Определение высоконагруженных систем и способов их построения
Нагрузка на сервер — это важный показатель использования серверного оборудования. Хит – это запрос клиента к серверу для получения информации. Нагрузка сервера определяется как отношение количества клиентских запросов (хитов) ко времени, выражается в хитах в секунду. Согласно исследованиям Microsoft в 2010 году высоконагруженным сервером можно считать сервер с нагрузкой 100-150 хитов в секунду.В литературе встречаются такие понятия как HPC-система, высоконагруженная система, высоконагруженный кластер, Highload-система, суперкомпьютер, которые порой используются как синонимы. Мы будем понимать сайт с нагрузкой не менее 150 хитов в секунду.
Кластер – это группа компьютеров, которые работают вместе и составляют единый унифицированный вычислительный ресурс. Каждый узел работает под управлением своей копии операционной системы, в качестве которой чаще всего используются Linux и BSD.
Чтобы понять каким образом задачи, выполняемые кластером, распределяются по его узлам необходимо дать определение масштабироемости. Масштабируемость — способность системы справляться с увеличением рабочей нагрузки (увеличивать свою производительность) при добавлении ресурсов. Система называется масштабируемой, если она способна увеличивать производительность пропорционально дополнительным ресурсам. Масштабируемость можно оценить через отношение прироста производительности системы к приросту используемых ресурсов. Чем ближе это отношение к единице, тем лучше. Также под масштабируемостью понимается возможность наращивания дополнительных ресурсов без структурных изменений центрального узла системы. Масштабирование архитектуры высоконагруженной системы может быть горизонтальным и вертикальным. Вертикальное масштабирование заключается в увеличении производительности системы за счёт увеличения мощности сервера. Главный недостаток вертикального масштабирования в том, что оно ограничено определённым пределом. Параметры железа нельзя увеличивать бесконечно. Однако на самом деле вертикальная компонента присутствует практически всегда, а универсального горизонтального масштабирования как такового не существует. Горизонтальное масштабирование заключается в увеличении производительности системы за счёт подключения дополнительных серверов. Именно горизонтальное масштабирование является сейчас фактически стандартом. Известен также такой термин, как диагональное масштабирование. Оно подразумевает одновременное использование двух подходов.
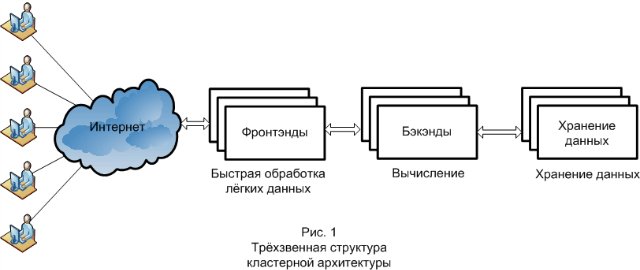
И наконец, необходимо определить основной принцип, использующийся при построении любой кластерной архитектуры. Это — трёхзвенная структура системы (рис. 1). Три звена – это фронтэнд, бэкэнд и хранилище данных. Каждое звено выполняет свои функции, отвечает за различные стадии в обработке запросов и по-разному масштабируется. Первоначально запрос приходит на фронтэнд. Фронтэнды отвечают, как правило, за отдачу статических файлов, первичную обработку запроса и передачу его дальше. Второе звено, куда приходит запрос, уже предварительно обработанный фронтэндом — это бэкэнд. Бэкэнд занимается вычислениями. На стороне бэкэнда, как правило, реализуется бизнес-логика проекта. Следующий слой, который вступает в дело обработки запроса – это хранилище данных, которые обрабатываются бэкэндом. Это может быть база данных или файловая система.
Обзор программно-аппаратных средств для построения кластерной HPC-системы
При построении кластера встаёт задача как распределять нагрузку между серверами. Для этого используется балансировка нагрузки, которая кроме самого распределения выполняет ещё ряд других задач, например: повышение отказоустойчивости (при выходе из строя одного из серверов система будет продолжать работать) и защита от некоторых типов атак (например SYN-flood).Балансировка фронтэндов и их защита
Один из методов балансировки «DNS Round Robin», используется для масштабирования фронтэндов. Суть его в том, что на DNS-сервере для записи домена системы создаётся несколько DNS-записей типа A. DNS-сервер выдаёт эти записи в чередующимся циклическом порядке. В простейшем случае DNS Round Robin работает, отвечая на запросы не только одним IP-адресом, а списком из нескольких адресов серверов, предоставляющих идентичный сервис. С каждым ответом последовательность ip-адресов меняется. Как правило, простые клиенты пытаются устанавливать соединения с первым адресом из списка, таким образом разным клиентам будут выданы адреса разных серверов, что распределит общую нагрузку между серверами. Для реализации метода подойдёт совершенно любой DNS-сервер, например bind. Минус этого метода состоит в том, что бывают DNS-сервера у некоторых провайдеров, которые принудительно кэшируют записи на долгое время.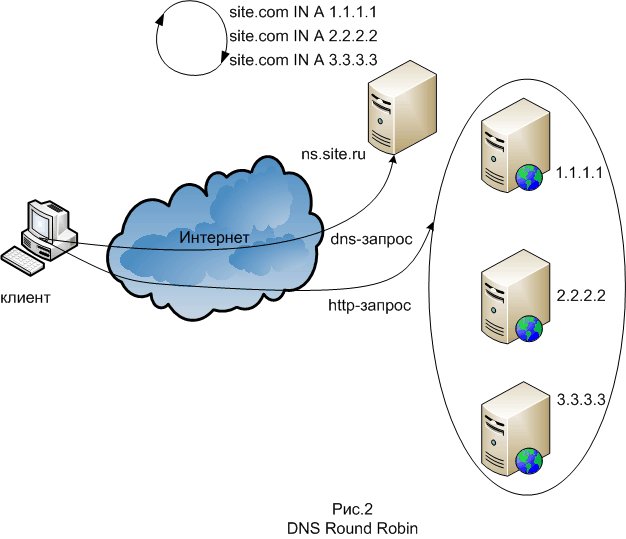 Следующий метод балансировки — это балансировка на втором уровне стека протоколов. Балансировка осуществляется при помощи маршрутизатора таким образом чтобы фронтэнды принимали соединения приходящие на IP-адрес системы и отвечали бы на них, но не отвечали на ARP-запросы, относящиеся к этому адресу. Из программных средств данного метода самое распространённое — это LVS (Linux Virtual Server), представляющий собой модуль ядра Linux, также этот метод балансировки называется Direct Routing. Основная терминология тут следующая: Director — собственно узел осуществляющий роутинг; Realserver — узел фермы серверов; VIP или Virtual IP — всего лишь IP нашего виртуального (собранного из кучи реальных) сервера; DIP и RIP — IP директора и реальных серверов. На директоре включается этот самый модуль IPVS (IP Virtual Server), настраиваются правила проброса пакетов и поднимается VIP — обычно как алиас к внешнему интерфейсу. Пользователи будут ходить через VIP. Пакеты, пришедшие на VIP пробрасываются выбранным методом до одного из Realserver'ов и там уже нормально отрабатываются. Клиенту кажется, что он работает с одной машиной.
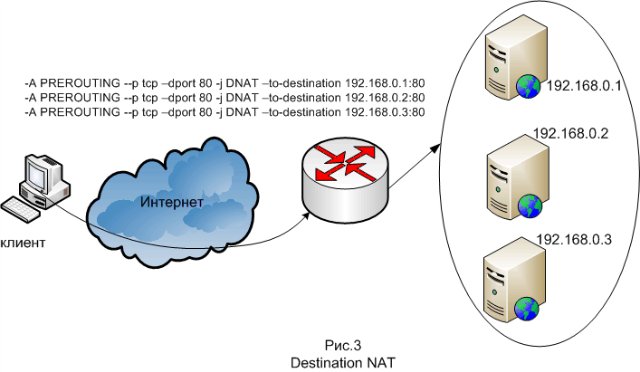
Следующий метод балансировки — это балансировка на втором уровне стека протоколов. Балансировка осуществляется при помощи маршрутизатора таким образом чтобы фронтэнды принимали соединения приходящие на IP-адрес системы и отвечали бы на них, но не отвечали на ARP-запросы, относящиеся к этому адресу. Из программных средств данного метода самое распространённое — это LVS (Linux Virtual Server), представляющий собой модуль ядра Linux, также этот метод балансировки называется Direct Routing. Основная терминология тут следующая: Director — собственно узел осуществляющий роутинг; Realserver — узел фермы серверов; VIP или Virtual IP — всего лишь IP нашего виртуального (собранного из кучи реальных) сервера; DIP и RIP — IP директора и реальных серверов. На директоре включается этот самый модуль IPVS (IP Virtual Server), настраиваются правила проброса пакетов и поднимается VIP — обычно как алиас к внешнему интерфейсу. Пользователи будут ходить через VIP. Пакеты, пришедшие на VIP пробрасываются выбранным методом до одного из Realserver'ов и там уже нормально отрабатываются. Клиенту кажется, что он работает с одной машиной.Ещё один метод – балансировка на третьем уровне стека протоколов, то есть на уровне IP. Работает данный метод таким образом, что когда происходит соединение на IP-адрес системы, на балансировщике делается Destination NAT, то есть подменяются в пакетах IP-адреса назначения на IP-адреса френтэндов. Для ответов заголовки пакетов модифицируются обратно. Осуществляется это при помощи netfilter, входящего в состав ядра Linux.
 Посколько именно фронтэнды принимают запросы от пользователей, основная задача по защите кластера ложится именно на фронтэнды (или на балансировщик фронтэндов в зависимости от архитектуры). Необходимо обеспечить защиту от всевозможных хакерских атак (например таких как SYN flood и DDOS). В основном для защиты используется фаерволл (firewall — огненная стена), другое его название — брандмауэр (brandmauer – противопожарная стена), другое название — межсетевой экран. Фаерволл блокирует вредоносный трафик при помощи правил фильтрации пакетов, а также может выполнять над трафиком такие действия как кэширование, трансляция адреса, переадресация. В GNU/Linux имеется встроенный брандмауэр netfilter, входящий в состав ядра Linux.
Посколько именно фронтэнды принимают запросы от пользователей, основная задача по защите кластера ложится именно на фронтэнды (или на балансировщик фронтэндов в зависимости от архитектуры). Необходимо обеспечить защиту от всевозможных хакерских атак (например таких как SYN flood и DDOS). В основном для защиты используется фаерволл (firewall — огненная стена), другое его название — брандмауэр (brandmauer – противопожарная стена), другое название — межсетевой экран. Фаерволл блокирует вредоносный трафик при помощи правил фильтрации пакетов, а также может выполнять над трафиком такие действия как кэширование, трансляция адреса, переадресация. В GNU/Linux имеется встроенный брандмауэр netfilter, входящий в состав ядра Linux.Масштабирование бэкэндов
При построении высоконагруженных веб-сайтов различают лёгкие и тяжёлые http-запросы. Лёгкие запросы – это запросы статических веб-страниц и изображений. Тяжёлые запросы – это обращение к некоей программе, которая генерирует контент динамически. Динамические веб-страницы генерирует программа или скрипт, написанная на языке высокого уровня: чаще всего PHP, ASP.net, Perl и Java. Совокупность этих программ называется бизнес-логикой. Бизнес-логика – это совокупность правил, принципов, зависимостей поведения объектов предметной области, реализация правил и ограничений автоматизируемых операций. Бизнес-логика располагается на бэкэндах. Используется две схемы: первая – фронтэнд веб-сервер обрабатывет лёгкие запросы, а тяжёлые он проксирует на бэкэнды; вторая – фронтэнд выступает чисто как прокси, но лёгкие запросы он проксирует на одну группу серверов, а тяжёлые на другую.В качестве веб-сервера, использующегося на бэкэндах часто используется Apache. Apache является самым популярным HTTP-сервером. Apache имеет встроенный механизм виртуальных хостов. Apache предоставляет различные мультипроцессорные модели (MPM) для использования в различных средах работы. Модель prefork — наиболее популярная в Linux — создает определенное число процессов Apache при его запуске и управляет ими в пуле. Альтернативной моделью является worker, которая использует несколько потоков вместо процессов. Хотя потоки легче чем процессы, их невозможно использовать до тех пор пока весь ваш сервер не будет безопасен для потоков. А модель prefork имеет свои проблемы: каждый процесс занимает много памяти. Высоконагруженные сайты параллельно обрабатывают тысячи файлов, будучи при этом ограничены в памяти и максимальным числом потоков или процессов. В 2003 немецкий разработчик Ян Кнешке заинтересовался в этой проблеме и решил, что сможет написать веб-сервер, который будет быстрее Apache, сфокусировавшись на правильных методиках. Он спроектировал сервер Lighttpd как один процесс с одним потоком и неблокирующимся вводом-выводом. Для выполнения задачи масштабирования можно использовать Lighttpd + Apache, таким образом что всю статику клиенту будет отдавать Lighttpd, а запросы, оканчивающиеся, например, на .cgi и .php будут передаваться Apache. Другим популярным сервером для решения проблемы масштабирования является Nginx. Nginx — это HTTP-сервер и обратный прокси-сервер, а также почтовый прокси-сервер. Как прокси-сервер Nginx ставится на фронтэнды. Бэкэндов может быть несколько, тогда Nginx работает как балансировщик нагрузки. Такая модель позволяет экономить системные ресурсы, за счет того, что запросы принимаются Nginx, Nginx передает запрос Apache и быстро получает ответ, после чего Apache освобождает память, а с клиентом дальше взаимодействует Nginx (отвечает на простые запросы), который написан для раздачи статического контента, большому количеству клиентов, при незначительном потреблении системных ресурсов. Под Microsoft Server в качестве веб-сервера бэкэнда используется IIS, при этом бизнес-логика пишется на ASP.net.
Ещё одно средство масштабирования бэкэндов – масштабируемый сервер приложений. Применимо если бизнес-логика написана на Java, а именно на его серверной версии. Называются подобные приложения сервлетами, а сервер – контейнером сервлетов или сервером приложений. Существует множество контейнеров сервлетов, с открытым исходным кодом: Apache Tomcat, Jetty, JBoss Application Server, GlassFish и проприетарных: Oracle Application Server, Borland Application Server. Многие серверы приложений поддерживают кластеризацию при условии, что приложение спроектировано и разработано в соответствии с четко определенными уровнями. Кроме того, для решения критических проблем с приложениями Oracle Application Server поддерживает «cluster islands» (кластерные острова) — наборы серверов на уровне J2EE, на котором параметры состояния сессии могут быть значительно легче воспроизведены, обеспечивая, тем самым, прозрачное перенаправление запроса клиента к другому компоненту, который сможет обслужить этот запрос, если некоторый J2EE-компонент выйдет из строя.
Масштабирование СУБД
И наконец, в описании программных средств, использующихся при создании кластерных HPC-систем необходимо упомянуть средства масштабирования хранилищ данных. В качестве хранилищ данных для веба используются базы данных общего назначения, самые распространённые из них это MySQL и PostgreSQL.Основной техникой масштабирования СУБД является шардинг, вернее корректнее было бы назвать шардинг не масштабированием, а разбиением данных по машинам. Суть метода в том, что при увеличении количества данных происходит добавление новых шард — серверов, которые добавляются при заполнении имеющихся шард до некоего лимита.
При масштабировании СУБД на помощь приходит техника репликации. Репликация — это средство связи между серверами баз данных. С помощью репликации можно перенести данные с одного сервера на другой либо продублировать данные на двух серверах. Репликация используется в технике масштабирования «виртуальных шард» — при помощи репликации данные разносятся так, чтобы каждый бэкэнд-сервер работал со своим виртуальным шардом, информация о том где физически находится искомый шард хранится в таблице соотвестствия. Также техника репликации в методе масштабировании, основаном на особенностях запросов к базе данных: редкие операции обновления и частые запросы на чтение. Каждый бэкэнд-сервер работает со своим сервером базы данных, они называются SLAVE, на этих серверах происходят операции чтения из таблицы (функция SELECT). Если же осуществляется запись в таблицу (функции INSERT и UPDATE) то запрос поступает на сервер MASTER и оттуда реплицируется на все сервера.
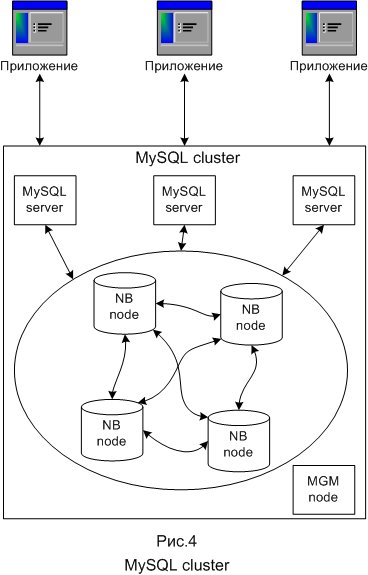
В MySQL используются разные системы хранения данных. Чащё всего это MyISAM и InnoDB. Существует также система хранения NDB, которая используется в специальном средстве масштабирования MySQL под названием MySQL cluster. Кластерная часть MySQL Cluster в настоящее время конфигурируется независимо от серверов MySQL. В MySQL Cluster каждая часть кластера именуется node (узел), при этом ноды на самом деле являются процессами. Может иметься любое число нод на одном компьютере. В минимальной конфигурации кластера MySQL будет по крайней мере три ноды: управляющая (MGM node) – её роль: управлять другими нодами внутри MySQL Cluster, типа обеспечения данных конфигурации, старта и остановки узлов, выполнение резервного копирования и т.д.; нода базы данных (DB node) — управляет и сохраняет базу данных непосредственно, имеется столько DB-узлов, сколько имеется фрагментов для репликаций, например, с двумя репликациями по два фрагмента каждая, надо четыре DB-узла; клиентская нода (API) — узел пользователя, который обратится к кластеру, в случае кластера MySQL, узел пользователя традиционный сервер MySQL, который использует тип хранения NDB Cluster, допуская доступ к кластеризуемым таблицам.
Распределённые вычисления как альтернативное решение
Порой, вместо построения собственной высоконагруженной системы на основе кластерной архитектуры, клиенту проще и выгоднее воспользоваться интернет-сервисами распределённых вычислений. Распределённые вычисления — способ решения трудоёмких вычислительных задач с использованием нескольких компьютеров, чаще всего объединённых в параллельную вычислительную систему. История распределённых вычислений ведёт своё начало с 1999 года, когда первокурсник Северо-восточного Университета США Шон Фэннинг написал систему обмена MP3 файлами между пользователями. Этот проект получил название Napster. По примеру Napster развился целый класс P2P (или пиринговых) сетей нового, децентрализованного типа, P2P-файлообмен состоит в том, что пользователь загружает файлы не с сервера, а с компьютеров других пользователей файлообменной сети, IP-адреса которых он получает со специализированного сервера, называемого трекером или хабом. Загрузка файлов происходит одновременно со всех пиров (участников пиринговой сети) и сопровождается одновременной отдачей, таким образом пиринговая сеть представляет собой некое распределённое файловое хранилище.Технология распределённых вычислений развивалась, и принципы P2P стали использоваться не только для создания распределённых файловых хранилищ, появились распределённые базы данных, потоки, процессоры.
Грид-вычисления (grid — решётка, сеть) — это форма распределённых вычислений, в которой «виртуальный суперкомпьютер» представлен в виде кластеров, соединённых с помощью сети, работающих вместе для выполнения огромного количества заданий. Грид — это система, которая координирует распределённые ресурсы посредством стандартных, открытых, универсальных протоколов и интерфейсов для обеспечения нетривиального качества обслуживания. Основной идеей, заложенной в концепции грид-вычислений, является централизованное удалённое предоставление ресурсов, необходимых для решения различного рода вычислительных задач. Пользователь может запустить любую задачу с любого компьютера на вычисление, ресурсы для этого вычисления должны быть автоматически предоставлены на удалённых высокопроизводительных серверах, независимо от типа задачи. Распределение ресурсов, в котором заинтересованы разработчики грид, это не обмен файлами, а прямой доступ к компьютерам, программному обеспечению, данным и другим ресурсам, которые требуются для совместного решения задач и стратегий управления ресурсами. Выделяют следующие уровни архитектуры грид: базовый (содержит различные ресурсы, такие как компьютеры, устройства хранения, сети, сенсоры и др.); связывающий (определяет коммуникационные протоколы и протоколы аутентификации); ресурсный (реализует протоколы взаимодействия с ресурсами РВС и их управления); коллективный (управление каталогами ресурсов, диагностика, мониторинг); прикладной (инструментарий для работы с грид и пользовательские приложения).

Следующим этапом в эволюции распределённых вычислений стали облачные вычисления. В лаборатории Беркли дают следующее определение: «Облачные вычисления — это не только приложения, поставляемые в качестве услуг через Интернет, но и аппаратные средства и программные системы в центрах обработки данных, которые обеспечивают предоставление этих услуг». Облачные вычисления — технология, в которой распределённые ресурсы предоставляются пользователю как интернет-сервис.
Благодаря облачным вычислениям компании могут предоставлять конечным пользователям удалённый динамический доступ к услугам, вычислительным ресурсам и приложениям (включая операционные системы и инфраструктуру) через Интернет. Вычислительные облака состоят из тысяч серверов, размещённых в физических и виртуальных центрах обработки данных, обеспечивающих работу десятков тысяч приложений, которые одновременно используют миллионы пользователей.
Все возможные методы классификации облаков можно свести к трёхслойной архитектуре облачных систем, состоящей из следующих уровней:
- инфраструктура как сервис (Infrastructure as a Service: IaaS)
- платформа как сервис (Platform as a Service: PaaS)
- програмное обеспечение как сервис (Software as a Service: SaaS)
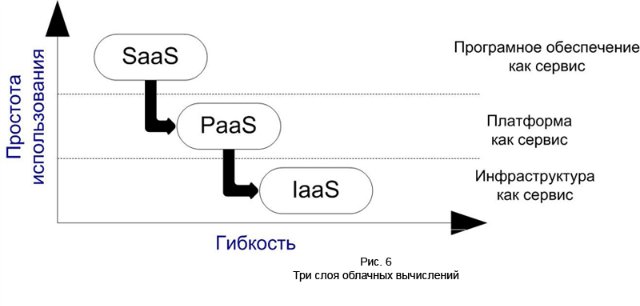
SaaS представляет собой модель развёртывания ПО на основе web, благодаря которому программное обеспечение оказывается полностью доступным через web-браузер. Для пользователей системы SaaS не имеет значения, где установлено программное обеспечение, какую операционную систему оно использует и на каком языке оно написано: PHP, Java или. NET. И, самое главное, пользователю нет необходимости устанавливать что-либо куда-либо. Например Gmail представляет собой, программу электронной почты, доступную через браузер. При этом сам Gmail распределён в облаке серверов, размещенных по всему миру, то есть использует технологию SaaS.
PaaS представляет пользователю инфраструктуру и функционально-полные среды обслуживания и разработки приложений для развёртки пользовательских web-приложений. Например, пользователь Google App Engine, может написать собственное приложение на Python, используя API от Google.
Iaas предлагает информационные ресурсы, такие как вычислительные циклы или ресурсы хранения информации, в виде сервиса. Вместо предоставления доступа к “сырым” вычислительным устройствам и системам хранения, поставщики IaaS обычно предоставляют виртуализированную структуру в виде сервиса.
Крупнейшими облачными провайдерами на конец 2012 годя являются: Amazon Web Services, Windows Azure и Google App Engine.
Amazon Web Services (AWS) — собирательное описание Amazon для всех представляемых компанией облачных сервисов, оно охватывает широкий диапазон сервисов. Amazon Elastic Cloud Compute (Amazon EC2) — это сердце «облака» Amazon. Этот сервис предоставляет API web-сервисов для выделения виртуальных серверов, управления ими и освобождения после того как они стали ненужными с возвращением освобождённых ресурсов в облако Amazon. EC2 представляет собой пользовательскую виртуальную сеть, в составе которой работают виртуальные серверы. Основным средством доступа к amazon EC2 является интерфейс прикладного программирования (API) web-сервисов. Amazon предоставляет ряд интерактивных инструментов, работающих повер API, таких как: консоль web-сервисов Amazon (Amazon Web Services Console), плагин для Firefox ElasticFox, набор инструментов командной строки Amazon (Amazon Command Line tools).
Windows Azure — облачная платформа, разработанная фирмой Microsoft. Windows Azure обеспечивает хранение, использование и модификацию данных и на компьютерах центра обработки данных Microsoft. С точки зрения пользователя, существуют две категории приложений — внутренние, исполняемые на компьютере пользователя и облачные, фактически исполняемые в среде Windows Azure на компьютерах центра обработки данных. Основной компонентой Windows Azure для управления приложениями в облаке является Windows Azure AppFabric, представляющую собой облачную платформу программного обеспечения промежуточного уровня для разработки, развёртывания и управления приложениями на платформе Windows Azure. По классификации Windows Azure относится к облачной платформе вида PaaS, т. е. Клиенту-разработчику предоставляются средства управления облачными приложениями (это как раз и обеспечивает компонента AppFabric).
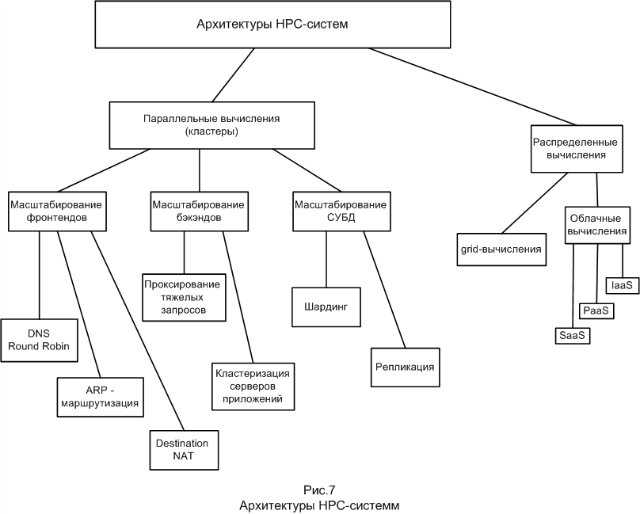
Обобщая, все рассмотренные архитектуры HPC-систем можно представить в виде такой блок-схемы:
Использованные источники
- Учебник по высоким нагрузкам — журн «Хакер: журнал от компьютерных хулиганов» — №7-11 2012г.
- Cборник лучших материалов конференции разработчиков высоконагруженных систем HighLoad++ за 2010 и 2011 года [Электронный ресурс] — Москва, 2012.
- Радченко Г.И. Распределённые вычислительные системы — Челябинск: Фотохудожник, 2012. — 182с.
- Риз Дж. Облачные вычисления: Пер с англ. — Спб.: БХВ-Петербург, 2011. -288с.: ил.
- Сафонов В. О. Платформа облачных вычислений Microsoft Windows Azure — М.: Национальный Открытый Университет «ИНТУИТ», 2013 — 234 с., ил.
