Comments 9
Я не большой специалист по БД, поэтому сразу же возник вопрос: а как повлияет индекс (и частичный индекс на NULL / not NULL) на скорость вычисления?
Ведь если NULL много, то может можно как-то их отдельно более быстро посчитать и учесть при суммировании? Да и возможны различные особенности внутренней реализации, скажем, более быстрое получение данных из индекса…
Ведь если NULL много, то может можно как-то их отдельно более быстро посчитать и учесть при суммировании? Да и возможны различные особенности внутренней реализации, скажем, более быстрое получение данных из индекса…
В индексе нет NULL значении, так что он будет ускорять арифметические операции.
В Oracle будет fast full scan index при полном сканировании или range scan при частичном без физического обращения к таблице.
В Oracle будет fast full scan index при полном сканировании или range scan при частичном без физического обращения к таблице.
если NULL много лучше всего фильтрованный покрывающий индекс сделать — where col is not null. И запрос с таким же условием выполнять — ну и будет индекс скан.
И того что я вижу, то SQL Server как-то «хитро» не обрабатывает NULL отдельно от других значений при агрегации. Поскольку NULL это точно такое же значение, как и 0, 'abc' и т.д. Оно занимает место на страницах:
Теперь этим запросом посмотрим сколько места занимают индексы:
Как можно увидеть NULL хранятся в ix1 в противном случае, его размер был бы идентичный ix2:
С точки зрения производительности… Чем меньше данных нужно вычитать из индекса и обработать, тем быстрее отработает запрос:
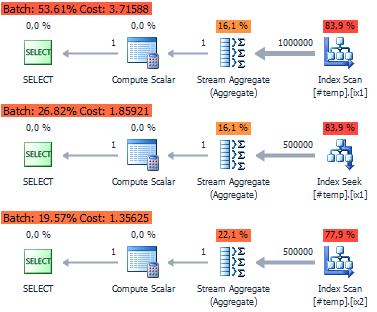
План выполнения полученный в dbForge:
USE tempdb
GO
IF OBJECT_ID('tempdb.dbo.#temp') IS NOT NULL
DROP TABLE #temp
GO
SELECT TOP(1000000) val = NULLIF(ROW_NUMBER() OVER (ORDER BY 1/0) % 2, 1)
INTO #temp
FROM [master].dbo.spt_values s1
CROSS JOIN [master].dbo.spt_values s2
GO
CREATE NONCLUSTERED INDEX ix1 ON #temp (val)
GO
CREATE NONCLUSTERED INDEX ix2 ON #temp (val) WHERE val IS NOT NULL
GO
Теперь этим запросом посмотрим сколько места занимают индексы:
SELECT i.name, a.total_pages, a.used_pages
FROM sys.indexes i
JOIN sys.partitions p ON i.[object_id] = p.[object_id] AND i.index_id = p.index_id
JOIN sys.allocation_units a ON p.[partition_id] = a.container_id
WHERE i.[object_id] = OBJECT_ID('#temp')
AND i.name IS NOT NULL
Как можно увидеть NULL хранятся в ix1 в противном случае, его размер был бы идентичный ix2:
name total_pages used_pages
----------- ------------- ------------
ix1 2739 2734
ix2 1369 1366
С точки зрения производительности… Чем меньше данных нужно вычитать из индекса и обработать, тем быстрее отработает запрос:
SET STATISTICS IO ON
SET STATISTICS TIME ON
SELECT SUM(val) FROM #temp WITH(INDEX(ix1))
SELECT SUM(val) FROM #temp WITH(INDEX(ix1)) WHERE val IS NOT NULL
SELECT SUM(val) FROM #temp WITH(INDEX(ix2)) WHERE val IS NOT NULL
Table '#temp_000000000005'. Scan count 1, logical reads 2729, physical reads 0, ...
SQL Server Execution Times:
CPU time = 125 ms, elapsed time = 123 ms.
Table '#temp_000000000005'. Scan count 1, logical reads 1372, physical reads 0, ...
SQL Server Execution Times:
CPU time = 62 ms, elapsed time = 64 ms.
Table '#temp__000000000005'. Scan count 1, logical reads 1365, physical reads 0, ...
SQL Server Execution Times:
CPU time = 47 ms, elapsed time = 51 ms.
План выполнения полученный в dbForge:

Как оказалось, операции агрегирования, в которых преобладают NULL значения обрабатываются быстрее.
Было бы интересно посмотреть более подробную статистику в профайлере, бенчмарк сам по себе ничего не объясняет.
Спасибо за интересную статью!
Sign up to leave a comment.
Что быстрее: 0 или NULL?