Comments 64
Всегда удивлялся авторам-изобретателям таких постов.
Попробуйте реализовать ещё генетическое программирование. Там весьма интересные результаты иногда получаются!
Спасибо Вам за идею. Я уже кое-что пробовал :-) Если эти два решения скрестить, то, как раз, получим Santa Fe Trail
а начальные значения весов генерятся случайно?
еще вопрос вдогонку -)
у вас на вход сети подаются данные с датчиков, о еде и о других агентах
а о скольки других агентах идет речь? ведь как я понимаю топология сети фиксирована, определенное число входных нейронов, скрытых слоев и 2 выходных нейрона. возможно речь идет об одном ближайшем другом агенте.
у вас на вход сети подаются данные с датчиков, о еде и о других агентах
сигнал о наличии других агентов поблизости (и соответственно — расстояние и косинус угла между направлением нашего агента и вектором направленным к другому агенту)
а о скольки других агентах идет речь? ведь как я понимаю топология сети фиксирована, определенное число входных нейронов, скрытых слоев и 2 выходных нейрона. возможно речь идет об одном ближайшем другом агенте.
Как я отмечал в начале статьи — у меня нету жёстко заданной топологии сети. Фиксированное только количество нейронов
Я экспериментировал, подавая на вход нейронной сети информацию как про одного так и про нескольких (2 и 3) ближайших агентов. Внешне — результаты довольно похожи.
На видео, можно заметить, когда агенты передвигаются стайками, то некоторые из них разворачиваются и начинают двигаться в противоположном направлении — вот так, косвенно, можно наблюдать взаимное влияние агентов
Я экспериментировал, подавая на вход нейронной сети информацию как про одного так и про нескольких (2 и 3) ближайших агентов. Внешне — результаты довольно похожи.
На видео, можно заметить, когда агенты передвигаются стайками, то некоторые из них разворачиваются и начинают двигаться в противоположном направлении — вот так, косвенно, можно наблюдать взаимное влияние агентов
у меня нету жёстко заданной топологии сети
т.е. это не многослойный персептрон Румельхарта, а сеть вообще с произвольной топологией?
upd: упс, не в тот уровень ответил -)
Введите небольшие штрафные баллы за пройденное расстояние — агенты станут значительно спокойнее двигаться.
Следующий шаг — ещё меньшие штрафные баллы за накопленный угол поворота — чтобы они не крутились туда-сюда.
Мне кажется, станет плавнее и сильно реалистичнее!
Следующий шаг — ещё меньшие штрафные баллы за накопленный угол поворота — чтобы они не крутились туда-сюда.
Мне кажется, станет плавнее и сильно реалистичнее!
Способность агента получать информацию о среде ограничивается «областью видимости» — грубо говоря, агент может видеть только впереди себя.
Спасибо за Вашу идею, но по этому поводу у меня немного иная точка зрения:
Такое поведение является эффективным, поскольку всегда есть вероятность, что, пока агент приближается к цели, то какой-нибудь другой агент может съесть эту частицу еды, или на пути к цели появится новый кусочек еды, который можно съесть быстрее.
Когда агенты «крутятся» туда-сюда, то они, соответственно, имеют больший угол обзора окружающей среды, и есть шанс заметить появившийся рядом кусочек еды (а значит — собрать больше пищи). Я ещё картинку приводил
Мне кажется, «правильное» поведение при отсутствии легкодоступной еды — стоять и вращаться в одну сторону, чтобы ничего не пропустить, а сейчас даже старшие поколения просто смотрят из стороны в сторону.
Не факт, что это хорошо повлияет на их общую эффективность. Я писал подобную штуку, только с текстовой пошаговой игрой — игроки могли каждый ход выбрать одно из нескольких действий (атаковать мечом, атаковать магией, тратя ману, лечиться магией, опять же, тратя ману, пить зелье здоровья или пить зелье маны). Так вот, как только в фитнес-функцию включался коэффициент, обратный затраченным на победу ходам, начинали плодиться «зерги», то бишь особи, которые берсерком рвались в бой, сначала сливая всю ману на атаку, а потом добивая мечом.
Они проигрывали противникам, которые умели лечиться, но тех было мало, а общую массу они валили берсерком. Не совсем то, что я ожидал)
Когда штраф за время я убрал, в топ стали выбиваться более умные, а не более агрессивные.
Они проигрывали противникам, которые умели лечиться, но тех было мало, а общую массу они валили берсерком. Не совсем то, что я ожидал)
Когда штраф за время я убрал, в топ стали выбиваться более умные, а не более агрессивные.
Прикольно :) Насколько я понял, у вас были различные персонажи? Вы обучали интеллект каждого персонажа по отдельности, или всех вместе одновременно?
Я делал так же как и вы, по сути. Генерил начальную популяцию персонажей — все одинаковые по структуре, разные только веса у нейросетей, ими управляющих. На вход НС шли свои параметры (здоровье, мана, количество зелий) и такие же параметры противника. На выходе выдавалась команда на одно из возможных действий.
Дальше они рандомно сражались друг с другом, по результатам N сражений вычислялся фитнес индивидов. Потом скрещивание, мутация, и все по новой.
Из-за необходимости «матчей» обучение было долгим, но логи было очень интересно читать. По началу, допустим, все были тупы и повторяли одно и то же действие — то самое, на которое им эти рандомные веса указали. Среди таких быстро стали выбираться наверх те, у кого этим действием была «атака мечом». Спустя некоторое время они и доминировали, почти вся популяция таких накапливалась — поэтому чтобы выжить в таком окружении нужно было что-то еще. И резко наверх начинали вылезать те, кто, допустим, научился атаковать магией.
То есть эволюция такими ступеньками шла — выучил кто-то новую фишку, через некоторое время начинает доминировать такой вид, эволюция замедляется — все уже эту фишку знают. Появляется один с новой фишкой — и все по новой.
Самого мозговитого индивида (после нескольких часов обучения!) я сходу даже не мог победить)
Правда, игра была очень «синтетическая», интересно попробовать на какой-нибудь более интересной. Моя начальная идея была сделать нейробота для дуэлей в WoW. Не нагружать его перемещением по миру (это я и сам могу), а именно быстрым принятием решений о применении скиллов во время дуэли.
Дальше они рандомно сражались друг с другом, по результатам N сражений вычислялся фитнес индивидов. Потом скрещивание, мутация, и все по новой.
Из-за необходимости «матчей» обучение было долгим, но логи было очень интересно читать. По началу, допустим, все были тупы и повторяли одно и то же действие — то самое, на которое им эти рандомные веса указали. Среди таких быстро стали выбираться наверх те, у кого этим действием была «атака мечом». Спустя некоторое время они и доминировали, почти вся популяция таких накапливалась — поэтому чтобы выжить в таком окружении нужно было что-то еще. И резко наверх начинали вылезать те, кто, допустим, научился атаковать магией.
То есть эволюция такими ступеньками шла — выучил кто-то новую фишку, через некоторое время начинает доминировать такой вид, эволюция замедляется — все уже эту фишку знают. Появляется один с новой фишкой — и все по новой.
Самого мозговитого индивида (после нескольких часов обучения!) я сходу даже не мог победить)
Правда, игра была очень «синтетическая», интересно попробовать на какой-нибудь более интересной. Моя начальная идея была сделать нейробота для дуэлей в WoW. Не нагружать его перемещением по миру (это я и сам могу), а именно быстрым принятием решений о применении скиллов во время дуэли.
Однажды делал нечто подобное, только генетикой подбирал параметры типа сила, ловкость, здоровье итд. И тоже рулили берсерки с большой ловкость, большим damage и почти без защиты и с одним хит-поинтом
Значит, фитнес такой. В этом одна из проблем ген.алга, иногда трудно подобрать правильную фитнес-функцию.
Возможно, следует изменить условия состязания, например, чтобы не было уже такой «статистической» победы над общей массой, то есть учитывать не просто количество побед, а как-то классифицировать тех, кого персонаж победил, чтобы 100 побед на одним и тем же «тупым защищающимся» не превосходили победы над «осторожным хиллером», «агрессивным магом» и т.п.
Возможно, следует изменить условия состязания, например, чтобы не было уже такой «статистической» победы над общей массой, то есть учитывать не просто количество побед, а как-то классифицировать тех, кого персонаж победил, чтобы 100 побед на одним и тем же «тупым защищающимся» не превосходили победы над «осторожным хиллером», «агрессивным магом» и т.п.
Память агента.
Я бы попробовал пустить один дополнительный выход сети себе же на вход на следующей итерации. А то и несколько.
Пускай использует как хочет — часы, счётчик пройденного расстояния, признак режима погони — или всё вместе :-)
Я бы попробовал пустить один дополнительный выход сети себе же на вход на следующей итерации. А то и несколько.
Пускай использует как хочет — часы, счётчик пройденного расстояния, признак режима погони — или всё вместе :-)
Спасибо Вам за идею. Уже пробовал :-) Если схематически изобразить, то я реализовывал такую схему:
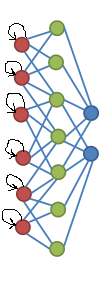
Такая структура позволяет «запоминать» предыдущие входные значение. Агенты, действительно, начинают меньше «смотреть по сторонам»

Такая структура позволяет «запоминать» предыдущие входные значение. Агенты, действительно, начинают меньше «смотреть по сторонам»
UFO just landed and posted this here
Это не совсем то, что мне кажется полезным.
Если всё что есть у агента — это показания «датчиков», то он может только реагировать. Вход-выход. «Одноклеточное» существо, живущее только сегодняшним днём. В вашей расширенной модели — ещё и вчерашним.
Однако, если агенту добавить произвольную память — он сможет составить план, или даже стратегию — вещи совершенно невозможные в чисто реактивной модели.
Готов спорить на пиво, что при наличии нескольких ячеек памяти, агент там будет хранить положение предыдущей, чуть дальней цели. Как только окажется, что текущую цель кто-то уже съел, агент уже будет знать, куда бежать за планом «б».
Если всё что есть у агента — это показания «датчиков», то он может только реагировать. Вход-выход. «Одноклеточное» существо, живущее только сегодняшним днём. В вашей расширенной модели — ещё и вчерашним.
Однако, если агенту добавить произвольную память — он сможет составить план, или даже стратегию — вещи совершенно невозможные в чисто реактивной модели.
Готов спорить на пиво, что при наличии нескольких ячеек памяти, агент там будет хранить положение предыдущей, чуть дальней цели. Как только окажется, что текущую цель кто-то уже съел, агент уже будет знать, куда бежать за планом «б».
А сколько итераций тогда давать на разрешение этой обратной связи? Состояния-то дискретные.
Одну? Две? N?
Одну? Две? N?
Не понял. Значение выхода «память» копируется из предыдущего хода в значение входа «вчерашняя память». Всё.
вот это имеется в виду если быть точным en.wikipedia.org/wiki/Recurrent_neural_network
Одну то есть.
Просто после того, как на вход поступит это значение из памяти, выходы снова изменятся — можно продолжать итеррировать до схождения к какому-нибудь устойчивому состоянию. Так делается, насколько я знаю, в сети хемминга.
Просто после того, как на вход поступит это значение из памяти, выходы снова изменятся — можно продолжать итеррировать до схождения к какому-нибудь устойчивому состоянию. Так делается, насколько я знаю, в сети хемминга.
Тут не нужно устойчивое состояние! Оно будет меняться каждйы раз
Просто ИНС может как-то использовать эти цифры при вычислении текущего хода.
Просто ИНС может как-то использовать эти цифры при вычислении текущего хода.
Спокойно. Я понимаю вашу идею, просто говорю, что это не единственная реализация.
Сеть Хемминга вполне себе обладает памятью, как и сеть Хопфилда — которая считается реализацией ассоциативной памяти. При этом у них обратная связь вычисляется до схождения к устойчивому состоянию. Нужно или не нужно тут устойчивое состояние вопрос спорный, т.к. обучение ведется ген.алгом и как сеть будет использовать эти цифры — неизвестно.
Сеть Хемминга вполне себе обладает памятью, как и сеть Хопфилда — которая считается реализацией ассоциативной памяти. При этом у них обратная связь вычисляется до схождения к устойчивому состоянию. Нужно или не нужно тут устойчивое состояние вопрос спорный, т.к. обучение ведется ген.алгом и как сеть будет использовать эти цифры — неизвестно.
кстати у этого обучения есть вполне нормальное название en.wikipedia.org/wiki/Reinforcement_learning
например один из способов обучения квадрокоптера — это нейросет с генетическим алгоритмом, где подкрепление (или же fitness function в нотации генетического алгоритма) ведется за счет считывания показаний скажем с гироскопа и корректировки положения коптера относительно земли
например один из способов обучения квадрокоптера — это нейросет с генетическим алгоритмом, где подкрепление (или же fitness function в нотации генетического алгоритма) ведется за счет считывания показаний скажем с гироскопа и корректировки положения коптера относительно земли
А можно ли отнести обучение ген. алгом к обучению с подкреплением? То есть формально — да, но вроде бы под последним обычно понимают прямую модификацию весов, или я ошибаюсь?
То есть не механизм с порождением большой популяции и отбором лучших.
То есть не механизм с порождением большой популяции и отбором лучших.
я бы смело отнес, википедия тоже относит
а чем «механизм с порождением большой популяции и отбором лучших» не прямая модификация? так же можно сказать что и градиентный спуск не очень то уж и прямая модификация, ведь надо сначала вычислить градиент, а в рекурентной сети так вообще шняга получается, вычислить для всех ячеек памяти а затем еще усреднить. то же ведь есть некторотая рутина перед модификацией. если рассмотреть ген алгоритм просто как функцию от вектора возвращающую вектор, то получается одно и то же
а чем «механизм с порождением большой популяции и отбором лучших» не прямая модификация? так же можно сказать что и градиентный спуск не очень то уж и прямая модификация, ведь надо сначала вычислить градиент, а в рекурентной сети так вообще шняга получается, вычислить для всех ячеек памяти а затем еще усреднить. то же ведь есть некторотая рутина перед модификацией. если рассмотреть ген алгоритм просто как функцию от вектора возвращающую вектор, то получается одно и то же
Возможно, просто как-то в памяти отложилось, что это разные вещи. Видимо от того, что понятие «обучение с подкреплением» более общее и не ограничивается тем подходом, что в ген.алге.
да, обучение с подкреплением более общее. а еще как то пошло в мире что генетические алгоритмы рассматриваются отдельно от скажем нейросетей. тому в принципе есть причина.
ген алгоритмы это крутой аппарат дискретной оптимизации, например для решения задачи коммивояжера они в последние года постоянно воюют с муравьиной колоние за лидерство, а нейросети только сейчас потихоньку приходят на более менее приемлимые результаты, хотя далеко от лидеров. см. машины больцмана и имитацию отжига
но ген алгоритмы не сильны в непрерывной оптимизации, где сильны градиентные или ньютоновские методы.
имхо нужно генетические операторы делать очень комплексными, например не просто мутация, а движение в сторону градиента целевой функции (если конечно такое возможно для конкретной фитнесс функции), в общем интересная и сложная тема =)
ген алгоритмы это крутой аппарат дискретной оптимизации, например для решения задачи коммивояжера они в последние года постоянно воюют с муравьиной колоние за лидерство, а нейросети только сейчас потихоньку приходят на более менее приемлимые результаты, хотя далеко от лидеров. см. машины больцмана и имитацию отжига
но ген алгоритмы не сильны в непрерывной оптимизации, где сильны градиентные или ньютоновские методы.
имхо нужно генетические операторы делать очень комплексными, например не просто мутация, а движение в сторону градиента целевой функции (если конечно такое возможно для конкретной фитнесс функции), в общем интересная и сложная тема =)
Про имитацию отжига знаю, про машины больцмана, к сожалению, только краем уха слышал — все хотел посмотреть повнимательнее на них. Тут где-то даже статья была, вроде.
Если мутацию делать направленной, то это может повлиять на область применения метода. Например, стандартную реализацию можно применить, когда фитнес-функция не выражена строго математически и ее градиент найти затруднительно. Вот как в том примере, что я приводил, с игрой — фитнес-функция вычислялась из статистики нескольких матчей, ее аналитическое выражение в данном случае невозможно.
Ген.Алги применяют еще в одном очень интересном направлении, генерят хардвар ими. Была статья про эксперимент, где обычным генетическим алгоритмом генерировалась прошивка для ПЛИС (то есть, по сути, связи между аппаратными ячейками), с целью создать прошивку, распознающую определенный тон.
Попытка увенчалась успехом, ген алг сгенерил такую прошивку. Когда стали ее разбирать, нашли много интересного — например, блоки, которые были ни с чем не соединены, но при попытке их убрать, прошивка переставала работать — то есть, похоже, что они влияли на уровне паразитных емкостей, индуктивностей и задержек распространения.
Если мутацию делать направленной, то это может повлиять на область применения метода. Например, стандартную реализацию можно применить, когда фитнес-функция не выражена строго математически и ее градиент найти затруднительно. Вот как в том примере, что я приводил, с игрой — фитнес-функция вычислялась из статистики нескольких матчей, ее аналитическое выражение в данном случае невозможно.
Ген.Алги применяют еще в одном очень интересном направлении, генерят хардвар ими. Была статья про эксперимент, где обычным генетическим алгоритмом генерировалась прошивка для ПЛИС (то есть, по сути, связи между аппаратными ячейками), с целью создать прошивку, распознающую определенный тон.
Попытка увенчалась успехом, ген алг сгенерил такую прошивку. Когда стали ее разбирать, нашли много интересного — например, блоки, которые были ни с чем не соединены, но при попытке их убрать, прошивка переставала работать — то есть, похоже, что они влияли на уровне паразитных емкостей, индуктивностей и задержек распространения.
да как раз я писал недавно про restricted Boltzmann machine http://habrahabr.ru/post/163819/ =)
но это все таки частный случай — ограниченные машины Больцмана, есть более общий вид где допустимы связи между видимыми и скрытыми нейронами
но это все таки частный случай — ограниченные машины Больцмана, есть более общий вид где допустимы связи между видимыми и скрытыми нейронами
Если я правильно понял — дискуссия о немного различных вещах: сети Хемминга и Хопфилда помогают запоминать конкретные шаблоны, а затем, подавая на вход данные, и прогоняя несколько итераций для схождения — на выходе получаем один из запомненных шаблонов (либо их комбинацию).
kosiakk предлагает запоминать значения, которые использовались для принятия решения на предыдущих шагах агента.
Также, следует учесть, что среда динамическая, поэтому сходимости в принятии решения, на протяжении нескольких шагов агента, вряд ли получится достичь.
Я попробую смоделировать такую сеть. Спасибо за идею
kosiakk предлагает запоминать значения, которые использовались для принятия решения на предыдущих шагах агента.
Также, следует учесть, что среда динамическая, поэтому сходимости в принятии решения, на протяжении нескольких шагов агента, вряд ли получится достичь.
Я попробую смоделировать такую сеть. Спасибо за идею
Я не говорю на нескольких шагах, хотя это тоже вариант. Я имел в виду на текущем шаге подать на вход памяти то значение, что было получено на прошлом. Далее итеррировать до устойчивого значения на выходе, которое станет значением для текущего шага.
Как-то так. Опять же, это просто один из вариантов реализации.
Как-то так. Опять же, это просто один из вариантов реализации.
Почему именно с выхода всей сети на вход?
Можел лучше просто скрытый слой сделать рекуррентным?
Можел лучше просто скрытый слой сделать рекуррентным?
А почему один слой? ИМХО, тут нельзя однозначно сказать, ведь этот выход не носит какой-то конкретный логический характер, как его будет юзать сеть в результате обучения ген.алгом — неизвестно.
кстати одного слоя достаточно, вообще есть теорема о том что одного скрытого слоя достаточно для аппроксимации абсолютно любой зависимости (конечно при достаточном количестве скрытых нейронов =)
глубокие сети используются для того что бы минимизировать количество параметров, но увеличить качество работы сети.
все же при сети прямого распространения, каждый скрытый слой формирует некоторые иерархические фичи, ну и считается что чем плодить кучу фич первого уровня, эффективнее (в плане качества+производительность+скорость обучения) сделать несколько иерархических фич, количество которых будет на порядки ниже чем если бы делалась сеть с одним скрытым слоем с кучей фич
глубокие сети используются для того что бы минимизировать количество параметров, но увеличить качество работы сети.
все же при сети прямого распространения, каждый скрытый слой формирует некоторые иерархические фичи, ну и считается что чем плодить кучу фич первого уровня, эффективнее (в плане качества+производительность+скорость обучения) сделать несколько иерархических фич, количество которых будет на порядки ниже чем если бы делалась сеть с одним скрытым слоем с кучей фич
>есть теорема о том что одного скрытого слоя достаточно для аппроксимации абсолютно любой зависимости
Так тут речь не о количестве слоев, а о том, как правильнее делать обратную связь — с выхода последнего слоя на вход первого, или на вход только скрытого.
Мой вопрос следует читать «почему делать рекуррентным только один скрытый слой», а не «почему делать один скрытый слой».
Так тут речь не о количестве слоев, а о том, как правильнее делать обратную связь — с выхода последнего слоя на вход первого, или на вход только скрытого.
Мой вопрос следует читать «почему делать рекуррентным только один скрытый слой», а не «почему делать один скрытый слой».
аа
ну тогда да, это уже труднее поддается анализу, а особенно принятие решения о том каеие связи куда направлять
нада помнить только что скрытые слои — это фичи
вообще я не специалист в рекурентных сетях, но в задачах часто связь установлена от скрытого нейрона к себе самому, получается учитывается не какой то конкретный входной сигнал, или лдин из выходных, а некоторая комбинация всех входных, значений, и значение такого скрытого нейрона уже более менее определяет выходные значения, вот пример задачи из курса Хинтона по сетям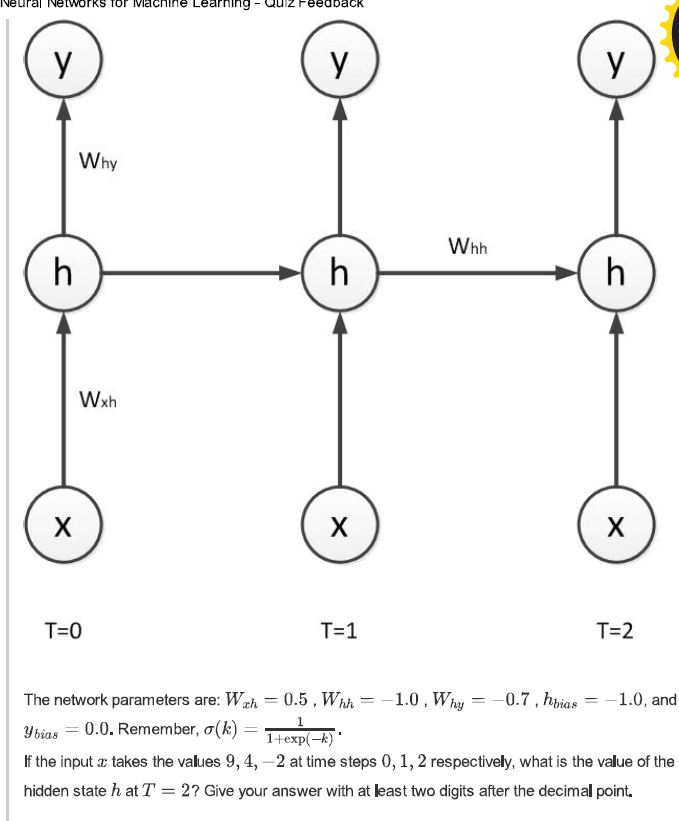
в статье одной, уже не вспомню автора, фичи проектировались вручную и автор знал семантику фич, в отличие скажем от фич сгенерированных ограниченной машиной Больцмана, и тогда он делал обратную связь с одной фичи на другие, семантику которых он тоже знал, и получались такие темпоральные комплексные фичи, и обучал он уже именно эти обратные связи. сказочный изврат, но почему бы нет =)
ну тогда да, это уже труднее поддается анализу, а особенно принятие решения о том каеие связи куда направлять
нада помнить только что скрытые слои — это фичи
вообще я не специалист в рекурентных сетях, но в задачах часто связь установлена от скрытого нейрона к себе самому, получается учитывается не какой то конкретный входной сигнал, или лдин из выходных, а некоторая комбинация всех входных, значений, и значение такого скрытого нейрона уже более менее определяет выходные значения, вот пример задачи из курса Хинтона по сетям

в статье одной, уже не вспомню автора, фичи проектировались вручную и автор знал семантику фич, в отличие скажем от фич сгенерированных ограниченной машиной Больцмана, и тогда он делал обратную связь с одной фичи на другие, семантику которых он тоже знал, и получались такие темпоральные комплексные фичи, и обучал он уже именно эти обратные связи. сказочный изврат, но почему бы нет =)
Ну так если выход замкнуть на вход (из последнего слоя в первый) это, наверное, и будет комбинация входных.
Тем более, что тут ген алгом обучение идет, эта связь может как угодно в итоговой сети работать.
Тут интересны еще два варианта:
1) Дополнительный, ничего не значащий логически выход замкнуть на вход
2) Используемый выход замкнуть на вход (то есть тот выход, значение которого потом идет на какие-то механизмы управления, в моем случае — выход с принятым решением, в случае агентов автора поста — выходы с дельта-углом или дельта-скоростью.
При обучении ген. алгом в первом случае это будет некоторый выход, который в процессе эволюции приобретет некий внутренний смысл, как сказали выше — может статься, что он станет указывать на наличие рядом врага (в текущий или прошедший момент времени), либо еще на какой-нибудь признак или их комбинацию.
Во втором случае — это будет память о своем прошлом состоянии (скорости и направления взгляда).
Вопрос в том, достаточно ли какого-то из этих вариантов, или нужны оба?
Тем более, что тут ген алгом обучение идет, эта связь может как угодно в итоговой сети работать.
Тут интересны еще два варианта:
1) Дополнительный, ничего не значащий логически выход замкнуть на вход
2) Используемый выход замкнуть на вход (то есть тот выход, значение которого потом идет на какие-то механизмы управления, в моем случае — выход с принятым решением, в случае агентов автора поста — выходы с дельта-углом или дельта-скоростью.
При обучении ген. алгом в первом случае это будет некоторый выход, который в процессе эволюции приобретет некий внутренний смысл, как сказали выше — может статься, что он станет указывать на наличие рядом врага (в текущий или прошедший момент времени), либо еще на какой-нибудь признак или их комбинацию.
Во втором случае — это будет память о своем прошлом состоянии (скорости и направления взгляда).
Вопрос в том, достаточно ли какого-то из этих вариантов, или нужны оба?
Как Вам ответили ниже, как правило, для таких задач достаточно одного скрытого слоя,
а за счет рекурретности нейроны знают, как о текущих входных данных, так и о своем преыдущем состоянии.
Рекуррентный слой, по сути, это State Machine, которая переходит из состояния в состояние под действием входных сигналов.
По своему опыту знаю, что рекуррентная нейросеть вполне может научиться выдавать периодический сигнал даже с одним скрыты слоем…
а за счет рекурретности нейроны знают, как о текущих входных данных, так и о своем преыдущем состоянии.
Рекуррентный слой, по сути, это State Machine, которая переходит из состояния в состояние под действием входных сигналов.
По своему опыту знаю, что рекуррентная нейросеть вполне может научиться выдавать периодический сигнал даже с одним скрыты слоем…
Если брать метафору еды, то у может имеет смысл идти дальше, пусть еда будет ресурсом который дает какие-либо преимущества, скорость, или вообще возможность двигаться.
Еда тоже может иметь разную ценность, чем выше скорость еды — тем выше ценность ее ресурса.
Можно наверное симулировать разделение на «травоядных» и " хищников".
Еда тоже может иметь разную ценность, чем выше скорость еды — тем выше ценность ее ресурса.
Можно наверное симулировать разделение на «травоядных» и " хищников".
это нечто прекрасное, помню как-то в детстве видел по дискавери как один мужик создал интеллект похожий на крысиный, и вот они бегали у него в окне приложения и искали еду, в точности как на видео, только без постоянного дерганья в поиске вектора направления, так вот это одна и причин по которой решил заняться программированием )
Profit? Or just for fun?
А как ты такой науке обучался?
В этой можно почитать про агентный подход для создания интеллектуальных систем, про различные варианты окружающей среды и стратегии принятия решений:
Stuart J. Russell, Peter Norvig, Artificial Intelligence: A Modern Approach (есть в переводе)
Начинать можна с этой книги: Toby Segaran, Programming Collective Intelligence
Также, советую почитать: Sean Luke, Essentials of Metaheuristics
Замечательная статья! Наглядно, интересно :)
А как проводилась оценка нейронной сети после генетической модификации? Какая использовалась функция полезности? (т.е. успешная мутация/скрещивание было или неуспешная)
А как проводилась оценка нейронной сети после генетической модификации? Какая использовалась функция полезности? (т.е. успешная мутация/скрещивание было или неуспешная)
Спасибо :-)
Качество нейронной сети определяется следующим образом:
есть тренировочная среда
затем, в этой тренировочной среде:
Таким образом, считаем что эффективность каждой нейронной сети пропорциональна количеству собранных частиц еды
Качество нейронной сети определяется следующим образом:
есть тренировочная среда
размеры среды 200 х 200, количество агентов — 10, количество частиц еды — 5.
затем, в этой тренировочной среде:
всем агентам присваивается нейронная сеть определенной конфигурации («мозг») и через некоторый промежуток времени фиксируется количество собранных частиц пищи.
Таким образом, считаем что эффективность каждой нейронной сети пропорциональна количеству собранных частиц еды
Выигрывают те нейронные сети, под управлением которых агенты смогли собрать больше еды — на их основе формируется новая популяция нейронных сетей и т.д.
Получается, как только агенты (одинаковые) сообща научатся съедать все частицы еды, эволюция останавливается, т.к. fitness-function перестаёт меняться?
Так как, в тренировочной среде частицы еды регенерируются, то, соответственно, со временем будут выигрывать те нейронные сети, которые будут заставлять агентов двигаться быстрее (соответсвенно — собирать больше частиц еды в определённый промежуток времени). Но, поскольку, я всё-таки ограничиваю максимальную скорость и угол поворота — то да, возможно появление нейронной сети, с наилучшими возможными показателями, и эволюция остановится.
Вот типичная кривая обучения нейронной сети агентов:

(построено по результатам консольного вывода эмулятора)
Вот типичная кривая обучения нейронной сети агентов:

(построено по результатам консольного вывода эмулятора)
Удивительно…
Я поначалу подумал что на каждом цикле отобора в генетическом алгоритме на одном поле сражаются разные сети!
Выделяется фиксированное количество ресурсов (допустим, суммарно по 10 единиц еды на агента) и разные сети ведут борьбу за них.
Под этим я и понимал «сражение» сетей — разные агенты на одном поле.
Как только всё съели — выбираются победители для дальнейшего скрещивания и продвижения. В качестве аварийного выхода на первых этапах — таймаут по числу ходов (когда все агенты тупят и ничего не едят вообще).
А у вас, стало быть, совершенно другая стратегия обучения, где сражение ограниченно по числу ходов, все боты одинаковые, на поле постоянное число единиц еды и эффективность каждого агента индивидуально не важна.
Я поначалу подумал что на каждом цикле отобора в генетическом алгоритме на одном поле сражаются разные сети!
Выделяется фиксированное количество ресурсов (допустим, суммарно по 10 единиц еды на агента) и разные сети ведут борьбу за них.
Под этим я и понимал «сражение» сетей — разные агенты на одном поле.
Как только всё съели — выбираются победители для дальнейшего скрещивания и продвижения. В качестве аварийного выхода на первых этапах — таймаут по числу ходов (когда все агенты тупят и ничего не едят вообще).
А у вас, стало быть, совершенно другая стратегия обучения, где сражение ограниченно по числу ходов, все боты одинаковые, на поле постоянное число единиц еды и эффективность каждого агента индивидуально не важна.
Слушайте, а ваш алгоритм выявления победителя мне кажется более продуктивным.
stemm, устройте баттл… интересно понаблюдать в реальном соревновании как видут себя различные брейны. Можно еще включить такой параметр в них как конкуренция с другим видом.
stemm, устройте баттл… интересно понаблюдать в реальном соревновании как видут себя различные брейны. Можно еще включить такой параметр в них как конкуренция с другим видом.
Мой — вполне традиционный подход.
Зато версия stemm может выдать коллективно-оптимальное поведение! Правда, у агентов недостаточно датчиков, чтобы эффективно взаимодействовать, но при наличии хорошего зрения — вполне сможет.
А в моей версии будут ниндзя-одиночки.
Зато версия stemm может выдать коллективно-оптимальное поведение! Правда, у агентов недостаточно датчиков, чтобы эффективно взаимодействовать, но при наличии хорошего зрения — вполне сможет.
А в моей версии будут ниндзя-одиночки.
Да, у меня была такая идея. Нужно будет запилить :-)
Да, важно сколько еды сумеет собрать команда агентов.
Максимизация эффективности коллективного поведения отличается от максимизации поведения индивидума.
Вот простой пример: можно заметить, когда несколько агентов двигаются в направлении к частичке пищи, то один из них может развернуться и начать двигаться в другом направлении. А если б я оптимизировал поведение индивидума — то для каждого агента было бы эффективнее соревноваться с другими, чтоб первым схватит кусочек еды, но сумарная эффективность группы агентов от этого только уменьшается.
Как более наглядный пример, можно упомянуть задачу о дилемме заключённого
Максимизация эффективности коллективного поведения отличается от максимизации поведения индивидума.
Вот простой пример: можно заметить, когда несколько агентов двигаются в направлении к частичке пищи, то один из них может развернуться и начать двигаться в другом направлении. А если б я оптимизировал поведение индивидума — то для каждого агента было бы эффективнее соревноваться с другими, чтоб первым схватит кусочек еды, но сумарная эффективность группы агентов от этого только уменьшается.
Как более наглядный пример, можно упомянуть задачу о дилемме заключённого
С большим удовольствием прочитал как предыдущую вашу статью, так и эту. Невероятно интересно. Начал недавно интересоваться нейронными сетями после прочтения этой статьи, где автор описывает проблемы создания AI и возможные пути их решения. Буду с нетерпением ожидать следующих ваших работ по этой тематике. Спасибо.
Одному мне при встрече слов «агент» и «нейронная сеть» в одном предложении захотелось написать «The Matrix has you...»?
Sign up to leave a comment.
Эволюция агентов управляемых нейронной сетью