Когда Алексей TheShade Шипилёв рассказывал про особенности поведения Java-строк с нулевым значением хэшкода, он приводил в качестве примера строку
Различных хэшкодов существует 232 — немногим более четырёх миллиардов, а слов в человеческом языке — порядка ста тысяч. Найти одно слово с нужным хэшкодом почти нереально, а вот сочетание из двух слов вполне можно. Если добавить ещё вариации вроде предлогов, то появится выбор.
Перебирать все возможные комбинации долго, но можно процесс оптимизировать, выполнив несложные преобразования над формулой хэшкода строки. Давайте напишем генератор словосочетаний с заданным хэшкодом. Писать будем на чистой Java 8, в модном нынче функциональном стиле.
Итак, формула хэшкода h от строки s, где l(s) — её длина, а s[i] — i-й символ:

Вычисления делаются по модулю 232, так как переполнение целого числа тут обычное дело. Заметим, что если у нас есть две строки s1 и s2 с известными хэшкодами, то хэшкод конкатенации этих строк будет равен
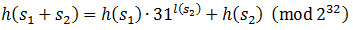
Тут уже наклёвывается алгоритм. Если мы хотим составить строку с заданным хэшкодом из двух частей, вторую часть можно подобрать так, чтобы она дополняла хэшкод до нужной величины. Придётся пробежаться по всем возможным длинам второй части, но это всё равно гораздо быстрее, чем перебирать все пары.
Будем генерировать словосочетания в таком виде:
Предлог с пробелами вокруг него или просто пробел назовём инфиксом. Первое слово будет s1, а инфикс и второе — s2. Базу слов возьмём, например, здесь (файл litf-win.txt). Файл выглядит примерно так:
Число нас не интересует, и мы его отрежем. Кроме того, выкинем слова короче трёх символов:
Предлоги набьём вручную:
Создадим список инфиксов: добавим пробелы вокруг предлогов и отдельный пробел:
Составим поток из всевозможных комбинаций инфиксов и слов (строки s2):
Теперь сформируем из этого потока ассоциативный массив (длина строки -> (хэшкод -> строка)). В Java 8 сделать это существенно проще, чем в предыдущих версиях:
Сделаем поток для s1 — слова с большой буквы (увы, готового метода для этого до сих пор нет):
Чтобы сопоставить s1 всевозможные варианты s2, можно воспользоваться
Обозначим целевой хэшкод за target. Тогда для каждой записи
Осталось склеить s1 и s2, отсортировать по алфавиту и вывести на консоль:
Вот и вся программа.
Программа отрабатывает секунд за десять и выдаёт больше сотни вариантов. Конечно, большинство из них грамматически не согласованы или просто скучны. Но неплохие тоже попадаются.
Итак, если вы хотите сделать доклад о том, что хэшкод для определённых строк каждый раз пересчитывается, его можно проиллюстрировать следующими примерами (target=0):
Если же вы собрались поведать коллегам, почему вредно вычислять
Поменяв значение target, вы можете нагенерировать словосочетания для любого другого хэшкода.
"лжеотождествление электровиолончели". Когда FindBugs предупреждает вас о проблемах с вычислением абсолютного значения хэшкода, равного Integer.MIN_VALUE, он приводит примеры строк, имеющих такой хэшкод — "polygenelubricants" или "DESIGNING WORKHOUSES". Откуда взялись эти примеры? Как самому составить красивую строку с заданным наперёд хэшкодом?Различных хэшкодов существует 232 — немногим более четырёх миллиардов, а слов в человеческом языке — порядка ста тысяч. Найти одно слово с нужным хэшкодом почти нереально, а вот сочетание из двух слов вполне можно. Если добавить ещё вариации вроде предлогов, то появится выбор.
Перебирать все возможные комбинации долго, но можно процесс оптимизировать, выполнив несложные преобразования над формулой хэшкода строки. Давайте напишем генератор словосочетаний с заданным хэшкодом. Писать будем на чистой Java 8, в модном нынче функциональном стиле.
Итак, формула хэшкода h от строки s, где l(s) — её длина, а s[i] — i-й символ:
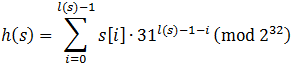
Вычисления делаются по модулю 232, так как переполнение целого числа тут обычное дело. Заметим, что если у нас есть две строки s1 и s2 с известными хэшкодами, то хэшкод конкатенации этих строк будет равен
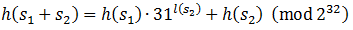
Тут уже наклёвывается алгоритм. Если мы хотим составить строку с заданным хэшкодом из двух частей, вторую часть можно подобрать так, чтобы она дополняла хэшкод до нужной величины. Придётся пробежаться по всем возможным длинам второй части, но это всё равно гораздо быстрее, чем перебирать все пары.
Будем генерировать словосочетания в таком виде:
"<Слово_с_большой_буквы> [<предлог/союз>] <слово_с_маленькой_буквы>"Предлог с пробелами вокруг него или просто пробел назовём инфиксом. Первое слово будет s1, а инфикс и второе — s2. Базу слов возьмём, например, здесь (файл litf-win.txt). Файл выглядит примерно так:
а 21715
аарона 2
ааронов 1
аб 1
аба 2
абажур 1
абажуром 7
...Число нас не интересует, и мы его отрежем. Кроме того, выкинем слова короче трёх символов:
List<String> words = Files.readAllLines(Paths.get("litf-win.txt"), Charset.forName("cp1251")).stream()
.map(s -> s.substring(0, s.indexOf(' ')))
.filter(s -> s.length() > 2)
.collect(Collectors.toList());Предлоги набьём вручную:
String[] preps = { "в", "и", "с", "по", "на", "под", "над", "от", "из",
"через", "перед", "за", "до", "о", "не", "или", "у", "про", "для" };Создадим список инфиксов: добавим пробелы вокруг предлогов и отдельный пробел:
List<String> infixes = Stream.concat(Stream.of(" "), Arrays.stream(preps).map(p -> ' '+p+' '))
.collect(Collectors.toList());Составим поток из всевозможных комбинаций инфиксов и слов (строки s2):
words.stream().flatMap(s -> infixes.stream().map((String infix) -> infix+s))Теперь сформируем из этого потока ассоциативный массив (длина строки -> (хэшкод -> строка)). В Java 8 сделать это существенно проще, чем в предыдущих версиях:
Map<Integer, Map<Integer, List<String>>> lenHashSuffix = words.stream()
.flatMap(s -> infixes.stream().map((String infix) -> infix+s))
.collect(Collectors.groupingBy(String::length, Collectors.groupingBy(String::hashCode)));Сделаем поток для s1 — слова с большой буквы (увы, готового метода для этого до сих пор нет):
words.stream().map(s -> Character.toTitleCase(s.charAt(0)) + s.substring(1))Чтобы сопоставить s1 всевозможные варианты s2, можно воспользоваться
flatMap. Осталось перебрать все длины из lenHashSuffix, вычислить подходящий хэшкод для s2 и извлечь строки с этим хэшкодом. Тут возникает вопрос: как для данной длины len вычислить h(s1)·31len? Метод Math.pow не подойдёт: он работает с дробными числами. Можно было бы написать цикл for, но это же несовременно! К счастью, у нас есть reduce!int hash = IntStream.range(0, len).reduce(s.hashCode(), (a, i) -> a*31);Обозначим целевой хэшкод за target. Тогда для каждой записи
entry из lenHashSuffix поток устраивающих нас строк s2 можно получить так:entry.getValue().getOrDefault(
target - IntStream.range(0, entry.getKey()).reduce(s.hashCode(), (a, i) -> a*31),
Collections.emptyList()).stream()Осталось склеить s1 и s2, отсортировать по алфавиту и вывести на консоль:
words.stream()
.map(s -> Character.toTitleCase(s.charAt(0)) + s.substring(1))
.flatMap(s -> lenHashSuffix.entrySet().stream()
.flatMap(entry -> entry.getValue().getOrDefault(
target - IntStream.range(0, entry.getKey()).reduce(s.hashCode(), (a, i) -> a*31),
Collections.emptyList()).stream().map(suffix -> s+suffix)))
.sorted().forEach(System.out::println);
Вот и вся программа.
Полный исходный текст
import java.nio.charset.Charset;
import java.nio.file.*;
import java.util.*;
import java.util.stream.*;
public class PhraseHashCode {
public static void main(String[] args) throws Exception {
int target = Integer.MIN_VALUE;
String[] preps = { "в", "и", "с", "по", "на", "под", "над", "от", "из",
"через", "перед", "за", "до", "о", "не", "или", "у", "про", "для" };
List<String> infixes = Stream.concat(Stream.of(" "), Arrays.stream(preps).map(p -> ' '+p+' '))
.collect(Collectors.toList());
List<String> words = Files.readAllLines(Paths.get("litf-win.txt"), Charset.forName("cp1251")).stream()
.map(s -> s.substring(0, s.indexOf(' ')))
.filter(s -> s.length() > 2)
.collect(Collectors.toList());
Map<Integer, Map<Integer, List<String>>> lenHashSuffix = words.stream()
.flatMap(s -> infixes.stream().map((String infix) -> infix+s))
.collect(Collectors.groupingBy(String::length, Collectors.groupingBy(String::hashCode)));
words.stream()
.map(s -> Character.toTitleCase(s.charAt(0)) + s.substring(1))
.flatMap(s -> lenHashSuffix.entrySet().stream()
.flatMap(entry -> entry.getValue().getOrDefault(
target - IntStream.range(0, entry.getKey()).reduce(s.hashCode(), (a, i) -> a*31),
Collections.emptyList()).stream().map(suffix -> s+suffix)))
.sorted().forEach(System.out::println);
}
}Результаты
Программа отрабатывает секунд за десять и выдаёт больше сотни вариантов. Конечно, большинство из них грамматически не согласованы или просто скучны. Но неплохие тоже попадаются.
Итак, если вы хотите сделать доклад о том, что хэшкод для определённых строк каждый раз пересчитывается, его можно проиллюстрировать следующими примерами (target=0):
"Бегавшая через бары"
"Издержки экономического"
"Почувствовалось под безотчетной"
"Принесенного в тридцатые"
"Пулею по должностному"
"Посмотрел про право"Если же вы собрались поведать коллегам, почему вредно вычислять
Math.abs от хэшкода, вам пригодятся такие строчки (target=Integer.MIN_VALUE):"Вельможи у сообщества"
"Объезд и интимное"
"Советовались и подождали"
"Отводит от ноздри"
"Рельсами через тяготенье"Поменяв значение target, вы можете нагенерировать словосочетания для любого другого хэшкода.
