Наша команда разрабатывает бекэнд-систему для обработки сообщений от мобильных устройств. Устройства собирают информацию о работе сложной техники и посылают сообщения в центр обработки. В этой статье я хочу поделиться подходами к построению подобных систем. Идеи достаточно общие, их можно применять для любой системы со следующей архитектурой:

По каналам связи устройства присылают сообщения на наш шлюз (gateway) – входную точку приложения. Задача приложения – разобраться, что именно пришло, произвести необходимые действия и сохранить информацию в базе данных для дальнейшего анализа. Базу мы будем рассматривать как конечную точку обработки. Звучит просто, но с ростом количества и разнообразия сообщений появляется несколько нюансов, которые я и хочу обсудить.
Немного про уровень нагрузки. Наша система обрабатывает сообщения от десятков тысяч устройств, при этом за секунду в среднем мы получаем от нескольких сотен до тысячи сообщений. Если ваши числа отличаются на пару порядков в ту или иную сторону, возможно, набор ваших проблем и подходов к их решению будет другим.
Кроме собственно числа сообщений в секунду, существует проблема их неравномерного получения. Приложение должно быть готово к коротким пикам нагрузки в десятки раз выше среднего. Для решения этой задачи система организуется в виде набора очередей и их обработчиков.
Приемный шлюз не делает никакой реальной работы – он просто получает сообщение от клиента и помещает его в очередь. Это очень дешевая операция, поэтому шлюз способен получать огромное количество сообщений в секунду. Затем, существует отдельный процесс, который получает из очереди несколько сообщений – ровно столько, сколько он хочет и может – и делает тяжелую работу. Обработка получается асинхронной, а нагрузка – стабильно ограниченной. Возможно, в пике слегка вырастет время пребывания сообщений в очереди, вот и все.
Зачастую, обработка сообщения нетривиальна и состоит из нескольких действий. Следующий логичный шаг – разбить работу на несколько этапов: несколько очередей и обработчиков. При этом физически разные очереди и обработчики могут располагаться на разных серверах, каждый из которых можно настраивать и масштабировать под его конкретную задачу:

Первая очередь содержит сообщения в том виде, в котором они поступили от устройства. Обработчик декодирует их и помещает во вторую очередь. Второй обработчик может, например, производить некую агрегацию и создавать информацию, интересную для бизнеса, а третий обработчик – сохранять её в базу данных.
Таков базовый расклад, о чем же еще надо подумать?
Асинхронная распределённая обработка сообщений привносит в программный продукт дополнительную сложность. Мы постоянно работаем над снижением этой цены. Код оптимизируется, в первую очередь, в сторону повышения читаемости, понятности для всех членов команды, простоты изменения и поддержки. Если в итоге никто кроме автора не сможет разобраться в коде, никакая великолепная архитектура не поможет сделать команду счастливой.
Тезис кажется простым, но нам потребовалось достаточно много времени, прежде чем мы не просто озвучили этот принцип, но и стали стабильно и постоянно применять его в ежедневной работе. Мы стараемся постоянно делать рефакторинг, если чувствуем, что код можно сделать чуть лучше и проще. Все исходники проходят ревью, а наиболее критические части обычно разрабатываются в паре.
Имеет смысл сразу определиться относительно требований к способности системы продолжать функционировать при возникновении отказов оборудования и подсистем. У всех они будут разными. Возможно, кто-то готов просто выбросить все сообщения за те 5 минут, что один из серверов перезагружается.
В нашей системе мы не хотим терять сообщения. Если какой-то сервис недоступен, вызов к базе заканчивается таймаутом, или происходит случайная ошибка в обработке, это не должно закончиться потерей информации от устройств. Зависимые сообщения должны сохраниться в очереди и будут обработаны сразу после устранения проблемы.
Допустим, ваш код на одном сервере синхронно вызывает веб сервис на другом сервере. Если второй сервер недоступен, обработка закончится ошибкой, а вы сможете разве что залогировать ее. При асинхронной обработке сообщение будет дожидаться, когда второй сервер вернется в рабочее состояние.
Число сообщений, обрабатываемых в единицу времени, задержки, нагрузки на сервера — всё это важные параметры производительности системы. Именно поэтому мы закладываем в проект гибкую архитектуру.
Однако, не зацикливайтесь на оптимизации с самого начала. Обычно подавляющая часть проблем с производительностью создается относительно небольшими кусками кода. К сожалению, мало кто способен заранее предсказать где именно будут эти проблемы. Вот тут люди пишут целые книги о преждевременной оптимизации. Убедитесь, что ваша архитектура позволяет быстро настраивать систему и забудьте об оптимизации до первых нагрузочных тестов.
В то же время, нагрузочные тесты нужно начинать делать рано, а затем сделать их частью стандартной процедуры тестирования. И только тогда, когда тесты покажут конкретную проблему, беритесь за оптимизацию.
Об этом я уже писал выше. Наш основной инструментарий — очереди и их обработчики. В дополнение к классическому стилю организации кода «получил запрос, вызвал удаленный код, дождался ответа, вернул ответ наверх», мы получаем подход «получил сообщение из очереди, отработал, отправил сообщение в другую очередь». От того, насколько удачный баланс в сочетании двух подходов вы найдете, зависит как масштабируемость, так и простота разработки системы.
Если обработка сообщения достаточно сложна и может быть разбита на несколько этапов, предусмотрите несколько очередей и обработчиков. Имейте в виду, что излишняя фрагментация может сделать систему более сложной для понимания. Тут нужен баланс. Достаточно часто существует разбиение, естественное и понятное для разработчиков. Если нет, то попробуйте подумать о точках отказа. Если обработчик может завершиться ошибкой по нескольким независимым причинам, можно подумать о его разбиении.
Обычно, сообщение приходит в формате какого-то протокола взаимодействия устройств в сети: бинарном, xml, json и т.д. Декодируйте и переводите их в свой внутренний формат как можно раньше. Это позволит решить минимум две задачи. Во-первых, протоколов может быть несколько; после декодирования вы сможете унифицировать формат дальнейших сообщений. Во-вторых, упрощается логирование и отладка.
Структурируйте код обработки таким образом, чтобы вы могли легко поменять конфигурацию очередей. Разбиение обработчика на два не должно приводить к туче рефакторинга. Не позволяйте вашему коду зависеть слишком сильно от конкретной реализации очередей, завтра вы можете захотеть изменить ее.
Зачастую имеет смысл получать сообщения из очереди не по одному, а сразу группами. Используемые вами сервисы могут принимать массив данных для пакетной обработки, в таком случае один большой вызов обычно будет намного эффективней ста маленьких. Вставка сотни записей в базу за один раз будет быстрее ста удаленных вызовов.
Вкладывайтесь в мониторинг с самого начала. Вы должны легко и наглядно видеть график пропускной способности, среднего времени обработки, текущий размер очереди, время с последнего сообщения с разбивкой по очередям.

Мы используем мониторинг не только в боевом окружении, но и в тестовом, и даже на машинах разработчиков. Правильно настроенные графики и уведомления весьма полезны при отладке и предварительном нагрузочном тестировании.
Системы обработки сообщений — идеальный полигон для автоматизированного тестирования. Протокол входных данных определен и ограничен, никаких взаимодействий с живыми людьми. Покрывайте код модульными тестами. Предусмотрите возможность заменить боевые очереди на тестовые очереди в локальной памяти и делайте быстрые тесты взаимодействия обработчиков. Наконец, делайте полноценные интеграционные тесты, которые можно гонять в бета (staging) окружении (а лучше и в продукции).
Чаще всего, вы не захотите, чтобы ошибка обработки одного сообщения остановила всю очередь. Не менее важна возможность диагностировать ошибку. Помещайте такие сообщения в специальное хранилище и нацельте на это хранилище все свои прожекторы. Предусмотрите возможность с легкостью переместить сообщение обратно в очередь обработки как только причина ошибки устранена.
Этот же или похожий механизм можно использовать для хранения сообщений, которые должны быть обработаны не раньше какого-то момента в будущем. Мы держим их в отстойнике и периодически проверяем, не настал ли час Ч.
Установка и обновление системы должна происходить в один или несколько кликов. Стремитесь к частым обновлениям на продукции, в идеале — автоматическому развертыванию после каждого коммита в master ветку. Установочный скрипт поможет разработчикам поддерживать их личную среду, а также среды тестирования в актуальном состоянии.
Хорошая понятная архитектура – это еще и способ упрощения коммуникации разработчиков, их общее видение и набор понятий. В этом смысле нам очень помогло формулирование метафоры системы в виде картинки, с которой можно начинать многие обсуждения в проекте.
Наша метафора похожа на вот эту картинку из статьи дядюшки Боба The Clean Architecture:
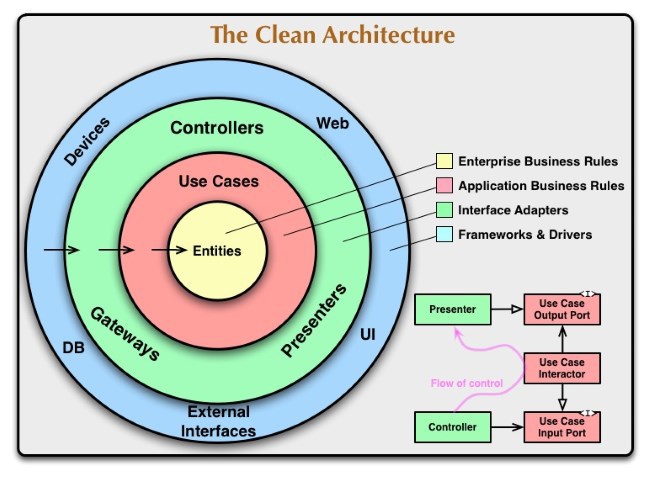
На нашей схеме мы обозначаем сущности системы и их зависимости, что помогает в дискуссии приблизиться к правильному дизайну, найти ошибки или запланировать рефакторинг.
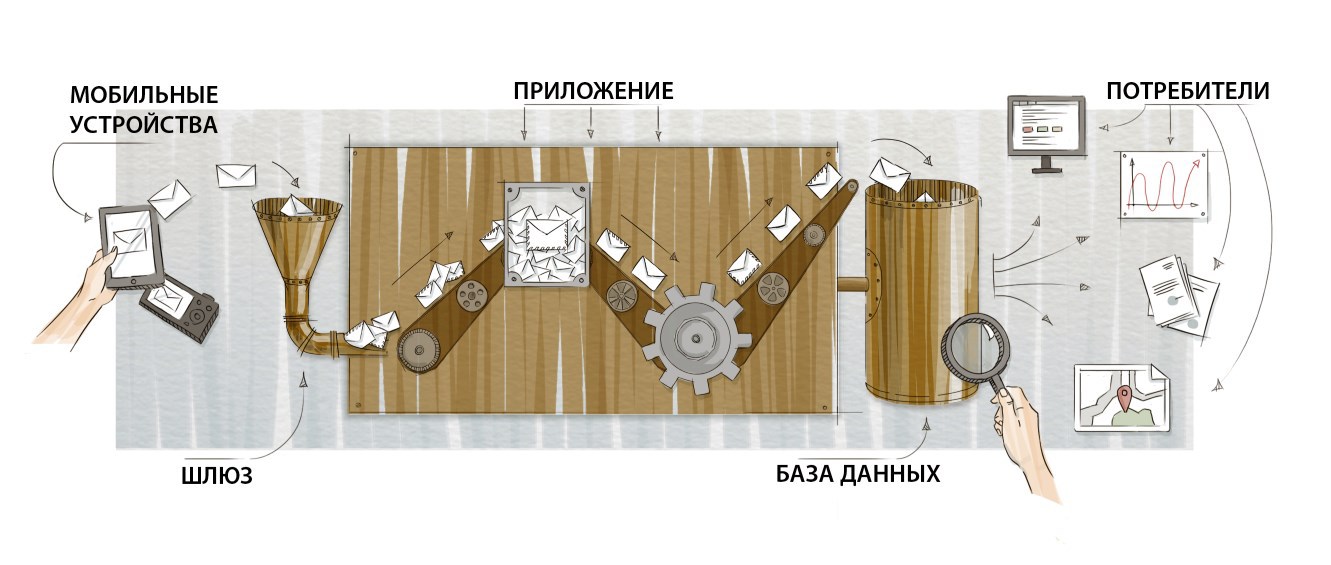
По каналам связи устройства присылают сообщения на наш шлюз (gateway) – входную точку приложения. Задача приложения – разобраться, что именно пришло, произвести необходимые действия и сохранить информацию в базе данных для дальнейшего анализа. Базу мы будем рассматривать как конечную точку обработки. Звучит просто, но с ростом количества и разнообразия сообщений появляется несколько нюансов, которые я и хочу обсудить.
Немного про уровень нагрузки. Наша система обрабатывает сообщения от десятков тысяч устройств, при этом за секунду в среднем мы получаем от нескольких сотен до тысячи сообщений. Если ваши числа отличаются на пару порядков в ту или иную сторону, возможно, набор ваших проблем и подходов к их решению будет другим.
Кроме собственно числа сообщений в секунду, существует проблема их неравномерного получения. Приложение должно быть готово к коротким пикам нагрузки в десятки раз выше среднего. Для решения этой задачи система организуется в виде набора очередей и их обработчиков.
Приемный шлюз не делает никакой реальной работы – он просто получает сообщение от клиента и помещает его в очередь. Это очень дешевая операция, поэтому шлюз способен получать огромное количество сообщений в секунду. Затем, существует отдельный процесс, который получает из очереди несколько сообщений – ровно столько, сколько он хочет и может – и делает тяжелую работу. Обработка получается асинхронной, а нагрузка – стабильно ограниченной. Возможно, в пике слегка вырастет время пребывания сообщений в очереди, вот и все.
Зачастую, обработка сообщения нетривиальна и состоит из нескольких действий. Следующий логичный шаг – разбить работу на несколько этапов: несколько очередей и обработчиков. При этом физически разные очереди и обработчики могут располагаться на разных серверах, каждый из которых можно настраивать и масштабировать под его конкретную задачу:
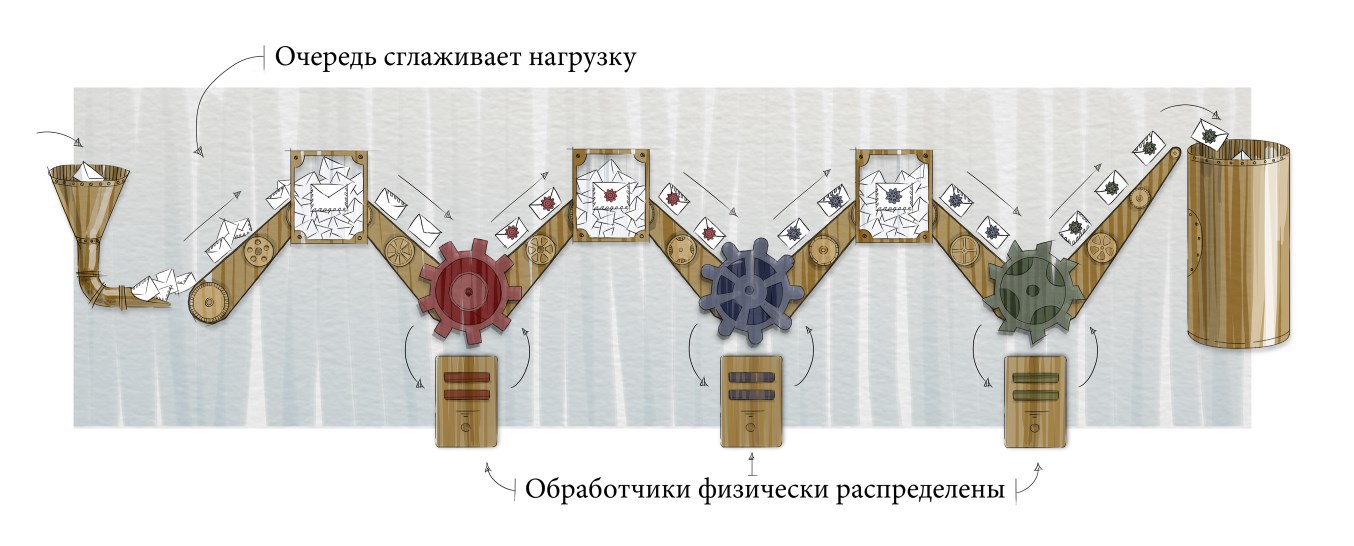
Первая очередь содержит сообщения в том виде, в котором они поступили от устройства. Обработчик декодирует их и помещает во вторую очередь. Второй обработчик может, например, производить некую агрегацию и создавать информацию, интересную для бизнеса, а третий обработчик – сохранять её в базу данных.
Таков базовый расклад, о чем же еще надо подумать?
Определяемся с ценностями
1. Простота создания, изменения и поддержки
Асинхронная распределённая обработка сообщений привносит в программный продукт дополнительную сложность. Мы постоянно работаем над снижением этой цены. Код оптимизируется, в первую очередь, в сторону повышения читаемости, понятности для всех членов команды, простоты изменения и поддержки. Если в итоге никто кроме автора не сможет разобраться в коде, никакая великолепная архитектура не поможет сделать команду счастливой.
Тезис кажется простым, но нам потребовалось достаточно много времени, прежде чем мы не просто озвучили этот принцип, но и стали стабильно и постоянно применять его в ежедневной работе. Мы стараемся постоянно делать рефакторинг, если чувствуем, что код можно сделать чуть лучше и проще. Все исходники проходят ревью, а наиболее критические части обычно разрабатываются в паре.
2. Отказоустойчивость
Имеет смысл сразу определиться относительно требований к способности системы продолжать функционировать при возникновении отказов оборудования и подсистем. У всех они будут разными. Возможно, кто-то готов просто выбросить все сообщения за те 5 минут, что один из серверов перезагружается.
В нашей системе мы не хотим терять сообщения. Если какой-то сервис недоступен, вызов к базе заканчивается таймаутом, или происходит случайная ошибка в обработке, это не должно закончиться потерей информации от устройств. Зависимые сообщения должны сохраниться в очереди и будут обработаны сразу после устранения проблемы.
Допустим, ваш код на одном сервере синхронно вызывает веб сервис на другом сервере. Если второй сервер недоступен, обработка закончится ошибкой, а вы сможете разве что залогировать ее. При асинхронной обработке сообщение будет дожидаться, когда второй сервер вернется в рабочее состояние.
3. Производительность
Число сообщений, обрабатываемых в единицу времени, задержки, нагрузки на сервера — всё это важные параметры производительности системы. Именно поэтому мы закладываем в проект гибкую архитектуру.
Однако, не зацикливайтесь на оптимизации с самого начала. Обычно подавляющая часть проблем с производительностью создается относительно небольшими кусками кода. К сожалению, мало кто способен заранее предсказать где именно будут эти проблемы. Вот тут люди пишут целые книги о преждевременной оптимизации. Убедитесь, что ваша архитектура позволяет быстро настраивать систему и забудьте об оптимизации до первых нагрузочных тестов.
В то же время, нагрузочные тесты нужно начинать делать рано, а затем сделать их частью стандартной процедуры тестирования. И только тогда, когда тесты покажут конкретную проблему, беритесь за оптимизацию.
Настраиваем мозг
1. Оперируйте очередями и асинхронными обработчиками
Об этом я уже писал выше. Наш основной инструментарий — очереди и их обработчики. В дополнение к классическому стилю организации кода «получил запрос, вызвал удаленный код, дождался ответа, вернул ответ наверх», мы получаем подход «получил сообщение из очереди, отработал, отправил сообщение в другую очередь». От того, насколько удачный баланс в сочетании двух подходов вы найдете, зависит как масштабируемость, так и простота разработки системы.
2. Разбивайте обработку на несколько этапов
Если обработка сообщения достаточно сложна и может быть разбита на несколько этапов, предусмотрите несколько очередей и обработчиков. Имейте в виду, что излишняя фрагментация может сделать систему более сложной для понимания. Тут нужен баланс. Достаточно часто существует разбиение, естественное и понятное для разработчиков. Если нет, то попробуйте подумать о точках отказа. Если обработчик может завершиться ошибкой по нескольким независимым причинам, можно подумать о его разбиении.
3. Не смешивайте декодирование и обработку
Обычно, сообщение приходит в формате какого-то протокола взаимодействия устройств в сети: бинарном, xml, json и т.д. Декодируйте и переводите их в свой внутренний формат как можно раньше. Это позволит решить минимум две задачи. Во-первых, протоколов может быть несколько; после декодирования вы сможете унифицировать формат дальнейших сообщений. Во-вторых, упрощается логирование и отладка.
4. Сделайте изменение конфигурации очередей легким
Структурируйте код обработки таким образом, чтобы вы могли легко поменять конфигурацию очередей. Разбиение обработчика на два не должно приводить к туче рефакторинга. Не позволяйте вашему коду зависеть слишком сильно от конкретной реализации очередей, завтра вы можете захотеть изменить ее.
5. Обрабатывайте сообщения группами
Зачастую имеет смысл получать сообщения из очереди не по одному, а сразу группами. Используемые вами сервисы могут принимать массив данных для пакетной обработки, в таком случае один большой вызов обычно будет намного эффективней ста маленьких. Вставка сотни записей в базу за один раз будет быстрее ста удаленных вызовов.
Создаем инструменты
1. Реализуйте тотальное наблюдение
Вкладывайтесь в мониторинг с самого начала. Вы должны легко и наглядно видеть график пропускной способности, среднего времени обработки, текущий размер очереди, время с последнего сообщения с разбивкой по очередям.
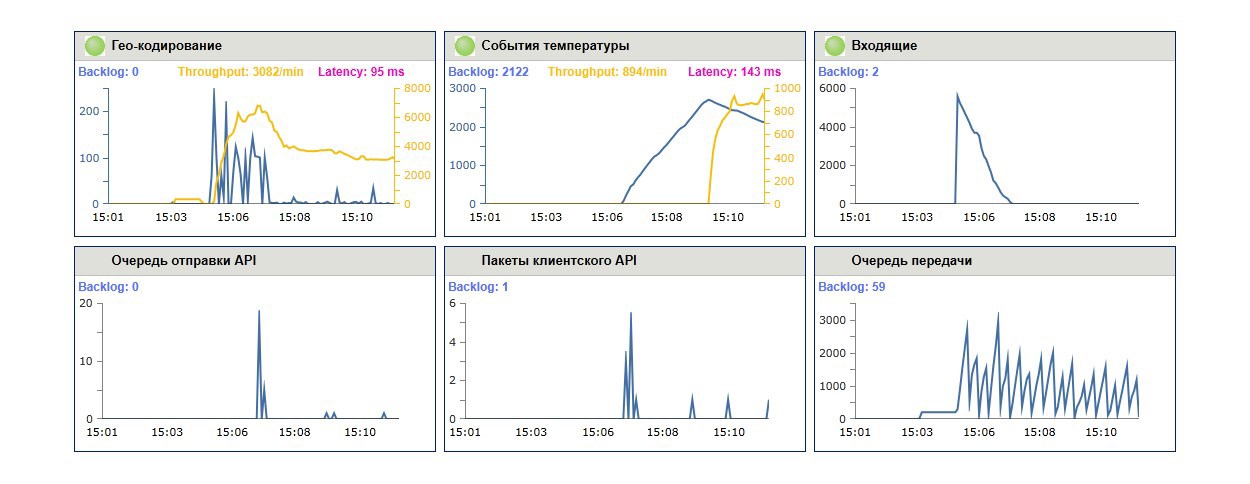
Мы используем мониторинг не только в боевом окружении, но и в тестовом, и даже на машинах разработчиков. Правильно настроенные графики и уведомления весьма полезны при отладке и предварительном нагрузочном тестировании.
2. Тестируйте всё
Системы обработки сообщений — идеальный полигон для автоматизированного тестирования. Протокол входных данных определен и ограничен, никаких взаимодействий с живыми людьми. Покрывайте код модульными тестами. Предусмотрите возможность заменить боевые очереди на тестовые очереди в локальной памяти и делайте быстрые тесты взаимодействия обработчиков. Наконец, делайте полноценные интеграционные тесты, которые можно гонять в бета (staging) окружении (а лучше и в продукции).
3. Заведите отстойник для ошибочных сообщений
Чаще всего, вы не захотите, чтобы ошибка обработки одного сообщения остановила всю очередь. Не менее важна возможность диагностировать ошибку. Помещайте такие сообщения в специальное хранилище и нацельте на это хранилище все свои прожекторы. Предусмотрите возможность с легкостью переместить сообщение обратно в очередь обработки как только причина ошибки устранена.
Этот же или похожий механизм можно использовать для хранения сообщений, которые должны быть обработаны не раньше какого-то момента в будущем. Мы держим их в отстойнике и периодически проверяем, не настал ли час Ч.
4. Автоматизируйте развертывание
Установка и обновление системы должна происходить в один или несколько кликов. Стремитесь к частым обновлениям на продукции, в идеале — автоматическому развертыванию после каждого коммита в master ветку. Установочный скрипт поможет разработчикам поддерживать их личную среду, а также среды тестирования в актуальном состоянии.
Вместо заключения
Хорошая понятная архитектура – это еще и способ упрощения коммуникации разработчиков, их общее видение и набор понятий. В этом смысле нам очень помогло формулирование метафоры системы в виде картинки, с которой можно начинать многие обсуждения в проекте.
Наша метафора похожа на вот эту картинку из статьи дядюшки Боба The Clean Architecture:
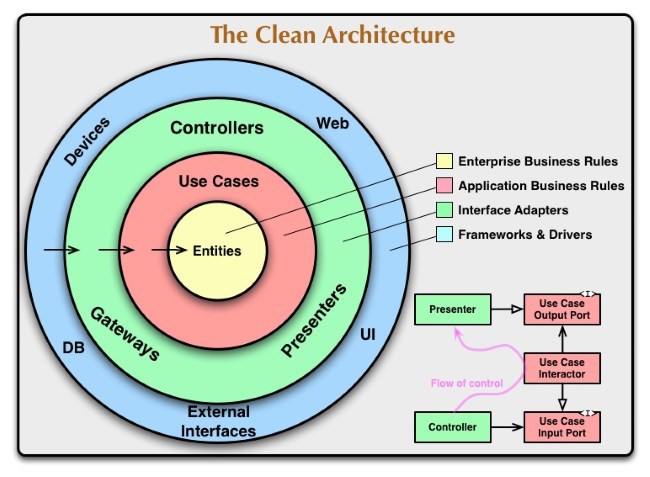
На нашей схеме мы обозначаем сущности системы и их зависимости, что помогает в дискуссии приблизиться к правильному дизайну, найти ошибки или запланировать рефакторинг.
