Публикуем статью, написанную на основании предыдущего доклада Ирины Суровой с прошлой конференции Analyst Days. В этом году Ирина выступает не только в роли докладчика, но и члена программного комитета будущей московской конференции.

Видео доклада:
Презентация доклада:
www.slideshare.net/VLDCORP/ss-21934265
Добрый день, мы сейчас будем говорить про трассировки. Сразу скажу, что это проект, в котором трассировки получились. И это был проект, можно сказать, очень долгая тестовая кошечка, потому что в начале мы могли посмотреть на производство этого продукта, на его релиз, в котором трассировок не было вообще, потом они появлялись и сейчас они улучшаются. Т.е. получаются такие лабораторные исследования: когда нулевой уровень берем, потом у нас какие-то изменения, есть возможность посмотреть, что получилось и поменять что-то дальше.
.
Я занимаюсь системным анализом в ИТ. Самим ИТ я занимаюсь очень давно, в системном анализе около 5 лет. Перешла от тестеров и, причем, будучи тестером, мысль о том, что нужны связи между требованиями и тест-кейсами, меня не покидала. C тех пор я очень люблю эту тему. И теперь у меня появилась такая возможность, и я решила рассказать об этом вам.
В общем, на слайде можете видеть то, чем я занимаюсь, чем горжусь, с какими вопросами ко мне можно обращаться.
• Трассировки в учебной литературе — серебряная пуля
• Трассировки на практике — тяжело и трудно
• Трассировки в research — вызовы и надежды (см. ollygotel.com/requirements-traceability)
• Я перфекционист и практик
• Есть экспериментальные данные — хочу поделиться
Коротко об определении:
[Gotel and Finkelstein 1994]
Или говоря по-русски:
Если мы посмотрим в учебную литературу (Вигерса и т.д.), все говорят о том, что трассировки нужно вести, без них невозможен impact analysis, невозможно точное планирование и текущее понимание, где находится проект. Но в реальности чаще всего это очень тяжело и трудно. Такой опыт, когда это тяжело и трудно, также есть и на моем проекте. А при этом, кроме опыта людей типа Вигерса, т.е. людей из индустрии, которые пишут учебники, и моего собственного опыта, тут приведена информация о том, как к теме traceability (трассировок) относится научное сообщество Computer science. Здесь я привела ссылку на сайт дамы, которая занимается этим как независимый researcher в Нью-Йорке. Она входит в сообщество людей, которое разрабатывает Traceability Body of Knowledge.У них есть целый roadmap, как они планируют развивать эту дисциплину и у нее на сайте достаточно много всего интересного, но очень научного. Соответственно, в моем докладе будут попадаться слайды, которые я буду перелистывать, потому что там много текста. Потом вы сможете их посмотреть. В принципе, большую часть из этого я проговорю. Я хочу, чтобы эта презентация потом могла помочь в каких-то конкретных случаях. Понятно, что сейчас все устали и хочется картинок. Поэтому сейчас будут картинки, а потом, если захотите, посмотрите на текст.
У меня есть экспериментальные данные на основе 3 релизов: релиз 1, который прошел без трассировок, релиз 2, который прошел с трассировками, а сейчас мы спланировали релиз 3, который пройдёт с улучшенными трассировками.
• 1 из продуктов лаборатории Касперского
• 3 релиза (прошлое, настоящее, будущее)
• Влияние бизнес-требований
• Влияние архитектуры
• Влияние окружающей среды (инструменты, практики и т.д.)
Итак, это контекст нашего проекта. Это один из продуктов Лаборатории Касперского. Релиз примерно раз в год. Продукт достаточно сложный. Я пришла примерно в середине релиза 1. Мы немного обсудим, как строилось управление требованиями и, в принципе, создание требований во всех релизах, а также посмотрим, что на это влияет: сбор бизнес-требований, структура проекта, культура компании. Дело в том, что у нас в компании одновременно развиваются несколько продуктов, и соответственно, получается, что окружающая среда может сильно повлиять на это всё.

Картинка №1. Когда я пришла на этот проект, это были системы (на схеме белые квадратики), которые мы использовали для управления требованиями. Это Excel, в нем был список бизнес-требований на уровне «хочу, чтобы была такая фича» (достаточно крупная). Например, «управление устройствами». Плюс абзац вроде «флешками управлять на ноутбуках». Вот это бизнес-требование. И таких – целый список в Excel.
Кроме этого, т.к. продукт строился на базе другого продукта, кроме таких бизнес-требований были еще требования в виде «взять фичу оттуда и вставить в новый продукт» либо «я хочу вот это, но, пожалуйста, под таким углом и чтобы система управления правами пользователя была». Вот это первый уровень описания – уровень бизнес-требований.
Второй уровень – это системные требования на функциональную область, т.е. уточнение бизнес-требований, которые содержались в другом файле Excel. Т.е. есть фича «управление устройствами» — отлично, делаем файл Excel «управление устройствами» и в ней ведутся требования. Кое-где встречаются картинки, диаграммы и т.д. Но основной набор – это файл, в котором все требования ведутся. Т.е. мы можем поставить, допустим, ссылку из бизнес-требования на файл Excel, но я бы не сказала, что это трассировки. Кроме этого, получается, видим артефакты, с которыми работают системные аналитики, а также я выделила здесь план проекта и почту.
Соответственно, когда мы говорим о бизнес-требованиях и системных требованиях, мы всегда помним, для чего они нужны. РМ’у они нужны для того, чтобы планировать проект, а команде они нужны, чтобы разрабатывать. В любом случае появляется план проекта и другие артефакты. Т.к. на этом проекте аналитики работали с Excel и почтой, я остальные системы не привожу (например, есть системы ведения версий файлов кода, но это вне скоупа презентации).
С какими проблемами я, как аналитик, сталкивалась? Менеджер проекта спрашивает: «Это бизнес-требование входит в скоуп или нет?». А я не знаю, потому что бизнес-требования ведут бизнес-аналитики и они не дают копаться в их файлах. Точно я не могу определить. Единственное, что я могу где-то у себя пометить и тщательно за ними следить. А т.к. аналитиков 4 человека, то там возможна ситуация, когда сохранили не то или не так, и неточности накапливаются.
Когда начинаются вопросы «а мы вообще реализовали этот функционал?», мы снова не знаем. Мы выдали требования в виде Excel-файла, а вот как их тестировали и разрабатывали, все ли строки прочитал разработчик, мы не знаем. До конца релиза сохраняется опасение «вдруг завтра что-то случится?», забыли еще какое-то бизнес-требование, что-то не реализовали. И ничего не ясно, все взаимосвязи «на пальцах».
Т.к. релиз всего лишь раз в год и за год у продукт-менеджера всегда появляются новые идеи, то мы в этот релиз мы пытаемся добавить еще что-то. И получается, когда мы хотим понять, насколько изменится скоуп, если добавится новое бизнес-требование, мы опять не знаем. Потому что план проекта – это своеобразная «колбаска», которая с этим не связана: очень трудно посчитать. На принятие любого решения уходит много времени тим-лидов аналитики и разработки, а также тест-менеджера для того, чтобы понять, в каком состоянии проект на текущий момент. А когда закончилась разработка и началось тестирование, ситуация становится еще хуже, потому что, хоть баги и есть, но всё ли протестировано из того, что сделано, – неизвестно. А отсутствие багов говорит либо о том, что разработано всё хорошо, либо всё плохо, либо мы просто ещё не протестировали, как следует.
На момент релиза у нас складывается достаточно неясная схема, с которой, я думаю, многие знакомы. У кого-то случается похожее, но не такое страшное. У других требования не фиксируются вообще, и отслеживать, по сути, нечего (такое характерно для небольших Agile-проектов, но их практика слабо масштабируется на большие проекты).
Мы получили список вызовов (челенеджей) – это те вопросы, которые мне задавались и я не смогла на них ответить.
• Трудно определить, входит это бизнес-требование в скоупе релиза или нет (C1)
• Трудно определить, как добавление бизнес-требования повлияет на скоуп релиза(C2)
• Трудно определить состояние релиза (что осталось сделать, что уже сделали) (C3)
• Трудно согласовывать требования (SRS на функциональную область – большой, табличный формат не удобен для работы с изменениями и комментариями (C4 — не относится к трассировкам)
• Трудно точно планировать работы команды, т.к. функциональная область – слишком большой элемент для планирования (C5).
• Трудно точно планировать объем работ по разработке в конкретной области, т.к. количество требований неизвестно (C6).
• Трудно быстро определить качество разработки конкретного функционала, так как требования и тест-кейсы не связаны (C7).
• Трудно точно планировать реализацию функционала, так как неясно, что уже поставили смежные команды, а что нет (C8).

В итоге мы как-то выжили, сдали релиз, были счастливы, когда это закончилось. Но ведь жизнь на этом не заканчивается. На предыдущий релиз я пришла как тимлид аналитиков, и мне надо было дотянуть до релиза («всё для фронта, всё для победы!») — на честном слове, на профессионализме, на прекрасных тестерах, на хорошей команде (а также «на соплях» и «на когтях» ). Но на этом всё не кончается – нам нужно браться за следующий релиз.

У нас было немного времени на то, чтобы подумать, что же необходимо учесть для того, чтобы было легче, и чем мы можем ответить на те же самые вызовы: сделаны бизнес-требования или нет, входят в скоуп или нет, протестированы или нет, что вообще творится и что нам осталось сделать до выпуска.

Дальше мы начали считать, что же надо учитывать, что влияет на наш проект – даже не на релиз, а на его подготовку. Мы посчитали, что у нас есть 3 группы источников требований для релиза:

Какой в нём смысл? Он помогает понять, откуда берутся фичи, особенно в высокотехнологичном (полунаучном) коробочном продукте – таком, как антивирус. По сути, квадрант – это одно из аналитических исследований, которое делает обзор трендов индустрии. И как это происходит? В компанию приходит опросник с множеством вопросов в стиле «есть ли в вашем продукте такая фича», «сколько у вас клиентов» и т.д. В результате, каждая компания заполняет по своему продукту все разделы в анкете, и после обработки аналитическим агентством получается отчет, содержащий отображение компаний-поставщиков продуктов в определенном сегменте индустрии, где положение компаний определяют 2 оси: полнота видения и способность реализации. квадрат с делением по 4 категориям: нишевые игроки, претенденты, провидцы и лидеры. И источником нового функционала в продукте будут такие вопросы, как «А есть ли у вас шифрование данных? Если есть, то какое?» и т.д.
По сути дела, в коробочных продуктах источником требований для продукта является не только опросники, а в целом тренд индустрии: нужно смотреть на конкурентов, на их планируемые разработки. Однако обзоры аналитических агенств являются являются важным источником требований.
В результате, степень детализации требуемых к реализации фич, в принципе, совпадает с тем, что было запрошено в первом релизе в виде «Хочу фичу». Т.е. определенные разделы опросника были успешно покрыты функционалом продукта. И теперь нам нужно понимать, как именно должен быть реализован этот функционал.(требуются трассировка)
Следующее – это график тестов ПО группы VB100 по уровню детектирования угроз. Наша компания продаёт, по сути, свою экспертизу, поэтому наш продукт должен побеждать в тестах. Во внешних тестах на уровень детекта, на производительность и т.д. Т.е. мы его отдаем на тестирование, его гоняют и получают какой-то результат. Организацией и поддержкой этого процесса занимаются наши исследовательские подразделения, которые в отличие от аналитических агентств, которые отслеживают тренды индустрии, превосходят тренды, «заглядывают за горизонт», придумывают новые вещи, которые позволят нам стать лучшими, а если уж не стать лучшими, то хотя бы войти в тройку лидеров. Т.е. постоянное требование – обеспечить вхождение в топ-3. Получается, что этим людям важно знать, как реализованы те технологии, которые они придумывали, как аналитики написали требования, с помощью каких тестов это проверялось. Таким образом, для них важно иметь трассировки от исходных бизнес-требований как к требованиям в спецификациях, так и к тест-кейсам.


Еще один (точнее два) источник требований – требования сертификаций вендоров и регуляторов (например, ФСТЭК в России, Common Criteria за рубежом, законодательство разных стран). Если вы хотите указать на упаковке «Работает под управлением Windows 8», вашему продукту нужно соответствовать требованиям Microsoft. Если вы хотите поставлять ваш продукт в госорганы – вам нужно сначала сертифицировать его во ФСТЭК, а иногда и в ФСБ. И для каждого из этих случаев нам также требуются трассировки для отслеживания выполнения исходных требований сертификации в продукте.
Таким образом, мы видим, как минимум, 3 группы потребителей трассировок требований. Получилось, что для наших продуктов критически важно, чтоб трассировки были. У нас есть заказчики, которым нужно отслеживать, реализованы ли те или иные фичи в продукте. Один из первых уроков: нет потребителя – не надо этим заниматься, найдите тех, кому это реально нужно.

Далее мы обсудим архитектуру продуктов. Здесь нарисовано 2 продукта: для физических лиц (например, Kaspersky Internet Security 2013) и тот, что стоит в корпоративной сети. Получается, что сетевой продукт похож на первый, но также общается с административной частью. В то же время, оба продукта набираются из набора компонент (или PDK – product development kit). Это «кубики», из которых мы собираем наш продукт. Например, чуть ранее я говорила про инновационные антивирусные технологии: они «упаковываются» в кубик, и потом мы вставляем его в продукты. В итоге получается сложная внутренняя структура из разных кубиков, завёрнутая в продуктовую логику, плюс если это корпоративный продукт, то он будет работать под управлением другого продукта. В такой ситуации мы всё равно обязаны предоставить пользователю надёжную защиту и быстрый ответ на вызов: только вирус появился, мы сразу же должны предоставить лечение и доставить его пользователю быстро. Для этого у нас есть инфраструктурные сервисы, которые живут в облаке.
Таким образом, каждый продукт состоит из компонентов, иногда может работать под управлением административной части и он всегда общается с облачными сервисами. А чтобы там (в облаке) были актуальные данные, которые помогут пользователям защитить себя, исследовательские подразделения, которые проводят работу по анализу вирусов (к слову, вирусные аналитики гораздо важнее системных аналитиков в Лаборатории Касперского), должны иметь возможность передавать свои результаты из внутренних систем (Kaspersky network на схеме) на front-end в облако.
А теперь самое занятное. Мы видим на схеме продукта набор компонент, каждый из которых делают совсем другие люди, это делают другие команды. И для того чтобы вышел релиз одного продукта, все они должны сделать свою работу вовремя. Т.е. мы сначала должны вовремя им сказать, что мы от них хотим (передать им требования). А потом следить за тем, успеваем или нет реализовать и поставить их часть (это возможно только через трассировки). Допустим, при разработке инфраструктурного сервиса они еще могут подождать (продукт у пользователя еще не стоит, к сервису никто не обращается), но если это касается компонентов, то их отсутствие задержит разработчиков продукта, которые не смогут написать код вовремя.
Что такое коробочный продукт? Это значит, что в час Х продукт выпускается, и к этому моменту все должны быть готовы выполнить свою часть работ. До часа Х тратятся деньги на маркетинговую кампанию (например, «21 февраля в Нью-Йорке Евгений Касперский презентует свой новый продукт KESB»). Это огромный фронт работ, который мы – разработчики – не видим. Если мы задержим релиз на день, это большие деньги, очень серьезное решение и большие последствия.
Мы, как команда реализации продукта, пришли к тому, что у нас есть заказчики, которые должны быть уверены, что мы всё сделали качественно, то, что нужно, и вовремя. И для этого должна трудиться огромная команда. И таким образом, мы точно определили, что у нас есть потребители трассировок на разных уровнях.
• Удобство создания требований для команды аналитиков — максимально
• Удобство поддержки трассировок требований — максимально
• Изменения для команды разработки — минимальны
• Время, затрачиваемое на переформатирование/изменение форматов — минимально
• Изобретение велосипедов — минимально
Как тимлид аналитиков я стремилась минимизировать изменения для команды: т.е. разработчика не должен касаться процесс получения требований. Но разработчики пошли дальше – они захотели, чтобы каждой задачей разработчика было требование. На самом деле, это мечта аналитика: чтобы разработчики и тестировщики работали по требованиям. Посмотрите на сбывшуюся мечту (ниже).

На схеме приведены продуктовые трассировки, которые удалось использовать на втором релизе. Конечно, количество используемых систем для этого велико. Но ниже я расскажу, что у нас получилось.
Во-первых, бизнес-требования велись на SharePoint. Мы не стали давить на наш бизнес-дивизион: хотят они укрупненные требования и ладно: мы их разобьём у себя. И после этого у нас (аналитиков) будут реальные бизнес-требования, которые можно посчитать (к примеру, релиз будет состоять не из 5 требований, а из 40). К тому же, на SharePoint поддерживали статусы по каждому требованию (входит/не входит в релиз, если да – то в какой, ответственный аналитик и т.д.) Т.е. мы показали картину scope релиза продукта, которым можно было бы управлять и который можно было считать. А саму идею и инструмент для реализации списка мы взяли у смежной команды (повторное использование идей ).
В TFS у нас велись бизнес-требования, системные требования и запросы на изменения в сторонние команды. Скажу кратко: мы разрабатывали требования в Enterprise Architect для того, чтобы можно было создавать единичные требования, из которых можно было бы собрать SRS, а дальше согласовывать и т.д. Разработчики написали односторонний синхронизатор из EA в TFS, чтобы с требованиями можно было работать в TFS всей команде.
Обращаю внимание, требования создавались и хранились в EA, как источнике знаний, а управление требованиями происходило в TFS. Так было организовано, потому что команде так было удобней. Получается, в ЕА мы делаем Word-файл, который согласуется с заказчиками (в т.ч. юристы, которые не хотят читать Excel). А команда разработки использует TFS. Что касается внешних команд, то не у всех них есть TFS. Раньше нам приходилось заводить change request’ы для них в отдельной системе, а сейчас нам стало доступно создать в их схеме фиктивный элемент, который является ссылкой на наш. В итоге мы используем опыт, который у нас есть, и не придумываем лишних велосипедов. Например, схему работы в ЕА придумала команда аналитиков другого продукта. Также велась разработка по третьим продуктам. Работу с change request'ами в TeamTrack разрабатывала другая команда и так далее. В результате, получилась схема передачи требований, представленная на слайде, и мы с ней прожили весь релиз 2.
В деталях: аналитики ведут макро-бизнес-требования (Epic-BRQ) в TFS. В то же время, они раскладывают их на более мелкие (BRQ). Далее к каждому BRQ трассируются системные требования (SR), которые его реализуют. При этом одно SR может быть необходимо для реализации нескольких бизнес-требований. Вниз от SR уходит стрелка в стороннюю команду на реализацию чейндж-реквестов (CR): для каждого такого запроса указывается ссылка на спецификацию бизнес-требования, которое надо реализовать (SRS).
Но тут у нас проявился интересный момент: до этого в команде была принята практика, когда компонентные требования трассируются на продуктовые требования, чтобы было понятно, через какое компонентное требование реализуется заданное продуктовое требование. РМ’ы в нашем случае договорились не вести таких трассировок. Мы не будем оговорить о том, почему они так решили, но мы можем посмотреть на результаты эксперимента: в итоге через 3 месяца нам пришлось маппировать 400 системных требований на все CR. И потребовалось это потому, что если требование является задачей на разработку, то разработчик должен знать, может ли он его уже делать или нет. А если компонент еще не поставлен, то ему не с чем работать – эту задачу еще брать нельзя. Получается, что трассировки между требованиями на различные команды помогут PM’у составить план и дадут информацию, что можно реализовывать, а что – нельзя. Это аналитику нужно только описать бизнес-требование и затем передать системные требования в другие команды. И всё. А у РМ’a на этом всё не заканчивается: он понимает, какие требования у него уже готовы к реализации, он понимает, какие команды и какие CR’ы ему должны поставить (а без трассировок он этого не сделает). Когда CR будет реализован, то мы можем приступать к реализации связанных с ним SR.
Схема, конечно, сложная, но в нашей архитектуре она оправдана.
Вопрос: что за зеленый блок SRS, в который входят потоки из двух SR и CR?
Ответ: Это отчет, который мы генерируем по системным требованиям в разрезе BRQ и выкладываем на портал SharePoint. Также есть связь «наверх»: мы в каждом бизнес-требовании даем ссылку на набор требований, который его реализует. Если в реализации бизнес-требования требуется работа нескольких команд, то мы даём ссылку на общий SRS, который указывает какие команды и какие CR выполняют. Это делает не аналитик, а архитектор, т.е. делает разбивание на системы.
Вопрос: Зачем создана связь между SR в EA и TFS? Что она означает?
Ответ: Системные требования нужны нам в ЕА, чтобы удобно работать и получать отчеты. А по требованию в TFS прописаны разработчик и тестер, работающие по нему. И в момент планирования итерации мы на каждого разработчика распределяем набор системных требований для реализации. Конечно, можно было дать ссылку на SRS (который на SharePoint), но наши разработчики не захотели работать по документу – им удобнее работать по единичному элементу. А с ЕА они вообще не работают.
В итоге мы публикуем SR в 2 места (TFS и SRS) и понимаем, что есть риск их расхождения, поэтому тщательно следим (вручную) за их актуальностью.
Вопрос: Нефункциональные требования вы трассировали?
Ответ: Да, они входят в функциональную область. Нужно понимать, что SR – это не просто один вид элемента: это может быть use-case, атомарное требование и т.д. Но сложность в чём: для программиста SR становится единицей работы, и релиз мы начинаем считать в требованиях.
Вопрос: Use-case является атомарным требованием? Что делать, если его нельзя реализовать в единицу работы? Используется ли подход UseCase 2.0?
Ответ: Да, use-case является единицей требований. И если за одну итерацию его нельзя реализовать, то тимлид разработки декомпозировал его так, как ему удобней. Но при этом ответственность за конечный результат по всему требованию к конечной итерации нёс он сам. И тестировалось в итоге всё требование целиком. И частично сделанный use-case не попадал наружу.
Вопрос: Цикл разработки релиза у вас – 1 год. Отслеживали ли вы изменения требований?
Ответ: Да, мы сразу же синхронизировали требования. Причем ситуация возможна 2 типов: либо поправили запятую и изменения в коде не требуется, либо я вношу существенное изменение в требование, которое может быть уже реализовано и протестировано. В таком случае оно переходит в статус active, и его будут переделывать. Делалось это через варианты синхронизации. А в TFS есть history у требования. И нами была сделана такая доработка, чтобы при синхронизации там отображались изменения как в режиме рецензирования Word. Версионирование требований в ЕА мы использовали, но это немного другая тема вне данного доклада.
Вопрос: Как требования связывались с тест-кейсами?
Ответ: На схеме они нарисованы сами по себе не случайно. Мы во втором релизе не смогли завязать требования на тест-кейсы. Чисто физически не смогли сделать столько изменений в процессе
• Жесткие сроки выхода релизов (Time Driven Development)
• Большая и распределенная команда
• Нет сложившегося процесса, который устраивает команду
Предлагаемые изменения к релизу 2
• База данных Бизнес-требований (BRQ) на SharePoint со статусами и признаком вхождения в scope релиза (было — список)
• Новые продуктовые требования хранятся в EA (было — запись в xls-файле)
• Команда разработчиков работает по SRS
• SRS — doc-файл на одно бизнес-требование (было — xls-файл на функциональную область)
• Единица измерения релиза — BRQ (было — функциональная область)
Принятые изменения в процессах
• Декомпозиция больших BRQ на набор маленьких (C4, C5)
• Использование реестра для ведения бизнес-требований (с полями «in scope/out of scope» и пр.) (С1)
• Создание уникально идентифицируемых атомарных требований, трассируемых к BRQ, и хранение их в общем репозитарии СУТ (с доп. Полями, например списком зависимых компонентов) (С6)
• Генерация SRS из СУТ по каждому BRQ для разработки и управления (С4)
• Использование в качестве единицы измерения работ атомарных SR, а не функциональных областей (С2, С3, С6, С8)
Типы трассировок для проверки, ревью и согласования требований
• На уровне продукта: BRQ — SRS (для согласования)
• На уровне компонентов/сервисов: BRQ-компонентный CR-компонентная SRS (BRQ-InfraCR-InfraSRS)
• Для проверки покрытия: продуктовые требования — компонентные требования
Типы трассировок для управления
• Для реализации и тестирования: BRQ-SRы
• Для сложных для реализации требований: SR — DevTask
• Для синхронизации работ разных команд: BRQ-CRы
• Для планирования последовательности работ: SRы — CR
• Для мониторинга состояния продуктовой разработки BRQ (статусы) — SRы (статусы), BRQ (статусы) — CRы (статусы)
В принципе, худо-бедно на нескольких системах с «костылями» уже стало лучше. А дальше потребовалось перейти к новому релизу, но это было уже не так страшно, т.к. каких-то успехов мы уже добились. Основные проблемы этой схемы:
• тест-кейсы не связаны
• дублирование
• много используемых систем

За время выпуска второго релиза на других проектах жизнь не останавливалась, и они тоже что-то делали. При этом весь RnD стали переводить на TFS. Появилась выделенная команда, которая делала в нём улучшения.

Всё, что вы видите на схеме, будет реализовано в TFS. Это «мечта поэта»!
Первый уровень – бизнес-требования. Прочь от SharePoint. Соседний проект сделал эту схему на TFS (ура!) и теперь не нужны никакие загадочные ссылки: всё в одном месте.
Следующий уровень – запросы на изменения. Теперь соседние команды тоже работают в TFS. C ними понятно, как работать.
Третий уровень – системные требования, привязанные как к бизнес-требованиям, так и к чейндж-реквестам. Дублирование ссылок оставлено для того, чтобы понимать, что готово и что нет в данный момент времени. Разработчики работают над конкретным требованием и для аналитика это большая тяжесть: теперь его требование точно прочитают. И если раньше в Excel можно было что-то не заметить, то тут уж точно к тебе придут в любом случае. Благодаря этому мы нашли кучу дыр в функционале, которые никогда не тестировались. Не потому что тестеры плохие, а потому что не успели или что-то еще. Соответственно, точность и качество реально повысилось.
В то же время были бои с аналитиками вроде «разделите мне юскейс пополам», когда разработчики хотели вместо требований хотели получить постановку задачи. Если вы будете внедрять данный подход у себя, заранее продумайте вопрос таких боёв – это очень важный момент. Легко скатиться на уровень «что надо сделать» вместо «что должно быть в результате».
Последний уровень – это привязка требований к тест-кейсам и багам. Часть проектов уже так работает. Получается, что все проектные артефакты (в т.ч. и принадлежащие другим проектным командам) находятся в одном месте, и мы надеемся, что этот релиз будет самым счастливым.
Уточнение: здесь не нарисован ЕА. Схема работы с ним осталась, потому что во-первых, в TFS нет нормальной выгрузки документов (я не могу заставить юристов смотреть TFS – это набор элементов, между которыми не видно связь и не ясен контекст). К тому же, если вы найдёте хороший RTF или PDF -генератор для TFS, то скажите мне – я буду счастлива.
И второй момент. В TFS не ясно, как делать baseline требований. Дело в том, что версионный контроль с функцией «сравнить», «сделать слияние» или вообще создать baseline на конкретный момент времени в TFS реализован только для кода. Тут нужно то же самое для требований. Когда это появится, мы, скорее всего, уйдем с ЕА. И даже то, что с ЕА очень удобно моделировать, нам не поможет, т.к. то же дублирование, о котором мы говорили, это реально плохо.
• Использование атомарных бизнес-требований позволяет нам быстрее понимать текущее состояние проекта (LL1)
• Использование атомарных системных требований в качестве задач для разработки/тестирования повышает качество продукта (LL2), но меняет смысл требования (в пользу постановки задачи)
• Отсутствие трассировок между требованиями и артефактами тестирования (TestCase и багами) мешает понять текущий статус конкретного требования (C7, LL3)
• Использование нескольких разных инструментов для поддержки процесса снижает эффективность разработки и качество продукта (LL4)
Ниже я перечислила, в каких случаях эта схема может пригодиться (чтобы меня потом не «били палками» любители Agile)
• Качество реализации бизнес-требований критично для успеха продукта на рынке
В нашем случае, если в одном из тестов сторонних тестовых лабораторий наш антивирус что-то не найдет – это будет видно, таким образом качество реализации требований становится заметным. Поэтому мы будем строить трассировки, чтобы бизнес видел, как их требования реализовывали и тестировали.
• Выход в срок критичен для успеха проекта
• Продукт содержит несколько подсистем со сложными взаимосвязями, которые разрабатывают разные команды
• Подсистемы переиспользуются в разных продуктах (это также применимо к сервисам) – здесь мы сталкиваемся со связями многие-ко-многим, что усложняет управление и контроль требований
• Процессы разработки в разных проектах похожи – стоит заметить, что доработки процесса, сделанные в смежных командах, позволили нам сэкономить на своих доработках. А если вы одни – то изменения будут медленные, т.к. помощи ждать неоткуда.
• Необходима поддержка руководства!
o Выделение ресурсов на разработку и поддержку процесса (сам процесс дорогой и требует больших затрат как на инструменты, так и на команду, которая их будет поддерживать; т.е. на голом энтузиазме поднять такое очень сложно)
o Мотивация сотрудников всех ролей на регулярное использование процесса
• Практики и правила должны быть хорошо описаны и понятны всем
• Инструменты должны быть настроены под практики и удобны для пользователей
• Команда, поддерживающая инструменты, должна быть квалифицированная и мотивированная
• Между разными проектными командами должен быть налажен обмен знаниями и практиками

Видео доклада:
Презентация доклада:
www.slideshare.net/VLDCORP/ss-21934265
Добрый день, мы сейчас будем говорить про трассировки. Сразу скажу, что это проект, в котором трассировки получились. И это был проект, можно сказать, очень долгая тестовая кошечка, потому что в начале мы могли посмотреть на производство этого продукта, на его релиз, в котором трассировок не было вообще, потом они появлялись и сейчас они улучшаются. Т.е. получаются такие лабораторные исследования: когда нулевой уровень берем, потом у нас какие-то изменения, есть возможность посмотреть, что получилось и поменять что-то дальше.
Обо мне
- В IT больше 10 лет, из них
- в системном анализе 5 лет
- опыт управления командой аналитиков
- опыт создания и поддержки процессов разработки
- соавтор клуба прикладного системного анализа проекта Stratoplan.ru
- участник сообщества аналитиков uml2.ru
- отвечаю за инструменты в отделе анализа
.
Я занимаюсь системным анализом в ИТ. Самим ИТ я занимаюсь очень давно, в системном анализе около 5 лет. Перешла от тестеров и, причем, будучи тестером, мысль о том, что нужны связи между требованиями и тест-кейсами, меня не покидала. C тех пор я очень люблю эту тему. И теперь у меня появилась такая возможность, и я решила рассказать об этом вам.
В общем, на слайде можете видеть то, чем я занимаюсь, чем горжусь, с какими вопросами ко мне можно обращаться.
О теме
• Трассировки в учебной литературе — серебряная пуля
• Трассировки на практике — тяжело и трудно
• Трассировки в research — вызовы и надежды (см. ollygotel.com/requirements-traceability)
• Я перфекционист и практик
• Есть экспериментальные данные — хочу поделиться
Коротко об определении:
Requirements traceability refers to the ability to describe and follow the life of a requirement, in both forwards and backwards direction (i.e. from its origins, through its development and specification, to its subsequent deployment and use, and through all periods of on-going refinement and iteration in any of these phases.)
[Gotel and Finkelstein 1994]
Или говоря по-русски:
Трассировки требований относится к способности описывать и следить за жизнью требований, в обоих прямом и обратном направлении (то есть от их истоков, через их развитие и спецификации, до их последовательной реализации и использования в последующем, и через все периоды постоянного уточнения в любой из этих фаз.)
Если мы посмотрим в учебную литературу (Вигерса и т.д.), все говорят о том, что трассировки нужно вести, без них невозможен impact analysis, невозможно точное планирование и текущее понимание, где находится проект. Но в реальности чаще всего это очень тяжело и трудно. Такой опыт, когда это тяжело и трудно, также есть и на моем проекте. А при этом, кроме опыта людей типа Вигерса, т.е. людей из индустрии, которые пишут учебники, и моего собственного опыта, тут приведена информация о том, как к теме traceability (трассировок) относится научное сообщество Computer science. Здесь я привела ссылку на сайт дамы, которая занимается этим как независимый researcher в Нью-Йорке. Она входит в сообщество людей, которое разрабатывает Traceability Body of Knowledge.У них есть целый roadmap, как они планируют развивать эту дисциплину и у нее на сайте достаточно много всего интересного, но очень научного. Соответственно, в моем докладе будут попадаться слайды, которые я буду перелистывать, потому что там много текста. Потом вы сможете их посмотреть. В принципе, большую часть из этого я проговорю. Я хочу, чтобы эта презентация потом могла помочь в каких-то конкретных случаях. Понятно, что сейчас все устали и хочется картинок. Поэтому сейчас будут картинки, а потом, если захотите, посмотрите на текст.
У меня есть экспериментальные данные на основе 3 релизов: релиз 1, который прошел без трассировок, релиз 2, который прошел с трассировками, а сейчас мы спланировали релиз 3, который пройдёт с улучшенными трассировками.
Релиз 1. Контекст
• 1 из продуктов лаборатории Касперского
• 3 релиза (прошлое, настоящее, будущее)
• Влияние бизнес-требований
• Влияние архитектуры
• Влияние окружающей среды (инструменты, практики и т.д.)
Итак, это контекст нашего проекта. Это один из продуктов Лаборатории Касперского. Релиз примерно раз в год. Продукт достаточно сложный. Я пришла примерно в середине релиза 1. Мы немного обсудим, как строилось управление требованиями и, в принципе, создание требований во всех релизах, а также посмотрим, что на это влияет: сбор бизнес-требований, структура проекта, культура компании. Дело в том, что у нас в компании одновременно развиваются несколько продуктов, и соответственно, получается, что окружающая среда может сильно повлиять на это всё.
Проектные артефакты
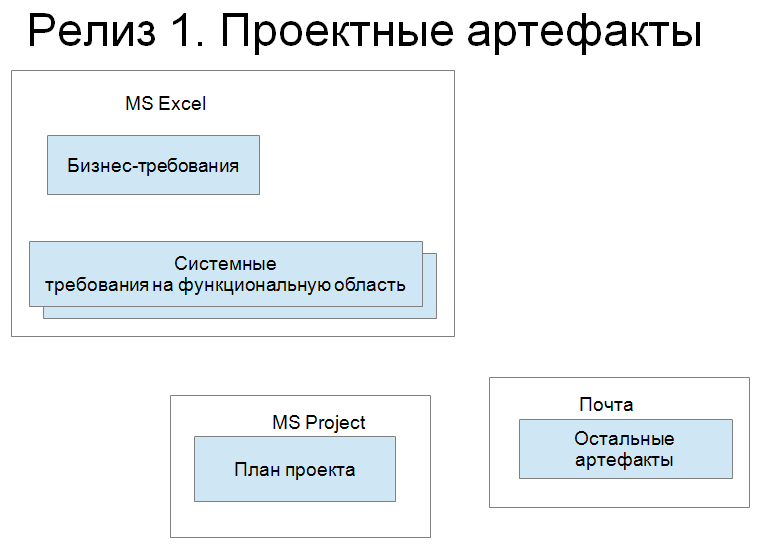
Картинка №1. Когда я пришла на этот проект, это были системы (на схеме белые квадратики), которые мы использовали для управления требованиями. Это Excel, в нем был список бизнес-требований на уровне «хочу, чтобы была такая фича» (достаточно крупная). Например, «управление устройствами». Плюс абзац вроде «флешками управлять на ноутбуках». Вот это бизнес-требование. И таких – целый список в Excel.
Кроме этого, т.к. продукт строился на базе другого продукта, кроме таких бизнес-требований были еще требования в виде «взять фичу оттуда и вставить в новый продукт» либо «я хочу вот это, но, пожалуйста, под таким углом и чтобы система управления правами пользователя была». Вот это первый уровень описания – уровень бизнес-требований.
Второй уровень – это системные требования на функциональную область, т.е. уточнение бизнес-требований, которые содержались в другом файле Excel. Т.е. есть фича «управление устройствами» — отлично, делаем файл Excel «управление устройствами» и в ней ведутся требования. Кое-где встречаются картинки, диаграммы и т.д. Но основной набор – это файл, в котором все требования ведутся. Т.е. мы можем поставить, допустим, ссылку из бизнес-требования на файл Excel, но я бы не сказала, что это трассировки. Кроме этого, получается, видим артефакты, с которыми работают системные аналитики, а также я выделила здесь план проекта и почту.
Соответственно, когда мы говорим о бизнес-требованиях и системных требованиях, мы всегда помним, для чего они нужны. РМ’у они нужны для того, чтобы планировать проект, а команде они нужны, чтобы разрабатывать. В любом случае появляется план проекта и другие артефакты. Т.к. на этом проекте аналитики работали с Excel и почтой, я остальные системы не привожу (например, есть системы ведения версий файлов кода, но это вне скоупа презентации).
С какими проблемами я, как аналитик, сталкивалась? Менеджер проекта спрашивает: «Это бизнес-требование входит в скоуп или нет?». А я не знаю, потому что бизнес-требования ведут бизнес-аналитики и они не дают копаться в их файлах. Точно я не могу определить. Единственное, что я могу где-то у себя пометить и тщательно за ними следить. А т.к. аналитиков 4 человека, то там возможна ситуация, когда сохранили не то или не так, и неточности накапливаются.
Когда начинаются вопросы «а мы вообще реализовали этот функционал?», мы снова не знаем. Мы выдали требования в виде Excel-файла, а вот как их тестировали и разрабатывали, все ли строки прочитал разработчик, мы не знаем. До конца релиза сохраняется опасение «вдруг завтра что-то случится?», забыли еще какое-то бизнес-требование, что-то не реализовали. И ничего не ясно, все взаимосвязи «на пальцах».
Т.к. релиз всего лишь раз в год и за год у продукт-менеджера всегда появляются новые идеи, то мы в этот релиз мы пытаемся добавить еще что-то. И получается, когда мы хотим понять, насколько изменится скоуп, если добавится новое бизнес-требование, мы опять не знаем. Потому что план проекта – это своеобразная «колбаска», которая с этим не связана: очень трудно посчитать. На принятие любого решения уходит много времени тим-лидов аналитики и разработки, а также тест-менеджера для того, чтобы понять, в каком состоянии проект на текущий момент. А когда закончилась разработка и началось тестирование, ситуация становится еще хуже, потому что, хоть баги и есть, но всё ли протестировано из того, что сделано, – неизвестно. А отсутствие багов говорит либо о том, что разработано всё хорошо, либо всё плохо, либо мы просто ещё не протестировали, как следует.
На момент релиза у нас складывается достаточно неясная схема, с которой, я думаю, многие знакомы. У кого-то случается похожее, но не такое страшное. У других требования не фиксируются вообще, и отслеживать, по сути, нечего (такое характерно для небольших Agile-проектов, но их практика слабо масштабируется на большие проекты).
Выявленные сложности:
Мы получили список вызовов (челенеджей) – это те вопросы, которые мне задавались и я не смогла на них ответить.
• Трудно определить, входит это бизнес-требование в скоупе релиза или нет (C1)
• Трудно определить, как добавление бизнес-требования повлияет на скоуп релиза(C2)
• Трудно определить состояние релиза (что осталось сделать, что уже сделали) (C3)
• Трудно согласовывать требования (SRS на функциональную область – большой, табличный формат не удобен для работы с изменениями и комментариями (C4 — не относится к трассировкам)
• Трудно точно планировать работы команды, т.к. функциональная область – слишком большой элемент для планирования (C5).
• Трудно точно планировать объем работ по разработке в конкретной области, т.к. количество требований неизвестно (C6).
• Трудно быстро определить качество разработки конкретного функционала, так как требования и тест-кейсы не связаны (C7).
• Трудно точно планировать реализацию функционала, так как неясно, что уже поставили смежные команды, а что нет (C8).
Релиз 1 закончен

В итоге мы как-то выжили, сдали релиз, были счастливы, когда это закончилось. Но ведь жизнь на этом не заканчивается. На предыдущий релиз я пришла как тимлид аналитиков, и мне надо было дотянуть до релиза («всё для фронта, всё для победы!») — на честном слове, на профессионализме, на прекрасных тестерах, на хорошей команде (а также «на соплях» и «на когтях» ). Но на этом всё не кончается – нам нужно браться за следующий релиз.
Надо делать следующий релиз

Релиз 2
Обдумываем будущее
У нас было немного времени на то, чтобы подумать, что же необходимо учесть для того, чтобы было легче, и чем мы можем ответить на те же самые вызовы: сделаны бизнес-требования или нет, входят в скоуп или нет, протестированы или нет, что вообще творится и что нам осталось сделать до выпуска.
Дальше мы начали считать, что же надо учитывать, что влияет на наш проект – даже не на релиз, а на его подготовку. Мы посчитали, что у нас есть 3 группы источников требований для релиза:
Магический квадрант Gartner’а и прочие аналитические отчеты по индустрии
Какой в нём смысл? Он помогает понять, откуда берутся фичи, особенно в высокотехнологичном (полунаучном) коробочном продукте – таком, как антивирус. По сути, квадрант – это одно из аналитических исследований, которое делает обзор трендов индустрии. И как это происходит? В компанию приходит опросник с множеством вопросов в стиле «есть ли в вашем продукте такая фича», «сколько у вас клиентов» и т.д. В результате, каждая компания заполняет по своему продукту все разделы в анкете, и после обработки аналитическим агентством получается отчет, содержащий отображение компаний-поставщиков продуктов в определенном сегменте индустрии, где положение компаний определяют 2 оси: полнота видения и способность реализации. квадрат с делением по 4 категориям: нишевые игроки, претенденты, провидцы и лидеры. И источником нового функционала в продукте будут такие вопросы, как «А есть ли у вас шифрование данных? Если есть, то какое?» и т.д.
По сути дела, в коробочных продуктах источником требований для продукта является не только опросники, а в целом тренд индустрии: нужно смотреть на конкурентов, на их планируемые разработки. Однако обзоры аналитических агенств являются являются важным источником требований.
В результате, степень детализации требуемых к реализации фич, в принципе, совпадает с тем, что было запрошено в первом релизе в виде «Хочу фичу». Т.е. определенные разделы опросника были успешно покрыты функционалом продукта. И теперь нам нужно понимать, как именно должен быть реализован этот функционал.(требуются трассировка)
Участие в тестах независимых лабораторий.
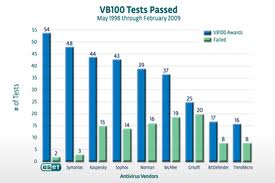
Следующее – это график тестов ПО группы VB100 по уровню детектирования угроз. Наша компания продаёт, по сути, свою экспертизу, поэтому наш продукт должен побеждать в тестах. Во внешних тестах на уровень детекта, на производительность и т.д. Т.е. мы его отдаем на тестирование, его гоняют и получают какой-то результат. Организацией и поддержкой этого процесса занимаются наши исследовательские подразделения, которые в отличие от аналитических агентств, которые отслеживают тренды индустрии, превосходят тренды, «заглядывают за горизонт», придумывают новые вещи, которые позволят нам стать лучшими, а если уж не стать лучшими, то хотя бы войти в тройку лидеров. Т.е. постоянное требование – обеспечить вхождение в топ-3. Получается, что этим людям важно знать, как реализованы те технологии, которые они придумывали, как аналитики написали требования, с помощью каких тестов это проверялось. Таким образом, для них важно иметь трассировки от исходных бизнес-требований как к требованиям в спецификациях, так и к тест-кейсам.
Внешняя среда


Еще один (точнее два) источник требований – требования сертификаций вендоров и регуляторов (например, ФСТЭК в России, Common Criteria за рубежом, законодательство разных стран). Если вы хотите указать на упаковке «Работает под управлением Windows 8», вашему продукту нужно соответствовать требованиям Microsoft. Если вы хотите поставлять ваш продукт в госорганы – вам нужно сначала сертифицировать его во ФСТЭК, а иногда и в ФСБ. И для каждого из этих случаев нам также требуются трассировки для отслеживания выполнения исходных требований сертификации в продукте.
Таким образом, мы видим, как минимум, 3 группы потребителей трассировок требований. Получилось, что для наших продуктов критически важно, чтоб трассировки были. У нас есть заказчики, которым нужно отслеживать, реализованы ли те или иные фичи в продукте. Один из первых уроков: нет потребителя – не надо этим заниматься, найдите тех, кому это реально нужно.
Архитектура продуктов
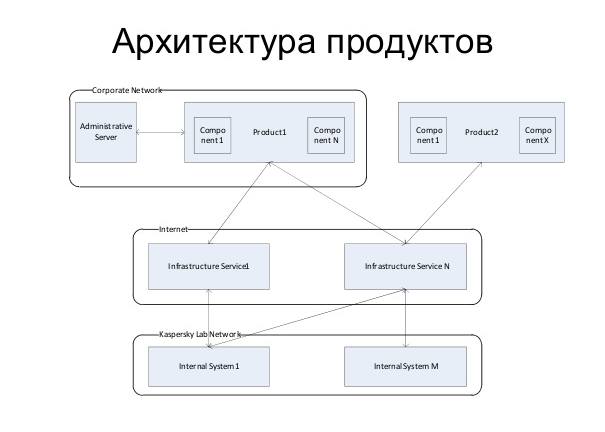
Далее мы обсудим архитектуру продуктов. Здесь нарисовано 2 продукта: для физических лиц (например, Kaspersky Internet Security 2013) и тот, что стоит в корпоративной сети. Получается, что сетевой продукт похож на первый, но также общается с административной частью. В то же время, оба продукта набираются из набора компонент (или PDK – product development kit). Это «кубики», из которых мы собираем наш продукт. Например, чуть ранее я говорила про инновационные антивирусные технологии: они «упаковываются» в кубик, и потом мы вставляем его в продукты. В итоге получается сложная внутренняя структура из разных кубиков, завёрнутая в продуктовую логику, плюс если это корпоративный продукт, то он будет работать под управлением другого продукта. В такой ситуации мы всё равно обязаны предоставить пользователю надёжную защиту и быстрый ответ на вызов: только вирус появился, мы сразу же должны предоставить лечение и доставить его пользователю быстро. Для этого у нас есть инфраструктурные сервисы, которые живут в облаке.
Таким образом, каждый продукт состоит из компонентов, иногда может работать под управлением административной части и он всегда общается с облачными сервисами. А чтобы там (в облаке) были актуальные данные, которые помогут пользователям защитить себя, исследовательские подразделения, которые проводят работу по анализу вирусов (к слову, вирусные аналитики гораздо важнее системных аналитиков в Лаборатории Касперского), должны иметь возможность передавать свои результаты из внутренних систем (Kaspersky network на схеме) на front-end в облако.
А теперь самое занятное. Мы видим на схеме продукта набор компонент, каждый из которых делают совсем другие люди, это делают другие команды. И для того чтобы вышел релиз одного продукта, все они должны сделать свою работу вовремя. Т.е. мы сначала должны вовремя им сказать, что мы от них хотим (передать им требования). А потом следить за тем, успеваем или нет реализовать и поставить их часть (это возможно только через трассировки). Допустим, при разработке инфраструктурного сервиса они еще могут подождать (продукт у пользователя еще не стоит, к сервису никто не обращается), но если это касается компонентов, то их отсутствие задержит разработчиков продукта, которые не смогут написать код вовремя.
Что такое коробочный продукт? Это значит, что в час Х продукт выпускается, и к этому моменту все должны быть готовы выполнить свою часть работ. До часа Х тратятся деньги на маркетинговую кампанию (например, «21 февраля в Нью-Йорке Евгений Касперский презентует свой новый продукт KESB»). Это огромный фронт работ, который мы – разработчики – не видим. Если мы задержим релиз на день, это большие деньги, очень серьезное решение и большие последствия.
Мы, как команда реализации продукта, пришли к тому, что у нас есть заказчики, которые должны быть уверены, что мы всё сделали качественно, то, что нужно, и вовремя. И для этого должна трудиться огромная команда. И таким образом, мы точно определили, что у нас есть потребители трассировок на разных уровнях.
Требования к изменениям процесса
• Удобство создания требований для команды аналитиков — максимально
• Удобство поддержки трассировок требований — максимально
• Изменения для команды разработки — минимальны
• Время, затрачиваемое на переформатирование/изменение форматов — минимально
• Изобретение велосипедов — минимально
Как тимлид аналитиков я стремилась минимизировать изменения для команды: т.е. разработчика не должен касаться процесс получения требований. Но разработчики пошли дальше – они захотели, чтобы каждой задачей разработчика было требование. На самом деле, это мечта аналитика: чтобы разработчики и тестировщики работали по требованиям. Посмотрите на сбывшуюся мечту (ниже).
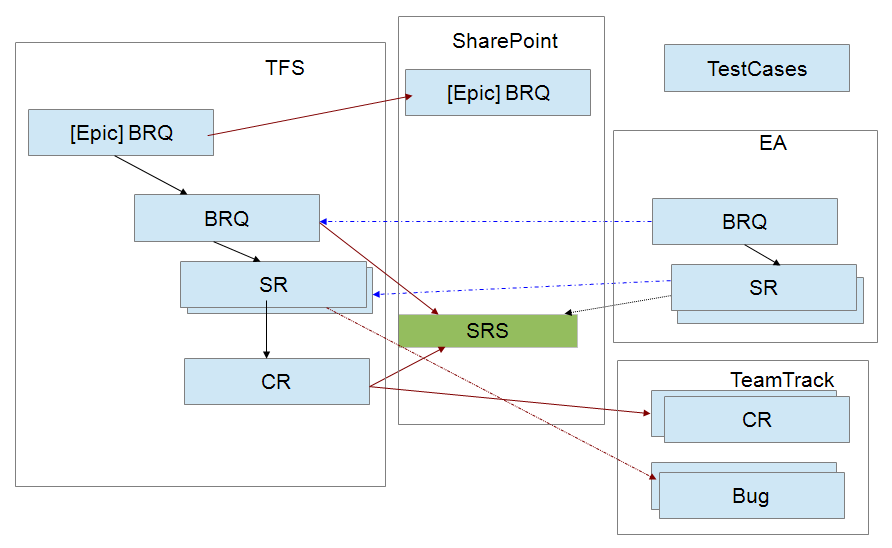
На схеме приведены продуктовые трассировки, которые удалось использовать на втором релизе. Конечно, количество используемых систем для этого велико. Но ниже я расскажу, что у нас получилось.
Во-первых, бизнес-требования велись на SharePoint. Мы не стали давить на наш бизнес-дивизион: хотят они укрупненные требования и ладно: мы их разобьём у себя. И после этого у нас (аналитиков) будут реальные бизнес-требования, которые можно посчитать (к примеру, релиз будет состоять не из 5 требований, а из 40). К тому же, на SharePoint поддерживали статусы по каждому требованию (входит/не входит в релиз, если да – то в какой, ответственный аналитик и т.д.) Т.е. мы показали картину scope релиза продукта, которым можно было бы управлять и который можно было считать. А саму идею и инструмент для реализации списка мы взяли у смежной команды (повторное использование идей ).
В TFS у нас велись бизнес-требования, системные требования и запросы на изменения в сторонние команды. Скажу кратко: мы разрабатывали требования в Enterprise Architect для того, чтобы можно было создавать единичные требования, из которых можно было бы собрать SRS, а дальше согласовывать и т.д. Разработчики написали односторонний синхронизатор из EA в TFS, чтобы с требованиями можно было работать в TFS всей команде.
Обращаю внимание, требования создавались и хранились в EA, как источнике знаний, а управление требованиями происходило в TFS. Так было организовано, потому что команде так было удобней. Получается, в ЕА мы делаем Word-файл, который согласуется с заказчиками (в т.ч. юристы, которые не хотят читать Excel). А команда разработки использует TFS. Что касается внешних команд, то не у всех них есть TFS. Раньше нам приходилось заводить change request’ы для них в отдельной системе, а сейчас нам стало доступно создать в их схеме фиктивный элемент, который является ссылкой на наш. В итоге мы используем опыт, который у нас есть, и не придумываем лишних велосипедов. Например, схему работы в ЕА придумала команда аналитиков другого продукта. Также велась разработка по третьим продуктам. Работу с change request'ами в TeamTrack разрабатывала другая команда и так далее. В результате, получилась схема передачи требований, представленная на слайде, и мы с ней прожили весь релиз 2.
В деталях: аналитики ведут макро-бизнес-требования (Epic-BRQ) в TFS. В то же время, они раскладывают их на более мелкие (BRQ). Далее к каждому BRQ трассируются системные требования (SR), которые его реализуют. При этом одно SR может быть необходимо для реализации нескольких бизнес-требований. Вниз от SR уходит стрелка в стороннюю команду на реализацию чейндж-реквестов (CR): для каждого такого запроса указывается ссылка на спецификацию бизнес-требования, которое надо реализовать (SRS).
Но тут у нас проявился интересный момент: до этого в команде была принята практика, когда компонентные требования трассируются на продуктовые требования, чтобы было понятно, через какое компонентное требование реализуется заданное продуктовое требование. РМ’ы в нашем случае договорились не вести таких трассировок. Мы не будем оговорить о том, почему они так решили, но мы можем посмотреть на результаты эксперимента: в итоге через 3 месяца нам пришлось маппировать 400 системных требований на все CR. И потребовалось это потому, что если требование является задачей на разработку, то разработчик должен знать, может ли он его уже делать или нет. А если компонент еще не поставлен, то ему не с чем работать – эту задачу еще брать нельзя. Получается, что трассировки между требованиями на различные команды помогут PM’у составить план и дадут информацию, что можно реализовывать, а что – нельзя. Это аналитику нужно только описать бизнес-требование и затем передать системные требования в другие команды. И всё. А у РМ’a на этом всё не заканчивается: он понимает, какие требования у него уже готовы к реализации, он понимает, какие команды и какие CR’ы ему должны поставить (а без трассировок он этого не сделает). Когда CR будет реализован, то мы можем приступать к реализации связанных с ним SR.
Схема, конечно, сложная, но в нашей архитектуре она оправдана.
Вопрос 1
Вопрос: что за зеленый блок SRS, в который входят потоки из двух SR и CR?
Ответ: Это отчет, который мы генерируем по системным требованиям в разрезе BRQ и выкладываем на портал SharePoint. Также есть связь «наверх»: мы в каждом бизнес-требовании даем ссылку на набор требований, который его реализует. Если в реализации бизнес-требования требуется работа нескольких команд, то мы даём ссылку на общий SRS, который указывает какие команды и какие CR выполняют. Это делает не аналитик, а архитектор, т.е. делает разбивание на системы.
Вопрос 2
Вопрос: Зачем создана связь между SR в EA и TFS? Что она означает?
Ответ: Системные требования нужны нам в ЕА, чтобы удобно работать и получать отчеты. А по требованию в TFS прописаны разработчик и тестер, работающие по нему. И в момент планирования итерации мы на каждого разработчика распределяем набор системных требований для реализации. Конечно, можно было дать ссылку на SRS (который на SharePoint), но наши разработчики не захотели работать по документу – им удобнее работать по единичному элементу. А с ЕА они вообще не работают.
В итоге мы публикуем SR в 2 места (TFS и SRS) и понимаем, что есть риск их расхождения, поэтому тщательно следим (вручную) за их актуальностью.
Вопрос 3
Вопрос: Нефункциональные требования вы трассировали?
Ответ: Да, они входят в функциональную область. Нужно понимать, что SR – это не просто один вид элемента: это может быть use-case, атомарное требование и т.д. Но сложность в чём: для программиста SR становится единицей работы, и релиз мы начинаем считать в требованиях.
Вопрос 4
Вопрос: Use-case является атомарным требованием? Что делать, если его нельзя реализовать в единицу работы? Используется ли подход UseCase 2.0?
Ответ: Да, use-case является единицей требований. И если за одну итерацию его нельзя реализовать, то тимлид разработки декомпозировал его так, как ему удобней. Но при этом ответственность за конечный результат по всему требованию к конечной итерации нёс он сам. И тестировалось в итоге всё требование целиком. И частично сделанный use-case не попадал наружу.
Вопрос 4
Вопрос: Цикл разработки релиза у вас – 1 год. Отслеживали ли вы изменения требований?
Ответ: Да, мы сразу же синхронизировали требования. Причем ситуация возможна 2 типов: либо поправили запятую и изменения в коде не требуется, либо я вношу существенное изменение в требование, которое может быть уже реализовано и протестировано. В таком случае оно переходит в статус active, и его будут переделывать. Делалось это через варианты синхронизации. А в TFS есть history у требования. И нами была сделана такая доработка, чтобы при синхронизации там отображались изменения как в режиме рецензирования Word. Версионирование требований в ЕА мы использовали, но это немного другая тема вне данного доклада.
Вопрос 5
Вопрос: Как требования связывались с тест-кейсами?
Ответ: На схеме они нарисованы сами по себе не случайно. Мы во втором релизе не смогли завязать требования на тест-кейсы. Чисто физически не смогли сделать столько изменений в процессе
Контекст релиза 2
• Жесткие сроки выхода релизов (Time Driven Development)
• Большая и распределенная команда
• Нет сложившегося процесса, который устраивает команду
Предлагаемые изменения к релизу 2
• База данных Бизнес-требований (BRQ) на SharePoint со статусами и признаком вхождения в scope релиза (было — список)
• Новые продуктовые требования хранятся в EA (было — запись в xls-файле)
• Команда разработчиков работает по SRS
• SRS — doc-файл на одно бизнес-требование (было — xls-файл на функциональную область)
• Единица измерения релиза — BRQ (было — функциональная область)
Принятые изменения в процессах
• Декомпозиция больших BRQ на набор маленьких (C4, C5)
• Использование реестра для ведения бизнес-требований (с полями «in scope/out of scope» и пр.) (С1)
• Создание уникально идентифицируемых атомарных требований, трассируемых к BRQ, и хранение их в общем репозитарии СУТ (с доп. Полями, например списком зависимых компонентов) (С6)
• Генерация SRS из СУТ по каждому BRQ для разработки и управления (С4)
• Использование в качестве единицы измерения работ атомарных SR, а не функциональных областей (С2, С3, С6, С8)
Типы трассировок для проверки, ревью и согласования требований
• На уровне продукта: BRQ — SRS (для согласования)
• На уровне компонентов/сервисов: BRQ-компонентный CR-компонентная SRS (BRQ-InfraCR-InfraSRS)
• Для проверки покрытия: продуктовые требования — компонентные требования
Типы трассировок для управления
• Для реализации и тестирования: BRQ-SRы
• Для сложных для реализации требований: SR — DevTask
• Для синхронизации работ разных команд: BRQ-CRы
• Для планирования последовательности работ: SRы — CR
• Для мониторинга состояния продуктовой разработки BRQ (статусы) — SRы (статусы), BRQ (статусы) — CRы (статусы)
Релиз 2. Результаты
В принципе, худо-бедно на нескольких системах с «костылями» уже стало лучше. А дальше потребовалось перейти к новому релизу, но это было уже не так страшно, т.к. каких-то успехов мы уже добились. Основные проблемы этой схемы:
• тест-кейсы не связаны
• дублирование
• много используемых систем
Релиз 3. Надо делать следующий релиз

За время выпуска второго релиза на других проектах жизнь не останавливалась, и они тоже что-то делали. При этом весь RnD стали переводить на TFS. Появилась выделенная команда, которая делала в нём улучшения.
Подготовка к релизу 3. Как будет
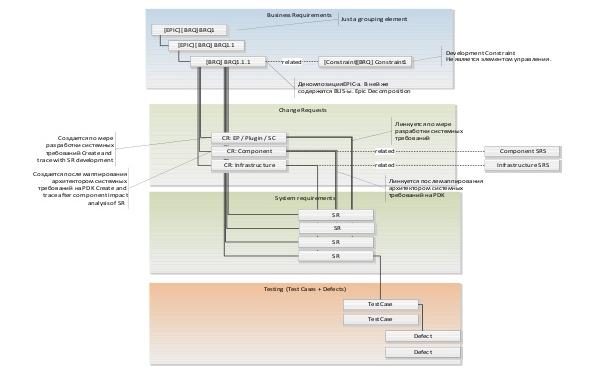
Всё, что вы видите на схеме, будет реализовано в TFS. Это «мечта поэта»!
Первый уровень – бизнес-требования. Прочь от SharePoint. Соседний проект сделал эту схему на TFS (ура!) и теперь не нужны никакие загадочные ссылки: всё в одном месте.
Следующий уровень – запросы на изменения. Теперь соседние команды тоже работают в TFS. C ними понятно, как работать.
Третий уровень – системные требования, привязанные как к бизнес-требованиям, так и к чейндж-реквестам. Дублирование ссылок оставлено для того, чтобы понимать, что готово и что нет в данный момент времени. Разработчики работают над конкретным требованием и для аналитика это большая тяжесть: теперь его требование точно прочитают. И если раньше в Excel можно было что-то не заметить, то тут уж точно к тебе придут в любом случае. Благодаря этому мы нашли кучу дыр в функционале, которые никогда не тестировались. Не потому что тестеры плохие, а потому что не успели или что-то еще. Соответственно, точность и качество реально повысилось.
В то же время были бои с аналитиками вроде «разделите мне юскейс пополам», когда разработчики хотели вместо требований хотели получить постановку задачи. Если вы будете внедрять данный подход у себя, заранее продумайте вопрос таких боёв – это очень важный момент. Легко скатиться на уровень «что надо сделать» вместо «что должно быть в результате».
Последний уровень – это привязка требований к тест-кейсам и багам. Часть проектов уже так работает. Получается, что все проектные артефакты (в т.ч. и принадлежащие другим проектным командам) находятся в одном месте, и мы надеемся, что этот релиз будет самым счастливым.
Уточнение: здесь не нарисован ЕА. Схема работы с ним осталась, потому что во-первых, в TFS нет нормальной выгрузки документов (я не могу заставить юристов смотреть TFS – это набор элементов, между которыми не видно связь и не ясен контекст). К тому же, если вы найдёте хороший RTF или PDF -генератор для TFS, то скажите мне – я буду счастлива.
И второй момент. В TFS не ясно, как делать baseline требований. Дело в том, что версионный контроль с функцией «сравнить», «сделать слияние» или вообще создать baseline на конкретный момент времени в TFS реализован только для кода. Тут нужно то же самое для требований. Когда это появится, мы, скорее всего, уйдем с ЕА. И даже то, что с ЕА очень удобно моделировать, нам не поможет, т.к. то же дублирование, о котором мы говорили, это реально плохо.
Lessons Learned
• Использование атомарных бизнес-требований позволяет нам быстрее понимать текущее состояние проекта (LL1)
• Использование атомарных системных требований в качестве задач для разработки/тестирования повышает качество продукта (LL2), но меняет смысл требования (в пользу постановки задачи)
• Отсутствие трассировок между требованиями и артефактами тестирования (TestCase и багами) мешает понять текущий статус конкретного требования (C7, LL3)
• Использование нескольких разных инструментов для поддержки процесса снижает эффективность разработки и качество продукта (LL4)
Выводы
Где и когда применима данная схема
Ниже я перечислила, в каких случаях эта схема может пригодиться (чтобы меня потом не «били палками» любители Agile)
• Качество реализации бизнес-требований критично для успеха продукта на рынке
В нашем случае, если в одном из тестов сторонних тестовых лабораторий наш антивирус что-то не найдет – это будет видно, таким образом качество реализации требований становится заметным. Поэтому мы будем строить трассировки, чтобы бизнес видел, как их требования реализовывали и тестировали.
• Выход в срок критичен для успеха проекта
• Продукт содержит несколько подсистем со сложными взаимосвязями, которые разрабатывают разные команды
• Подсистемы переиспользуются в разных продуктах (это также применимо к сервисам) – здесь мы сталкиваемся со связями многие-ко-многим, что усложняет управление и контроль требований
• Процессы разработки в разных проектах похожи – стоит заметить, что доработки процесса, сделанные в смежных командах, позволили нам сэкономить на своих доработках. А если вы одни – то изменения будут медленные, т.к. помощи ждать неоткуда.
Что требуется для создания и поддержки процесса
• Необходима поддержка руководства!
o Выделение ресурсов на разработку и поддержку процесса (сам процесс дорогой и требует больших затрат как на инструменты, так и на команду, которая их будет поддерживать; т.е. на голом энтузиазме поднять такое очень сложно)
o Мотивация сотрудников всех ролей на регулярное использование процесса
• Практики и правила должны быть хорошо описаны и понятны всем
• Инструменты должны быть настроены под практики и удобны для пользователей
• Команда, поддерживающая инструменты, должна быть квалифицированная и мотивированная
• Между разными проектными командами должен быть налажен обмен знаниями и практиками
