Comments 59
UFO just landed and posted this here
Я сравнил только для текста с EventMachine. Когда я дошел до теста с раздачей файлов, я уже для себя решил, что буду использовать Python. Поэтому такой тест не проводил, к сожалению.
Почему решили, что python, если em производительнее?
Python мне ближе идеологически. Честно говоря, я сейчас сожалею, что не провел тогда более подробное тестирование с EventMachine, с раздачей файлов. И мне было бы интересно сравнить его с asyncio в Python 3.4, что я как-нибудь обязательно сделаю.
Раздачей должен заниматься nginx. Он ведь у вас всё равно стоит на фронте, судя по порту 8080 в коде. Не думаю, что результаты заполнения заголовка x-sendfile как-то будет отличасться от отправки просто текста.
Задачей было проверить скорость отдачи файлов с использованием различных фреймворков. Более того, в моем проекте было непонятно где именно будут хранится файлы, в файловой системе или GridFS или еще где-то. Понятно, что в продакшене будут использоваться балансировщик, кеширование, авторизация и прочие моменты и результаты тестов будут другие.
Небольшой офтоп, но всё-таки, как вам производительность/простота/удобство GridFS? Я для своих just-for-fun проектов всегда страдаю перфекционизмом с минимальными затратами, например, поднимаю ноды на своих домашних серверах (2x Intel Atom, Intel Quad Core, Raspberry Pi) и при этом настраиваю между ними IPSec, конфигурирую балансировку и прочие «ненужные чудеса». Так вот я смотрел в сторону где бы хранить файлы (миллионы их объёма до 50МБ). Набрёл на WeedFS в итоге и вот пока для моего гордого кластера это самое удобное решение, при этом единственный метод коммуникации с ним — HTTP API, то есть с Nginx связывается на ура без дополнительных прослоек.
Я отказался от использования GridFS в своем проекте, хотя MongoDB мне нравится. До тех пор, пока размер данных небольшой, я все храню в обычной файловой системе и это, на мой взгляд, самое лучшее решение. Когда встанет вопрос хранения, то я думаю в сторону Ceph FS, но об этом решении надо говорить с тем, кто имел опыт его использования.
Про GridFS можно говорить много, но есть несколько моментов, которые стоит учитывать. Это обычная MongoDB, а GridFS это просто удобный интерфейс для хранения файлов в ней. Запускать MongoDB лучше всего в изолированном окружении, в количестве 2-х экземпляров + арбитр, что привносит доп. расходы. Писать мы можем в нее только последовательно и запись производиться через 1 сервер (если нет шардинга). Если у вас преимущественно чтение, в редких случаях запись, не требуется редактировать или удалить старые файлы, есть возможность выделить ресурсы на запуск нескольких экземпляров MongoDB, то можете рассмотреть этот вариант. В остальных же случаях надо искать другое решиние.
Про GridFS можно говорить много, но есть несколько моментов, которые стоит учитывать. Это обычная MongoDB, а GridFS это просто удобный интерфейс для хранения файлов в ней. Запускать MongoDB лучше всего в изолированном окружении, в количестве 2-х экземпляров + арбитр, что привносит доп. расходы. Писать мы можем в нее только последовательно и запись производиться через 1 сервер (если нет шардинга). Если у вас преимущественно чтение, в редких случаях запись, не требуется редактировать или удалить старые файлы, есть возможность выделить ресурсы на запуск нескольких экземпляров MongoDB, то можете рассмотреть этот вариант. В остальных же случаях надо искать другое решиние.
Решил дополнить немного. Большинство ограничений можно обойти, но на практике мы получим низкую производительность. Удалить старые файлы из GridFS мы конечно можем, но больше свободного места мы таким образом не получим. Редактирование файлов можно выполнить вручную (когда-то это можно было делать штатными средствами), но тогда чтение будет не последовательное и мы получим низкую производительность (насколько я помню, именно по этой причине они выпилили эту возможность).
что-то как-то rps на i7 не очень, неделю назад бенчмаркал undertow на i7 4790, выдавало примерно 440к rps на 400 подключений
Я использовал только 1 ядро процессора в своем тесте, это стоит учитывать.
а какой смысл так делать?
Чистота эксперимента:
Все эти «фреймворки» асинхронные, поэтому нет большой разницы в сколько процессов их гонять.
С другой стороны многоядерная машинка начнет I/O выполнять на других ядрах — это смажет результат.
Все эти «фреймворки» асинхронные, поэтому нет большой разницы в сколько процессов их гонять.
С другой стороны многоядерная машинка начнет I/O выполнять на других ядрах — это смажет результат.
Цель была выяснить не производительность процессора, а производительность разных фреймворков. Зная производительность на 1 ядре я могу примерно понять производительность на 2-ух и более.
Легенду почти не видно…
2014 года на дворе, а вы почему-то очень старый Ruby 1.8.7 гоняете, при этом он с Eventmachine показывает блестящие результаты, но вы все равно выбираете иное. Я видимо чего-то не понимаю.
Ещё было бы интересно сравнить с потоковым фреймворком, bottle, flask или т.п. (зажатым в одно ядро), у них нет оверхеда на «евент-луп» и обработку асинхронного кода, но есть большее потребление памяти (в теории).
Оверхед на использование ивент-лупа перестаёт быть значительным уже при двух активных сокетах. Оверхед проявляет сильно только при одном сокете. Во всех остальных случаях ивентлуп на одном ядре должен быть быстрее N потоков на одном ядре.
Во всех остальных случаях ивентлуп на одном ядре должен быть быстрее N потоков на одном ядре.
Это зависит от работы которую выполняет сервер, асинхронность не всегда «быстрее».
Например в тестах выше Gevent показывает результат лучше чем например Twisted, а ведь у gevent нет классического ивент-лупа (там происходит переключение стеков).
По простому, производительность асинхронности проявляется на «долгих» открытых коннектах.
Можете привести пример при N > 1? Можно практический. Можно в личку:)
Вот сейчас прогнал у себя на python3.4, в lxc на одно ядро (так же проверял с taskset):
ab -n 20000 -c 100 10.0.3.16:8888/
uwsgi --http :8888 --wsgi-file source.py --logto /dev/null --processes 1 --threads 10
5946 rps
6mb ram
cpu ~40%
Исходник от сюда: uwsgi-docs.readthedocs.org/en/latest/WSGIquickstart.html#the-first-wsgi-application
tornadoweb
2507 rps
11mb ram
cpu 100%
Исходник от сюда: www.tornadoweb.org/en/stable/
Кол-во передаваемых данных выравнено. Большее кол-во потоков для uwsgi профита не дало.
По результатам видно что торнадо уперся в cpu. Так же тут ещё повлияло что в uwsgi варианте нет диспетчера урлов, да и всего прочего питон кода который отъедает процессор.
ab -n 20000 -c 100 10.0.3.16:8888/
uwsgi --http :8888 --wsgi-file source.py --logto /dev/null --processes 1 --threads 10
5946 rps
6mb ram
cpu ~40%
Исходник от сюда: uwsgi-docs.readthedocs.org/en/latest/WSGIquickstart.html#the-first-wsgi-application
tornadoweb
2507 rps
11mb ram
cpu 100%
Исходник от сюда: www.tornadoweb.org/en/stable/
Кол-во передаваемых данных выравнено. Большее кол-во потоков для uwsgi профита не дало.
По результатам видно что торнадо уперся в cpu. Так же тут ещё повлияло что в uwsgi варианте нет диспетчера урлов, да и всего прочего питон кода который отъедает процессор.
Логи
$ ab -n 20000 -c 100 http://10.0.3.16:8888/
This is ApacheBench, Version 2.3 <$Revision: 1528965 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 10.0.3.16 (be patient)
Completed 2000 requests
Completed 4000 requests
Completed 6000 requests
Completed 8000 requests
Completed 10000 requests
Completed 12000 requests
Completed 14000 requests
Completed 16000 requests
Completed 18000 requests
Completed 20000 requests
Finished 20000 requests
Server Software:
Server Hostname: 10.0.3.16
Server Port: 8888
Document Path: /
Document Length: 11 bytes
Concurrency Level: 100
Time taken for tests: 3.363 seconds
Complete requests: 20000
Failed requests: 0
Total transferred: 1100000 bytes
HTML transferred: 220000 bytes
Requests per second: 5946.81 [#/sec] (mean)
Time per request: 16.816 [ms] (mean)
Time per request: 0.168 [ms] (mean, across all concurrent requests)
Transfer rate: 319.41 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.2 0 3
Processing: 8 17 0.8 17 19
Waiting: 7 16 0.8 16 19
Total: 8 17 0.6 17 19
Percentage of the requests served within a certain time (ms)
50% 17
66% 17
75% 17
80% 17
90% 17
95% 18
98% 18
99% 19
100% 19 (longest request)
$ ab -n 20000 -c 100 http://10.0.3.16:8888/
This is ApacheBench, Version 2.3 <$Revision: 1528965 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking 10.0.3.16 (be patient)
Completed 2000 requests
Completed 4000 requests
Completed 6000 requests
Completed 8000 requests
Completed 10000 requests
Completed 12000 requests
Completed 14000 requests
Completed 16000 requests
Completed 18000 requests
Completed 20000 requests
Finished 20000 requests
Server Software: TornadoServer/3.2.2
Server Hostname: 10.0.3.16
Server Port: 8888
Document Path: /
Document Length: 12 bytes
Concurrency Level: 100
Time taken for tests: 7.976 seconds
Complete requests: 20000
Failed requests: 0
Total transferred: 4140000 bytes
HTML transferred: 240000 bytes
Requests per second: 2507.39 [#/sec] (mean)
Time per request: 39.882 [ms] (mean)
Time per request: 0.399 [ms] (mean, across all concurrent requests)
Transfer rate: 506.86 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 0 0 0.4 0 8
Processing: 3 40 2.6 39 52
Waiting: 3 40 2.6 39 52
Total: 8 40 2.5 39 52
Percentage of the requests served within a certain time (ms)
50% 39
66% 39
75% 40
80% 40
90% 42
95% 46
98% 48
99% 50
100% 52 (longest request)
Ну так а вы не думали что в случае с tornado как весь этот лишний код (диспетчер, парсер) как раз и съедает весь проц?
Чтобы сранивать производительность blocking / non-blocking нужно сделать так, чтобы именно сеть была основным workload'ом.
Ну для такого теста нужно тестировать в рамках одного фреймворка или вообще без него, используя лишь голые сокеты.
Чтобы сранивать производительность blocking / non-blocking нужно сделать так, чтобы именно сеть была основным workload'ом.
Ну для такого теста нужно тестировать в рамках одного фреймворка или вообще без него, используя лишь голые сокеты.
Ну так а вы не думали что в случае с tornado как весь этот лишний код (диспетчер, парсер) как раз и съедает весь проц?Я про этот «оверхед» выше и написал в отличие от многопоточных фреймворков:
… у них нет оверхеда на «евент-луп» и обработку асинхронного кода,
И это опровергает ваш комментарий выше
Оверхед на использование ивент-лупа перестаёт быть значительным уже при двух активных сокетах. Оверхед проявляет сильно только при одном сокете. Во всех остальных случаях ивентлуп на одном ядре должен быть быстрее N потоков на одном ядре.
Чтобы сранивать производительность blocking / non-blockingРечь не про blocking/non-blocking сокеты, а про асинхронный и многопоточный код (хоть эти понятия и «ходят рядом»). Не блокирующие сокеты могут и в многопоточном использоваться, например в том же uwsgi вполне возможно используются не блокирующие сокеты до передачи данных в поток, или библиотеки которые работают с пачкой сокетов (например zmq poller).
В вашем тесте есть одно но: tornado обработывает соединения и парсит запрос с python коде, а uwsgi в python коде тупо дергает одну функцию. Это уже C/C++ vs Python а не threads vs event loop. Тогда надо сравнивать uwsgi (threaded) с nginx(event loop)+wsgi.
Я про этот «оверхед» выше и написал в отличие от многопоточных фреймворков:
Увольте! Я в своём предложении написал про диспетчер и парсер, они есть как в синхронном/блокирующем коде, так и в асинхронном.
Вы же, сравниваете два разных фреймворка и судите о производительности синхронности/асинхронности по производительности разных фреймворков и это не правильно.
Ваши тесты показывают лишь то, что один фреймворк выдерживает большую пропускную способность чем другой.
Но это не значит что у tornado меньшая производительности из-за eventloopа и асинхронности. Она может быть меньше из-за более тяжелого парсера, из-за более тяжелого диспетчера, из-за многих причин. uwsgi же написан на плюсах и в питоне лишь биндинги к сишным вызовам. Конечно он быстрее питонячьего большого tornado!
Сравнивать blocking/non-blocking и sync/async надо в рамках одной абстракции, одного фреймворка и одного api.
Я в своём предложении написал про диспетчер и парсер, они есть как в синхронном/блокирующем коде, так и в асинхронном.Ок, вот пример с bottlepy — 4356 rps против 2500 rps у торнадо, вариант с WebOb выдает 5000 rps.
Вы же, сравниваете два разных фреймворкаВсе правильно, сравнить надо вещи которые отличаются.
судите о производительности синхронности/асинхронности по производительности разных фреймворков и это не правильно.Нет, я просто показал что приложение на асинхронном фреймворке не всегда быстрее, «все зависит от задачи».
Сравнивать blocking/non-blocking и sync/async надо в рамках одной абстракции, одного фреймворка и одного api.Приведите свои примеры/тесты.
Похоже я понял в чем спор — вы вышли за пределы топика и рассуждаете об абстрактной синхронности/асинхронности, когда я говорю о синхронных/асинхронных релизациях на питоне, с чего и начался тред, конкретно по теме мне было интересно добавить bottle/flask в тесты к tornado, twisted, gevent, хотя это итак видно по моему первому комментарию.
Думаю теперь нет смысла у вас спрашивать о наличии «асинхронного оверхеда» в tornado/twisted перед bottleby и аналогами, т.к. это очевидно.
Но это не значит что асинхронные фреймворки хуже/медленнее. В первую очередь они нужны для задач которые не под силу (либо не оправдано использовать) потоковым фреймворкам, а бо`льшая производительность получается за счет того что работа не простаивает в ожидании IO операций.
И опять же не нужно их пихать везде, даже если асинхронный фреймворк дает лучшую производительность в данной задаче, это не значит что это лучше для проекта в целом.
А если говорить об абстрактной синхронности/асинхронности — то это большой философский вопрос, который мне не интересен.
В исходном сообщении треда вы написали что у инвент-луп обработки есть оверхед, и я сказал что он незначительный и проявляется в одном случае. Это утверждение выглядело более чем абстрактным.
По поводу своих тестов. Я как-то уже давно писал две реализации модулей стрелялки для jmeter. Написал используя голые сокеты (никаких #netty/#grizzly) и получил следующие результаты на тестировании между двумя машинками в разных ДЦ с latency в 5ms. Тестировал echo-протокол. Сокет получил запрос echo, и его же отправил. Пока сокет ответ не получил, следующий запрос он не отправляет.
В случае блокирующих сокетов, на каждое соединение выделялось по одному нативном потоку. В случае неблокирующи сокетов количество отдельных потоков для селекторов было малое. Так, для 550Krps было всего 4 потока event-loop'а. Дополнительную информацию можно увидеть тут
Так выглядела пропускная способность:
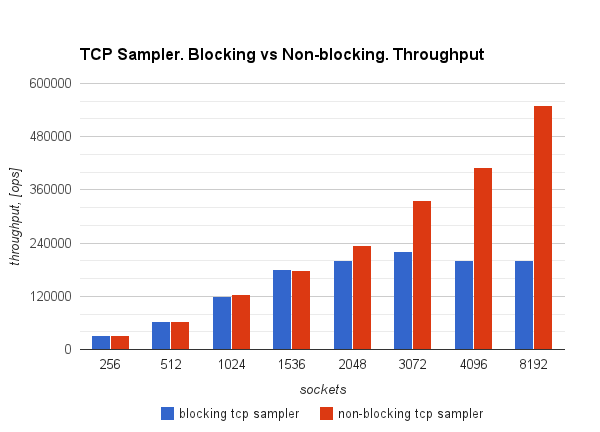
А вот так утилизация процессора:
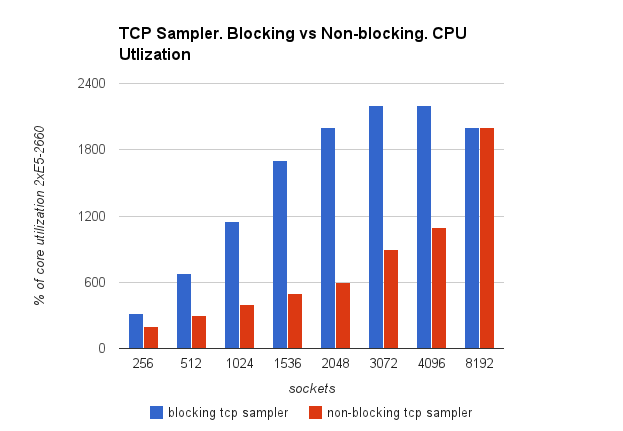
Машинки стояли мощные, 32 логических ядра:)
На таких графиках видно как работа с неблокирующими сокетами позволяет добиться вдвое большей пропускной способности при той же утилизации. Причем, в случае неблокирующих сокетов, дальше я упёрся во внутренний код стрелялки, который занимается логикой, и дальнейшие бенчмарки без jmeter показали еще большие значения производительности.
По поводу своих тестов. Я как-то уже давно писал две реализации модулей стрелялки для jmeter. Написал используя голые сокеты (никаких #netty/#grizzly) и получил следующие результаты на тестировании между двумя машинками в разных ДЦ с latency в 5ms. Тестировал echo-протокол. Сокет получил запрос echo, и его же отправил. Пока сокет ответ не получил, следующий запрос он не отправляет.
В случае блокирующих сокетов, на каждое соединение выделялось по одному нативном потоку. В случае неблокирующи сокетов количество отдельных потоков для селекторов было малое. Так, для 550Krps было всего 4 потока event-loop'а. Дополнительную информацию можно увидеть тут
Так выглядела пропускная способность:

А вот так утилизация процессора:

Машинки стояли мощные, 32 логических ядра:)
На таких графиках видно как работа с неблокирующими сокетами позволяет добиться вдвое большей пропускной способности при той же утилизации. Причем, в случае неблокирующих сокетов, дальше я упёрся во внутренний код стрелялки, который занимается логикой, и дальнейшие бенчмарки без jmeter показали еще большие значения производительности.
У gevent используются корутины, и по факту это обертка над неблокирующими сокетами, и внутри используется select/poll/epoll ;-)
> Fast event loop based on libev (epoll on Linux, kqueue on FreeBSD). © www.gevent.org
> Fast event loop based on libev (epoll on Linux, kqueue on FreeBSD). © www.gevent.org
А исходников не будет?
Сервера уже повыключали? Я бы мог вам на Erlang для сравнения написать аналог.
Сервера уже повыключали? Я бы мог вам на Erlang для сравнения написать аналог.
А почему у всех Python 2, а у Tornado Python 3? По памяти, по моим тестам около 10% разница получалась в пользу 2.
Тут важен процессор, по памяти расход везде небольшой. Я бы с радостью везде использовал 3-ий Python, но поддержки нет, это конечно печально.
Стоило проверять все на одной версии питона — они слишком разные по производительности.
Но, в среднем, питоновский код медленнее на тройке. Например Django медленнее где-то на 7%. Шаблонизаторы еще медленнее — до 20%.
Но, в среднем, питоновский код медленнее на тройке. Например Django медленнее где-то на 7%. Шаблонизаторы еще медленнее — до 20%.
Стоит добавить, что для второго питона есть PyPy и торнадо на нем отлично работает. В отличие от gevent. И разница в производительности там существенная.
Прошу прощения, что ввел в заблуждение. «По памяти» -> «Если ничего не путаю». Разница именно в rps на легкой нагрузке(запись в dict значения).
Сравнение всё же было бы честнее проводить на одной вресии Python.
Сравнение всё же было бы честнее проводить на одной вресии Python.
Для наглядности прогон ab -c 500 -n 50000 -s 5 127.0.0.1:8888/ на hello world с www.tornadoweb.org/en/stable/
Тест проведен наспех на попавшемся под руку AMD E350. Python полностью съел одно ядро. Еще одного с запасом хватило на ab и прочее.
Тяжелые приложения были все убиты. Тест повторялся несколько раз, результаты отличались незначительно.
Краткий итог:
Python 3 ~495 rps, 1011 ms mean, total time 101 s
Python 2 ~635 rps, 788 ms mean, total time 79 s
Итого Tornado на Python 2 в данных условиях почти на 30% быстрее, чем на Python 3.
P.S. Тест только для наглядной демонстрации заметной разницы. На реальных задачах такой разницы не наблюдал, но 10% легко.
Тест проведен наспех на попавшемся под руку AMD E350. Python полностью съел одно ядро. Еще одного с запасом хватило на ab и прочее.
Тяжелые приложения были все убиты. Тест повторялся несколько раз, результаты отличались незначительно.
Python 2.7.7
Server Software: TornadoServer/3.2.2
Server Hostname: 127.0.0.1
Server Port: 8888
Document Path: /
Document Length: 12 bytes
Concurrency Level: 500
Time taken for tests: 78.771 seconds
Complete requests: 50000
Failed requests: 0
Total transferred: 10350000 bytes
HTML transferred: 600000 bytes
Requests per second: 634.75 [#/sec] (mean)
Time per request: 787.714 [ms] (mean)
Time per request: 1.575 [ms] (mean, across all concurrent requests)
Transfer rate: 128.31 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 554 1232.9 0 7027
Processing: 23 219 86.6 205 5960
Waiting: 23 219 86.6 205 5960
Total: 47 773 1240.9 206 7256
Percentage of the requests served within a certain time (ms)
50% 206
66% 223
75% 251
80% 1226
90% 3217
95% 3233
98% 3255
99% 7220
100% 7256 (longest request)
Server Hostname: 127.0.0.1
Server Port: 8888
Document Path: /
Document Length: 12 bytes
Concurrency Level: 500
Time taken for tests: 78.771 seconds
Complete requests: 50000
Failed requests: 0
Total transferred: 10350000 bytes
HTML transferred: 600000 bytes
Requests per second: 634.75 [#/sec] (mean)
Time per request: 787.714 [ms] (mean)
Time per request: 1.575 [ms] (mean, across all concurrent requests)
Transfer rate: 128.31 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 554 1232.9 0 7027
Processing: 23 219 86.6 205 5960
Waiting: 23 219 86.6 205 5960
Total: 47 773 1240.9 206 7256
Percentage of the requests served within a certain time (ms)
50% 206
66% 223
75% 251
80% 1226
90% 3217
95% 3233
98% 3255
99% 7220
100% 7256 (longest request)
Python 3.4.1
Server Software: TornadoServer/3.2.2
Server Hostname: 127.0.0.1
Server Port: 8888
Document Path: /
Document Length: 12 bytes
Concurrency Level: 500
Time taken for tests: 101.091 seconds
Complete requests: 50000
Failed requests: 0
Total transferred: 10350000 bytes
HTML transferred: 600000 bytes
Requests per second: 494.60 [#/sec] (mean)
Time per request: 1010.911 [ms] (mean)
Time per request: 2.022 [ms] (mean, across all concurrent requests)
Transfer rate: 99.98 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 696 1161.8 0 15040
Processing: 51 304 50.9 295 2005
Waiting: 50 303 50.9 295 2005
Total: 72 999 1162.7 331 15301
Percentage of the requests served within a certain time (ms)
50% 331
66% 1282
75% 1316
80% 1335
90% 3282
95% 3303
98% 3346
99% 3391
100% 15301 (longest request)
Server Hostname: 127.0.0.1
Server Port: 8888
Document Path: /
Document Length: 12 bytes
Concurrency Level: 500
Time taken for tests: 101.091 seconds
Complete requests: 50000
Failed requests: 0
Total transferred: 10350000 bytes
HTML transferred: 600000 bytes
Requests per second: 494.60 [#/sec] (mean)
Time per request: 1010.911 [ms] (mean)
Time per request: 2.022 [ms] (mean, across all concurrent requests)
Transfer rate: 99.98 [Kbytes/sec] received
Connection Times (ms)
min mean[±sd] median max
Connect: 0 696 1161.8 0 15040
Processing: 51 304 50.9 295 2005
Waiting: 50 303 50.9 295 2005
Total: 72 999 1162.7 331 15301
Percentage of the requests served within a certain time (ms)
50% 331
66% 1282
75% 1316
80% 1335
90% 3282
95% 3303
98% 3346
99% 3391
100% 15301 (longest request)
Краткий итог:
Python 3 ~495 rps, 1011 ms mean, total time 101 s
Python 2 ~635 rps, 788 ms mean, total time 79 s
Итого Tornado на Python 2 в данных условиях почти на 30% быстрее, чем на Python 3.
P.S. Тест только для наглядной демонстрации заметной разницы. На реальных задачах такой разницы не наблюдал, но 10% легко.
Большое спасибо за ваш тест. Теперь я понял, что вы имели ввиду. Ниже habrahabr.ru/post/228455/#comment_7741325 я ответил почему использовал разные версии Python во время тестирования.
еще бы Go lang потестировать по той же схеме…
На Raspberry Pi:) и в один поток, Go оказался быстрей node.js но медленней nginx — gist.github.com/msoap/7060974
эмм. а почему в тесте руби 1.8.7? сейчас во всю идет 2.1.2.
Еще, не могли бы вы объяснить, почему вы тестировали разные фреймворки на разных версиях python?
Еще, не могли бы вы объяснить, почему вы тестировали разные фреймворки на разных версиях python?
Я использовал каждый фреймворк с последний версией Python, которую он поддерживает. Я бы не стал использовать 2-ую версию Python в новом проекте даже в случае более высокой производительности. Другими словами, я не вижу смысла использовать Tornado со 2-ой версией Python в то время, когда он поддерживает 3-юю. С версией ruby вы правы, я проглядел, виной тому стабильный дистрибутив Debian, я думаю.
Ну тут уж либо шашечки, либо ехать. Если Вы не хотите писать на Python 2(я давно не писал на 2 и уж точно стану без весских причин возращаться) — тогда нет смысла вообще смотреть на фреймворки, которые не поддерживают Python 3. Если же это в принципе рассматривается, то сравнивать надо на Python 2. Разница может быть больше, чем между фреймворками. Так что во многом смысл сравнения теряется.
Я очень не хотел писать на Python 2 и это было почти невероятным событием для меня. Но я думал так — если я найду какое-то решение, которое будет уходить в отрыв и будет поддерживать только Python 2, то это станет поводом копать в сторону этого решения.
Так стало как раз с Gevent, который официально не поддерживает 3-ий Python, но есть форк, который поддерживает. Я бы, честно говоря, и использовал сейчас именно этот форк, если бы не реализация asyncio в python 3.4. Вы можете сказать, что я должен был сравнить производительность этого форка Gevent с тем же Tornado на 3-их версиях и я с вами соглашусь.Трудность здесь, как я написал в статье, с выделенным количеством времени на мое исследование. Для меня это мог стать бесконечный процесс, который закончился бы каким-нибудь Erlang'ом.
Если бы я тогда последовал принципу проверить все на Python 2, что бы сравнение между фреймворками было более честным, и выиграл бы Tornado или любой другой фреймворк, который поддерживает Python 3, то я бы безусловно захотел использовать именно 3-юю версию с ним, а тогда мне пришлось бы все равно запускать тесты еще и на 3-ей версии Python.
Так стало как раз с Gevent, который официально не поддерживает 3-ий Python, но есть форк, который поддерживает. Я бы, честно говоря, и использовал сейчас именно этот форк, если бы не реализация asyncio в python 3.4. Вы можете сказать, что я должен был сравнить производительность этого форка Gevent с тем же Tornado на 3-их версиях и я с вами соглашусь.Трудность здесь, как я написал в статье, с выделенным количеством времени на мое исследование. Для меня это мог стать бесконечный процесс, который закончился бы каким-нибудь Erlang'ом.
Если бы я тогда последовал принципу проверить все на Python 2, что бы сравнение между фреймворками было более честным, и выиграл бы Tornado или любой другой фреймворк, который поддерживает Python 3, то я бы безусловно захотел использовать именно 3-юю версию с ним, а тогда мне пришлось бы все равно запускать тесты еще и на 3-ей версии Python.
В Ruby с пришествием 1.9 (а сейчас уже 2.1) всё должно стать заметно лучше, как минимум по памяти.
Там появились Fibers (легковесные быстросоздаваемые треды с их шедулингом силами приложения, а не VM). Ну и Garbage collector с тех пор начительно улучшился, как по скорости так и по поведению Copy-on-Write механизмов.
Added: Это я к тому, что комментаторы не зря указывают автору на устаревшую версию Руби.
Там появились Fibers (легковесные быстросоздаваемые треды с их шедулингом силами приложения, а не VM). Ну и Garbage collector с тех пор начительно улучшился, как по скорости так и по поведению Copy-on-Write механизмов.
Added: Это я к тому, что комментаторы не зря указывают автору на устаревшую версию Руби.
Ммм, 1.8.7, некрофилия…
Хотелось бы увидеть конфиг nginx, так же узнать какой был tcp congestion control algorithm и другие настройки tcp включая initcwnd, initrwnd.
А почему у Вас GridFS только для 2-х серверов протестирован?
Asyncio из Python 3.4
Sign up to leave a comment.
Немного тестов производительности сетевых фреймворков