Введение
Недавно и не надолго ко мне в руки попала система хранения данных (СХД) VNXe3200, которая была анонсирована компанией EMC2 для заказчиков 5 мая 2014 года. VNXe3200 — это второе поколение entry-level Unified СХД компании EMC2. В данной модели появились технологии доступные ранее только на более старших и более дорогих midrange массивах. В частности технология FastCachе — т.е. кэш второго уровня на SSD дисках, который встает в разрез между традиционным кэшем в оперативной памяти контроллера СХД (в терминологии EMC — Storage Processor) и собственно дисками. Я решил проверить, как данная технология влияет на производительность ввода/вывода на самых младших СХД компании EMC2.
В отличии от старших СХД EMC VNX, в данной модели как блочный, так и файловый доступ реализован на одних и тех же контроллерах (SP). СХД в базе имеет на каждый SP по 4 медных порта 10Gbit/s (10GBASE-T), через которые реализуется подключение клиентов/хостов по протоколам CIFS/SMB, NFS и iSCSI. Порты эти с autonegotiation 10G/1G/100Mb в секунду. Дополнительно в каждый SP можно поставить плату на 4 порта 8Gb/s FC. Тестировать решено было при помощи IOMETER. В этом помогла, в том числе, вот эта статья с Хабра: ссылка.
Описание стенда и тестов
С профилем нагрузки мудрить не стал, взял стандартный Database pattern (Intel/StorageReview.com).
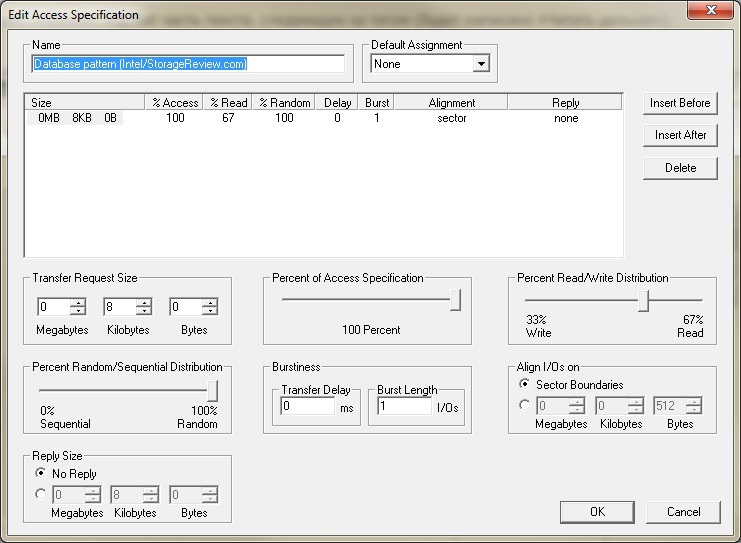
Для тестирования был взят Blade BL460c G7 сервер (один CPU 6 ядер + HT, 24GB ОЗУ), подключенный по FC к СХД через встроенные в блэйдовую корзину FC коммутаторы c портами на 4Gbit/s. На сервере была установлена OS Windows 2012 R2 c загрузкой по FC с VNXe3200 (boot from SAN). К серверу был подключен, так же по FC, тестовый том (LUN) размером в 1Tb c файловой системой NTFS. На СХД собран дисковый пул из 10 дисков (SAS 2,5" 10k RPM 600Gb) с двумя приватными рэйд группами (RG) внутри, которые имеют конфигурацию Raid5 (4+1). Так же на массиве их двух SSD дисков (2,5" 100Gb) собран FastCache (зеркальная пара Raid1).
Тестирование проводилось в три этапа.
1) При помощи IOMETER создается маленький тестовый файл размером в 2Gb, в расчете что он полностью поместиться в Cache SP на СХД.
2) Предыдущий тестовый файл удалялся и создается тестовый файл размером ~50Gb, в расчете на то что он не поместится в Cache SP, но зато полностью войдет в FastCache.
3) Предыдущий тестовый файл удалялся и создается тестовый файл размером ~500Gb, в расчете на то что он не поместиться ни в один из кэшей и при 100% рандомном доступе практически даст производительность имеющихся шпиндельных дисков.
Тесты были настроены таким образом, чтобы перед каждым проходом был «разогрев» в 10 минут, потом тест 20 минут. Каждый тест выполнялся с экспоненциальным ростом потоков ввода/вывода (1-2-4-8-16) на каждый из 12-ти workers (6 ядер + HT). При этом, помимо собственно выдаваемых СХД IOPS-ов, было интересно комфортное среднее время отклика < 10 миллисекунд (ms). Сразу оговорюсь, что приведу «картинки» с графиками из интерфейса VNXe3200, но количественные показатели на них совпадают с результатами в csv файлах IOMETER, которые будут приведены ссылками.
Дальше немного расчетов.
Если не учитывать влияние cache на ввод/вывод, то для дисков SAS 10k EMC предлагает считать по 150 IOPS на диск. У нас в сумме на бэкенде при 10 дисках должно получиться 150*10=1500 IOPS. Если мы учтем нашу нагрузку r/w 67%/33% и потери на работу с CRC в Raid5, то получим следующее уравнение с одной неизвестной. 1500=X*0.33*4+X*0.67, где X это у нас те IOPS, которые получат хосты с наших дисков. A 4 — это размер «пенальти» для Raid5. То есть в Raid5 для выполнения одной операции записи, приходящей с хоста, требуется 4 операции ввода/вывода на бэкенде (на дисках СХД). Для Raid1/Raid10 значение пенальти — 2, для Raid6 — 6. В итоге получаем X=1500/1,99= ~750 IOPS. На практике я замечал что максимальные достигаемые значения бывают больше расчетных в 1,5-2 раза. Значит в пиковой нагрузке можем получить 1125-1500 IOPS с наших 10 SAS дисков.
Перейдем собственно к тестам и их результатам
Тест 1
Как и предполагалось тестовый файл практически полностью поместился в cache SP.

При тестировании мы получили следующую картину по IOPS и попаданиям запросов ввода/вывода в кэш. Тут нужно оговориться о том, что данный график показывает на самом деле все IO проходящие через SP. Часть из них отрабатывается из SP cache (hit), часть «пролетает» SP cache на сквозь (miss) и отрабатывается либо из FastCache, либо со шпиндельных SAS дисков.
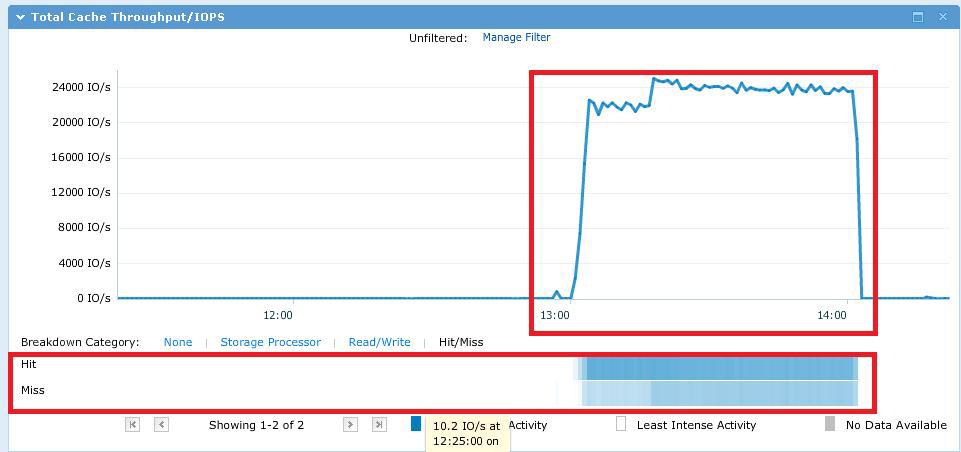
При этом среднее время отклика при максимальном количестве потоков в IOMETER (12 workers * 16 потоков IO = 192 потока ввода/вывода) составило ~8 ms. Файл с результатами IOMETER тут. Первый тест был проведен с увеличением количества потоков на worker от 4 до 32 (4-8-16-32). Заметил поздно в чем каюсь, но переделывать уже было некогда.
Тест 2
В процессе теста тестовый файл на ~50GB почти полностью поместился в FastCache, как и ожидалось.
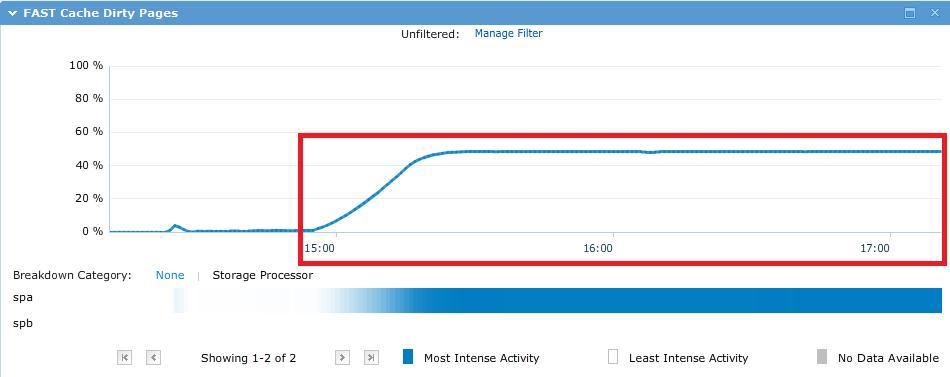
В результате получилась следующая картинка, на которой видно, что практически все запросы пролетают мимо SP cache.

Среднее время отклика на 192 потоках было ~12.5 ms. Комфортное время отклика было на 8 потоках на worker ~8 ms (96 потоков IO). Файл с результатами IOMETER тут.
Тест 3
В процессе теста ввод/вывод рандомно «бегал» по всем ~500Gb и ни один cache в теории тут помочь не мог, что и видно на практике по графикам ниже.
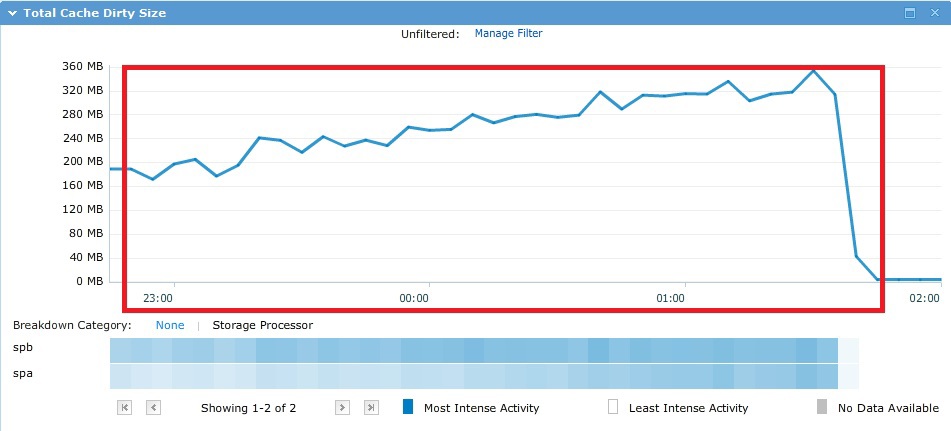
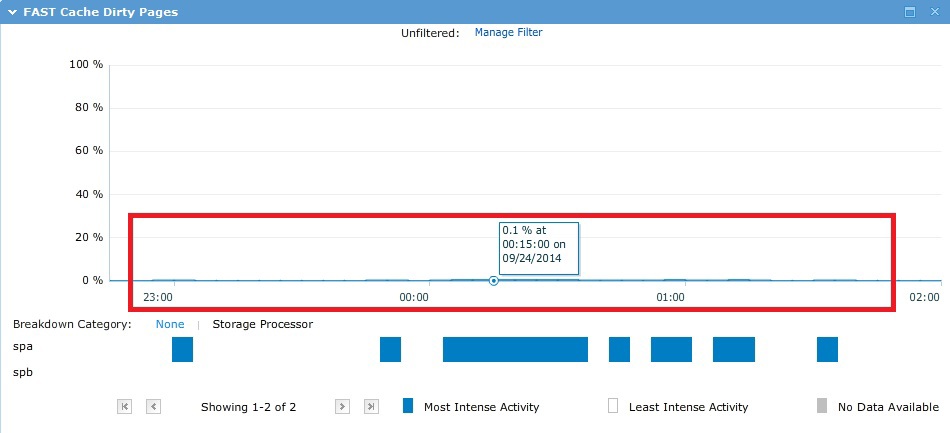
В результате, как и планировалось, получили производительность 10 SAS шпинделей в Raid5. При этом 4 первых в СХД диска из использованных в пуле — это так называемый VaultPack. То есть часть от этих первых дисков (~82,5 GB с каждого) «отрезана» под системные нужды.
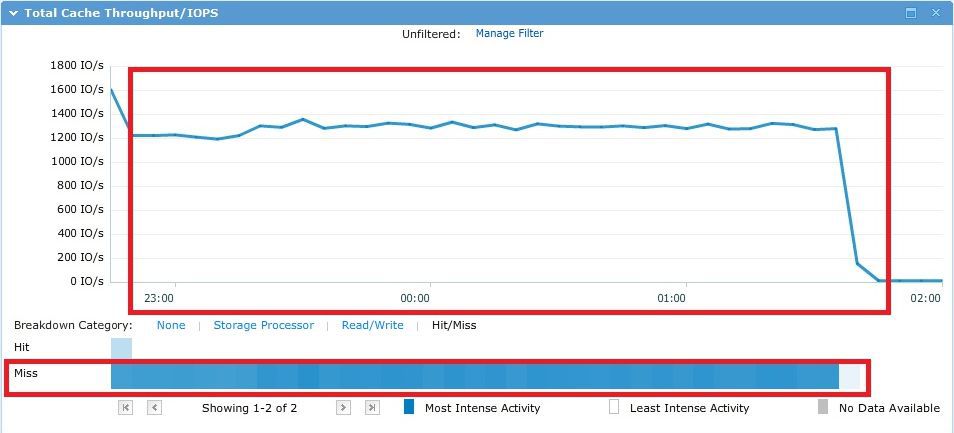
Среднее время отклика на 192 потоках было довольно большим и составило ~149 ms. Комфортное время отклика было при 1 потоке на worker (12 потоков IO) ~10 ms. Файл с результатами IOMETER тут.
Небольшое отступление про пулы
При проектировании диского пула, если вы не знаете реальные размеры области «горячих» и «теплых» данных, то EMC рекомендует придерживаться следующих пропорций для трехуровнего пула:
10% — SSD диски
20% — SAS диски
70% — NL-SAS диски
Кроме того нужно учитывать, что при добавлении flash tier в пул автоматически все метаданные thin лунов, созданных а пуле, будут размещены на SSD. Если там хватает для них места. Это позволяет поднять общую производительность thin лунов и пула. Под эти метаданные нужно планировать дополнительно место на SSD из расчета 3Gb объема на каждый 1Tb реально занятый тонкими лунами на пуле. При всем этом луны имеющие политику тиринга «highest available tier» будут иметь приоритет при размещении на SSD-тире перед любыми другими данными.
Использование политики «lowest available tier» для thin лунов приводит к размещению их метаданных на самых медленных дисках.
Итоги
Тестирование показало, что все типы Cache в СХД в целом оказывают положительное влияние не только на общую производительность массива. Но и на среднее время отклика операций ввода/вывода, особенно под высокой нагрузкой. А учитывая выше сказанное, в кэш как раз будут попадать наиболее «горячие» данные.
Можно сделать вывод, что FastCache в EMC VNXe3200 будет являться вполне удачным и востребованным дополнением даже при небольших конфигурациях. Учитывая что процесс его «разогрева» (попадания данных в кэш) происходит достаточно быстро.
