Всем привет!
В прошлой статье мы начали разговор о преимуществах контейнерной изоляции (контейнеризации), теперь мне бы хотелось углубится в технические аспекты реализации контейнеров.

Для Linux существует по крайне мере три реализации контейнеров:
Постойте, а где же LXC и что за Linux upstream containers c namespaces да cgroups? Если мы обсуждаем подсистему ядра Linux, отвечающую за изоляцию наборов процессов друг от друга, то называть ее LXC категорически не верно по той причине, что LXC — это имя собственное, название набора утилит только для управления подсистемами ядра Linux, а вовсе не для обеспечения работы контейнеров в ядре!
Механизмы, которые обеспечивают работу контейнеров внутри ядра, называются namespaces (вот хороший обзор данной функциональности). Кроме этого, за ограничения различных ресурсов контейнера (объем занимаемой памяти, нагрузка на диск, нагрузка на центральный процессор) отвечает механизм ядра — cgroups (обзор). А в свою очередь обе эти технологии для удобства повествования я решил объединить под названием Linux upstream containers, то есть контейнеры из актуальной версии Linux ядра с kernel.org.
Если же говорить о пространстве пользователя, то такие пакеты как LXC, systemd-nspawn и даже vzctl (утилита из проекта OpenVZ) занимаются исключительно тем, что создают/удаляют namespac'ы и конфигурируют для них cgroup'ы.
Если с Linux upstream containers все более-менее понятно, так как они входят в ядро Linux, то для OpenVZ потребуются пояснения. OpenVZ — это open source проект развиваемый компанией Parallels (называвшейся ранее SwSoft) с 2005 года (уже более 8 лет) и занимающийся разработкой и поддержкой production ready решения по контейнеризации на базе ядра Linux (патчи накладываются на ядра от RHEL).
Данный проект состоит из двух частей — Linux ядра с патчами от компании Parallels (vzkernel), а также набора утилит для управления ядром (vzctl, vzlist и проч). Так как модифицированное ядро от OpenVZ строится на базе ядра Red Hat Enterprise Linux, то логично предположить, что рекомендованная ОС для OpenVZ — это RedHat либо CentOS. Также недавно была осуществлена очень большая работа по предоставлению поддержки OpenVZ в Debian 7 Wheezy, но со своей стороны я все равно рекомендуют использовать OpenVZ исключительно на CentOS 6.
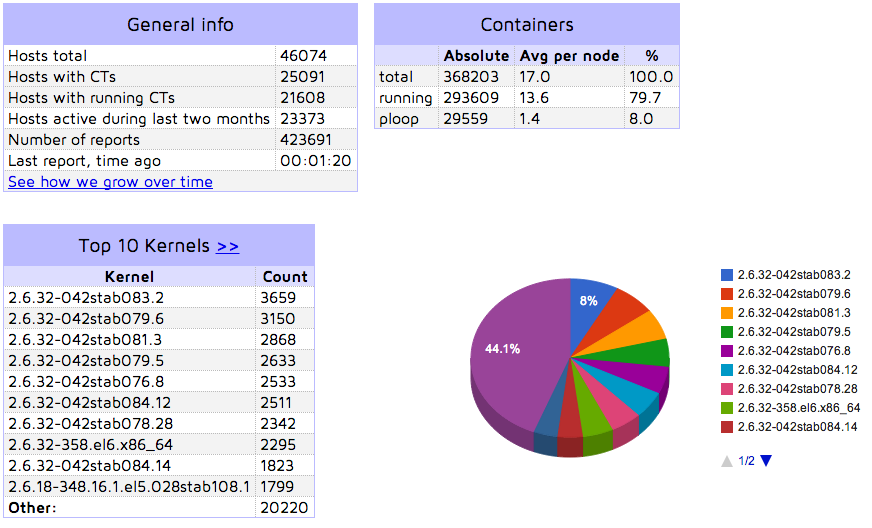
На данный момент в мире насчитывается более 25 тысяч серверов (стоит отметить, что в связи с особенностями сбора статистики, данные несколько занижены) с установленным OpenVZ, подробную статистику можно увидеть тут: https://stats.openvz.org/
Для проекта OpenVZ можно выделить следующие вехи развития:
Я, к сожалению, никак не могу прокомментировать отличия RHEL4/RHEL5 версий, так как даже не видел RHEL 4 версию. А вот отличия в RHEL 5 и 6 — крайне значительные, наиболее важный аспект в них, что солидная часть патча OpenVZ была удалена и вместо нее проект OpenVZ перешел на использование стандартных механизмов ядра Linux — namespace и cgroups, в будущих же версиях данная работа будет продолжена и в светлом будущем OpenVZ для своей работы не будет требовать ничего, кроме набора утилит, весь требуемый функционал ядра будет в Linux upstream.
Две фундаментальных технологии лежат в основе Linux upstream containers — это namespaces и cgroups. Фреймворк namespaces в виде mount namespace был впервые представлен в 2000 году известным разработчиком Al Viro (Alexander Viro). В свою же очередь фреймворк cgroup был разработан в Google, с участием инженеров Paul Menage и Rohit Seth.
Также очень большой вклад в разработку новых подсистем namespaces/cgroups внесли разработчики проекта OpenVZ. В частности, namespace'ы PID и Net были разработаны в контексте проекта OpenVZ. Кроме этого, недавно был переведен в стабильную фазу фреймворк Criu для сериализации/десериализации наборов работающих Linux процессов lwn.net/Articles/572125, разрабатывался он также в контексте решения задач для OpenVZ.
Если Вы хотите оценить вклад самостоятельно, предлагаю два документа — отчет о вкладе компаний в разработку ядра в 2013 году и аналогичный отчет за 2012й год: Parallels там имеет вклад 0.7% и 0.9% соответственно. Может показаться, что 1% — это мало, то хотелось бы напомнить, что размер правок в год достигает нескольких миллионов строк.
Если Вы уже используете OpenVZ и у Вас есть что сообщить (баги) или чем поделиться (патчи), то милости прошу в баг-трекер OpenVZ Каждый Ваш бег репорт улучшает стабильность и качество проекта для всех его пользователей!

Тут я хотел бы пойти по пути, через который, уверен, проходил каждый системный администратор, у которого стояла задача «изолировать пользователей друг от друга» в пределах одного Linux сервера.
Итак, допустим у нас имеется два веб-приложения, которые принадлежат разным клиентам (обращаю внимание, я тут не использую термин «пользователи», чтобы не было путаницы с Linux пользователями) и не должны никак влиять друг на друга (например, при взломе, перегрузке, исчерпании ресурсов) и тем более на сам физический сервер.
Давайте последовательность предпринимаемых шагов представим в виде списка:
Итого, для реализации изоляции базовых систем нам потребовались следующие namespace'ы:
Безусловно, путь был очень тернистый и реализация данных подсистем в ядре шла в немного иной последовательности, но сейчас все они доступны и собрались в такую чудесную картину под названием Linux upstream containers!

Спасибо что остаетесь с нами! В ближайшие дни мы подготовим и опубликуем продолжение серии!
Отдельно хотелось бы поблагодарить Andrey Wagin avagin за помощь в редактуре особо сложных технических вопросов.
С уважением,
CTO хостинг-компании FastVPS
Павел Одинцов
В прошлой статье мы начали разговор о преимуществах контейнерной изоляции (контейнеризации), теперь мне бы хотелось углубится в технические аспекты реализации контейнеров.

Контейнеризация в Linux
Для Linux существует по крайне мере три реализации контейнеров:
- Linux upstream containers (namespaces + cgroups)
- Linux VServer
- OpenVZ
Постойте, а где же LXC и что за Linux upstream containers c namespaces да cgroups? Если мы обсуждаем подсистему ядра Linux, отвечающую за изоляцию наборов процессов друг от друга, то называть ее LXC категорически не верно по той причине, что LXC — это имя собственное, название набора утилит только для управления подсистемами ядра Linux, а вовсе не для обеспечения работы контейнеров в ядре!
Механизмы, которые обеспечивают работу контейнеров внутри ядра, называются namespaces (вот хороший обзор данной функциональности). Кроме этого, за ограничения различных ресурсов контейнера (объем занимаемой памяти, нагрузка на диск, нагрузка на центральный процессор) отвечает механизм ядра — cgroups (обзор). А в свою очередь обе эти технологии для удобства повествования я решил объединить под названием Linux upstream containers, то есть контейнеры из актуальной версии Linux ядра с kernel.org.
Если же говорить о пространстве пользователя, то такие пакеты как LXC, systemd-nspawn и даже vzctl (утилита из проекта OpenVZ) занимаются исключительно тем, что создают/удаляют namespac'ы и конфигурируют для них cgroup'ы.
Что такое OpenVZ?
Если с Linux upstream containers все более-менее понятно, так как они входят в ядро Linux, то для OpenVZ потребуются пояснения. OpenVZ — это open source проект развиваемый компанией Parallels (называвшейся ранее SwSoft) с 2005 года (уже более 8 лет) и занимающийся разработкой и поддержкой production ready решения по контейнеризации на базе ядра Linux (патчи накладываются на ядра от RHEL).
Данный проект состоит из двух частей — Linux ядра с патчами от компании Parallels (vzkernel), а также набора утилит для управления ядром (vzctl, vzlist и проч). Так как модифицированное ядро от OpenVZ строится на базе ядра Red Hat Enterprise Linux, то логично предположить, что рекомендованная ОС для OpenVZ — это RedHat либо CentOS. Также недавно была осуществлена очень большая работа по предоставлению поддержки OpenVZ в Debian 7 Wheezy, но со своей стороны я все равно рекомендуют использовать OpenVZ исключительно на CentOS 6.
На данный момент в мире насчитывается более 25 тысяч серверов (стоит отметить, что в связи с особенностями сбора статистики, данные несколько занижены) с установленным OpenVZ, подробную статистику можно увидеть тут: https://stats.openvz.org/

История развития OpenVZ
Для проекта OpenVZ можно выделить следующие вехи развития:
- OpenVZ для RHEL4 (закрыт по EOL)
- OpenVZ для RHEL5
- OpenVZ для RHEL6
- OpenVZ для RHEL7 (пока в стадии написания)
Я, к сожалению, никак не могу прокомментировать отличия RHEL4/RHEL5 версий, так как даже не видел RHEL 4 версию. А вот отличия в RHEL 5 и 6 — крайне значительные, наиболее важный аспект в них, что солидная часть патча OpenVZ была удалена и вместо нее проект OpenVZ перешел на использование стандартных механизмов ядра Linux — namespace и cgroups, в будущих же версиях данная работа будет продолжена и в светлом будущем OpenVZ для своей работы не будет требовать ничего, кроме набора утилит, весь требуемый функционал ядра будет в Linux upstream.
История развития Linux upstream containers
Две фундаментальных технологии лежат в основе Linux upstream containers — это namespaces и cgroups. Фреймворк namespaces в виде mount namespace был впервые представлен в 2000 году известным разработчиком Al Viro (Alexander Viro). В свою же очередь фреймворк cgroup был разработан в Google, с участием инженеров Paul Menage и Rohit Seth.
Также очень большой вклад в разработку новых подсистем namespaces/cgroups внесли разработчики проекта OpenVZ. В частности, namespace'ы PID и Net были разработаны в контексте проекта OpenVZ. Кроме этого, недавно был переведен в стабильную фазу фреймворк Criu для сериализации/десериализации наборов работающих Linux процессов lwn.net/Articles/572125, разрабатывался он также в контексте решения задач для OpenVZ.
Если Вы хотите оценить вклад самостоятельно, предлагаю два документа — отчет о вкладе компаний в разработку ядра в 2013 году и аналогичный отчет за 2012й год: Parallels там имеет вклад 0.7% и 0.9% соответственно. Может показаться, что 1% — это мало, то хотелось бы напомнить, что размер правок в год достигает нескольких миллионов строк.
Если Вы уже используете OpenVZ и у Вас есть что сообщить (баги) или чем поделиться (патчи), то милости прошу в баг-трекер OpenVZ Каждый Ваш бег репорт улучшает стабильность и качество проекта для всех его пользователей!
Техническая реализация подсистемы изоляции контейнеров

Тут я хотел бы пойти по пути, через который, уверен, проходил каждый системный администратор, у которого стояла задача «изолировать пользователей друг от друга» в пределах одного Linux сервера.
Итак, допустим у нас имеется два веб-приложения, которые принадлежат разным клиентам (обращаю внимание, я тут не использую термин «пользователи», чтобы не было путаницы с Linux пользователями) и не должны никак влиять друг на друга (например, при взломе, перегрузке, исчерпании ресурсов) и тем более на сам физический сервер.
Давайте последовательность предпринимаемых шагов представим в виде списка:
- Можно запустить приложения от различных Linux пользователей. Таким образом безопасность файловой системы соседнего приложения будет контролироваться исключительно системой прав на файлы и папки Linux и при некорректной конфигурации может появиться возможность компрометации файлов. Также все служебные файлы физического сервера будут доступны обоим приложениям, что также может привести к утечке данных и последующей компрометации всей системы. Данный способ не решает всех проблем и нужно что-то более продвинутое.
- Чтобы повысить безопасность файловой системы попробуем использовать функционал chroot, который позволяет «запереть» процесс внутри определенной папки, из которой ему будет очень сложно выбраться. Для этого нам потребуется создать полноценный набор системных файлов (например, посредством debootstrap) для каждого из приложений и положить их в отдельные файловые иерархии. Таким образом, каждое приложение будет иметь собственную никак не пересекающуюся с товарищем файловую иерархию. Но в случае, если процесс внутри chroot работает от имени root пользователя (а таких процессов довольно много), то используя стандартные механизмы (многократный chroot) он сможет выбраться из chroot и попасть в файловую систему физического сервера, что, разумеется, не допустимо. Такой вариант тоже нам не подходит.
- Кроме chroot Linux уже очень давно существует подсистема Linux mount namespace, которая предоставляет более широкий функционал, но с полной защитой, что из него не вырваться. В контейнеризации используется именно он. Так как уже не получится без привлечения кода на С описывать наши действия подробно, я ограничусь их формальным описанием. Итак, задач изоляции обычных файловых систем мы решили.
- Теперь предположим, что каждое из приложений использует фиксированный порт, например, 443й. Как нам поступить, если на сервере всего 1 IP адрес и он прикреплен к физическому серверу? Разумеется, сначала нам потребуется два дополнительных IP адреса, по одному для каждого сервиса. Нам придется назначить оба из них на физический сервер и настроить для каждого приложения явное прослушивание именно его IP адреса. Но что если одно из приложений будет взломано и попробует начать прослушивание какого-либо порта на IP физического сервера или на IP соседа с целью компрометации доступов? У него это получится и никто ему не помешает это сделать. Как же с этим бороться? Тут нам снова помогут namespace'ы — а именно network namespace, посредством которого каждый из контейнеров (пожалуй, их уже можно называть именно так!) получает строго зафиксированный отдельный IP адрес (а также пространство сокетов, портов и роутинг-таблицу). Таким образом будет обеспечена полная изоляция на уровне сокетов, IP адресов и портов от соседа. Никакой взаимное влияние теперь невозможно.
- А сейчас давайте немного полезем в дебри процессов и вспомним, что, например, веб-сервер Apache крайне активно использует семафоры, а акселератор опкода PHP APC очень часто использует shm память. Что произойдет, если один процесс возьмет да и очистить память соседа, которая ему отлично видна? Или прочтет ее и извлекет какие-либо конфиденциальные данные? Категорически неприятное событие, которое сводит все наши ухищрения по изоляции на нет. Но решение есть — IPC namespace, который изолирует семафоры, очереди, мьютексы, shm память для IPC и IPC Sys V в том виде, что каждый контейнер видит только свои IPC ресурсы и ничьи более. Ура! Проблема решена.
- На данном этапе у нас почти все хорошо, но остается проблема с тем, что из контейнера мы видим все процессы физического сервера, а также процессы соседа. Нередко процессы раскрывают пароли или иную важную информацию в своих именах, так что такая возможность — крайне нежелательна. Кроме этого, если мы хотим запустить процесс с фиксированным PID, который уже занят соседним контейнером или хост системой — это у нас не получится, так как Linux требует уникальности PID для всех процессов. Чтобы избавится от такого поведения, мы воспользуется PID namespace, который для каждого контейнера создаст полностью изолированную (от физического сервера и от соседа) систему нумерации PID, что в свою очередь дает возможность запустить, например, несколько процессов с PID равным 1. Стоп, а какой процесс на Linux имеет такой PID? Правильно, init! В нашей «самопальной изоляции» мы дошли до этапа, когда мы можем запустить полноценную систему, а не только 1 процесс внутри контейнера! Ура!
- Но наше счастье по поводу запуска полноценного Linux в контейнере будет неполным, так как хостнеймы будут совпадать у обоих контейнеров с хостнеймом физического сервера, что может, например, при работе по ssh привести к неприятным последствиям да и очень много ПО проверяет корректность хостнейма и его соответствие IP адресу машины. Его тоже надо изолировать, делается это namespace'ом с очень не интуитивным названием — UTS, который всего-навсего позволяет задать каждому контейнеру свой уникальный хостнейм.
Итого, для реализации изоляции базовых систем нам потребовались следующие namespace'ы:
- Mount
- Network
- Pid
- UTS
- IPC
Безусловно, путь был очень тернистый и реализация данных подсистем в ядре шла в немного иной последовательности, но сейчас все они доступны и собрались в такую чудесную картину под названием Linux upstream containers!

Что ждать в продолжении?
- Техническая реализация подсистемы лимитирования аппаратных ресурсов контейнеров
- Общие проблемы при использовании контейнеров
- Преимущества OpenVZ над стандартной контейнеризацией в Linux
- Проблема со стороны user space
- Выводы
Спасибо что остаетесь с нами! В ближайшие дни мы подготовим и опубликуем продолжение серии!
Отдельно хотелось бы поблагодарить Andrey Wagin avagin за помощь в редактуре особо сложных технических вопросов.
С уважением,
CTO хостинг-компании FastVPS
Павел Одинцов
