В нашем проекте возникла следующая задача — есть база с большим количеством товаров, на уровне сотен тысяч. У каждого товара есть сотни динамически создаваемых характеристик. Необходимо обеспечить быструю фильтрацию по товарам по набору различных характеристик. Время формирования ответа должно быть не более 0.3 секунды, нужно поддерживать сложную логику в стиле.
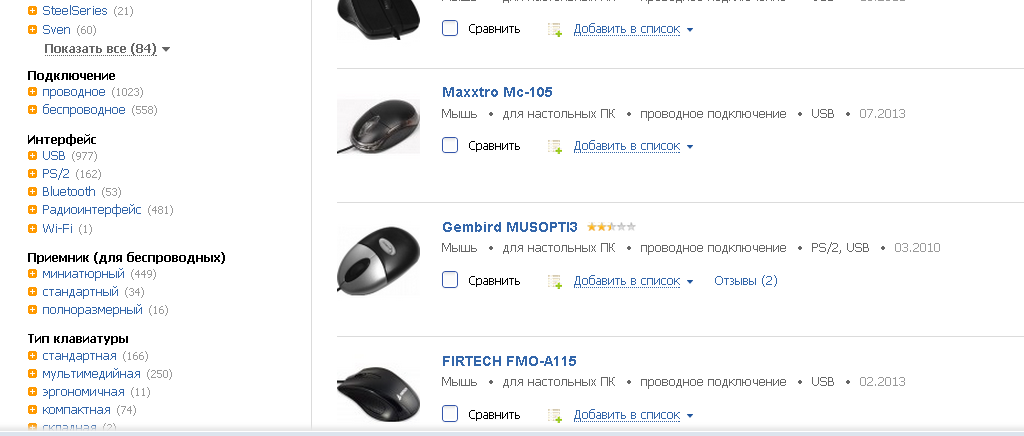
Типичный пример подобного функционала — hotline.ua/computer/myshi-klaviatury
У нас все реализовано в рамках MySQL + Symfony2/Doctrine, скорость неудовлетворительная — ответы формируются в течении 1-10 секунд. Мои попытки оптимизировать все это хозяйство — под катом.
У hotline реализован более продвинутый вариант — с подсказкой, сколько товаров останется после активации критерия. Например, если выбрать фильтр «Bluetooth», то после загрузки страницы возле фильтра «Тип сенсора мыши — оптический» будет цифра 17. Фактически, для такой реализации нужно не просто делать выборку по критериям, но и предварительно для каждого оставшегося фильтра подсчитывать количество товаров при его активации.
Для решения этой задачи я решил опробовать графовую базу данных Neo4j. Для поверхностного ознакомления рекомендую прочитать этот пост.
Для каждого товара создать отдельную ноду, в свойствах ноды хранить id товара в базе MySQL. Для каждого критерия создать свою ноду, в свойствах хранить id критерия. Дальше, связать все ноды товаров с нодами критериев, которые подходят для товара. При изменении характеристик товара или свойств критериев обновлять связи между нодами.
Учитывая, что я с графовыми базами данных никогда не работал — я решил развернуть локально Neo4j, изучить на базовом уровне Cypher и попробовать реализовать требуемую логику. Если все получиться — провести тестирование скорости работы для базы из 1 миллиона товаров, у каждого 500 характеристик.
Разворачивание системы достаточно простое — скачиваем дистрибутив и устанавливаем его.
У Neo4j сервера есть RestAPI, для php есть библиотека neo4jphp. Также есть bundle для интеграции с Symfony2 — klaussilveira/neo4j-ogm-bundle.
В дистрибутив входит веб сервер и приложение для работы с ним, по умолчанию http://localhost:7474/
Есть еще старая версия клиента, с другим функционалом.
В качестве документации удобно использовать краткую документацию. Примеры кода есть в graphgist. По идее, они должны там выполнятся онлайн, но сейчас это не работает. Чтобы посмотреть код нужно перейти по ссылке из graphgist (например, сюда) и там нажать кнопку Page Source.
Для экспериментов с Neo4j очень удобно использовать встроенный веб клиент Там можно выполнять запросы Cypher и просматривать ответ на запросы вместе со связями и характеристиками нод.
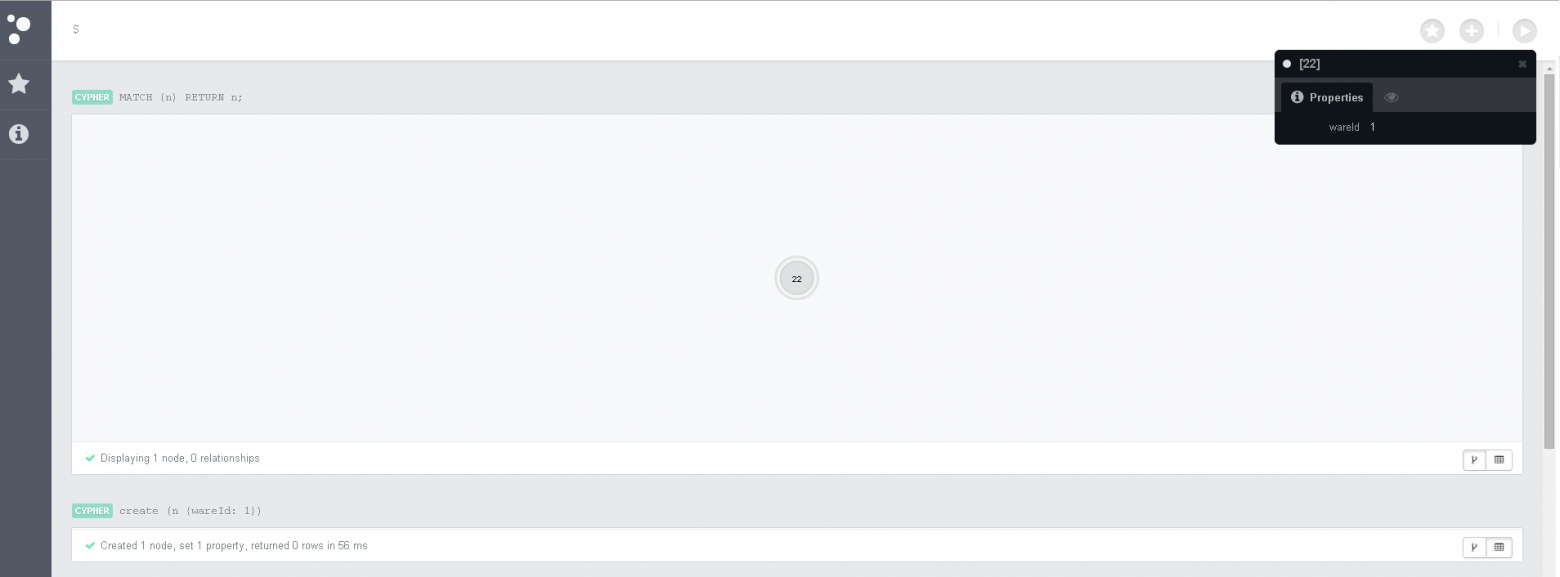
Простые Cypher команды
Создание ноды с меткой
Выбрать все ноды
Счетчик
Создать 2 связанные ноды
Связать 2 существующие ноды
Удалить все связанные ноды
Удалить все несвязанные ноды — если попробовать запустить эту команду в базе, где есть связанные ноды — она не пройдет. Нужно удалить вначале связанные ноды.
Выбрать товары, которым подходит критерий 3
Сразу несколько Cypher команд веб клиент выполнять не умеет. Тут говорят, что старый клиент это умеет, но я не нашел такой возможности. Поэтому, нужно копировать по 1 строке.
Можно выполнить создание множества нод со связями одной командой, нужно давать разные имена нодам, связям можно не давать имя
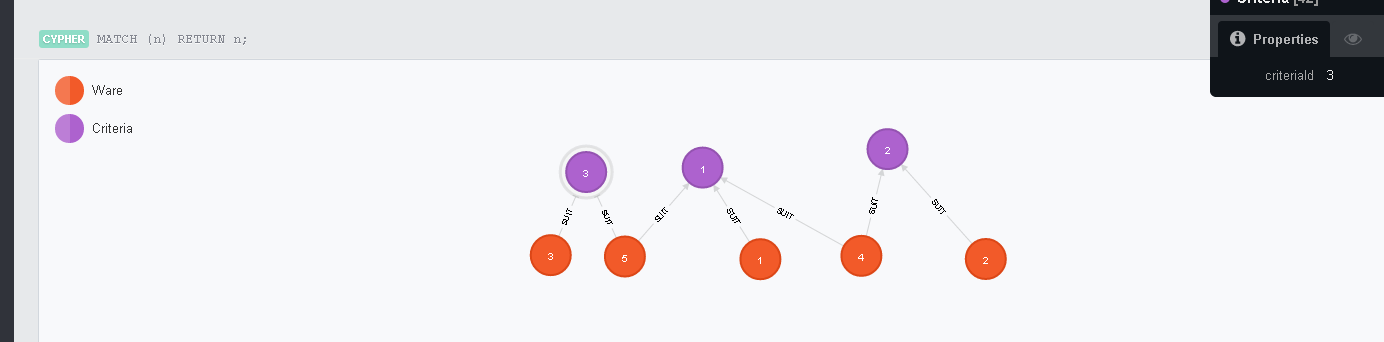
Получится такая структура. Если у вас выглядит менее понятно — можно переставить мышкой ноды.
Пришло время протестировать скорость заполнения базы и простых выборок из большой базой.
Для этого клонируем neo4jphp
Базовое описание этой библиотеки есть в этом посте, поэтому я сразу выложу код для заполнения тестовой базы еxamples/test_fill_1.php
Скрипт заполнения базы я оставил на ночь. Примерно спустя 4 часа скрипт перестал добавлять данные и сервис Neo4j начал грузить сервер на 100%. Утром по итогу работы было вставлено 78300 товаров из 8 категорий товаров.
Результаты тестового заполнения базы — примерно 20 товаров в секунду с 200-400 связями. Не очень высокий результат — Mysql и Cassandra выдавали около 10-20 тысяч вставок в секунду (10 полей, 1 primary index, 1 индекс). Но скорость вставки для нас не критична — мы можем обновлять граф данных в фоновом режиме после редактирования товара. А вот скорость выборки данных — критична.
Размер тестовой базы данных на диске — 1781 мегабайт. В ней хранится 78300 товаров, 4000 критериев, 15660000-31320000 связей. Общее количество объектов (нодов и связей) менее 32 миллионов — в среднем по 55 байт на сущность. Многовато, как по мне, но главное требование все же скорость выборок, а не размер базы.
Первая попытка протестировать скорость выборки провалилась — сервер Neo4j опять «ушел» в режим 100% загрузки процессора и за несколько минут так и не выдал ответ на запрос.
Чтобы двигаться дальше нужно разобраться, как оптимизировать запрос в Neo4j. Вначале я хотел ограничить стартовый набор нод в выборке с помощью инструкции START
Для этого нужно, чтобы в базе были индексы. В Neo4j я не нашел команду для просмотра перечня текущих индексов, но в веб приложении Neo4j можно набрать команду
Добавить индексы можно командой
Уникальный индекс можно создать командой
Индексы, добавленные командами выше, нельзя использовать в START директиве. Тут утверждают, что их можно использовать только в where
Если я правильно понял документацию, можно смело использовать WHERE вместо START
Так родился первый рабочий запрос
В нашей тестовой базе индексов не обнаружено, поэтому мы создадим еще одну базу для теста другим способом. Возможности создать независимые наборы данных (аналог базы данных в MySQL) в Neo4j я не нашел. Поэтому для тестирования я просто менял путь к хранилищу данных в настройках Neo4j Community (Database location)
Внимательные читатели возможно обнаружили пару комментариев в коде test_fill_1.php, а именно
В batch режиме в Neo4jphp у меня не получилось добавить метки к нодам, а индексы почему то не сохранились. Учитывая, что Cypher перестал для меня быть китайской грамотой, я решил заполнять базу хардкорно — на чистом Cypher. Так получился test_fill_2.php
Скорость добавления данных оказалась предсказуемо большей, чем в первом варианте.
Тестовый скрипт с добавлением 30000 нодов и 500000 — 1000000 связей на cypher отработал за 140 секунд, база заняла на диске 62 мегабайта. При попытке запустить скрипт c $waresCount=1000 (не говоря уже о 10000 товаров) я получил ошибку «Stack overflow error». Я переписал скрипт c использованием.
Это привело к катастрофическому падению скорости работы, модифицированный скрипт работал примерно около часа. Я решил протестировать скорость выборки по нескольким критериям и вернуться к вопросу быстрой вставки данных позже.
Скрипт выше отработал за 0.02 секунды. В целом — это вполне приемлемо, но проблема как быстро сохранять большое количество связей между нодами при апдейте свойств товара — осталась.
Я решил «для очистки совести» опробовать MySQL в качестве хранилища. Связи между нодами будут храниться в отдельной таблице без дополнительной информации.
Тестовый скрипт для заполнения базы ниже
Заполнение базы заняло 12 секунд. Размер таблицы — 37 мегабайт. Поиск по 2 критериям занимает 0.0007 секунд
Под mysql есть полноценное графовое хранилище данных — но я его не тестировал. Судя по документации, он гораздо примитивнее Neo4j.
Neo4j — очень крутая штука. Запрос наподобие «Выбрать контакты пользователей, которые лайкнули киноактёров, которые снялись в фильмах, в которых звучали саунтдтреки, которые были написаны музыкантами, которым я поставил лайк» в Neo4j решается тривиально. Примерно так
Для SQL это гораздо более хлопотное занятие.
Сравнивать полноценную графовую базу с голой таблицей индексов в MySQL — некорректно, но в рамках решения моей задачи — использование Neo4j никаких плюсов не дало.
UPDATE. Изменил url'ы картинок, по идее должны у всех загрузаться.
UPDATE 2. Предложили еще несколько вариантов — MongoDB, elasticsearch, solr, sphinx, OrientDB. Планирую протестировать MongoDB, результаты тестов выложу тут же.
(характеристика1 = true AND (характеристика2 < 100)) OR (характеристика1 = false AND (характеристика3 > 17)) ... далее обычно мешанина из AND\ORТипичный пример подобного функционала — hotline.ua/computer/myshi-klaviatury

У нас все реализовано в рамках MySQL + Symfony2/Doctrine, скорость неудовлетворительная — ответы формируются в течении 1-10 секунд. Мои попытки оптимизировать все это хозяйство — под катом.
Терминология задачи по фильтрации товаров (в упрощенном виде)
- характеристика — определенное свойство товара. Например, объем памяти.
- шаблон товара — набор всех возможных характеристик однотипных товаров, например — перечень возможных характеристик компьютерных мышек. При добавлении нового товара администратор может выбирать характеристики в рамках шаблона. Добавить новую характеристику для одного товара невозможно — нужно добавить характеристику в шаблон для этого товара. Одновременно эта характеристика будет доступна для всех товаров, использующих этот шаблон
- группа товаров — товары на основе одного шаблона. Например, компьютерные мышки. Фильтрация делается только для товаров из одной группы
- критерий — логическое правило, которое состоит из набора формальных требований к характеристикам товара. Например, «геймерская мышка» — это набор требований к характеристикам (размер не миниатюрный) AND (сенсор лазерный) AND (разрешение сенсора не менее 1500)
- фильтр — группа критериев для однотипных товаров. В зависимости от критериев, они могут комбинироваться через AND или OR
У hotline реализован более продвинутый вариант — с подсказкой, сколько товаров останется после активации критерия. Например, если выбрать фильтр «Bluetooth», то после загрузки страницы возле фильтра «Тип сенсора мыши — оптический» будет цифра 17. Фактически, для такой реализации нужно не просто делать выборку по критериям, но и предварительно для каждого оставшегося фильтра подсчитывать количество товаров при его активации.
Для решения этой задачи я решил опробовать графовую базу данных Neo4j. Для поверхностного ознакомления рекомендую прочитать этот пост.
Терминология Neo4j и графовых баз данных в целом.
- graph database, графовая база данных — база данных построенная на графах — узлах и связях между ними
- Cypher — язык для написания запросов к базе данных Neo4j (примерно, как SQL в MYSQL)
- node, нода — объект в базе данных, узел графа. Количество узлов ограниченно 2 в степени 35 ~ 34 биллиона
- node label, метка ноды — используется как условный «тип ноды». Например, ноды типа movie могут быть связанны с нодами типа actor. Метки нод — регистрозависимые, причем Cypher не выдает ошибок, если набрать не в том регистре название.
- relation, связь — связь между двумя нодами, ребро графа. Количество связей ограниченно 2 в степени 35 ~ 34 биллиона
- relation identirfier, тип связи — в Neo4j у связей. Максимальное количество типов связей 32767
- properties, свойства ноды — набор данных, которые можно назначить ноде. Например, если нода — это товар, то в свойствах ноды можно хранить id товара из базы MySQL
- node ID, ID нода — уникальный идентификатор ноды. По умолчанию, при просмотрах результата отображается именно этот ID. как его использовать в Cypher запросах я не нашел
Схема решения задачи
Для каждого товара создать отдельную ноду, в свойствах ноды хранить id товара в базе MySQL. Для каждого критерия создать свою ноду, в свойствах хранить id критерия. Дальше, связать все ноды товаров с нодами критериев, которые подходят для товара. При изменении характеристик товара или свойств критериев обновлять связи между нодами.
Первый вариант решения — с Neo4j
Учитывая, что я с графовыми базами данных никогда не работал — я решил развернуть локально Neo4j, изучить на базовом уровне Cypher и попробовать реализовать требуемую логику. Если все получиться — провести тестирование скорости работы для базы из 1 миллиона товаров, у каждого 500 характеристик.
Разворачивание системы достаточно простое — скачиваем дистрибутив и устанавливаем его.
У Neo4j сервера есть RestAPI, для php есть библиотека neo4jphp. Также есть bundle для интеграции с Symfony2 — klaussilveira/neo4j-ogm-bundle.
В дистрибутив входит веб сервер и приложение для работы с ним, по умолчанию http://localhost:7474/
Есть еще старая версия клиента, с другим функционалом.
В качестве документации удобно использовать краткую документацию. Примеры кода есть в graphgist. По идее, они должны там выполнятся онлайн, но сейчас это не работает. Чтобы посмотреть код нужно перейти по ссылке из graphgist (например, сюда) и там нажать кнопку Page Source.
Для экспериментов с Neo4j очень удобно использовать встроенный веб клиент Там можно выполнять запросы Cypher и просматривать ответ на запросы вместе со связями и характеристиками нод.
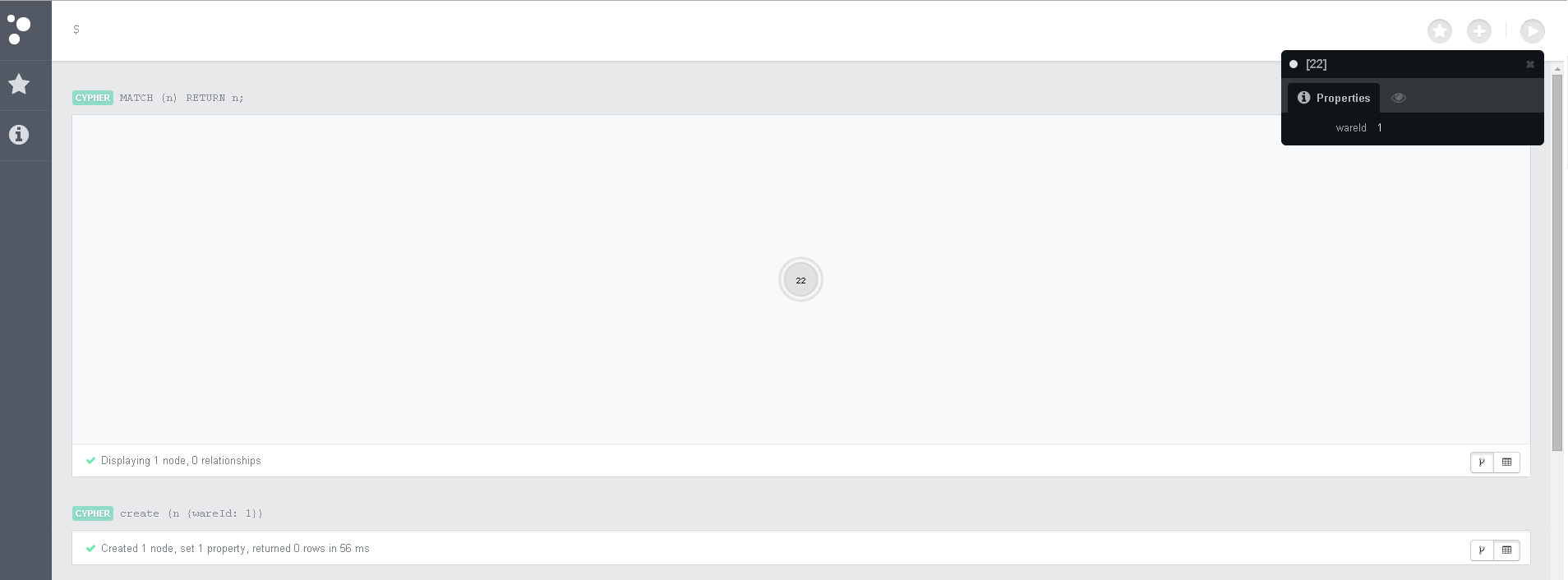
Простые Cypher команды
Создание ноды с меткой
create (n:Ware {wareId: 1}); Выбрать все ноды
MATCH (n) RETURN n;Счетчик
MATCH (n:Ware {wareId:1}) RETURN "Our graph have "+count(*)+" Nodes with label Ware and wareId=1" as counter;Создать 2 связанные ноды
CREATE (n{wareId:1})-[r:SUIT]->(m{criteriaId:1})Связать 2 существующие ноды
MATCH (a {wareId: 1}),
(b {criteriaId: 2})
MERGE (a)-[r:SUIT]->(b)Удалить все связанные ноды
match (n)-[r]-() DELETE n,r;Удалить все несвязанные ноды — если попробовать запустить эту команду в базе, где есть связанные ноды — она не пройдет. Нужно удалить вначале связанные ноды.
match n DELETE n;Выбрать товары, которым подходит критерий 3
MATCH (a:Ware)-->(b:Criteria {criteriaId: 3}) RETURN a;Сразу несколько Cypher команд веб клиент выполнять не умеет. Тут говорят, что старый клиент это умеет, но я не нашел такой возможности. Поэтому, нужно копировать по 1 строке.
Можно выполнить создание множества нод со связями одной командой, нужно давать разные имена нодам, связям можно не давать имя
CREATE (w1:Ware{wareId:1})-[:SUIT]->(c1:Criteria{criteriaId:1}), (w2:Ware{wareId:2})-[:SUIT]->(c2:Criteria{criteriaId:2}), (w3:Ware{wareId:3})-[:SUIT]->(c3:Criteria{criteriaId:3}), (w4:Ware{wareId:4})-[:SUIT]->(c1), (w5:Ware{wareId:5})-[:SUIT]->(c1), (w4)-[:SUIT]->(c2), (w5)-[:SUIT]->(c3);
Получится такая структура. Если у вас выглядит менее понятно — можно переставить мышкой ноды.

Промежуточные тесты скорости Neo4j
Пришло время протестировать скорость заполнения базы и простых выборок из большой базой.
Для этого клонируем neo4jphp
git clone https://github.com/jadell/neo4jphp.gitБазовое описание этой библиотеки есть в этом посте, поэтому я сразу выложу код для заполнения тестовой базы еxamples/test_fill_1.php
<?php
use Everyman\Neo4j\Client,
Everyman\Neo4j\Index\NodeIndex,
Everyman\Neo4j\Relationship,
Everyman\Neo4j\Node,
Everyman\Neo4j\Cypher;
require_once 'example_bootstrap.php';
$neoClient = new Client();
$neoWares = new NodeIndex($neoClient, 'Ware');
$neoCriterias = new NodeIndex($neoClient, 'Criteria');
$neoWareLabel = $neoClient->makeLabel('Ware');
$neoCriteriaLabel = $neoClient->makeLabel('Criteria');
$wareTemplatesCount = 200; // количество шаблонов товара
$criteriasCount = 500; // количество критериев
$waresCount = 10000; // количество товаров
$commitWares = 100; // количество товаров, которое будет идти в 1 batch
$minRelations = 200; // минимальное количество связей товара с критериями
$maxRelations = 400; // максимальное количество связей товара с критериями
$time = time();
for($wareTemplateId = 0;$wareTemplateId<$wareTemplatesCount;$wareTemplateId++) {
$neoClient->startBatch();
print $wareTemplateId." (".$criteriasCount." criterias, ".$waresCount." wares with rand(".$minRelations.",".$maxRelations.") ...";
$criterias = array();
// создаем критерии
for($criteriaId = 1;$criteriaId <=$criteriasCount;$criteriaId++) {
$c = $neoClient->makeNode()->setProperty('criteriaId', $wareTemplateId * $criteriasCount + $criteriaId)->save(); // ->addLabels(array($neoCriteriaLabel)) - не работает с commitBatch
$neoCriterias->add($c, 'criteriaId', $wareTemplateId * $wareTemplatesCount + $criteriaId); // ->save() такого метода нет
$criterias[] = $c;
}
// создаем товары
for($wareId = 1;$wareId <=$waresCount;$wareId++) {
$w = $neoClient->makeNode()->setProperty('wareId', $wareTemplateId * $waresCount + $wareId)->save(); // ->addLabels(array($neoWareLabel)) - не работает с commitBatch
$neoWares->add($c, 'wareId', $wareTemplateId * $waresCount + $criteriaId);
// каждый товар привязываем к случайному количеству критериев
for($i = 1;$i<=rand($minRelations,$maxRelations);$i++) {
$w->relateTo($criterias[array_rand($criterias)], "SUIT")->save();
}
if(($wareId % $commitWares) == 0) {
// комитим, при слишком больших комитах Neo4j зависает
$neoClient->commitBatch();
print " [commit ".$commitWares." ".(time() - $time)." sec]";
$time = time();
$neoClient->startBatch();
}
}
$neoClient->commitBatch();
print " done in ".(time() - $time)." seconds\n";
$time = time();
}
Скрипт заполнения базы я оставил на ночь. Примерно спустя 4 часа скрипт перестал добавлять данные и сервис Neo4j начал грузить сервер на 100%. Утром по итогу работы было вставлено 78300 товаров из 8 категорий товаров.
Результаты тестового заполнения базы — примерно 20 товаров в секунду с 200-400 связями. Не очень высокий результат — Mysql и Cassandra выдавали около 10-20 тысяч вставок в секунду (10 полей, 1 primary index, 1 индекс). Но скорость вставки для нас не критична — мы можем обновлять граф данных в фоновом режиме после редактирования товара. А вот скорость выборки данных — критична.
Размер тестовой базы данных на диске — 1781 мегабайт. В ней хранится 78300 товаров, 4000 критериев, 15660000-31320000 связей. Общее количество объектов (нодов и связей) менее 32 миллионов — в среднем по 55 байт на сущность. Многовато, как по мне, но главное требование все же скорость выборок, а не размер базы.
Первая попытка протестировать скорость выборки провалилась — сервер Neo4j опять «ушел» в режим 100% загрузки процессора и за несколько минут так и не выдал ответ на запрос.
MATCH (c {criteriaId: 1})<--(a)-->(b {criteriaId: 3}) RETURN a.wareId;Чтобы двигаться дальше нужно разобраться, как оптимизировать запрос в Neo4j. Вначале я хотел ограничить стартовый набор нод в выборке с помощью инструкции START
START n=node:nodeIndexName(key={value}) MATCH (c)<--(a)-->(b) RETURN a.wareId;
Для этого нужно, чтобы в базе были индексы. В Neo4j я не нашел команду для просмотра перечня текущих индексов, но в веб приложении Neo4j можно набрать команду
:schemaДобавить индексы можно командой
CREATE INDEX ON :Criteria(criteriaId)Уникальный индекс можно создать командой
CREATE CONSTRAINT ON (n:Criteria) ASSERT n.criteriaId IS UNIQUE;Индексы, добавленные командами выше, нельзя использовать в START директиве. Тут утверждают, что их можно использовать только в where
The indexes created via Cypher are called Schema indexes, and are not to be used in the START clause. The START clause index lookups are reserved for the legacy indexes that you create via autoindexing or through the non-Cypher APIs.
In order to use the :user index you've created, you can do this:
match n:user
where n.name=«aapo»
return n;
Если я правильно понял документацию, можно смело использовать WHERE вместо START
START is optional. If you do not specify explicit starting points, Cypher will try and infer starting points from your query. This is done based on node labels and predicates contained in your query. See Chapter 14, Schema for more information. In general, the START clause is only really needed when using legacy indexes.
Так родился первый рабочий запрос
MATCH (a:Ware)-->(c1:Criteria {criteriaId: 3}),(c2:Criteria {criteriaId: 1}),(c3:Criteria {criteriaId: 2}) WHERE (a)-->(c2) AND (a)-->(c3) RETURN a;
В нашей тестовой базе индексов не обнаружено, поэтому мы создадим еще одну базу для теста другим способом. Возможности создать независимые наборы данных (аналог базы данных в MySQL) в Neo4j я не нашел. Поэтому для тестирования я просто менял путь к хранилищу данных в настройках Neo4j Community (Database location)
Внимательные читатели возможно обнаружили пару комментариев в коде test_fill_1.php, а именно
$c = $neoClient->makeNode()->setProperty('criteriaId', $wareTemplateId * $criteriasCount + $criteriaId)->save(); // ->addLabels(array($neoCriteriaLabel)) - не работает с commitBatch
$neoCriterias->add($c, 'criteriaId', $wareTemplateId * $wareTemplatesCount + $criteriaId); // ->save() такого метода нет
В batch режиме в Neo4jphp у меня не получилось добавить метки к нодам, а индексы почему то не сохранились. Учитывая, что Cypher перестал для меня быть китайской грамотой, я решил заполнять базу хардкорно — на чистом Cypher. Так получился test_fill_2.php
<?php
use Everyman\Neo4j\Client,
Everyman\Neo4j\Index\NodeIndex,
Everyman\Neo4j\Relationship,
Everyman\Neo4j\Node,
Everyman\Neo4j\Cypher;
require_once 'example_bootstrap.php';
$neoClient = new Client();
$wareTemplatesCount = 100; // количество шаблонов товара
$criteriasCount = 50; // количество критериев
$waresCount = 250; // количество товаров
$minRelations = 20; // минимальное количество связей товара с критериями
$maxRelations = 40; // максимальное количество связей товара с критериями
if($maxRelations > $criteriasCount) {
throw new \Exception("maxRelations[".$maxRelations."] should be bigger, that criteriasCount[".$criteriasCount."]");
}
$query = new Cypher\Query($neoClient, "CREATE CONSTRAINT ON (n:Criteria) ASSERT n.criteriaId IS UNIQUE;", array());
$result = $query->getResultSet();
$query = new Cypher\Query($neoClient, "CREATE CONSTRAINT ON (n:Ware) ASSERT n.wareId IS UNIQUE;", array());
$result = $query->getResultSet();
for($wareTemplateId = 0;$wareTemplateId<$wareTemplatesCount;$wareTemplateId++) {
$time = time();
$queryTemplate = "CREATE ";
print $wareTemplateId." (".$criteriasCount." criterias, ".$waresCount." wares with rand(".$minRelations.",".$maxRelations.") ...";
$criterias = array();
for($criteriaId = 1;$criteriaId <=$criteriasCount;$criteriaId++) {
// создаем нод критерия в виде (w1:Ware{wareId:1})
$cId = $criteriaId + $criteriasCount*$wareTemplateId;
$queryTemplate .= "(c".$cId.":Criteria{criteriaId:".$cId."}), ";
$criterias[] = $cId;
}
for($wareId = 1;$wareId <=$waresCount;$wareId++) {
$wId = $wareId + $waresCount*$wareTemplateId;
// создаем нод товара в виде (w1:Ware{wareId:1})
$queryTemplate .= "(w".$wId.":Ware{wareId:".$wId."}), ";
// создаем связи между нодами в виде (w1)-[:SUIT]->(c1)
$possibleLinks = array_merge(array(), $criterias); // clone $criterias не работает
for($i = 1;$i<=rand($minRelations,$maxRelations);$i++) {
$linkId = $possibleLinks[array_rand($possibleLinks)];
unset($possibleLinks[$linkId]);
$queryTemplate .= "w".$wId."-[:SUIT]->c".$linkId.", ";
}
}
$queryTemplate = substr($queryTemplate,0,-2); // удаляем последний ", "
$build = time();
$query = new Cypher\Query($neoClient, $queryTemplate, array()); // $queryTemplate будет в районе 42 мегабайт для 10000 товаров, 500 критериев, 200-400 связей между товаром-критерием
$result = $query->getResultSet();
print " Query build in ".($build - $time)." seconds, executed in ".(time() - $build)." seconds\n";
// die();
}
Скорость добавления данных оказалась предсказуемо большей, чем в первом варианте.
Тестовый скрипт с добавлением 30000 нодов и 500000 — 1000000 связей на cypher отработал за 140 секунд, база заняла на диске 62 мегабайта. При попытке запустить скрипт c $waresCount=1000 (не говоря уже о 10000 товаров) я получил ошибку «Stack overflow error». Я переписал скрипт c использованием.
MATCH (a {wareId: 1}),
(b {criteriaId: 2})
MERGE (a)-[r:SUIT]->(b)
Это привело к катастрофическому падению скорости работы, модифицированный скрипт работал примерно около часа. Я решил протестировать скорость выборки по нескольким критериям и вернуться к вопросу быстрой вставки данных позже.
<?php
use Everyman\Neo4j\Client,
Everyman\Neo4j\Index\NodeIndex,
Everyman\Neo4j\Relationship,
Everyman\Neo4j\Node,
Everyman\Neo4j\Cypher;
require_once 'example_bootstrap.php';
$neoClient = new Client();
$time = microtime();
$query = new Cypher\Query($neoClient, "MATCH (a:Ware)-->(b:Criteria {criteriaId: 3}),(c:Criteria {criteriaId: 1}),(c2:Criteria {criteriaId: 2}) WHERE (a)-->(c) AND (a)-->(c2) RETURN a;", array());
$result = $query->getResultSet();
print "Done in ".(microtime() - $time)." seconds\n";
Скрипт выше отработал за 0.02 секунды. В целом — это вполне приемлемо, но проблема как быстро сохранять большое количество связей между нодами при апдейте свойств товара — осталась.
Альтернативное решение
Я решил «для очистки совести» опробовать MySQL в качестве хранилища. Связи между нодами будут храниться в отдельной таблице без дополнительной информации.
CREATE TABLE IF NOT EXISTS `edges` (
`criteriaId` int(11) NOT NULL,
`wareId` int(11) NOT NULL,
UNIQUE KEY `criteriaId` (`criteriaId`,`wareId`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
Тестовый скрипт для заполнения базы ниже
<?php
mysql_connect("localhost", "root", "");
mysql_select_db("test_nodes");
$wareTemplatesCount = 100;
$criteriasCount = 50;
$waresCount = 250;
$minRelations = 20;
$maxRelations = 40;
$time = time();
for($wareTemplateId = 0;$wareTemplateId<$wareTemplatesCount;$wareTemplateId++) {
$criterias = array();
for($criteriaId = 1;$criteriaId <=$criteriasCount;$criteriaId++) {
$criterias[] = $wareTemplateId * $criteriasCount + $criteriaId;
}
for($wareId = 1;$wareId <=$waresCount;$wareId++) {
$edges = array();
$wId = $wareTemplateId * $waresCount + $wareId;
$links = array_rand($criterias,rand($minRelations,$maxRelations));
foreach($links as $linkId) {
$edges[] = "(".$criterias[$linkId].",".$wareId.")";
}
// заносим сразу связи между товарами и критериями
mysql_query("INSERT INTO edges VALUES ".implode(",",$edges));
}
print ".";
}
print " [added ".$wareTemplatesCount." templates in ".(time() - $time)." sec]";
$time = time();
Заполнение базы заняло 12 секунд. Размер таблицы — 37 мегабайт. Поиск по 2 критериям занимает 0.0007 секунд
SELECT e1.wareId
FROM `edges` AS e1
JOIN edges AS e2 ON e1.wareId = e2.wareId
WHERE e1.criteriaId =17
AND e2.criteriaId =31
Еще один вариант
Под mysql есть полноценное графовое хранилище данных — но я его не тестировал. Судя по документации, он гораздо примитивнее Neo4j.
Выводы
Neo4j — очень крутая штука. Запрос наподобие «Выбрать контакты пользователей, которые лайкнули киноактёров, которые снялись в фильмах, в которых звучали саунтдтреки, которые были написаны музыкантами, которым я поставил лайк» в Neo4j решается тривиально. Примерно так
MATCH (me:User {userId:123})-[:Like]->(musicants:User)-[:Author]->(s:Soundtrack)-[:Used]->(f:Film)<-[:Starred]-(actor: User)<-[:Like]-(u:User) RETURN u
Для SQL это гораздо более хлопотное занятие.
Сравнивать полноценную графовую базу с голой таблицей индексов в MySQL — некорректно, но в рамках решения моей задачи — использование Neo4j никаких плюсов не дало.
UPDATE. Изменил url'ы картинок, по идее должны у всех загрузаться.
UPDATE 2. Предложили еще несколько вариантов — MongoDB, elasticsearch, solr, sphinx, OrientDB. Планирую протестировать MongoDB, результаты тестов выложу тут же.
