Comments 90
Я один не понимаю зачем линеаризовывать истории? Много народу стремится склеить всё в одно кишку длинную. Дерево же всегда предпочтительнее, оно даёт возможность наблюдать за развитием и вливанием фич, осознавать что и как делалось. тЦеликом и полностью поддерживаю идею поста.
Одномерные сущности проще обозревать, чем двумерные. Но вообще стремиться к линейной истории любыми средствами не стоит.
Если проблема в обозревании, возможно логичнее использовать необходимый инструмент для представления, а не искажать данные?
Предполагаю, что большинство git GUI помимо древовидного вида имеют и линейный с сортировкой по дате.
Кроме того, можно написать инструмент, который бы древовидную историю отображал в точности так, как если бы вместо merge использовался rebase. И вид красивый, и история правдива.
Предполагаю, что большинство git GUI помимо древовидного вида имеют и линейный с сортировкой по дате.
Кроме того, можно написать инструмент, который бы древовидную историю отображал в точности так, как если бы вместо merge использовался rebase. И вид красивый, и история правдива.
Угу. Поэтому, чтобы починить сложный трехмерный мотор, надо проехать по нему катком раз пятьсот. После этого устройство мотора становится тривиальным и чинить его легко и просто.
Тут надо головой думать когда rebase делаешь. Делать rebase надо только в том feature branch, который только «твой» и если в процессе что-то сломалось, то править и делать нормальный merge в общую ветку.
Ну вот в примере как раз feature branch только Васин, в процессе rebase что-то сломалось, он добавил коммит с исправлениями, но коммиты всё равно остались «битыми». После чего сделал нормальный merge (получился fast-forward, но не суть).
Вася rebase сделал криво и уволили его не зря.
Если в процессе rebase вылезли грабли синхронизации с основной веткой, то надо исправить грабли и сделать rebase ещё раз, чтобы в дерево уехали коммиты уже соответствующие последнему состоянию.
Если в процессе rebase вылезли грабли синхронизации с основной веткой, то надо исправить грабли и сделать rebase ещё раз, чтобы в дерево уехали коммиты уже соответствующие последнему состоянию.
Т.е вы предлагаете вручную переписать все 30 коммитов на использование API 2.0?
Вася всё равно в последнем коммите исправлял всё что накоммитил раньше на использование API 2.0. Вместо этого коммита ему надо было откатиться опять на начало ветки и делать суть те же коммиты что и до этого, но с использованием уже API 2.0.
ОК.
Тогда получаем правило:
Тогда получаем правило:
После каждого rebase делать checkout на каждый измененный коммит, проверять весь написанный код на актуальность, прогонять все тесты, при необходимости вносить изменения и переписывать все коммиты. Если в это время в master добавится ещё хотя бы один коммит, повторить всё сначала.
Очень верное правило. Только проверка должна быть автоматизирована, конечно же.
> проверять весь написанный код на актуальность, прогонять все тесты, при необходимости вносить изменения и переписывать все коммиты
Цена линейной истории. А вообще, перед merge всё вышесказанное делать обязательно, иначе будут грабли вне зависимости от вида истории.
> добавится ещё хотя бы один коммит
добавится ещё хотя бы один коммит затрагивающий работу того что используется в rebased коммитах.
> повторить всё сначала.
Не настолько это страшно и долго. интерактивный режим коммита в помощь.
Цена линейной истории. А вообще, перед merge всё вышесказанное делать обязательно, иначе будут грабли вне зависимости от вида истории.
> добавится ещё хотя бы один коммит
добавится ещё хотя бы один коммит затрагивающий работу того что используется в rebased коммитах.
> повторить всё сначала.
Не настолько это страшно и долго. интерактивный режим коммита в помощь.
При merge нужно проверить только 1 коммит, а при rebase — все.
Затрагивает работу или нет — неизвестно, пока не проверим. Баги возникают как раз там, где не предполагаешь.
Собственно, о том и речь.
добавится ещё хотя бы один коммит затрагивающий работу того что используется в rebased коммитах.
Затрагивает работу или нет — неизвестно, пока не проверим. Баги возникают как раз там, где не предполагаешь.
Цена линейной истории.
Собственно, о том и речь.
Нужно просто тот комит, который Вася сделал сверху своих изменений для совместимости, отребейзить через git rebase --interactive потом вниз и все бы стало хорошо. Это логично и не требует никаких автоматических проверок. Т.е. да, Вася просто криво сделал rebase.
Не получится. Ниже объяснение, почему.
В этом коммите исправления этих 30 коммитов, так что таким макаром не получится…
Вася сделал кривой ребейс, а Антон не отследил что один пишет для старого API, а второй переделывает API полностью, одновременно вырезая старую версию напрочь? Я не могу определить, стоит их всех вообще поувольнять, или Васе просто повезло, что ему удалось оттуда наконец уйти?
А то, что в параллельной реальности у тех же людей с тем же уровнем компетенции проблем не возникает, вас ни на какие мысли не наводит? :)
Вообще, цикл статей наводит на мысль, что обсуждается вопрос «А нужен ли git в советском союзе?» Правильный ответ: не нужен. Сначала перестройка, 85год, из RCS рождается CVS, пока вокруг все ходят с дискетками и диффать файлы можно только если два монитора стоят рядом. Потом внезапно — Subversion. О-ля-ля! Робкие попытки с Monotone, где каждый коммит — это фактически branch, и его нужно явно мержить, а если в репо оказались два несмерженных коммита, то закоммитать новое уже нельзя. Уже где-то слышится дуделки git'а, но мы то слышали (хоть и не пробовали), что он не усер-френдли, поэтому mercurial, и даже лично здоровались с человеком, который портает bazaar под венду. Потом вдруг сверху спускается git rebase, куча мата от необходимости править конфликты каждый раз — ведь алгоритм не такой robust'овый, как merge. Потом через полгодика, вместе с ключиком -i, приходит эйфория от осознания того, что больше не нужно коммитать говно-код и говно-каменты в общую ветку — их можно легко (по сравнению с «невозможно» других систем) исправить (или заставить исправить). Ну а потом все уже устаканивается и приходит понимание, что и merge --no-ff есть не зря.
А в колхозе git не нужен, нет.
А в колхозе git не нужен, нет.
Вполне можно делать bisect и по коммитам оставшимся в ответвлении.
Сделал ветку, в ней сделал все коммиты. Сделал её rebase на master, чтобы влить изменения из master в мою ветку. И затем стволу master сделал merge fast forward из ветки. Затем удалил ветку. Как видим коммиты дублировались, они есть и в master и в ответвлении.
Ошибку можно искать через bisect в оставшемся ответвлении даже после удаления ветки, там все коммиты целые со старым API 1.0.
В стволе действительно остались битые коммиты, от коммита API 2.0 до коммита API 2.0 for all subfeatures.
По хорошему, конечно, при слиянии в master надо было делать merge fast forward со squash вместе с API 2.0 for all subfeatures. Потому, что такие битые коммиты никак code review не облегчат. Но это тоже полумера. Лучше всего вместо rebase+mergeFF делать mergeFF+mergeNoFF.
И в принципе считаю, что линейная история только усложняет code review.
Сделал ветку, в ней сделал все коммиты. Сделал её rebase на master, чтобы влить изменения из master в мою ветку. И затем стволу master сделал merge fast forward из ветки. Затем удалил ветку. Как видим коммиты дублировались, они есть и в master и в ответвлении.
Ошибку можно искать через bisect в оставшемся ответвлении даже после удаления ветки, там все коммиты целые со старым API 1.0.
В стволе действительно остались битые коммиты, от коммита API 2.0 до коммита API 2.0 for all subfeatures.
По хорошему, конечно, при слиянии в master надо было делать merge fast forward со squash вместе с API 2.0 for all subfeatures. Потому, что такие битые коммиты никак code review не облегчат. Но это тоже полумера. Лучше всего вместо rebase+mergeFF делать mergeFF+mergeNoFF.
И в принципе считаю, что линейная история только усложняет code review.
Всё верно. Проблемы не будет, если оригинальная история сохранена в каком-либо виде. Можно объединить оригинальную ветку с master, как показали Вы; можно просто её запушить отдельной веткой и master останется линейным, но тогда таких веток со временем будет очень много; можно иметь отдельный репозиторий для таких веток с полной достоверной историей, а в основном — только линейный master. Возможны варианты.
Я в итоге остановился на (master->branch)mergeFF + (branch->master)mergeNoFF, а Вы у себя что используете?
У нас feature-ветки вливаются в основную через merge --no-ff. Если ветка коротенькая, и состоит из 1 коммита, то без принудительного fast-forward. Впрочем, я не считаю это «серебряной пулей», и для других команд с другой стратегией разработки может быть актуальным и например rebase, главное знать о недостатках выбранного решения.
Я не совсем понял, как расшифровывается "(master->branch)mergeFF". master вливается в branch через fast-forward? Но ведь branch итак ответвился от master, и если после этого не было коммитов в master, то и вливать нечего. А если были, то fast-forward не получится.
Я не совсем понял, как расшифровывается "(master->branch)mergeFF". master вливается в branch через fast-forward? Но ведь branch итак ответвился от master, и если после этого не было коммитов в master, то и вливать нечего. А если были, то fast-forward не получится.
Дерево же всегда предпочтительнее
А ещё оно смотрится круче. Реально внушительнее видеть древовидную структуру, чем линейную)
Дерево? История с merge'ами — нудный и запутанный ациклический граф. Поэтому народ, который *царь* в своем репозитории и стремиться линеаризовывать историю. При демократии такой метод работает хуже — за всеми нажен merge да merge, а то какой-то несознательный гражданин написает на общественную клумбу.
Порадуемся за git, который является мультипарадигмической системой, позволяющей получить хоть код, чистый, аки горлица (в динамике, не в статике! — где каждый коммит компилится и без опечаток, как без опечаток и commit message), хоть командную работу при езде в поезде и полете в самолете. (Добиться и того и другого сразу однозначно не получится, даже git не поможет, тут нуден кнут и кандалы.)
Порадуемся за git, который является мультипарадигмической системой, позволяющей получить хоть код, чистый, аки горлица (в динамике, не в статике! — где каждый коммит компилится и без опечаток, как без опечаток и commit message), хоть командную работу при езде в поезде и полете в самолете. (Добиться и того и другого сразу однозначно не получится, даже git не поможет, тут нуден кнут и кандалы.)
Я вижу ещё мораль N2: делать неинтегрированные ветки в 30 коммитов == искать приключений на свой репозиторий.
Предлагаете интегрировать недоделанную функциональность? Думаю, нет.
Возможно, имеете в виду, что более частый rebase с master не привел бы к такому результату? Нет. Коммит с API 2.0 был запушен до готовности фичи, но уже после написания большей части функционала. Поэтому в любом случае все ребейзнутые коммиты оказались бы после коммита с API 2.0 и стали «битыми».
И потом, не в количестве дело. Было бы коммитов не 30, а 5, суть бы не изменилась: при изменении контекста коммиты стали «битыми».
Возможно, имеете в виду, что более частый rebase с master не привел бы к такому результату? Нет. Коммит с API 2.0 был запушен до готовности фичи, но уже после написания большей части функционала. Поэтому в любом случае все ребейзнутые коммиты оказались бы после коммита с API 2.0 и стали «битыми».
И потом, не в количестве дело. Было бы коммитов не 30, а 5, суть бы не изменилась: при изменении контекста коммиты стали «битыми».
Речь не про частый rebase относительно мастера, а про короткие ветки и частый мерж. Раз уж чистого continuous integration нет, то хоть мелко-дискретный пусть будет.
Интегрировать ли недоделанную функциональность? Тут можно ковырять понятие «доделанной функциональности», но я рискну просто ответить «да».
Точнее, разбивать «большую» функциональность на маленькие подзадачи, следить чтобы промежуточные результаты ничего не ломали, и мержить.
Проблема здесь и правда не только в количестве комитов, но и в нём тоже. Вдумайтесь — Вася больше недели разрабатывал большую фичу в своём локальном мире. Параллельно с изменением API.
Мержился бы чаще — нашёл бы проблему раньше, и без проблем переписал бы на новый API 5 комитов.
Интегрировать ли недоделанную функциональность? Тут можно ковырять понятие «доделанной функциональности», но я рискну просто ответить «да».
Точнее, разбивать «большую» функциональность на маленькие подзадачи, следить чтобы промежуточные результаты ничего не ломали, и мержить.
Проблема здесь и правда не только в количестве комитов, но и в нём тоже. Вдумайтесь — Вася больше недели разрабатывал большую фичу в своём локальном мире. Параллельно с изменением API.
Мержился бы чаще — нашёл бы проблему раньше, и без проблем переписал бы на новый API 5 комитов.
В общем, если следовать правилу типа этого, то проблем с rebase не будет.
Только вариант с merge получается намного менее трудозатратным, rebase не бесплатен. Это я и хотел показать.
Только вариант с merge получается намного менее трудозатратным, rebase не бесплатен. Это я и хотел показать.
Что интересно, в параллельной реальности и Васю не уволили.
По этой причине требование линеаризации обычно совмещается с требованиями на реформирование коммитов перед пушем, так, чтобы каждый отдельный коммит компилировался и был отдельным семантическим изменением. Можно даже заставить CI проверять дополнительно к каждому ушедшему в мастер коммиту ещё и все, что находятся между ним и последним протестированым (возможно, так и буду делать).
… требованиями на реформирование коммитов перед пушем, так, чтобы каждый отдельный коммит компилировался и был отдельным семантическим изменением.
Очень хорошее требование. Но конкретно в этом примере оно привело бы к тому, что пришлось бы переписывать заново все 30 коммитов.
Кроме того, то, что все коммиты компилируются, а rebase прошел без конфликтов, не означает то, что операция прошла без проблем, см. пример про 2*3=5.
Да, пришлось бы. Заодно с высокой вероятностью уместил бы эти 30 в осмысленные 5. В нескольких проектах, где я участв(-овал\-ую) есть простое правило, которое мне очень нравится — ты полностью в ответе за то, чтобы после слияния твоей ветке в масте осталась идеальная история коммитов. Какие бы изменения не приходили до этого, за итоговый результат всегда отвечаешь ты и тратишь столько времени на это, сколько потребуется.
«компилируются» == «компилируются и проходят все тесты», конечно же, на то он и Continuous Integration, чтобы предупредить вовремя.
«компилируются» == «компилируются и проходят все тесты», конечно же, на то он и Continuous Integration, чтобы предупредить вовремя.
Чего только люди не придумают, лишь бы не смотреть на реальную историю
А можно было ведь коммит с исправлениями вставить перед своими 30 коммитами после того, как сделал rebase.
Нет, коммит с исправлениями зависит от всех 30 коммитов.
rebase -i и вперед
Я понял. Но не выйдет. Можете попробовать на репозитории.
В содержании коммита с исправлениями содержится код из всех 30 коммитов.
Остаётся только переписывать все 30 коммитов заново.
В содержании коммита с исправлениями содержится код из всех 30 коммитов.
Остаётся только переписывать все 30 коммитов заново.
Портируете refs?
Если делать постоянно rebase и иметь линейную историю, то вы теряете всякую связь с вашим ишу трекером. А если делать merge ваших веток, в которых вы разрабатывали вашу фичу/версию, то вы в git будете видеть историю, когда фича была замерджена и иметь какую-то свзять с вашим ишу трекером.
Как по мне, rebase стоит делать для локальной ветки и её аналога в origin и если вы имеете какие-то незначительные изменения (пара несвязанных коммитов, хотфикс).
Как по мне, rebase стоит делать для локальной ветки и её аналога в origin и если вы имеете какие-то незначительные изменения (пара несвязанных коммитов, хотфикс).
Чем больше я читаю статей про git и комментариев к ним, тем больше мне начинает казаться, что программисты, которые работают с git'ом вместо, собственно, программирования занимаются плясками вокруг git'а.
Может, это статьи просто вводят в заблуждение?
P.S. про --rebase я узнал именно из этой серии топиков
P.S. про --rebase я узнал именно из этой серии топиков
Я вам точно могу сказать, что есть немалые команды, которые работают с гитом и не парятся.
Вы не прочитаете об этом на хабре, т.к. писать о скучной повседневной работе с системой контроля версий никому не интересно.
Вы не прочитаете об этом на хабре, т.к. писать о скучной повседневной работе с системой контроля версий никому не интересно.
git — это как Emacs. Так что с ним можно и программить, и плясками заниматься.
Я не понимаю, в чем кроется ненависть к ребейзам? Надуманные примеры, странные выводы, уволенный Вася. Читаю и прямо плачу.
Петя пере… кхм апи, не оставив депрекатед версию, а виноват Вася. А если бы какой-нибудь Ваня затер бы все файлы в мастер-ветке? Виноват бы тоже остался Вася с его ребейзами?
Петя пере… кхм апи, не оставив депрекатед версию, а виноват Вася. А если бы какой-нибудь Ваня затер бы все файлы в мастер-ветке? Виноват бы тоже остался Вася с его ребейзами?
Вы бы предпочли, чтобы я в статью вывалил реальную гору кода, и сказал: разбирайтесь? Естественно, пример синтетический. Вместо изменения API можете подставить рефакторинг интерфейса класса / обновления в субмодуле/ использование новой версии компилятора / фреймворка и т.п. — суть от этого не изменится.
И да, статьи не про то, кто виноват, а про недостатки rebase, про которые часто забывают, и которые надо учитывать при его использовании. Ваш КО.
И да, статьи не про то, кто виноват, а про недостатки rebase, про которые часто забывают, и которые надо учитывать при его использовании. Ваш КО.
Понятно, что ребейз придуман перфекционистами и не стоит его лишний раз использовать, не имея тяги к порядку, которая заставит и каждый коммит проверить и историю линейную сделать и тесты под это дело написать. Но примеры получаются совсем неубедительными. С похожими аргументами можно ратовать за то, что мержить — это плохо. Затираются изменения, при слиянии получается нерабочая каша, того, кто делал мерж надо уволить, а всех остальных заставлять сразу пихать все коммиты в основной репозиторий, причем проверять, чтобы коммит был сделан на самую новую ревизию. Чтобы не дай бог не пришлось мержить две ветки.
Проблема не в инструментах, а в людях. Там зазевался, тут забыл, тогда сроки поджимали и не успел проверить, а сейчас просто лень. Не стоит искать решение проблемы в инструментах — в конце концов не важно кто как что делает. Куда как важнее, что из этого получается. Как найти островок стабильности в этом «человеческом факторе». Один в репозитарий заливает всякий бред, второй правит баги вообще на продакшене, забывая про репозитарий, третий по приколу сменит локаль в какой-то функции и забудет вернуть её обратно, в результате чего парсилка дробей отвалится, что обнаружат через год только — ищи потом, свищи, кто виноват, где бага родилась.
Проблема не в инструментах, а в людях. Там зазевался, тут забыл, тогда сроки поджимали и не успел проверить, а сейчас просто лень. Не стоит искать решение проблемы в инструментах — в конце концов не важно кто как что делает. Куда как важнее, что из этого получается. Как найти островок стабильности в этом «человеческом факторе». Один в репозитарий заливает всякий бред, второй правит баги вообще на продакшене, забывая про репозитарий, третий по приколу сменит локаль в какой-то функции и забудет вернуть её обратно, в результате чего парсилка дробей отвалится, что обнаружат через год только — ищи потом, свищи, кто виноват, где бага родилась.
О том и речь. Разработчики не идеальны, а при достоверной истории найти причину бага куда проще.
На мой взгляд без разницы. Не столь важно узнать почему появилась бага, сколько где она находится, чтобы её исправить. Ну, или узнать кто её привнес, чтобы поручить эту багу ему — пусть сам со своими ошибками разбирается, а потом рассказывает, как так получилось.
Вот в примере из статьи: где находился баг?
Как это легче определить: при rebase или при merge?
Как это легче определить: при rebase или при merge?
В примере из статьи основной баг находится в процессе разработки.
А так, да. Если закрыть глаза на этот баг, при мерже понять что происходит и в чем причины, конечно же, проще.
А так, да. Если закрыть глаза на этот баг, при мерже понять что происходит и в чем причины, конечно же, проще.
Если положить, что багов в процессе нет, значит продукт идеален, а история для локализации ошибок не потребуется. Но мы же в реальном мире живем, значит баги будут, — это вводная обоих примеров.
И ещё. К статье это не относится. Но. По экономическим причинам бывает, что зависимые части (в статье API и feature) есть смысл разрабатывать параллельно. Также не повод откладывать переход на новую версию фреймворка только потому, что кто-то из разработчиков использует в своей ветке старую. И т.п. Жизнь заставляет идти на компромиссы.
И ещё. К статье это не относится. Но. По экономическим причинам бывает, что зависимые части (в статье API и feature) есть смысл разрабатывать параллельно. Также не повод откладывать переход на новую версию фреймворка только потому, что кто-то из разработчиков использует в своей ветке старую. И т.п. Жизнь заставляет идти на компромиссы.
Насколько вижу, в описываемой компании принято фиксить проблемы путем создания новых коммитов с исправлениями. Зачем тогда вообще понадобилось Антону искать проблемный коммит? Отдебажил код, написал фикс, запушил новым коммитом.
Для локализации бага. Зачем бегать глазками по коду, если git-bisect может выдать проблемный коммит сразу?
Зачем Антону вообще искать проблемный коммит, если он может локализовать баг просто отладкой кода? Или там настолько плохая декомпозиция кода, что по описанию ошибки непонятно, хотя бы в каком модуле она возникает?
См. ниже.
Трогать проблемную строчку без понимания причины её добавления == не отдавать отчета в том что делаешь. Можно ведь случайно вернуть (предыдущую) багу которую эта строка решала.
Кроме того, знать причину крайне полезно для улучшения процесса и недопущения новых багов.
Антон нашел проблемную строку в файле. Находит коммит, где эта строка появилась. Читает комментарии к коммиту.
Во-первых, иногда легче найти проблемный коммит, а затем уже строку, нежели сразу строку. Я как раз постарался составить такой пример.
Во-вторых, ваш подход не даст полной картины: например, почему до коммитов из feature всё работало, а после — нет.
Во-вторых, ваш подход не даст полной картины: например, почему до коммитов из feature всё работало, а после — нет.
Можете поискать ошибку из примера самостоятельно, используя оба подхода, и сравнить (держа в уме, конечно, что пример элементарен, а в реальности кода на несколько порядков больше). Код целиком (вариант rebase), проблемный коммит (вариант merge).
Поясню: где легче найти местонахождение бага: в целом проекте, или в строчках одного коммита?
Я из лагеря линейной истории, но это не значит что линейной всегда. Фича из 30 коммитов должна быть в ветке, чтобы было видно где начало и конец. Но большинство других коммитов целостны и достаточны сами по себе (багфикс, мини-фича, рефакторинг) и ветка для каждого такого коммита делает историю дурно пахнущей. Перед мерджем этого в master-ветвь хочется перекреститься.
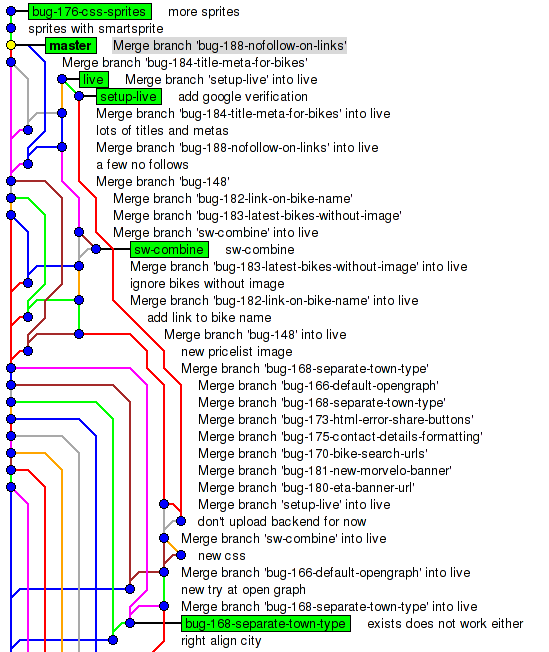

Вам не нравится вид такой истории? Я выше уже писал, это проблема инструмента просмотра.
Линеаризованная история, пропуская merge-коммиты:
То же, но с аккуратным форматированием:
Здесь соглашусь, единичный коммит мерджить с --no-ff излишне, а вот 2 и более — вполне нормально.
Линеаризованная история, пропуская merge-коммиты:
git log --graph --no-merges
То же, но с аккуратным форматированием:
git log --graph --no-merges --pretty=format:'%C(red)%h%Creset%C(yellow)%d%Creset %s %C(green)(%cr)%Creset %C(blue)<%an>%Creset' --color
Но большинство других коммитов целостны и достаточны сами по себе (багфикс, мини-фича, рефакторинг) и ветка для каждого такого коммита делает историю дурно пахнущей.
Здесь соглашусь, единичный коммит мерджить с --no-ff излишне, а вот 2 и более — вполне нормально.
Петя — очень нехороший человек.
Все просто: rebase — хорошо, линеаризация истории — плохо.
В этом случае Васе нужно было:
— сделать rebase ветки на мастер
— пофиксить конфликты в отдельном коммите (если изменения API глобальные — возможно, сделать реордер коммитов для наглядности)
— сделать merge --no-ff в мастер
Не хватает кармы чтобы картинку запостить, но выглядеть это будет примерно так:
|
o
| \
| o
| /
o
|
Справа — коммиты Васи в отдельной ветке.
Да, это все еще требует больше усилий, чем банальный мерж, но в результате историю можно эффективно просматривать без «специализированных инструментов» — и сразу видно, какие коммиты суть отдельная фича, и дифф цельной фичи (=мерж коммит) можно увидеть в 2 клика.
В этом случае Васе нужно было:
— сделать rebase ветки на мастер
— пофиксить конфликты в отдельном коммите (если изменения API глобальные — возможно, сделать реордер коммитов для наглядности)
— сделать merge --no-ff в мастер
Не хватает кармы чтобы картинку запостить, но выглядеть это будет примерно так:
|
o
| \
| o
| /
o
|
Справа — коммиты Васи в отдельной ветке.
Да, это все еще требует больше усилий, чем банальный мерж, но в результате историю можно эффективно просматривать без «специализированных инструментов» — и сразу видно, какие коммиты суть отдельная фича, и дифф цельной фичи (=мерж коммит) можно увидеть в 2 клика.
Попробуйте на репозитоии из примера. Вы получите те же «битые» коммиты с измененным контекстом, на которых проект не собирается.
--no-ff позволяет сохранить информацию о том, что ветка существовала, но rebase всё равно контекст меняет.
--no-ff позволяет сохранить информацию о том, что ветка существовала, но rebase всё равно контекст меняет.
Гит гибок — и прибивать гвоздями методики совершенно необязательно. Из чтения ваших постов про гит может сложиться впечатление, что возможны только два варианта — всегда плохой ребейз и всегда хороший мерж. А это не так.
У нас есть как минимум 4 одинаково (в зависимости от того, чего конкретно мы хотим) хороших варианта:
— откатить ребейз и сделать обычный мерж;
— откатить коммиты в ветке через reset --soft и собрать ветку заново (как делают разработчики того же Линукса);
— сделать как написано выше+реордер коммитов, чтобы фикс-коммит утащить вниз (если изменения не глобальные — это возможно);
— забить на некомпилируемость и сделать просто как написано в предыдущем комменте — ибо, например, в кровавом энтерпрайзе бисект ни на фиг не нужен.
Выбор подходящего варианта для каждого конкретного случая позволит нам иметь историю ровно такую, какую мы хотим.
А оба ваших поста про гит, уж извините — популизм, пагубно влияющий на умы начинающих гитоводов. К тому же — с подменой тезиса: плохая линеаризованная история (что правда)=плохой ребейз (что неправда).
У нас есть как минимум 4 одинаково (в зависимости от того, чего конкретно мы хотим) хороших варианта:
— откатить ребейз и сделать обычный мерж;
— откатить коммиты в ветке через reset --soft и собрать ветку заново (как делают разработчики того же Линукса);
— сделать как написано выше+реордер коммитов, чтобы фикс-коммит утащить вниз (если изменения не глобальные — это возможно);
— забить на некомпилируемость и сделать просто как написано в предыдущем комменте — ибо, например, в кровавом энтерпрайзе бисект ни на фиг не нужен.
Выбор подходящего варианта для каждого конкретного случая позволит нам иметь историю ровно такую, какую мы хотим.
А оба ваших поста про гит, уж извините — популизм, пагубно влияющий на умы начинающих гитоводов. К тому же — с подменой тезиса: плохая линеаризованная история (что правда)=плохой ребейз (что неправда).
Я не ставил своей целью расмотреть все возможные workflow, а намеренно описал лишь недостатки rebase, ибо про его плюсы пишут абсолютно во всех вводных статьях, а про минусы и грамотное применение забывают. Свежий пример.
Кроме того, многие ошибочно полагают (и это подтверждают комментарии), что:
1) если ребейзить только локально, то никаких проблем не будет;
2) если не было конфликта при rebase, значит и не было проблем;
3) если после rebase код компилируется и проходит тесты, значит всё нормально;
4) поможет merge --no-ff;
5) поможет squash;
6) ситуацию легко исправить через rebase -i.
В общем случае все эти способы не избавят от описанных проблем.
Поэтому rebase — сложный инструмент, и применять его надо с умом, соблюдая правила, или хотя бы четко понимая последствия отказа от этих правил. Только и всего.
Кроме того, многие ошибочно полагают (и это подтверждают комментарии), что:
1) если ребейзить только локально, то никаких проблем не будет;
2) если не было конфликта при rebase, значит и не было проблем;
3) если после rebase код компилируется и проходит тесты, значит всё нормально;
4) поможет merge --no-ff;
5) поможет squash;
6) ситуацию легко исправить через rebase -i.
В общем случае все эти способы не избавят от описанных проблем.
Поэтому rebase — сложный инструмент, и применять его надо с умом, соблюдая правила, или хотя бы четко понимая последствия отказа от этих правил. Только и всего.
В большинстве случаев описанные ситуации вылавливаются на этапе запуска тестов после ребейза. Не компилируется или тесты упали — ищем проблему и применяем один из описанных подходов (наиболее подходящий под наш workflow).
Описанное в посте как минимум поймается после пункта 3) из вашего списка, а потому если в полиси сказано «хотим компилируемых коммитов» — Васю таки надо увольнять. В чем тут вина ребейза — все еще не вижу.
И мне ну очень сложно представить ситуацию в реальном проекте, когда не было конфликтов, код компилируется, тесты проходят, но проблема была. И (глубокое ИМХО, разумеется) в реальной жизни такими ситуациями (когда со стремящейся к нулю вероятностью у нас в дереве будет пара некомпилируемых коммитов) можно смело пренебречь.
Повторюсь: вы взяли гипотетическую и совершенно дурацкую ситуацию (либо с криворуким Васей, либо с несогласованным workflow) — и сделали из нее далеко идущие обобщающие выводы о вредности или полезности отдельных компонентов гита. А на самом деле вина гита тут только лишь в том, что он предоставляет слишком хорошие прицельные приспособления, которыми так удобно целиться себе в ногу.
Описанное в посте как минимум поймается после пункта 3) из вашего списка, а потому если в полиси сказано «хотим компилируемых коммитов» — Васю таки надо увольнять. В чем тут вина ребейза — все еще не вижу.
И мне ну очень сложно представить ситуацию в реальном проекте, когда не было конфликтов, код компилируется, тесты проходят, но проблема была. И (глубокое ИМХО, разумеется) в реальной жизни такими ситуациями (когда со стремящейся к нулю вероятностью у нас в дереве будет пара некомпилируемых коммитов) можно смело пренебречь.
Повторюсь: вы взяли гипотетическую и совершенно дурацкую ситуацию (либо с криворуким Васей, либо с несогласованным workflow) — и сделали из нее далеко идущие обобщающие выводы о вредности или полезности отдельных компонентов гита. А на самом деле вина гита тут только лишь в том, что он предоставляет слишком хорошие прицельные приспособления, которыми так удобно целиться себе в ногу.
сделали из нее далеко идущие обобщающие выводы о вредности или полезности отдельных компонентов гита.
Где вы вообще такое разглядели?
Rebase теряет контекст, в котором коммиты были написаны. Это факт, и про него нужно знать. Точка.
В результате либо мы прикладываем усилия и проверяем новый контекст всех коммитов; либо осознанно забиваем и смиряемся с неправдивой историей; либо отказываемся от rebase в пользу более простого merge, который не искажет историю. Каждый выберет своё.
Плох только тот вариант, когда инструмент используется, но о его минусах понятия не имеют.
Перечитал пост (особенно мораль) — вы меня уели, таки разглядел в посте то, чего там не было :)
Действительно, ребейз теряет контекст и об этом нужно помнить (хотя это в большинстве случаев и не важно).
Действительно, ребейз теряет контекст и об этом нужно помнить (хотя это в большинстве случаев и не важно).
Собственно, фишка rebase'в том, чтобы оторваться от контекста и легко приложить патчи к чему угодно (обычно к HEAD'у чужой ветки, но возможностей куда больше). Работает конечно в пределах эвристичности patch'а и семантики кода, к которому прикладывается. Тут Yan169 прав, «это должен знать каждый» (и соответственно использовать — совсем не каждый и не всегда).
rebase — инструмент не для начинающих, тут я согласен. Однако, он опупительно полезен и в повседневной работе при должном умении, ибо позволяет сделать историю гораздо читабельнее (особенно в свете отсутствия веток в гите). Впрочем, не буду повторяться, ибо понятно, что мнений на этот счет может быть несколько.
Вася не правильно пользуется rebase-ом, значит нету продуманного workflow работы с git-ом (понятного разработчикам), значит виноват Антон.
Мое мнение состоит в том, что нельзя просто взять и заменить merge на rebase, в надежде, что все будет как раньше, только с линейной историей. Rebase — это сложный инструмент, который переписывает историю. Поэтому для его безболезненного использования нужна какая-то стратегия, основанная на разумных ограничениях. У нас, например, это 3 простых правила:
1. Squash коммитов перед мержем ребейзнутого бранча в мастер
2. Фича бранчи мержатся в мастер не реже чем раз в день (гибрид постоянной интеграции и бранчевания)
3. Никаких rebase-ов для запушенных данных
При этом, правило номер 2 выполняется не всегда. Скажем, если мы берем контрактника на определенную задачу, то для него вполне нормально будет сидеть в своем фича бранче месяц, а потом выдать в мастер один коммит (в результате rebase+squash). Если что-то пойдет не так после попадания его работы в мастер, то и откатить его задачу целиком будет очень просто (поскольку это один коммит).
Если бы Вася пользовался этими правилами (или даже только 1-м), то проблема, описанная в статье, не возникла бы.
Мое мнение состоит в том, что нельзя просто взять и заменить merge на rebase, в надежде, что все будет как раньше, только с линейной историей. Rebase — это сложный инструмент, который переписывает историю. Поэтому для его безболезненного использования нужна какая-то стратегия, основанная на разумных ограничениях. У нас, например, это 3 простых правила:
1. Squash коммитов перед мержем ребейзнутого бранча в мастер
2. Фича бранчи мержатся в мастер не реже чем раз в день (гибрид постоянной интеграции и бранчевания)
3. Никаких rebase-ов для запушенных данных
При этом, правило номер 2 выполняется не всегда. Скажем, если мы берем контрактника на определенную задачу, то для него вполне нормально будет сидеть в своем фича бранче месяц, а потом выдать в мастер один коммит (в результате rebase+squash). Если что-то пойдет не так после попадания его работы в мастер, то и откатить его задачу целиком будет очень просто (поскольку это один коммит).
Если бы Вася пользовался этими правилами (или даже только 1-м), то проблема, описанная в статье, не возникла бы.
Если бы Вася пользовался squash, то все его 30 коммитов по N строк выглядели как 1 в 30*N строк, и искать с нем ошибку было бы так же сложно.
Зачем добровольно отказываться от возможности легко локализовать ошибку через git-bisect?
Зачем добровольно отказываться от возможности легко локализовать ошибку через git-bisect?
2. Фича бранчи мержатся в мастер не реже чем раз в день (гибрид постоянной интеграции и бранчевания)
Не понимаю. Есть к примеру ветка «сomments», в которой разработчик пишет добавление комментариев к статье. К концу дня он успел добавить форму добавления комментария и сохранение в базу, а отображение комментариев — нет. И эту недофичу мерджить в мастер? Зачем?
В нашем workflow вполне нормально живут long-running branches, которые интегрируются только в момент полной готовности, который может быть наступить к следующему релизу, через несколько релизов, а может и вообще не наступить, если бизнес-требования вдруг изменились, и вектор развития изменился.
Да, именно так. Фича которая не вмещается в день работы разбивается на подфичи, которые интегрируются в мастер каждый день. Зачем? Ну плюсы такие же как у continous integration подхода в чего чистом виде — избежать больших и сложных мержей, которые часто приводят к ошибкам.
Например, представьте ситуацию, что у вас в команде 10 разработчиков, каждый из которых месяц работает в своем бранче. А через месяц они начинают все это дело мержить в мастер. Вероятность того, что такой глобальный мерж 10-ти веток (каждая из которых эволюционировала целый месяц) пройдет гладко — крайне мала. Будет долго, сложно, и высока вероятность добавления ошибок.
Отлично, если это работает для вас. Я считаю, что идеального workflow не существует. Для нас работает наш, для вас — ваш. Это прекрасно. Кстати, вы таки используете merge или rebase?
Например, представьте ситуацию, что у вас в команде 10 разработчиков, каждый из которых месяц работает в своем бранче. А через месяц они начинают все это дело мержить в мастер. Вероятность того, что такой глобальный мерж 10-ти веток (каждая из которых эволюционировала целый месяц) пройдет гладко — крайне мала. Будет долго, сложно, и высока вероятность добавления ошибок.
Отлично, если это работает для вас. Я считаю, что идеального workflow не существует. Для нас работает наш, для вас — ваш. Это прекрасно. Кстати, вы таки используете merge или rebase?
Merge без фанатизма, нечто похожее на git flow: release, master, develop + feature branches.
del
Sign up to leave a comment.
Чем опасен rebase-2, или как rebase мешал баг искать