Comments 26
Сложилось мнение, что авторы библиотек для STM32 прилагают максимум усилий для запутывания своего кода. Одних только макросов, вызывающих макросы, которые вызывают макросы можно насчитать десятки. Это ужасно.
А вы пробовали поменять константу, задающую размер буфера посылки, с 64 на 128? У меня этот фокус сработал и удалось получить (посылая ZLP после каждого пакета), скорость в 128 000 байт/сек.
А вы пробовали поменять константу, задающую размер буфера посылки, с 64 на 128? У меня этот фокус сработал и удалось получить (посылая ZLP после каждого пакета), скорость в 128 000 байт/сек.
макросов, вызывающих макросы, которые вызывают макросы можно насчитать десятки
Вряд ли они это делают специально. Сложно также представить организацию работ, при которой это возникает в результате взаимодействия разных разработчиков, если только речь не идет о какой-то глобальной софтверной корпорации наподобие Microsoft. Может быть, есть какая-то среда, в которой все это генерируется автоматически? И писать в ней программы для STM32 легко и просто. :)
Буфер там по умолчанию вообще большой — около 2k, скорость не мерил пока
Я именно о размере блока, передаваемого внутри одного пакета по USB. Это строка 55 файла usbd_conf.h
#define CDC_DATA_MAX_PACKET_SIZE 64
Я думаю, если в fifo передатчика записать 128 байт, то они будут отправлены двумя пакетами
Почему? Судя по какой-то доке дата пакеты могут быть длинной 1024 байта за пакет. Другое дело, что неведомо как это реализовано в CDC, если я правильно понимаю CDC — это типа ком-порт виртуальный? Если Control Transfer'ами пулять — должно 1024 проскакивать за пакет?
Специально проверил при помощи wireshark — пересылается 128 байт в кадре:
Сценарий — устройство шлет поток uint32, каждое последующее на 1 больше предыдущего.
Компьютер их читает и сравнивает со своим счетчиком.
Первая колонка- сколько блоков по 128 прочитано, вторая — сколько сошлось, третья — скорость байт/сек.
Скриншот wireshark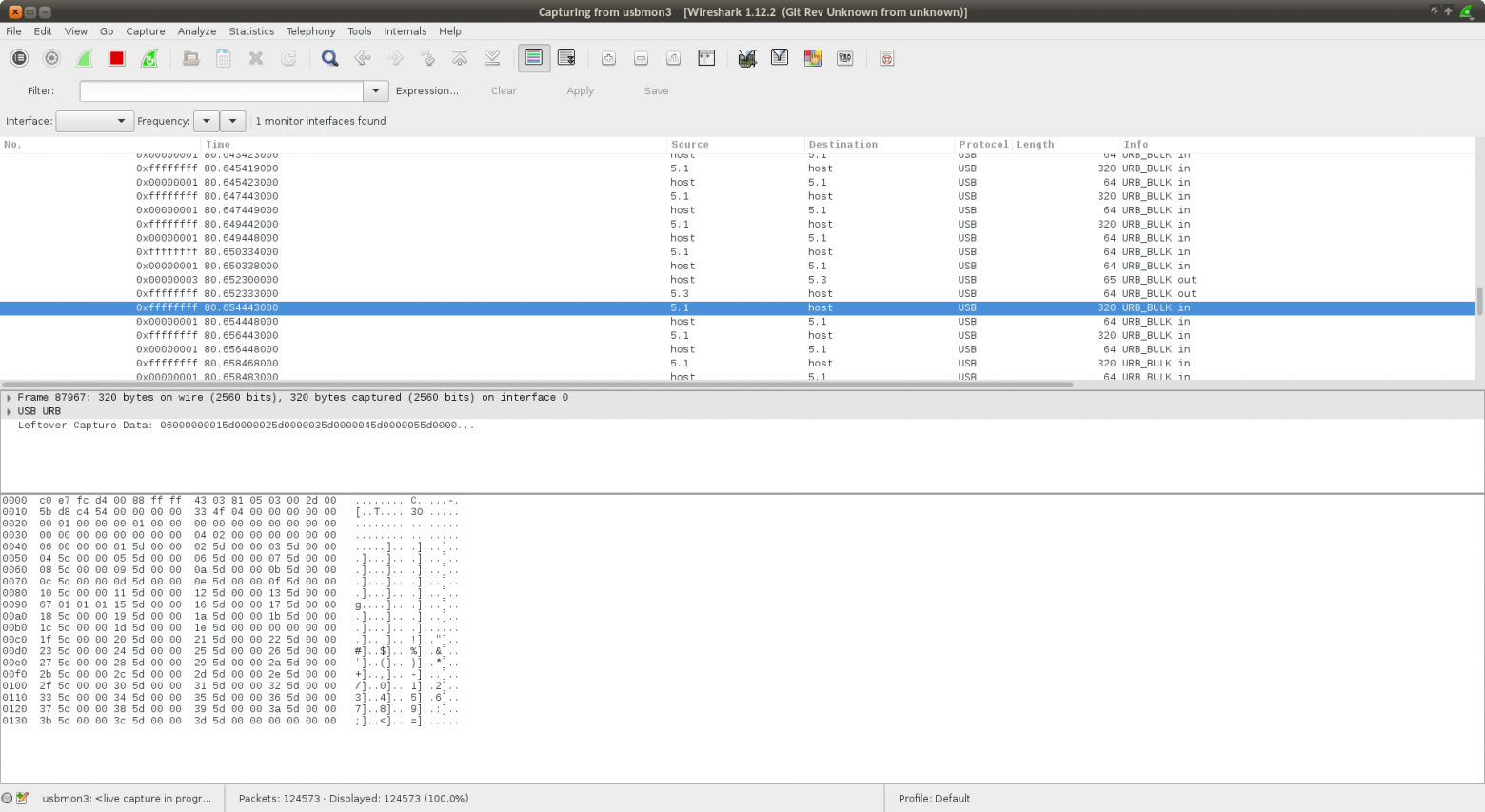

Сценарий — устройство шлет поток uint32, каждое последующее на 1 больше предыдущего.
Компьютер их читает и сравнивает со своим счетчиком.
Статистика
7 7 128000
6 6 112000
7 7 128000
6 6 112000
6 6 112000
7 7 128000
7 7 146286
6 6 112000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 128000
7 7 128000
6 6 112000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
6 6 112000
7 7 128000
7 7 128000
6 6 112000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 128000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
6 6 112000
7 7 128000
7 7 128000
6 6 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 128000
7 7 146286
6 6 112000
7 7 128000
6 6 112000
6 6 112000
7 7 128000
7 7 146286
6 6 112000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 128000
7 7 128000
6 6 112000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
6 6 112000
7 7 128000
7 7 128000
6 6 112000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 128000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
6 6 112000
7 7 128000
7 7 128000
6 6 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 128000
6 6 112000
7 7 128000
6 6 112000
7 7 128000
6 6 128000
7 7 146286
Первая колонка- сколько блоков по 128 прочитано, вторая — сколько сошлось, третья — скорость байт/сек.
Спасибо за ссылку, отличная дока. Теоретически да, за кадр можно передать до килобайта. Наверное стоит так и делать, чтобы скорость поднять. Но в стандарте размер ограничен гораздо меньшими значениями видимо, чтобы за кадр больше одного устройства смогло передать свои данные. Тут в разделе Bulk transfer пишут следующее:
For full speed endpoints, the maximum bulk packet size is either 8, 16, 32 or 64 bytes long. For high speed endpoints, the maximum packet size can be up to 512 bytes long
For full speed endpoints, the maximum bulk packet size is either 8, 16, 32 or 64 bytes long. For high speed endpoints, the maximum packet size can be up to 512 bytes long
Вы пробовали на STM32F407 запустить одновременно и независимо оба USB?
А то руки не дошли: с libopencm3 еще не пробовал, а STM'овский SPL — такой жестокий быдлокод, что трех дней исправления ошибок не хватило для полноценной работы USB.
Кстати, даже сами STM согласились, что SPL — быдлокод. И рекомендуют вместо этого использовать другой быдлокод — HAL. Судя по огрызкам примеров, разницы особой нет. Тоже код для мигания светодиодиком будет в пару килобайт разворачиваться.
А то руки не дошли: с libopencm3 еще не пробовал, а STM'овский SPL — такой жестокий быдлокод, что трех дней исправления ошибок не хватило для полноценной работы USB.
Кстати, даже сами STM согласились, что SPL — быдлокод. И рекомендуют вместо этого использовать другой быдлокод — HAL. Судя по огрызкам примеров, разницы особой нет. Тоже код для мигания светодиодиком будет в пару килобайт разворачиваться.
Нет, второй не пробовал.
Второй (hal/cube) по первым ощущениям получше. Надеюсь, что он будет более портируем между семействами.
Тот же шлак.
Лучше по-минимуму чужие библиотеки использовать. И вместо STM'овских брать opencm3. А в мелочах стараться только на регистрах все делать, напрямую: все равно быстрей почитать даташит и выяснить, что с каким регистром надо делать, чем бродить по коду той же opencm3, копипастить нужные функции и вычищать мусор! А мусор вычищать придется, как только нужно будет какую-нибудь критическую секцию написать или если возникнет проблема с размером кода.
Лучше по-минимуму чужие библиотеки использовать. И вместо STM'овских брать opencm3. А в мелочах стараться только на регистрах все делать, напрямую: все равно быстрей почитать даташит и выяснить, что с каким регистром надо делать, чем бродить по коду той же opencm3, копипастить нужные функции и вычищать мусор! А мусор вычищать придется, как только нужно будет какую-нибудь критическую секцию написать или если возникнет проблема с размером кода.
Лучше по-минимуму чужие библиотеки использовать.Это только если говорить про hal. Тот же udp/ip стек я писал, но не вижу смысла не использовать uip или lwip, когда нужно работать с сетью.
Я предпочитаю оценивать с точки зрения соотношения имеющегося времени, ресурсов контроллера и трудозатрат на написание своего барахла. В случае spl я не видел экономии, а только переобертывание операций над теми же регистрами (плюс проверки аргументов). В таком раскладе требуется не только помнить, как настраивается/используется соответствующий модуль через регистры, но и помнить маппинг между spl и низкоуровневыми операциями. Такая абстракция ради абстракции, которая нафиг не нужна.
Не вижу я принципиальной разницы между
d = SPIx->DR; и d = SPI_I2S_ReceiveData(SPIx);, но второе добавляет оверхед как в плане дополнительного bl, так и с точки зрения восприятия кода.В случае cubef4 у меня пока не возникло сходного ощущения бесполезного оверхеда.
стараться только на регистрах все делать, напрямую: все равно быстрей почитать даташит и выяснить, что с каким регистром надо делать
И так всякий раз для нового МК? Безумству храбрых поем мы песню…
А еще вопрос — про CMSIS все забыли — вроде неплохая была идея?
Свои наработки использовать. Для одного семейства даже перерабатывать правильно написанный код почти не надо.
У меня вообще пунктик по этому поводу — ни строчки чужого кода без анализа, как он работает.
У меня вообще пунктик по этому поводу — ни строчки чужого кода без анализа, как он работает.
А стандартные библиотеки? А компилятор Вы тоже проверяете? А компоновщик? Или тут пунктик уже не срабатывает?
Мне все-таки представляется, что мы должны доверять тем, кто написал используемые нами программные модули, конечно, за исключением тех случаев, когда четко видим, что доверять нельзя.
Есть классная фраза «трансцедентное число в трансцедентной степени является трансцедентным, за исключением тех случаев, когда обратное либо очевидно, либо тривиально».
Мне все-таки представляется, что мы должны доверять тем, кто написал используемые нами программные модули, конечно, за исключением тех случаев, когда четко видим, что доверять нельзя.
Есть классная фраза «трансцедентное число в трансцедентной степени является трансцедентным, за исключением тех случаев, когда обратное либо очевидно, либо тривиально».
> И так всякий раз для нового МК?
Естественно. Можно подумать, вы с этим SPL тупо меняете в Makefile тип процессора (скажем, вместо -DSTM32F103 пишете -DSTM32F407) и у вас все работает!
Чушь! Все равно придется очень много переделывать.
Поэтому аппаратно-зависимые вещи я стараюсь в один-два файла запихивать и не мешать с логикой. В результате перенос на другую платформу элементарно пройдет: меняем define'ы в соответствии с распределением IO по ногам МК, меняем секции инициализации и define'ы работы с железяками, и все.
А CMSIS-то при чем? Там всего-то общие define'ы и обертки:
wc -l core_cm3.h
183 core_cm3.h
183 несчастных строчки!!!
Естественно. Можно подумать, вы с этим SPL тупо меняете в Makefile тип процессора (скажем, вместо -DSTM32F103 пишете -DSTM32F407) и у вас все работает!
Чушь! Все равно придется очень много переделывать.
Поэтому аппаратно-зависимые вещи я стараюсь в один-два файла запихивать и не мешать с логикой. В результате перенос на другую платформу элементарно пройдет: меняем define'ы в соответствии с распределением IO по ногам МК, меняем секции инициализации и define'ы работы с железяками, и все.
А CMSIS-то при чем? Там всего-то общие define'ы и обертки:
wc -l core_cm3.h
183 core_cm3.h
183 несчастных строчки!!!
А CMSIS-то при чем? Там всего-то общие define'ы и обертки
Вообще то ОЧЕНЬ сильное утверждение.
Идея CMSIS в том и состояла, чтобы создать прототипы аппаратно-независимых библиотек по работе с железом, то есть это очередной вариант HAL, но рекомендованный продавцом архитектуры. Другой вопрос, насколько идея была реализована, но от этого она хуже не становится.
И позволю с Вами не согласиться в главном —
Чушь! Все равно придется очень много переделыватьна мой взгляд, идеальный вариант, если Вы действительно меняете 1 строчку, где стоит указание компилятору и среде о типе используемого процессора, а код программы вообще не меняется. В принципе, было бы неплохо, если бы среда программирования сама определяла тип подключенного программируемого МК и выдавала предупреждение о несоответствии, но это уже экзотика.
Если вы меняете stm32f103 на stm32f107, то по большей части так и есть. Если же скачете на другое семейство (f4xx) — изменения будут. Это принципиально не отличается от того, что вы переезжаете с stm на lxp, например. Имена регистров и констант меняются, низкоуровневый код надо менять.
При этом стандартной практикой является вынесения прямой работы с аппаратной частью в отдельные файлы. Некий минимальный hal, вне зависимости от того, используете вы голый cmsis, адреса периферии напрямую, spl или cube (если говорить на примере stm32). Это тоже самое, что использовать libc вместо явного вызова syscall'ов.
При этом стандартной практикой является вынесения прямой работы с аппаратной частью в отдельные файлы. Некий минимальный hal, вне зависимости от того, используете вы голый cmsis, адреса периферии напрямую, spl или cube (если говорить на примере stm32). Это тоже самое, что использовать libc вместо явного вызова syscall'ов.
А еще вопрос — про CMSIS все забыли — вроде неплохая была идея?cmsis все используют. Тот же spl построен поверх оного.
Но cmsis довольно маленький. Базовая часть относится к самому ядру, отладке и nvic. Также в рамках cmsis поставляются тонны дефайнов для конкретных микроконтроллеров (базовые адреса участков памяти, адреса регистров и т. п.)
Но в рамках CMSIS были и библиотеки для работы с аппаратурой, по крайней мере в варианте, который я скачал, они есть.
То есть помимо базовой части есть и расширеная часть, так почему бы ее не использовать?
Другое дело, что я не очень верю в принципиальную возможность построения универсальной аппаратнонезависимой библиотеки, но я могу и ошибаться.
То есть помимо базовой части есть и расширеная часть, так почему бы ее не использовать?
Другое дело, что я не очень верю в принципиальную возможность построения универсальной аппаратнонезависимой библиотеки, но я могу и ошибаться.
Замечание по тексту: «разработчики USB стека» следует читать как «разработчики USB стека для STM32», а то сначала я отнес эти слова в адрес разработчиков USB и был слегка озадачен )
Да конечно, спасибо, поправил
Да, с STM бардак. Есть CUBE, есть несколько сред разработки. При том, в каждой среде есть своя копия стандартных библиотек и свои шаблоны проекта, т.е. возможность создать скелет кода, содержащий инициализацию периферии, векторов прерываний и главный цикл. В CUBE есть возможность настроить содержимое проекта, и указать для какой среды его генерировать. При том, структура кода, выдаваемого CUBE серьезно отличается от того, что получается при создании проекта по шаблону! И в том, что выдаёт CUBE разобраться гораздо сложнее.
Sign up to leave a comment.
Доработка USB-стека в микроконтроллерах STM32 и TivaC