Недавно у меня с коллегой вышла дискуссия — влияет ли объём данных на трудоёмкость разработки.
В сухом остатке осталось:
Для разработчика, прямо скажем, выводы получились не очень весёлые и однозначные.
Но дискуссия возникла не на пустом месте, а в рамках обсуждения задачи с простым вычислительным алгоритмом, но большим количеством данных.
Цель публикации — поделиться опытом как, за приемлемое время, обработать два связанных списка по миллиарду записей в каждом.
Представленные в публикации данные похожи на те, что были в оригинальной задаче. Изменения коснулись, в основном, прикладной терминологии. Назовём это «Учёт в муравейнике».
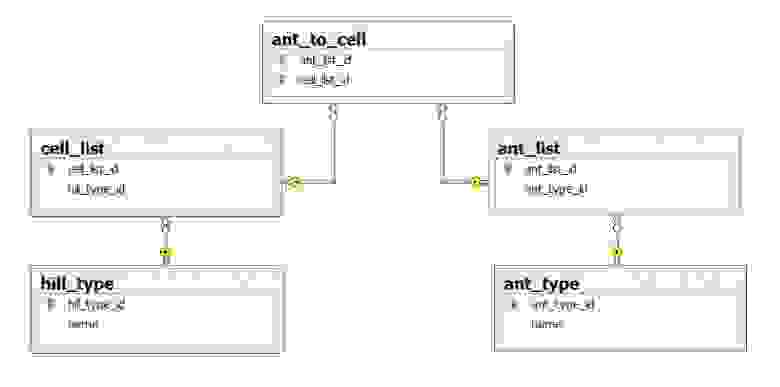
Структура данных показана на рисунке:
Задача состоит в том, чтобы для каждого района муравейника (hill_type) подготовить свой список проживающих в нём муравьёв (ant_list), определённого типа (ant_type) и с их номерами домов (cell_list).
Кому интересно, есть утилита для генерации тестовых данных. Утилита подготовлена в виде консольной программы, написанной на C# (Visual Studio Community 2013).
Код утилиты выложен на GitHub в файле anthill-makedata.cs. Для получения рабочей программы в Visual Studio надо создать консольный проект, заменить файл program.cs на anthill-makedata.cs и собрать проект. Такой подход выбран с точки зрения компактности, наглядности и безопасности распространения.
По-умолчанию (без параметров) утилита готовит набор тестовых данных (5 файлов в CSV формате) на тысячу записей. В качестве параметра можно указать желаемый размер данных — от тысячи до миллиарда:
anthill-makedata.exe 1000000000
Подготовка тестовых данных в миллиард записей займёт до 30 минут и около 50 Гигабайт дискового пространства. Время выполнения можно посмотреть в журнале (anthill-makedata.log).
Для просмотра данных можно использовать FAR.
Здесь, кому интересно, можно подумать — а как бы они стали решать эту задачу.
В процессе разработки выяснялось, что с матчастью у меня «не очень», потому что ни с первого, ни со второго захода выйти на приемлемое быстродействие не получилось. Обработка на полных данных шла, ну очень, медленно. Виной тому была процедура поиска, которая выполнялась быстро на малых данных, но, при увеличении данных, всё замедлялось до неприличия.
В конце-концов, решение было найдено. Более того — для работы на полных данных хватило даже того, что было под капотом моего не самого мощного компа: CPU — Core 5i, RAM — 12Gb (было 8, добавил 4), HDD — самый простой (5400 об).
Суть решения — в использовании обычного индексного массива. Для каждого списка создаётся массив размером в миллиард. Номер ячейки в массиве — соответствует номеру объекта (муравей, дом). В ячейки массивов помещаются, соответственно, идентификаторы типов муравьёв и типов частей муравейника. После того как массивы муравьёв и домов заполнены (из тестовых данных — файлы anthill-ant-list.csv и anthill-cell-list.csv), «протягивается» файл связи anthill-ant-to-cell.csv и одновременно пишутся файлы (CSV) с результатами.
Обращение к ячейке массива по индексу происходит мгновенно, так как нет затрат времени на поиск. При этом, основную часть времени занимает считывание и запись файлов (работа с HDD).
Решение подготовлено в виде консольной программы, написанной на C# (Visual Studio Community 2013).
Код программы выложен на GitHub в файле anthill-makeresult.cs. Для получения рабочей программы в Visual Studio надо создать консольный проект, заменить файл program.cs на anthill-makeresult.cs и собрать проект (примечание: в свойствах проекта, в разделе BUILD, снять галочку [Prefer 32-bit]). Запускать программу следует в той-же директории, где находятся файлы тестовых данных.
По-умолчанию (без параметров) программа готовит списки муравьёв-солдат (CSV файлы). В качестве параметра можно указать желаемый тип:
anthill-makeresult.exe 4 (4 — код типа «рабочий»)
Подготовка результатов по полным данным занимает до 30 минут. С учётом тестовых данных, требуется около 100 Гигабайт дискового пространства.
Для рассмотренной задачи, утверждение, что объём данных не оказывает существенного влияния на трудоёмкость разработки, оказалось верным:
Из минусов можно отметить:
В сухом остатке осталось:
- Объём данных не должен оказывать значительного влияния на трудоёмкость разработки. Основная трудоёмкость разработки, как правило, связана со сложностью алгоритма обработки данных, а не с их количеством. Заранее зная фактический объём данных, достаточно разработать код, который работает на небольших данных, а затем его можно применить к требуемому объёму.
- Все основные вычислительные алгоритмы давным-давно известны (как минимум уже несколько десятков лет). Главное, как можно раньше (до начала разработки), определить правильный подход к задаче. Но это вопрос не трудоёмкости, а профпригодности — то есть, матчасть надо изучать заранее, а разрабатывать быстро.
- Ни один Заказчик не поймёт почему трудоёмкость разработки кода в несколько сотен строк, заняла много времени. Заказчику проще сменить команду, чем вложиться своим временем и деньгами в чей-то процесс обучения или в какой-то непонятный ему эксперимент.
- Небольшие накладные расходы, связанные с объёмом данных, конечно могут быть. Но эти издержки, обычно, не превышают погрешности первоначальной (правильной) оценки трудоёмкости и учитывать их отдельно не имеет смысла.
Для разработчика, прямо скажем, выводы получились не очень весёлые и однозначные.
Но дискуссия возникла не на пустом месте, а в рамках обсуждения задачи с простым вычислительным алгоритмом, но большим количеством данных.
Цель публикации — поделиться опытом как, за приемлемое время, обработать два связанных списка по миллиарду записей в каждом.
Постановка задачи
Представленные в публикации данные похожи на те, что были в оригинальной задаче. Изменения коснулись, в основном, прикладной терминологии. Назовём это «Учёт в муравейнике».
Для наглядности процесса дело было так:
В одном сказочном лесу решили провести учёт зверей. Для этого создали простенькую систему учёта, куда записали всех зверей — всего около тысячи. Систему сделали, зверям присвоили номера, номера также получили норки, берлоги, гнёзда. Короче всё получилось просто и быстро.
Об этом узнали в муравейнике и тоже решили разработать свою систему учёта. За основу взяли систему учёта зверей.
В итоге каждый муравей получил номер-имя и номер-дома проживания. Каждому муравью присвоили тип: рабочий, солдат,… Дома распределили по районам муравейника: центр, верх, низ,…
После того, как учёт был завершён и на муравьином собрании все радостно праздновали завершение работы, слово взял главный муравей-солдат. Он сказал (понятное дело говорил он распространяя всякие феромоны — так муравьям понятнее), что учёт ему нравится, это нужное и полезное дело и теперь надо во все части муравейника разослать списки муравьёв-солдат, проживающих в этой части муравейника. Сделать это надо, как обычно принято в таких случаях, срочно и безотлагательно.
Тут засуетились и другие муравьиные представители — им тоже были нужны списки для распределения всяких там жучков-червячков и для проведения других не менее важных мероприятий.
А было муравьёв — миллиард.
Об этом узнали в муравейнике и тоже решили разработать свою систему учёта. За основу взяли систему учёта зверей.
В итоге каждый муравей получил номер-имя и номер-дома проживания. Каждому муравью присвоили тип: рабочий, солдат,… Дома распределили по районам муравейника: центр, верх, низ,…
После того, как учёт был завершён и на муравьином собрании все радостно праздновали завершение работы, слово взял главный муравей-солдат. Он сказал (понятное дело говорил он распространяя всякие феромоны — так муравьям понятнее), что учёт ему нравится, это нужное и полезное дело и теперь надо во все части муравейника разослать списки муравьёв-солдат, проживающих в этой части муравейника. Сделать это надо, как обычно принято в таких случаях, срочно и безотлагательно.
Тут засуетились и другие муравьиные представители — им тоже были нужны списки для распределения всяких там жучков-червячков и для проведения других не менее важных мероприятий.
А было муравьёв — миллиард.

Структура данных показана на рисунке:
- ant_type — типы муравьёв (1- царица, 2 — личинка, 3 — нянька, 4 — рабочий, 5 — солдат)
- hill_type — районы муравейника (1 — центр, 2 — верх, 3 — низ, 4 — север, 5 — юг, 6 — восток, 7 — запад)
- ant_list — список муравьёв (миллиард записей)
- cell_list — список домов (миллиард записей)
- ant_to_cell — какой муравей в каком доме живёт (миллиард записей)
Задача состоит в том, чтобы для каждого района муравейника (hill_type) подготовить свой список проживающих в нём муравьёв (ant_list), определённого типа (ant_type) и с их номерами домов (cell_list).
Тестовые данные
Кому интересно, есть утилита для генерации тестовых данных. Утилита подготовлена в виде консольной программы, написанной на C# (Visual Studio Community 2013).
Код утилиты выложен на GitHub в файле anthill-makedata.cs. Для получения рабочей программы в Visual Studio надо создать консольный проект, заменить файл program.cs на anthill-makedata.cs и собрать проект. Такой подход выбран с точки зрения компактности, наглядности и безопасности распространения.
По-умолчанию (без параметров) утилита готовит набор тестовых данных (5 файлов в CSV формате) на тысячу записей. В качестве параметра можно указать желаемый размер данных — от тысячи до миллиарда:
anthill-makedata.exe 1000000000
Подготовка тестовых данных в миллиард записей займёт до 30 минут и около 50 Гигабайт дискового пространства. Время выполнения можно посмотреть в журнале (anthill-makedata.log).
Для просмотра данных можно использовать FAR.
Решение
Здесь, кому интересно, можно подумать — а как бы они стали решать эту задачу.
В процессе разработки выяснялось, что с матчастью у меня «не очень», потому что ни с первого, ни со второго захода выйти на приемлемое быстродействие не получилось. Обработка на полных данных шла, ну очень, медленно. Виной тому была процедура поиска, которая выполнялась быстро на малых данных, но, при увеличении данных, всё замедлялось до неприличия.
В конце-концов, решение было найдено. Более того — для работы на полных данных хватило даже того, что было под капотом моего не самого мощного компа: CPU — Core 5i, RAM — 12Gb (было 8, добавил 4), HDD — самый простой (5400 об).
Суть решения — в использовании обычного индексного массива. Для каждого списка создаётся массив размером в миллиард. Номер ячейки в массиве — соответствует номеру объекта (муравей, дом). В ячейки массивов помещаются, соответственно, идентификаторы типов муравьёв и типов частей муравейника. После того как массивы муравьёв и домов заполнены (из тестовых данных — файлы anthill-ant-list.csv и anthill-cell-list.csv), «протягивается» файл связи anthill-ant-to-cell.csv и одновременно пишутся файлы (CSV) с результатами.
Обращение к ячейке массива по индексу происходит мгновенно, так как нет затрат времени на поиск. При этом, основную часть времени занимает считывание и запись файлов (работа с HDD).
Решение подготовлено в виде консольной программы, написанной на C# (Visual Studio Community 2013).
Код программы выложен на GitHub в файле anthill-makeresult.cs. Для получения рабочей программы в Visual Studio надо создать консольный проект, заменить файл program.cs на anthill-makeresult.cs и собрать проект (примечание: в свойствах проекта, в разделе BUILD, снять галочку [Prefer 32-bit]). Запускать программу следует в той-же директории, где находятся файлы тестовых данных.
По-умолчанию (без параметров) программа готовит списки муравьёв-солдат (CSV файлы). В качестве параметра можно указать желаемый тип:
anthill-makeresult.exe 4 (4 — код типа «рабочий»)
Подготовка результатов по полным данным занимает до 30 минут. С учётом тестовых данных, требуется около 100 Гигабайт дискового пространства.
Краткое резюме
Для рассмотренной задачи, утверждение, что объём данных не оказывает существенного влияния на трудоёмкость разработки, оказалось верным:
- Готовое решение получилось простым и уложилось в 300 строк кода, включая обработку ошибок, журналирование и комментарии.
- Решение одинаково работает как на малых, так и на больших (до заданного размера) данных.
- Главный тормоз — не в обработке данных, а в операциях ввода-вывода (медленная работа HDD).
Из минусов можно отметить:
- Подход не является универсальным. Существенное влияние на решение могут оказать, например, другая структура или другой формат прикладных данных.
- Работа с CSV файлами не всегда удобна, не защищена от ошибок и не гарантирует целостности данных.
