Comments 55
Прирост кораблей увеличивается вдвое?
Сыграл против противника по данной сетке — до 14-го выстрела были одни промахи (может он тоже статью на Хабре прочитал). В дальнейшем стал попадать, но сетки всё равно придерживался.
Как результат — выиграл :) Правда уже на финальной «ловле» однопалубников.
Как результат — выиграл :) Правда уже на финальной «ловле» однопалубников.
Сетка действует до первого попадания. После этого всё сбивается, и конфигурации приходится пересчитывать для каждой партии индивидуально.
Кстати, чтобы бороться с прочитавшими, можно:
— поворачивать и отражать сетку как угодно;
— менять в последовательности первый ход со вторым, 5-й с 6-м и/или 7-й с 8-м. Конечно, если первые 8 клеток будут промахи, то это не поможет, но в противном случае слегка усложнит жизнь оппонента.
Кстати, чтобы бороться с прочитавшими, можно:
— поворачивать и отражать сетку как угодно;
— менять в последовательности первый ход со вторым, 5-й с 6-м и/или 7-й с 8-м. Конечно, если первые 8 клеток будут промахи, то это не поможет, но в противном случае слегка усложнит жизнь оппонента.
А ваш алгоритм позволяет пересчитывать карту в реальном времени для каждого хода?
Для первых ходов считает по 30-40 секунд, дальше быстрее. Так что если запомнить последовательность первых ходов (8 штук, например), можно его нормально испытывать. Сейчас как раз сочиняю ему противников.
А на чем реализовано? Может, можно оптимизировать на C, чтобы считало еще быстрее.
На C#. Оптимизировать, конечно, можно — после того, как стали понятны масштабы данных.
Тогда вообще прекрасно. При хорошей оптимизации можно надеяться на сокращение времени расчетов до примерно 10с, что очень даже приемлемо в ходе онлайн-игры с человеком.
После небольшой оптимизации (построен в явном виде граф переходов между классами — 1 млн вершин и 12 млн рёбер, реализация множества классов с картами распределения переделана с Hashtable на «битовую реализацию», убраны лишние захваты памяти) скорость возросла в 2 с лишним раза (около 10 сек на пустое поле). Сейчас я строю дерево дебютов на глубину 10 ходов (наилучшие ходы для каждой последовательности ответов), после этого можно будет рассчитывать на не более, чем 2-3 секунды на 1 ход.
Очень интересно. Ваши результаты практически совпадают с моими, полученными методом Монте-Карло по перебору большого числа равномерно распределенных комбинаций кораблей (в свое время за несколько недель работы ноута было насчитано и сохранено более 3Гб комбинаций). Надо будет исследовать ваш алгоритм подробнее. Быть может, это прорыв!
Вы можете построить heat-map для всей карты, чтобы наглядно показать разницу между априорными вероятностями нахождения кораблей в клетке?
Инструментов для этого я не знаю, а писать с нуля неохота. Таблички для двух ситуаций в статье приведены, можете взять их и построить. Вероятности для пустого поля варьируются от 14% до 26%.

сообщение по ошибке продублировалось, удалил.

Картинка чуть лучше — вероятность всё ещё нормализована, но цвета симметричны относительно 1% вероятности — среднее ожидание при случайном распределении.
Вообще-то клеток с кораблями на пустом поле — 20 штук, поэтому вероятность должна составлять порядка 20% в среднем. У вас где-то ошибка. Посмотрите на мою карту.
Нет, на первый взгляд всё правильно. Вероятность увеличена в 5 раз (нормирована на 100%), поэтому меняется от 0.73 до 1.28.
Повторюсь, при правильной нормировке вероятность попадания — то есть отношение числа комбинаций размещения всех кораблей, при которых в данной клетке имеется корабль, к общему числу допустимых комбинаций, составляет порядка 20% в среднем для клеток необстрелянного поля. Сами подумайте, как вероятность попасть в корабль на пустом поле может быть порядка 1%? Так было бы, если бы на поле находился только один однопалубный корабль.
Считайте что там просто всё поделено на 20.
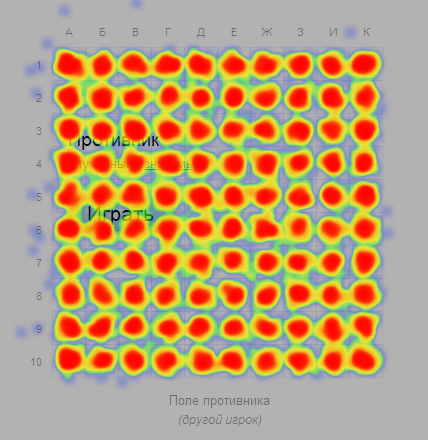
Карта 4,5 млн кликов c сайта ru.battleship-game.org
img-fotki.yandex.ru/get/9068/24566399.5/0_895b2_b6229b0d_L.png
(не получается вставить картинкой, поэтому даю ссылку на источник)
img-fotki.yandex.ru/get/9068/24566399.5/0_895b2_b6229b0d_L.png
{kind=link}
(не получается вставить картинкой, поэтому даю ссылку на источник)
Хм, человек обычно кликает по центрам клеток? Какая полезная информация!
Похоже, что есть ситуации, когда выгоднее стрелять не на соседнюю клетку с раненным кораблём, а чуть дальше.
Например, после ходов
C1 — мимо
J8 — мимо
C10 — ранил
D10 — добил
A8 — мимо
H10 — ранил
I10 — мимо
программа стреляет не в G10 и не в H9, как следовало бы ожидать, а в F10. Насколько больше там вероятность найти корабль, я пока посмотреть не могу (программа строит дерево дебютов, и мешать ей не хочется), но позже обязательно проверю.
Например, после ходов
C1 — мимо
J8 — мимо
C10 — ранил
D10 — добил
A8 — мимо
H10 — ранил
I10 — мимо
программа стреляет не в G10 и не в H9, как следовало бы ожидать, а в F10. Насколько больше там вероятность найти корабль, я пока посмотреть не могу (программа строит дерево дебютов, и мешать ей не хочется), но позже обязательно проверю.
А можно куда-нибудь выложить код хотя бы в его текущем виде? Хочется пощупать своими руками, но сочинять свою прогу — не могу собраться с силами и выделить время.
В понедельник попробую выложить. Но вам не понравится — там мало комментариев и много однобуквенных переменных.
astr73.ucoz.ru/Files/mb3.zip
Configs10 — калькулятор для анализа конфигураций, SmartPlayer — «игрок», у которого можно спрашивать очередной ход, а можно — сообщить ему результат хода.
Если в директории запуска находится файл gametree.dat, программа его прочитает и будет брать из него первые 10 ходов. Если нет — ей придётся вычислять каждый ход с нуля, зато в этом случае можно дать игроку любую последовательность ходов и их результатов, и спросить, что она рекомендует делать дальше.
Читабельность кода по-прежнему никакая…
Configs10 — калькулятор для анализа конфигураций, SmartPlayer — «игрок», у которого можно спрашивать очередной ход, а можно — сообщить ему результат хода.
Если в директории запуска находится файл gametree.dat, программа его прочитает и будет брать из него первые 10 ходов. Если нет — ей придётся вычислять каждый ход с нуля, зато в этом случае можно дать игроку любую последовательность ходов и их результатов, и спросить, что она рекомендует делать дальше.
Читабельность кода по-прежнему никакая…
Итак, вероятность найти корабль на поле F10 — 36.957%, на поле G10 — 36.272%, а на H9 — 29.102%. Так что F10 вероятнее, чем G10 — хотя и всего на 0.7%. Но если подбить ещё один двухпалубник, то программа после очередного попадания почти никогда не пытается стрелять в соседнюю клетку, обычно целится через клетку.
Реализовал ваш алгоритм по описанию, не используя код вашей программы. Посчитал карту пустого поля. Она в точности совпадает с цифрами, которые вы приводите. Также совпадает количество классов эквивалентности (оно устанавливается на 1053612 после добавления 7й строки и далее не увеличивается) и общее число комбинаций. Так что спасибо за приведенные числа! Благодаря им удалось удостовериться, что грубых ошибок в моей программе нет, ну а в вашей — тем более!
Моя программа, хоть и написана на C++, но пока еще работает слишком медленно. Около минуты. Буду оптимизировать. Похоже, что основные тормоза дает использование библиотечного класса std::map. Он, в свою очередь, тормозит в системных функциях занятия и освобождения памяти.
К сожалению, программе для работы требуется много памяти. Из-за большого количества комбинаций приходится использовать 64-битные числа для запоминания карт классов. Это дает 800 байт на класс, всего 842Мб для запоминания карт всех классов, без учета накладных расходов. Реальное использование памяти программой — около 1.5Гб, что, думаю, подлежит оптимизации. Но ниже ~900Мб оптимизировать вряд ли удастся. Можно попытаться использовать дробные 32-битные числа и посмотреть, что из этого выйдет.
Моя программа, хоть и написана на C++, но пока еще работает слишком медленно. Около минуты. Буду оптимизировать. Похоже, что основные тормоза дает использование библиотечного класса std::map. Он, в свою очередь, тормозит в системных функциях занятия и освобождения памяти.
К сожалению, программе для работы требуется много памяти. Из-за большого количества комбинаций приходится использовать 64-битные числа для запоминания карт классов. Это дает 800 байт на класс, всего 842Мб для запоминания карт всех классов, без учета накладных расходов. Реальное использование памяти программой — около 1.5Гб, что, думаю, подлежит оптимизации. Но ниже ~900Мб оптимизировать вряд ли удастся. Можно попытаться использовать дробные 32-битные числа и посмотреть, что из этого выйдет.
Где вы там map используете? Замените на unordered_map — и сразу же получите прирост скорости в число раз порядка логарифма числа элементов. Если в используемой библиотеке unordered_map нет — в инете полно алгоритмов.
Также хорошую оптимизацию могут дать нестандартные аллокаторы, хотя unordered_map не настолько часто дергает память, как map древовидный.
Также хорошую оптимизацию могут дать нестандартные аллокаторы, хотя unordered_map не настолько часто дергает память, как map древовидный.
map используется во время генерации классов эквивалентности при добавлении строки. Новые классы возникают из старых в произвольном порядке, и часть новых классов являются одним и тем же классом и поэтому должны быть объединены. Так что тут нужен ассоциативный контейнер для быстрого поиска. Я сейчас планирую реализовать инвазивное дерево, AVL или Red-Black для этих целей.
А я вам предлагаю использовать хеш-таблицу. Это и есть самый быстрый ассоциативный контейнер для быстрого поиска.
Спасибо. Попробую разные варианты, в том числе hash-based map. Думаю начать с boost::intrusive. Как раз то, что доктор прописал. Там есть разные деревья, и хеш-карты в том числе. Хранить же сами классы и соответствующие им карты я планирую в массиве. Так победим.
Пока что прогресс следующий. Задействовал библиотеку boost. Из нее использую intrusive::set (интрузивное red-black tree). В качестве ключа поиска используется сжатая в 28 бит информация о классе эквивалентности, фактически — одно 32-битное число. Так что функция сравнения теперь тривиальна, и необходимости использовать hash-based-map нет совсем. hash позволяет ускорить сравнение, а тут ускорять нечего, когда сравниваются 32-битные целые.
Для хранения дерева классов и их карт использую boost::circular_buffer. Память выделяется единожды при начале работы алгоритма и далее все крутится в одном буфере. Так что какие-либо тормоза из-за выделения/освобождения памяти теперь тоже исключены. Хотя почему-то программа все равно тратит некоторое количество процессорного времени в режиме ядра. Странно, ведь я не вызываю никаких системных функций. Может быть, это из-за того, что программа много памяти занимает, и работает системный своп-диспетчер? Интенсивной работы диска во время работы программы нет, памяти хватает вроде.
Как ни странно, работа программы по сравнению с прошлой версией (std::map) не ускорилась. Сейчас она отрабатывает чуть меньше, чем за 2 минуты, но я до оптимизации точно не измерял; может быть, так и было. Что любопытно: 64-битный билд работает на 20 секунд быстрее 32-битного. Может быть, выполняется много 64-битных сложений во время обработки карт классов?
Теперь буду оптимизировать другие части программы. Знать бы, какие из них в первую очередь нуждаются в оптимизации. Надо профайлер искать и ставить.
Также появилась идея по поводу радикального ускорения алгоритма. Первые 4 строки в текущей версии обрабатываются значительно быстрее последующих, т.к. количество классов эквивалентности нарастает постепенно. Если начинать процесс одновременно сверху и снизу, а потом как-то объединить результаты — то, может быть, можно посчитать все то же самое быстрее. Но это я буду потом пробовать, после оптимизации работающей версии.
Для хранения дерева классов и их карт использую boost::circular_buffer. Память выделяется единожды при начале работы алгоритма и далее все крутится в одном буфере. Так что какие-либо тормоза из-за выделения/освобождения памяти теперь тоже исключены. Хотя почему-то программа все равно тратит некоторое количество процессорного времени в режиме ядра. Странно, ведь я не вызываю никаких системных функций. Может быть, это из-за того, что программа много памяти занимает, и работает системный своп-диспетчер? Интенсивной работы диска во время работы программы нет, памяти хватает вроде.
Как ни странно, работа программы по сравнению с прошлой версией (std::map) не ускорилась. Сейчас она отрабатывает чуть меньше, чем за 2 минуты, но я до оптимизации точно не измерял; может быть, так и было. Что любопытно: 64-битный билд работает на 20 секунд быстрее 32-битного. Может быть, выполняется много 64-битных сложений во время обработки карт классов?
Теперь буду оптимизировать другие части программы. Знать бы, какие из них в первую очередь нуждаются в оптимизации. Надо профайлер искать и ставить.
Также появилась идея по поводу радикального ускорения алгоритма. Первые 4 строки в текущей версии обрабатываются значительно быстрее последующих, т.к. количество классов эквивалентности нарастает постепенно. Если начинать процесс одновременно сверху и снизу, а потом как-то объединить результаты — то, может быть, можно посчитать все то же самое быстрее. Но это я буду потом пробовать, после оптимизации работающей версии.
Hash позволяет ускорять не сравнение, а поиск!
Хеш-таблица достаточного размера имеет среднее время поиска O(1) — в то время как поиск в дереве — это O(log N). Сколько у вас узлов в дереве? 1053612? Переход к хеш-таблице запросто может ускорить программу в 20 раз.
PS Вот нафига ускорять выделение памяти и сложение матриц — если с самого начала очевидно, что тормозят деревья?
Хеш-таблица достаточного размера имеет среднее время поиска O(1) — в то время как поиск в дереве — это O(log N). Сколько у вас узлов в дереве? 1053612? Переход к хеш-таблице запросто может ускорить программу в 20 раз.
PS Вот нафига ускорять выделение памяти и сложение матриц — если с самого начала очевидно, что тормозят деревья?
Понял толково. В самом деле, вы правы. Нужно будет обязательно попробовать.
У автора оригинального алгоритма тоже использовалась hashtable, однако. См. его коммент. Правда, впоследствии он от нее отказался в пользу некой «битовой реализации». Ну ладно, попробую пройти тот же путь!
У автора оригинального алгоритма тоже использовалась hashtable, однако. См. его коммент. Правда, впоследствии он от нее отказался в пользу некой «битовой реализации». Ну ладно, попробую пройти тот же путь!
Реализовал на boost::unordered_map. Действительно, ускорение оказалось существенным! Теперь программа отрабатывает за 1:05 минут. В полтора раза быстрее стало в целом. По-прежнему медленнее, чем программа автора поста на C#. Его программа на моем компьютере отрабатывает секунд за 35-40 при обсчете первого хода.
Наверно, можно как-то оптимизировать хеши (ускорить их вычисление). И искать еще что-то в программе, что тормозит. Я вчера уже начал посматривать в программу автора поста. Когда реализовал этот алгоритм сам — начинаешь понимать его код понемногу. Может быть найду какие-нибудь трюки, которые он использовал, а я еще нет.
Наверно, можно как-то оптимизировать хеши (ускорить их вычисление). И искать еще что-то в программе, что тормозит. Я вчера уже начал посматривать в программу автора поста. Когда реализовал этот алгоритм сам — начинаешь понимать его код понемногу. Может быть найду какие-нибудь трюки, которые он использовал, а я еще нет.
Думаю, что теперь главный трюк — построение графа переходов между классами и их перенумерация порядковыми номерами. Чтобы во время прохода по полю вообще не требовалось поиска классов.
Раз уж вы участвуете в обсуждении — к вам вопрос следующего плана.
В моей программе классы эквивалентности для разных строк несовместимы. Скажем, после обработки первых трех строк образовалось некоторое количество классов. При обработке четвертой строки из этих классов происходят новые классы, но я пока что никак не утилизирую старые. Обработал класс — стер его из памяти. Это приводит к большому расходу памяти, ведь надо хранить почти полностью две копии карт всех классов. С другой стороны, может быть, есть какие-то правила «наследования» следующей строкой классов от предыдущей строки. Скажем, самый простой класс — пустая строка, 0 кораблей сверху от нее — «выживает» до самого конца, пока он не отвергается в процессе окончательной обработки.
Вы в вашей программе как-то наследуете классы для следующих строк?
В моей программе классы эквивалентности для разных строк несовместимы. Скажем, после обработки первых трех строк образовалось некоторое количество классов. При обработке четвертой строки из этих классов происходят новые классы, но я пока что никак не утилизирую старые. Обработал класс — стер его из памяти. Это приводит к большому расходу памяти, ведь надо хранить почти полностью две копии карт всех классов. С другой стороны, может быть, есть какие-то правила «наследования» следующей строкой классов от предыдущей строки. Скажем, самый простой класс — пустая строка, 0 кораблей сверху от нее — «выживает» до самого конца, пока он не отвергается в процессе окончательной обработки.
Вы в вашей программе как-то наследуете классы для следующих строк?
У меня классы не зависят от номера строки. В класс входят:
— маска занятых клеток в строке
— накопленные длины кораблей в единичных занятых клетках строки
— количество оставшихся кораблей на поле (отдельно — четвёрок, троек, двоек, единиц).
Так что, пустая строка на пока что пустом поле выглядит, как [0x000, [], [1,2,3,4]], и не имеет значения, была ли эта строка первой на поле, или пятой (если первые 4 строки тоже пустые).
Поэтому можно реализовать граф переходов от текущей строки к следующей, и формула пересчёта числа состояний — это всего лишь умножение некоторого вектора на очень большую и очень разреженную матрицу.
Понятно, что в графе нет циклов (за исключением петель на пустых строках), но я это никак не использую. Хотя можно было бы — умножение на треугольную матрицу можно вести без дополнительной памяти на вектор результатов.
— маска занятых клеток в строке
— накопленные длины кораблей в единичных занятых клетках строки
— количество оставшихся кораблей на поле (отдельно — четвёрок, троек, двоек, единиц).
Так что, пустая строка на пока что пустом поле выглядит, как [0x000, [], [1,2,3,4]], и не имеет значения, была ли эта строка первой на поле, или пятой (если первые 4 строки тоже пустые).
Поэтому можно реализовать граф переходов от текущей строки к следующей, и формула пересчёта числа состояний — это всего лишь умножение некоторого вектора на очень большую и очень разреженную матрицу.
Понятно, что в графе нет циклов (за исключением петель на пустых строках), но я это никак не использую. Хотя можно было бы — умножение на треугольную матрицу можно вести без дополнительной памяти на вектор результатов.
Попытался еще разобраться в вашем коде. Возникло такое впечатление, что вы сначала строите список всех классов путем рассмотрения допустимых комбинаций для кораблей сверху, снизу и в самой строке, а также комбинаций вертикальных кораблей, занимающих в рассматриваемой строке клетку. После этого ваша программа многократно проходит этот список и строит карты. Пожалуйста подтвердите, правильно ли я понял. А то ваш код очень труден для понимания; выше я переоценил свои способности по пониманию чужого кода :)
Примерно так. Сначала ищутся непротиворечивые классы (то, чем определяется класс, я уже написал). Непротиворечивый — значит, кораблей в нём не больше, чем возможно. Корабли снизу я не считаю, меня интересуют только длины кусочков кораблей, пересекающих текущую строку.
Потом классы сортируются — чтобы у них была сквозная нумерация и можно было пользоваться бинарным поиском. После этого для каждого класса проверяется, какими строчками его можно продолжить, и какие классы при этом получатся. Получается граф переходов.
Кроме того, для каждого класса определяем, может ли он закончить поле (т.е. если после него пойдут только пустые строки — будет ли набор кораблей полным).
И дальше как-то пересчитываются карты — по набору карт для n строк проходом по графу строится набор для n+1 строки.
Ещё надо учесть, что программа считает не только варианты с пустым полем, но и с частично проверенным, так что при переходах приходится учитывать дополнительные условия. И я не научил её использовать информацию, что корабль ранен, а не убит.
Потом классы сортируются — чтобы у них была сквозная нумерация и можно было пользоваться бинарным поиском. После этого для каждого класса проверяется, какими строчками его можно продолжить, и какие классы при этом получатся. Получается граф переходов.
Кроме того, для каждого класса определяем, может ли он закончить поле (т.е. если после него пойдут только пустые строки — будет ли набор кораблей полным).
И дальше как-то пересчитываются карты — по набору карт для n строк проходом по графу строится набор для n+1 строки.
Ещё надо учесть, что программа считает не только варианты с пустым полем, но и с частично проверенным, так что при переходах приходится учитывать дополнительные условия. И я не научил её использовать информацию, что корабль ранен, а не убит.
И я не научил её использовать информацию, что корабль ранен, а не убит.Это как раз сделать просто. Когда корабль убит — окружаем его заведомо пустыми клетками и в таком виде передаем основному алгоритму.
Это-то просто. Но надо сделать, чтобы когда корабль ранен, она не считала ситуации, в которых он убит. Особенно сложно это считать, когда есть несколько раненых кораблей.
Да, и правда, это сложнее…
В самом деле, это важный момент. Я пока еще не перешел к обсчету частично проверенного поля, и даже не задумывался еще об описанной вами проблеме. Буду пытаться в будущем это учесть. Спасибо!
Есть простое решение (но не для идеального подсчёта, а для игры) — надо заставить программу-игрока добивать раненный корабль. Ситуациями, в которых это невыгодно, можно пренебречь. Просматриваем клетки, в которые корабль может продолжаться, и выбираем из них самую вероятную. Очевидно, что на поле, на котором этот корабль убит, в этих клетках ничего быть не может — а значит, мы видим только информацию от тех полей, где он действительно ранен.
Дальше я бы оптимизировал так. Как работает исходный алгоритм (насколько я его понял)? Идем по всем строкам (N=10), для каждой строки перебираем все классы (M=1053612). Для каждого класса ищем все возможные переходы (d, чему равно не знаю, 210=1024 — это очень грубая оценка сверху) и складываем карты заполнения (N2). Итоговое время — O(N3Md).
Как тут можно оптимизировать? Вычислять для классов не всю карту заполнения, а только общее количество комбинаций, соответствующие классу. Этого достаточно, чтобы в конце работы алгоритма найти общую карту заполнения.
Действительно, пусть у нас уже вычислены все значения c[i, m] = это количества вариантов расположения кораблей на первых i строках с классом эквивалентности m. Пусть нам надо вычислить, в скольких вариантах расположения кораблей занята клетка с координатами (i, j). Тогда достаточно перебрать все классы эквивалентности i-ой строки, допускающие занятость j-й клетки на ней и найти сумму ∑mc[i,m] c[n-i+1,m'], где m' — «дополнение» класса m, составляющие в сумме с ним корректную доску (такое дополнение единственно).
Такой способ подсчета потребует сначала O(NMd) времени на составление таблицы c — а потом еще O(N2M) для нахождения окончательного результата. Итоговое время — O(NMd+N2M) = O(NMd), поскольку d заведомо больше N. Алгоритм асимптотически ускорен в N2 раз. Вряд ли, правда, он реально ускорится в 100 раз — так как он стал куда более сложным, но ускорение должно быть заметным. Особенно учитывая, что алгоритму понадобится еще и меньше памяти…
Как тут можно оптимизировать? Вычислять для классов не всю карту заполнения, а только общее количество комбинаций, соответствующие классу. Этого достаточно, чтобы в конце работы алгоритма найти общую карту заполнения.
Действительно, пусть у нас уже вычислены все значения c[i, m] = это количества вариантов расположения кораблей на первых i строках с классом эквивалентности m. Пусть нам надо вычислить, в скольких вариантах расположения кораблей занята клетка с координатами (i, j). Тогда достаточно перебрать все классы эквивалентности i-ой строки, допускающие занятость j-й клетки на ней и найти сумму ∑mc[i,m] c[n-i+1,m'], где m' — «дополнение» класса m, составляющие в сумме с ним корректную доску (такое дополнение единственно).
Такой способ подсчета потребует сначала O(NMd) времени на составление таблицы c — а потом еще O(N2M) для нахождения окончательного результата. Итоговое время — O(NMd+N2M) = O(NMd), поскольку d заведомо больше N. Алгоритм асимптотически ускорен в N2 раз. Вряд ли, правда, он реально ускорится в 100 раз — так как он стал куда более сложным, но ускорение должно быть заметным. Особенно учитывая, что алгоритму понадобится еще и меньше памяти…
Оптимизировал сложение матриц. Если раньше я всегда складывал полные матрицы (10х10) — то теперь только те строки, в которых содержится информация, в зависимости от того, на какой строке работает в данный момент алгоритм. Ускорение незначительное (порядка 5с), теперь программа отработала за 1:47. Буду копать дальше.
Sign up to leave a comment.
Снова «Морской бой». Считаем число возможных расположений кораблей