Garena, в которой я сейчас работаю, находится в процессе роста и я занимаюсь наймом инженеров, сисадминов и подобного персонала, чтобы удовлетворить аппетиты растущей платформы и выдержать планы и сроки выпуска продуктов. Проблема, с которой я постоянно сталкиваюсь, заключается в том, что не только одна наша компании занимается поиском и наймом инженеров. Это особенно актуально сейчас, когда многие компании опубликовали свои ежегодные бонусы (или отсутствие оных) и неудовлетворённые рядовые сотрудники компаний пополняют ряды соискателей. Иными словами, собираются в кучу музыкальные стулья с компаниями и инженерами.
«музыкальные стулья» (детская игра; под музыку дети ходят вокруг ряда стульев; когда музыка прекращается, играющие бросаются занимать стулья, которых на один меньше, чем играющих)
Нечего и говорить, что это является причиной определенных сложностей с наймом. Отрадно, что есть много кандидатов. Однако обратной стороной данного факта является проблема сохранения высоко квалифицированного инженера с адекватным складом ума в рамках растущего cтартапа. В то же время подбор и утверждение кандидата должны быть быстрыми, так как промедление, даже с частично подходящим кандидатом, чревато его потерей в течение одного-двух дней.
Это заставляет меня задаться вопросом — каким путем лучше пойти при наличии большого списка кандидатов и, в итоге, выбрать лучшего инженера или, во всяком случае, того, кто входит в число лучших этого списка.
В книге Why Flip a Coin: The Art and Science of Good Decisions, H.W. Lewis писал об аналогичной (хотя и более строгой) проблеме, связанной со знакомством. Вместо выбора кандидатов в книге рассказано о выборе жены, а вместо проведения интервью, рассмотрена проблема знакомства. Однако, в отличии от книги, где предполагается что Вы можете встречаться только с одним человеком за раз, в моей ситуации я, очевидно, могу проинтервьюировать более чем одного кандидата. Тем не менее, возникающие проблемы в значительной степени неизменны, если я буду интервьюировать слишком много кандидатов и потрачу слишком много времени на принятие решения, то они будут перехвачены другими компаниями. Не говоря уже о том, что я, вероятно, ещё до того умру с пеной у рта от передозировки общения.
В книге Льюис предложил следующую стратегию — скажем, мы выбираем из списка состоящего из 20 кандидатов. Вместо того, чтобы интервьюировать каждого, мы случайным образом выбираем и интервьюируем 4х кандидатов и выбираем лучшего из этого списка-образца. Теперь, имея в запасе этого лучшего из этих 4х кандидатов, мы интервьюируем остальную часть списка по одному до тех пор, пока мы не встретим кого-либо лучшего и, в итоге, нанимаем этого кандидата.
Как вы догадались, эта стратегия является вероятностной и не гарантирует выбор наилучшего кандидата. В самом деле, есть 2 наихудших варианта развития событий. Во-первых, если мы случайно выбрали 4х худших кандидатов в качестве списка-образца и первый кандидат, выбранный из остальной части списка, будет 5 м худшим, то мы наймем 5 го худшего кандидата. Не хорошо. И наоборот, если самый лучший кандидат находится в списке-образце, то мы рискуем провести 20 интервью, а затем потерять этого лучшего кандидата, поскольку весь процесс занял слишком много времени. Снова плохо.
Итак, хорошая ли это стратегия? Кроме того, какая оптимальная численность списка (общее число кандидатов) и списка-образца нам необходима для того, чтобы извлечь максимальную пользу из этой стратегии? Давайте будем хорошими инженерами и воспользуемся моделированием методом Монте-Карло, чтобы найти ответ.
Давайте начнем с численности списка в 20 кандидатов, а затем переберем численность списка-образца от 0 до 19. Для каждого списка-образца мы находим вероятность того, что кандидат, которого мы выбираем, является лучшим кандидатом в списке. На самом деле мы уже знаем эту вероятность, если список-образец равен 0 или 19. В случае если список-образец равен 0, будет выбран первый кандидат, которого мы интервьюируем (поскольку не с кем сравнивать), поэтому вероятность равна 1/20, и составляет 5%. Аналогичным образом со списком-образцом равным 19, нам придется выбрать последнего кандидат и вероятность этого также равна 1/20 и составляет 5%.
Вот Ruby код моделирующий это. Прогоним моделирование 100,000 раз, чтобы рассчитать вероятность как можно более точно, и сохраняем результат в CSV файл optimal.csv
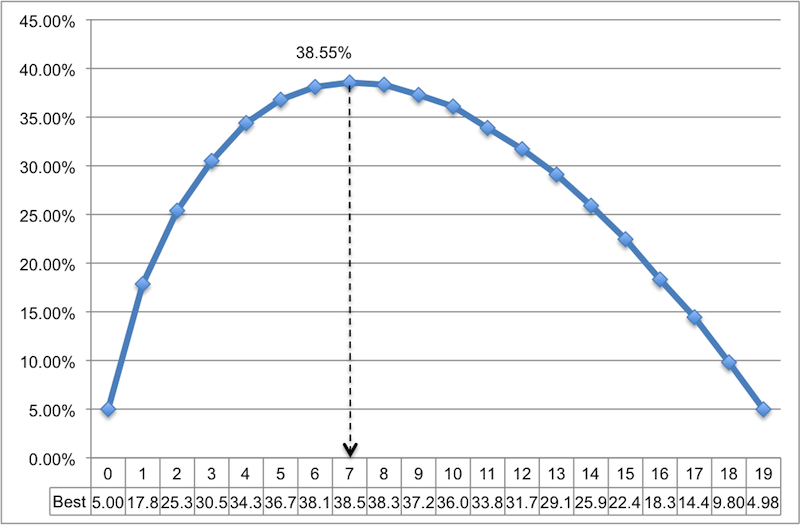
Код достаточно самоочевидный (особенно со всеми комментариями), поэтому я не буду вдаваться в подробности. Результат показан ниже на линейном графике, после открытия и разметки файла в MS Excel. Как вы можете видеть, если вы выберите 4 кандидатов в качестве списка-образца, вы будете иметь примерно 1 шанс из 3, что вы выбираете наилучшего кандидата. Лучшие шансы, если выбрать 7 кандидатов в качестве списка-образца. В этом случае вероятность того, что вы выберете наилучшего кандидата около 38,5%. Выглядит не очень хорошо.

Но, честно говоря, в случае нескольких кандидатов мне не нужно, что бы кандидат был «наилучший» (во всяком случае, такие оценки носят субъективный характер). Допустим, я хочу получить кандидата находящегося в верхней четверти списка (верхние 25%). Каковы мои шансы тогда?
Вот пересмотренный код, который моделирует это.
В файле Optimal.csv мы добавили новую колонку, которая содержит верхнюю четверть (top 25%) кандидатов. Ниже показан новый график. Для сравнения добавлены результаты предыдущего моделирования.

Теперь результат обнадеживает, наиболее оптимальный размер списка-образца составляет 4 (хотя для практических целей и 3 достаточно хорошо, так как разница между 3 и 4 мала). В этом случае вероятность выбора кандидата из верхней четверти списка устремляется к 72,7%. Великолепно!
Теперь разберемся с 20 кандидатами. Как насчет списка с большим количеством кандидатов? Как эта стратегия выдержит, скажем, список, содержащий 100 кандидатов?
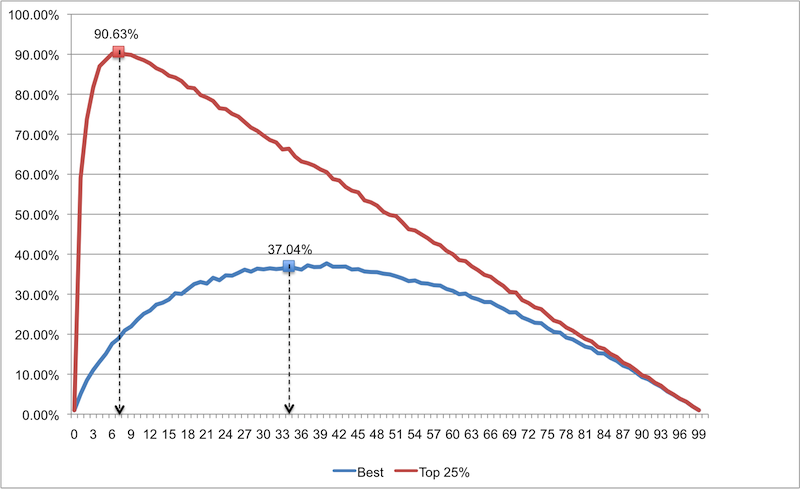
Как вы видите, эта стратегия не подходит для определения наилучшего кандидата из большого списка (список-образец слишком велик, а вероятность успеха слишком низка). Этот результат хуже, чем полученный нами для списка с меньшей численностью. Однако, если нас устроит кандидат из верхней четверти списка (т.е. будем менее требовательны), нам достаточно 7 кандидатов в списке-образце, при этом вероятность достижения необходимых результатов составит 90.63%. Это изумительные шансы!
Это значит, если вы менеджер по найму с сотней кандидатов, вам не нужно пытаться убить себя, интервьюируя каждого. Просто проинтервьюируйте список-образец из 7 кандидатов, выберите лучшего, а затем интервьюируйте остальных одного за другим, пока не встретите того, который лучше, чем лучший в списке-образце. Вероятность того, что вы выберите кого-либо из лучших 25% списка в 100 кандидатов составит 90.63% (и это, вероятно, будет тот, кто вам нужен)!
«музыкальные стулья» (детская игра; под музыку дети ходят вокруг ряда стульев; когда музыка прекращается, играющие бросаются занимать стулья, которых на один меньше, чем играющих)
Нечего и говорить, что это является причиной определенных сложностей с наймом. Отрадно, что есть много кандидатов. Однако обратной стороной данного факта является проблема сохранения высоко квалифицированного инженера с адекватным складом ума в рамках растущего cтартапа. В то же время подбор и утверждение кандидата должны быть быстрыми, так как промедление, даже с частично подходящим кандидатом, чревато его потерей в течение одного-двух дней.
Это заставляет меня задаться вопросом — каким путем лучше пойти при наличии большого списка кандидатов и, в итоге, выбрать лучшего инженера или, во всяком случае, того, кто входит в число лучших этого списка.
В книге Why Flip a Coin: The Art and Science of Good Decisions, H.W. Lewis писал об аналогичной (хотя и более строгой) проблеме, связанной со знакомством. Вместо выбора кандидатов в книге рассказано о выборе жены, а вместо проведения интервью, рассмотрена проблема знакомства. Однако, в отличии от книги, где предполагается что Вы можете встречаться только с одним человеком за раз, в моей ситуации я, очевидно, могу проинтервьюировать более чем одного кандидата. Тем не менее, возникающие проблемы в значительной степени неизменны, если я буду интервьюировать слишком много кандидатов и потрачу слишком много времени на принятие решения, то они будут перехвачены другими компаниями. Не говоря уже о том, что я, вероятно, ещё до того умру с пеной у рта от передозировки общения.
В книге Льюис предложил следующую стратегию — скажем, мы выбираем из списка состоящего из 20 кандидатов. Вместо того, чтобы интервьюировать каждого, мы случайным образом выбираем и интервьюируем 4х кандидатов и выбираем лучшего из этого списка-образца. Теперь, имея в запасе этого лучшего из этих 4х кандидатов, мы интервьюируем остальную часть списка по одному до тех пор, пока мы не встретим кого-либо лучшего и, в итоге, нанимаем этого кандидата.
Как вы догадались, эта стратегия является вероятностной и не гарантирует выбор наилучшего кандидата. В самом деле, есть 2 наихудших варианта развития событий. Во-первых, если мы случайно выбрали 4х худших кандидатов в качестве списка-образца и первый кандидат, выбранный из остальной части списка, будет 5 м худшим, то мы наймем 5 го худшего кандидата. Не хорошо. И наоборот, если самый лучший кандидат находится в списке-образце, то мы рискуем провести 20 интервью, а затем потерять этого лучшего кандидата, поскольку весь процесс занял слишком много времени. Снова плохо.
Итак, хорошая ли это стратегия? Кроме того, какая оптимальная численность списка (общее число кандидатов) и списка-образца нам необходима для того, чтобы извлечь максимальную пользу из этой стратегии? Давайте будем хорошими инженерами и воспользуемся моделированием методом Монте-Карло, чтобы найти ответ.
Давайте начнем с численности списка в 20 кандидатов, а затем переберем численность списка-образца от 0 до 19. Для каждого списка-образца мы находим вероятность того, что кандидат, которого мы выбираем, является лучшим кандидатом в списке. На самом деле мы уже знаем эту вероятность, если список-образец равен 0 или 19. В случае если список-образец равен 0, будет выбран первый кандидат, которого мы интервьюируем (поскольку не с кем сравнивать), поэтому вероятность равна 1/20, и составляет 5%. Аналогичным образом со списком-образцом равным 19, нам придется выбрать последнего кандидат и вероятность этого также равна 1/20 и составляет 5%.
Вот Ruby код моделирующий это. Прогоним моделирование 100,000 раз, чтобы рассчитать вероятность как можно более точно, и сохраняем результат в CSV файл optimal.csv
-
- require 'rubygems'
- require 'faster_csv'
-
- population_size = 20
- sample_size = 0..population_size-1
- iteration_size = 100000
- FasterCSV.open('optimal.csv', 'w') do |csv|
- sample_size.each do |size|
- is_best_choice_count = 0
- iteration_size.times do
- # создаем список и сортируем случайным образом
- population = (0..population_size-1).to_a.sort_by {rand}
- # получаем список-образец
- sample = population.slice(0..size-1)
- rest_of_population = population[size..population_size-1]
- # это лучший из списка-образца?
- best_sample = sample.sort.last
- # находим наилучшего выбранного этой стратегией
- best_next = rest_of_population.find {|i| i > best_sample}
- best_population = population.sort.last
- # наилучший ли это выбор? считаем сколько раз этот выбор наилучший
- is_best_choice_count += 1 if best_next == best_population
- end
- best_probability = is_best_choice_count.to_f/iteration_size.to_f
- csv << [size, best_probability]
- end
- end
-
Код достаточно самоочевидный (особенно со всеми комментариями), поэтому я не буду вдаваться в подробности. Результат показан ниже на линейном графике, после открытия и разметки файла в MS Excel. Как вы можете видеть, если вы выберите 4 кандидатов в качестве списка-образца, вы будете иметь примерно 1 шанс из 3, что вы выбираете наилучшего кандидата. Лучшие шансы, если выбрать 7 кандидатов в качестве списка-образца. В этом случае вероятность того, что вы выберете наилучшего кандидата около 38,5%. Выглядит не очень хорошо.
Но, честно говоря, в случае нескольких кандидатов мне не нужно, что бы кандидат был «наилучший» (во всяком случае, такие оценки носят субъективный характер). Допустим, я хочу получить кандидата находящегося в верхней четверти списка (верхние 25%). Каковы мои шансы тогда?
Вот пересмотренный код, который моделирует это.
-
- require 'rubygems'
- require 'faster_csv'
-
- population_size = 20
- sample_size = 0..population_size-1
- iteration_size = 100000
- top = (population_size-5)..(population_size-1)
- FasterCSV.open('optimal.csv', 'w') do |csv|
- sample_size.each do |size|
- is_best_choice_count = 0
- is_top_choice_count = 0
- iteration_size.times do
- population = (0..population_size-1).to_a.sort_by {rand}
- sample = population.slice(0..size-1)
- rest_of_population = population[size..population_size-1]
- best_sample = sample.sort.last
- best_next = rest_of_population.find {|i| i > best_sample}
- best_population = population.sort.last
- top_population = population.sort[top]
- is_best_choice_count += 1 if best_next == best_population
- is_top_choice_count += 1 if top_population.include? best_next
- end
- best_probability = is_best_choice_count.to_f/iteration_size.to_f
- top_probability = is_top_choice_count.to_f/iteration_size.to_f
- csv << [size, best_probability, top_probability]
- end
- end
-
В файле Optimal.csv мы добавили новую колонку, которая содержит верхнюю четверть (top 25%) кандидатов. Ниже показан новый график. Для сравнения добавлены результаты предыдущего моделирования.
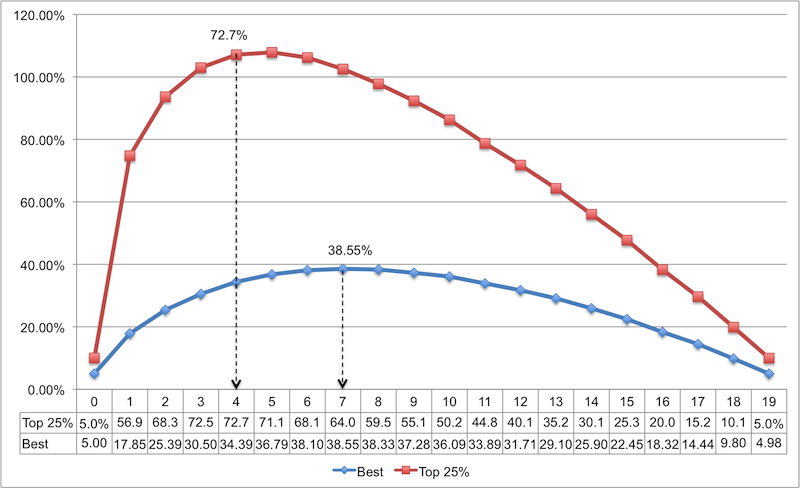
Теперь результат обнадеживает, наиболее оптимальный размер списка-образца составляет 4 (хотя для практических целей и 3 достаточно хорошо, так как разница между 3 и 4 мала). В этом случае вероятность выбора кандидата из верхней четверти списка устремляется к 72,7%. Великолепно!
Теперь разберемся с 20 кандидатами. Как насчет списка с большим количеством кандидатов? Как эта стратегия выдержит, скажем, список, содержащий 100 кандидатов?
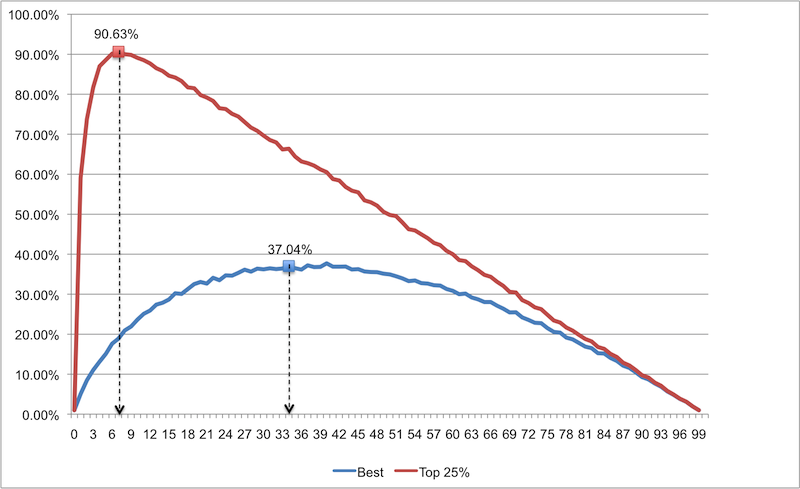
Как вы видите, эта стратегия не подходит для определения наилучшего кандидата из большого списка (список-образец слишком велик, а вероятность успеха слишком низка). Этот результат хуже, чем полученный нами для списка с меньшей численностью. Однако, если нас устроит кандидат из верхней четверти списка (т.е. будем менее требовательны), нам достаточно 7 кандидатов в списке-образце, при этом вероятность достижения необходимых результатов составит 90.63%. Это изумительные шансы!
Это значит, если вы менеджер по найму с сотней кандидатов, вам не нужно пытаться убить себя, интервьюируя каждого. Просто проинтервьюируйте список-образец из 7 кандидатов, выберите лучшего, а затем интервьюируйте остальных одного за другим, пока не встретите того, который лучше, чем лучший в списке-образце. Вероятность того, что вы выберите кого-либо из лучших 25% списка в 100 кандидатов составит 90.63% (и это, вероятно, будет тот, кто вам нужен)!
