Comments 122
Микрософт очень грамотно спозиционировала TypeScript — это современные спецификации ECMAScript + типы. И ничего лишнего. В отличие от CoffeScript или Dart, меняющих язык до неузнаваемости.
Внезапно, flow!
Он от тайпскрипта отличается очень незначительно. Разве что тайпскрипт — это ещё и транспайлер, а не только тайпчекер, что является преимуществом, так как:
- Набор поддерживаемых фичей должен быть одинаковым в транспиляторе и тайпчекере.
- Не надо по нескольку раз парсить JS, что ускоряет транспиляцию и уменьшает число точек потенциального сбоя.
- Есть возможность билдить инкрементально, что ещё сильнее ускоряет билд при разработке.
- Не нужно настраивать и дружить между собой несколько инструментов.
Flow создает так называемый Flowgraph, который представляет собой граф всего приложения — он запоминает, какие модули связаны друг с другом. TypeScript не предлагает ничего подобного, потому что это слишком большая задача, Flow заходит дальше. Flow определяет, отрезаны ли большие части приложения от остальной части кода, и предлагает удалить их! Джефф Моррисон много говорил об этом на ReactEurope.
TypeScript не предлагает ничего подобного, потому что это слишком большая задача
Любой статически типизированный язык строит граф всего приложения в процессе компиляции. Иначе он просто бы не смог проверять типы.
Flow определяет, отрезаны ли большие части приложения от остальной части кода, и предлагает удалить их!
Думаю и к тайпскрипту это вскоре прикрутят. А вообще, лучше бы они объединились, и вместе пилили JS++, а не конкурировали, вынуждая разработчиков выбирать между двумя похожими технологиями.
Если вы, как и я, устали от этих всё более усложняющихся инструментов… то присоединяйтесь к разработке простого и эффективного сферического фреймворка
Напрашивается картинка про 14 конкурирующих стандартов
Получается, что бенчмарк — это хорошо, но он не показывает особого преимущества Angular Light над React.
В аппаратных интерфейсах (то что вы назвали "портами") вы кажется несколько некомпетенты. Каждый интерфейс выполняет свою задачу и к примеру нет дискуссий о надежности или перспективности. Тот же UART (который вы обозвали COM-портом), спокойно трудится в вашем смартфоне, соединяя чип Bluetooth с центральным процессором.
Что действительно стоит сравнивать — так это максимальную скорость, количество сигнальныйх линий, требования к линиям, ограничения на длину, устойчивость к помехам, требования к наличию PHY и т.д. Всё это можно выразить в числах и сравнить.
Новые интерфейсы изобретают просто потому что новые технологии позволяют сигналы быстрее и точнее.
Ангуляр, например, без конца дёргает функцию фильтрации (которая — бизнес-логика, ага) только для того, чтобы узнать не изменился ли список выводимых строк, потому как он не знает от чего он зависит, а от чего — нет. Реакт будет на каждый чих пытаться перерендерить весь виртуальный дом, если мы не понапишем костылей в виде shouldComponentUpdate. В приветмирах всё это отрабатывает быстро, но когда это всё начинает тормозить — вам уже некуда деваться. И повляются статьи по оптимизациям в духе "не используете $timeout", "делайте одноразовые биндинги", "добавляйте debounce" и тп.
Я говорил вот об этих портах.
При этом каждый вложенный элемент получил уникальное имя
… где же я это видел? А, конечно. asp.net Web Forms. Гарантированно уникальный идентификатор для каждого контрола.
А во-вторых, получались они на сервере и слабопредсказуемо, поэтому работать с ними из клиентского кода было адски неприятно.
$mol_app_todo.app().taskRow(4).dropper() сразу понятно, что это кнопка удаления задачи в четвёртой по счёту строке в приложении mol_app_todo.Ну, допустим, так:
var cellId = row.cell('title').objectPath
var cellNode = row.cell('title').node().get()
Какими, например?
Ванильным JS, например.
var cellId = row.cell('title').objectPath
Неплохо, но печально. Печально по двум причинам: во-первых, мне надо как-то догадаться, что
objectPath — это идентификатор, назначенный HTML-элементу, и, во-вторых, на строковом идентификаторе все прелести статической проверки умерли.Не так уж это и сложно, догадаться:

'title' — это ключ, для создания множества типовых объектов. Ничто не мешает сделать по отдельной фабрике для каждой ячейки:
var cellId = row.cellTitle().objectPath
var cellNode = row.cellTitle().node().get()Ну, или использовать энумерацию, как предложила Сферрка.
В норме, фреймворк должен абстрагировать от реальных узлов, потому как этих реальных узлов может и не быть в случае нативных компонент.
Вооо, вот мы и вернулись к стартовому "Все зависит от того, кто работает с объектами по этим идентификаторам. Если только сами компоненты, то пофиг."
Пока всё укладывается в рамки JSF, всё хорошо. Можно просто получить id компонента.
Но если вдруг так случалось, что нужно было получить правильный id уже отрендеренного компонента, начинались костыли.
Как видно, эти проблемы не только в вебформах, а в подходе в целом.
В 1.x всё ещё нет наследования, только композиция. А [select] это не хак, это фактический стандарт веб-компонентов (в v1 версии спецификации веб-компонентов заменено на именованные слоты, что немного отличается, но в целом более практично).
А в какой версии оно есть?
Это хак в том смысле, что берётся одно дерево и оно видоизменяется. При этом происходит жёсткая завязка на конкретную структуру этого дерева.
<dom-module id="my-panel">
<template>
<div class="header">
<content select="[my-panel-head]" />
</div>
<div class="bodier">
<content />
</div>
</template>
<script>Polymer({is: 'my-panel'})</script>
</dom-module>Нет больше полностью декларативного объявления компонентов, как минимум то, что я написал выше нужно сделать, потом оно найдет модуль с id соответствующим is и таким образом инициализирует компонент.
Также в 1.x получше дела с производительностью, много интересных фич в плане стилей — CSS variables & CSS mixins везде.
Мне ближе всего Polymer, так что я вкладываюсь в его разработку разными идеями и патчами, что приближает его к тому, что я считаю идеальным.
Наследования пока нет вообще (если не считать прототипы в локальных ветках отдельных разработчиков), обещают давно, не уверен на сколько оно сейчас готово. Слоты есть в спецификации, Polymer их не внедряет пока не появятся в стабильных версиях популярных браузеров.
Или вы считаете отсутствие наследования
А вам точно нужно наследование в UI-фреймворке?
- Форкнуть и героическими усилиями за неделю добавить недостающие точки расширения, шаблоны, стратегии, параметры или что там ещё может прийти в голову. Потом ещё долго огребать от несовместимостей с основной веткой.
- Оставить фичереквест мейнтейнерам и надеяться, что до дедлайна они соизволят необходимый функционал реализовать.
- Сказать заказчику, что это не возможно с готовыми решениями и требуется пара недель на разработку своего велосипеда.
- Написать мартышкин патч, который после рендеринга пробегается по DOM-у и приводит его к нужному виду. Обычно так и делают.
- Отнаследоваться и перегрузить необходимые аспекты поведения. Такое мало где поддерживается.
Вы не в теме проблематики.
Вам, конечно, виднее.
Отнаследоваться и перегрузить необходимые аспекты поведения.
А почему вы считаете, что нужные вам аспекты поведения будут открыты для наследования? Понимаете ли, доступные для переопределения методы — это и есть точки расширения, если в этом месте расширения не закладывали, то и наследование не поможет.
Другое дело, что у вас, конечно, есть точки расширения, но уверены ли вы, что любое вписанное в них поведение не сломает компонент? Например, была у вас табличка, вы хотите переопределить общий генератор таблички, но оставить генераторы строчек — как (конечно же, не глядя в исходный код) это сделать?
Перегрузить генератор таблички (rows) и не трогать генератор строчек (row). Все компоненты создаются через фабрики во владеющих их компонентах.
Затем, чтобы создать свой компонент на 90% похожий на оригинал.
Ну так наследование для этого не обязательно. Берете свой компонент, включаете внутрь него нужный компонент, кастомизируете как надо, нужные операции делегируете.
Перегрузить генератор таблички (rows) и не трогать генератор строчек (row).
Понимаете ли, у меня может быть две разных задачи: одна — переопределить генератор таблички так, чтобы он отсеивал нужные мне строки, а дальше они выводились, как и раньше, а другая — переопределить генератор таблички так, чтобы он выводил те же строки, что и раньше, но принципиально в другом виде.
Если очень грубо, то:
type Table =
//...
member this.Render context =
html {
yield! RenderHeader
yield! Rows |> Seq.concat (fun r -> r.Render(context))
yield! RenderFooter
}
Нас интересует фрагмент
Rows |> Seq.concat (fun r -> r.Render(context)). Если мне нужна фильтрация, то я пишу this.Rows |> Seq.filter ... |> Seq.concat (fun r -> r.Render(context))), а если переопределение отображения — то:
for (i, r) in Rows do
yield "<tr>"
yield! ["<td>"; i; "</td>"]
yield! r.Cells |> Seq.concat (fun c -> c.Render(context))
yield "</tr>"
А вот теперь, собственно, вопрос: как не получить при этом код, который ломается от любого случайного чиха?
Берете свой компонент, включаете внутрь него нужный компонент, кастомизируете как надо, нужные операции делегируете.Именно так и работает наследование.
Не понял, где у вас там что ломается. Но код, конечно, жуткий.
public class BaseClass
{
public void DoSmthng(obj param)
{
.....
}
}
public class Wrapper
{
private BaseClass _innerObj = new BaseClass();
public void DoSmthng(obj param)
{
...
_innerObj.DoSmthng(param);
}
} public void DoSmthng(obj param){ _innerObj.DoSmthng(param); } ради непонятно чего. Есть идеи как сделать проще и гибче? Буду рад их услышать.Именно так и работает наследование.
Нет, так работает композиция. Вы правда не знаете разницы, или просто шутите так?
Не понял, где у вас там что ломается.
Ну давайте еще раз, на пальцах.
Есть типичный генератор-табличек-с-данными: сгенери заголовок, сгенери строчки с данными, сгенери подвал. Строчки с данными — это, понятное дело, обход коллекции данных, и генерация TR на каждый из элементов. Грубо говоря, декомпозиция выглядит так:
GenerateTable
GenerateHeader
for each row
GenerateRow
GenerateFooter
В каких-то случаях надо вмешаться то, какие строчки генерятся (т.е., поменять логику
for each), а в каких-то — в то, как они генерятся (т.е., заменить вызов GenerateRow на что-нибудь другое).Так вот, в типичном "компоненте"
GenerateTable и GenerateRow связаны между собой настолько сильно, что вмешательство в один требует постоянной сверки с другим (это, кстати, не проблема наследования, это проблема кастомизации вообще). Как вы решаете эту проблему?$my_stats : $mol_tabler childs
< header : $mol_view childs < foot : null
< rows : null
< footer : $mol_view childs < foot : nullТут у нас объявлены следующие свойства: childs, header, head, footer, foot, rows. Можете перегружать любое из них.
rows реализуется как-то так:
rows() { this.prop( () => {
var next = []
for( var i = 0 ; i < 100 ; ++i ) next.push( this.row( i ).get() )
return rows
} ) }row — просто фабрика, например:
row( id : number ) { return (new $mol_view).setup( _ => {
_.child = () => this.prop( id )
} ) }Её тоже можно переопределить.
rows, я должен повторить большую часть этого замечательного кода ради измения, скажем в var i = 0 ; i < 50 ; ++i?Что же касается необходимости наследования: если
header, rows и footer будут не перегружаемыми методами, а свойствами, содержащими функции, то каждый из нх все равно останется точкой расширения:new table
{
header = () => {/* custom header generation */},
rows = () => {/* custom header generation */},
footer = () => {/* custom header generation */}
}Ну да, а еще бывает вот так:```cs
Html.Table()
.Header(() => {/… /})
.Footer(() => {/… /})
.RowTemplate(item => {/… /})
И тоже никакого наследования.
Но самое интересное все равно начинается в тот момент, когда вы поменяли поведение контрола (того же календаря), а теперь хотите, чтобы оно поменялось по всей системе (например, чтобы рабочие дни у вас помечались с понедельника по субботу), включая те места, где этот контрол создаете не вы, а другие контролы (например, в заголовке колонки грида есть кнопка "Фильтр", по которой для колонок с типом "дата" выпадает календарь). И вот если вы <i>это</i> хотите сделать легко и просто, то наследование вам не поможет (точнее, его недостаточно).В JS/TS методы — это поля содержащие функции. То, что вы реализовали — это тоже форма наследования, мартышкин патч. Она менее эффективна, чем через классы.
Даже если где-то календарик создаю не я, то я создаю компонент, который создаёт компонент, который создаёт календарик. Так что я вполне в состоянии перегрузить фабрику создания календариков, чтобы она создавала инстанс другого класса.
Я вам скажу страшную вещь, но грид не должен ничего знать про типы колонок — всё это инъектируется извне.
а о кастомизации порядка и состава вложенных компонент.
А там будут те же проблемы. Не вынесли конкретную "компоненту" в свойство — здравствую, копипаста.
То, что вы реализовали — это тоже форма наследования, мартышкин патч.
Нет, это не наследование — объект остается того же типа. Это как раз чистая кастомизация.
Так что я вполне в состоянии перегрузить фабрику создания календариков, чтобы она создавала инстанс другого класса.
В каждом компоненте будете ее перегружать (и молиться, чтобы каждый компонент ее выставлял)? Или будете надеяться, что все компоненты смотрят на общую фабрику (и используют один интерфейс)?
Я вам скажу страшную вещь, но грид не должен ничего знать про типы колонок — всё это инъектируется извне.
Грид как минимум знает про типы колонок, которые он умеет отображать. Метаданные конкретного набора данных он действительно получает снаружи.
Не вынесли конкретную «компоненту» в свойство —— свалится при компиляции :-) Во view.tree создавать подкомпоненты можно исключительно через именованные фабрики.
Нет, это не наследование — объект остается того же типа. Это как раз чистая кастомизация.В JS/TS все объекты «одного типа». Различия лишь в составе и значениях полей.
В каждом компоненте будете ее перегружать (и молиться, чтобы каждый компонент ее выставлял)? Или будете надеяться, что все компоненты смотрят на общую фабрику (и используют один интерфейс)?Можно во все компонентны инъектировать и общую фабрику. Если уж надо совсем-совсем гарантированно везде, то проще, просто заменить исходный класс своим.
Грид как минимум знает про типы колонок, которые он умеет отображать.Мой грид не занимается отображением колонок. Что я делаю не так? :-)
Во view.tree создавать подкомпоненты можно исключительно через именованные фабрики.
Так я просто не стану считать то, что вы хотите кастомизировать, компонентой — и, как следствие, не буду ничего никуда выносить.
В JS/TS все объекты «одного типа».
Даже в JS это не так, а уж в TS — тем более. Ну и да, о какой тогда строгой типизации вы пишете в своем посте?
Можно во все компонентны инъектировать и общую фабрику.
Можно. Для этого вам придется налагать на все компоненты очень жесткие требования (которые при этом сложно статически валидировать).
Мой грид не занимается отображением колонок. Что я делаю не так
Называете гридом не то же самое, что другие люди.
Так я просто не стану считать то, что вы хотите кастомизировать, компонентой — и, как следствие, не буду ничего никуда выносить.Во view.tree вы не сможете этого сделать. Но во view.ts вы, конечно, можете сотворить любое непотребство, если сильно заморочиться.
Даже в JS это не так, а уж в TS — тем более. Ну и да, о какой тогда строгой типизации вы пишете в своем посте?Вы плохо знаете JS :-) В TS — структурная типизация.
Называете гридом не то же самое, что другие люди.Или наоборот, не превращаю простую абстракцию табличного вывода данных в кухонный комбайн, который должен уметь всё на свете.
Но во view.ts вы, конечно, можете сотворить любое непотребство, если сильно заморочиться.
Ну вот видите.
В TS — структурная типизация.
Да, я был неправ, действительно структурная. Но интерфейсы как раз помогают статическому чекеру.
Или наоборот, не превращаю простую абстракцию табличного вывода данных в кухонный комбайн
Так вы не путайте "абстракцию табличного вывода" и грид. Это два разных уровня.
1) Урезанный функционал, например нет переключения активных/удаленных задач
2) Меньше DOM/HTML, упрощенный HTML дает до +30% скорости (400 DOM элементов вместо 800 на список).
3) Упрощенные стили (CSS), это дает до +15% скорости рендеринга
4) Хитрый способ сохранения в localStorage + JSON.stringify, дает до +10% скорости, мы тут не скорость конвертирования JSON меряем, сохранение должно быть везде одинаково, либо убрано вообще.
Так что если вы приведете свое приложение в соответствие с остальными, то результат может заметно просесть.
Кстати ваше приложение как то не так работает в FireFox (как минимум у меня), не видно тасков в todo листе в момент тестирования. Судя по результатам вы в нем и тестировали.
А в Chrome у меня такие результаты после 3-х запусков (с последние версией Angular Light):

vintage, весь смысл проекта TodoMVC показать идентичный результат, через призму разных подходов. Вы не просто «упростили», как написал lega, вы даже не используете шаблоны и CSS предоставляемый TodoMVC. Ай-ай.
- Не дошли руки добавить, да, однако фильтрация через изменение адреса поддерживается. Это не сильно влияет на результат.
- Если тот же функционал можно реализовать меньшим числом элементов — это разве не плюс? Да и HTML не столь уж и проще. В решении на $mol используется 4 элемента на строку. В решении на AL — 5. Возможно вас смутило, что в решении на $mol рендерятся лишь те строки, что попадают в видимую область. Ну так это тоже плюс, а не минус.
- К сожалению, изначально стили там написаны через одно место, так что требуется их адаптация. Кроме того, там есть ещё и 2 версии дизайна. 15% к скорости отрисовки — возможно, но сомнительно. К общему времени выполнения — совсем крохи.
- Мы меряем общую скорость работы идиоматичного кода. На одних фреймворках удобнее хранить все данные одним огромным JSON-ом, на других — отдельными парами ключ-значение. В этом нет ничего хитрого или нечестного.
- Это прототип, а не готовое решение, в ИЕ и ФФ я ещё даже не запускал. Бенчмарки я гонял в Хроме. Там погрешность порядка 100мс, так что выигрывает то одно решение, то другое. Если последняя версия AL стабильно выигрывает, то жду пул-реквест. :-)
Да, TodoMVC не образец красивой верстки, но тогда нужно было бы сделать два вариант, первый как есть, а второй свой, но который выглядит точно также как и первый, только «правильно». А дальше хоть статью пиши, как можно упростить и выиграть в скорости просто оптимизировав верстку.
Визуализацию я подтяну, не волнуйтесь, внешне будет не отличимо.
Я пошёл по пути более грамотного построения процесса:
Это конечно правильно и хорошо, по возможности всегда так делаю, но прекрасно понимаю, что моё «правильно» и «правильно» другого разработчика, могут сильно различаться при работе с одним и тем же инструментом.
А не так, что верстальщик каждый раз присылает новый хтмл
Да, жизнь она такая и если для вас проблема использовать уже готовую верстку как есть, то возможно вам нужен другой инструмент.
Визуализацию я подтяну, не волнуйтесь, внешне будет не отличимо.
Вот с этого и нужно было начинать, только помимо визуализации, нужно и функционал привести в идентичное состояние.
При переходе на Angular, React, Meteor, Aurelia и так далее, я смогу использовать уже готовую верстку. Даже в Elm, можно загнать верстку или просто воспользоваться каким-нибудь elm-html.
Если тот же функционал можно реализовать меньшим числом элементов — это разве не плюс?Это плюс, но для большинства фреймворков можно оптимизировать HTML, что даст лучшие показатели. В итоге получается соревнование кто лучше HTML подпилит, а не скорость фреймворка (хотя они и составят основную часть). Чтобы было честно нужно для всех оптимизировать HTML, а это накладно. Поэтому, я считаю, как минимум нужно выкладывать «каноническую» версию, ну и для интереса можно оптимизированную прикладывать.
15% к скорости отрисовки — возможно, но сомнительно. К общему времени выполнения — совсем крохи.Общее время сокращается, например крайний случай — если отключить стили совсем то общее время выполнения снижается на ~30% (для AL).
жду пул-реквест. :-)Да, я ещё оптимизированную версию запилю, интересно :)
У меня время вообще в 2 раза уменьшается, но тут дело не в стилях как таковых, а в размере области рендеринга (в маленьком окне отключение стилей почти не влияет).
Но нет ничего эффективней, чем просто показать цирюльнику фотографию чистого подбородка, удобно расположиться в кресле и быть уверенным, что всё, что тот сделает — это просто сбреет вам бороду.
Я правильно понимаю, что достигается это подпиской на конкретные поля данных и перерендером/патчингом частей шаблона, которые на эти данные завязаны?
Он не зря имеет такой странный вид, ведь его можно скопировать и вставить в консоль, получив тем самым прямой доступ к инстансу компоненты, за этот элемент ответственнойТ.е. вы на каждый элемент создаете глобальную переменную?, это только в debug режиме?
Сферический идеальный фреймворкЯ правильно понял что все манипуляции вокруг tree формата (в основном) для того что-бы можно было наследовать шаблоны (и CSS)?, а JS/TS и так наследовать можно.
Т.е. вы на каждый элемент создаете глобальную переменную?, это только в debug режиме?Любой объект доступен по абсолютному пути, который и используется в качестве идентификатора. Это фича такая. Там ещё ссылки на объекты контролируются — когда на него не остаётся ссылок — он уничтожается. Вообще говоря, можно было бы сильно ускорить работу, если бы браузер предоставлял апи по отключению GC.
Я правильно понял что все манипуляции вокруг tree формата (в основном) для того что-бы можно было наследовать шаблоны (и CSS)?, а JS/TS и так наследовать можно.Наследование, биндинги, минимизация визуального шума, возможность объявлять и использовать компоненты изучив лишь один простой язык (он проще чем html, но даёт больше возможностей, и гораздо проще чем js).
биндинги
Хотел по биндингам задать вопрос, но сам нашел, получается в вашем случае когда нужно сделать текстовый биндинг (пример из Ангуляра)
Clear completed {{getCount()}}Вам нужно "переместить" этот кусок в js и "назначить" дополнительное имя для связывания, таким образом шаблон получается разорван на 2 части, часть в tree другая часть в ts, хотя это по видимому ViewModel, но проще это этого не стало, да и верстальщику от этого поплохеет — что-бы поправить текст на месте, нужно лести в дебри TS.
Кстати это не гибко т.к. (по видимому) нельзя даже параметр в эту ф-ию передать (например: {{getCount('active')}}, {{getCount('removed')}} )
минимизация визуального шума
С учетом того что к view еще нужно портянку в TS писать, шума тут явно больше (чем в том же ангуляре).
Вообщем мне кажется вы все усложнили в погоне за возможностью наследования, которая не часто и нужна (хотя может и нужна но не такой ценой).
Думаю проще было-бы сделать какой-нибудь трансформер html, например это
$my_panelExt : $my_panel childs
< header
< bodier
< footer : $mol_block childs < foot : nullМожно сделать как-то так:
myPanelExt = htmlTransform(myPanel, {
header: true,
bodier: true,
footer: foot()
})О! Я вспомнил, раньше модно было использовать XSLT, кажется вы изобретаете то же самое, только синтаксис другой.
Вам нужно «переместить» этот кусок в js и «назначить» дополнительное имя для связывания, таким образом шаблон получается разорван на 2 части, часть в tree другая часть в ts, хотя это по видимому ViewModel, но проще это этого не стало, да и верстальщику от этого поплохеет — что-бы поправить текст на месте, нужно лести в дебри TS.Текстами и не верстальщик должен заниматься. В общем случае тексты нужно будет переключать в зависимости от языка, не трогая шаблоны. Я ещё не продумывал этот аспект, но он точно не должен быть в шаблонах.
Кстати это не гибко т.к. (по видимому) нельзя даже параметр в эту ф-ию передать (например: {{getCount('active')}}, {{getCount('removed')}} )Идея в том, что шаблон не знает ничего про програмный код. Всё, что делает шаблон — это предоставляет слоты. А уже программист засовывает в эти слоты всё, что нужно.
С учетом того что к view еще нужно портянку в TS писать, шума тут явно больше (чем в том же ангуляре).Конкретно во view.tree его меньше, во view.ts ещё меньше сделать не получилось без ущерба для статической типизации.
Вообщем мне кажется вы все усложнили в погоне за возможностью наследования, которая не часто и нужна (хотя может и нужна но не такой ценой).Кастомизация нужна, прям очень. view.tree поддерживает наследование и агрегацию с мартышкиными патчами.
Думаю проще было-бы сделать какой-нибудь трансформер htmlИ статическая типизация идёт лесом. И верстальщик будет счастлив на JS шаблоны делать.
О! Я вспомнил, раньше модно было использовать XSLT, кажется вы изобретаете то же самое, только синтаксис другой.Polymer куда ближе к XSLT, он делает выборки из деревьев по селекторам.
ответить
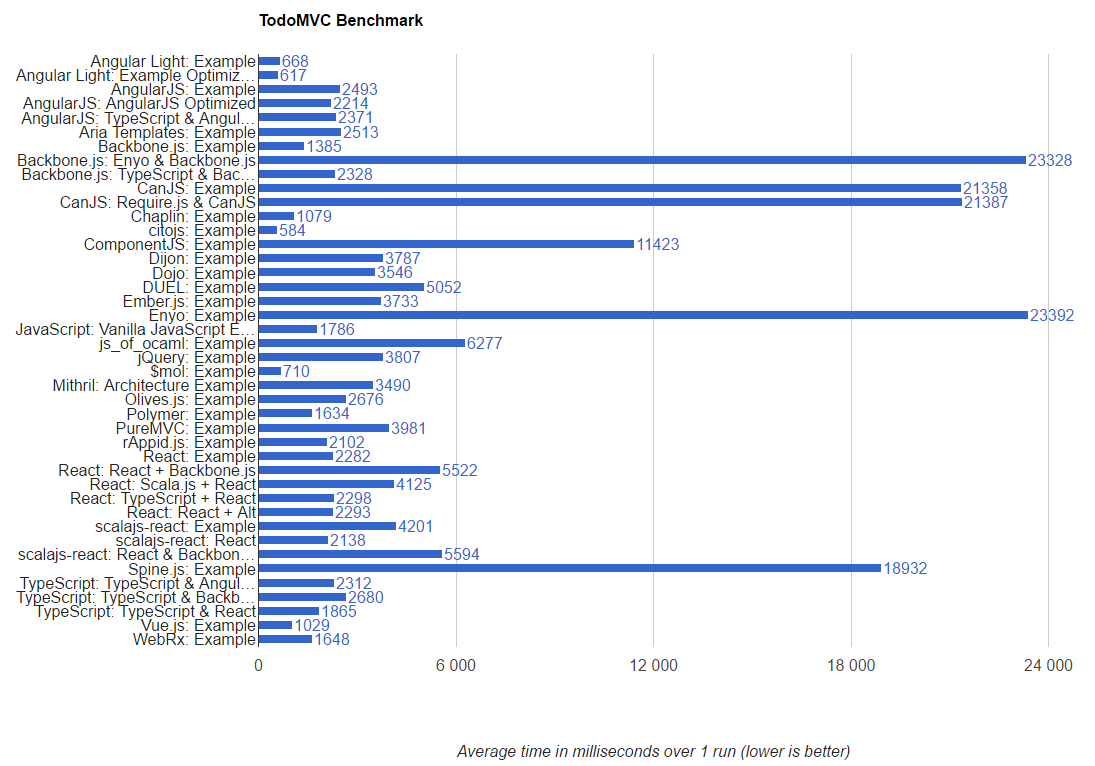
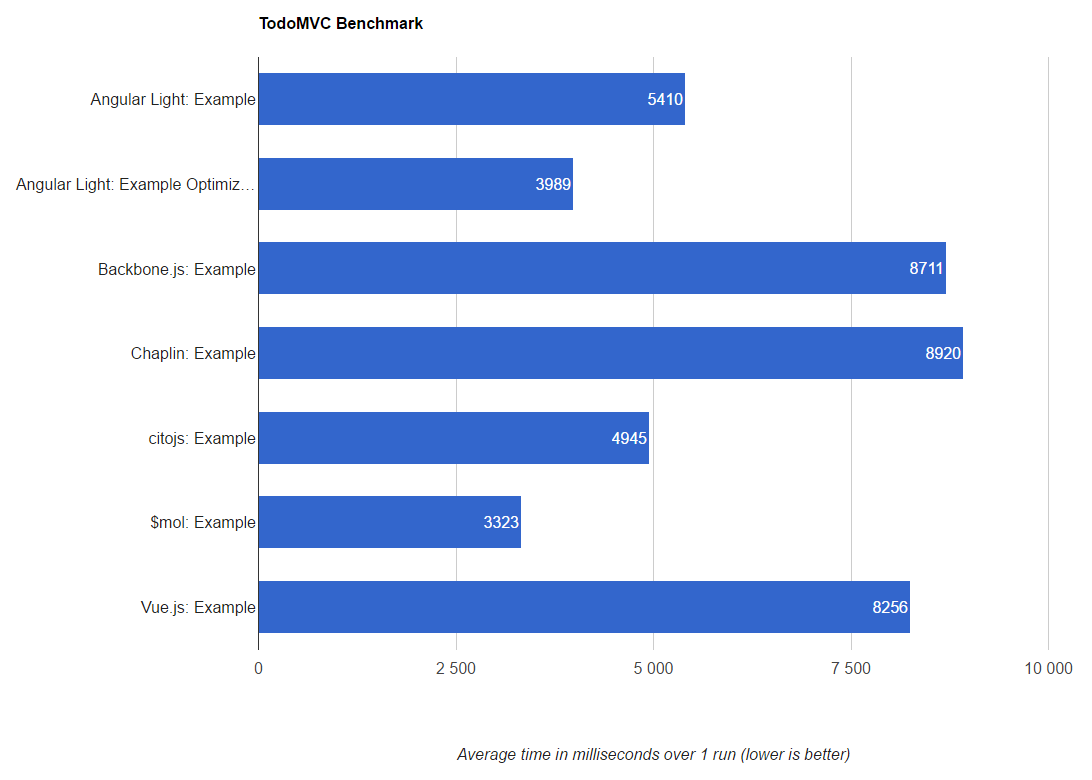
На данный момент результат такой (если сравнить с предыдущим скрином, видно что цифры немного ходят туда сюда).

Ответ для https://habrahabr.ru/post/276747/#comment_8784117

А что значит "не комплитит задачи"? Вручную все работает (да и на тесте тоже).
У меня вот на работе коллега написал ещё один JS-грид, он конечно по сути ничем не отличается от десятков других, но зато свой родной.
Мне даже нравится поддерживать такие начинания, особенно когда ты знаешь чем всё закончится.
Те же атомы — я написал свою реализацию в 160 строк и доволен как слон. Что касается фреймворков… нужна простота. минимальное количество кода, чтобы проще было скопипастить к себе исходники, чем читать документацию. Максимальная приближенность к голому хтмл и яваскрипту.
Мой тезис в том, что html + javascript плохо подходят для написания ui-компонент, в отличие от view.tree + typescript. html позволяет лишь передать элементу в качестве параметров лишь набор текстовых пар "ключ-зачение" и не более одного анонимного html-поддерева. А требуется-то и несколько именованных поддеревьев передавать, от чего возникают костыли со вложенными элементами, выносом параметров в отдельные функции и выборками по селектору. js код сложно исследовать — только в отладчике можно узнать наверняка какие поля есть у того или иного объекта.
А вот html… пытаться от него изолироваться, имхо, бесполезное дело. Но я до сих пор не уверен, как делать правильно. Возможно, использование компонента не обязано быть единственным тегом? Как в старые добрые времена jquery — мы пишем разметку, а потом она "оживает". типа: <div class=tabs activeTab={activeTab}><div class=tab></div><div class=tab></div></div>. Не знаю.
$my_app : $my_tab_list
activeTab < activeTab < first
child < tabs
< first : $my_tab
< second : $my_tab
100 задач:
400 задач:
Я считаю, что всегда будет библиотека ХХХ, которая быстрей, так что главное сделать у себя так, чтобы замена движка не вызывала попоболь, вот и всё.
По поводу «табличного процессора». Под такую задачу, с вероятностью 100% это будет
canvas, а ячейки пересчитывать в едином цикле. Хотя возможно я бы попробовал какие-то элементы RP, взял бы а какую-нибудь уже готовую библиотеку, вроде reactor.js, хотя думаю единый цикл будет эффективнее.жёсткая реализация на коленке с рендерингом через vdom, которая по мере усложнения приложения будет всё больше тормозить и течь
Ровно это я думаю о когда вижу атомы и год на них, без обид, это только мой вгляд со стороны. А не видя тестов, покрытия и какого либо крупного проекта только убеждаюсь в этом.
гибкая реализация с атомами, с меньшей алгоритмической сложностью.
По моему этом само обман, серьезно, неявные связи атомов, это бич всего RP, которая в итоге приводит к необоснованному росту обсерверов.
Опять же, если RP это прямо-таки «серебренная пуля», почему нет крупных игроков? Да, есть Метеор, но там всё совсем не так гладко, а Blaze выпиливают в угоду React. В итоге имеем только Rx, да Beacon.
P.S. Но, я всё равно желаю вам удачи, это хорошая тема для исследования, но я бы всё попытался отточить сами атомы и скомбинировать их уже с каким-то готовым решением, а не пилить абсолютно всё своё, это путь в никуда.
А я вот считаю, что нет смысла разрабатывать отдельную библиотеку с тем же интерфейсом, а лучше взять существующую и улучшить её.
Зачем тут canvas? И каким таким образом canvas спасёт вас от необходимости перевычислять значения всех ячеек на каждый чих? Может и от stack overflow он как-то поможет при длинных зависимостях между ячейками? Ну а касательно reactor.js — вы фактически признали ущербность подхода "перевычисляем всё на каждый чих", ибо reactor.js — это крайне урезанная версия атомов.
Вы видите основания для тормозов и утечек по мере роста приложения в случае $mol_view? Я бы с радостью про них послушал. Аргумент "сперва добейся" пропустим.
Опять же, можете обосновать откуда может взяться необоснованный рост обсерверов? Может я не вижу каких-то очевидных вещей? Может не всегда A зависит от B и C при A=B+C?
А может беда не в RP, а в том, что метеор имеет кривую архитектуру?
Комбинировать атомы легко с чем угодно. Для интероперабельности атомы поддерживают интерфейсы обсерверов (on) и промисов (then,catch). На прошлом проекте я, например, комбинировал их с angular. Правда сам ангуляр был как пятая нога — зачем делать грязную проверку всего скоупа, если и так известно какие свойства поменялись?
А по вашей логике авторы inferno и citojs тоже глупостями занимаются, ибо вместо того, чтобы просто взять готовый и протестированный react
Нет, citojs не замена, а дополнение, его можно использовать в качестве альтернативы
React.createElement.Что ж вы, кстати, не воспользовались inferno?
Нет поддержки IE8.
Ну а касательно reactor.js — вы фактически признали ущербность подхода "перевычисляем всё на каждый чих", ибо reactor.js — это крайне урезанная версия атомов.
Как это признал, я же написал, что буду использовать
cavnas и единый цикл, как раз перерисовка всего и вся на каждый чих. А cavnas, потому что DOM под такую задачу не годиться, слишком медленный и не удобный. Сейчас даже проверил, Spreadsheets гугловый наконец-то переделали на canvas, вроде меньше тормозить стал. Осталось Docs ещё переделать, уверен что они либо это уже делают, либо сделают скоро.Вы видите основания для тормозов и утечек по мере роста приложения в случае $mol_view?
Мне и не нужно это видеть, многое говорит банальное отсутствие покрытия тестами и реальных приложений. И в целом JS не любит обилие функций, поэтому kvo плетется позади банального «перерисуем всё».
Аргумент "сперва добейся" пропустим.
Не понял, к чему это? Вот вы сами говорите, что $mol — это прототип, но при каждом удобном случае предлагаете попробовать атомы. И вам каждый раз отвечаю, что проще «перерисовывать всё». Неоднократно писал, что все примеры, которые я видел с реактивщеной надуманы и перегружены. Взять ваш же пример TodoMVC и мой, какой из них тупа короче и использует меньше библиотек? Да и просто по общему общему кода меньше, м? Для меня идеальный фрейворк, тот, который легко заменим.
Опять же, можете обосновать откуда может взяться необоснованный рост обсерверов?
Мне сейчас тяжело сформировать пример чтобы показать что я имею ввиду. Главное я не имел ввиду, что атомы кто-то криво работают, просто если я правильно понимаю, при их использовании они образую две связи «от кого завися» и «кто от них зависит», вот тут и «проблема» (в кавычках).
А может беда не в RP, а в том, что метеор имеет кривую архитектуру?
Может. И самая большая ошибка была в том, что они сделал абсолютно «всё своё», так слона не продать.
Как вы ловко перескакиваете с обсуждения архитектуры на конкретные решения и обратно, а также сравниваете полноценный фреймворк с библиотекой для рисования. Судя по тестам, что я привёл выше, недоделанный и толком даже не оптимизировавшийся $mol_view уделал citojs на 400 задачах. Это называется "kvo далеко позади"? Есть такой показатель как "алгоритмическая сложность". И у vdom сложность обновления зашкаливает
O(DataSize*AppComplexity*DOMSize). В случае атомов она куда меньше O(SubAppComplexity).Реализация на citojs: 6.2кб без учёта транспиляции в js и собственно citojs.
Реализация на $mol_view: 5кб без учёта транспиляции и не относящихся к $mol_app_todo модулей.
Общий объём скомпилированного кода со всеми библиотеками оценить сложно, ибо вы и использовали babel, который секунду только компилирует приложение при загрузке. В любом случае, ваша реализация представляет из себя один единственный шаблон на всё приложение и гигантский свич на все действия пользователя, что, мягко выражаясь, не особо поддерживаемо, ибо порождает горы копипасты. Для сравнения: шаблон у вас весит 3кб, а у меня 1кб.
И что плохого в том, что каждый атом знает от кого зависит и кто зависит от него? Это позволяет легко и просто контролировать время жизни объектов и не дёргать лишние пересчёты на каждый чих.
Если тянуть с собой мегабайт зависимостей — такого слона продать не менее сложно.
У меня вопрос, как замеры делаете? А то мне кажется мое f12 в Chrome кажется совсем колхозным решением.
Почему же, вполне хорошее решение. Правда вносит свои погрешности. Например, работающий профилировщик может снижать частоту кадров, из-за чего бенчмарк может начать "летать", работая вхолостую. Поэтому лучше всё же, замерять какие-то реалистичные сценарии. Например, время перехода с одной сложной страницы на другую.
Вы описали проблемы и возможные их решения. Но кто-то не столкнется и с десятой частью этих проблем, а для кого-то наоборот — здесь нет и десятой части их проблем.
Помните раньше было выражение — сферический конь в вакууме, вспомнилось :)
Про todomvc — какой оценивать реальную производительность фреймворка по этому показателю?
Думаете кто то реально будет использовать фреймворк на 1мб для реализации подобных задач?
Почти любой разраб реализует эту задачу на vanila.js более качественно чем с фреймворком.
А на более сложных задачах все будет в большей степени зависеть от конкретной реализации, в меньшей степени от фреймворка.
Если отрисовка и фпс — самый критичный фактор — вряд ли кто то вообще будет использовать фреймворк, т.к. нативная реализация будет заведомо более оптимизируемой и контролируемой.
Про todomvc — какой оценивать реальную производительность фреймворка по этому показателю?
К сожалению, нет никакой "реальной производительности фреймворка". Есть только отзывчивость конкретных написанных с его помощью приложений в конкретных сценариях использования. Десятикратная разница в отзывчивости между реализациями на разных фреймворках в большей степени следствие архитектурных особенностей этих фреймворков.
Думаете кто то реально будет использовать фреймворк на 1мб для реализации подобных задач?
Это уже происходит, ибо с фреймворком разработка идёт быстрее.
Почти любой разраб реализует эту задачу на vanila.js более качественно чем с фреймворком.
Почему же тогда VanillaJS реализация существенно проигрывает половине фреймворков? Ассемблер Ванильный яваскрипт позволяет талантливому разработчику написать быстрое приложение. Си++ Фреймворк позволяет посредственному разработчику написать приложение не хуже за вдвое меньшее время.
А на более сложных задачах все будет в большей степени зависеть от конкретной реализации, в меньшей степени от фреймворка.
Только если вы сначала продумываете архитектуру, а потом подбираете/пишите для неё фреймворк. Но зачастую сначала выбирают фреймворк, а потом он диктует архитектуру приложения.
Если отрисовка и фпс — самый критичный фактор — вряд ли кто то вообще будет использовать фреймворк, т.к. нативная реализация будет заведомо более оптимизируемой и контролируемой.
Почему же игры (где за низкий фпс вас закидают геймпадами) поголовно делаются на фреймворках (так называемых "движках")?
>К сожалению, нет никакой «реальной производительности фреймворка».
вот именно, вам говорят о том же, к чему ваши ссылки на тудумвц бенчмарки?
Почему же тогда VanillaJS реализация существенно проигрывает половине фреймворков?
вы про реализацию чего говорите?
Прочитал статью и первый вопрос который возник — идеальный фреймворк для чего?
Идеальный UI фреймворк