Comments 24
Где можно взглянуть на исходники конечного результата?
Если интересно, можно просто написать решето, работающее за чисто линейное время (правда, на каждое число потребуется не один бит, а один int).
Исходный код можно и по-другому асимптотически прооиптимизировать. Правда, к CUDA и распараллеливанию мой комментарий не имеет никакого отношения.
Исходный код можно и по-другому асимптотически прооиптимизировать. Правда, к CUDA и распараллеливанию мой комментарий не имеет никакого отношения.
За линейное время искать простые числа ещё нельзя.
Внимательно прочитал. Не всё там так хорошо. Во-первых оно не параллелится. Умеет считать простые числа от 2 до N.
Память.
const int N = 10000000;
int lp[N+1]; — sizeof(int)*10000000 = 38мб
vector pr; — (количествоПростыхЧисел*2+1)*sizeof(int) (случай 32 бит) = ~5мб.
Объединим в ~40мб. 1e7
1e8 ~= 400мб
1e9 ~= 4гб
Тут мы перестаём влезать в int.
1e10 ~= 80гб.
Не соглашусь с линейностью работы алгоритма по причине того что поиск по вектору имеет сложность отличную от единицы, а именно — N. На больших числах общая сложность стремится к единице, но не равна, как утверждается. Сейчас напишу об этом emaxx.
Память.
const int N = 10000000;
int lp[N+1]; — sizeof(int)*10000000 = 38мб
vector pr; — (количествоПростыхЧисел*2+1)*sizeof(int) (случай 32 бит) = ~5мб.
Объединим в ~40мб. 1e7
1e8 ~= 400мб
1e9 ~= 4гб
Тут мы перестаём влезать в int.
1e10 ~= 80гб.
Не соглашусь с линейностью работы алгоритма по причине того что поиск по вектору имеет сложность отличную от единицы, а именно — N. На больших числах общая сложность стремится к единице, но не равна, как утверждается. Сейчас напишу об этом emaxx.
Итак. Разобрался. Алгоритм имеет линейную сложность, действительно. Предполагал что vector в сях — односвязный список, но нет.
Но при этом вон тот мой комментарий тоже истинен. Линейного алгоритма поиска простых чисел нет ( f(10) = 29 ). Решета есть.
Но при этом вон тот мой комментарий тоже истинен. Линейного алгоритма поиска простых чисел нет ( f(10) = 29 ). Решета есть.
Тут нельзя не напомнить о проводившемся полтора года назад конкурсе на поиск сумм простых чисел — Результаты новогоднего Хабра-соревнования по программированию, анализ и обсуждение
Немного странные результаты. CUDA обычно дает ускорение от 10 до 100 раз (в зависимости от того, насколько задача хорошо параллелится). У вас же ускорение всего в 3 раза. Блочное решето вроде бы хорошо параллелит. Имхо меньше 1 секунды должно получаться довольно просто.
Возможно ускорение слабое еще и из-за того, что тестировалось все на достаточно слабой GeForce 9600 GT, у которой всего 64 потоковых процессора.
Да, видимо, карточка слабая. Чуть ниже пишут, что этот код отрабатывает 1 сек на GTX 660, так что с ним, похоже, все нормально.
Для интереса попробовал запустить ваш код еще на старенькой, но довольно мощной Tesla C2050 — и на ней результат получился довольно неутешительный, 4.27 секунд.
Такая большая разница довольно любопытна. На моих задачах разница между этими двумя картами (GTX 660 и C2050) получалась гораздо более скромная. Число потоковых процессоров у 660й больше в два раза (448 у теслы против 960 у 660й), пропусная способность памяти одинаковая. На вашей задаче я бы ожидал разницу раза в полтора-два в худшем случае.
Такая большая разница довольно любопытна. На моих задачах разница между этими двумя картами (GTX 660 и C2050) получалась гораздо более скромная. Число потоковых процессоров у 660й больше в два раза (448 у теслы против 960 у 660й), пропусная способность памяти одинаковая. На вашей задаче я бы ожидал разницу раза в полтора-два в худшем случае.
если что — я не автор поста и код не мой
Там, на самом деле, довольно много вещей, которые могут сказаться на время выполнения. Для оценки производительности лучше смотреть на число мультипроцессоров (streaming multiprocessor, SM), частоту ядер и число warp-sheduler'ов на каждый SM, а не на число потоковых процессоров (в любой момент времени активны только 16 (warp_size/2) потока на каждый warp-sheduler независимо от числа потоковых процессоров).
На C2050 14 SM (32 ядра в каждом SM, итого 448), 1 warp-sheduler на SM, частота ядер 0.575 GHz
На GTX660 5 SM (192 ядра в каждом SM, итого 960), 4 warp-shedulers на SM, частота ядер 0.98 GHz
Т.е. уже разница 2,5 раза. Но эта цифра мало что говорит, потому что мы еще активно работаем с памятью. У GTX660 латентность памяти получается несколько ниже, поскольку больше ядер на 1 warp-sheduler (48 против 32). Хотя, с другой стороны, в C2050 вроде бы есть какие-то кэши… И это я еще не вспоминал про shared память (в код не смотрел, вероятно она не используется).
Короче, там столько нюансов, что лучше код затачивать под одну конкретную карточку…
P.S. Я CUDA ковырял года 2 назад, мог кое-какие детали забыть и где-нибудь наврать, поправьте если что не так.
Там, на самом деле, довольно много вещей, которые могут сказаться на время выполнения. Для оценки производительности лучше смотреть на число мультипроцессоров (streaming multiprocessor, SM), частоту ядер и число warp-sheduler'ов на каждый SM, а не на число потоковых процессоров (в любой момент времени активны только 16 (warp_size/2) потока на каждый warp-sheduler независимо от числа потоковых процессоров).
На C2050 14 SM (32 ядра в каждом SM, итого 448), 1 warp-sheduler на SM, частота ядер 0.575 GHz
На GTX660 5 SM (192 ядра в каждом SM, итого 960), 4 warp-shedulers на SM, частота ядер 0.98 GHz
Т.е. уже разница 2,5 раза. Но эта цифра мало что говорит, потому что мы еще активно работаем с памятью. У GTX660 латентность памяти получается несколько ниже, поскольку больше ядер на 1 warp-sheduler (48 против 32). Хотя, с другой стороны, в C2050 вроде бы есть какие-то кэши… И это я еще не вспоминал про shared память (в код не смотрел, вероятно она не используется).
Короче, там столько нюансов, что лучше код затачивать под одну конкретную карточку…
P.S. Я CUDA ковырял года 2 назад, мог кое-какие детали забыть и где-нибудь наврать, поправьте если что не так.
Я просто оставлю это здесь.
Отличнейший результат по сравнению с тем что в статье
0.04 sec на core i7 3770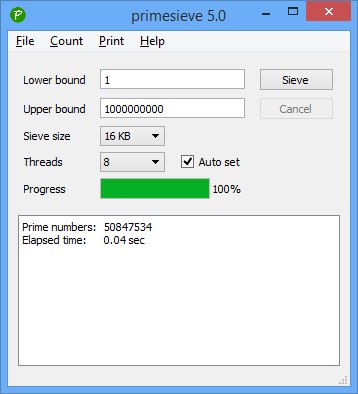

Поигрался с вашим кодом — на моей машине версия для GPU отрабатывает всего за секунду, а версию для CPU было лень адаптировать, ибо WinAPI.
(GPU: NVidia GTX 660).
Но если убрать лишнее ветвление тут:
вместо этого просто написав
то будет работать на 15-20% быстрее, т.е. примерно за 0.81-0.86 секунды.
(GPU: NVidia GTX 660).
Но если убрать лишнее ветвление тут:
for(k=offset; k<=(i+1)*PART_SIZE; k+=part1[j]*2)
if(part[(k-(i*PART_SIZE)-1)/2]) part[(k-(i*PART_SIZE)-1)/2] = false;
вместо этого просто написав
for(k=offset; k<=(i+1)*PART_SIZE; k+=part1[j]*2)
part[(k-(i*PART_SIZE)-1)/2] = false;
то будет работать на 15-20% быстрее, т.е. примерно за 0.81-0.86 секунды.
вот есть такая очень полированная, взрослая, дико быстрая реализация Eratosthenes sieve, со всеми бантиками, уже многопоточная: http://primesieve.org/ но с одним огорчительным ограничением: до 2^64
вот бы нашелся витязь в тигровой шкуре, который бы перенес на GPU и
— повысил битность до 256 вначале
— а потом до arbitrary битности
исчерпывающий(!) а не только чисел Мерсенна список всех простых чисел до 2048 бит это уже интересный вопрос ;)
вот бы нашелся витязь в тигровой шкуре, который бы перенес на GPU и
— повысил битность до 256 вначале
— а потом до arbitrary битности
исчерпывающий(!) а не только чисел Мерсенна список всех простых чисел до 2048 бит это уже интересный вопрос ;)
Sign up to leave a comment.
Параллелим непараллельное или поиск простых чисел на GPU