в говнокоде способен разобраться, но это не значит что мне удобно будет развивать такой код. функциональное, это другой подход, способ мыслей, и перестраиваться на него только потому что кому-то скучно работать по логике языка, ну совершенно не хочется.
«Фейсбук написан на PHP» — лишь городская легенда.
Там очень много всего намешано, и даже для PHP они писали собственный компилятор в нативный код.
Там очень много всего намешано, и даже для PHP они писали собственный компилятор в нативный код.
UFO just landed and posted this here
Стоит. Разработчиков на Ruby, Python и Perl, к примеру, очень тяжело найти. И зарплаты у них в среднем выше.
Это из личного опыта, как со стороны соискателя, так и со стороны работодателя.
Это из личного опыта, как со стороны соискателя, так и со стороны работодателя.
Честно говоря для меня это выглядит как какой-то синтаксический ад:
use React\Curry;
array_map(Curry\bind('strpos', Curry\…(), 0, 1), ['foo', 'bar', 'baz']);
Так же как и заказ на Ruby, Python и Perl сложнее найти, а от этого и цены для заказчиков выше, то что на PHP будет разработано за 500$ и за 20$ в год работать, на других технологиях обойдется дороже.
UFO just landed and posted this here
Я сейчас в компании, где используют Perl. Вакансии типичные можно глянуть на reg.ru или masterhost.ru.
UFO just landed and posted this here
Странно. Ну год назад ведущему в .masterhost предлагали 150, если не ошибаюсь. Точно сказать не могу.
Касательно reg.ru, — у нас удаленка. Соответственно зарплата сильно зависит от места проживания.
Касательно reg.ru, — у нас удаленка. Соответственно зарплата сильно зависит от места проживания.
UFO just landed and posted this here
Думаю, это спорный вопрос. В любом случае диапазон по зарплате — легко можно изменить, было бы за что.
В Москве дорогое жильё, поэтому переезжать смысла нет.
UFO just landed and posted this here
20тр это довольно хреновое жилье в Москве.
UFO just landed and posted this here
Ну да за 35 уже нормальное жилье.
Но где тогда смысл? При разнице в 20тр вы получаете потерю в 15тр от зарплаты. Но получаете гораздо худшие условия для жизни. Особенно если дети есть. Москва не очень хороший город для жизни. Я бы стал рассматривать переезд в Москву при разнице в зарплате от 40 и выше.
Хотя все индивидуально. Кому то наоборот, кроме Москвы ничего не нужно.
Но где тогда смысл? При разнице в 20тр вы получаете потерю в 15тр от зарплаты. Но получаете гораздо худшие условия для жизни. Особенно если дети есть. Москва не очень хороший город для жизни. Я бы стал рассматривать переезд в Москву при разнице в зарплате от 40 и выше.
Хотя все индивидуально. Кому то наоборот, кроме Москвы ничего не нужно.
И как же при смене языка с PHP на Perl/Ruby/Python сможете претендовать на зарплату ведущему?
Вот интересно, почему удаленная зарплата зависит от места проживания.
А про Ruby, — типичные вакансии — на undev.ru
Очень люблю функциональщину, влюблен в Scala. Поэтому все время останавливаю себя от функциональных вызовов в php. Медленно это (в плане вызова функции). Опять же разнобой в порядках параметров в функциях (array_map,array_reduce), а до 5.3 вообще костыльно выглядели вызовы.
В 5.3 есть проблема в том, что в замыкание нельзя передать $this (появилось в 5.4), урезана работа с ассоциативными массивами (не добраться до ключей).
Но, вцелом, хоть что-то.
В 5.3 есть проблема в том, что в замыкание нельзя передать $this (появилось в 5.4), урезана работа с ассоциативными массивами (не добраться до ключей).
Но, вцелом, хоть что-то.
UFO just landed and posted this here
Что значит «не добраться до ключей»?
Colada не смотрели, случаем? Scala тут один из источников вдозновения.
Насчет функциональности — каким бы синтаксис не был, все полезно! Это круто! Мне этим JavaScript еще прет! А вот такой пипец всегда бесил.
$print = 'printf';
$print("Hello %s\n", 'World');
UFO just landed and posted this here
Ну очень вымученный пример. Почему не записать так?
function calculate_totals(array $cart, $vatPercentage)
{
$vat = $vatPercentage / (100 + $vatPercentage);
$gross = array_sum(array_map(function($position) {
return $position['price'] * $position['quantity'];
}, $cart));
return [
'gross' => $gross,
'tax' => $gross * $vat,
'net' => $gross * (1 - $vat),
];
}
Знаете в чем прикол?
Напишите эту логику на стороне БД, и работать иногда будет раз в 10-100 быстрее. :)
Иногда скорость важнее красоты
Напишите эту логику на стороне БД, и работать иногда будет раз в 10-100 быстрее. :)
Иногда скорость важнее красоты
Важнее всего — возможность дальнейшей поддержки и развития продукта. Покажите мне систему контроля версий для БД и нормальное IDE.
Система контроля версий — это система контроля версий файлов. Хоть вордовские документы храните.
Нет никаких проблем в ней хранить скрипты, которые разворачивают или альтерят базу. IDE тоже разные есть. Но вообще-то не так прямо там они и нужны. Пошагово запрос все равно не выполните.
Это верно. Но как показывает практика, как раз БД — самое оно для этого. Правильная схема данных и побольше ее грузить тем, чем должна заниматься — обработкой данных. Возможность изменить вычисления, поменять запросы и т.д. — в базе делаются гораздо быстрее и безопаснее, чем где-то в коде императивного языка.
Правда, надо и уметь писать запросы. Т.к. встречал такие проекты, где каждая хранимка утыкана ифами, циклами и тысячами строк.
Нет никаких проблем в ней хранить скрипты, которые разворачивают или альтерят базу. IDE тоже разные есть. Но вообще-то не так прямо там они и нужны. Пошагово запрос все равно не выполните.
Важнее всего — возможность дальнейшей поддержки и развития продукта
Это верно. Но как показывает практика, как раз БД — самое оно для этого. Правильная схема данных и побольше ее грузить тем, чем должна заниматься — обработкой данных. Возможность изменить вычисления, поменять запросы и т.д. — в базе делаются гораздо быстрее и безопаснее, чем где-то в коде императивного языка.
Правда, надо и уметь писать запросы. Т.к. встречал такие проекты, где каждая хранимка утыкана ифами, циклами и тысячами строк.
Система контроля версий — это система контроля версий файлов. Хоть вордовские документы храните.И что я с ними делать буду? Как мне быстро откатить какую-то правку в хранимках? Вытаскивать файл, сочинять ALTER? Ерунда же полная.
IDE нужны, конечно. Посмотреть что куда ссылается, навигация между хранимками, триггерами, отладка и прочее. Нет таких IDE. После какого-нибудь Visual Studio посмотришь на IDE для БД, кажется, что в прошлый век попал.
99% времени жизни проекта нормальной сложности — его поддержка, скорость работы это хорошо, но 99% времени нужно быстро фиксить баги и дописывать к старому что-то новое. А тут у БД полный ад с этим.
Да есть и IDE и которые на себя откаты берут.
Правда, я не такой уже и базовик, чтобы знать их. Для майкрософт просто мне достаточно Management Studio. Есть в VS тоже, получше. Правда в дорогой версии Ultimate. Но если пользоваться пиратской — без разницы. И та и другая поддерживают навигацию.
Есть получше. Не пользовался, но базовики пользуются ERwin.
Это всё верно. Но как раз критика БД не к месту. Обычно, просто люди пишут коряво скрипты и запросы, а потом жалуются, что там ад. Как минимум, почти как факт надо воспринимать, что любой запрос, даже очень сложный, пишется за час-два. При правильной схеме это значит, что почти любое требование вы реализовываете за час-два. Это скорость разработки. Почему так получается? Потому что код более емкий информационно и меньше шансов ошибиться, попасть в бесконечный цикл почти невозможно, переполнить стек не возможно.
А писать на каком-то императивном языке с развитым IDE с возможностью дебажить (в БД такие IDE тоже есть) — это все равно что писать неизменяемый, опасный код, в котором всё пишется с нуля, куча решается проблем, не связанных с задачей, а значит и много много багов — но зато, можно в этих багах с удовольствием копаться.
Скрипты и БД — настолько просто всё, что даже при полном отсутствии IDE и средств для сохранения в системе контроля версий или при отсутствии средств для написания юнит-тестов — это все можно сделать/настроить за один /два дня.
Ад с БД встречается и часто. Но это не БД виновато, а руки кривые. В большинстве случаев программы пишут программисты, у которых SQL не является хорошо проработан. Поэтому, получается в базе говнокод. И сталкиваясь с этим, программисты стараются как можно больше логики писать на своем языке, перетягивая одеяло у СУБД. Последние разрабатывают, как сервера, для обработки данных, оптимизируют, обычно включают мощные средства авторизации — полноценный сервер. А программисты все же поверх него говнокодистый сервер пишут всегда, разрушая строгие проверки целостности данных, пишут свой механизм транзакций, дублируют данные (кешируют). Короче, дописывают такой же по задачам только хиленький сервер.
Правда, я не такой уже и базовик, чтобы знать их. Для майкрософт просто мне достаточно Management Studio. Есть в VS тоже, получше. Правда в дорогой версии Ultimate. Но если пользоваться пиратской — без разницы. И та и другая поддерживают навигацию.
Есть получше. Не пользовался, но базовики пользуются ERwin.
99% времени жизни проекта нормальной сложности — его поддержка, скорость работы это хорошо, но 99% времени нужно быстро фиксить баги и дописывать к старому что-то новое. А тут у БД полный ад с этим.
Это всё верно. Но как раз критика БД не к месту. Обычно, просто люди пишут коряво скрипты и запросы, а потом жалуются, что там ад. Как минимум, почти как факт надо воспринимать, что любой запрос, даже очень сложный, пишется за час-два. При правильной схеме это значит, что почти любое требование вы реализовываете за час-два. Это скорость разработки. Почему так получается? Потому что код более емкий информационно и меньше шансов ошибиться, попасть в бесконечный цикл почти невозможно, переполнить стек не возможно.
А писать на каком-то императивном языке с развитым IDE с возможностью дебажить (в БД такие IDE тоже есть) — это все равно что писать неизменяемый, опасный код, в котором всё пишется с нуля, куча решается проблем, не связанных с задачей, а значит и много много багов — но зато, можно в этих багах с удовольствием копаться.
Скрипты и БД — настолько просто всё, что даже при полном отсутствии IDE и средств для сохранения в системе контроля версий или при отсутствии средств для написания юнит-тестов — это все можно сделать/настроить за один /два дня.
Ад с БД встречается и часто. Но это не БД виновато, а руки кривые. В большинстве случаев программы пишут программисты, у которых SQL не является хорошо проработан. Поэтому, получается в базе говнокод. И сталкиваясь с этим, программисты стараются как можно больше логики писать на своем языке, перетягивая одеяло у СУБД. Последние разрабатывают, как сервера, для обработки данных, оптимизируют, обычно включают мощные средства авторизации — полноценный сервер. А программисты все же поверх него говнокодистый сервер пишут всегда, разрушая строгие проверки целостности данных, пишут свой механизм транзакций, дублируют данные (кешируют). Короче, дописывают такой же по задачам только хиленький сервер.
Чудовищное поделие этот ERWin.
Вы так говорите, как будто БД сразу с пользователем взаимодействует. Как только программисты уровнем выше придут в первый же раз выяснять отношения, сразу начнутся костыли и прочие прелести. И опять будет ад. Именно ещё и поэтому проще не разделять приложение на две части, а писать сразу логику на уровень выше.
Вы так говорите, как будто БД сразу с пользователем взаимодействует. Как только программисты уровнем выше придут в первый же раз выяснять отношения, сразу начнутся костыли и прочие прелести. И опять будет ад. Именно ещё и поэтому проще не разделять приложение на две части, а писать сразу логику на уровень выше.
Это зависит от программистов.
Да, сейчас есть проблемы. Проблемы с кадрами в первую очередь. Знания людей влияют на разработку в целом. Если не хватает ума написать запрос, то обычно в коде программиста и на уровень выше будет редкий говнокод, размазанный ровным слоем по куче файлов и классов.
Спорить начинать не хочу на эту тему, про частности, про СУБД. А просто про нечто в вакууме скажу. Логика, написанная на уровень выше — не что иное, как конкурирующий сервер с тем, что ниже. Люди пишут велосипедище, причем опасное, с мегакостылями. Например, в базе данных декларативно моделируют с помощью связей — как должна проверяться целостность данных. Таким образом формируют некоторую модель предметной области. Но программистам на уровень выше — не нравится такая строгость и делают свой сервер, который ослабляет проверки или вообще уничтожает. Доходит до того, что думают, что СУБД вообще должна только хранить данные. Чушь несусветная. Если бы было так, зачем деньги тратить на СУБД? Оплачивать работу разработчиков оракла, майкрософта, которая вам не нужна? Если нужно только хранить данные — есть файловая система.
Вообще, принципиально, данные не должны дублироваться. Они должны быть в одном месте — один источник. Как бы есть принцип правильной разработки — не дублировать код, не дублировать данные. Когда люди пишут на уровень выше, то по сути, они дубрируют данные, создают механизмы синхронизации. Плохо всё это.
Данные и их обработка должны быть как можно ближе. Просто помечтайте, что СУБД не состояла бы из таблиц, а состояла из объектов и язык был бы ваш любимый (PHP, Java, C#). Вы бы и в этом случае выносили работу еще в один сервер сверху? Скорее нет. Теперь двигаемся на шаг дальше в воображении: такой гипотетический сервер на любимом императивном языке имеет смысл, если бы он мегаускорял работу с данными. Т.е. вы пишете на своем языке, а он умеет оптимизировать обработку большого объема данных. Хорошо было бы, но это невозможно в императивных языках. Тогда, дальше пытаемся представить: нужен какой-то язык, который бы ограничил работу как-то декларативно, чтобы сервер мог брать на себя работу.
Вот такой язык и есть SQL. Он ограничен, но благодаря этому, он позволяет легко изменять вычисления при любом требовании. Императивные (ООП) языки сделаны по принципу — пишем опасный код, который всё может, но чтобы смогли контролировать баги при росте объема кода — скрываем код — за функциями, за классами. Реляционные БД сделаны по другому принципу — создаем декларативно отношения, создаем ограниченный язык, который можно применять ко всем данным открыто, не боясь что-то сломать. Это функциональный подход по сути.
SQL не идеален. Возможно, будут более лучшие языки и сервера в будущем. Но методологически, неправильно думать, что правильно писать логику где-то еще.
А сейчас, пока будущее не наступило, приходится действовать по обстоятельствах. Смотря в чем коллектив более опытный.
Да, сейчас есть проблемы. Проблемы с кадрами в первую очередь. Знания людей влияют на разработку в целом. Если не хватает ума написать запрос, то обычно в коде программиста и на уровень выше будет редкий говнокод, размазанный ровным слоем по куче файлов и классов.
Спорить начинать не хочу на эту тему, про частности, про СУБД. А просто про нечто в вакууме скажу. Логика, написанная на уровень выше — не что иное, как конкурирующий сервер с тем, что ниже. Люди пишут велосипедище, причем опасное, с мегакостылями. Например, в базе данных декларативно моделируют с помощью связей — как должна проверяться целостность данных. Таким образом формируют некоторую модель предметной области. Но программистам на уровень выше — не нравится такая строгость и делают свой сервер, который ослабляет проверки или вообще уничтожает. Доходит до того, что думают, что СУБД вообще должна только хранить данные. Чушь несусветная. Если бы было так, зачем деньги тратить на СУБД? Оплачивать работу разработчиков оракла, майкрософта, которая вам не нужна? Если нужно только хранить данные — есть файловая система.
Вообще, принципиально, данные не должны дублироваться. Они должны быть в одном месте — один источник. Как бы есть принцип правильной разработки — не дублировать код, не дублировать данные. Когда люди пишут на уровень выше, то по сути, они дубрируют данные, создают механизмы синхронизации. Плохо всё это.
Данные и их обработка должны быть как можно ближе. Просто помечтайте, что СУБД не состояла бы из таблиц, а состояла из объектов и язык был бы ваш любимый (PHP, Java, C#). Вы бы и в этом случае выносили работу еще в один сервер сверху? Скорее нет. Теперь двигаемся на шаг дальше в воображении: такой гипотетический сервер на любимом императивном языке имеет смысл, если бы он мегаускорял работу с данными. Т.е. вы пишете на своем языке, а он умеет оптимизировать обработку большого объема данных. Хорошо было бы, но это невозможно в императивных языках. Тогда, дальше пытаемся представить: нужен какой-то язык, который бы ограничил работу как-то декларативно, чтобы сервер мог брать на себя работу.
Вот такой язык и есть SQL. Он ограничен, но благодаря этому, он позволяет легко изменять вычисления при любом требовании. Императивные (ООП) языки сделаны по принципу — пишем опасный код, который всё может, но чтобы смогли контролировать баги при росте объема кода — скрываем код — за функциями, за классами. Реляционные БД сделаны по другому принципу — создаем декларативно отношения, создаем ограниченный язык, который можно применять ко всем данным открыто, не боясь что-то сломать. Это функциональный подход по сути.
SQL не идеален. Возможно, будут более лучшие языки и сервера в будущем. Но методологически, неправильно думать, что правильно писать логику где-то еще.
А сейчас, пока будущее не наступило, приходится действовать по обстоятельствах. Смотря в чем коллектив более опытный.
Вы так говорите, как будто у SQL альтернатив нет. Я вам обратную ситуацию скажу, выкидываете SQL и общаетесь с хранилищем без него из своего любимого языка программирования. Почему бы не так?
Альтернативы SQL конечно, есть. Но нет пока распространенных таких СУБД.
Так я вам эту ситуацию и описал выше.
В чем проблемы такого подхода? В языках.
1. Если вы выбрасываете SQL и общаетесь с реляционной СУБД как с хранилищем, то вы по сути вообще СУБД не пользуетесь. Мне нравится аналогия — купили очень дорогой, последней модели, танк. Привязали тачку и возите на нем копья. SQL — это то, зачем по сути создан сервер — это язык для обработки данных. Для обработки, очевидно, они и создаются. Иначе с чего бы так люди парились по поводу оптимизаций серверов.
Если вы хотите использовать СУБД как хранилище, тогда вам файловой системы более чем достаточно. Страшно, что в случае аварии данные потеряются? Так они и будут теряться в случае использования реляционной СУБД и вашей отдельной прослойки (пока данные не сохранятся в СУБД)
Сделать какую-то фиксацию на случай сбоя электричества в случае вообще нет никаких проблем. Только для этого нужна реляционная СУБД? Тогда нет никакой логики в покупке дорогих и даже дешевых СУБД.
Да, можно создать такую систему, в которой логика на «любимом» языке, а за ним хранилище. Только, по сути, вы создаете с нуля СУБД. Это и есть велосипед. Что такое транзакции в такой СУБД? На плечи программиста ложится. Что такое целостность данных? Что будет, если к одному и тому же по смыслу экземпляру начнут обращаться с разных потоков разные клиенты? На плечи программистов. Дедлоки? На плечи программистов. И т.д. Вы полностью создаете СУБД. Доказывать не буду, что она никогда не сравнится по безопасности с теми дорогими СУБД. Там команды состоят из неглупых людей.
Чем еще плох подход, когда пишут на хранилище. Тем, что у вас задача «купить хлеб», а не построить хлебный магазин и купить в нем хлеб.
2. Если любимый язык не императивный, там уже возможны варианты.
Я не сверхсторонник реляционных баз данных и языка SQL. Альтернативы скорее всего будут, в скором времени появятся. Идея в воздухе давно висит. Не выстреливает пока из-за того, что большинство программистов сидят на игле ООП и считают, что именно ООП — правильно и такие возможно должны быть сервера. ООП с++-ного типа не очень клеится к надежности с одной стороны, а с другой не очень клеится с самой возможностью создать такой сервер, который брал на себя работу по обработке данных. А если такой сервер не будет брать на себя хотя бы часть работы, то это и не сервер вообще, а файловая система с компилятором
Я вам обратную ситуацию скажу, выкидываете SQL и общаетесь с хранилищем без него из своего любимого языка программирования. Почему бы не так?
Так я вам эту ситуацию и описал выше.
В чем проблемы такого подхода? В языках.
1. Если вы выбрасываете SQL и общаетесь с реляционной СУБД как с хранилищем, то вы по сути вообще СУБД не пользуетесь. Мне нравится аналогия — купили очень дорогой, последней модели, танк. Привязали тачку и возите на нем копья. SQL — это то, зачем по сути создан сервер — это язык для обработки данных. Для обработки, очевидно, они и создаются. Иначе с чего бы так люди парились по поводу оптимизаций серверов.
Если вы хотите использовать СУБД как хранилище, тогда вам файловой системы более чем достаточно. Страшно, что в случае аварии данные потеряются? Так они и будут теряться в случае использования реляционной СУБД и вашей отдельной прослойки (пока данные не сохранятся в СУБД)
Сделать какую-то фиксацию на случай сбоя электричества в случае вообще нет никаких проблем. Только для этого нужна реляционная СУБД? Тогда нет никакой логики в покупке дорогих и даже дешевых СУБД.
Да, можно создать такую систему, в которой логика на «любимом» языке, а за ним хранилище. Только, по сути, вы создаете с нуля СУБД. Это и есть велосипед. Что такое транзакции в такой СУБД? На плечи программиста ложится. Что такое целостность данных? Что будет, если к одному и тому же по смыслу экземпляру начнут обращаться с разных потоков разные клиенты? На плечи программистов. Дедлоки? На плечи программистов. И т.д. Вы полностью создаете СУБД. Доказывать не буду, что она никогда не сравнится по безопасности с теми дорогими СУБД. Там команды состоят из неглупых людей.
Чем еще плох подход, когда пишут на хранилище. Тем, что у вас задача «купить хлеб», а не построить хлебный магазин и купить в нем хлеб.
2. Если любимый язык не императивный, там уже возможны варианты.
Я не сверхсторонник реляционных баз данных и языка SQL. Альтернативы скорее всего будут, в скором времени появятся. Идея в воздухе давно висит. Не выстреливает пока из-за того, что большинство программистов сидят на игле ООП и считают, что именно ООП — правильно и такие возможно должны быть сервера. ООП с++-ного типа не очень клеится к надежности с одной стороны, а с другой не очень клеится с самой возможностью создать такой сервер, который брал на себя работу по обработке данных. А если такой сервер не будет брать на себя хотя бы часть работы, то это и не сервер вообще, а файловая система с компилятором
Если вы выбрасываете SQL и общаетесь с реляционной СУБД как с хранилищем, то вы по сути вообще СУБД не пользуетесьЯ про реляционные СУБД и не говорил, а потом пусть даже реляционные. SQL не единственный язык для этого.
Остальное я не понял. Какая файловая система, о чём вы (кстати, файловые системы тоже кластерные бывают, ничего на них у вас не потеряется, так же посмотрите что такое «дисковые полки»)? Какие велосипеды? «Альтернативы скорее всего будут»? Вы NOSQL никогда не видели что ли? Им лет-то больше, чем реляционным с SQL, сейчас новая волна популярности как раз, среди NOSQL есть и реляционные, для работы с графами, например, Neo4J, вполне себе «реляции», только сетевые.
Просто реляционные СУБД пока лидируют и я их как образец и представляю.
Работаете на PHP/C#/Java/C++ с любой СУБД как с хранилищем, я-ля «дай мне объект с таким айди», то вы будете в своем любимом языке реализовывать все прелести СУБД (реляционных, например, в которых уже это реализовано).
Работаете на PHP/C#/Java/C++ с любой СУБД как с хранилищем, я-ля «дай мне объект с таким айди», то вы будете в своем любимом языке реализовывать все прелести СУБД (реляционных, например, в которых уже это реализовано).
про NoSql я пока говорить не хочу. То в большинстве случаев просто огрызки функциональности реляционных СУБД. В угоду оптимизациям. Велосипедостроители побеждают — количество переходит в качество. Вот и волна популярности.
Про файловую систему, как мне казалось, всё понятно. Что есть транзакция? То, что в файловой системе сохранится и не потеряется, не спорю, это проблемы файловой системы. А вот согласованность данных в этой файловой системе проблемы СУБД. Если уже настолько тупая СУБД, что она только скидывает данные и поднимает, то по крайней мере надо реализовать транзакцию записи одного объекта. Потому как сбой может произойти «в процессе». И файл не будет иметь нужную структуру.
Так вот, сделать такую СУБД — работа порядка часов. Удивляет, когда для этого используют реляционную СУБД и со святой уверенностью утверждают, что так и должна выглядеть правильная архитектура.
Про файловую систему, как мне казалось, всё понятно. Что есть транзакция? То, что в файловой системе сохранится и не потеряется, не спорю, это проблемы файловой системы. А вот согласованность данных в этой файловой системе проблемы СУБД. Если уже настолько тупая СУБД, что она только скидывает данные и поднимает, то по крайней мере надо реализовать транзакцию записи одного объекта. Потому как сбой может произойти «в процессе». И файл не будет иметь нужную структуру.
Так вот, сделать такую СУБД — работа порядка часов. Удивляет, когда для этого используют реляционную СУБД и со святой уверенностью утверждают, что так и должна выглядеть правильная архитектура.
Вы про NOSQL не хотите говорить, а я не хочу хранить данные в файловой системе. Зачем мне это, есть есть какой-нибудь Riak.
Ну и NOSQL бывают сильно сложнее, чем «вытащить объект по ID».
Ну и NOSQL бывают сильно сложнее, чем «вытащить объект по ID».
Вы про NOSQL не хотите говорить, а я не хочу хранить данные в файловой системе. Зачем мне это, есть есть какой-нибудь Riak.
Не равносильный обмен. Я ни в коем случае не говорил, что надо писать велосипед, вроде своего хранилища. Я просто намекнул, что хранилище можно написать в зависимости от простоты от полудня до двух дней. И приводил этот пример для того случая, когда люди «создают архитектуру» на серьезных реляционных СУБД, доводя работу с ними до абсурда.
Тут логика разговора была такая: реляционные СУБД <-> NoSql (как обрезанный функционал) <-> самодельное файловое хранилище. Которое, часто, мало чем от не самодельного будет отличаться.
Т.е. вы не хотите писать велосипед на файловой системе. Это хорошо. Зато собираетесь писать велосипед из транзакций, поддержки целостности данных.
Ну и NOSQL бывают сильно сложнее, чем «вытащить объект по ID»
Конечно. Только они, повторюсь, в большей части — просто огрызки из функционала. Да, иногда это надо. Иногда под некоторые задачи.
Будете смеяться, но именно в это время я пишу свой собственный нереляционный сервер для обработки данных. Но опыт написания уже не первого мне как раз говорит: не фиг их в абсолютном большинстве писать. Там в реляционных много есть вещей, далеко не простых, уже реализованных.
Нереляционные СУБД — это видимо от нефиг делать, от недостатка романтики в жизни программистов. Программисты вдруг вспоминают, что они могут еще и алгоритмы писать. И давай где надо и где не надо писать велосипеды. Даже мода появилась. Чуть ли не каждый второй разработчик «бизнес-приложений» мнит себя разработчиком высоконагруженной системы. А мега объем для его воображения — 100 пользователей и 100 000 записей в таблице.
Нереляционные решения — это инструменты, которые нужны в редких задачах. Твитер не каждый разрабатывает. И такое повальное желание всех что-то такое написать — неоправданно. Поезд ушел.
Нереляционные решения — это либо для датамайнинга, либо для несложных, но высоконагруженных систем. Ключевое слово — несложных, вроде какой-то социальной сети.
Когда появляется мода, инструменты узкого назначения начинают тыкать куда надо и куда не надо. Реляционные СУБД достаточно универсальны и нужны всегда серьезные основания, чтобы выбрать другие решения.
И конечно, нереляционные решения бывают сложнее чем файловое хранилище. Но мы то как раз говорили о модели — на любимом языке писать логику, а сервер — хранилище.
Какой-то у вас подозрительный взгляд на NOSQL. С чего бы талантливым ребятам из Яндекса писать своё хранилище Elliptics вот уже несколько лет тогда? Я немного знаком был с проблемами, которые там встречались, двумя днями там и не пахло.
Ну и взгляд на нереляционные БД странный до невозможности. Это не от нефиг делать, у этого инструмента есть своя чёткая ниша. В частности, в какой-нибудь «Монге» я могу хранить документы с произвольным набором полей, это крайне удобно и такая потребность часто встречается в программах докуменооборота, например.
Или вот, как хранить и обрабатывать граф в реляционных БД? Помрёшь же сколько надо всего написать.
Ну и, например ещё, где хранить кеш как в нереляционных БД, к примеру?
Таких ниш — несколько больше, чем я перечислил.
Ну и взгляд на нереляционные БД странный до невозможности. Это не от нефиг делать, у этого инструмента есть своя чёткая ниша. В частности, в какой-нибудь «Монге» я могу хранить документы с произвольным набором полей, это крайне удобно и такая потребность часто встречается в программах докуменооборота, например.
Или вот, как хранить и обрабатывать граф в реляционных БД? Помрёшь же сколько надо всего написать.
Ну и, например ещё, где хранить кеш как в нереляционных БД, к примеру?
Таких ниш — несколько больше, чем я перечислил.
Нет, не подозрительный. Мы просто пережевываем тему — а почему бы БД не быть просто хранилищем, а нам не писать свою логику. Вот, хранилище делается за пару дней.
Даже и графы. Нет ничего сложного там, где надо потом допиливать руками.
Вот про талантливых ребят и Яндекса — пойдет. Но, все прямо у нас разработчики Яндекса. Яндекс, как и Гугл — у них есть узкая ниша — вебмайнинг. Как раз написать базу такую, как основу, можно за пару дней. А потом несколько лет трахаться с алгоритмами, пытаясь найти лучшие, чтобы соорудить класстеризации, классификации, релевантный поиск. Там не с базой проблемы.
Граф хранить и обрабатывать в реляционных БД, можно. Хотя сложно и они неоптимально это будут делать. Тут от задачи зависит. Подозрительно, когда по умолчанию берут и выбирают базу на графах, просто так, потому что так удобно.
Как минимум, в приложениях для бизнеса с ходу назову пару проблем, с которыми точно столкнетесь. На какой нибудь Монге храните документы, которая удобна для этого. А деньги, обработку других данных, на реляционной. Точно, на Монге это будет менее удобно. Завтра приходит заказчик и говорит:
— А мне захотелось, чтобы мы получили графики, как зависит наша прибыль от документооборота.
И всё. Теперь возникла почти нерешаемая проблема. Вопрос: заказчик дурак, не понимает, что лучше хранить документооборот в Монго, даже если потом данные нельзя вместе обрабатывать?
Данные, разделенные на разные базы — тоже очень нехорошо. Сейчас важна универсальность и скорость разработки. Границ между данными быть не должно, иначе сильно плохо влияет на возможность быстрых изменений. На Монго написать всё тогда. А всё — это значит половина функционала реляционной СУБД руками пишется. А это также значит, если всё в Монго, что в случае нового пришествия заказчика, будете не пару часов на запрос просить, а полгода на переделку. Потому что не так планировали связи между данными и т.д.
В общем есть ниша у NoSql, единственное, его пихают везде.
Даже и графы. Нет ничего сложного там, где надо потом допиливать руками.
Вот про талантливых ребят и Яндекса — пойдет. Но, все прямо у нас разработчики Яндекса. Яндекс, как и Гугл — у них есть узкая ниша — вебмайнинг. Как раз написать базу такую, как основу, можно за пару дней. А потом несколько лет трахаться с алгоритмами, пытаясь найти лучшие, чтобы соорудить класстеризации, классификации, релевантный поиск. Там не с базой проблемы.
Граф хранить и обрабатывать в реляционных БД, можно. Хотя сложно и они неоптимально это будут делать. Тут от задачи зависит. Подозрительно, когда по умолчанию берут и выбирают базу на графах, просто так, потому что так удобно.
Как минимум, в приложениях для бизнеса с ходу назову пару проблем, с которыми точно столкнетесь. На какой нибудь Монге храните документы, которая удобна для этого. А деньги, обработку других данных, на реляционной. Точно, на Монге это будет менее удобно. Завтра приходит заказчик и говорит:
— А мне захотелось, чтобы мы получили графики, как зависит наша прибыль от документооборота.
И всё. Теперь возникла почти нерешаемая проблема. Вопрос: заказчик дурак, не понимает, что лучше хранить документооборот в Монго, даже если потом данные нельзя вместе обрабатывать?
Данные, разделенные на разные базы — тоже очень нехорошо. Сейчас важна универсальность и скорость разработки. Границ между данными быть не должно, иначе сильно плохо влияет на возможность быстрых изменений. На Монго написать всё тогда. А всё — это значит половина функционала реляционной СУБД руками пишется. А это также значит, если всё в Монго, что в случае нового пришествия заказчика, будете не пару часов на запрос просить, а полгода на переделку. Потому что не так планировали связи между данными и т.д.
В общем есть ниша у NoSql, единственное, его пихают везде.
Миграции как система контроля версий БД и были придуманы.
Современные IDE умеют работать с SQL, какие Вам нужны еще фичи?)
Полностью согласен что переносить логику в БД ужасная идея:-)
Современные IDE умеют работать с SQL, какие Вам нужны еще фичи?)
Полностью согласен что переносить логику в БД ужасная идея:-)
А как на счет масштабируемости? Базу масштабировать сложнее, чем аппликейшен сервера обращающиеся к ней, соответственно базу лучше грузить по минимуму.
PHP всегда был простым, процедурным языком программирования, черпавшим свое вдохновение из C и Perl..
правда, он всё не так понял, и в итоге стал таким какой есть. Ни Си, ни Perl и рядом с этим г. не стояли. так что, слишком много чести сравнивать его с этими великими языками.
пхп-киддисы, минусуйте, я жду.
«Шуруп, забитый молотком, держится лучше, чем гвоздь, закрученный отверткой» (ц)
Ради чего надо «функционально программировать на PHP», если код от этого становится и запутаннее, и медленнее?
А «трюки» типа
Ради чего надо «функционально программировать на PHP», если код от этого становится и запутаннее, и медленнее?
А «трюки» типа
$controller = new IndexController();
$action = $_GET['action'] . 'Action';
$controller->$action();
$_GET['action'] какой-нибудь private_method%00Нет, ну если just for fun, то пожалуйста, но надеюсь никому не придет в голову применять это в реальном долгосрочном и/или командном проекте. Да вот за такое:
use React\Curry;
array_map(Curry\bind('strpos', Curry\…(), 0, 1), ['foo', 'bar', 'baz']);
другие разработчики, не функциональщики, проклянут. Фактически на другом языке написано. Язык ведь это не только синтаксис, это его логика, подходы. Это позволяет нескольким разработчикам знающим 1 язык работать вместе. Да человеку незнакомому с С# например, но хорохо знающему PHP, проще будет прочитать код на С# чем разобратся вот в таком «php». Хочещь быть функциональщиком, используй языки изначально под это заточенные. А тут получается что разработчик либо всегда работает один и над проектами которые не могут достатся другому программисту, либо ему нужно в команду таких же функциональщиков на php. И тот и другой случай практически нереален. Ну это если по правильному, есть конечно же еще вариант когда человек пишет как ему нравится, а на остальное наплевать.
use React\Curry;
array_map(Curry\bind('strpos', Curry\…(), 0, 1), ['foo', 'bar', 'baz']);
другие разработчики, не функциональщики, проклянут. Фактически на другом языке написано. Язык ведь это не только синтаксис, это его логика, подходы. Это позволяет нескольким разработчикам знающим 1 язык работать вместе. Да человеку незнакомому с С# например, но хорохо знающему PHP, проще будет прочитать код на С# чем разобратся вот в таком «php». Хочещь быть функциональщиком, используй языки изначально под это заточенные. А тут получается что разработчик либо всегда работает один и над проектами которые не могут достатся другому программисту, либо ему нужно в команду таких же функциональщиков на php. И тот и другой случай практически нереален. Ну это если по правильному, есть конечно же еще вариант когда человек пишет как ему нравится, а на остальное наплевать.
Где бенчмарки? Иначе этодемагогия. Первый код скорее всего самый быстрый.
Sign up to leave a comment.
Функциональное программирование на PHP