Эта история начинается с публикации «Самый сложный кроссворд, составленный компьютером». В ней приведен один из самых сложных кроссвордов, составленных программой (см. ниже).

Я был уверен, что все кроссворды давным-давно генерируются программно и был несколько удивлен тем, что это может быть проблемой. Замечу, что речь идет именно о «канадских» кроссвордах, в которых каждое слово имеет пересечение с другим словом на каждой букве или очень близких к ним по сложности. В моей работе аналитика, не так много действительно сложных задач, поэтому мне стало интересно попробовать разработать алгоритм, который мог бы это сделать. Результат размышлений, подкрепленный программой для генерации кроссвордов, приводится в этой статье.
Для заполнения кроссворда всегда используется перебор. Мы ставим первое слово, затем все следующие, проверяя, чтобы буквы на пересечениях совпадали с буквами в словах, поставленных ранее. И так, пока все слова не будут поставлены. Казалось бы – нет ничего проще. Однако простой подсчет количества итераций подбора слов для кроссворда средней длины на 50 слов может изменить это мнение. Так, для установки любого слова, кроме первого, при наличии 1 000 слов соответствующей длины в базе и наличия всего одного заполненного ранее слова на пересечении, в среднем понадобится 1 000/33 = 30 итераций (нам, в среднем, нужно будет просмотреть 30 слов, прежде чем нам попадется слово, имеющее нужную букву на позиции заполненного ранее пересечения). При наличии более одного заполненного ранее слова-пересечения, это количество будет резко расти. Простой подсчет показывает, что для заполнения 50 слов, нам нужно выполнить 30^(50-1) итераций. Это миллиарды миллиардов итераций. Даже на современных компьютерах, это потребует дни и месяцы работы. И здесь на первое место выходит уже не собственно перебор, а алгоритм, который позволит сократить время генерации кроссворда на много порядков.
Сразу, «на берегу», мы должны принять то, что генерация кроссворда будет состоять из двух этапов:
Исходя из этого, я буду помечать решения, приведенные далее, к какому этапу они применимы.
Все опыты будут ставиться на кроссворде, приведенном на рисунке ниже.

Это далеко не самый сложный кроссворд, однако решения, актуальные для него, будут актуальны и для всех остальных кроссвордов. А небольшое количество слов гарантирует нам сравнительно быстрое получение результата.
И последнее. В статье будет опущено все, что касается генерации базы слов для программы. Эта часть «стоила» не менее 50% всего затраченного времени. Сейчас в базе более 158 тыс. слов, из которых более 125 тыс. являются уникальными. База в максимальной степени вычищена программным способом, однако все еще требует к себе внимания в ручном режиме. Я не стал каким либо способом закрывать или шифровать базу – она лежит открытая в текстовом виде и простейшем key-value формате. Вы можете удалить или добавить в ней слова, подкорректировать описания или полностью заменить своей (например, на другом языке).
Первое, что нужно определить – последовательность заполнения слов. Для этого имеются весьма простые и очевидные решения.
Решение № 1: Слова будут генерироваться в последовательности, зависящей в первую очередь, от их длины. Чем длиннее слово, тем больше у него может быть пересечений и тем труднее будет найти слово для установки. Напротив, самые короткие слова, длиной в 2 или 3 буквы, будут иметь минимальное количество пересечений и их максимально удобно подбирать на завершающем этапе генерации. Данное решение используется на этапе анализа.
Решение № 2: Из слов с одинаковой длиной, в первую очередь будут устанавливаться слова с наибольшей сложностью установки. Сложность установки – расчетный параметр, который показывает «насколько сложно будет подобрать значение в это слово» и «насколько большая будет цена ошибки, если слово подобрать не удастся». Понятно, что слова одинаковой длины, например, 5 букв, могут пересекаться как с одним словом, так и сразу с пятью, при этом сложность установки будет совершенно разная. Данное решение используется на этапе анализа.
Решение № 3: C учетом предыдущих решений, слова у нас расположены в такой последовательности, которая не гарантирует пересечение двух соседних слов между собой. Это означает, что если мы не нашли слово для установки, тогда нужно изменить не предыдущее слово, а одно из ранее установленных слов, которые пересекаются с этим словом и по сути задают для него условия подбора. Логично из всех ранее установленных слов-пересечений, заменить слово, установленное последним, чтобы откатиться на минимальное количество слов генерации. Данное решение используется на этапе генерации.
Если отследить установку слов в той последовательности, которая была определенна на основании решений № 1 и № 2, можно заметить, что установка некоторых слов образует локально независимые фрагменты. Посмотрите на рисунок ниже.

На рисунке цветами показана последовательность установки первых слов в сетку кроссворда в порядке, соответствующем известному «Каждый охотник желает знать, где сидит фазан». Первым будет установлено слово, помеченное красным. После него – слово, помеченное желтым и т.д. После установки всего 2-х слов в кроссворде образовался локальный фрагмент, помеченный голубым цветом.
Прежде, чем продолжить, определимся сначала с терминологией:
При появлении фрагмента возникает дилема – либо продолжить генерацию кроссворда в ранее определенной последовательности, либо сгенерировать сначала все слова фрагмента, чтобы проверить правильность установки стартового слова. Это одно из мест алгоритма, которое может критически влиять на его общую производительность и которое не имеет четкого логического решения.
Решение № 4: Для каждого устанавливаемого слова будет выполняться поиск фрагментов. Все слова, принадлежащие одному фрагменту будут иметь последовательную очередность установки, начиная от стартового слова, либо от первого слова фрагмента. Данное решение используется на этапе анализа.
В данный момент, часть алгоритма по изменению последовательности генерации слов фрагментов выглядит следующим образом:
Собственно на этом все – алгоритм для генерации кроссворда обычным перебором готов. При минимальной детализации, выглядит он следующим образом:
Проверено – он реально работает на сетках до среднего уровня сложности. Однако, по мере усложнения сетки кроссворда и увеличении количества слов, количество удачных попыток генерации, стремится к 0. Собственно, с этого момента и начинается самое интересное.
Первый вопрос, который приходит в голову – можно ли как-нибудь уменьшить количество откатов? Ведь каждый откат на несколько слов назад может стоить десятки и сотни тысяч итераций. Логически верным шагом становится добавление правил, которые уменьшают количество ошибок установки слов, вроде, не ставить мягкий или твердый знак в клетку, с которой начинается слово и т.д. Если не лезть глубоко, описать большинство этих правил для русского языка довольно просто, но есть проблема – они будут абсолютно бесполезны, например, для английского. Мне же хотелось сделать универсальный алгоритм, не зависящий от языка.
Размышления над этим вопросом привели к следующему: «как было бы хорошо, чтобы для каждого еще неустановленного слова, пересекающего текущее устанавливаемое слово, было гарантировано наличие вариантов для установки».
Так появилась идея использовать шаблоны, подобные команде LIKE в Transact-SQL. Шаблон – это символьная строка, по которой будет выполняться сравнение слов. Сам шаблон включает буквы и символы-шаблоны. Во время сравнения с шаблоном необходимо, чтобы буквы в точности совпадали с символами, указанными в строке. Символы-шаблоны могут совпадать с произвольными элементами символьной строки.
Решение № 5: Для каждого стартового слова будут рассчитываться шаблоны всех пересекающихся с ним слов. Стартовое слово должно иметь буквы строго из списка в шаблоне, соответствующего позиции буквы пересечения. Данное решение используется на этапе генерации.
Примеры шаблонов для слов из трех букв приведены ниже:
На примере последнего, читать шаблоны следует так: для слова из 3-х букв, у которого первые две буквы равны «ДО», в базе есть слова, у которых последняя буква равна одной из «Г К М Н».
Вернемся снова к фрагментам. Посмотрите на рисунок ниже.
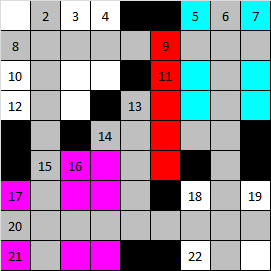
В нем серым отмечены клетки слов, установленных ранее. При установке слова, помеченного красным, образуются сразу два фрагмента, отмеченных голубым и фиолетовым цветами.
Если вы посмотрите на фиолетовый фрагмент, то увидите, что он связан со стартовым словом одним единственным пересечением. И это прекрасно! Это дает нам возможность воспользоваться еще одним решением.
Еще немного терминологии:
Решение № 6: При неудачной генерации фрагмента, для которого стартовое слово является акселератором, алгоритм будет хранить список букв, которые были установлены в стартовое слово на пересечении с одним из слов фрагмента для блокировки повторных установок слов, имеющих эти буквы на упомянутом пересечении. Данное решение используется на этапе генерации.
Алгоритм использования акселераторов приведен ниже.
Сначала – как это работает без акселератора:
Глубина фрагмента может быть достаточно большой и общее количество итераций для заполнения фрагмента может исчисляться миллионами. Для перебора всех возможных вариантов, нужно количество итераций для однократного заполнения фрагмента, умножить на количество слов в базе с длиной, как у стартового слова (которых могут быть десятки тысяч).
Как это работает с акселератором:
Глубина фрагмента та же. Однако, для перебора всех возможных вариантов, нужно количество итераций для заполнения фрагмента умножить уже не на количество вариантов для стартового слова, а всего на 33 (количество букв в алфавите).
Предыдущие решения, по сути исчерпали те 20% усилий, которые, согласно принципу Парето, дают нам 80% результата. Далее приходится использовать все более сложные подходы, с порой неясными перспективами.
Однажды, при генерации кроссворда, программа выдала такое сообщение: «Время полного перебора: 11 471 день …». Это сообщение появляется только в том случае, если был выполнен перебор всех вариантов для самого первого слова и требуется найти для него новое значение. Программа уже затраченное время просто умножает на оставшееся количество вариантов. Меня это позабавило и заставило задуматься, можно ли это время конвертировать в результат? Идея состоит в том, чтобы обдуманно обрезать некоторые варианты перебора, имеющие минимальную вероятность успеха.
Основной тезис этого решения – пусть лучше программа за минимально возможное время выдаст отрицательный результат (т.е. среди наиболее оптимальных вариантов подбор не удался), чем будет заниматься подбором столько времени, что будут превышены все мыслимые границы.
Решение № 7: При установке слова, которое пересекают слова с большой сложность установки, запрещено ставить на позицию упомянутого пересечения буквы, частота применения которых в словах пересечениях минимальна. Данное решение используется на этапе генерации.
Если по простому – это решение отбрасывает некоторое количество букв русского алфавита (иногда до 20), повышая шанс сгенерировать сложные участки из слов с чаще используемыми буквами (тут в шоколаде итальянский алфавит с его 21 буквой). В результате мы получим больше вариантов для подбора сложного в установке слова, когда до него дойдет очередь, а значит – больше шанс для успешной генерации всего кроссворда.
Есть и минусы – часть вариантов перебора будет безвозвратно потеряна. Возможно, именно среди них будет тот самый, единственно возможный вариант заполнения сетки. Только Вы можете получить его через 30 лет – нужно лишь немного подождать.
Еще одним минусом является то, что длинные слова, имеющие более 10 пересечений, сильнее всего и блокируются. Это приводит к тому, что программа не может начать генерацию, блокируя первое слово, пока для него не закончатся варианты. Обходится этот минус лишь частично, уменьшением степени блокировки, а значит и эффективности этого решения.
Для систематизации сеток по сложности генерации введен атрибут «Сложность генерации», который рассчитывается на основании количества слов, их длины и количества пересечений. По факту — более менее стабильно результат можно получать при сложности до 600 единиц. Все что выше — на удачу.
Ниже показано среднее время генерации на 10 попытках для нескольких сеток, расположенных в порядке возрастания сложности генерации.
Несложная тестовая сетка для опытов, с небольшим количеством слов.
Подитог: Сетки такой сложности генерируются быстро и стабильно.

Это сетка посложнее. Это маленький «канадский» кроссворд, где все слова имеют пересечения на всех буквах.
Подитог: Сетки такой сложности в большинстве случаев генерируются довольно быстро, однако, иногда генерация может затянуться на 10 минут и более.

Эта довольно сложная сетка оказалась весьма «удобной» для генерации.
Подитог: Благодаря тому что эта сетка очень хорошо фрагментируется и пересечения имеются не на всех буквах длинных слов, программа генерирует его почти мгновенно.

А вот эта сетка уже имеет «целевую» сложность. Это полноценный «канадский» кроссворд, правда, далеко не самый сложный.
Подитог: Программа справилась! Успешный результат генерации, в самом крайнем случае, можно получить всего за 17 минут. Среднее время генерации чуть более 4 минут.
И, наконец – тот, самый сложный кроссворд, с которого все началось. В нем 72 слова, что не так уж и много. Однако, сложность генерации получилась очень высокой. Основной проблемой для генерации являются четыре самых длинных слова, с которыми пересекаются почти все остальные слова кроссворда. Они как кости скелета, на которые нужно нанизать все остальные слова. Откаты отбрасывает процесс генерации почти на самое начало. Таким образом, процесс генерации этой сетки можно сравнить с Сизифом, толкающим камень в гору. И каждый раз, когда до цели остается совсем немного, камень скатывается к самому началу пути.
Увы – эта вершина осталась непокоренной! Я запускал несколько генераций с разными настройками, с лимитом по длительности до 10 часов, однако ни одна из них не была завершена успешно. Времени явно не хватает. Кто знает, может быть эта непокоренная вершина вдохновит кого-нибудь на новый штурм!
И все-таки да! Генерация кроссворда, даже для самых современных компьютеров, является сложной задачей. Я уверен, что возможности улучшить этот алгоритм далеко не исчерпаны, однако, независимо от возможностей алгоритма и мощности компьютера, всегда можно усложнить сетку кроссворда еще чуть-чуть, чтобы программа пообещала Вам результат, лет, через 20-30.
Надеюсь, вам было интересно, и вы дочитали до конца.

Я был уверен, что все кроссворды давным-давно генерируются программно и был несколько удивлен тем, что это может быть проблемой. Замечу, что речь идет именно о «канадских» кроссвордах, в которых каждое слово имеет пересечение с другим словом на каждой букве или очень близких к ним по сложности. В моей работе аналитика, не так много действительно сложных задач, поэтому мне стало интересно попробовать разработать алгоритм, который мог бы это сделать. Результат размышлений, подкрепленный программой для генерации кроссвордов, приводится в этой статье.
Для заполнения кроссворда всегда используется перебор. Мы ставим первое слово, затем все следующие, проверяя, чтобы буквы на пересечениях совпадали с буквами в словах, поставленных ранее. И так, пока все слова не будут поставлены. Казалось бы – нет ничего проще. Однако простой подсчет количества итераций подбора слов для кроссворда средней длины на 50 слов может изменить это мнение. Так, для установки любого слова, кроме первого, при наличии 1 000 слов соответствующей длины в базе и наличия всего одного заполненного ранее слова на пересечении, в среднем понадобится 1 000/33 = 30 итераций (нам, в среднем, нужно будет просмотреть 30 слов, прежде чем нам попадется слово, имеющее нужную букву на позиции заполненного ранее пересечения). При наличии более одного заполненного ранее слова-пересечения, это количество будет резко расти. Простой подсчет показывает, что для заполнения 50 слов, нам нужно выполнить 30^(50-1) итераций. Это миллиарды миллиардов итераций. Даже на современных компьютерах, это потребует дни и месяцы работы. И здесь на первое место выходит уже не собственно перебор, а алгоритм, который позволит сократить время генерации кроссворда на много порядков.
На дорожку…
Сразу, «на берегу», мы должны принять то, что генерация кроссворда будет состоять из двух этапов:
- Анализ – создание плана генерации, основным результатом которого является определенная последовательность генерации слов кроссворда и другие данные, которые будут помогать на этапе генерации.
- Генерация – последовательное заполнение сетки кроссворда словами, методом полного перебора всех возможных вариантов, с учетом данных, полученных на этапе анализа.
Исходя из этого, я буду помечать решения, приведенные далее, к какому этапу они применимы.
Все опыты будут ставиться на кроссворде, приведенном на рисунке ниже.

Это далеко не самый сложный кроссворд, однако решения, актуальные для него, будут актуальны и для всех остальных кроссвордов. А небольшое количество слов гарантирует нам сравнительно быстрое получение результата.
И последнее. В статье будет опущено все, что касается генерации базы слов для программы. Эта часть «стоила» не менее 50% всего затраченного времени. Сейчас в базе более 158 тыс. слов, из которых более 125 тыс. являются уникальными. База в максимальной степени вычищена программным способом, однако все еще требует к себе внимания в ручном режиме. Я не стал каким либо способом закрывать или шифровать базу – она лежит открытая в текстовом виде и простейшем key-value формате. Вы можете удалить или добавить в ней слова, подкорректировать описания или полностью заменить своей (например, на другом языке).
Начало пути
Первое, что нужно определить – последовательность заполнения слов. Для этого имеются весьма простые и очевидные решения.
Решение № 1: Слова будут генерироваться в последовательности, зависящей в первую очередь, от их длины. Чем длиннее слово, тем больше у него может быть пересечений и тем труднее будет найти слово для установки. Напротив, самые короткие слова, длиной в 2 или 3 буквы, будут иметь минимальное количество пересечений и их максимально удобно подбирать на завершающем этапе генерации. Данное решение используется на этапе анализа.
Решение № 2: Из слов с одинаковой длиной, в первую очередь будут устанавливаться слова с наибольшей сложностью установки. Сложность установки – расчетный параметр, который показывает «насколько сложно будет подобрать значение в это слово» и «насколько большая будет цена ошибки, если слово подобрать не удастся». Понятно, что слова одинаковой длины, например, 5 букв, могут пересекаться как с одним словом, так и сразу с пятью, при этом сложность установки будет совершенно разная. Данное решение используется на этапе анализа.
Решение № 3: C учетом предыдущих решений, слова у нас расположены в такой последовательности, которая не гарантирует пересечение двух соседних слов между собой. Это означает, что если мы не нашли слово для установки, тогда нужно изменить не предыдущее слово, а одно из ранее установленных слов, которые пересекаются с этим словом и по сути задают для него условия подбора. Логично из всех ранее установленных слов-пересечений, заменить слово, установленное последним, чтобы откатиться на минимальное количество слов генерации. Данное решение используется на этапе генерации.
Фрагменты
Если отследить установку слов в той последовательности, которая была определенна на основании решений № 1 и № 2, можно заметить, что установка некоторых слов образует локально независимые фрагменты. Посмотрите на рисунок ниже.
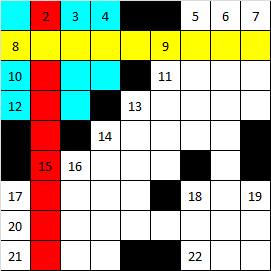
На рисунке цветами показана последовательность установки первых слов в сетку кроссворда в порядке, соответствующем известному «Каждый охотник желает знать, где сидит фазан». Первым будет установлено слово, помеченное красным. После него – слово, помеченное желтым и т.д. После установки всего 2-х слов в кроссворде образовался локальный фрагмент, помеченный голубым цветом.
Прежде, чем продолжить, определимся сначала с терминологией:
- Фрагмент – группа слов в количестве от 1 слова до 50% от общего количества слов кроссворда, генерация которых никак не зависит от всех остальных, еще не поставленных слов.
- Стартовое слово – слово, после установки которого образовался фрагмент (на рисунке выше – это слово, выделенное желтым цветом).
- Первое слово – слово фрагмента, имеющее минимальную очередность установки из всех слов фрагмента.
- Глубина фрагмента – количество слов, составляющих фрагмент.
При появлении фрагмента возникает дилема – либо продолжить генерацию кроссворда в ранее определенной последовательности, либо сгенерировать сначала все слова фрагмента, чтобы проверить правильность установки стартового слова. Это одно из мест алгоритма, которое может критически влиять на его общую производительность и которое не имеет четкого логического решения.
Решение № 4: Для каждого устанавливаемого слова будет выполняться поиск фрагментов. Все слова, принадлежащие одному фрагменту будут иметь последовательную очередность установки, начиная от стартового слова, либо от первого слова фрагмента. Данное решение используется на этапе анализа.
В данный момент, часть алгоритма по изменению последовательности генерации слов фрагментов выглядит следующим образом:
- Находим фрагменты.
- Определяем сложность заполнения фрагмента.
- Определяем слово, за которым нужно расположить все слова фрагмента по следующим правилам:
- Слова, являющиеся членами фрагментов, устанавливаем друг за другом.
Собственно на этом все – алгоритм для генерации кроссворда обычным перебором готов. При минимальной детализации, выглядит он следующим образом:
- Определяется последовательность генерации слов.
- Выполняется подбор и установка слова с учетом ранее установленных слов.
- При отсутствии слова для установки, выполняется откат на последнее пересекающееся с ним слово, поиск которого продолжается так, как будто предыдущее его значение не было найдено вовсе.
Проверено – он реально работает на сетках до среднего уровня сложности. Однако, по мере усложнения сетки кроссворда и увеличении количества слов, количество удачных попыток генерации, стремится к 0. Собственно, с этого момента и начинается самое интересное.
Шаблоны
Первый вопрос, который приходит в голову – можно ли как-нибудь уменьшить количество откатов? Ведь каждый откат на несколько слов назад может стоить десятки и сотни тысяч итераций. Логически верным шагом становится добавление правил, которые уменьшают количество ошибок установки слов, вроде, не ставить мягкий или твердый знак в клетку, с которой начинается слово и т.д. Если не лезть глубоко, описать большинство этих правил для русского языка довольно просто, но есть проблема – они будут абсолютно бесполезны, например, для английского. Мне же хотелось сделать универсальный алгоритм, не зависящий от языка.
Размышления над этим вопросом привели к следующему: «как было бы хорошо, чтобы для каждого еще неустановленного слова, пересекающего текущее устанавливаемое слово, было гарантировано наличие вариантов для установки».
Так появилась идея использовать шаблоны, подобные команде LIKE в Transact-SQL. Шаблон – это символьная строка, по которой будет выполняться сравнение слов. Сам шаблон включает буквы и символы-шаблоны. Во время сравнения с шаблоном необходимо, чтобы буквы в точности совпадали с символами, указанными в строке. Символы-шаблоны могут совпадать с произвольными элементами символьной строки.
Решение № 5: Для каждого стартового слова будут рассчитываться шаблоны всех пересекающихся с ним слов. Стартовое слово должно иметь буквы строго из списка в шаблоне, соответствующего позиции буквы пересечения. Данное решение используется на этапе генерации.
Примеры шаблонов для слов из трех букв приведены ниже:
- Шаблон: "___"
- Буква № 1: Ё А Б В Г Д Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Э Ю Я
- Буква № 2: Ё А Б В Г Д Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ы Ь Э Ю Я
- Буква № 3: Ё А Б В Г Д Е Ж З И Й К Л М Н О П Р С Т У Ф Х Ц Ч Ш Щ Ы Ь Э Ю Я
- Шаблон: «ДО_»
- Буква № 1: Д
- Буква № 2: О
- Буква № 3: Г К М Н
На примере последнего, читать шаблоны следует так: для слова из 3-х букв, у которого первые две буквы равны «ДО», в базе есть слова, у которых последняя буква равна одной из «Г К М Н».
Акселераторы
Вернемся снова к фрагментам. Посмотрите на рисунок ниже.
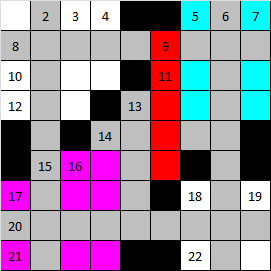
В нем серым отмечены клетки слов, установленных ранее. При установке слова, помеченного красным, образуются сразу два фрагмента, отмеченных голубым и фиолетовым цветами.
Если вы посмотрите на фиолетовый фрагмент, то увидите, что он связан со стартовым словом одним единственным пересечением. И это прекрасно! Это дает нам возможность воспользоваться еще одним решением.
Еще немного терминологии:
- Акселератор – стартовое слово, имеющее дочерний фрагмент, имеющий с ним одно единственное пересечение. Свое название он получил за свойство ускорять генерацию фрагментов на порядок и более.
Решение № 6: При неудачной генерации фрагмента, для которого стартовое слово является акселератором, алгоритм будет хранить список букв, которые были установлены в стартовое слово на пересечении с одним из слов фрагмента для блокировки повторных установок слов, имеющих эти буквы на упомянутом пересечении. Данное решение используется на этапе генерации.
Алгоритм использования акселераторов приведен ниже.
Сначала – как это работает без акселератора:
- Выполняется поиск и установка всех слов фрагмента.
- Если заполнение фрагмента выполнено успешно, то идем дальше, иначе – меняется стартовое слово и процесс заполнения слов фрагмента повторяется.
Глубина фрагмента может быть достаточно большой и общее количество итераций для заполнения фрагмента может исчисляться миллионами. Для перебора всех возможных вариантов, нужно количество итераций для однократного заполнения фрагмента, умножить на количество слов в базе с длиной, как у стартового слова (которых могут быть десятки тысяч).
Как это работает с акселератором:
- Выполняется поиск и установка слов фрагмента.
- Если заполнение фрагмента выполнено успешно, то идем дальше, иначе – запоминаем букву, стоящую на пересечении акселератора и слова фрагмента.
- Меняется слово, установленное на акселераторе, при этом новое слово не должно на упомянутом выше пересечении иметь буквы, которые были запомнены ранее.
Глубина фрагмента та же. Однако, для перебора всех возможных вариантов, нужно количество итераций для заполнения фрагмента умножить уже не на количество вариантов для стартового слова, а всего на 33 (количество букв в алфавите).
Динамическая балансировка сложностью установки
Предыдущие решения, по сути исчерпали те 20% усилий, которые, согласно принципу Парето, дают нам 80% результата. Далее приходится использовать все более сложные подходы, с порой неясными перспективами.
Однажды, при генерации кроссворда, программа выдала такое сообщение: «Время полного перебора: 11 471 день …». Это сообщение появляется только в том случае, если был выполнен перебор всех вариантов для самого первого слова и требуется найти для него новое значение. Программа уже затраченное время просто умножает на оставшееся количество вариантов. Меня это позабавило и заставило задуматься, можно ли это время конвертировать в результат? Идея состоит в том, чтобы обдуманно обрезать некоторые варианты перебора, имеющие минимальную вероятность успеха.
Основной тезис этого решения – пусть лучше программа за минимально возможное время выдаст отрицательный результат (т.е. среди наиболее оптимальных вариантов подбор не удался), чем будет заниматься подбором столько времени, что будут превышены все мыслимые границы.
Решение № 7: При установке слова, которое пересекают слова с большой сложность установки, запрещено ставить на позицию упомянутого пересечения буквы, частота применения которых в словах пересечениях минимальна. Данное решение используется на этапе генерации.
Если по простому – это решение отбрасывает некоторое количество букв русского алфавита (иногда до 20), повышая шанс сгенерировать сложные участки из слов с чаще используемыми буквами (тут в шоколаде итальянский алфавит с его 21 буквой). В результате мы получим больше вариантов для подбора сложного в установке слова, когда до него дойдет очередь, а значит – больше шанс для успешной генерации всего кроссворда.
Есть и минусы – часть вариантов перебора будет безвозвратно потеряна. Возможно, именно среди них будет тот самый, единственно возможный вариант заполнения сетки. Только Вы можете получить его через 30 лет – нужно лишь немного подождать.
Еще одним минусом является то, что длинные слова, имеющие более 10 пересечений, сильнее всего и блокируются. Это приводит к тому, что программа не может начать генерацию, блокируя первое слово, пока для него не закончатся варианты. Обходится этот минус лишь частично, уменьшением степени блокировки, а значит и эффективности этого решения.
Тестирование
Для систематизации сеток по сложности генерации введен атрибут «Сложность генерации», который рассчитывается на основании количества слов, их длины и количества пересечений. По факту — более менее стабильно результат можно получать при сложности до 600 единиц. Все что выше — на удачу.
Ниже показано среднее время генерации на 10 попытках для нескольких сеток, расположенных в порядке возрастания сложности генерации.
Сетка № 1
Несложная тестовая сетка для опытов, с небольшим количеством слов.
- Сложность генерации: 248
- Количество слов: 28
- Среднее время успешной генерации, сек.: 5 (от 1 до 32)
Подитог: Сетки такой сложности генерируются быстро и стабильно.
Сетка № 2

Это сетка посложнее. Это маленький «канадский» кроссворд, где все слова имеют пересечения на всех буквах.
- Сложность генерации: 372
- Количество слов: 34
- Среднее время успешной генерации, сек.: 62 (от 1 до 472)
Подитог: Сетки такой сложности в большинстве случаев генерируются довольно быстро, однако, иногда генерация может затянуться на 10 минут и более.
Сетка № 3

Эта довольно сложная сетка оказалась весьма «удобной» для генерации.
- Сложность генерации: 544
- Количество слов: 46
- Среднее время успешной генерации, сек.: 1 (от 1 до 2)
Подитог: Благодаря тому что эта сетка очень хорошо фрагментируется и пересечения имеются не на всех буквах длинных слов, программа генерирует его почти мгновенно.
Сетка № 4

А вот эта сетка уже имеет «целевую» сложность. Это полноценный «канадский» кроссворд, правда, далеко не самый сложный.
- Сложность генерации: 570
- Количество слов: 78
- Среднее время успешной генерации, сек.: 250 (от 10 до 989)
Подитог: Программа справилась! Успешный результат генерации, в самом крайнем случае, можно получить всего за 17 минут. Среднее время генерации чуть более 4 минут.
Сетка № 5
И, наконец – тот, самый сложный кроссворд, с которого все началось. В нем 72 слова, что не так уж и много. Однако, сложность генерации получилась очень высокой. Основной проблемой для генерации являются четыре самых длинных слова, с которыми пересекаются почти все остальные слова кроссворда. Они как кости скелета, на которые нужно нанизать все остальные слова. Откаты отбрасывает процесс генерации почти на самое начало. Таким образом, процесс генерации этой сетки можно сравнить с Сизифом, толкающим камень в гору. И каждый раз, когда до цели остается совсем немного, камень скатывается к самому началу пути.
Увы – эта вершина осталась непокоренной! Я запускал несколько генераций с разными настройками, с лимитом по длительности до 10 часов, однако ни одна из них не была завершена успешно. Времени явно не хватает. Кто знает, может быть эта непокоренная вершина вдохновит кого-нибудь на новый штурм!
Резюме
И все-таки да! Генерация кроссворда, даже для самых современных компьютеров, является сложной задачей. Я уверен, что возможности улучшить этот алгоритм далеко не исчерпаны, однако, независимо от возможностей алгоритма и мощности компьютера, всегда можно усложнить сетку кроссворда еще чуть-чуть, чтобы программа пообещала Вам результат, лет, через 20-30.
Надеюсь, вам было интересно, и вы дочитали до конца.
