Comments 74
96% процентов в состоянии реализовать Binary search, интересно сколько из них перед тем как проголосовать загуглили что это вообще такое? Понимаю что это самое простое что только может быть, но если щас поймать любого из коллег и спросить что это — никто не ответит
Алгоритмы использовал только для задач в вакууме типа codingame, в основном связанные с графами и деревьями. В вебе даже и не припомню, чтобы пригодились хоть раз
Алгоритмы использовал только для задач в вакууме типа codingame, в основном связанные с графами и деревьями. В вебе даже и не припомню, чтобы пригодились хоть раз
Я бы ответил — на первом-втором курсе решали задачи из уже не помню какого задачника на разных языках.
Другое дело что это мне пока действительно еще ни разу не пригодилось — большая часть уже реализована в стандартных библиотеках.
Другое дело что это мне пока действительно еще ни разу не пригодилось — большая часть уже реализована в стандартных библиотеках.
Если бы меня спросили, что такое бинарный поиск, я бы ответил. А вот прочитал Binary search и тупил минуту…
Да, согласен, это странно...
Да, согласен, это странно...
Потому что это как, если бы, инженеру при обучении рассказали бы как создать велосипед. Большая часть инженеров, никакие велосипеды не создаёт, а занимается на работе совсем другим. Но, изучение инженерных решений использующихся в велосипедах — полезно в качестве учебного примера.
Поясню, хороший инженер — это:
— не тот, кто вызубрил «10 стандартных велосипедов», не понимая как они работают,
— и не тот, кто смотрит на велосипед как на новые ворота,
А тот кто зная как они и почему работают, может
— починить чужой незнакомый велосипед (умение разбираться в чужом коде)
— а в случае необходимости создать свой велосипед под желаемые требования.
— не тот, кто вызубрил «10 стандартных велосипедов», не понимая как они работают,
— и не тот, кто смотрит на велосипед как на новые ворота,
А тот кто зная как они и почему работают, может
— починить чужой незнакомый велосипед (умение разбираться в чужом коде)
— а в случае необходимости создать свой велосипед под желаемые требования.
В вебе binary search пригодился когда пришлось на highstock-е (график с несколькими сериями и большим количеством значений) искать точку в исходном массиве чтобы вывести больше данных о ней в попапе.
Результаты опроса следует читать так: 96% людей считают, что могут реализовать binary search. Впрочем, написанный ими код наверное будет иногда работать https://habrahabr.ru/post/203398/
Кстати, в этой части можно отнести положительное влияние реализации таких алгоритмов на итераторах, в частности, в C++, где тебя просто вынуждают написать:
или, для более широкого круга итераторов:
auto mid = start + std::distance(start, end) / 2;или, для более широкого круга итераторов:
auto mid = start;
std::advance(mid, std::distance(start, end) / 2);"Более широкий круг итераторов" — это что?
Бинарный поиск на связных списках? :)
Бинарный поиск на связных списках? :)
http://www.cplusplus.com/reference/iterator/
первый вариант подходит для RandomAccess, второй будет работать и для Bidirectional и, даже, Forward
первый вариант подходит для RandomAccess, второй будет работать и для Bidirectional и, даже, Forward
Собственно, почему бы и нет? Если сравнение намного медленнее, чем проход по списку (например, сравнение алгебраических чисел или работа в интервальной арифметике), то бинарный поиск вполне оправдан.
Думаю для чистоты эксперимента можно было добавить пару фейковых алгоритмов )
Вот честный ответ: "Я не могу написать бинарный поиск"
Спецификация в данном случае описание принципа работы?
Скорее да.
То есть я правильно понимаю, что если не могу переизобрести RBTree, а как именно черный дядя с красным племянником взаимодействуют не помню, то галочку не ставлю?
Рассматривайте этот вопрос, как задачу спортивного программирования. Есть входные данные, есть ожидаемые выходные. Есть ограничения по памяти и времени, т.е. если вместо сбалансированного дерева будет обычное, то так случится, что оно обязательно выродится в список для хотя бы одного из наборов входных данных и сложность вырастет с логарифмической до линейной, программа вылете по timeout. И нужно написать код, который пройдет все тесты. Если считаете, что написали — галочку ставите.
Я не помню все типы алгоритмов, но если посмотрю описание, то реализовать смогу. Тогда уж не хватает опроса: знаете ли вы в каких задачах используются данные алгоритмы или наоборот с помощью какого алгоритма вы бы реализовывали определенную задачу.
В универе делал модифицированный алгоритм быстрой сортировки, который сортирует только по краям массива, для лабораторной по визуализации опытов Пирсона. Надо было обозначить в результатах опытов некоторый рукав недалеко от верхней и нижней границы, который укладывается в заданную вероятность. Думаю, у кого-нибудь в работе могут быть похожие задачи.
А по работе не приходилось.
А по работе не приходилось.
картинка
Подробностей не помню, помню, что решил сортировать массив отклонений от теоретической вероятности в сериях для каждого номера опыта, и оно даже с quicksort почему-то долго работало.

Подробностей не помню, помню, что решил сортировать массив отклонений от теоретической вероятности в сериях для каждого номера опыта, и оно даже с quicksort почему-то долго работало.
Частота появления орла
Первые несколько секунд тупил. Про эксперимент без гугла не вспомнил, поэтому чего-то показалось, что связано с Толкиеном.
Алгоритм Гэндальфа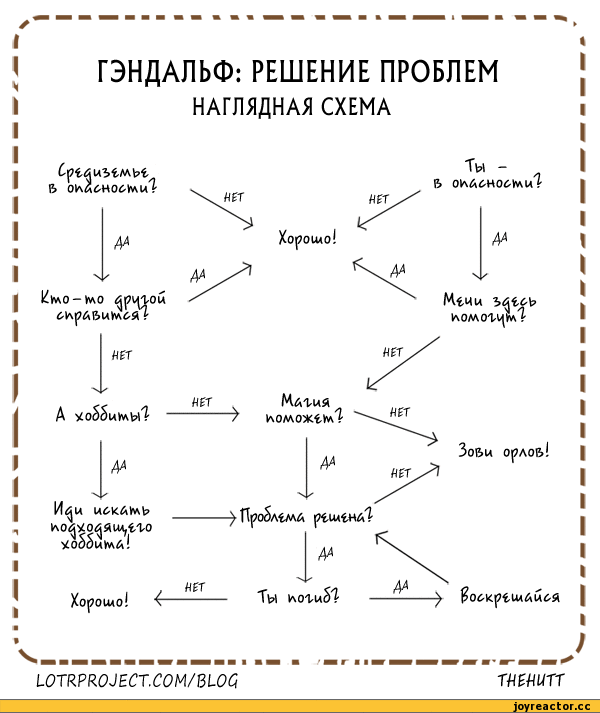
П.С.: Благодаря опросу осознал, чего я стою без гугла. Почти ничего не стою. Грустно. Нужно ботать.
Нам платят не за забивание головы тем, что гуглится за 5 минут. Ничего грустного в этом нет — наоборот, больше места в памяти для хранения уникальных знаний и навыков. Помните Шерлока Холмса, который не знал устройство солнечной системы, зато знал сотни сортов табака? :)
Это тоже да, тоже верно. Но на собеседованиях так не ответишь если всякую хитроту спрашивают. Я сейчас не про опыт Пирсона конкретно говорю, а просто о сложных вещах, которые спрашивать любят (особенно если в компетенция "strong algo skills" указан). Так что при смене работы всё равно приходится читать.
Помните Шерлока Холмса, который не знал устройство солнечной системы, зато знал сотни сортов табака?
Конан Дойл, выражаясь современным языком, стебался.
UFO just landed and posted this here
А теперь представьте, что вы — PHP-программист и ваша regexp библиотека выглядит вот так. И?
Если среди средств решения задачи у вас в принципе не предусмотрено "создание regex'а"?
Все эти споры — абсолютно бесполезны, по большому счёту. Просто потому что происходят между людьми живущими в разных мирах. В вашем проблема с тормозами сервиса может быть решена, в мире, где "живут" 90% (если не 99% программистов) — она решена быть не может. В принципе. Никак.
Ну и зачем им алгоритмы?
Если среди средств решения задачи у вас в принципе не предусмотрено "создание regex'а"?
Все эти споры — абсолютно бесполезны, по большому счёту. Просто потому что происходят между людьми живущими в разных мирах. В вашем проблема с тормозами сервиса может быть решена, в мире, где "живут" 90% (если не 99% программистов) — она решена быть не может. В принципе. Никак.
Ну и зачем им алгоритмы?
Приходилось реализовывать Hierarchical k-mean на Java. Задача кластеризации SIFT-дескрипторов. Стандартный k-means довольно медленный и не параллельный (есть в Apache Math), но вот иерархического так и не смогли найти, пришлось писать.
Алгоритмы знать — хорошо, обязательно — нет. Алгоритмы те или иные ты используешь повседневно, да ты не пишешь свою реализацию. Хороший мастер должен знать свои инструменты.
Всё это сильно зависит от области, в которой работает программист.
Ну вот примеры из моей практики (у меня специальность — машинное зрение в области рентгеновского неразрушающего контроля):
Довольно много задачек было, где требовалась, скажем математическая морфология, но реализовывать самому ничего не пришлось — есть же библиотеки, нужно лишь знание того, как работыает замыкание, размыкание, и т.п. В учебных целях безусловно имеет смысл реализовать что-то самому, но в продакшене это не нужно. Вообще в обработке изображений алгоритмы более-менее известны и "устаканились", самое главное — "чувствовать" когда применить тот или иной алгоритм, ну и на раннем этапе понять "взлетит или нет" и не упираться в тупиковую ветвь — а это с опытом приходит.
Сейчас нет большого смысла в умении реализовать тот или иной алгоритм на низком уровне "из головы" — есть куча библиотек, где уже всё реализовано (ну разве что целью разработки не является собственно библиотека). Важно избегать бездумного применения применения тех или иных методов "авось получится" — для этого надо просто понимать как алгоритмы работают и области их применения. Если вы поднимете меня среди ночи и попросите реализовать восемь алгоритмов сортировки или там построить фурье спектр сигнала, то я скорей всего не смогу сделать это, не подглядывая в справочник, но в повседневной работе это совершенно не мешает.
Ну вот примеры из моей практики (у меня специальность — машинное зрение в области рентгеновского неразрушающего контроля):
- регистрация рентгеновских изображений (в смысле нахождение аффинного преобразования между эталонным и текущим изображением). Тут я воспользовался классическим преобразованием Фурье-Меллина — оно сразу выдаёт необходимые значения.
- точная приводка спиц колёсных дисков — тут строились два "циркулярных" профиля с центром в ступице и затем анализировалась корреляция между профилями
- реализация алгоритма распознавания типов литых колёсных дисков по стереоизображению (строилась карта глубины, затем сравнивались фурье спектры текущего диска и дисков в базе данных)
- поиск дефектов на основе медианной фильтрации — тут пришлось воспользоваться алгоритмом Хуанга (его ещё "бегущей медианой" называют) для обеспечения возможности работы фильтра в реальном времени, ну и в зависимости от значения градиента динамически менялось ядро фильтра.
- реализация тренированного медианного фильтра — это когда ядро "размазано" по всей картинке.
- оптимизация перемещения робота-манипулятора для достижения минимального времени проверки — тут вообще классика с обходом графа, по сути задача коммивояжера.
Довольно много задачек было, где требовалась, скажем математическая морфология, но реализовывать самому ничего не пришлось — есть же библиотеки, нужно лишь знание того, как работыает замыкание, размыкание, и т.п. В учебных целях безусловно имеет смысл реализовать что-то самому, но в продакшене это не нужно. Вообще в обработке изображений алгоритмы более-менее известны и "устаканились", самое главное — "чувствовать" когда применить тот или иной алгоритм, ну и на раннем этапе понять "взлетит или нет" и не упираться в тупиковую ветвь — а это с опытом приходит.
Сейчас нет большого смысла в умении реализовать тот или иной алгоритм на низком уровне "из головы" — есть куча библиотек, где уже всё реализовано (ну разве что целью разработки не является собственно библиотека). Важно избегать бездумного применения применения тех или иных методов "авось получится" — для этого надо просто понимать как алгоритмы работают и области их применения. Если вы поднимете меня среди ночи и попросите реализовать восемь алгоритмов сортировки или там построить фурье спектр сигнала, то я скорей всего не смогу сделать это, не подглядывая в справочник, но в повседневной работе это совершенно не мешает.
Частенько приходится писать DFS или топологическую сортировку. Библиотечные реализации не подходят просто потому что на сведение задачи к стандартному виду потребуется больше времени чем на написание DFS :)
Мне больше по работе приходилось реализовывать всякие штуки из аналитической геометрии.
В сортировках надо бы добавить LSD и MSD Radix Sort, в поиске Knuth-Morris-Pratt (по мне так самый гениальный алгоритм из базовых) и Boyer-Moore, в графах Minimum cut и Topological order.
Опрос по поводу Boyer-Moore даст некорректные результаты — у этого алгоритма есть аж 4 варианта, и в очень многих учебниках приводится лишь самый простой из них.
Поэтому между "читатель думает что знает алгоритм Бойера-Мура" и "читатель знает алгоритм Бойера-Мура" лежит огромная пропасть.
Поэтому между "читатель думает что знает алгоритм Бойера-Мура" и "читатель знает алгоритм Бойера-Мура" лежит огромная пропасть.
И у квиксорта тоже несколько вариантов и модификаций, а некоторые небезызвестные люди вроде Robert Sedgewick и вовсе диссертацию по нему защитили. С таким же успехом можно к большому количеству алгоритмов придраться… Или Вы действительно думаете, что у этого опроса высокая точность? :)
Первый раз увидел Maximum subarray problem, и почему-то подумал, что это и есть КМП, о котором я представление имею, потому и поставил там галку. На самом деле её ставить не стоило.
"Maximum subarray problem" обычно попадает туда же, куда и Дейкстра: не бывает хороших программистов, не умеющих подобный алгоритм реализовать, но бывают хорошие программисты, не умеющие его назвать.
Вопрос для "Дейкстры": как пойдёт юнит в Цивилизации, если его задача — дойти максимально быстро до точки, куда его послали? Hint: Убедитесь что ваш модуль объезжает болото по железной дороге если это выгодно и прёт напролом, если железная дорога слишком длинна.
Вопрос для "maximum subarray problem" — собственно формулировка задачи.
Вопрос для "Дейкстры": как пойдёт юнит в Цивилизации, если его задача — дойти максимально быстро до точки, куда его послали? Hint: Убедитесь что ваш модуль объезжает болото по железной дороге если это выгодно и прёт напролом, если железная дорога слишком длинна.
Вопрос для "maximum subarray problem" — собственно формулировка задачи.
Как раз на прошлой неделе делал STL совместимый DFS-итератор над Gumbo.
Большая часть уже и так отлична описана в книге Algorithms, 4th Edition (http://algs4.cs.princeton.edu/home/) и по ним есть курс на Coursera. Интересно почитать про графы
Алгоритмов сортировки маловато
http://youtube.com/watch?v=rQtereWDc24&feature=youtu.be
1. Selection Sort
2. Insertion Sort
3. Quick Sort (LR pointers)
4. Merge Sort
5. Heap Sort
6. Radix Sort ( LSD )
7. Radix Sort ( MSD )
8. std::sort (gcc)
9. std::stable_sort (gcc)
10. shell sort
11. bubble sort
12. Cocktail Shaker Sort
13. Gnome Sort
14. Bitonic sort
15. Bogo Sort
http://youtube.com/watch?v=rQtereWDc24&feature=youtu.be
1. Selection Sort
2. Insertion Sort
3. Quick Sort (LR pointers)
4. Merge Sort
5. Heap Sort
6. Radix Sort ( LSD )
7. Radix Sort ( MSD )
8. std::sort (gcc)
9. std::stable_sort (gcc)
10. shell sort
11. bubble sort
12. Cocktail Shaker Sort
13. Gnome Sort
14. Bitonic sort
15. Bogo Sort
Если интересны примеры из практики — при разработке на низком уровне иногда алгоритмы разные нужны позарез, а никаких библиотек нет и не предвидится. Чаще всего получается портировать существующий код, но его проще написать заново с учетом всех ограничений.
К примеру, в фазе PEI BeforeMem кучи нет совсем, а стека настолько мало, что большая часть параметров передается через регистры, а вызов функций происходит через прямой переход по известному адресу (т.е. все исполняемые файлы в этой фазе — XIP). Тем не менее, однажды пришлось реализовывать в таких условиях алгоритм Бойера-Мура-Хорспула.
В фазе DXE уже есть куча и много-много памяти, но нет стандартной библиотеки, поэтому некоторые вещи все равно приходится переписывать или портировать, недавно занимался реализацией функции Argon2 в виде DXE-драйвера, к примеру. Из менее "серьезных алгоритмов" — иногда нужны конечные автоматы (для драйверов устройств), сортировки (там же, плюс список загрузочных устройсв надо иногда сортировать, но там хватает вообще любого алгоритма почти всем), разные виды поиска, в общем — вроде бы мелочь, но всю её приходится писать самому, т.к. библиотек никаких нет.
К примеру, в фазе PEI BeforeMem кучи нет совсем, а стека настолько мало, что большая часть параметров передается через регистры, а вызов функций происходит через прямой переход по известному адресу (т.е. все исполняемые файлы в этой фазе — XIP). Тем не менее, однажды пришлось реализовывать в таких условиях алгоритм Бойера-Мура-Хорспула.
В фазе DXE уже есть куча и много-много памяти, но нет стандартной библиотеки, поэтому некоторые вещи все равно приходится переписывать или портировать, недавно занимался реализацией функции Argon2 в виде DXE-драйвера, к примеру. Из менее "серьезных алгоритмов" — иногда нужны конечные автоматы (для драйверов устройств), сортировки (там же, плюс список загрузочных устройсв надо иногда сортировать, но там хватает вообще любого алгоритма почти всем), разные виды поиска, в общем — вроде бы мелочь, но всю её приходится писать самому, т.к. библиотек никаких нет.
63% могут реализовать удаление из BST. Что, правда?
Знание binary_search понадобилось на работе не так давно.
Дело в том, для нашего языка
a) нет библиотеки с ним ( да, вот так тоже бывает)
b) нужно было даже не сам бинари_серч закодить, а генератор таких бинари-серчей для разных классов объектов ( т.е. даже наличие библиотеки не помогло бы, это такое слабое ООП в языке).
ДП как-то приходилось реализовывать в рабочем коде, DFS, еще что-то. Но конечно такой экскурс в университетские годы бывает не чаще раза в год, к сожалению :(. С другой стороны обычно знание таких вещей удивляет коллег. Тут вот все написали что все знают — на практике почему-то у меня не так, как применить в реальных задачах не видят частенько.
Дело в том, для нашего языка
a) нет библиотеки с ним ( да, вот так тоже бывает)
b) нужно было даже не сам бинари_серч закодить, а генератор таких бинари-серчей для разных классов объектов ( т.е. даже наличие библиотеки не помогло бы, это такое слабое ООП в языке).
ДП как-то приходилось реализовывать в рабочем коде, DFS, еще что-то. Но конечно такой экскурс в университетские годы бывает не чаще раза в год, к сожалению :(. С другой стороны обычно знание таких вещей удивляет коллег. Тут вот все написали что все знают — на практике почему-то у меня не так, как применить в реальных задачах не видят частенько.
К сожалению, подобные опросы не имеют смысла по многим причинам. Вот некоторые из них.
Во-первых, здесь перечислены далеко не все алгоритмы, которые нужны разработчикам библиотек низкого уровня. Скажем, в моём репертуаре свыше 50 алгоритмов, каждый из которых может быть реализован разными способами в зависимости от конкретной ситуации. Например, бинарный поиск — 5 основных вариантов. Задача о максимальном потоке (которой у вас почему-то нет) — 14 различных алгоритмов. Транспортная задача (у вас тоже нет) — 4 алгоритма и т. д
Во-вторых, едва ли участники опроса хорошо представляют себе свои собственные способности в вопросе кодирования алгоритмов. Например, большинство уверено, что бинарный поиск им по плечу, однако здесь же на хабре есть статья, которая рассказывает о том, почему только 10% программистов могут его правильно реализовать. И вообще, это не только на хабре, это в принципе известный феномен — переоценка своих способностей.
Почему так получается? Потому что нельзя путать программистов из IT сферы, которые пишут код как будто собирая конструктор из деталей, и программистов из сферы разработки этих самых конструкторов. Это абсолютно разные сферы, настолько разные, что далеко не всегда люди из этих сфер могут понять друг друга. Я отношусь к числу разработчиков библиотек. Люди вроде меня пишут эти самые boost, gmp, stl и прочие инструменты, вплоть до новых языков программирования и мы обязаны знать математику, лежащую в основе всех этих алгоритмов, а также знать все классические алгоритмы в их многообразных формах и вариантах взаимодействия. Но спросите меня как пропатчить kde под freebsd, я буду в полной растерянности, и то же самое будет, если меня попросят написать простенький калькулятор с кнопочками для windows или просто любой софт — я в этом просто не разбираюсь, хотя и мог бы научиться.
Короче, вывод. При решении обычных IT задач вроде создания софта нужно искать готовые библиотеки, уже отлаженные и переотлаженные профессионалами. При решение новых сложных научных задач и при создании мощных высокопроизводительных библиотек нужно писать свой код.
Ранее я занимался усиленно наукой и в моих задачах нужно было выполнять сверхсложные вычисления. Так вот, первое правило было — никаких сторонних библиотек, всё пишется под конкретную задачу с максимально жёсткой оптимизацией. В результате обогнать алгоритмы из stl в 10-100 раз не составляло труда (повторюсь, на конкретной задаче, а не в общем случае). Но в обычных задачах, где пишется софт — эти оптимизации не нужны. Вряд ли кому-то в пользовательском мире захочется запустить программу расчёт каких-нибудь состояний макромолекулы, получая на выходе числа, размером до сотен миллионов знаков, и выводить формулы, запись которых не умещается на жёсткий диск, правда?: )
Во-первых, здесь перечислены далеко не все алгоритмы, которые нужны разработчикам библиотек низкого уровня. Скажем, в моём репертуаре свыше 50 алгоритмов, каждый из которых может быть реализован разными способами в зависимости от конкретной ситуации. Например, бинарный поиск — 5 основных вариантов. Задача о максимальном потоке (которой у вас почему-то нет) — 14 различных алгоритмов. Транспортная задача (у вас тоже нет) — 4 алгоритма и т. д
Во-вторых, едва ли участники опроса хорошо представляют себе свои собственные способности в вопросе кодирования алгоритмов. Например, большинство уверено, что бинарный поиск им по плечу, однако здесь же на хабре есть статья, которая рассказывает о том, почему только 10% программистов могут его правильно реализовать. И вообще, это не только на хабре, это в принципе известный феномен — переоценка своих способностей.
Почему так получается? Потому что нельзя путать программистов из IT сферы, которые пишут код как будто собирая конструктор из деталей, и программистов из сферы разработки этих самых конструкторов. Это абсолютно разные сферы, настолько разные, что далеко не всегда люди из этих сфер могут понять друг друга. Я отношусь к числу разработчиков библиотек. Люди вроде меня пишут эти самые boost, gmp, stl и прочие инструменты, вплоть до новых языков программирования и мы обязаны знать математику, лежащую в основе всех этих алгоритмов, а также знать все классические алгоритмы в их многообразных формах и вариантах взаимодействия. Но спросите меня как пропатчить kde под freebsd, я буду в полной растерянности, и то же самое будет, если меня попросят написать простенький калькулятор с кнопочками для windows или просто любой софт — я в этом просто не разбираюсь, хотя и мог бы научиться.
Короче, вывод. При решении обычных IT задач вроде создания софта нужно искать готовые библиотеки, уже отлаженные и переотлаженные профессионалами. При решение новых сложных научных задач и при создании мощных высокопроизводительных библиотек нужно писать свой код.
Ранее я занимался усиленно наукой и в моих задачах нужно было выполнять сверхсложные вычисления. Так вот, первое правило было — никаких сторонних библиотек, всё пишется под конкретную задачу с максимально жёсткой оптимизацией. В результате обогнать алгоритмы из stl в 10-100 раз не составляло труда (повторюсь, на конкретной задаче, а не в общем случае). Но в обычных задачах, где пишется софт — эти оптимизации не нужны. Вряд ли кому-то в пользовательском мире захочется запустить программу расчёт каких-нибудь состояний макромолекулы, получая на выходе числа, размером до сотен миллионов знаков, и выводить формулы, запись которых не умещается на жёсткий диск, правда?: )
Вот хотя бы ради того, чтобы вы написали этот комментарий, такие опросы нужно делать. Благодаря ему картина мира в этой области стала более четкой и вырисовалось дальнейшее направление движения, спасибо!
Раз Вы считаете, что мой ответ полезен, могу его дополнить.
В-третьих, от того, каким будет распределение голосов на таком опросе ровным счётом ничего не зависит. Если опрос покажет, что программисты должны изучать алгоритмы, то никто не побежит покупать книги вроде (простейших) Т. Кормена "Алгоритмы. Построение и анализ", а если покажет, что не должны, то никто не побежит эти книги выбрасывать. Потому что каждому своё. Вот, скажем, должен ли печник хорошо владеть основами строительной механики? По идее да, но только очень поверхностно, чтобы лишь грамотно рассчитать фундамент и отверстие в крыше для трубы. Однако и печник, и инженер-строитель — это профессии строительные. Так и и программист, за этим словом скрываются десятки разных направлений. Опрос покажет только наличие людей тех или иных направлений, принявших участие в опросе.
В-четвёртых, сама постановка Ваших вопросов совершенно неверна. Спрашивать, может ли кто-то написать нечто почти не подглядывая — это не то же самое, что знать алгоритм. При работе в проектировании и кодировании библиотек нередко разработчик изобретает сам способ кодирования того или иного алгоритма, зачастую даже не зная алгоритма, а зная лишь идею. Одно из моих правил, которого я последнее время придерживаюсь — не смотреть коды или псевдокоды из литературы. Я читаю у кого-то об алгоритме (как правило, это научная статья), но только до момента, когда автор предлагает код (или псевдокод), сам код принципиально не смотрю. Затем додумываю алгоритм по-своему и пишу код свой собственный. Так нужно делать обязательно, потому что авторы научных статей — математики — зачастую (но не обязательно) — плохие программисты на практике. Где-то в 80% случаев написанный таким образом собственный код (без знания алгоритма, а со знанием только общей идеи) оказывается впоследствии красивее, короче и быстрее кода автора. Но есть и обратные примеры. Сейчас я занимаюсь учебным проектом по длинной арифметики и вижу, насколько хорошо она уже реализована в проектах вроде gmp и mpir. Поэтому идеи заимствую оттуда и сделать даже чуть-чуть лучше получается редко, если вообще получается. Чего не скажешь про stl, всё кроме бинарного поиска и сортировки можно написать эффективнее без особого труда.
То есть этим абзацем я хочу сказать, что знать алгоритм — это ни о чём не говорит. Нужно задавать вопрос конкретно: "можешь ли ты реализовать деление длинного числа на длинное число (пусть, для начала, будет тысяча десятичных знаков)?" или "есть массив из миллиона целых чисел от 1 до 10, можешь ли ты отсортировать его по неубыванию?" (горе тому, кто скажет хоть слово про qsort или mergeSort) или "рассчитай n-е число Фибоначчи в цикле, используя во всей программе лишь 3 переменных (одна из которых нужна для организации самого цикла)". Нужно спрашивать не о знании алгоритмов, а о понимании общей культуры программирования в том или ином направлении. Ещё аналогия. Можно знать (в теории), как пробежать 1000 метров за 3 минуты, а можно уметь это делать, но тогда неизбежно ты будешь уметь и 500 метров за 70 секунд, и 3 км за 10-11 минут и вообще будешь понимать общую биомеханику бега.
Надеюсь, мысль понятна. Знать алгоритмы — это всё равно что знать 1000 фактов, но не понимать, что они означают. Уметь программировать — это всё равно что уметь сопоставлять эти 1000 фактов с реальностью, согласованно друг с другом, пусть даже не обязательно хорошо зная все эти факты, а просто открывая их для себя по мере надобности из необходимости практики жизни.
В-пятых, здесь идёт классическое нарушение самой культуры социологических опросов. Вы опрашиваете произвольную группу людей, не делая различий в их исходной мотивации голосования, в их навыках, не разделяете по направлениям своей работы (от простых сисадминов в магазине до менеджеров крупных корпораций, от кодеров-самоучек до директоров фирм), в общем, получается каша из мнений, причём (я Вам гарантирую) сильно преувеличенных. Зайдите, скажем, на форум олимпиадных программистов — там все галочки будут поставлены и ещё сотню новых пунктов вам придумают. Зайдите на форум веб-программистов… там тоже скорее всего почти все галочки будут поставлены, но, сами понимаете, почему: ) В первом случае ребята действительно знают алгоритмы, а во втором скорее всего просто слышали эти слова. Короче, опрос не состоятельный получается, не учтены когнитивные искажения и прочие социологические феномены современного мира.
Пожалуй, я закончил, если что, обращайтесь лично. Прошу прощения, если кому-то показалось, что я чем-то хвастаюсь. Нет, поверьте, в коллективе разработчиков библиотек я даже никому неизвестен и по сути рядом не стою с создателями известных продуктов. Просто в этих вопросах "понимания" я более-менее разбираюсь и потому высказался.
В-третьих, от того, каким будет распределение голосов на таком опросе ровным счётом ничего не зависит. Если опрос покажет, что программисты должны изучать алгоритмы, то никто не побежит покупать книги вроде (простейших) Т. Кормена "Алгоритмы. Построение и анализ", а если покажет, что не должны, то никто не побежит эти книги выбрасывать. Потому что каждому своё. Вот, скажем, должен ли печник хорошо владеть основами строительной механики? По идее да, но только очень поверхностно, чтобы лишь грамотно рассчитать фундамент и отверстие в крыше для трубы. Однако и печник, и инженер-строитель — это профессии строительные. Так и и программист, за этим словом скрываются десятки разных направлений. Опрос покажет только наличие людей тех или иных направлений, принявших участие в опросе.
В-четвёртых, сама постановка Ваших вопросов совершенно неверна. Спрашивать, может ли кто-то написать нечто почти не подглядывая — это не то же самое, что знать алгоритм. При работе в проектировании и кодировании библиотек нередко разработчик изобретает сам способ кодирования того или иного алгоритма, зачастую даже не зная алгоритма, а зная лишь идею. Одно из моих правил, которого я последнее время придерживаюсь — не смотреть коды или псевдокоды из литературы. Я читаю у кого-то об алгоритме (как правило, это научная статья), но только до момента, когда автор предлагает код (или псевдокод), сам код принципиально не смотрю. Затем додумываю алгоритм по-своему и пишу код свой собственный. Так нужно делать обязательно, потому что авторы научных статей — математики — зачастую (но не обязательно) — плохие программисты на практике. Где-то в 80% случаев написанный таким образом собственный код (без знания алгоритма, а со знанием только общей идеи) оказывается впоследствии красивее, короче и быстрее кода автора. Но есть и обратные примеры. Сейчас я занимаюсь учебным проектом по длинной арифметики и вижу, насколько хорошо она уже реализована в проектах вроде gmp и mpir. Поэтому идеи заимствую оттуда и сделать даже чуть-чуть лучше получается редко, если вообще получается. Чего не скажешь про stl, всё кроме бинарного поиска и сортировки можно написать эффективнее без особого труда.
То есть этим абзацем я хочу сказать, что знать алгоритм — это ни о чём не говорит. Нужно задавать вопрос конкретно: "можешь ли ты реализовать деление длинного числа на длинное число (пусть, для начала, будет тысяча десятичных знаков)?" или "есть массив из миллиона целых чисел от 1 до 10, можешь ли ты отсортировать его по неубыванию?" (горе тому, кто скажет хоть слово про qsort или mergeSort) или "рассчитай n-е число Фибоначчи в цикле, используя во всей программе лишь 3 переменных (одна из которых нужна для организации самого цикла)". Нужно спрашивать не о знании алгоритмов, а о понимании общей культуры программирования в том или ином направлении. Ещё аналогия. Можно знать (в теории), как пробежать 1000 метров за 3 минуты, а можно уметь это делать, но тогда неизбежно ты будешь уметь и 500 метров за 70 секунд, и 3 км за 10-11 минут и вообще будешь понимать общую биомеханику бега.
Надеюсь, мысль понятна. Знать алгоритмы — это всё равно что знать 1000 фактов, но не понимать, что они означают. Уметь программировать — это всё равно что уметь сопоставлять эти 1000 фактов с реальностью, согласованно друг с другом, пусть даже не обязательно хорошо зная все эти факты, а просто открывая их для себя по мере надобности из необходимости практики жизни.
В-пятых, здесь идёт классическое нарушение самой культуры социологических опросов. Вы опрашиваете произвольную группу людей, не делая различий в их исходной мотивации голосования, в их навыках, не разделяете по направлениям своей работы (от простых сисадминов в магазине до менеджеров крупных корпораций, от кодеров-самоучек до директоров фирм), в общем, получается каша из мнений, причём (я Вам гарантирую) сильно преувеличенных. Зайдите, скажем, на форум олимпиадных программистов — там все галочки будут поставлены и ещё сотню новых пунктов вам придумают. Зайдите на форум веб-программистов… там тоже скорее всего почти все галочки будут поставлены, но, сами понимаете, почему: ) В первом случае ребята действительно знают алгоритмы, а во втором скорее всего просто слышали эти слова. Короче, опрос не состоятельный получается, не учтены когнитивные искажения и прочие социологические феномены современного мира.
Пожалуй, я закончил, если что, обращайтесь лично. Прошу прощения, если кому-то показалось, что я чем-то хвастаюсь. Нет, поверьте, в коллективе разработчиков библиотек я даже никому неизвестен и по сути рядом не стою с создателями известных продуктов. Просто в этих вопросах "понимания" я более-менее разбираюсь и потому высказался.
У меня вопрос: что означает "знать алгоритм"?
В универе я знал (мог реализовать по памяти) 90% алгоритмов сортировок, сейчас помню от силы штук 5, т.к. на практике не приходилось их велосипедить. Нужно обязательно их помнить, забивать ими память? Или же в маловероятной ситуации, когда алгоритм мне понадобится (разве что, собеседование в Яндекс), можно просто взять и прочитать в инете? А если бы я не знал его 10 лет назад — то прочитав сейчас, не смог бы понять? Или на понимание ушло бы на пару минут больше?
Еще момент: вопрос "Приходилось ли вам по работе (оправданно!) реализовывать какой-либо из стандартных алгоритмов..." с вариантами ответа Да / Нет — это определение средней температуры по больнице. Один раз реализовать тривиальный двоичный поиск, или постоянно велосипедить алгоритмы — это все попадает под "Да". Мне не хватило третьего варианта: "Да, но крайне редко".
На мой взгляд, алгоритмы (кроме совсем базовых) помнить не нужно, это справочная информация, их стоит изучить для развития алгоритмического мышления, осознание алгоритма создаст в мозге несколько нейронных связей, которые останутся в нем навсегда, и будут давать свои дивиденты во многих логических задачах, которые человек будет решать потом. Мы пока не умеем учиться по-другому, приходиться прокачать через мозг огромный массив знаний (сколько дат вы помните из истории, изучаемой в школе? А цифр по географии?). Остается лишь малая часть, но так формируется база, образованность человека. С алгоритмами также.
В универе я знал (мог реализовать по памяти) 90% алгоритмов сортировок, сейчас помню от силы штук 5, т.к. на практике не приходилось их велосипедить. Нужно обязательно их помнить, забивать ими память? Или же в маловероятной ситуации, когда алгоритм мне понадобится (разве что, собеседование в Яндекс), можно просто взять и прочитать в инете? А если бы я не знал его 10 лет назад — то прочитав сейчас, не смог бы понять? Или на понимание ушло бы на пару минут больше?
Еще момент: вопрос "Приходилось ли вам по работе (оправданно!) реализовывать какой-либо из стандартных алгоритмов..." с вариантами ответа Да / Нет — это определение средней температуры по больнице. Один раз реализовать тривиальный двоичный поиск, или постоянно велосипедить алгоритмы — это все попадает под "Да". Мне не хватило третьего варианта: "Да, но крайне редко".
На мой взгляд, алгоритмы (кроме совсем базовых) помнить не нужно, это справочная информация, их стоит изучить для развития алгоритмического мышления, осознание алгоритма создаст в мозге несколько нейронных связей, которые останутся в нем навсегда, и будут давать свои дивиденты во многих логических задачах, которые человек будет решать потом. Мы пока не умеем учиться по-другому, приходиться прокачать через мозг огромный массив знаний (сколько дат вы помните из истории, изучаемой в школе? А цифр по географии?). Остается лишь малая часть, но так формируется база, образованность человека. С алгоритмами также.
В опросе речь не про "знание", а про возможность самостоятельно написать. При этом я уточнил, что готовность к использованию в production написанного не важна, подойдет, например, просто сама идея, что для binary search нужен отсортированный массив, и нужно каждый раз уменьшать диапазон вдвое. Т.е. опрос именно про наличие тех самых нейронных связей алгоритмического мышления.
По поводу — "не знал 10 лет назад, решил узнать сейчас" — заняло бы не на пару минут дольше, а в лучшем случае на пару часов (если мы конечно не о сортировке пузырьком говорим). Опять же в силу особенности работы мозга. Чем старше мы становимся, тем менее подвижна наша психика и менее пластичен наш мозг, тем труднее в него забивать новые данные.
Про написание на работе — тут конечно все зависит от личного мнения отвечающего. В идеале, я бы хотел получить разделение аудитории на вот таких ребят и всех остальных. Если пару раз написал на работе binary search в своей собственной JS UI библиотеке, чтобы найти один букмарк из десятка, потому что не захотел тянуть underscore в проект — это, по-хорошему, не считается. Но так как мир не идеальный, получили среднюю температуру по больнице.
И, кстати, не факт, что нейронные связи остаются в мозге навсегда. Насколько я знаю, мозг работает по принципу "не использовать, значит потерять". Если перестаешь применять навык, со временем он разрушается. И тем быстрее он разрушается, чем позже был получен.
По поводу — "не знал 10 лет назад, решил узнать сейчас" — заняло бы не на пару минут дольше, а в лучшем случае на пару часов (если мы конечно не о сортировке пузырьком говорим). Опять же в силу особенности работы мозга. Чем старше мы становимся, тем менее подвижна наша психика и менее пластичен наш мозг, тем труднее в него забивать новые данные.
Про написание на работе — тут конечно все зависит от личного мнения отвечающего. В идеале, я бы хотел получить разделение аудитории на вот таких ребят и всех остальных. Если пару раз написал на работе binary search в своей собственной JS UI библиотеке, чтобы найти один букмарк из десятка, потому что не захотел тянуть underscore в проект — это, по-хорошему, не считается. Но так как мир не идеальный, получили среднюю температуру по больнице.
И, кстати, не факт, что нейронные связи остаются в мозге навсегда. Насколько я знаю, мозг работает по принципу "не использовать, значит потерять". Если перестаешь применять навык, со временем он разрушается. И тем быстрее он разрушается, чем позже был получен.
Про мозг — вопрос сложный. Насколько помню видеолекции Анохина, все воспоминания остаются навсегда, теряется доступ к ним. И не факт, что это равносильно: не имея возможности вспомнить алгоритм, мы имеем определенный фундамент из всех изученных ранее алгоритмов. Может они натренировали мозг (т.е. дело не в памяти, а параметрах работы мозга), может "забытые" куски все-таки участвуют в решении задач, но польза от изученного ранее, я уверен, есть.
Про разделение аудитории — честно, не вижу смысла. И без опросов понятно, что всегда найдутся особы люди (о чем бы ни шла речь), которые постоянно используют в работе то, что иные лишь ненадолго впустили в свою память. Разработчики библиотек по-полной варятся во всех алгоритмах — это скорее исключения, далекие от общей картины (а ведь речь о ней). Упомянутые в заголовке статьи "современные разработчики" — это огромная толпа людей, использующих те самые библиотеки, и им алгоритмы на практике нужны довольно редко. Зачем знать 10 алгоритмов сортировки, когда можно вызвать стандартный std::sort? В ответ люди почему-то начинают приводить исключения, какие-то редкие кейсы, когда человеку почему-то понадобится написать свой велосипед. И вот это поражает, совершенно иррациональный подход в рациональной сфере.
Редкое происходит редко, частое — часто, большую часть усилий нужно отдать на то, что даст большую часть результата. Алгоритмы — гимнастика мозга, но к реальной разработке они все меньше относятся. Поэтому, неприятно на собеседованиях видеть, когда интервьюер (чаще, молодые ребята) просто светится от гордости, что он знает на память пять видов сбалансированных деревьев и до деталей алгоритм удаления из них (особенно Яндекс промышляет почитанием Скиены).
Зачем?
Знания ради знаний? Вклад этих знаний в результат (для большинства кейсов, повторюсь!) — минимален. Если для человека программирование — это удовольствие само по себе, человек наливается эндорфинами от решения сложных задач, желательно в неком сэндбоксе, оторванной от живых пользователей задачи — тогда да, 100+1 способов отсортировать массив способен доставить удовольствие. Если программирование для вас — не только приятная и увлекательная деятельность, но инструмент улучшения мира, способ дать людям нечто новое, то надо это просто сделать, быстро и качественно, используя насколько можно готовые библиотеки! Здесь важнее понимание архитектурных принципов, цикла разработки, построения удобного UI и пр. Это способность решить реальную задачу реального мира за ограниченное время, в процессе чего вероятность реализации давно известного алгоритма стремится к минимуму. Или же результаты опроса говорят об обратном?
Про разделение аудитории — честно, не вижу смысла. И без опросов понятно, что всегда найдутся особы люди (о чем бы ни шла речь), которые постоянно используют в работе то, что иные лишь ненадолго впустили в свою память. Разработчики библиотек по-полной варятся во всех алгоритмах — это скорее исключения, далекие от общей картины (а ведь речь о ней). Упомянутые в заголовке статьи "современные разработчики" — это огромная толпа людей, использующих те самые библиотеки, и им алгоритмы на практике нужны довольно редко. Зачем знать 10 алгоритмов сортировки, когда можно вызвать стандартный std::sort? В ответ люди почему-то начинают приводить исключения, какие-то редкие кейсы, когда человеку почему-то понадобится написать свой велосипед. И вот это поражает, совершенно иррациональный подход в рациональной сфере.
Редкое происходит редко, частое — часто, большую часть усилий нужно отдать на то, что даст большую часть результата. Алгоритмы — гимнастика мозга, но к реальной разработке они все меньше относятся. Поэтому, неприятно на собеседованиях видеть, когда интервьюер (чаще, молодые ребята) просто светится от гордости, что он знает на память пять видов сбалансированных деревьев и до деталей алгоритм удаления из них (особенно Яндекс промышляет почитанием Скиены).
Зачем?
Знания ради знаний? Вклад этих знаний в результат (для большинства кейсов, повторюсь!) — минимален. Если для человека программирование — это удовольствие само по себе, человек наливается эндорфинами от решения сложных задач, желательно в неком сэндбоксе, оторванной от живых пользователей задачи — тогда да, 100+1 способов отсортировать массив способен доставить удовольствие. Если программирование для вас — не только приятная и увлекательная деятельность, но инструмент улучшения мира, способ дать людям нечто новое, то надо это просто сделать, быстро и качественно, используя насколько можно готовые библиотеки! Здесь важнее понимание архитектурных принципов, цикла разработки, построения удобного UI и пр. Это способность решить реальную задачу реального мира за ограниченное время, в процессе чего вероятность реализации давно известного алгоритма стремится к минимуму. Или же результаты опроса говорят об обратном?
Работал я как-то в двух командах. В первой все говорили, что самое важное — это value продукта. В том числе разработчики. И вместо обсуждения всяких алгоритмов и архитектур обсуждали бизнес-кейсы (а зачем тогда продакт-оунеры?). Все хотели дать людям нечто новое, собрав из готовых решений. В общем без слез на то, что было под капотом не взглянешь. А в другой команде технари были помешаны на своем деле. Обсуждали то, что и положено обсуждать технарям, фанатели от программирования самого по себе. И эту их энергию в нужное русло просто грамотно направляли продакт-оунеры. В итоге и продукт был лучше и под капотом у него было все круто. Ну и удовольствия от работы в такой команде было больше лично для меня.
Решение о том, какой фреймворк или ORM использовать, писать ли сейчас подробные юнит-тесты или потратить время на рефакторинг, какой подход выбрать для разруливания конкурентного редактирования одной записи, каким из множества способов хранить в базе мультиязычные данные, и миллион других подобных вопросов — решает не owner, а технический специалист, т.е. Вы.
А пример асимметричный) В первом случае перекос в бизнес, во-втором — все хорошо. Я бы вместо него привел другой (реальный) пример, когда программисты фанатели от новых крутых технологий, брали модные фреймворки (потому что интересно!) вместо того, что подходит для задачи. Технический челлендж — огромный, красивые слайды, все очень высокотехнологичное. Только не работает, не вытянули производительность. В итоге проект просто не смог выйти на продакшен, его закрыли, их уволили, время потрачено.
А пример асимметричный) В первом случае перекос в бизнес, во-втором — все хорошо. Я бы вместо него привел другой (реальный) пример, когда программисты фанатели от новых крутых технологий, брали модные фреймворки (потому что интересно!) вместо того, что подходит для задачи. Технический челлендж — огромный, красивые слайды, все очень высокотехнологичное. Только не работает, не вытянули производительность. В итоге проект просто не смог выйти на продакшен, его закрыли, их уволили, время потрачено.
Согласен полностью. Но я же не про гипотетическую ситуацию говорил, а про реальную. Это я к тому, что если выбирать, я бы предпочел работать в "идеальных" командах и в командах с перекосом в техническую сторону, даже если потом всех уволят в итоге)
Просто пример "бизнеса" был получен неудачный. А представьте, что Вы работали в команде разработки софта для нового космического аппарата многоразового использования. Не прям ядро, а UI для операторов например. И многочисленные бизнес-кейсы в этом случае — все из предметной области космонавтики. При этом в силу ограничений, можно использовать только узкий набор технологий (например, С++ и STL), и вместо фокуса на алгоритмах идет погружение в предметную область, контекст задачи. Было бы скучно?
Так тут бы предметная область была бы научной областью самой по себе. Конечно, скучно бы не было, но только потому, что это космонавтика. А если бы то же самое, но в медицине — я бы заскучал. Это же все субъективно. А любовь программиста программировать должна быть всегда. Опять же имхо)
А если бы эта работа над медицинским проектом означала бы спасение миллионов жизней? Тогда как?
Кажется, что наше обсуждение уже немного выходит за рамки первоначальной темы.
Я просто хотел донести мысль, что программисты склонны увлекаться технической и алгоритмической сложностью, порою настолько, что польза их работы для человечества ставится ниже собственного фана. Алгоритмы — это высокоуровневые абстракции, погружаясь в которые человек может далеко уйти от реального мира. В итоге, копаться в сотне алгоритмов становится интереснее, чем решить задачу (используя библиотеки), которая может спасти жизни, продвинуть науку, сделать жизнь людей чуточку лучше.
По вопросу примера, добавлю, что за 10 лет разработки лишь однажды мне пришлось делать свою реализацию стандартных алгоритмов. Это был модуль искусственного интеллекта для игры 3D Инструктор: вождение по Москве (ныне City Car Driving). Все дороги Москвы — это граф, перекрестки — вершины, и для расчета кратчайшего маршрута нужен был алгоритм Дейкстры. Прикрутить стандартный в теории можно было (тот же BGL), но там какие-то нюансы были в структуре данных наших и пара небольших дополнений к алгоритму, в итоге оказалось проще и быстрее сделать свою реализацию (благо, алгоритм простой). А, еще A* там был. Ну а для руления преследующей машины на короткой дистанции (вроде это называется стиринг, много лет уже прошло..) ничего готового не подошло. Вообще, игровые движки того времени (не знаю, как сейчас) очень любили свои реализации ВСЕГО, даже базовые контейнеры типа вектора. Я это к чему: игровой проект был насыщен математикой, физикой и вычислениями. Приходилось и с тензорами инерции работать, матрицы, кватернионы и углый эйлера — так это постоянно, много формул из механики и пр. Но никогда при этом мне не пригодилось знание более чем одного алгоритма сортировки, знание 20 видов структур данных.
Насчет алгоритмов… Хороший разработчик, в отличие от посредственного, обладает одной важной чертой. Нет, это не знание алгоритмов — это добро всегда можно найти и реализовать. В программировании наиболее важной является другая черта — учесть все вариации входных данных. Ключевое слово — "все". Хороший программист способен разбить все множество входных данных на классы эквивалентности, учтя при этом технические реалии (конечную память, ограничения на размеры структур данных, численные переполнения и т.д.), аккуратно их расписать, собрать одинаковые части вместе, и уже после этого написать код, который будет правильно работать для всех этих случаев.
Да, это сложно. Но только тот, кто это может и делает, достоин звания "инженер-программист", которое у многих значится в названии должности. :-)
Да, это сложно. Но только тот, кто это может и делает, достоин звания "инженер-программист", которое у многих значится в названии должности. :-)
Осталось только понять как такой "инженер-программист" будет "учитывать при этом технические реалии" не зная про свойства используемых алгоритмов.
А так — да, знание алгоритмов не очень нужно. Нужно метазнание. Я про это уже писал. А детали… что детали… их всегда придумать можно...
А так — да, знание алгоритмов не очень нужно. Нужно метазнание. Я про это уже писал. А детали… что детали… их всегда придумать можно...
Sign up to leave a comment.
Большой опрос по алгоритмам