Comments 61
Вижу тут я антипаттерна три:
- Вставка шаблонов в код.
- Строковая интерполяция для вставки данных.
- Отсутствие экранирования.
Вот-вот. Совершенно не совершенный код с костылем!
Почему же это антипаттерны? Например, если я буду использовать это не для серверных скриптов, обрабатывающих чужой пользовательский ввод, а для собственных утилит, скажем, для обработки текста.
Ну вот введёте вы в своей утилите текст, содержащий символ "больше" и весь интерфейс поедет. Оно вам надо?
Но у меня на выходе не HTML. Всё, что нужно, я экранирую в других местах. Экранирование — это совсем другая задача, я не пытался данной функцией решить все возможные проблемы обработки ввода.
4) Экранирование вдалеке от места использования.
Я не понимаю, зачем мне экранирование символов, которые в моём случае не являются специальными. Использование JavaScript или Node.js не всегда имеет целью создание HTML.
Любой выходной язык требует ту или иную форму экранирования. Даже если вы просто выводите текст в консоль.
И вы предлагаете мне внести в эту функцию экранирование для всех возможных выходных языков?
Вы можете сделать фабрику таких функций.
В принципе, это имело бы смысл, если бы я писал универсальную библиотеку на все случаи жизни. Но пока это сильно уведёт нас в сторону. Функция ведь и так открыта для любых добавлений. Никому ничего не мешает добавить в строчку, конкатенирующую выражение, любые дополнительные функции для экранирования, проверки ограничений и т.д.
это просто гениально! Как же люди сами до этого не доходят
Пришёл к чему-то подобному.
В данном случае
Правда шаблонные литералы не через
Пример из тестов
it('section', () => checkMarkBegin('section', renderDOM`
|#doc
| #section^1
| #heading "1. txt"
| #text "2. txt"*
| #section^3
| #heading "3. txt"
`, renderDOM`
|#doc
| #section^1
| #heading "1. txt"
| #section^2
| #heading "2. txt"
| #section^3
| #heading "3. txt"`));В данном случае
renderDom делает гораздо больше, чем просто поправляет отступы и убирает лишние переносы строк. Но, касаемо самого текста, суть примерно та же. Для большей очевидности и наглядности каждую строку начинаю с |.Правда шаблонные литералы не через
String.raw за пределами тестов мне пока не пригодилось. А вот в них позволили очень сложные вырвиглазные вещи описать, используя в 10 раз меньше кода и улучшив раз в 5 наглядность. Правда попутно сочиняя новый язык шаблонов, но это уже другая история :)Спасибо. Я сначала пробовал вводить горизонтальные рамки, чтобы отделять многострочные литералы от кода и хоть как-то чинить нарушение структуры отступов, вроде:
Но так выходило ещё более громоздко. И проблемы с выравниванием строк самого литерала не решало.
if (verbose) {
console.log(
/*`````````````````*/
`const a is ${a}.
const b is ${b}.`
/*`````````````````*/
);
} else {
console.log(
/*`````````````````*/
`a = ${a}.
b = ${b}.`
/*`````````````````*/
);
}Но так выходило ещё более громоздко. И проблемы с выравниванием строк самого литерала не решало.
У способа с
| я словил одну проблему: я использую повсеместно Tab-ы. А т.к. | завершает indent-часть кода, то последующие за ним Tab-ы каждый редактор рисует как ему хочется. К примеру sublimetext делает с ними что-то совершенно невменяемое (длина таба варьируется в зависимости от расположения Марса). В итоге я до | использую табы, а после (т.е. "внутри шаблонной строки") ― пробелы.- Ошибка в коде:
var firstname = 'Firstname'; var lastname = 'Lastname'; console.log(xs`user: ${firstname} ${lastname}`); // 'user: FirstnameLastname' пробел отсутствует
- Для каждой переменной в шаблоне создается новый RegExp.
str.replace(/^ +/mg, '')
- Если шаблон маленький, то можно просто написать:
console.log(`a = ${a}.`); console.log(`b = ${b}.`);
Если же шаблон имеет хоть какой-то размер, то скорей всего он будет в отдельной функции "getMagicTmpl", а не в перемешку с остальным кодом. И в этой функции он будет оформлен как надо.
- Итог:
Есть функция с ошибками, которая не покрывает всех возможных вариантов ("это можно предусмотреть в обрабатывающей функции: удалять лишь часть пробелов"), которая написана далеко не оптимально и не понятен сценарий ее использования в реальном проекте.
2 Для каждой переменной в шаблоне создается новый RegExp.
А есть ли разница? Я как-то уже пробовал переиспользовать уже созданные RE в критичных к производительности местах. Никакой разницы в производительности не заметил. Сейчас перепроверил в консоли:
console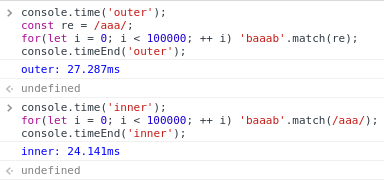

3… И в этой функции он будет оформлен как надо.
Если бы. Там возникнут те же самые проблемы.
Слишком простая регулярка, при сложных и длинных регулярках с второй пример будет значительно дольше
Подозреваю, что дело вовсе не в сложности регулярного выражения. Вероятнее всего, ИМХО, JS-движок сам кеширует эту RE. Разве не так? Во всяком случае это движку ничего не стоит, а выгода очевидна.
JS-движок сам кеширует ...Он не может всегда кешировать, особенно если есть RegExp c изменяемой переменной
Вот так у меня даже без изменяемых переменных в регулярке(Просто в js на регулярках собаку cъел, делая много парсеров контента
console
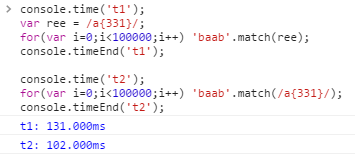
console.timer('t1');
const re = /a{331}/;
for(i=0;i<100000;i++) 'baab'.match(re);
console.timerEnd('t1');
t1: 65.231ms
console.timer('t2');
const re;
for(i=0;i<100000;i++) 'baab'.match(/a{331}/);
console.timerEnd('t2');
t2: 97.846
Vivaldi 1.0.435.26: 70 vs 75Chrome 50: 13 vs 11Firefox 45: 105 vs 101nodeJS v5.2.0: 9.7 vs 10
Одно и то же. Linux Mint 64bit.
у меня даже без изменяемых переменных в регулярке
Хм. Подскажите, а что вы имеете ввиду?
Хм. Подскажите, а что вы имеете ввиду?К примеру:
for(i=0;i<100000;i++) 'baab'.match(new RegExp(i%5, g))Возможно в лине браузеры и кешируют статические регулярки, но на windows различие явное
new RegExp
Ааа. Вот вы про что. А я уж было подумал, что вы про какую-нибудь PERL хитрость с пробросом переменной внутрь уже созданной RE говорите. Ужаснулся даже, чего только не удумали. В случае создания нового RegExp-а из строки проблемы тоже нет, ведь чаще всего такие RE будут разными в каждой итерации, собственно потому и создаются руками.
Итак. Windows:
Chrome 49— 280x172, 226x162, 131x102. (ссылка)Firefox 44— 124x107, 114x103, 115x119 (ссылка)IE 9— 112x89, 113x87, 116x88 (ссылка)
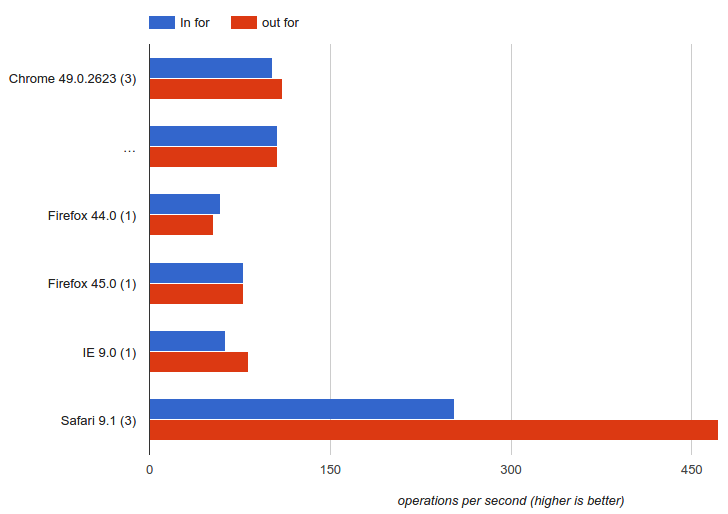
Итого: ощутимая разница есть, но в пользу НЕ выноса RE за пределы цикла. Пожалуй, щас jsperf какой-нибудь склепаю.
RegExp как объект должен пересоздваться в цикле, если не вынесен за его пределы,
У меня разница примерно на порядок
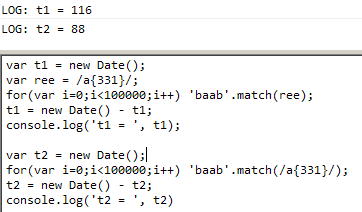
<script type="text/javascript">
var t1=new Date();
var a = "a{331}"; //К примеру эту переменную a получаем из какой-то функции
const re = new RegExp(a,"g");
for(i=0;i<100000;i++) 'baab'.match(re);
alert(new Date()-t1);
var t2=new Date();
for(i=0;i<100000;i++) 'baab'.match(RegExp(a,"g"));
alert(new Date()-t2);
</script>У меня разница примерно на порядок
Deff, мы ходим по кругу. Давайте уже определимся, мы говорим про обычные регулярки, или про
Речь ведь идёт о том, что если регулярка обычная, записанная в виде
new RegExp? Никто вроде и не спорит с тем, что new RegExp нужно выносить за пределы цикла, если она не должна быть уникальной для каждой итерации. Речь ведь идёт о том, что если регулярка обычная, записанная в виде
/blabla/, то нет резона выносить её за пределы циклов, т.к. браузеры и без того будут её кешировать, а код будет более читаемым. Т.е. пункта из root-комментария выше, я считаю, из разряда неработающих микрооптимизаций, которые, как известно, — зло. Я сказал про возможное наличие переменной в регулярке, которое кроме как через регесп не вставить(Вы сами спросили что Вы имеете ввиду)
Есть еще и запоминаюшие скобки(без регеспов), которые тоже стоит протестировать цикл/не цикл, если у Вас есть такое желание, но во всех справочниках и учебниках определение переменных выносят за пределы цикла, что вроде бы как логично, ибо кеширование переменных браузером в цикле — расчет на наивного пользователя.
2. Думаю даже при кешировании разница во времени постоянна, попробуйте увеличить длину цикла на порядок, затем уменьшить. Ибо я пока не понимаю причины даже небольшого уменьшения времени(за которое имхо даже не стоит бороться)
Есть еще и запоминаюшие скобки(без регеспов), которые тоже стоит протестировать цикл/не цикл, если у Вас есть такое желание, но во всех справочниках и учебниках определение переменных выносят за пределы цикла, что вроде бы как логично, ибо кеширование переменных браузером в цикле — расчет на наивного пользователя.
2. Думаю даже при кешировании разница во времени постоянна, попробуйте увеличить длину цикла на порядок, затем уменьшить. Ибо я пока не понимаю причины даже небольшого уменьшения времени(за которое имхо даже не стоит бороться)
Ибо я пока не понимаю причины даже небольшого уменьшения времени
Я право тоже. Но лезть в дебри
C++ кода и смотреть почему оно так, мне лень. В одном из своих парсеров, который работает десятки часов напролёт, я думал, что смогу сэкономить хотя бы 5-10% времени именно на выносе всех регулярок из класса куда-нибудь повыше, и дёргать уже экземпляры RegExp-а. Это сильно бы усложнило понимание кода (прямо реально сильно, т.к. регулярки были уникальны и будучи оторванными от контекста...), но я ожидал от этого каких-нибудь явных преимуществ в производительности.Но оказалось что никакой внятной разницы нет. Всё в пределах погрешности. С тех пор к inline-регуляркам я стал относится, как вычисляемым на этапе компиляции значениям, что распространено в системных языках.
прямо реально сильно, т.к. регулярки были уникальны и будучи оторванными от контекста...),При наличии хорошего очевидного названия переменной для регулярки — проблемы вроде как не стоит, тем паче вынесение переменных перед циклом, — стандартная практика.
2. Мой первый пример с цифрами для Оперы 12.17 (Часто ей пользуюсь, ибо на поддержке нужна правка скриптов прямо в контенте страницы, чего нет у остальных браузеров, проверил сейчас в Лисе, цифры примерно соответствуют Вашим)
тем паче вынесение переменных перед циклом
С простым циклом — соглашусь. А если это экземпляр класса? Внутри этого класса пол-сотни методов, и в большей части из них есть специфичекие регекспы? Единственное место куда их можно вынести — за пределы этих методов. К примеру в конструктор класса, или выше по коду.
Учитывая, что эти RE являются чуть ли не сутью данного класса (парсер, что с него взять), то это очень сильно ухудшает читаемость кода.
Однако производительность в данном случае стоит того, поэтому я, скрепя сердцем, готов был пойти на такой шаг. Но оказалось не нужным.
При наличии хорошего очевидного названия переменной для регулярки
Именование это самая главная проблема программирования в целом :) А разумное именование для RE это проблема в квадрате. Должно быть вы шутите :D
Мой первый пример с цифрами для Оперы 12.17
Ого. Последний из могикан?
jsPerf. Разницу >5% показал только в IE9.
{kind=link}
{kind=link}
{kind=link}
Спасибо большое. Ошибку, кажется, исправил, создание регулярных выражений вынес из цикла (можно их и из функции вынести в глобальные переменные, но это уже будет, наверное, преждевременная оптимизация для моих задач).
Сценарий использования в моём случае такой: я делаю локальные копии сетевых словарей при помощи Node.js или NW.js, поэтому в скриптах постоянно приходится записывать большие блоки текста в файл. Блоки многострочные, состоящие частично из моих строк (в том числе с разметкой языка для словарной оболочки), частично из переменных, содержащих извлечённую из сетевых страниц информацию.
Сценарий использования в моём случае такой: я делаю локальные копии сетевых словарей при помощи Node.js или NW.js, поэтому в скриптах постоянно приходится записывать большие блоки текста в файл. Блоки многострочные, состоящие частично из моих строк (в том числе с разметкой языка для словарной оболочки), частично из переменных, содержащих извлечённую из сетевых страниц информацию.
вот это костылище!
удивительно, что C-like язык не предоставляет такой же возможности для записи длинной строки в несколько строк, как это реализовано в самом C.
удивительно, что C-like язык не предоставляет такой же возможности для записи длинной строки в несколько строк, как это реализовано в самом C.
В C есть 2 способа писать строки в несколько строк, но они ничем особо не отличаются от вариантов в js:
Или
Но тут, как минимум, не просто запись в несколько строк, а template literals
var jsstr =
"test" +
"middle" +
"end";Или
var jsstr = "\
test\
middle\
end";Но тут, как минимум, не просто запись в несколько строк, а template literals
ну да, не отличаются, лишних пробелов не будет и переводов строк.
а "+" для С не нужен
а "+" для С не нужен
все ж таки в С проще — не нужна операция сложения
Не нужна операция сложения, но нужно открывать и закрывать кавычки, поэтому это не сильно отличается от js варианта с +
В случае с `` как раз ни кавычки, ни сложение не требуется, тем и удобен
Например, для шаблонизатора где учитываются отступы для формирования dom, можно сделать так
Соответственно, даже вариант без сложения, с постоянной расстановкой кавычек был бы уже не удобен
В случае с `` как раз ни кавычки, ни сложение не требуется, тем и удобен
Например, для шаблонизатора где учитываются отступы для формирования dom, можно сделать так
var html = template.compile(`
extends layout
block main
include menu
ul.submenu
li.item home
li.item about
block footer
.end footer text
`);Соответственно, даже вариант без сложения, с постоянной расстановкой кавычек был бы уже не удобен
ну да, не отличаются, лишних пробелов не будет и переводов строк.
Правда? Я не знаю
C, вопрос:void fn()
{
if(some)
char *str = "\n
line1\n
line2\n
line3";
}Будет ли
str равным \nline1\n line2\nline3?вообще-то, когда я писал свой первый комментарий я имел в виду разбиение длинной строки так, чтобы не надо было части склеивать операцией конкатенации, именно этот синтаксис отсутствует в js и в php, кстати, тоже
Приведите, пожалуйста, пример кода и его результирующий вывод.
ну вот как-то так http://cpp.sh/862m
Но здесь же совсем разные задачи решаются. В вашем случае — разбиение длинной строки на сегменты, при этом переводы строк в коде не соответствуют переводам строк в выводе. В случае шаблонных литералов в JS — попытка добиться максимального соответствия между шаблоном и выводом. Что видим в коде, получим в выводе. Проблема была в том, чтобы это соответствие ещё как-то вписать в структуру кода.
Это не одно и тоже. У вас в каждой строке необходимо указывать кавычки, а каждый перевод строки задавать в виде \n. Тоже самое, но с +-ми в JS было и ранее, но мало кто считал это удобным для много-строчного текста :)
Под linux str будет равным "\n\n line1\n\n line2\n\n line3", т.е. не экранированые переводы строк тоже добавятся. (Под windows будет "\n\r\n ....")
Как альтернатива:
function xs(str){
return str.replace(/\n +/g, '\n').replace(/^\n|\n$/g, '');
}
const a = 1;
const b = 2;
console.log(xs(`
a = ${a}.
b = ${b}.
`));
Раз пошли в ход такие конструкции, возможно стоит вспомнить такой костыль?
Имхо он заодно и отделяет контент такой текстовой константы от остального
Имхо он заодно и отделяет контент такой текстовой константы от остального
function textConst (){ /*==123==;
<style type="text/css">
#pun .main{
display:none;
}
</style>
<div id=world>
Привет Мир!
</div>
==123==;*/
} textConst = textConst.toString().split('==123==;')[1];
alert(textConst)Есть вопрос, может кто-нибудь сможет мне подсказать? Есть ли возможность на основании template strings теперь как-то заменить функционал underscore или mustache? Я так и не нашёл функцию, позволяющую создать template string из стороннего объекта, например загруженного через AJAX файла. Пример:
файл template.html
$(name)
скрипт
fetch('template.html').then(_=>_.text()).then(templateString=>{
compileTemplate(templateString, {name:'Вася'});
})
все актуальные шаблонизаторы строят функцию, которую потом выполняют через eval. Есть ли вариант в этом примере реализовать функцию compileTemplate, которая будет использовать шаблонные строки?
файл template.html
$(name)
скрипт
fetch('template.html').then(_=>_.text()).then(templateString=>{
compileTemplate(templateString, {name:'Вася'});
})
все актуальные шаблонизаторы строят функцию, которую потом выполняют через eval. Есть ли вариант в этом примере реализовать функцию compileTemplate, которая будет использовать шаблонные строки?
Если я правильно понял, то вы можете разобрать строку на составляющие самостоятельно, а затем скормить её String.raw. Правда если интерполируемые значения могут иметь сложную структуру, то лучше даже не начинать.
А по сути template string это часть языка. Т.е. JS парсер, натыкаясь на такую строку ещё при разборе разбивает её на составляющие и в AST уходят уже куски, а не вся целиком. Едва ли такая часть парсера будет доступна снаружи.
А по сути template string это часть языка. Т.е. JS парсер, натыкаясь на такую строку ещё при разборе разбивает её на составляющие и в AST уходят уже куски, а не вся целиком. Едва ли такая часть парсера будет доступна снаружи.
Наивная функция может быть такой:
Вывод:
Но боюсь, что такой парсинг много чего не учитывает. Например, вложенные шаблонные строки сразу же всё усложнят.
const str = 'A: ${1+2}\nB: ${3+4}';
function compileTL(str) {
const strings = str.split(/\$\{.*?\}/);
const expressions = str.match(/\$\{.*?\}/g).map(expr => eval(expr.replace(/^\$\{|\}$/g, '')));
return String.raw({ raw: strings }, ...expressions);
}
console.log(compileTL(str));
Вывод:
A: 3
B: 7
Но боюсь, что такой парсинг много чего не учитывает. Например, вложенные шаблонные строки сразу же всё усложнят.
Не уверен, что это именно то, что нужно, но вроде бы на близкую тему.
Круто конечно, но только вот в вашем «большом примере» функция съест все ведущие пробелы, и нарушит форматирование html-кода. А если его нужно сохранить, тогда литерал будет выбиваться влево из основного кода.
Обновил функцию для сохранения вложенных отступов.
Sign up to leave a comment.
Удобная вставка многострочных шаблонных литералов в код на JavaScript