Эта статья ориентирована на ABAP-разработчиков в системах SAP ERP. Она содержит много специфических для платформы моментов, которые малоинтересны или даже спорны для разработчиков, использующих другие платформы.
Это третья часть публикации. Начало можно прочитать тут:
Модульные тесты в ABAP. Часть первая. Первый тест
Модульные тесты в ABAP. Часть вторая. Грабли
Считается, что главной метрикой качества тестов является покрытие. В разработческих интернетах часто можно встретить формулировки в стиле “полное покрытие”. Как правило, под полным покрытием понимается некий абсолют в 100.00%.
Процент покрытия – цифра сомнительная, ровно настолько же сомнительная, как и “средняя температура по больнице”. Процент покрытия по проекту – это среднее покрытие его частей. То есть: Модуль-1 имеет покрытие 80%, Модуль-2 имеет покрытие 20%, в среднем покрытие будет равно 50%, если допустить что модули примерно равны по содержимому. А верно ли что 80% в четыре раза лучше чем 20%?
Среднее бывает разное. В ABAP UNIT есть три различные метрики покрытия:
Например, есть класс, группа функций или пул подпрограмм:
NB. Пул подпрограмм проще для демонстрации, чем группа функций или класс с методами. Пул подпрограмм описывается существенно меньшим количеством букв, чем класс. Параметры вынесены за рамки определений. В рамках этой маленькой демонстрации существенной разницы нет. И вообще: все переменные вымышлены, любые совпадения с продуктивным кодом случайны.
И предположим, что мы написали по одному простому тесту на каждую подпрограмму, функцию, метод. Для всех подпрограмм мы будем использовать значения [A = 7, B = 77].
NB: Пусть пока будет общая инициализация, а проверку результата опустим.
Это самый простой случай, можно посчитать на пальцах. Покрытие по процедурам будет 100% = ( 1 + 1 + 1 ) / ( 1 + 1 + 1 ) * 100.
А если для тех же процедур мы посчитаем количество инструкций?
Каждая процедура содержит разное количество инструкций. Причём при заданных входных параметрах будут вызваны не все инструкции:
Инструкции считаются просто: обычные инструкции, сама процедура считается за инструкцию, условие считается за инструкцию. Конструкция завершения условия ENDIF не считается за инструкцию, потому что она только определяет место перехода, но не связана с какими-либо вычислениями или действиями.
Если мы посчитаем метрику по инструкциям, то будет 71% = ( 3 + 5 + 2 ) / ( 3 + 8 + 3 ) * 100.
Рассмотрим работу метрики на DO_SOMETHING_ELSE. Инструменты разработки ABAP могут раскрасить строки исходного кода в соответствии с метрикой:
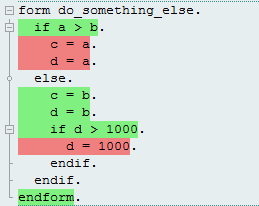
Наглядно, быстро, понятно. Просто удивительно, даже не ожидал такого от ABAP.
Из этой раскраски становится очевидно, что если бы мы взяли другие исходные параметры, то процент покрытия могу бы быть другим. В случае [A = 77, B = 7]:

При этом становится очевидным, что полного покрытия по данной метрике можно достичь только используя более одного тестового сценария. Например, при двух тестах [A = 77, B = 7] и [A = 7, B = 7777] всё позеленеет:

Таким образом метрика выходит на 100%. Можно ненадолго успокоиться.
Эта метрика работает несколько сложнее. Она берёт все инструкции, которые могут вызвать ветвление, и проверяет их на то, что каждая такая инструкция выполняется в обе стороны.
Посмотрим на базе последнего примера:
Первая инструкция [IF A > B] на двух тестах отработала два раза: один раз по TRUE [A = 77, B = 7] и один раз по FALSE [A = 7, B = 7777].
А вот вторая инструкция [IF D > 1000] отработала только один раз на TRUE [A = 7, B = 7777].
Сам вызов функции считается за безусловную единицу, плюс первый IF даёт два из двух, второй IF даёт только единицу из двух. Значит наша метрика будет равна 80% = (1 + 2 + 1 ) / (1 + 2 + 2) * 100.
И тут уже выходит что для одной функции двух тестов уже мало, а нужно три. К предыдущим двум можно ещё добавить сценарий [A = 7, B = 77], чтобы второй IF отработал на FALSE.
После добавления третьего сценария метрика по этой функции вышла на 100%.
А что же с DO_NOTHING, спросите вы? Не существует такого теста, чтобы метрика по ветвям или инструкциям вышла на 100%. Очевидно, что функция требует рефакторинга, без которого выйти на полное покрытие не получится. Эту функцию следует или удалить, или она должна превратиться из DO_NOTHING в DO_SOMETHING_COMPLETELY_DIFFERENT.
Жаль нельзя написать ещё больше тестов и получить более 100%.
Понятно, что метрика Procedure coverage менее показательна в деталях. К ней можно внимательно присматриваться только на ранних этапах, если кода много а тестов ещё почти нет. А вот к какой метрике из двух оставшихся приглядываться после? Если первая метрика просто показывает насколько широко вы охватили функционал, то последние показывают, насколько вы его качественно охватили.
Как вы заметили, можно получить 100% по инструкциям, но при этом не будет 100% по ветвям. Но не наоборот (или я не могу придумать такой пример). Если вы уж получили 100% по ветвям, то значит вы зашли во все закоулки и все инструкции отработали. Но кому-то может показаться, что метрика по ветвям даёт менее показательные весовые коэффициенты в среднем, так как игнорирует один из явных весовых показателей – количество строк кода, то есть количество инструкций.
BTW: Да, пустая процедура даёт 100% показатели!
Для работы ABAP Unit неважно:
Главное, чтоб локальный класс:
Но, с другой стороны, даже имена переменных-то тоже не являются случайным набором букв.
Следовательно, у нас по каждому пункту должна быть некоторая общая условная договорённость, облегчающая общее восприятие картины. Вроде соглашения по именованию или форматированию.
Тестовых классов должно быть ровно столько сколько нужно. Как минимум, каждый большой объект (группа функций, программа, класс) должен иметь один тестовый класс, можно больше.
Если у вас простая группа из нескольких связанных функций, то к ней достаточно и одного класса. А вот если в вашей группе есть шесть пачек малосвязанных функций, то здесь здесь должен скорее возникнуть вопрос “А сколько должно быть групп функций?”, а это тема для совсем другого разговора.
После корректного ответа на данный вопрос можно взять метод SETUP в качестве критерия делимости. Такой метод в классе должен быть один, вызывается он автоматически перед каждым тестовым методом.
Каждый сценарий должен дать отдельный тестовый метод, наименование метода должно прямо выводиться из тестируемого кода.
Один из принципов модульного тестирования: тестовый класс должен тестировать только тот код, в юрисдикции которого он находится. И хотя тесты могут находиться в любом месте исходного кода, но стоит отделять работающую функциональность от тестов.
Вот мастер для групп функций создаёт отдельную include-программу по предопределённому шаблону: например: LZFI_BTET99 для группы функций ZFI_BTE. Ничего плохого в этом не вижу, надо принимать за образец и продолжать в том же духе.
Также и в программах типа REPORT: пишите тесты строго в одной отдельной include-программе, с именем по шаблону.
Впрочем, никому не могу запретить писать всё вперемешку: код, его тест, код, его тест…
Нельзя каждые пять минут запускать полный цикл модульных тестов. Но, как минимум, перед деблокированием запроса необходимо запускать тест причастных объектов.
Просто пачка тезисов для подведения черты:
В суете не забывайте главное: тесты – это не самоцель. Всё должно нести пользу.
Прямая реальная польза от тестов будет только в те моменты, когда по прошествии времени тесты будут провалены, когда кто-то будет допиливать эту функциональность.
Потому что умение правильно падать – самый лучший способ избежать травм. Если это верно для каратистов и велосипедистов, значит и для программистов тоже будет нелишним. Лучше правильно упасть плохо крутя педали, чем неправильно упасть хорошо крутя педали. Умение правильно падать важнее правильной экипировки.
А прямо сейчас можно извлечь только косвенную пользу:
На сегодня всё, до новых встреч.
Это третья часть публикации. Начало можно прочитать тут:
Модульные тесты в ABAP. Часть первая. Первый тест
Модульные тесты в ABAP. Часть вторая. Грабли
Будем меряться
Считается, что главной метрикой качества тестов является покрытие. В разработческих интернетах часто можно встретить формулировки в стиле “полное покрытие”. Как правило, под полным покрытием понимается некий абсолют в 100.00%.
Процент покрытия – цифра сомнительная, ровно настолько же сомнительная, как и “средняя температура по больнице”. Процент покрытия по проекту – это среднее покрытие его частей. То есть: Модуль-1 имеет покрытие 80%, Модуль-2 имеет покрытие 20%, в среднем покрытие будет равно 50%, если допустить что модули примерно равны по содержимому. А верно ли что 80% в четыре раза лучше чем 20%?
Среднее бывает разное. В ABAP UNIT есть три различные метрики покрытия:
- по процедурам (procedure coverage)
- по инструкциям (statement coverage)
- по ветвям (branch coverage)
Например, есть класс, группа функций или пул подпрограмм:
form do_something.
c = a.
d = b.
endform.
form do_something_else.
if a > b.
c = a.
d = a.
else.
c = b.
d = b.
if d > 1000.
d = 1000.
endif.
endif.
endform.
form do_nothing.
if 1 = 2.
c = d = 0.
endif.
endform.
NB. Пул подпрограмм проще для демонстрации, чем группа функций или класс с методами. Пул подпрограмм описывается существенно меньшим количеством букв, чем класс. Параметры вынесены за рамки определений. В рамках этой маленькой демонстрации существенной разницы нет. И вообще: все переменные вымышлены, любые совпадения с продуктивным кодом случайны.
И предположим, что мы написали по одному простому тесту на каждую подпрограмму, функцию, метод. Для всех подпрограмм мы будем использовать значения [A = 7, B = 77].
class lcl_test definition for testing
duration short
risk level harmless.
private section.
methods: setup.
methods: do_something for testing.
methods: do_something_else for testing.
methods: do_nothing for testing.
endclass.
class lcl_test implementation.
method setup.
a = 7.
b = 77.
endmethod.
method do_something.
perform do_something.
endmethod.
method do_something_else.
perform do_something_else.
endmethod.
method do_nothing.
perform do_nothing.
endmethod.
endclass.
NB: Пусть пока будет общая инициализация, а проверку результата опустим.
Procedure coverage
Это самый простой случай, можно посчитать на пальцах. Покрытие по процедурам будет 100% = ( 1 + 1 + 1 ) / ( 1 + 1 + 1 ) * 100.
Statement coverage
А если для тех же процедур мы посчитаем количество инструкций?
Каждая процедура содержит разное количество инструкций. Причём при заданных входных параметрах будут вызваны не все инструкции:
- DO_SOMETHING: отработало три инструкции из трех
- DO_SOMETHING_ELSE: отработало пять инструкций из восьми
- DO_NOTHING: отработало две инструкции из трёх
Инструкции считаются просто: обычные инструкции, сама процедура считается за инструкцию, условие считается за инструкцию. Конструкция завершения условия ENDIF не считается за инструкцию, потому что она только определяет место перехода, но не связана с какими-либо вычислениями или действиями.
Если мы посчитаем метрику по инструкциям, то будет 71% = ( 3 + 5 + 2 ) / ( 3 + 8 + 3 ) * 100.
Рассмотрим работу метрики на DO_SOMETHING_ELSE. Инструменты разработки ABAP могут раскрасить строки исходного кода в соответствии с метрикой:

Наглядно, быстро, понятно. Просто удивительно, даже не ожидал такого от ABAP.
Из этой раскраски становится очевидно, что если бы мы взяли другие исходные параметры, то процент покрытия могу бы быть другим. В случае [A = 77, B = 7]:

При этом становится очевидным, что полного покрытия по данной метрике можно достичь только используя более одного тестового сценария. Например, при двух тестах [A = 77, B = 7] и [A = 7, B = 7777] всё позеленеет:

Таким образом метрика выходит на 100%. Можно ненадолго успокоиться.
Branch coverage
Эта метрика работает несколько сложнее. Она берёт все инструкции, которые могут вызвать ветвление, и проверяет их на то, что каждая такая инструкция выполняется в обе стороны.
Посмотрим на базе последнего примера:
Первая инструкция [IF A > B] на двух тестах отработала два раза: один раз по TRUE [A = 77, B = 7] и один раз по FALSE [A = 7, B = 7777].
А вот вторая инструкция [IF D > 1000] отработала только один раз на TRUE [A = 7, B = 7777].
Сам вызов функции считается за безусловную единицу, плюс первый IF даёт два из двух, второй IF даёт только единицу из двух. Значит наша метрика будет равна 80% = (1 + 2 + 1 ) / (1 + 2 + 2) * 100.
И тут уже выходит что для одной функции двух тестов уже мало, а нужно три. К предыдущим двум можно ещё добавить сценарий [A = 7, B = 77], чтобы второй IF отработал на FALSE.
После добавления третьего сценария метрика по этой функции вышла на 100%.
А что же с DO_NOTHING, спросите вы? Не существует такого теста, чтобы метрика по ветвям или инструкциям вышла на 100%. Очевидно, что функция требует рефакторинга, без которого выйти на полное покрытие не получится. Эту функцию следует или удалить, или она должна превратиться из DO_NOTHING в DO_SOMETHING_COMPLETELY_DIFFERENT.
Сто процентов!
Жаль нельзя написать ещё больше тестов и получить более 100%.
Понятно, что метрика Procedure coverage менее показательна в деталях. К ней можно внимательно присматриваться только на ранних этапах, если кода много а тестов ещё почти нет. А вот к какой метрике из двух оставшихся приглядываться после? Если первая метрика просто показывает насколько широко вы охватили функционал, то последние показывают, насколько вы его качественно охватили.
Как вы заметили, можно получить 100% по инструкциям, но при этом не будет 100% по ветвям. Но не наоборот (или я не могу придумать такой пример). Если вы уж получили 100% по ветвям, то значит вы зашли во все закоулки и все инструкции отработали. Но кому-то может показаться, что метрика по ветвям даёт менее показательные весовые коэффициенты в среднем, так как игнорирует один из явных весовых показателей – количество строк кода, то есть количество инструкций.
BTW: Да, пустая процедура даёт 100% показатели!
Уговор есть уговор
Для работы ABAP Unit неважно:
- сколько у вас тестовых классов вообще;
- как называется тестовый класс;
- в каком месте он расположен;
- как называются его методы.
Главное, чтоб локальный класс:
- был доступен;
- имел кличку “for testing”;
- имел методы с кличками “for testing”.
Но, с другой стороны, даже имена переменных-то тоже не являются случайным набором букв.
Следовательно, у нас по каждому пункту должна быть некоторая общая условная договорённость, облегчающая общее восприятие картины. Вроде соглашения по именованию или форматированию.
Что?
Тестовых классов должно быть ровно столько сколько нужно. Как минимум, каждый большой объект (группа функций, программа, класс) должен иметь один тестовый класс, можно больше.
Если у вас простая группа из нескольких связанных функций, то к ней достаточно и одного класса. А вот если в вашей группе есть шесть пачек малосвязанных функций, то здесь здесь должен скорее возникнуть вопрос “А сколько должно быть групп функций?”, а это тема для совсем другого разговора.
После корректного ответа на данный вопрос можно взять метод SETUP в качестве критерия делимости. Такой метод в классе должен быть один, вызывается он автоматически перед каждым тестовым методом.
Каждый сценарий должен дать отдельный тестовый метод, наименование метода должно прямо выводиться из тестируемого кода.
Где?
Один из принципов модульного тестирования: тестовый класс должен тестировать только тот код, в юрисдикции которого он находится. И хотя тесты могут находиться в любом месте исходного кода, но стоит отделять работающую функциональность от тестов.
Вот мастер для групп функций создаёт отдельную include-программу по предопределённому шаблону: например: LZFI_BTET99 для группы функций ZFI_BTE. Ничего плохого в этом не вижу, надо принимать за образец и продолжать в том же духе.
Также и в программах типа REPORT: пишите тесты строго в одной отдельной include-программе, с именем по шаблону.
Впрочем, никому не могу запретить писать всё вперемешку: код, его тест, код, его тест…
Когда?
Нельзя каждые пять минут запускать полный цикл модульных тестов. Но, как минимум, перед деблокированием запроса необходимо запускать тест причастных объектов.
Подытожу
Просто пачка тезисов для подведения черты:
- С этим можно жить.
- Код теста получается больше продуктивного кода.
- Во многих случаях подходы TDD оправданы и рекомендуются к употреблению.
- Обзор существующего продуктивного кода без тестов вызывает существенное напряжение мозговых извилин.
- Если пытаться покрыть тестами уже написанный код, то часто без рефакторинга не обойтись. А рефакторинг – несколько другая и более сложная задача, чем само покрытие тестами. Рефакторинг можно отложить до момента, когда вы будете делать с кодом что-то ещё.
- Если у вас есть продуктивный код, который не меняется годами, то его покрывать тестами нужно в последнюю очередь.
- Код может быть остаться непокрытым из-за замкнутой петли: Нельзя сделать правильные тесты, потому что сначала надо сделать серьёзный рефакторинг, а делать рефакторинг не рекомендуется пока нет тестов.
- В некоторых случаях выполнить покрытие тестами не получается. Так бывает. Смиритесь.
- По некоторым метрикам подсчета полноты покрытия гораздо проще добиться 100%, чем по другим. Это не означает, что нужно делать так, как проще.
- Не замечал тестов в стандартном коде системы, а если бы они были, то их было бы запрещено выполнять.
В суете не забывайте главное: тесты – это не самоцель. Всё должно нести пользу.
Прямая реальная польза от тестов будет только в те моменты, когда по прошествии времени тесты будут провалены, когда кто-то будет допиливать эту функциональность.
Потому что умение правильно падать – самый лучший способ избежать травм. Если это верно для каратистов и велосипедистов, значит и для программистов тоже будет нелишним. Лучше правильно упасть плохо крутя педали, чем неправильно упасть хорошо крутя педали. Умение правильно падать важнее правильной экипировки.
А прямо сейчас можно извлечь только косвенную пользу:
- Тесты документируют сценарии использования
- Тесты помогают выявить места, требующие внимания (рефакторинг)
- Тесты помогают выполнить базовые проверки тех мест, которые сложно тестировать вручную
На сегодня всё, до новых встреч.
